hdfs file system shell的簡單使用
1、背景
此處我們通過命令列,簡單的學習一下 hdfs file system shell 的一些操作。
2、hdfs file system shell命令有哪些
我們可以通過如下網址https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html來看看支援的命令操作。 其中大部分命令都和linux的命令用法類似。
3、確定shell操作的是哪個檔案系統

# 操作本地檔案系統
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls file:///
Found 19 items
dr-xr-xr-x - root root 24576 2023-02-18 14:47 file:///bin
dr-xr-xr-x - root root 4096 2022-06-13 10:41 file:///boot
drwxr-xr-x - root root 3140 2023-02-28 20:17 file:///dev
......
# 操作hdfs 檔案系統
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls hdfs://hadoop01:8020/
Found 1 items
drwxrwx--- - hadoopdeploy supergroup 0 2023-02-19 17:20 hdfs://hadoop01:8020/tmp
# 操作hdfs 檔案系統 fs.defaultFS
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /
Found 1 items
drwxrwx--- - hadoopdeploy supergroup 0 2023-02-19 17:20 /tmp
[hadoopdeploy@hadoop01 ~]$
4、本地準備如下檔案
| 檔名 | 內容 |
|---|---|
| 1.txt | aaa |
| 2.txt | bbb |
| 3.txt | ccc |
5、hdfs file system shell
5.1 mkdir建立目錄
語法: Usage: hadoop fs -mkdir [-p] <paths>
-p表示,如果父目錄不存在,則建立父目錄。
[hadoopdeploy@hadoop01 sbin]$ hadoop fs -mkdir -p /bigdata/hadoop
[hadoopdeploy@hadoop01 sbin]$
5.2 put上傳檔案
語法: Usage: hadoop fs -put [-f] [-p] [-d] [-t <thread count>] [-q <thread pool queue size>] [ - | <localsrc> ...] <dst>
-f 如果目標檔案已經存在,則進行覆蓋操作
-p 保留存取和修改時間、所有權和許可權
-d 跳過._COPYING_的臨時檔案
-t 要使用的執行緒數,預設為1。上傳包含1個以上檔案的目錄時很有用
-q 要使用的執行緒池佇列大小,預設為1024。只有執行緒數大於1時才生效
# 建立3個檔案 1.txt 2.txt 3.txt
[hadoopdeploy@hadoop01 ~]$ echo aaa > 1.txt
[hadoopdeploy@hadoop01 ~]$ echo bbb > 2.txt
[hadoopdeploy@hadoop01 ~]$ echo ccc > 3.txt
# 上傳原生的 1.txt 到hdfs的 /bigdata/hadoop 目錄中
[hadoopdeploy@hadoop01 ~]$ hadoop fs -put -p 1.txt /bigdata/hadoop
# 因為 /bigdata/hadoop 中已經存在了 1.txt 所有上傳失敗
[hadoopdeploy@hadoop01 ~]$ hadoop fs -put -p 1.txt /bigdata/hadoop
put: `/bigdata/hadoop/1.txt': File exists
# 通過 -f 引數,如果目標檔案已經存在,則進行覆蓋操作
[hadoopdeploy@hadoop01 ~]$ hadoop fs -put -p -f 1.txt /bigdata/hadoop
# 檢視 /bigdata/hadoop 目錄中的檔案
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop
Found 1 items
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
# 通過多執行緒和 萬用字元 上傳多個檔案
[hadoopdeploy@hadoop01 ~]$ hadoop fs -put -p -f -t 3 *.txt /bigdata/hadoop
# 檢視 /bigdata/hadoop 目錄中的檔案
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop
Found 3 items
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
5.3 ls檢視目錄或檔案
語法: Usage: hadoop fs -ls [-h] [-R] <paths>
-h 展示成人類可讀的,比如檔案的大小,展示成多少M等。
-R 遞迴展示。
# 列出/bigdata 目錄和檔案
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/
Found 1 items
drwxr-xr-x - hadoopdeploy supergroup 0 2023-02-28 12:37 /bigdata/hadoop
# -R 遞迴展示
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls -R /bigdata/
drwxr-xr-x - hadoopdeploy supergroup 0 2023-02-28 12:37 /bigdata/hadoop
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
# -h 展示成人類可讀的,比如多少k,多少M等
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls -R -h /bigdata/
drwxr-xr-x - hadoopdeploy supergroup 0 2023-02-28 12:37 /bigdata/hadoop
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
5.4 cat 檢視檔案內容
語法: Usage: hadoop fs -cat [-ignoreCrc] URI [URI ...]
-ignoreCrc 禁用checkshum驗證
注意: 如果檔案比較大,需要慎重讀取,因為這是檢視檔案的全部內容
# 檢視 1.txt 和 2.txt 的檔案內容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat -ignoreCrc /bigdata/hadoop/1.txt /bigdata/hadoop/2.txt
aaa
bbb
[hadoopdeploy@hadoop01 ~]$
5.5 head 檢視檔案前1000位元組內容
語法: Usage: hadoop fs -head URI
Displays first kilobyte of the file to stdout(顯示檔案的前1000位元組)
# 檢視1.txt的前1000位元組
[hadoopdeploy@hadoop01 ~]$ hadoop fs -head /bigdata/hadoop/1.txt
aaa
[hadoopdeploy@hadoop01 ~]$
5.6 tail 檢視檔案後1000位元組內容
語法: Usage:hadoop fs -tail [-f] URI
Displays last kilobyte of the file to stdout.(顯示檔案的後1000位元組)
-f:表示將隨著檔案的增長輸出附加資料,就像在Unix中一樣。
# 檢視1.txt的後1000位元組
[hadoopdeploy@hadoop01 ~]$ hadoop fs -tail /bigdata/hadoop/1.txt
aaa
[hadoopdeploy@hadoop01 ~]$
5.7 appendToFile 追加資料到hdfs檔案中
語法: Usage: hadoop fs -appendToFile <localsrc> ... <dst>
將單個src或多個src從本地檔案系統附加到目標檔案系統。還可以從標準輸入(localsrc是-)讀取輸入並附加到目標檔案系統。
# 檢視1.txt檔案的內容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat /bigdata/hadoop/1.txt
aaa
# 檢視2.txt檔案的內容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat /bigdata/hadoop/2.txt
bbb
# 將1.txt檔案的內容追加到2.txt檔案中
[hadoopdeploy@hadoop01 ~]$ hadoop fs -appendToFile 1.txt /bigdata/hadoop/2.txt
# 再次檢視2.txt檔案的內容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat /bigdata/hadoop/2.txt
bbb
aaa
[hadoopdeploy@hadoop01 ~]$
5.8 get下載檔案
語法: Usage: hadoop fs -get [-ignorecrc] [-crc] [-p] [-f] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>
將檔案複製到本地檔案系統。可以使用-gnrecrc選項複製未能通過CRC檢查的檔案。可以使用-crc選項複製檔案和CRC。
-f 如果目標檔案已經存在,則進行覆蓋操作
-p 保留存取和修改時間、所有權和許可權
-t 要使用的執行緒數,預設為1。下載包含多個檔案的目錄時很有用
-q 要使用的執行緒池佇列大小,預設為1024。只有執行緒數大於1時才生效
# 下載hdfs檔案系統的1.txt 到本地當前目錄下的1.txt.download檔案
[hadoopdeploy@hadoop01 ~]$ hadoop fs -get /bigdata/hadoop/1.txt ./1.txt.download
# 檢視 1.txt.download是否存在
[hadoopdeploy@hadoop01 ~]$ ls
1.txt 1.txt.download 2.txt 3.txt
# 再次下載,因為本地已經存在1.txt.download檔案,所有報錯
[hadoopdeploy@hadoop01 ~]$ hadoop fs -get /bigdata/hadoop/1.txt ./1.txt.download
get: `./1.txt.download': File exists
# 通過 -f 覆蓋已經存在的檔案
[hadoopdeploy@hadoop01 ~]$ hadoop fs -get -f /bigdata/hadoop/1.txt ./1.txt.download
# 多執行緒下載
[hadoopdeploy@hadoop01 ~]$ hadoop fs -get -f -t 3 /bigdata/hadoop/*.txt ./123.txt.download
get: `./123.txt.download': No such file or directory
# 多執行緒下載
[hadoopdeploy@hadoop01 ~]$ hadoop fs -get -f -t 3 /bigdata/hadoop/*.txt .
[hadoopdeploy@hadoop01 ~]$
5.9 getmerge合併下載
語法: Usage: hadoop fs -getmerge [-nl] [-skip-empty-file] <src> <localdst>
將多個src檔案的內容合併到localdst檔案中
-nl 表示在每個檔案末尾增加換行符
-skip-empty-file 跳過空檔案
# hdfs上1.txt檔案的內容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat /bigdata/hadoop/1.txt
aaa
# hdfs上3.txt檔案的內容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat /bigdata/hadoop/3.txt
ccc
# 將hdfs上1.txt 3.txt下載到本地 merge.txt 檔案中 -nl增加換行符 -skip-empty-file跳過空檔案
[hadoopdeploy@hadoop01 ~]$ hadoop fs -getmerge -nl -skip-empty-file /bigdata/hadoop/1.txt /bigdata/hadoop/3.txt ./merge.txt
# 檢視merge.txt檔案
[hadoopdeploy@hadoop01 ~]$ cat merge.txt
aaa
ccc
[hadoopdeploy@hadoop01 ~]$
5.10 cp複製檔案
語法: Usage: hadoop fs -cp [-f] [-p | -p[topax]] [-t <thread count>] [-q <thread pool queue size>] URI [URI ...] <dest>
-f 如果目標檔案存在則進行覆蓋。
-t 要使用的執行緒數,預設為1。複製包含多個檔案的目錄時很有用
-q 要使用的執行緒池佇列大小,預設為1024。只有執行緒數大於1時才生效
# 檢視 /bigdata目錄下的檔案
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata
Found 1 items
drwxr-xr-x - hadoopdeploy supergroup 0 2023-02-28 12:55 /bigdata/hadoop
# 檢視/bigdata/hadoop目錄下的檔案
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop
Found 3 items
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 8 2023-02-28 12:55 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
# 將 /bigdata/hadoop 目錄下所有的檔案 複製到 /bigdata 目錄下
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cp /bigdata/hadoop/* /bigdata
# 檢視 /bigdata/ 目錄下的檔案
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata
Found 4 items
-rw-r--r-- 2 hadoopdeploy supergroup 4 2023-02-28 13:17 /bigdata/1.txt
-rw-r--r-- 2 hadoopdeploy supergroup 8 2023-02-28 13:17 /bigdata/2.txt
-rw-r--r-- 2 hadoopdeploy supergroup 4 2023-02-28 13:17 /bigdata/3.txt
drwxr-xr-x - hadoopdeploy supergroup 0 2023-02-28 12:55 /bigdata/hadoop
[hadoopdeploy@hadoop01 ~]$
5.11 mv移動檔案
語法: Usage: hadoop fs -mv URI [URI ...] <dest>
將檔案從源移動到目標。此命令還允許多個源,在這種情況下,目標需要是一個目錄。不允許跨檔案系統移動檔案。
# 列出 /bigdata/hadoop 目錄下的檔案
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop
Found 3 items
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 8 2023-02-28 12:55 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
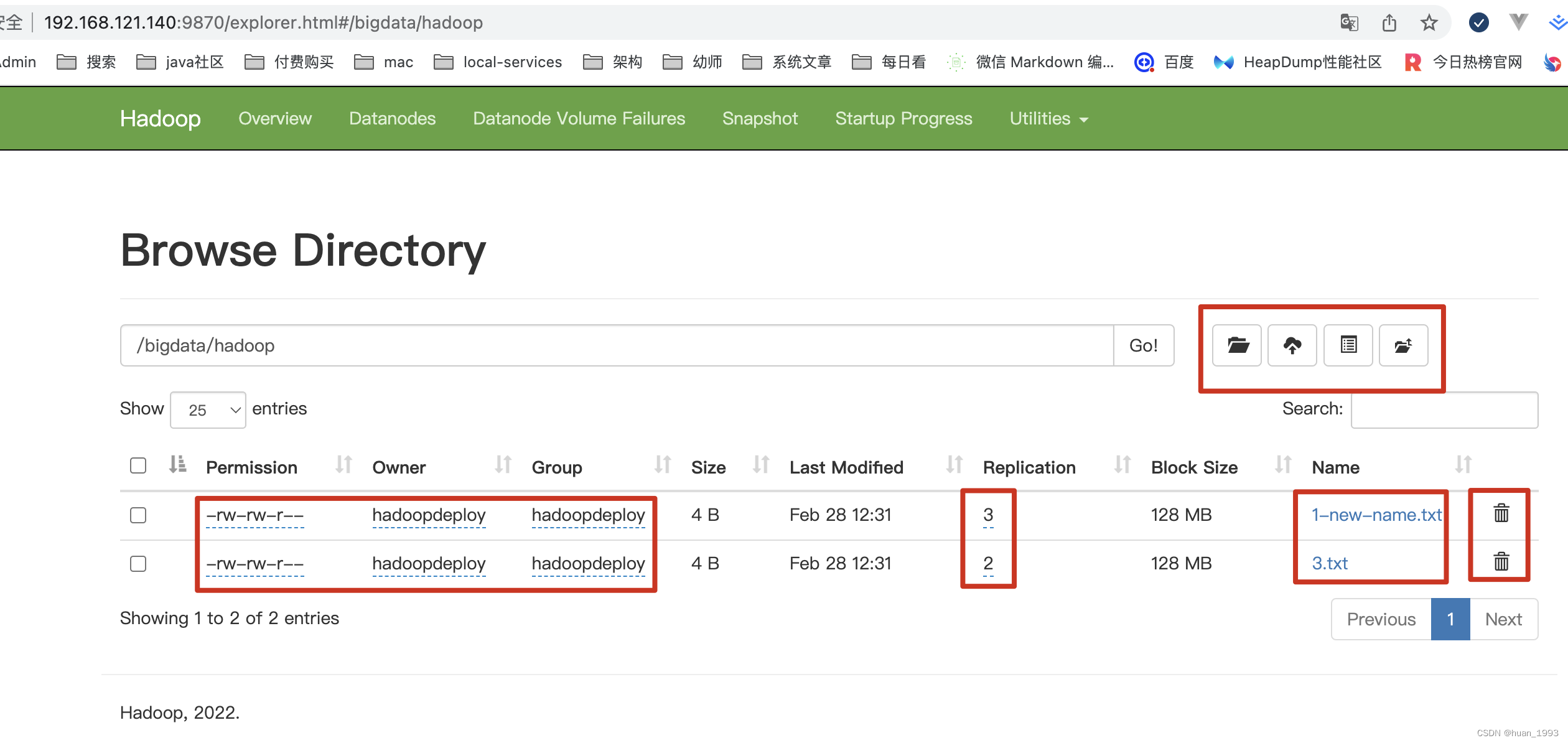
# 將 1.txt 重新命名為 1-new-name.txt
[hadoopdeploy@hadoop01 ~]$ hadoop fs -mv /bigdata/hadoop/1.txt /bigdata/hadoop/1-new-name.txt
# 列出 /bigdata/hadoop 目錄下的檔案,可以看到1.txt已經改名了
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop
Found 3 items
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1-new-name.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 8 2023-02-28 12:55 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
[hadoopdeploy@hadoop01 ~]$
5.12 setrep 修改指定檔案的副本數
語法: Usage: hadoop fs -setrep [-R] [-w] <numReplicas> <path>
更改檔案的副本數。如果path是一個目錄,則該命令遞迴更改以path為根的目錄樹下所有檔案的副本數。執行此命令時,EC檔案將被忽略。
-R -R標誌是為了向後相容。它沒有影響。
-w -w標誌請求命令等待複製完成。這可能需要很長時間。
# 修改1-new-name.txt檔案為3個副本
[hadoopdeploy@hadoop01 ~]$ hadoop fs -setrep -w 3 /bigdata/hadoop/1-new-name.txt
Replication 3 set: /bigdata/hadoop/1-new-name.txt
Waiting for /bigdata/hadoop/1-new-name.txt .... done
[hadoopdeploy@hadoop01 ~]$
5.13 df顯示可用空間
語法: Usage: hadoop fs -df [-h] URI [URI ...]
[hadoopdeploy@hadoop01 ~]$ hadoop fs -df /bigdata/hadoop
Filesystem Size Used Available Use%
hdfs://hadoop01:8020 27697086464 1228800 17716019200 0%
# -h 顯示人類可讀的
[hadoopdeploy@hadoop01 ~]$ hadoop fs -df -h /bigdata/hadoop
Filesystem Size Used Available Use%
hdfs://hadoop01:8020 25.8 G 1.2 M 16.5 G 0%
5.14 du統計資料夾或檔案的大小
語法: Usage: hadoop fs -df [-h] URI [URI ...]
[hadoopdeploy@hadoop01 ~]$ hadoop fs -du /bigdata/hadoop
4 12 /bigdata/hadoop/1-new-name.txt
8 16 /bigdata/hadoop/2.txt
4 8 /bigdata/hadoop/3.txt
[hadoopdeploy@hadoop01 ~]$ hadoop fs -du -s /bigdata/hadoop
16 36 /bigdata/hadoop
[hadoopdeploy@hadoop01 ~]$ hadoop fs -du -s -h /bigdata/hadoop
16 36 /bigdata/hadoop
# 16 表示/bigdata/hadoop目錄下所有檔案的總大小
# 36 表示/bigdata/hadoop目錄下所有檔案佔據所有副本的總大小
[hadoopdeploy@hadoop01 ~]$ hadoop fs -du -s -h -v /bigdata/hadoop
SIZE DISK_SPACE_CONSUMED_WITH_ALL_REPLICAS FULL_PATH_NAME
16 36 /bigdata/hadoop
[hadoopdeploy@hadoop01 ~]$
5.15 chgrp chmod chown改變檔案的所屬許可權
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 8 2023-02-28 12:55 /bigdata/hadoop/2.txt
# 給2.txt增加可執行的許可權
[hadoopdeploy@hadoop01 ~]$ hadoop fs -chmod +x /bigdata/hadoop/2.txt
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop/2.txt
-rwxrwxr-x 2 hadoopdeploy hadoopdeploy 8 2023-02-28 12:55 /bigdata/hadoop/2.txt
[hadoopdeploy@hadoop01 ~]$
5.16 rm刪除檔案或目錄
語法: Usage: hadoop fs -rm [-f] [-r |-R] [-skipTrash] [-safely] URI [URI ...]
如果啟用了回收站,檔案系統會將已刪除的檔案移動到垃圾箱目錄。
目前,預設情況下禁用垃圾桶功能。使用者可以通過為引數fs. trash.interval(在core-site.xml中)設定大於零的值來啟用回收站。
-f 如果檔案不存在,將不會顯示診斷訊息或修改退出狀態以反映錯誤。
-R 選項遞迴刪除目錄及其下的任何內容。
-r 選項等價於-R。
-skipTrash 選項將繞過回收站,如果啟用,並立即刪除指定的檔案。當需要從大目錄中刪除檔案時,這很有用。
-safely 在刪除檔案總數大於 hadoop.shell.delete.limited.num.files的檔案時(在core-site.xml中,預設值為100)之前,需要進行安全確認
# 刪除2.txt,因為我本地啟動了回收站,所以檔案刪除的檔案進入了回收站
[hadoopdeploy@hadoop01 ~]$ hadoop fs -rm /bigdata/hadoop/2.txt
2023-02-28 22:04:51,302 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop01:8020/bigdata/hadoop/2.txt' to trash at: hdfs://hadoop01:8020/user/hadoopdeploy/.Trash/Current/bigdata/hadoop/2.txt
[hadoopdeploy@hadoop01 ~]$
6、介面操作
可能有些人會說,這麼多的命令,怎麼記的住,如果我們可以操作hdfs的介面,則可以在介面上進行操作。
7、參考連結
1、https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html
本文來自部落格園,作者:huan1993,轉載請註明原文連結:https://www.cnblogs.com/huan1993/p/17167762.html