ChatGPT強勢爆紅,背後的技術原理是?一文輕鬆搞懂!
作者:小牛呼嚕嚕 | https://xiaoniuhululu.com
計算機內功、原始碼解析、科技故事、專案實戰、面試八股等更多硬核文章,首發於公眾號「小牛呼嚕嚕」
大家好,我是呼嚕嚕,最近一段時間被ChatGPT瘋狂刷屏,自從2022年11月釋出上線後,不僅 5 天時間便突破百萬使用者,月活使用者突破 1 億更是僅用時 2 個月,成為史上增速最快的消費級應用,遠超如今其他知名應用,tiktok,facebook,google等等,可謂來勢洶洶。
什麼是ChatGPT?
ChatGPT是由OpenAI團隊開發和訓練一個人工智慧聊天機器人程式,換句話說就是專注於對話生成的大型語言模型。在2022年11月30 日OpenAI 的執行長Sam Altman在推特上寫道:「今天我們推出了 ChatGPT,嘗試在這裡與它交談」,然後是一個連結,任何人都可以註冊一個帳戶,開始免費與 OpenAI 的新聊天機器人交談。
它有著通用人工智慧的名義,我們人類可以和他談日常瑣事,還可以利用它來寫年度總結,和程式設計師一樣寫程式碼,修改 bug,書寫情詩,做表格,發論文,寫作業,做翻譯,甚至可以探討哲學問題擎等……。人類歷史上還沒有出現過這麼通用,"全知全能"的AI。
在ChatGPT釋出後的五天內,就有超過100萬的玩家,而Facebook花了 10 個月才達到這種程度。《紐約時報》稱其為「有史以來向公眾釋出的最好的人工智慧聊天機器人,比爾蓋茲說 ChatGPT 出現的意義「不亞於網際網路的誕生」,微軟 CEO 納德拉(Satya Nadella)說它堪比工業革命,也有人擔憂其會取代大多數普通人的工作崗位
OpenAI
這我們就不得不提,ChatGPT的研發者OpenAI,OpenAI公司於2015年12月在美國舊金山成立,那時谷歌剛收購一家公司DeepMind,沒錯就是那個研製出接連擊敗世界圍棋冠軍李世石、柯潔的AlphaGo的公司

谷歌本世紀初就已經開始佈局ai領域,擁有多年的技術積累,再收購DeepMind,壟斷人工智慧領域的野心路人皆知。為了阻止谷歌在人工智慧領域的壟斷,Altman帶頭提議組建一個與谷歌競爭的實驗室,將作為一個非營利組織運營,通過與其他機構和研究者的「自由合作」,向公眾開放專利和研究成果,促進先進人工智慧的好處"民主化"。OpenAI的創立者不僅僅有Altman,還有Elon Musk、Greg Brockman、Ilya Sutskever、John Schulman等知名企業家財力支援,還擁有
各種技術大牛加入,如 Ilya Sutskever, Carlos Virella, James Greene, Wojciech Zaremb等。OpenAI團隊麻雀雖小五臟俱全,但其能帶來大量技術創新。

背後的原理和發展歷程
如今ChatGPT取得令人驚豔的成就,但一切並不是一蹴而就的。ChatGPT是由OpenAI團隊在2019年6月首次釋出的,下圖就是ChatGPT訓練的主要3個階段:
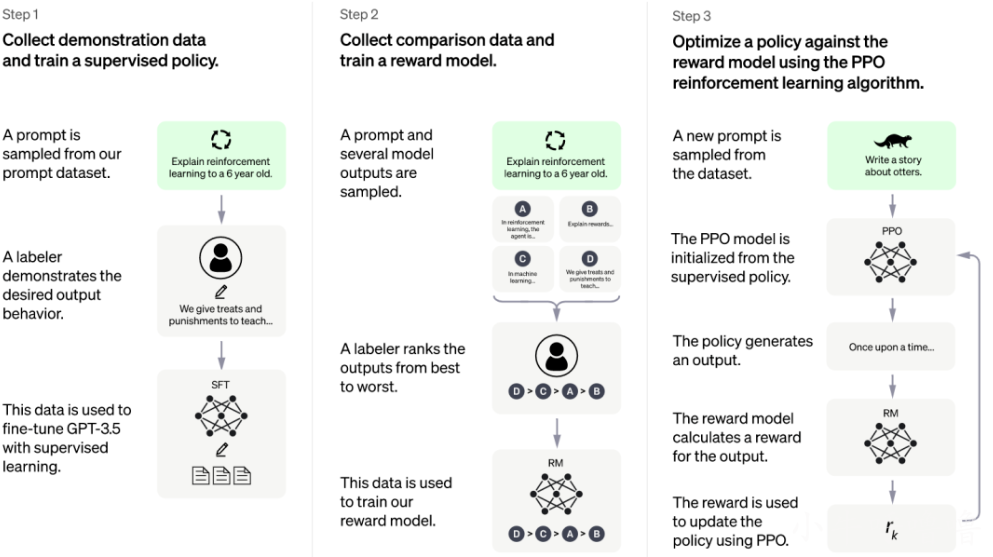
上圖來自ChatGPT官網
第一步,首先收集演示資料並訓練監督策略模型(SFT)
ChatGPT 模型本身是無法理解人類不同型別指令中蘊含的不同意圖,這時候需要一個"老師"去教它,這個叫"訓練"。
所以需要由人類事先標註好的高質量資料集進行訓練。ChatGPT使用的資料集裡面資料是海量的,所以我們不能忽視在背後默默標註資料的第三方外包人員的辛苦付出。
為了訓練ChatGPT,ChatGPT被美國《時代週刊》爆料初僱傭肯亞外包勞工進行資料標註,他們時薪不到2美元且內容對他們造成心理傷害。
接著我們就需要把這些整理好的資料來餵給ChatGPT進行半監督學習,在ChatGPT出現之前,NLP 模型(自然語言處理)主要是基於針對特定任務的大量標註資料進行訓練,也就是「有答案」的資料集,這也叫"監督式學習"。自然語言處理是一個非常嚴密的推理過程,不僅要識別每個詞,還要處理詞語間的序列,因此誕生了迴圈神經網路(RNN)模型。但RNN只考慮單詞或者上下文資訊,常常導致全文句意前後不連貫,或者理解複雜句子時出錯。這也就導致一些缺點:需要大量的高質量標註資料,高質量的標註資料往往很難獲得,而且在實際標註中,有些標籤並不存在明確的邊界;模型又僅限於所接受的訓練,泛化能力不足。
所以ChatGPT採用"半監督式學習",使用海量的無標註資料訓練一個預訓練模型,然後再根據特定任務進行微調,比如自然語言推理、問答和常識推理、語意相似度、文字分類。將無監督學習的結果用於左右有監督模型的預訓練目標,也叫生成式預訓練(Generative Pre-training),沒錯這就是ChatGPT的GPT3個字的來源!

和谷歌一直換ai的策略不同的是,ChatGPT就很執著,ChatGPT-1剛出來的時候,被業內群嘲,但openai團隊,並不氣餒,不斷擴大訓練資料規模,屬實是大力出奇跡的典範:
- 2019年6月,ChatGPT-1,這是第一個基於自然語言處理的對話生成模型,擁有1.17億引數;
- 2020年6月:釋出了ChatGPT-2,該模型擁有1.17億個引數的基礎上進一步增加到了15億個引數,成為當時最先進的自然語言處理模型之一。
- 2020年11月:OpenAI推出了GPT-3,這是一個擁有1750億個引數的巨型語言模型,可以生成高質量的自然語言文字。它的出現引起了廣泛的關注和討論,並被認為是人工智慧領域的一項重大成就。
- 2022年3月,OpenAI新推出13億引數的InstructGPT。從人工評測效果上看,相比1750億引數的GPT3,人們更喜歡13億引數的InstructGPT生成的回覆。可見,並不是訓練資料規模越大越好。更低的引數,也就意味著更低的成本
- 2022年11月,推測約20億引數的ChatGPT-3.5被推出,具體資料暫未公開,轟動全球

到這裡,就訓練成了SFT模型(Supervised Fine-Tuning Model),此時ChatGPT已經能初步能夠理解人類的真實意圖,算是"學有小成"了
第二步:訓練獎勵模型(RM)
由於現有的回答是多種多樣的,界限是模糊的,無法直接通過標註直接劃分。那麼如何讓AI的回答符合人類的意圖?
根據論文Scalable agent alignment via reward modeling: a research direction的理論, 這個時候我們需要給ChatGPT的隨機抽取一批新問題,每個問題都設定一個獎勵目標,讓ChatGPT生成多個回答,接著人類根據回答的質量,打分,進而依據分數排名,讓高質量回答的分數高於低質量回答,以符合人類意圖的方式解決複雜的現實世界問題。
到這裡,就形成了獎勵模型(Reward Model),再次通過大量的訓練,這個模型會讓ChatGPT越來越能懂人類真是意圖,不斷打分,ChatGPT就會不斷地進化。

第三步:採用近端策略優化PPO強化學習來優化策略
到了這一階段,由於人類的精力是有限的,哪怕是僱傭更多的人,但對於網際網路網上海量的資料,還是滄海一粟。這個時候,就需要讓 ChatGPT 開啟"自學"模式,不斷學習,自我進化。
給ChatGPT更多全新的資料,通過PPO強化學習演演算法生成回答,並利用上一階段訓練好的獎勵模型,來靠獎勵打分排序來調整模型引數。然後不斷重複第二和第三階段的過程,也就是自己給自己出題,再自己對答案,然後微調模型引數,進行海量次數的迭代,這樣直至訓練出最終符合預期的模型,實現"最終進化"
在 ChatGPT 基礎的 InstructGPT 的論文中,Actor 和監督微調模型都使用了 1750 億引數的 GPT-3 系列模型,Critic 和獎勵模型則使用了 60 億引數的 GPT-3 系列模型。
更詳細的移步論文:Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback

帶來的爭議和挑戰
然後新事物的誕生並不僅僅只有美好的一面,ChatGPT也帶來許多潛在的問題。2023年1月,國際機器學習大會禁止在提交的論文中使用ChatGPT或其他大型語言模型來生成任何文字。大量學生用ChatGPT來寫作業,導致紐約市公立學校禁止師生在校園網路及裝置上使用ChatGPT。
資料集的獲取是否符合版權問題一直是ChatGPT繞不開的問題,無法保證個人資訊保安,可能導致資訊洩露。由於ChatGPT目前是基於2021年及其之前所擁有的資料集進行回答的整合,問它2022,2023或者最近國際上發生的事,它是不知曉的。這就不可避免地保證資料集接觸到負面的,暴力的,充滿惡意的資訊。如何最大限度地並長久地隔離這些負面資訊?如果是人工去隔離,是非常困難且痛苦的,類似於內容稽核員,鑑黃師...
除此之外,使用者對ChatGPT的惡意利用也會帶來很多資料安全問題。比如利用自然語言編寫的能力,編寫惡意軟體,從而逃避防病毒軟體的檢測;利用ChatGPT的編寫功能,生成釣魚電子郵件;利用對話功能,冒充真實的人或者組織騙取他人資訊等。
現在尷尬的是當我們知曉答案的正確與否時,我們可以向ChatGPT求教,但當諮詢我們不熟悉的領域,ChatGPT目前無法保證它的答案是正確的,需要再和專業的人確認。因為其技術上將海量的資料結合表達能力很強的Transformer模型結合,從而對自然語言進行了一個非常深度的建模。它本質上只是通過概率最大化不斷生成符合預期的回答,而不是通過邏輯推理來生成正確的回答。
2022年12月,程式設計師非常熟悉的Stack Overflow禁止使用者釋出使用ChatGPT生成的答案,理由是ChatGPT的答案雖看似可用,實際上卻有很高的錯誤率,一本正經地胡說八道。
尾語
從 IBM 的「深藍」,到 Google 的 AlphaGo,再到 OpenAI 的 ChatGPT,AI的突破都是循序漸進、從小到大地一步步實現,只有腳踏實地深耕基礎領域,才能有質的飛越。盲目地造新概念,一窩蜂去摘果實,割韭菜會制約整個行業的發展
隨著時間和技術的發展,AI的崛起,是大勢所趨。大量機械的、重複的,沒有思考價值的工作,會逐漸消失,但也會將給世界帶來新的產業革命。
ChatGPT可以用更接近人類的思考方式參與使用者的查詢過程,可以根據上下文和語境,提供恰當的回答,並模擬多種人類情緒和語氣,甚至可以主動承認自身錯誤,吸取教訓並優化答案。如果你長時間和它交流,你會有時感覺它在"討好你"。
ChatGPT的出現給所有人都敲想了警鐘,時代的輪盤已經悄悄轉動,要想不被拋棄,我們人類只有不斷地學習,思考,進步

參考論文&資料:
- Illustrating Reinforcement Learning from Human Feedback (RLHF) Illustrating Reinforcement Learning from Human Feedback (RLHF)
- Optimizing Language Models for Dialogue ChatGPT: Optimizing Language Models for Dialogue
- Scalable agent alignment via reward modeling: a research direction
- Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
- wikipedia.chatgpt
- https://ishare.ifeng.com/c/s/v002SAoIcZHgoIRNibxJaZUF5GX--9krUn32boGRnKTCEXk4__
本篇文章到這裡就結束啦,如果我的文章對你有所幫助,還請幫忙一鍵三連:點贊、關注、收藏,你的支援會激勵我輸出更高質量的文章,感謝!
計算機內功、原始碼解析、科技故事、專案實戰、面試八股等更多硬核文章,首發於公眾號「小牛呼嚕嚕」,我們下期再見。
