【譯】.NET 7 中的效能改進(八)
原文 | Stephen Toub
翻譯 | 鄭子銘
Mono
到目前為止,我一直提到 "JIT"、"GC "和 "執行時",但實際上在.NET中存在多個執行時。我一直在談論 "coreclr",它是推薦在Linux、macOS和Windows上使用的執行時。然而,還有 "mono",它為Blazor wasm應用程式、Android應用程式和iOS應用程式提供動力。它在.NET 7中也有明顯的改進。
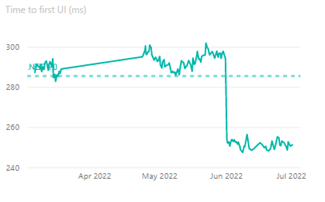
就像coreclr(它可以JIT編譯,AOT編譯部分JIT回退,以及完全Native AOT編譯),mono有多種實際執行程式碼的方式。其中一種方式是直譯器,它使mono能夠在不允許JIT的環境中執行.NET程式碼,而不需要提前編譯或招致它可能帶來的任何限制。有趣的是,直譯器本身幾乎就是一個成熟的編譯器,它解析IL,為其生成自己的中間表示法 (intermediate representation)(IR),並在IR上進行一次或多次優化;只是在流水線的末端,當編譯器通常會發出程式碼時,直譯器卻將這些資料儲存下來,以便在執行時進行解釋。因此,直譯器有一個與我們討論的coreclr的JIT非常相似的難題:優化的時間與快速啟動的願望。在.NET 7中,直譯器採用了類似的解決方案:分層編譯。 dotnet/runtime#68823增加了直譯器的能力,最初編譯時對IR進行最小的優化,然後一旦達到一定的呼叫次數閾值,就花時間對IR進行儘可能多的優化,用於該方法的所有未來呼叫。這產生了與coreclr相同的好處:改善了啟動時間,同時也有高效的持續吞吐量。當這一點合併後,我們看到Blazor wasm應用程式的啟動時間改善了10-20%。下面是我們的基準測試系統中正在跟蹤的一個應用的例子。
不過,直譯器並不只是用於整個應用程式。就像coreclr可以在R2R影象不包含方法的程式碼時使用JIT一樣,mono可以在一個方法沒有AOT程式碼時使用直譯器。在mono上發生的這種情況是泛型委託的呼叫,在這種情況下,泛型委託的呼叫會觸發回落到直譯器;對於.NET 7,這種差距已經通過dotnet/runtime#70653解決。然而,一個更有影響的案例是dotnet/runtime#64867。以前,任何帶有catch或filter例外處理條款的方法都不能被AOT編譯,而會退回到被解釋的狀態。有了這個PR,方法現在可以被AOT編譯,而且只有當異常真正發生時,它才會退回到使用直譯器,在該方法呼叫的剩餘執行過程中切換到直譯器。由於許多方法都包含這樣的條款,這可以使吞吐量和CPU消耗有很大的不同。同樣地,dotnet/runtime#63065使帶有finally例外處理條款的方法能夠被AOT編譯;只有finally塊被解釋,而不是整個方法被解釋。
除了這樣的後端改進,另一類改進來自coreclr和mono之間的進一步統一。幾年前,coreclr和mono有自己的整個庫堆疊,建立在它們之上。隨著時間的推移,隨著.NET的開源,mono的部分棧被共用元件一點一點地取代。時至今日,無論採用哪種執行時,System.Private.CoreLib以上的所有核心.NET庫都是一樣的。事實上,CoreLib本身的原始碼幾乎完全是共用的,大約95%的原始檔被編譯到為每個執行時構建的CoreLib中,只有百分之幾的原始檔是專門為每個執行時準備的(這些宣告意味著本篇文章其餘部分討論的絕大多數效能改進無論在mono和coreclr上執行都同樣適用)。即使如此,現在的每一個版本我們都在努力減少剩下的百分之幾,這不僅是出於可維護性的考慮,而且還因為從效能的角度來看,用於coreclr的CoreLib的原始碼通常會得到更多的關注。例如,dotnet/runtime#71325將mono的陣列和跨度排序通用排序工具類轉移到coreclr使用的更有效的實現。
然而,最大的改進類別之一是向量化。這分為兩部分。首先,由於dotnet/runtime#64961、dotnet/runtime#65086、dotnet/runtime#65128、dotnet/runtime#66317、dotnet/runtime#66391、dotnet/runtime#66409、dotnet/runtime#66512、 dotnet/runtime#66586、 dotnet/runtime#66589、 dotnet/runtime#66597、 dotnet/runtime#66476和 dotnet/runtime#67125;等PR,Vector
反射 (Reflection)
反射是那些你要麼愛要麼恨的領域之一(我發現在寫完Native AOT部分後立即寫這一節有點幽默)。它的功能非常強大,提供了查詢程序中所有程式碼的後設資料和可能遇到的任意程式集的能力,動態呼叫任意功能,甚至在執行時發出動態生成的IL。面對像連結器這樣的工具或像Native AOT這樣的解決方案,它也很難很好地處理,因為它需要在構建時準確地確定哪些程式碼將被執行,而且它在執行時通常相當昂貴;因此它既是我們儘可能避免的東西,也是投資於減少成本的東西,因為它在許多不同型別的應用程式中如此受歡迎,因為它非常有用。與大多數版本一樣,它在.NET 7中也有一些不錯的改進。
受影響最大的領域之一是反射呼叫。通過MethodBase.Invoke,這個功能可以讓你使用一個MethodBase(例如MethodInfo)物件,該物件代表呼叫者之前查詢過的一些方法,並呼叫它,帶有任意的引數,執行時需要將這些引數傳遞給被呼叫者,並帶有任意的返回值,需要被傳遞回來。如果你提前知道方法的簽名,優化呼叫速度的最好方法是通過CreateDelegate
private MethodInfo _method;
[GlobalSetup]
public void Setup() => _method = typeof(Program).GetMethod("MyMethod", BindingFlags.NonPublic | BindingFlags.Static);
[Benchmark]
public void MethodInfoInvoke() => _method.Invoke(null, null);
private static void MyMethod() { }
| 方法 | 執行時 | 平均值 | 比率 |
|---|---|---|---|
| MethodInfoInvoke | .NET 6.0 | 43.846 ns | 1.00 |
| MethodInfoInvoke | .NET 7.0 | 8.078 ns | 0.18 |
反射還涉及到對代表型別、方法、屬性等的物件的大量操作,在使用這些API時,這裡和那裡的調整可以增加到一個可衡量的差異。例如,我在過去的效能文章中談到,我們實現效能提升的方法之一是將原生程式碼從執行時移植回託管的C#中,這可能是反直覺的。這樣做對效能的提升有多種方式,但其中之一是,從受控程式碼呼叫到執行時中會有一些開銷,而消除這種跳轉就可以避免這種開銷。這在dotnet/runtime#71873中可以看到充分的效果,它將與Type、RuntimeType(執行時用來表示其型別的Type派生類)和Enum相關的幾個 "FCalls "從本地轉移到託管。
[Benchmark]
public Type GetUnderlyingType() => Enum.GetUnderlyingType(typeof(DayOfWeek));
| 方法 | 執行時 | 平均值 | 比率 |
|---|---|---|---|
| GetUnderlyingType | .NET 6.0 | 27.413 ns | 1.00 |
| GetUnderlyingType | .NET 7.0 | 5.115 ns | 0.19 |
這種現象的另一個例子是dotnet/runtime#62866,它將AssemblyName的大部分底層支援從本地執行時程式碼轉移到CoreLib的受控程式碼中。這反過來又對任何使用它的東西產生了影響,比如當使用Activator.CreateInstance過載時,需要解析的組合名稱。
private readonly string _assemblyName = typeof(MyClass).Assembly.FullName;
private readonly string _typeName = typeof(MyClass).FullName;
public class MyClass { }
[Benchmark]
public object CreateInstance() => Activator.CreateInstance(_assemblyName, _typeName);
| 方法 | 執行時 | 平均值 | 比率 |
|---|---|---|---|
| CreateInstance | .NET 6.0 | 3.827 us | 1.00 |
| CreateInstance | .NET 7.0 | 2.276 us | 0.60 |
dotnet/runtime#67148刪除了由CreateInstance使用的RuntimeType.CreateInstanceImpl方法內部的幾個陣列和列表分配(使用Type.EmptyTypes而不是分配一個新的Type[0],避免不必要地將一個構建器變成一個陣列,等等),從而減少分配,加快吞吐。
[Benchmark]
public void CreateInstance() => Activator.CreateInstance(typeof(MyClass), BindingFlags.NonPublic | BindingFlags.Instance, null, Array.Empty<object>(), null);
internal class MyClass
{
internal MyClass() { }
}
| 方法 | 執行時 | 平均值 | 比率 | 已分配 | 分配比率 |
|---|---|---|---|---|---|
| CreateInstance | .NET 6.0 | 167.8 ns | 1.00 | 320 B | 1.00 |
| CreateInstance | .NET 7.0 | 143.4 ns | 0.85 | 200 B | 0.62 |
例如,dotnet/runtime#66750更新了AssemblyName.FullName的計算,使用堆疊分配的記憶體和ArrayPool
private AssemblyName[] _names = AppDomain.CurrentDomain.GetAssemblies().Select(a => new AssemblyName(a.FullName)).ToArray();
[Benchmark]
public int Names()
{
int sum = 0;
foreach (AssemblyName name in _names)
{
sum += name.FullName.Length;
}
return sum;
}
| 方法 | 執行時 | 平均值 | 比率 | 已分配 | 分配比率 |
|---|---|---|---|---|---|
| Names | .NET 6.0 | 3.423 us | 1.00 | 9.14 KB | 1.00 |
| Names | .NET 7.0 | 2.010 us | 0.59 | 2.43 KB | 0.27 |
更多與反射有關的操作也被變成了JIT的內在因素,正如前面討論的那樣,使JIT能夠在JIT編譯時而不是在執行時計算各種問題的答案。例如,在dotnet/runtime#67852中的Type.IsByRefLike就是這樣做的。
[Benchmark]
public bool IsByRefLike() => typeof(ReadOnlySpan<char>).IsByRefLike;
| 方法 | 執行時 | 平均值 | 比率 | 程式碼大小 |
|---|---|---|---|---|
| IsByRefLike | .NET 6.0 | 2.1322 ns | 1.000 | 31 B |
| IsByRefLike | .NET 7.0 | 0.0000 ns | 0.000 | 6 B |
在benchmarkdotnet的一個警告中指出,.NET 7的版本如此接近於零。
// * Warnings *
ZeroMeasurement
Program.IsByRefLike: Runtime=.NET 7.0, Toolchain=net7.0 -> The method duration is indistinguishable from the empty method duration
而它與一個空方法沒有區別,因為它實際上就是這樣,我們可以從反組合中看到。
; Program.IsByRefLike()
mov eax,1
ret
; Total bytes of code 6
還有一些很難看到的改進,但它們消除了作為填充反射快取的一部分的開銷,最終減少了通常在啟動路徑上所做的工作,幫助應用程式更快地啟動。dotnet/runtime#66825、dotnet/runtime#66912和dotnet/runtime#67149都屬於這一類別,它們消除了作為收集引數、屬性和事件資料一部分的不必要的或重複的陣列分配。
互操作 (Interop)
長期以來,.NET對互操作有很好的支援,使.NET應用程式能夠消費大量用其他語言編寫的功能和/或由底層作業系統暴露的功能。這種支援的基礎是 "平臺呼叫 "或 "P/Invoke",在程式碼中通過應用於方法的[DllImport(..)]表示。DllImportAttribute可以宣告一個可以像其他.NET方法一樣被呼叫的方法,但它實際上代表了一些外部方法,當這個管理方法被呼叫時,執行時應該呼叫這些方法。DllImport指定了關於該函數在哪個庫中的細節,它在該庫的匯出中的實際名稱是什麼,關於輸入引數和返回值的高階細節,等等,執行時確保所有正確的事情發生。這種機制在所有的作業系統上都適用。例如,Windows有一個方法CreatePipe用於建立匿名管道。
BOOL CreatePipe(
[out] PHANDLE hReadPipe,
[out] PHANDLE hWritePipe,
[in, optional] LPSECURITY_ATTRIBUTES lpPipeAttributes,
[in] DWORD nSize
);
如果我想從C#中呼叫這個函數,我可以宣告一個[DllImport(...)]的對應函數,然後我可以像呼叫其他託管方法一樣呼叫它。
[DllImport("kernel32", SetLastError = true)]
[return: MarshalAs(UnmanagedType.Bool)]
private static unsafe extern bool CreatePipe(
out SafeFileHandle hReadPipe,
out SafeFileHandle hWritePipe,
void* lpPipeAttributes,
uint nSize);
這裡有幾個有趣的事情要注意。有幾個引數是可以直接使用的,在管理方和本地方都有相同的表示方法,例如,lpPipeAttributes是一個指標,nSize是一個32位元的整數。但是返回值呢?C#中的bool型別(System.Boolean)是一個位元組的型別,但是本地簽名中的BOOL型別是四個位元組;因此呼叫這個託管方法的程式碼不能直接呼叫本地函數,因為需要有一些 "marshalling "邏輯,將四個位元組的返回BOOL轉換為一個位元組的返回bool。同樣,本地函數有兩個輸出指標hReadPipe和hWritePipe,但託管簽名宣告了兩個SafeFileHandles(SafeHandle是一種.NET型別,它包裹著一個指標,並提供一個finalizer和Dispose方法,以確保該指標在不再被使用時被適當地清理)。一些邏輯需要把本地函數產生的輸出控制程式碼包進這些SafeFileHandles中,以便從管理方法中輸出。那SetLastError = true呢?.NET有Marshal.GetLastPInvokeError()這樣的方法,有些程式碼需要接收這個方法產生的任何錯誤,並確保它可以通過後續的GetLastPInvokeError()來使用。
如果不需要編排邏輯,例如管理簽名和本地簽名在所有的意圖和目的上都是一樣的,所有的引數都是可編排的,所有的返回值都是可編排的,在方法的呼叫上不需要額外的邏輯,等等,那麼[DllImport(...)]最終就是一個簡單的穿透,執行時需要做很少的工作來實現它。然而,如果[DllImport(...)]涉及到任何這種編排工作,執行時需要生成一個 "存根",建立一個專門的方法,當[DllImport(...)]被呼叫時,它將處理所有的輸入,委託給實際的本地函數,並且修復所有的輸出。該存根在執行時生成,執行時有效地進行反射發射,動態地生成IL,然後進行JIT。
這樣做有很多弊端。首先,它需要時間來生成所有的marshalling程式碼,這些時間可能會對使用者體驗產生負面影響,比如啟動時。第二,其實現的性質抑制了各種優化,如內聯。第三,有些平臺不允許使用JIT,因為允許動態生成的程式碼被執行的安全風險(或者在Native AOT的情況下,根本就沒有JIT)。第四,這一切都被隱藏起來,使開發人員更難真正理解發生了什麼。
但如果這些邏輯都能在構建時而不是在執行時生成呢?生成程式碼的成本將只在構建時產生,而不是在每個程序執行時產生。這些程式碼將有效地成為使用者程式碼,擁有所有C#編譯器和執行時的優化功能。這些程式碼將成為應用程式的一部分,能夠使用任何理想的AOT系統進行提前編譯,無論是crossgen還是Native AOT或其他系統。這些程式碼是可以檢查的,使用者可以檢視,以瞭解到底有哪些工作是代表他們完成的。聽起來非常令人嚮往。聽起來很神奇。聽起來像是前面提到的Roslyn原始碼生成器的工作。
.NET 6在.NET SDK中包含了幾個原始碼生成器,而.NET 7在此基礎上又增加了幾個。其中一個是全新的LibraryImport生成器,它提供的正是我們剛才討論的神奇的、理想的解決方案。
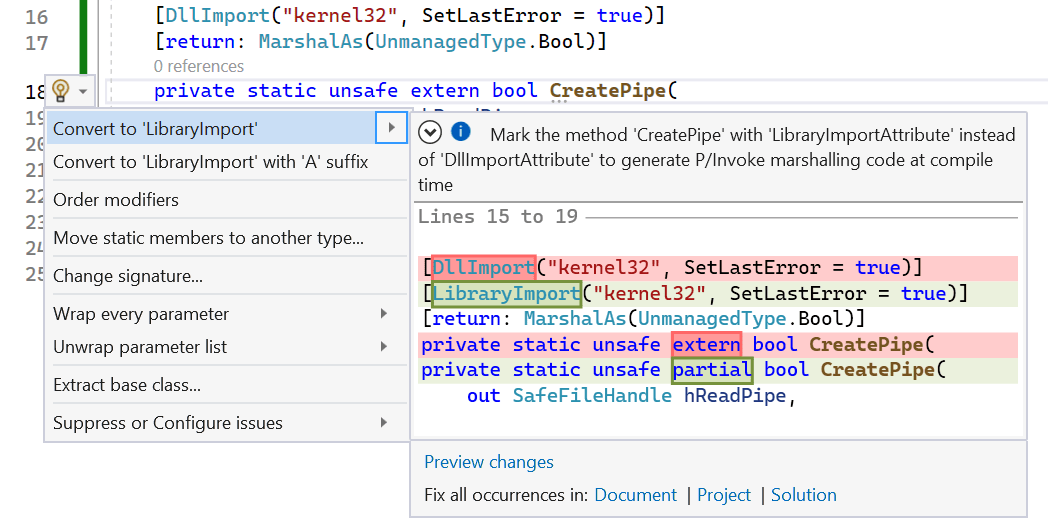
讓我們回到我們之前的CreatePipe例子。我們將做兩個小調整。我們把屬性從DllImport改為LibraryImport,並把extern關鍵字改為部分。
[LibraryImport("kernel32", SetLastError = true)]
[return: MarshalAs(UnmanagedType.Bool)]
private static unsafe partial bool CreatePipe(
out SafeFileHandle hReadPipe,
out SafeFileHandle hWritePipe,
void* lpPipeAttributes,
uint nSize);
現在,如果你在家裡的Visual Studio中跟隨,試著右擊CreatePipe並選擇Go to Definition。這可能看起來有點奇怪。"轉到定義?這不是定義嗎?" 這是一個部分方法,這是一種宣告的方式,由另一個部分定義來填補,在這種情況下,.NET 7 SDK中的原始碼生成器注意到了這個帶有[LibraryImport]屬性的方法,並完全生成了整個C#中的marshalling stub程式碼,直接構建在程式集中。雖然預設情況下,這些程式碼不會被持久化,但Visual Studio仍然允許你瀏覽它(你可以通過在你的.csproj中新增
[System.CodeDom.Compiler.GeneratedCodeAttribute("Microsoft.Interop.LibraryImportGenerator", "7.0.6.42316")]
[System.Runtime.CompilerServices.SkipLocalsInitAttribute]
private static unsafe partial bool CreatePipe(out global::Microsoft.Win32.SafeHandles.SafeFileHandle hReadPipe, out global::Microsoft.Win32.SafeHandles.SafeFileHandle hWritePipe, void* lpPipeAttributes, uint nSize)
{
int __lastError;
bool __invokeSucceeded = default;
System.Runtime.CompilerServices.Unsafe.SkipInit(out hReadPipe);
System.Runtime.CompilerServices.Unsafe.SkipInit(out hWritePipe);
System.IntPtr __hReadPipe_native = default;
System.IntPtr __hWritePipe_native = default;
bool __retVal;
int __retVal_native = default;
// Setup - Perform required setup.
global::Microsoft.Win32.SafeHandles.SafeFileHandle hReadPipe__newHandle = new global::Microsoft.Win32.SafeHandles.SafeFileHandle();
global::Microsoft.Win32.SafeHandles.SafeFileHandle hWritePipe__newHandle = new global::Microsoft.Win32.SafeHandles.SafeFileHandle();
try
{
{
System.Runtime.InteropServices.Marshal.SetLastSystemError(0);
__retVal_native = __PInvoke(&__hReadPipe_native, &__hWritePipe_native, lpPipeAttributes, nSize);
__lastError = System.Runtime.InteropServices.Marshal.GetLastSystemError();
}
__invokeSucceeded = true;
// Unmarshal - Convert native data to managed data.
__retVal = __retVal_native != 0;
}
finally
{
if (__invokeSucceeded)
{
// GuaranteedUnmarshal - Convert native data to managed data even in the case of an exception during the non-cleanup phases.
System.Runtime.InteropServices.Marshal.InitHandle(hWritePipe__newHandle, __hWritePipe_native);
hWritePipe = hWritePipe__newHandle;
System.Runtime.InteropServices.Marshal.InitHandle(hReadPipe__newHandle, __hReadPipe_native);
hReadPipe = hReadPipe__newHandle;
}
}
System.Runtime.InteropServices.Marshal.SetLastPInvokeError(__lastError);
return __retVal;
// Local P/Invoke
[System.Runtime.InteropServices.DllImportAttribute("kernel32", EntryPoint = "CreatePipe", ExactSpelling = true)]
static extern unsafe int __PInvoke(System.IntPtr* hReadPipe, System.IntPtr* hWritePipe, void* lpPipeAttributes, uint nSize);
}
通過這個,你可以準確地讀出正在進行的Marshalling工作。兩個SafeHandle範例正在被分配,然後在本地函數完成後,Marshal.InitHandle方法被用來將產生的控制程式碼儲存到這些範例中(分配發生在本地函數呼叫之前,因為如果SafeHandle分配由於超出記憶體的情況而失敗,在本地控制程式碼已經產生後執行分配會增加洩漏的機會)。BOOL到bool的轉換是通過!=0的比較進行的。錯誤資訊是通過在本地函數呼叫後呼叫Marshal.GetLastSystemError(),然後在返回前呼叫Marshal.SetLastPInvokeError(int)來獲取。實際的本地函數呼叫仍然通過[DllImport(...)]實現,但現在P/Invoke是可控的,不需要執行時生成任何存根,因為所有這些工作都在這段C#程式碼中處理了。
為了實現這一點,我們做了大量的工作。去年,我在《.NET 6的效能改進》中提到了其中的一些內容,但在.NET 7中又做了大量的工作,以完善設計,使其實現穩健,在所有的dotnet/runtime和其他地方推廣,並向所有的C#開發人員公開這些功能。
LibraryImport生成器是作為dotnet/runtimelab的一個實驗開始的。當它準備就緒時,dotnet/runtime#59579將180個跨越多年的努力提交到dotnet/runtime主分支。
在.NET 6中,整個核心.NET庫有近3000個[DllImport]的使用。截至我寫這篇文章時,在.NET 7中,有......讓我搜尋一下......7個(我希望可以說是0個,但還有一些零星的,主要與COM互操作有關,仍然存在)。這並不是一夜之間發生的轉變。大量的PR逐個庫進行了新舊轉換,例如dotnet/runtime#62295和dotnet/runtime#61640,用於System.Private.CoreLib,dotnet/runtime#61742和dotnet/runtime#62309用於加密庫,dotnet/runtime#61765用於網路,dotnet/runtime#61996和dotnet/runtime#61638用於大多數其他I/O相關的庫,還有dotnet/runtime#61975,dotnet/runtime#61389, dotnet/runtime#62353, dotnet/runtime#61990, dotnet/runtime#61949, dotnet/runtime#61805, dotnet/runtime#61741, dotnet/runtime#61184, dotnet/runtime#54290, dotnet/runtime#62365, dotnet/runtime#61609, dotnet/runtime#61532, and dotnet/runtime#54236 中的長尾部分的額外移植。
如果有一個工具來幫助實現自動化,這樣的移植工作就會變得非常容易。 dotnet/runtime#72819啟用了分析器和固定器來執行這些轉換。
還有很多其他的PR,使LibraryImport生成器成為.NET 7的現實。為了突出一些,dotnet/runtime#63320引入了一個新的[DisabledRuntimeMarshalling]屬性,可以在程式集級別指定,以禁用所有執行時內建的marshalling;在這一點上,作為互操作的一部分進行的唯一marshalling是在使用者的程式碼中進行的marshalling,例如,由[LibraryImport]生成。其他PR如dotnet/runtime#67635和dotnet/runtime#68173增加了新的編排型別,包括常見的編排邏輯,並且可以從[LibraryImport(...)]中參照,用於客製化編排的執行方式(生成器是基於模式的,並允許通過提供實現正確形狀的型別來客製化編排,這些型別支援最常見的編排需要)。真正有用的是,dotnet/runtime#71989增加了對marshaling {ReadOnly}Span
還有一類與互操作相關的變化,我認為值得一談的是與SafeHandle的清理有關。作為一個提醒,SafeHandle的存在是為了緩解圍繞管理本地控制程式碼和檔案描述符的各種問題。一個本地控制程式碼或檔案描述符只是一個記憶體地址或數位,它指的是一些擁有的資源,當它用完後必須被清理/關閉。一個SafeHandle的核心只是一個管理物件,它包裝了這樣一個值,並提供了一個Dispose方法和一個關閉它的終端子。這樣,如果你為了關閉資源而忽略了SafeHandle的處置,當SafeHandle被垃圾回收和最終執行它的終端子時,資源仍然會被清理掉。然後,SafeHandle還提供了一些圍繞該關閉的同步,試圖儘量減少資源在仍在使用時被關閉的可能性。它提供了DangerousAddRef和DangerousRelease方法,分別遞增和遞減一個參考計數,如果在參考計數高於0時呼叫Dispose,由Dispose觸發的實際釋放控制程式碼將被推遲到參考計數回到0。當你把一個SafeHandle傳入一個P/Invoke時,該P/Invoke的生成程式碼會處理呼叫DangerousAddRef和DangerousRelease(由於我已經頌揚過LibraryImport的神奇之處,你可以很容易地看到這一點,比如在前面的生成程式碼例子中)。我們的程式碼努力在SafeHandles之後確定地進行清理,但很容易意外地留下一些用於最終處理。
dotnet/runtime#71854給SafeHandle新增了一些只用於偵錯的跟蹤程式碼,使在dotnet/runtime工作的開發人員(或更具體地說,使用執行時的檢查構建的開發人員)更容易發現此類問題。當SafeHandle被構建時,它捕獲了當前的堆疊跟蹤,如果SafeHandle被最終確定,它將堆疊跟蹤轉儲到控制檯,使我們很容易看到最終被最終確定的SafeHandle是在哪裡建立的,以便跟蹤它們並確保它們被處理掉。從這個涉及150多個檔案和近1000行程式碼的PR中可能可以看出,有不少地方從清理中受益。現在,公平地說,其中許多是在特殊的程式碼路徑上。例如,考慮一個假想的P/Invoke,比如。
[LibraryImport("SomeLibrary", SetLastError = true)]
internal static partial SafeFileHandle CreateFile();
和使用它的程式碼,如。
SafeFileHandle handle = Interop.CreateFile();
if (handle.IsInvalid)
{
throw new UhOhException(Marshal.GetLastPInvokeError());
}
return handle;
看上去很直接。除了這段程式碼實際上會在失敗路徑上留下一個SafeHandle用於最終處理。SafeHandle裡面有一個無效的控制程式碼並不重要,它仍然是一個可最終確定的物件。為了處理這個問題,這段程式碼會被更穩健地寫成。
SafeFileHandle handle = Interop.CreateFile();
if (handle.IsInvalid)
{
int lastError = Marshal.GetLastPInvokeError();
handle.Dispose(); // or handle.SetHandleAsInvalid()
throw new UhOhException(lastError);
}
return handle;
這樣一來,即使在失敗的情況下,這個SafeHandle也不會產生最終的壓力。還要注意的是,作為增加Dispose呼叫的一部分,我也把Marshal.GetLastPInvokeError()移了上去。這是因為在SafeHandle上呼叫Dispose可能最終會呼叫SafeHandle的ReleaseHandle方法,而SafeHandle派生型別的開發者將過載該方法以關閉資源,這通常涉及到另一個P/Invoke。如果這個P/Invoke有SetLastError=true,它就可以覆蓋我們要丟擲的錯誤程式碼。因此,一旦我們知道互操作呼叫失敗,我們就立即存取並儲存最後的錯誤,然後清理,最後才丟擲。綜上所述,在那個PR中,有許多地方的SafeHandles甚至在成功路徑上也被留作最終確定。dotnet/runtime#71991、dotnet/runtime#71854、dotnet/runtime#72116、dotnet/runtime#72189、dotnet/runtime#72222、dotnet/runtime#72203和dotnet/runtime#72279都發現並修復了許多SafeHandles被留作最終處理的情況(這要感謝前面提到的PR中的診斷措施)。
dotnet/runtime#70000來自@huoyaoyuan,將幾個與委託相關的 "FCalls "從原生程式碼中實現改寫為託管,從而減少了呼叫這些操作時的開銷,這些操作通常涉及到Marshal.GetDelegateForFunctionPointer的場景。 dotnet/runtime#68694也將一些瑣碎的功能從本地轉移到託管,作為放鬆對使用釘子手柄 (pinning handles) 的引數驗證的一部分。這反過來又極大地減少了使用GCHandle.Alloc來處理這種釘子手柄的開銷。
private byte[] _buffer = new byte[1024];
[Benchmark]
public void PinUnpin()
{
GCHandle.Alloc(_buffer, GCHandleType.Pinned).Free();
}
| 方法 | 執行時 | 平均值 | 比率 | 程式碼大小 |
|---|---|---|---|---|
| PinUnpin | .NET 6.0 | 37.11 ns | 1.00 | 353 B |
| PinUnpin | .NET 7.0 | 32.17 ns | 0.87 | 232 B |
執行緒 (Threading)
執行緒是影響每個應用程式的跨領域問題之一,因此,執行緒領域的變化會產生廣泛的影響。在這個版本中,ThreadPool本身有兩個非常大的變化;dotnet/runtime#64834將 "IO池 "轉為使用一個完全受管的實現(而之前的IO池仍然在原生程式碼中,儘管在以前的版本中工作者池已經完全轉為受管),dotnet/runtime#71864同樣將定時器的實現從基於原生程式碼轉為完全受管程式碼。這兩個變化會影響效能,前者在較大的硬體上被證明了,但在大多數情況下,這並不是他們的主要目標。相反,其他的PR一直專注於提高吞吐量。
其中一個問題是dotnet/runtime#69386。執行緒池有一個 "全域性佇列",任何執行緒都可以將工作排入其中,然後池中的每個執行緒都有自己的 "本地佇列"(任何執行緒都可以從該佇列中退出,但只有所屬執行緒可以排入)。當一個工作者需要處理另一個工作時,它首先檢查自己的本地佇列,然後檢查全域性佇列,然後只有當它在這兩個地方都找不到工作時,它才去檢查所有其他執行緒的本地佇列,看看它是否能幫助減輕它們的負擔。隨著機器規模的擴大,擁有越來越多的核心和越來越多的執行緒,這些共用佇列,特別是全域性佇列上的爭奪就越來越多。這個PR通過在機器達到一定的閾值(現在是32個處理器)時引入額外的全域性佇列來解決這些大型電腦器的問題。這有助於在多個佇列中劃分存取,從而減少爭論。
另一個是dotnet/runtime#57885。為了協調執行緒,當工作專案被排隊和取消排隊時,池子向其執行緒發出請求,讓它們知道有工作可以做。然而,這往往會導致超額認購,更多的執行緒會爭先恐後地試圖獲得工作專案,特別是在系統沒有滿負荷的時候。這反過來又會表現為吞吐量的下降。這一變化徹底改變了執行緒的請求方式,即每次只請求一個額外的執行緒,在該執行緒取消其第一個工作專案後,如果有剩餘的工作,它可以發出一個額外執行緒的請求,然後該執行緒可以發出一個額外的請求,以此類推。下面是我們的效能測試套件中的一個效能測試(我把它簡化了,從測試中刪除了一堆設定選項,但它仍然是準確的設定之一)。乍一看,你可能會想,"嘿,這是一個關於ArrayPool的效能測試,為什麼它會出現線上程討論中?" 而且,你會是對的,這是一個專注於ArrayPool的效能測試。然而,正如前面提到的,執行緒影響著一切,在這種情況下,中間的那個await Task.Yield()導致這個方法的剩餘部分被排到ThreadPool中執行。由於測試的結構,做 "真正的工作",與執行緒池中的執行緒競爭CPU週期,以獲得他們的下一個任務,它顯示了移動到.NET 7時的可衡量的改進。
private readonly byte[][] _nestedArrays = new byte[8][];
private const int Iterations = 100_000;
private static byte IterateAll(byte[] arr)
{
byte ret = default;
foreach (byte item in arr) ret = item;
return ret;
}
[Benchmark(OperationsPerInvoke = Iterations)]
public async Task MultipleSerial()
{
for (int i = 0; i < Iterations; i++)
{
for (int j = 0; j < _nestedArrays.Length; j++)
{
_nestedArrays[j] = ArrayPool<byte>.Shared.Rent(4096);
_nestedArrays[j].AsSpan().Clear();
}
await Task.Yield();
for (int j = _nestedArrays.Length - 1; j >= 0; j--)
{
IterateAll(_nestedArrays[j]);
ArrayPool<byte>.Shared.Return(_nestedArrays[j]);
}
}
}
| 方法 | 執行時 | 平均值 | 比率 |
|---|---|---|---|
| MultipleSerial | .NET 6.0 | 14.340 us | 1.00 |
| MultipleSerial | .NET 7.0 | 9.262 us | 0.65 |
在ThreadPool之外,也有一些改進。一個顯著的變化是對AsyncLocal
private AsyncLocal<int> asyncLocal1 = new AsyncLocal<int>();
private AsyncLocal<int> asyncLocal2 = new AsyncLocal<int>();
private AsyncLocal<int> asyncLocal3 = new AsyncLocal<int>();
private AsyncLocal<int> asyncLocal4 = new AsyncLocal<int>();
[Benchmark(OperationsPerInvoke = 4000)]
public void Update()
{
for (int i = 0; i < 1000; i++)
{
asyncLocal1.Value++;
asyncLocal2.Value++;
asyncLocal3.Value++;
asyncLocal4.Value++;
}
}
| 方法 | 執行時 | 平均值 | 比率 | 程式碼大小 | 已分配 | 分配比率 |
|---|---|---|---|---|---|---|
| Update | .NET 6.0 | 61.96 ns | 1.00 | 1,272 B | 176 B | 1.00 |
| Update | .NET 7.0 | 61.92 ns | 1.00 | 1,832 B | 144 B | 0.82 |
另一個有價值的修復是針對dotnet/runtime#70165中的鎖定。這個特別的改進有點難以用benchmarkdotnet來演示,所以只要試著執行這個程式,先在.NET 6上,然後在.NET 7上。
using System.Diagnostics;
var rwl = new ReaderWriterLockSlim();
var tasks = new Task[100];
int count = 0;
DateTime end = DateTime.UtcNow + TimeSpan.FromSeconds(10);
while (DateTime.UtcNow < end)
{
for (int i = 0; i < 100; ++i)
{
tasks[i] = Task.Run(() =>
{
var sw = Stopwatch.StartNew();
rwl.EnterReadLock();
rwl.ExitReadLock();
sw.Stop();
if (sw.ElapsedMilliseconds >= 10)
{
Console.WriteLine(Interlocked.Increment(ref count));
}
});
}
Task.WaitAll(tasks);
}
這只是簡單地啟動了100個任務,每個任務都進入和退出一個讀寫鎖,等待所有的任務,然後重新做這個過程,持續10秒。它還會計算進入和退出鎖所需的時間,如果它不得不等待至少15ms,就會寫一個警告。當我在.NET 6上執行這個程式時,我得到了大約100次進入/退出鎖的時間>=10ms的情況。而在.NET 7上,我得到的是0次出現。為什麼會有這種差別?ReaderWriterLockSlim的實現有它自己的自旋迴圈實現,該自旋迴圈試圖將各種事情混在一起做,從呼叫Thread.SpinWait到Thread.Sleep(0)到Thread.Sleep(1)。問題出在Thread.Sleep(1)上。這是說 "讓這個執行緒休眠1毫秒";然而,作業系統對這樣的時間安排有最終的決定權,在Windows上,預設情況下,這個休眠會接近15毫秒(在Linux上會低一點,但仍然相當高)。因此,每次在鎖上出現足夠的爭奪,迫使它呼叫Thread.Sleep(1)時,我們就會產生至少15毫秒的延遲,甚至更多。前面提到的PR通過消除對Thread.Sleep(1)的使用來解決這個問題。
最後要指出的是與執行緒有關的變化:dotnet/runtime#68639。這個是Windows特有的。Windows有處理器組的概念,每個處理器組最多可以有64個核心,預設情況下,當一個程序執行時,它被分配到一個特定的處理器組,只能使用該組中的核心。在.NET 7中,執行時翻轉其預設值,因此預設情況下,如果可能的話,它會嘗試使用所有處理器組。
原文連結
Performance Improvements in .NET 7

本作品採用知識共用署名-非商業性使用-相同方式共用 4.0 國際許可協定進行許可。
歡迎轉載、使用、重新發布,但務必保留文章署名 鄭子銘 (包含連結: http://www.cnblogs.com/MingsonZheng/ ),不得用於商業目的,基於本文修改後的作品務必以相同的許可釋出。
如有任何疑問,請與我聯絡 ([email protected])