Java 文字檢索神器 "正規表示式"
Java 文字檢索神器 "正規表示式"

每博一文案
在我們短促而又漫長的一生中,我們在苦苦地尋找人生的幸福,可幸福往往又與我們失之交臂,
當我們為此而耗盡寶貴的。青春年華,皺紋也悄悄地爬上了眼角的時候,我們或許才能悄悄懂得生活實際上意味
著什麼。
—————— 《平凡的世界》
葉賽寧的詩,不惋惜,不呼喚,我也不啼哭。金黃的落葉堆滿我心間。我已經再不是青春少年。
—————— 《平凡的世界》
生活中有那麼一種人,你蔑視甚至汙辱他,他不僅視為正常,還對你挺佩服;你要是在人格上對他平等相待,
他反而倒小看你!這種人的情況,在偉魯迅的不朽著作中詳盡詮釋,這裡就不再贅述。
—————— 《平凡的世界》
一個平平常常的日子,細濛濛的雨絲夾著一星半點的雪花,正紛紛淋淋地向大地飄灑著。時令已快到驚蟄,
雪當然再也不會存留,往往還沒等落地,就已經消失得無影無蹤了。黃土高原嚴寒而漫長的冬天看來
就要過去,但那真正溫暖的春天還遠遠地沒有到來。
—————— 《路遙》
@
1. 正規表示式的概述
我相信,作為一名程式設計師或者準程式設計師,你肯定是知道正規表示式的。作為計算機領域最偉大的發明之一,正規表示式簡單、強大,它可以極大地提高我們工作中的文書處理效率。現在,各大作業系統、程式語言、文字編輯器都已經支援正規表示式,甚至我還和極客時間的編輯開玩笑說,他們也應該好好學學正則這門手藝。
正則,就是正規表示式,英文是 Regular Expression,簡稱 RE。 顧名思義,正則其實就是一種 描述文字內容組成規律的表示方式。
在程式語言中,正則常常用來簡化文書處理的邏輯。在 Linux 命令中,它也可以幫助我們輕鬆地查詢或編輯檔案的內容,甚至實現整個資料夾中所有檔案的內容替換,比如 grep、egrep、sed、awk、vim 等。另外,在各種文字編輯器中,比如 Atom,Sublime Text 或 VS Code 等,在查詢或替換的時候也會使用到它。總之,正則是無處不在的,已經滲透到了日常工作的方方面面。
簡單來說,正則是一個非常強大的文書處理工具,它的應用極其廣泛。我們可以利用它來校驗資料的有效性,比如使用者輸入的手機號是不是符合規則;也可以從文字中提取想要的內容,比如從網頁中抽取資料;還可以用來做文字內容替換,從而得到我們想要的內容。
通過它的功能和分佈的廣泛你也能看出來,正則是一個非常值得花時間和精力好好學習的基本技能。之前你花幾十分鐘才能搞定的事情,可能用正則很快就搞定了;之前不能解決的問題,你係統地學習正則後,可能發現也能輕鬆解決了。
1.1 正規表示式的威力
初始正規表示式,這裡我們先來體會一下正規表示式的威力。
例如01: 下面這段文字是,我們通過爬蟲獲取到的,下面我們通過正規表示式獲取到其中文字的所有英文單詞
Java平臺由Java虛擬機器器(Java Virtual Machine)和Java 應用程式設計介面(Application Programming Interface、簡稱API)構成。Java 應用程式設計介面為Java應用提供了一個獨立於作業系統的標準介面,可分為基本部分和擴充套件部分。在硬體或作業系統平臺上安裝一個Java平臺之後,Java應用程式就可執行。Java平臺已經嵌入了幾乎所有的作業系統。這樣Java程式可以只編譯一次,就可以在各種系統中執行。Java應用程式設計介面已經從1.1x版發展到1.2版。常用的Java平臺基於Java1.8最近版本為Java19。
package blogs.blog12;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest01 {
public static void main(String[] args) {
// 假定,編寫了爬蟲,從百度頁面得到如下文字:
String content = "Java平臺由Java虛擬機器器(Java Virtual Machine)和Java 應用程式設計介面(Application Programming Interface、簡稱API)構成。Java 應用程式設計介面為Java應用提供了一個獨立於作業系統的標準介面," +
"可分為基本部分和擴充套件部分。在硬體或作業系統平臺上安裝一個Java平臺之後," +
"Java應用程式就可執行。Java平臺已經嵌入了幾乎所有的作業系統。" +
"這樣Java程式可以只編譯一次,就可以在各種系統中執行。" +
"Java應用程式設計介面已經從1.1x版發展到1.2版。常用的Java平臺基於Java1.8," +
"最近版本為Java19。";
// 提取文章中所有的英文單詞:
// 傳統方法: 使用遍歷方式: 程式碼量大,效率不高:
// 正規表示式:
// 1. 先建立一個Pattern 物件,模式物件,可以理解成就是一個正規表示式物件
Pattern pattern = Pattern.compile("[a-zA-Z]+");
// 2. 建立一個匹配器物件
// 理解:就是 matcher 匹配器,按照所編寫的 pattern(模式/樣式) ,到 content 文字中去匹配
// 找到就返回 true,否則就返回false
Matcher matcher = pattern.matcher(content);
// 3. 開始迴圈匹配
while(matcher.find()) { // 找到返回 true,否則返回false
// 匹配內容,文字,放到 matcher.group() 當中
String group = matcher.group(0);
System.out.println(group);
}
}
}
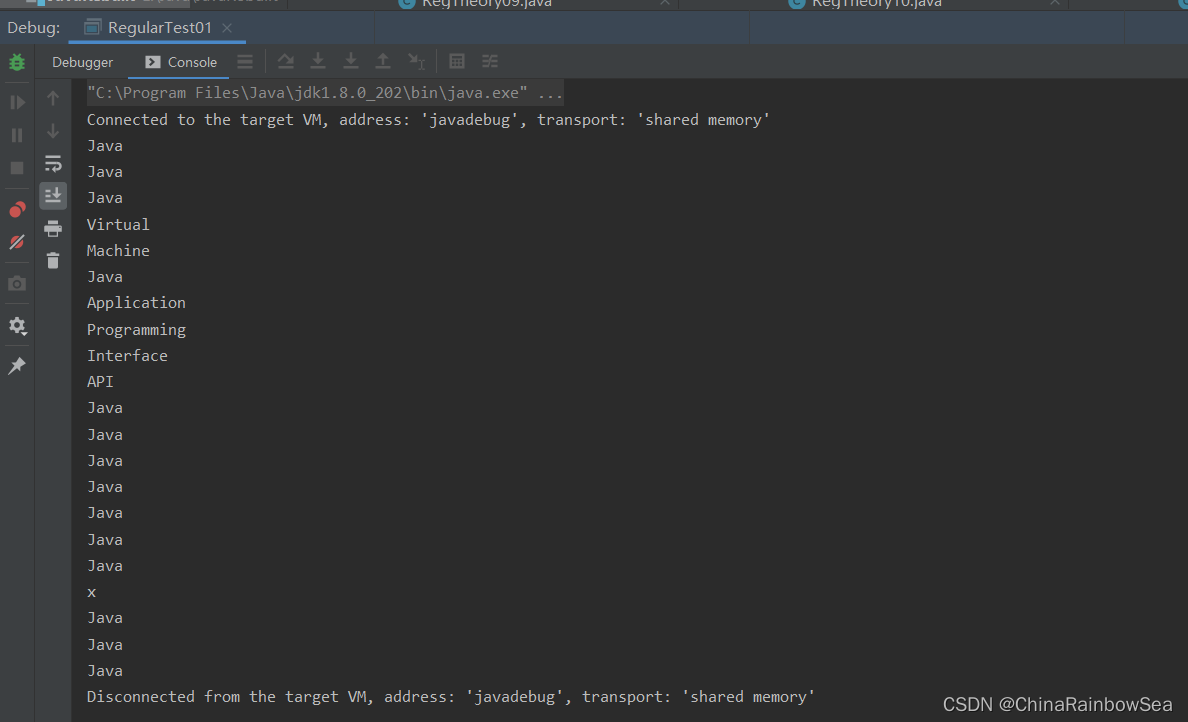
例如02: 提取到上述文字內容中的所有 數位 。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest01 {
public static void main(String[] args) {
// 假定,編寫了爬蟲,從百度頁面得到如下文字:
String content = "Java平臺由Java虛擬機器器(Java Virtual Machine)和Java 應用程式設計介面(Application Programming Interface、簡稱API)構成。Java 應用程式設計介面為Java應用提供了一個獨立於作業系統的標準介面," +
"可分為基本部分和擴充套件部分。在硬體或作業系統平臺上安裝一個Java平臺之後," +
"Java應用程式就可執行。Java平臺已經嵌入了幾乎所有的作業系統。" +
"這樣Java程式可以只編譯一次,就可以在各種系統中執行。" +
"Java應用程式設計介面已經從1.1x版發展到1.2版。常用的Java平臺基於Java1.8," +
"最近版本為Java19。";
// 1.建立一個正規表示式物件
Pattern pattern = Pattern.compile("[\\d]+");
// 2.建立一個匹配器,用於匹配符合正規表示式的字串
Matcher matcher = pattern.matcher(content);
// 迴圈遍歷獲取符合條件的字串
while(matcher.find()) { // 一點一點的同文字中遍歷匹配是否符合該正規表示式,符合返回true,否則返回false
String group = matcher.group(0);
System.out.println(group);
}
}
}
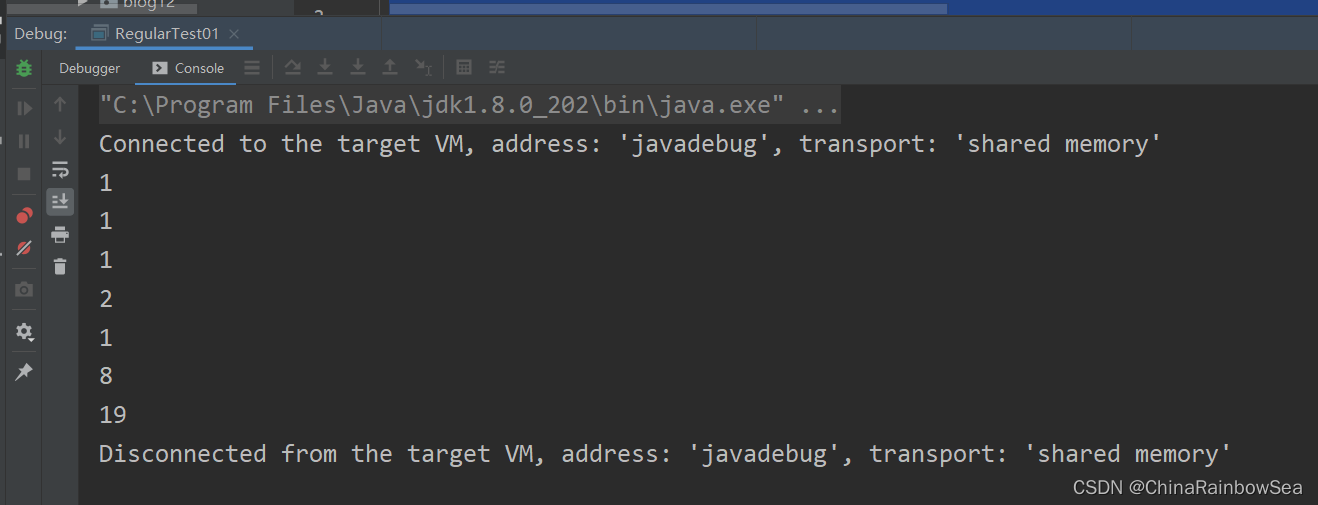
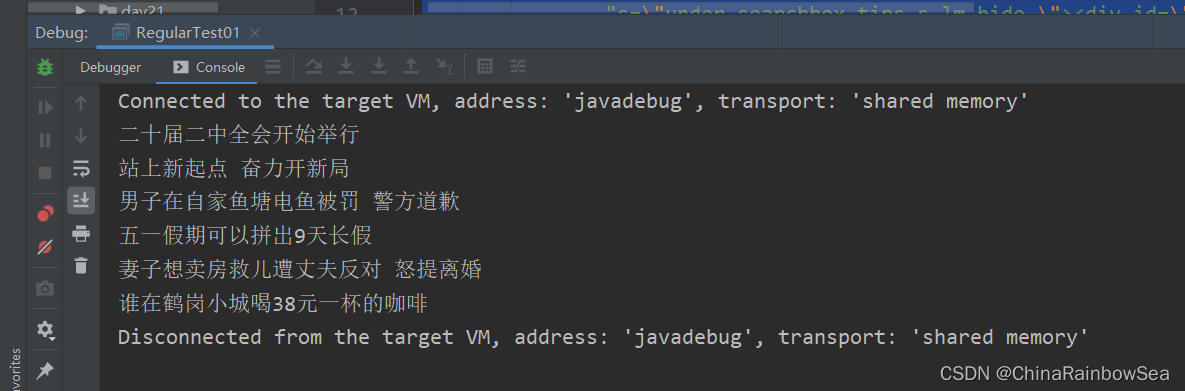
例如03 : 如下是一段從 www.baidu.com 網頁中擷取的一段原始碼:通過正規表示式獲取到其中的百度熱搜資訊 。
name="oq" value=""><input type="hidden" name="rsv_pq" value="0xb79379dd001c441c"><input type="hidden" name="rsv_t" value="6ab2PWJNZs4OfZhgLwgMJI9gVsivBq7kMA9T8vJRItmCHeBsBD0QsnashhrZ"><input type="hidden" name="rqlang" value="en"></form><div id="m" class="under-searchbox-tips s_lm_hide "><div id="lm-new"></div></div><div id="s-hotsearch-wrapper" class="s-isindex-wrap s-hotsearch-wrapper hide "><div class="s-hotsearch-title"><a class="hot-title" href="https://top.baidu.com/board?platform=pc&sa=pcindex_entry" target="_blank"><div class="title-text c-font-medium c-color-t" aria-label="百度熱搜"><i class="c-icon"></i><i class="c-icon arrow"></i></div></a><a id="hotsearch-refresh-btn" class="hot-refresh c-font-normal c-color-gray2"><i class="c-icon refresh-icon"></i><span class="hot-refresh-text">換一換</span></a></div><ul class="s-hotsearch-content" id="hotsearch-content-wrapper"><li class="hotsearch-item odd" data-index="0"><a class="title-content c-link c-font-medium c-line-clamp1" href="https://www.baidu.com/s?wd=%E4%BA%8C%E5%8D%81%E5%B1%8A%E4%BA%8C%E4%B8%AD%E5%85%A8%E4%BC%9A%E5%BC%80%E5%A7%8B%E4%B8%BE%E8%A1%8C&sa=fyb_n_homepage&rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2&hisfilter=1" target="_blank" ><div class="title-content-noindex" style="display: none;"></div><i class="c-icon title-content-top-icon c-color-red c-gap-right-small" style="display: ;"></i><span class="title-content-index c-index-single c-index-single-hot0" style="display: none;">0</span><span class="title-content-title">二十屆二中全會開始舉行</span></a><span class="title-content-mark ie-vertical c-text c-gap-left-small "></span></li><li class="hotsearch-item even" data-index="3"><a class="title-content c-link c-font-medium c-line-clamp1" href="https://www.baidu.com/s?wd=%E7%AB%99%E4%B8%8A%E6%96%B0%E8%B5%B7%E7%82%B9+%E5%A5%8B%E5%8A%9B%E5%BC%80%E6%96%B0%E5%B1%80&sa=fyb_n_homepage&rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2&hisfilter=1" target="_blank" ><div class="title-content-noindex" style="display: none;"></div><i class="c-icon title-content-top-icon c-color-red c-gap-right-small" style="display: none;"></i><span class="title-content-index c-index-single c-index-single-hot3" style="display: ;">3</span><span class="title-content-title">站上新起點 奮力開新局</span></a><span class="title-content-mark ie-vertical c-text c-gap-left-small "></span></li><li class="hotsearch-item odd" data-index="1"><a class="title-content tag-width c-link c-font-medium c-line-clamp1" href="https://www.baidu.com/s?wd=%E7%94%B7%E5%AD%90%E5%9C%A8%E8%87%AA%E5%AE%B6%E9%B1%BC%E5%A1%98%E7%94%B5%E9%B1%BC%E8%A2%AB%E7%BD%9A+%E8%AD%A6%E6%96%B9%E9%81%93%E6%AD%89&sa=fyb_n_homepage&rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2&hisfilter=1" target="_blank" ><div class="title-content-noindex" style="display: none;"></div><i class="c-icon title-content-top-icon c-color-red c-gap-right-small" style="display: none;"></i><span class="title-content-index c-index-single c-index-single-hot1" style="display: ;">1</span><span class="title-content-title">男子在自家魚塘電魚被罰 警方道歉</span></a><span class="title-content-mark ie-vertical c-text c-gap-left-small c-text-hot">熱</span></li><li class="hotsearch-item even" data-index="4"><a class="title-content c-link c-font-medium c-line-clamp1" href="https://www.baidu.com/s?wd=%E4%BA%94%E4%B8%80%E5%81%87%E6%9C%9F%E5%8F%AF%E4%BB%A5%E6%8B%BC%E5%87%BA9%E5%A4%A9%E9%95%BF%E5%81%87&sa=fyb_n_homepage&rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2&hisfilter=1" target="_blank" ><div class="title-content-noindex" style="display: none;"></div><i class="c-icon title-content-top-icon c-color-red c-gap-right-small" style="display: none;"></i><span class="title-content-index c-index-single c-index-single-hot4" style="display: ;">4</span><span class="title-content-title">五一假期可以拼出9天長假</span></a><span class="title-content-mark ie-vertical c-text c-gap-left-small "></span></li><li class="hotsearch-item odd" data-index="2"><a class="title-content tag-width c-link c-font-medium c-line-clamp1" href="https://www.baidu.com/s?wd=%E5%A6%BB%E5%AD%90%E6%83%B3%E5%8D%96%E6%88%BF%E6%95%91%E5%84%BF%E9%81%AD%E4%B8%88%E5%A4%AB%E5%8F%8D%E5%AF%B9+%E6%80%92%E6%8F%90%E7%A6%BB%E5%A9%9A&sa=fyb_n_homepage&rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2&hisfilter=1" target="_blank" ><div class="title-content-noindex" style="display: none;"></div><i class="c-icon title-content-top-icon c-color-red c-gap-right-small" style="display: none;"></i><span class="title-content-index c-index-single c-index-single-hot2" style="display: ;">2</span><span class="title-content-title">妻子想賣房救兒遭丈夫反對 怒提離婚</span></a><span class="title-content-mark ie-vertical c-text c-gap-left-small c-text-hot">熱</span></li><li class="hotsearch-item even" data-index="5"><a class="title-content c-link c-font-medium c-line-clamp1" href="https://www.baidu.com/s?wd=%E8%B0%81%E5%9C%A8%E9%B9%A4%E5%B2%97%E5%B0%8F%E5%9F%8E%E5%96%9D38%E5%85%83%E4%B8%80%E6%9D%AF%E7%9A%84%E5%92%96%E5%95%A1&sa=fyb_n_homepage&rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2&hisfilter=1" target="_blank" ><div class="title-content-noindex" style="display: none;"></div><i class="c-icon title-content-top-icon c-color-red c-gap-right-small" style="display: none;"></i><span class="title-content-index c-index-single c-index-single-hot5" style="display: ;">5</span><span class="title-content-title">誰在鶴崗小城喝38元一杯的咖啡</span></a><span class="title-content-mark ie-vertical c-text c-gap-left-small "></span></li></ul></div><textarea id="hotsearch_data" style="display:none;">
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest01 {
public static void main(String[] args) {
String content = "name=\"oq\" value=\"\"><input type=\"hidden\" name=\"rsv_pq\"" +
" value=\"0xb79379dd001c441c\"><input type=\"hidden\" name=\"rsv_t\" valu" +
"e=\"6ab2PWJNZs4OfZhgLwgMJI9gVsivBq7kMA9T8vJRItmCHeBsBD0QsnashhrZ\"><inp" +
"ut type=\"hidden\" name=\"rqlang\" value=\"en\"></form><div id=\"m\" clas" +
"s=\"under-searchbox-tips s_lm_hide \"><div id=\"lm-new\"></div></div><div" +
" id=\"s-hotsearch-wrapper\" class=\"s-isindex-wrap s-hotsearch-wrapper hid" +
"e \"><div class=\"s-hotsearch-title\"><a class=\"hot-title\" href=\"https:/" +
"/top.baidu.com/board?platform=pc&sa=pcindex_entry\" target=\"_blank\"><div " +
"class=\"title-text c-font-medium c-color-t\" aria-label=\"百度熱搜\"><i cla" +
"ss=\"c-icon\"></i><i class=\"c-icon arrow\"></i></div></a><" +
"a id=\"hotsearch-refresh-btn\" class=\"hot-refresh c-font-normal c-color-gra" +
"y2\"><i class=\"c-icon refresh-icon\"></i><span class=\"hot-refresh-" +
"text\">換一換</span></a></div><ul class=\"s-hotsearch-content\" id=\"hotsearc" +
"h-content-wrapper\"><li class=\"hotsearch-item odd\" data-index=\"0\"><a cla" +
"ss=\"title-content c-link c-font-medium c-line-clamp1\" href=\"https://www.b" +
"aidu.com/s?wd=%E4%BA%8C%E5%8D%81%E5%B1%8A%E4%BA%8C%E4%B8%AD%E5%85%A8%E4%BC%" +
"9A%E5%BC%80%E5%A7%8B%E4%B8%BE%E8%A1%8C&sa=fyb_n_homepage&rsv_dl=fy" +
"b_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&" +
";rsv_idx=2&hisfilter=1\" target=\"_blank\" ><div class=\"title-content" +
"-noindex\" style=\"display: none;\"></div><i class=\"c-icon title-content-t" +
"op-icon c-color-red c-gap-right-small\" style=\"display: ;\"></i><s" +
"pan class=\"title-content-index c-index-single c-index-single-hot0\" style=" +
"\"display: none;\">0</span><span class=\"title-content-title\">二十屆二中全會" +
"開始舉行</span></a><span class=\"title-content-mark ie-vertical c-text c-g" +
"ap-left-small \"></span></li><li class=\"hotsearch-item even\" data-index=\"" +
"3\"><a class=\"title-content c-link c-font-medium c-line-clamp1\" href=\"h" +
"ttps://www.baidu.com/s?wd=%E7%AB%99%E4%B8%8A%E6%96%B0%E8%B5%B7%E7%82%B9+%E5" +
"%A5%8B%E5%8A%9B%E5%BC%80%E6%96%B0%E5%B1%80&sa=fyb_n_homepage&rsv_dl" +
"=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&am" +
"p;rsv_idx=2&hisfilter=1\" target=\"_blank\" ><div class=\"title-content" +
"-noindex\" style=\"display: none;\"></div><i class=\"c-icon title-content-t" +
"op-icon c-color-red c-gap-right-small\" style=\"display: none;\"></" +
"i><span class=\"title-content-index c-index-single c-index-single-hot3\" st" +
"yle=\"display: ;\">3</span><span class=\"title-content-title\">站上新起點 奮" +
"力開新局</span></a><span class=\"title-content-mark ie-vertical c-text c-gap" +
"-left-small \"></span></li><li class=\"hotsearch-item odd\" data-index=\"1\"" +
"><a class=\"title-content tag-width c-link c-font-medium c-line-clamp1\" hr" +
"ef=\"https://www.baidu.com/s?wd=%E7%94%B7%E5%AD%90%E5%9C%A8%E8%87%AA%E5%AE%" +
"B6%E9%B1%BC%E5%A1%98%E7%94%B5%E9%B1%BC%E8%A2%AB%E7%BD%9A+%E8%AD%A6%E6%96%B9" +
"%E9%81%93%E6%AD%89&sa=fyb_n_homepage&rsv_dl=fyb_n_homepage&from" +
"=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2&hisfilte" +
"r=1\" target=\"_blank\" ><div class=\"title-content-noindex\" style=\"displ" +
"ay: none;\"></div><i class=\"c-icon title-content-top-icon c-color-red c-ga" +
"p-right-small\" style=\"display: none;\"></i><span class=\"title-c" +
"ontent-index c-index-single c-index-single-hot1\" style=\"display: ;\">1<" +
"/span><span class=\"title-content-title\">男子在自家魚塘電魚被罰 警方道歉</sp" +
"an></a><span class=\"title-content-mark ie-vertical c-text c-gap-left-smal" +
"l c-text-hot\">熱</span></li><li class=\"hotsearch-item even\" data-index=" +
"\"4\"><a class=\"title-content c-link c-font-medium c-line-clamp1\" href=" +
"\"https://www.baidu.com/s?wd=%E4%BA%94%E4%B8%80%E5%81%87%E6%9C%9F%E5%8F%AF" +
"%E4%BB%A5%E6%8B%BC%E5%87%BA9%E5%A4%A9%E9%95%BF%E5%81%87&sa=fyb_n_homep" +
"age&rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&am" +
"p;fr=top1000&rsv_idx=2&hisfilter=1\" target=\"_blank\" ><div class" +
"=\"title-content-noindex\" style=\"display: none;\"></div><i class=\"c-ico" +
"n title-content-top-icon c-color-red c-gap-right-small\" style=\"display: " +
"none;\"></i><span class=\"title-content-index c-index-single c-ind" +
"ex-single-hot4\" style=\"display: ;\">4</span><span class=\"title-content-" +
"title\">五一假期可以拼出9天長假</span></a><span class=\"title-content-mark " +
"ie-vertical c-text c-gap-left-small \"></span></li><li class=\"hotsearch-i" +
"tem odd\" data-index=\"2\"><a class=\"title-content tag-width c-link c-font" +
"-medium c-line-clamp1\" href=\"https://www.baidu.com/s?wd=%E5%A6%BB%E5%AD%90" +
"%E6%83%B3%E5%8D%96%E6%88%BF%E6%95%91%E5%84%BF%E9%81%AD%E4%B8%88%E5%A4%AB%E5%" +
"8F%8D%E5%AF%B9+%E6%80%92%E6%8F%90%E7%A6%BB%E5%A9%9A&sa=fyb_n_homepage&am" +
"p;rsv_dl=fyb_n_homepage&from=super&cl=3&tn=baidutop10&fr=to" +
"p1000&rsv_idx=2&hisfilter=1\" target=\"_blank\" ><div class=\"title-c" +
"ontent-noindex\" style=\"display: none;\"></div><i class=\"c-icon title-content-" +
"top-icon c-color-red c-gap-right-small\" style=\"display: none;\"></i><spa" +
"n class=\"title-content-index c-index-single c-index-single-hot2\" style=\"displ" +
"ay: ;\">2</span><span class=\"title-content-title\">妻子想賣房救兒遭丈夫反對 怒提離" +
"婚</span></a><span class=\"title-content-mark ie-vertical c-text c-gap-left-small" +
" c-text-hot\">熱</span></li><li class=\"hotsearch-item even\" data-index=\"5\"><a" +
" class=\"title-content c-link c-font-medium c-line-clamp1\" href=\"https://www.ba" +
"idu.com/s?wd=%E8%B0%81%E5%9C%A8%E9%B9%A4%E5%B2%97%E5%B0%8F%E5%9F%8E%E5%96%9D38%E5%" +
"85%83%E4%B8%80%E6%9D%AF%E7%9A%84%E5%92%96%E5%95%A1&sa=fyb_n_homepage&rsv_dl=f" +
"yb_n_homepage&from=super&cl=3&tn=baidutop10&fr=top1000&rsv_idx=2" +
"&hisfilter=1\" target=\"_blank\" ><div class=\"title-content-noindex\" style=\"di" +
"splay: none;\"></div><i class=\"c-icon title-content-top-icon c-color-red c-gap-right" +
"-small\" style=\"display: none;\"></i><span class=\"title-content-index c-ind" +
"ex-single c-index-single-hot5\" style=\"display: ;\">5</span><span class=\"title-cont" +
"ent-title\">誰在鶴崗小城喝38元一杯的咖啡</span></a><span class=\"title-content-mark ie-v" +
"ertical c-text c-gap-left-small \"></span></li></ul></div><textarea id=\"hotsearch_da" +
"ta\" style=\"display:none;\">";
// 找規律:程式設計正規表示式
// <span class="title-content-title">二十屆二中全會開始舉行</span></a>
// <span class="title-content-title">站上新起點 奮力開新局</span></a>
// 1. 建立正規表示式物件
String reg = "[\\d]</span><span class=\"title-content-title\">(\\S*\\s?\\S*)</span></a>";
Pattern pattern = Pattern.compile(reg);
// 2. 建立匹配器物件,用於匹配判斷
Matcher matcher = pattern.matcher(content);
// 迴圈匹配,匹配返回true,否則返回false
while(matcher.find()) {
String group = matcher.group(1); // 分組
System.out.println(group);
}
}
}
2. Java中正規表示式的相關類
java.util.regex 包主要包括三類: Pattern、Matcher 和 PatternSyntaxException。
-
Pattern 物件是正規表示式的編譯標識。沒有提供公共的構造。 要建立一個模式,您必須首先呼叫其中一個
public static compile方法,然後返回一個Pattern物件。 這些方法接受正規表示式作為第一個引數。 -
Matcher 物件是解析器和針對輸入字串執行匹配操作的發動機。像 Patter 類一樣,也沒有定義公共的建構函式, Matcher 通過呼叫物件上的 matcher 方法來獲取 Pattern 物件。
-
PatternSyntaxException 物件是一個未經檢查的異常,其指示在正規表示式模式中的語法錯誤。
2.1 Pattern 類

該類沒有定義構造器,所以不可以通過 new 的方式建立物件,而是通過呼叫其中的 Pattern.comile(String regex) 建立該正規表示式的物件。
public static Pattern compile(String regex); // regex 為正規表示式的格式;
// 返回該正規表示式的 Pattern 物件。
public Matcher matcher(CharSequence input); // CharSequence input 就是一個需要匹配的字串。
// 返回一個 Matcher 匹配器物件。
2.1.1 Pattern 類中的一些標識屬性
在 Pattern 類定義的替代 compile,它接受一組影響匹配的方式的標誌方法。flags 引數是一個位掩碼,可以包含以下任何公共靜態欄位:
-
Pattern.CANON_EQ
啟用規範等價。指定此標誌後,當且僅當其完整規範分解匹配時,兩個字元才可視為匹配。 例如,當指定此標誌時,表示式 "a\u030A" 將與字串 "\u00E5" 匹配。預設情況下,匹配不考慮採用規範等價。指定此標誌可能會造成效能損失。
-
Pattern.CASE_INSENSITIVE
啟用不區分大小寫的匹配。預設情況下,不區分大小寫的匹配假定僅匹配 US-ASCII 字元集中的字元。 可以通過指定 UNICODE_CASE 標誌連同此標誌來啟用 Unicode 感知的、不區分大小寫的匹配。 通過嵌入式標誌表示式 (?i) 也可以啟用不區分大小寫的匹配。 指定此標誌可能會造成輕微的效能損失。
-
Pattern.COMMENTS
模式中允許空白和註釋。 此模式將忽略空白和在結束行之前以 # 開頭的嵌入式註釋。 通過嵌入式標誌表示式 (?x) 也可以啟用註釋模式。
-
Pattern.DOTALL
啟用點陣模式。在 dotall 模式下,表示式
.匹配任何字元,包括行終止符。預設情況下, 此表示式與行終止符不匹配。Dotall 模式也可以通過嵌入式標誌表示式啟用(?s)。(s 是「單行」模式的助記符,這在 Perl 中也被使用)。 -
Pattern.LITERAL
啟用模式的文字解析。當指定此標誌時,指定模式的輸入字串將被視為文字字元序列。輸入序列中的元字元或跳脫序列將沒有特殊意義。當與此標誌一起使用時,標誌 CASE_INSENSITIVE 和 UNICODE_CASE 保留對匹配的影響。其他旗幟變得多餘。沒有嵌入的標誌字元用於啟用文字解析。
-
Pattern.MULTILINE
啟用多行模式。在多行模式中,表示式^和$匹配恰好在之前或之前分別是行終止符或輸入序列的結尾。 預設情況下,這些表示式僅在整個輸入序列的開頭和結尾匹配。也可以通過嵌入式標誌表示式啟用多模式模式(?m)。
-
Pattern.UNICODE_CASE
啟用 Unicode 感知的大小寫摺疊。當指定此標誌時,不區分大小寫的匹配(由 CASE_INSENSITIVE 標誌啟用)以與 Unicode 標準一致的方式完成。 預設情況下,不區分大小寫的匹配假定僅匹配 US-ASCII 字元集中的字元。Unicode 感知案例摺疊也可以通過嵌入式標誌表示式啟用(?u)。 指定此標誌可能會造成效能損失。
-
Pattern.UNIX_LINES
啟用 UNIX 線路模式。在這種模式下,只有'\n' 行結束在行為的認可.,^ 和 $。 UNIX 線路模式也可以通過嵌入式標誌表示式啟用(?d)。
如下是一些 Pattern 類中常用的方法:
public static boolean matches(String regex,CharSequence input); //判斷該字串中是否有符合該正規表示式的子字串;有返回 true,沒有返回 false。
//CharSequence 是一個介面,其中String 類實現了該介面。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest02 {
/**
* public static boolean matches(String regex,CharSequence input) 方法
*/
public static void main(String[] args) {
String content = "jfdasij123";
boolean matches = Pattern.matches("\\w*123", content);
System.out.println(matches);
boolean matches2 = Pattern.matches("\\d", "1");
System.out.println(matches2);
}
}
public String[] split(CharSequence input); // 根據給定的正規表示式分割,將分割後的字串儲存到String陣列中
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest02 {
/**
*public String[] split(CharSequence input) 分割字串
*/
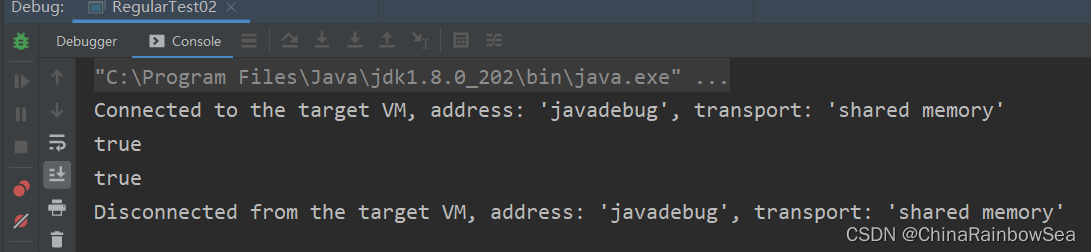
public static void main(String[] args) {
String content = "one:two:three:four:five";
// 1.建立正規表示式物件
Pattern pattern = Pattern.compile(":"); // 以 : 分割
String[] split = pattern.split(content);
for (String regStr : split) {
System.out.println(regStr);
}
}
}
split 方法是一種很好的工具,用於收集位於匹配模式兩側的文字。如下範例,該 split 方法可以從字串「one2️⃣three4️⃣five」 中提取單詞 「one two three four five」。
-
public static String quote(String s)
返回指定 String 的字面值模式 String,此方法產生一個 String,可以將其用於建立與字串 s 匹配的 Pattern, 就好像它是字面值模式一樣。輸入序列中的元字元和跳脫序列不具有任何特殊意義。
嘗試了下,沒有搞懂是啥,返回的全是 "
\Qxxx\E" 的串 -
public String toString()
返回 String 此模式的表示。這是編譯此模式的正規表示式。
2.2 Matcher 類


該類同樣也是沒有公開的構造器呼叫的,所以同樣也是不能 new 物件的。需要通過 呼叫pattern.matcher()方法返回一個 Mathcer 物件。
public Matcher matcher(CharSequence input); // CharSequence input 就是一個需要匹配的字串。
// 返回一個 Matcher 匹配器物件。
如下是 Matcher 類一些常用的方法
2.2.1 索引方法
索引方法提供了有用的索引值,它們精確地顯示了輸入字串中匹配的位置:
public int start():返回上一個匹配的起始索引。public int start(int group):返回上次匹配操作期間給定組捕獲的子序列的起始索引。public int end():返回最後一個字元匹配後的偏移量。public int end(int group):返回在上一次匹配操作期間由給定組捕獲的子序列的最後一個字元之後的偏移量。
start 和 end 方法的使用:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest02 {
/**
* matcher 中的 start / end 的使用
*/
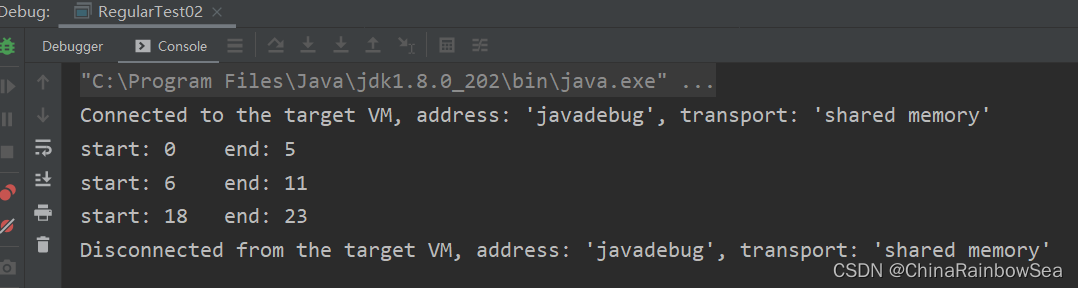
public static void main(String[] args) {
String content = "hello hello fdafd hello";
// 1. 建立正規表示式物件
Pattern pattern = Pattern.compile("\\bhello\\b");
// 2. 建立匹配器物件
Matcher matcher = pattern.matcher(content);
// 迴圈匹配
while(matcher.find()) {
System.out.print("start: " + matcher.start()); // 返回所匹配的子字串的起始下標位置
System.out.print("\t"+"end: " + matcher.end()); // 返回所匹配的子字串的結束下標位置 + 1
System.out.println();
}
}
}
2.2.2 檢查方法
public boolean lookingAt():嘗試將輸入序列從區域開頭開始與模式相匹配。public boolean find():嘗試找到匹配模式的輸入序列的下一個子序列。public boolean find(int start):重置此匹配器,然後嘗試從指定的索引開始找到與模式匹配的輸入序列的下一個子序列。public boolean matches():嘗試將整個區域與模式進行匹配。
使用 matches 和 lookingAt 方法
matches 和 lookingAt 方法都嘗試將輸入序列與模式進行匹配。然而,差異在於,matches 要求整個輸入序列匹配, lookingAt 而不需要。兩種方法始終從輸入字串的開頭開始。
- lookingAt : 只要所匹配物件的字串中含有滿足該正規表示式中的規則的子字串,則返回 true,若一個都沒有滿足該正規表示式的子串,才返回 false。
- matches : 只有所匹配物件的字串整體都滿足該正規表示式中的規則,才返回 true,否則返回 false。
package blogs.blog12;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest02 {
/**
* 使用 matches 和 lookingAt 方法
*/
public static void main(String[] args) {
String content = "hiiiiiiiiiii";
// 1. 建立正規表示式物件
Pattern pattern = Pattern.compile("hi");
// 2. 建立匹配器物件
Matcher matcher = pattern.matcher(content);
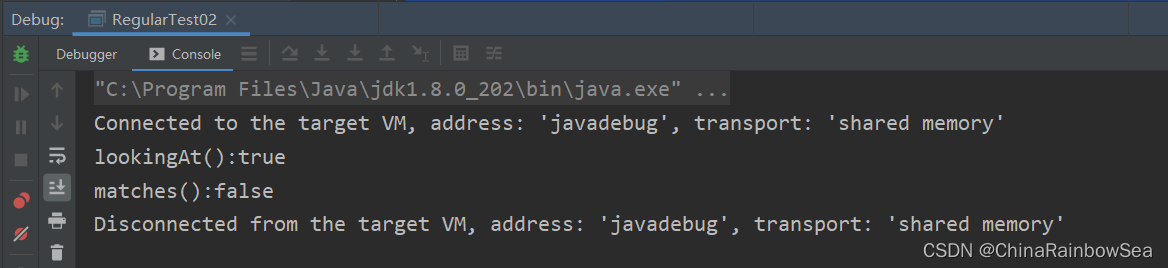
System.out.println("lookingAt():" + matcher.lookingAt()); // true 只要其中匹配的字串存在滿足該正規表示式的規則返回true,
System.out.println("matches():" + matcher.matches()); // false 必須要該匹配的字串整體滿足正規表示式的規則才返回 true
}
}
2.2.3 替換方法
替換方法是替換輸入字串中的文字的有用方法。.
public Matcher appendReplacement(StringBuffer sb, String replacement):執行非終端附加和替換步驟。public StringBuffer appendTail(StringBuffer sb):實現終端附加和替換步驟。public String replaceAll(String replacement):將與模式匹配的輸入序列的每個子序列替換為給定的替換字串。public String replaceFirst(String replacement):將與模式匹配的輸入序列的第一個子序列替換為給定的替換字串。public static String quoteReplacement(String s):返回 String 指定的文字替換 String。該方法產生一個在類的方法中 String 作為文字替換 s 的 appendReplacement 方法 Matcher。所產生的字串 s 將作為字面序列處理。斜槓('\')和美元符號('$')將沒有特殊意義。
使用 replaceFirst(String) and replaceAll(String)
- replaceFirst(String) : 替換滿足給定的正規表示式的第一個子字串的內容。
- replaceAll(String) : 替換滿足給定的正規表示式的所有子字串的內容。
- 注意: 這兩者都不會修改其原本的字串內容,而是返回一個替換成功後的字串。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest02 {
/**
* 使用 replaceFirst(String) and replaceAll(String)
*/
public static void main(String[] args) {
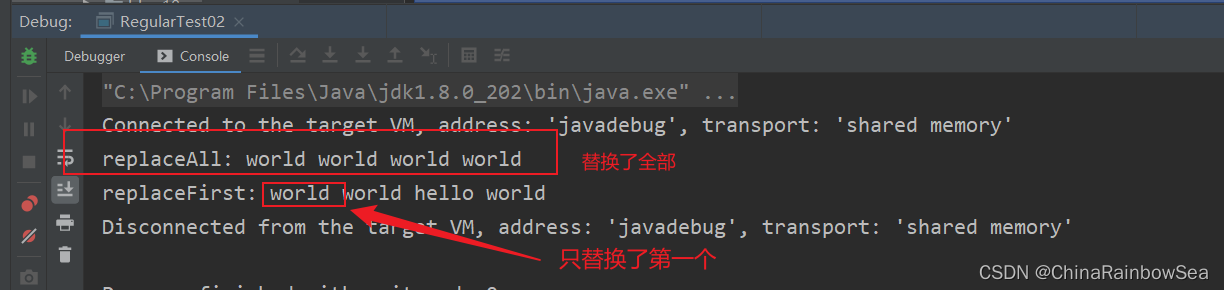
String content = "hello world hello world";
// 1. 建立正規表示式物件
Pattern pattern = Pattern.compile("hello");
// 2. 建立匹配器物件
Matcher matcher = pattern.matcher(content);
String replaceAll = matcher.replaceAll("world"); // 替換全部
System.out.println("replaceAll: " + replaceAll);
String replaceFirst = matcher.replaceFirst("world"); // 替換第一個
System.out.println("replaceFirst: " + replaceFirst);
}
}
再看:
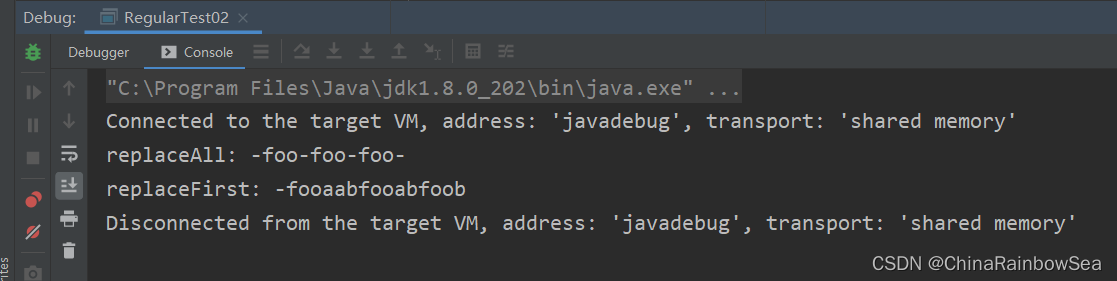
在第一個版本中,所有出現的程式碼 hello 都被替換 world。但為什麼要停在這裡?而不是替換一個簡單的文字 hello, 您可以替換匹配任何正規表示式的文字。該方法的 API 指出,「給定正規表示式 a*b,輸入aabfooaabfooabfoob 和替換字串 -, 在該表示式的匹配器上呼叫此方法將產生字串 -foo-foo-foo-。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest02 {
/**
* 使用 replaceFirst(String) and replaceAll(String)
*/
public static void main(String[] args) {
String content = "aabfooaabfooabfoob";
// 1. 建立正規表示式物件
Pattern pattern = Pattern.compile("a*b");
// 2. 建立匹配器物件
Matcher matcher = pattern.matcher(content);
String replaceAll = matcher.replaceAll("-"); // 替換全部
System.out.println("replaceAll: " + replaceAll);
String replaceFirst = matcher.replaceFirst("-"); // 替換第一個
System.out.println("replaceFirst: " + replaceFirst);
}
}
a*b 表示 ab 或則 b 都符合條件,但是是貪婪量詞,會出現長度零匹配的結果。所以就出現了上面的輸出效果
Matcher 類還提供 appendReplacement 和 appendTail 文字替換方法。使用這兩種方法來實現與之相同效果的 replaceAll。
2.3 PatternSyntaxException異常類
PatternSyntaxException 是未經檢查的異常,指示正規表示式模式中的語法錯誤。PatternSyntaxException 類提供了以下方法來幫助你確定是什麼出了問題:
public String getDescription():檢索錯誤的描述。public int getIndex():檢索錯誤索引。public String getPattern():檢索錯誤的正規表示式模式。public String getMessage():返回一個多行字串,其中包含語法錯誤及其索引的描述,錯誤的正規表示式模式以及模式中錯誤索引的可視指示。
2.4 String 類
2.4.1 java.lang.String 與 java.util.regex.Pattern等效的幾個方法
java.lang.String 通過幾種模仿行為的方法也存在正規表示式支援 java.util.regex.Pattern 中。為方便起見,他們的 API 的關鍵摘錄如下。
-
public boolean matches(String regex):告訴這個字串是否匹配給定的正規表示式。這種形式的這種方法的呼叫產生與表示式完全相同的結果。
str.matches(regex) 和 Pattern.matches(regex, str) -
public String[] split(String regex, int limit):將此字串拆分為給定正規表示式的匹配項。這種形式的方法的呼叫產生與表示式相同的結果
str.split(regex, n) 和 Pattern.compile(regex).split(str, n) -
public String[] split(String regex):將此字串拆分為給定則表示式的匹配項。此方法的工作方式與使用給定表示式和極限引數為零的雙引數拆分方法相同。尾隨的空字串不包含在結果陣列中。
還有一個替換方法,替換CharSequence另一個:
-
public String replace(CharSequence target,CharSequence replacement):將與字面目標序列匹配的字串的每個子字串替換為指定的字面替換序列。替換從字串開始到結束,例如,在字串「aaa」中用「b」替換「aa」將導致「ba」而不是「ab」。
2.4.2 java.lang.String 與 java.util.regex.Matcher 等效的幾個方法
為了方便起見,String 該類也模仿了幾種 Matcher 方法:
public String replaceFirst(String regex, String replacement):用給定的替換替換與給定正規表示式匹配的此字串的第一個子字串。這種形式的這種方法的呼叫產生與表示式完全相同的結果str.replaceFirst(regex, repl)和Pattern.compile(regex).matcher(str).replaceFirst(repl)public String replaceAll(String regex, String replacement):用給定的替換替換與給定正規表示式匹配的此字串的每個子字串。這種形式的這種方法的呼叫產生與表示式完全相同的結果str.replaceAll(regex, repl)和Pattern.compile(regex).matcher(str).replaceAll(repl)
3. 正規表示式的語法
3.1 元字元: (\\) 跳脫字元
首先我們說一下什麼是 跳脫字元(Escape Character)。它在維基百科中是這麼解釋的:
在電腦科學與遠端通訊中,當跳脫字元放在字元序列中,它將對它後續的幾個字元進行替代並解釋。通常,判定某字元是否為跳脫字元由上下文確定。跳脫字元即標誌著跳脫序列開始的那個字元。
這麼說可能有點不好理解,我再來給你通俗地解釋一下。跳脫序列通常有兩種功能。第一種功能是編碼無法用字母表直接表示的特殊資料。第二種功能是用於表示無法直接鍵盤錄入的字元(如回車符)。
在Java中對於一些特殊的字元的匹配,判斷是 需要通過跳脫得到其真正的含義的。
注意:在Java當中兩個 \\ 才表示 一個 \
需要用到跳脫符號的字元有大致有以下一些: {*,+,(),$,/,\,?,[],^,{},}
舉例: "匹配 (" 左括號,匹配 "$" 美元符號。
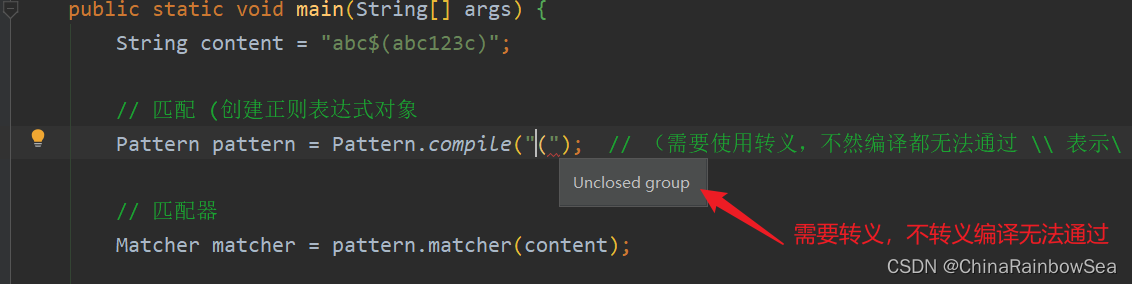
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest03 {
public static void main(String[] args) {
String content = "abc$(abc123c)";
// 匹配 (建立正規表示式物件
Pattern pattern = Pattern.compile("\\("); // (需要使用跳脫,不然編譯都無法通過 \\ 表示\
// 匹配器
Matcher matcher = pattern.matcher(content);
// 迴圈匹配
while(matcher.find()) {
String group = matcher.group(0); // 整體沒有分組的情況
System.out.println(group);
}
}
}
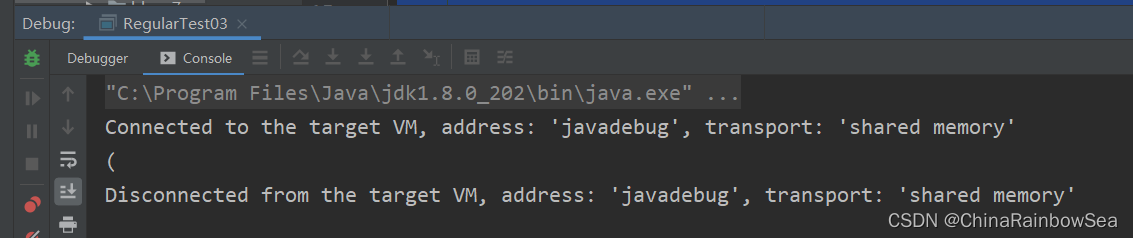
舉例: 匹配"." 單個 點符號,如果不使用跳脫的話,單個點具有表示任意字元的意義。
特殊的當 "." 是在 [.] 方括號中表示的就是 . 本身了,不需要跳脫。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest03 {
public static void main(String[] args) {
String content = "abc.$(abc123c).";
// 匹配 (建立正規表示式物件
Pattern pattern = Pattern.compile("."); // 單個未跳脫的"."表示任意字元
// 匹配器
Matcher matcher = pattern.matcher(content);
// 迴圈匹配
while(matcher.find()) {
String group = matcher.group(0); // 整體沒有分組的情況
System.out.println(group);
}
}
}
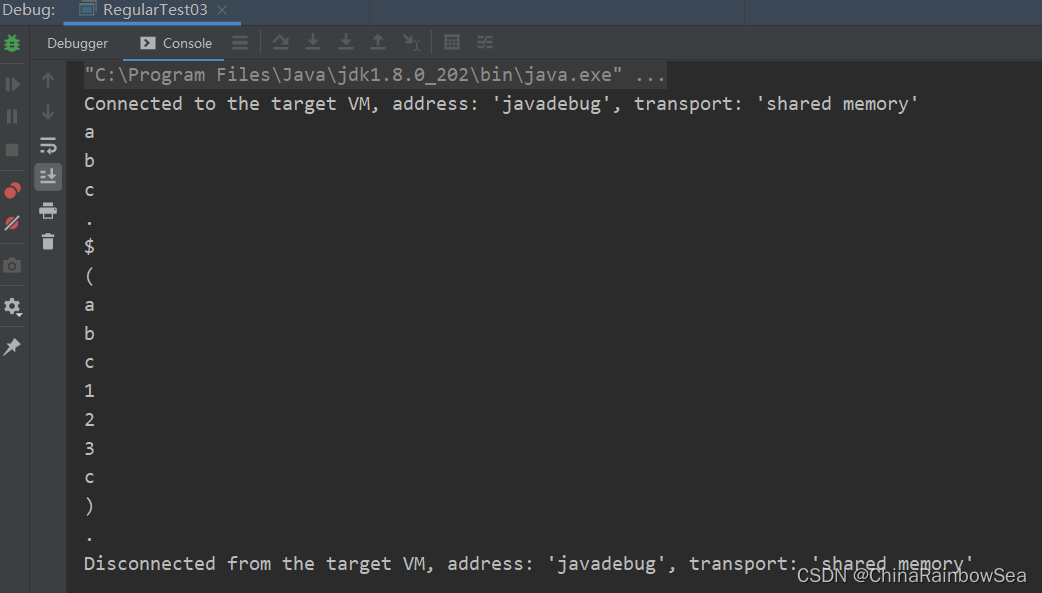
使用 「\\.」 跳脫後: 注意:這裡其實一個 \ 就是表示跳脫的意思了,但是Java中想要表示一個 \ 就需要用兩個 \\ 表示。
3.2 元字元:字元匹配符
注意: 如下的跳脫字元實際上是 單個 "\"的,但是因為在 Java中想要表示單個 斜杆「\」 就需要兩個 "\\" 斜杆表示一個斜杆。
| 符號 | 作用 | 範例 | 解釋 |
|---|---|---|---|
| [ ] | 可接受匹配的字元列表 | [abcd] | 可以匹配a,b,c,d 中的任意 1 個字元 |
| [^ ] | ^表示取反的意思,不接受的字元列表 | [^abc] | 除了a,b,c 之外的任何 1 個字元,包括數位和特殊符號 |
| - | 連字元:表示之間的意思 | A-Z | 表示任意 大寫的 A到 Z 之間的字元。說白了就是任意大寫字母 |
| . | 單個「點」:表示匹配除了 「\n」 以外的任何單個字元 | a..b | 以 a 開頭,b 結尾,中間包含2 個任意字元(除了「\n」) 長度為 4 的字串。例如:aaab,aefb,a35b,a#*b |
| \\d | 匹配單個數位字元,相當於 [0-9] | \\d{3}(\\d)? | 包含3個或4個數位的字串(其中的 ? 表示 0 個或1個)。例如:123,9876。 |
| \\D | 匹配 單 個非數位字元,相當於[^0-9] | \\D(\\d)* | 以 單 個非數位字元開頭,後接任意個數位字串(其中的 * 表示 0 個或 n 個)。例如:a,A123 |
| \\w | 小寫 w 匹配單 個數位,大小寫字母字元以及一個 「_」 下劃線相當於[0-9a-zA-Z_ ] |
\\d{3}\\w | 以 3 個數位字元開頭後接4個數位/大小寫字母/下劃線的 長度為 7 的字串。例如:234abcd,12345Pe,123___1 |
| \\W | 大寫的 W 匹配 單 個非數位,大小寫字母字元,相當於 [^0-9a-zA-Z_ ] | \\W+\\d | 以至少1個非數位非字母字元開頭的,2個數位字元結尾的字串(其中的 + 表示 1 個或 n 個)。例如:@29,#?@10。 |
| \\s | 小寫的 s 表示:匹配任何空白字元(空格,製表符等) | ||
| \\S | 大寫的 S 表示:匹配任何非空白字元和 \\s 剛好相反 | ||
| \\n | 匹配出 \n |
舉例: 匹配三個連續的數位字元:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 字元匹配符的使用
*/
public class RegularTest04 {
public static void main(String[] args) {
String content = "adc 999fajoi111 fajoidfj000";
// 編寫正規表示式
String regStr = "\\d\\d\\d"; // \\d 表示[0-9]的數位字元
// 或者
String regStr2 = "\\d{3}"; // 表示三個連續的數位字元
// 1. 建立正規表示式物件
Pattern pattern = Pattern.compile(regStr);
// 2. 建立匹配器物件
Matcher matcher = pattern.matcher(content);
// 迴圈匹配
while(matcher.find()) {
String group = matcher.group(0);
System.out.println(group);
}
}
}
3.3 元字元正規表示式:不區分大小寫的二種方式
在Java中正則表示式的匹配機制是:預設是區別字母的大小寫的 。
首先,我們來看一下不區分大小寫模式。它有什麼用呢?學一個知識的時候,我一般喜歡先從它的應用出發,這樣有時候更能激發我學習的興趣,也更容易看到學習成果。
下面我來舉個例子說明一下。在進行文字匹配時,我們要關心單詞本身的意義。比如要查詢單詞 cat,我們並不需要關心單詞是 CAT、Cat,還是 cat。根據之前我們學到的知識,你可能會把正則寫成這樣:[Cc][Aa][Tt],這樣寫雖然可以達到目的,但不夠直觀,如果單詞比較長,寫起來容易出錯,閱讀起來也比較困難。
方式一:
在正規表示式中存在一個模式修飾符 :放在整個正則前面時,就表示整個正規表示式都是不區分大小寫的。模式修飾符是通過 (? 模式標識) 的方式來表示的。常用的有如下三種處理方式。
(?i)abc: 表示abc都不區分大小寫。a(?i)bc: 表示 bc 不區分大小寫,但是 a 是區分大小寫的。ab(?i)c:表示只有 c 是不區分大小寫的。a((?i)b)c: 表示只有 b 是不區分大小寫的。
注意: (?i) 模式修飾符,修飾的是後面的字元內容,不是前面的,被修飾的字元匹配時,是忽略大小寫的。可以通過括號進行單個的修飾隔離。
舉例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 字元匹配符的使用
*/
public class RegularTest04 {
public static void main(String[] args) {
String content = "abc ABC aBC aBc Abc";
// 1. 建立對應的正規表示式物件
Pattern pattern1 = Pattern.compile("(?i)abc"); // abc 都忽略大小寫
Pattern pattern2 = Pattern.compile("a(?i)bc"); // bc 忽略大小寫
Pattern pattern3 = Pattern.compile("a((?i)b)c"); // 只有 b 是忽略大小寫的
// 2. 建立對應的 匹配器物件
Matcher matcher1 = pattern1.matcher(content);
// 3. 迴圈匹配
System.out.print("abc 都忽略大小寫: ");
while (matcher1.find()) {
System.out.print(" " + matcher1.group());
}
Matcher matcher2 = pattern2.matcher(content);
System.out.print("\nbc 忽略大小寫: ");
while (matcher2.find()) {
System.out.print(" " + matcher2.group());
}
Matcher matcher3 = pattern3.matcher(content);
System.out.print("\n只有 b 是忽略大小寫: ");
while (matcher3.find()) {
System.out.print(" " + matcher3.group());
}
System.out.println();
}
}
方式二:
通過 在建立 Pattern 正規表示式物件時,設定 忽略大小寫。核心程式碼如下:
public static Pattern compile(String regex,int flags;// 將給定的正規表示式編譯到具有給定標誌的模式中。
Pattern.CASE_INSENSITIVE
啟用不區分大小寫的匹配。預設情況下,不區分大小寫的匹配假定僅匹配 US-ASCII 字元集中的字元。 可以通過指定 UNICODE_CASE 標誌連同此標誌來啟用 Unicode 感知的、不區分大小寫的匹配。 通過嵌入式標誌表示式 (?i) 也可以啟用不區分大小寫的匹配。 指定此標誌可能會造成輕微的效能損失。
舉例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 字元匹配符的使用
*/
public class RegularTest04 {
public static void main(String[] args) {
String content = "abc Abc aBc ABC abC";
// 1. 建立正規表示式物件,並設定忽略大小寫
Pattern pattern = Pattern.compile("abc",Pattern.CASE_INSENSITIVE);
// 2. 建立匹配器
Matcher matcher = pattern.matcher(content);
// 3.迴圈匹配
while(matcher.find()) {
String group = matcher.group();
System.out.println(group);
}
}
}
3.4 元字元:選擇匹配符號
在匹配某個字串的時候是選擇性的,即:既可以匹配這個,又可以匹配那個,這時你需要用到選擇匹配符號 "|"。
| 符號 | 作用 | 範例 | 解釋 |
|---|---|---|---|
| | | 匹配 「|」 前後的表示式 | ab|cd | 匹配 ab 或者 cd |
舉例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 選擇匹配符 |
*/
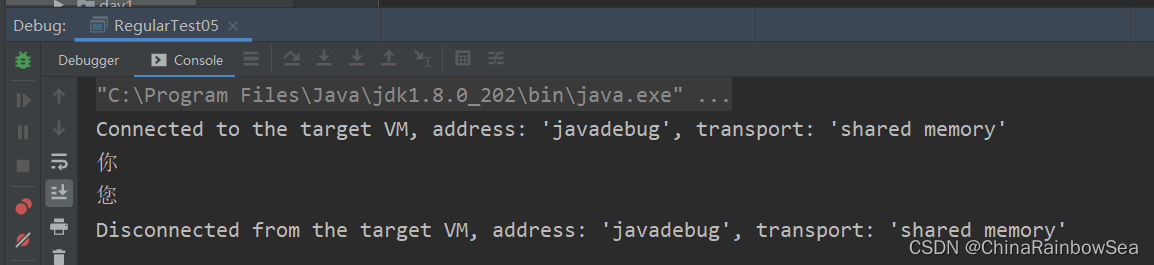
public class RegularTest05 {
public static void main(String[] args) {
String content = "你 您 擬 ";
// 1. 建立正規表示式物件
Pattern pattern = Pattern.compile("你|您");
// 2. 建立匹配器
Matcher matcher = pattern.matcher(content);
// 3.迴圈匹配
while(matcher.find()) {
String group = matcher.group();
System.out.println(group);
}
}
}
3.5 元字元:限定符
用於指定前面的字元和組合項連續出現多少次。
| 符號 | 作用 | 範例 | 解釋 |
|---|---|---|---|
| * | 指定字元重複 0 次 或 n 次 : 0 到多 | (abc)* | 僅包含任意個abc的字串。例如:abc,abcabcabc |
| + | 指定字元重複 1 次或 n次: 至少一次 | m+(abc)* | 以至少m個字元開頭(1或多個m字母),後接任意個 abc的字串。例如:m,mabc,mabcabc |
| ? | 指定字元重複 0 次或 1 次:最多1次 | m+abc? | 以至少m個字元開頭(1或多個m字母),後接ab或abc的字串。例如:mab,mabc,mmmab。(注意 ? 修飾鄰近的字元) |
| 只能輸入n個字元 | [abcd] | 由abcd中字母組成的任意長度為3的字串。例如:abc,dbc,abc | |
| 指定至少 n 個匹配 | [abcd] | 由 abcd中字母組成的任意長度不小於3 的字串,最多沒有設定。例如:aab,dbc,aaabdc | |
| 指定至少 n 個但不多於 m 個匹配 | [abcd] | 由abcd中字母組成的任意長度不小於3,不大於5 的字串。例如:abc,abcd,aaaaa,bcdab |
舉例:
package blogs.blog12;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 限定符
*/
public class RegularTest06 {
public static void main(String[] args) {
String content = "a111111";
//String regStr = "1+"; // 匹配一個或多個
//String regStr = "\\d+"; // 匹配一個數位或者多個數位
//String regStr = "1*"; // 匹配任意多個
String regStr = "a1?"; // 匹配a 或者 a1 , 0 個或 1 個
// 1. 建立正規表示式物件
Pattern pattern = Pattern.compile(regStr);
// 2. 建立匹配器
Matcher matcher = pattern.matcher(content);
// 3.迴圈匹配
while(matcher.find()) {
String group = matcher.group();
System.out.println(group);
}
}
}
3.6 貪婪匹配(Greedy)/ 非貪婪匹配(Lazy)
3.6.1 貪婪匹配(Greedy)
首先,我們來看一下貪婪匹配。在正則中,表示次數的量詞 預設是貪婪的,在貪婪模式下,會嘗試儘可能最大長度去匹配。
首先,我們來看一下在字串 aaabb 中使用正則 a* 的匹配過程。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 限定符
*/
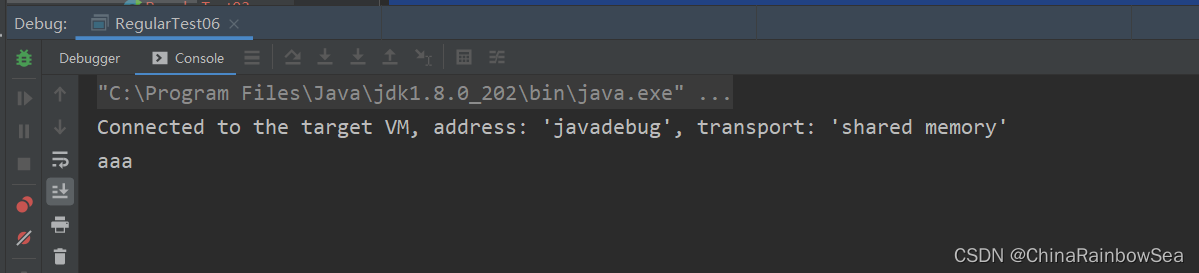
public class RegularTest06 {
public static void main(String[] args) {
String content = "aaabb ";
// 1. 建立正規表示式物件
Pattern pattern = Pattern.compile("a*");
// 2. 建立匹配器
Matcher matcher = pattern.matcher(content);
// 3.迴圈匹配
while(matcher.find()) {
String group = matcher.group();
System.out.println(group);
}
}
}
| 字串 | aaabb |
|---|---|
| 下標 | 012345 |
| 匹配 | 開始 | 結束 | 說明 | 匹配內容 |
|---|---|---|---|---|
| 第 1 次 | 0 | 3 | 到第一個字母 b 發現不滿足,輸出 aaa | aaa |
| 第 2 次 | 3 | 3 | 匹配剩下的 bb,發現匹配不上,輸出空字串 | 空字串 |
| 第 3 次 | 4 | 4 | 匹配剩下的 b,發現匹配不上,輸出空字串 | 空字串 |
| 第 4 次 | 5 | 5 | 匹配剩下的空字串,輸出空字串 | 空字串 |
a* 在匹配開頭的 a 時,會嘗試儘量匹配更多的 a,直到第一個字母 b 不滿足要求為止,匹配上三個 a,後面每次匹配時都得到了空字串。
相信看到這裡你也發現了,貪婪模式的特點就是儘可能進行最大長度匹配。所以要不要使用貪婪模式是根據需求場景來定的。如果我們想盡可能最短匹配呢?那就要用到非貪婪匹配模式了。
3.6.2 非貪婪匹配(Lazy)
那麼如何將貪婪模式變成非貪婪模式呢?我們 可以在量詞後面加上英文的問號 (?),正則就變成了 a*?。此時的匹配結果
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 限定符
*/
public class RegularTest06 {
public static void main(String[] args) {
String content = "aaabb ";
// 1. 建立正規表示式物件
Pattern pattern = Pattern.compile("a+?");
// 2. 建立匹配器
Matcher matcher = pattern.matcher(content);
// 3.迴圈匹配
while(matcher.find()) {
String group = matcher.group();
System.out.println(group);
}
}
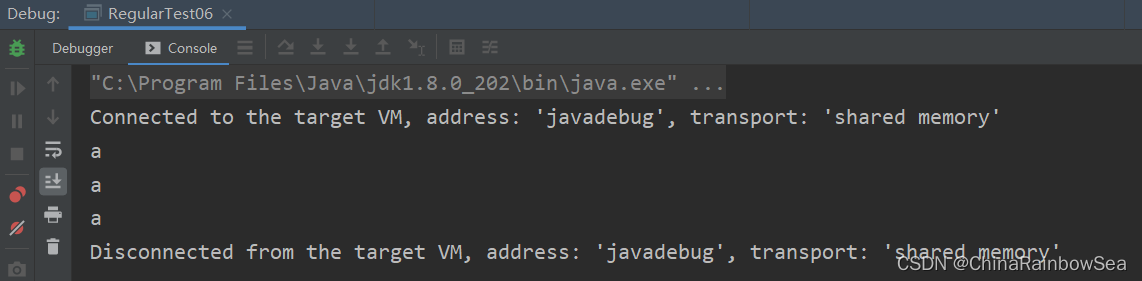
這一次我們可以看到,這次匹配到的結果都是單個的 a,就連每個 a 左邊的空字串也匹配上了。
到這裡你可能就明白了,非貪婪模式會盡可能短地去匹配,我把這兩者之間的區別寫到了下面這張圖中。

3.7 元字元:定位符
定位符,規定要匹配的字串出現的位置,比如在字串的開始,還是結束的位置,這個也是相當有用的。
| 符號 | 作用 | 範例 | 解釋 |
|---|---|---|---|
| ^ | 指定起始字元 | [1]+[a-z]* | 以至少1個數位開頭,後接任意個小寫字母的字串。例如:123,6aa,555edf |
| $ | 指定結束字元 | [2]\\-[a-z]+$ | 以至少1個數位開頭,中間連線字元」-「,並以至少1個小寫字母結尾的字串。例如:1-a |
| \\b | 匹配目標字串的邊界。 | han\\b | (這裡的邊界可以是字元之間的空格/結尾)。例如:sphan nnhan可以匹配到兩者中的 han |
| \\B | 匹配目標字串的非邊界 | han\\B | 和 \\b 的含義相反。例如:sphan nnhan。只能匹配到 nnhan中的 han |
舉例:
package blogs.blog12;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
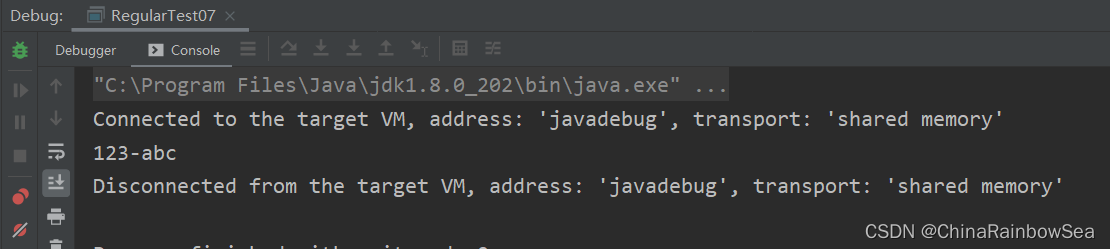
public class RegularTest07 {
public static void main(String[] args) {
String content = "123-abc"; // a123abc 123abc 123abc12,
//String regStr = "^[0-9]+[a-z]*"; // 以至少1個數位開頭,後接任意個小寫字母的字串
//String regStr = "^[0-9]+[a-z]+$"; // 以至少1個數位開頭,必須以至少一個小寫字母界結尾
String regStr = "^[0-9]+\\-[a-z]+$";
// 建立正則物件
Pattern pattern = Pattern.compile(regStr);
// 建立匹配器
Matcher matcher = pattern.matcher(content);
// 迴圈
while(matcher.find()) {
String group = matcher.group(0);
System.out.println(group);
}
}
}
舉例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest07 {
public static void main(String[] args) {
String content = "hanshunping sphan nnhaan";
//String regStr = "han\\b"; // 表示匹配邊界 han ,邊界:空格的子字串的後面
String regStr = "han\\B"; // 僅僅只是字串的結尾,不含空格
// 建立正則物件
Pattern pattern = Pattern.compile(regStr);
// 建立匹配物件
Matcher matcher = pattern.matcher(content); // 該引數是個介面,String 實現了該介面
// 迴圈
while(matcher.find()) {
String group = matcher.group();
System.out.println(group);
}
}
}
4. 正規表示式:分組 / 特殊的分組
常用的分組構造形式:
在正規表示式中使用() 圓括號,括起來的就表示分組了 。
()非命名捕獲/也稱為編號分組,捕獲匹配的子字串,編號為 0 的表示第一個分組,第一個捕獲是由整個正規表示式模式匹配的文字,其它捕獲結果則根據左括號的順序從 1 開始自動編號。(? \<name> pattern): 命令捕獲/也稱為命名分組,將匹配的子字串捕獲到一個組名稱或編號名稱中,用於 name 的字串不能包含任何標點符號,並且不能以數位開頭,可以使用單引號代替尖括號。例如 ('?' name)。
4.1 編號分組
括號在正則中可以 用於分組,被括號括起來的部分 「子表示式」會被儲存成一個 子組。
那分組和編號的規則是怎樣的呢?其實很簡單,用一句話來說就是,第幾個括號就是第幾個分組。這麼說可能不好理解,我們來舉一個例子看一下。
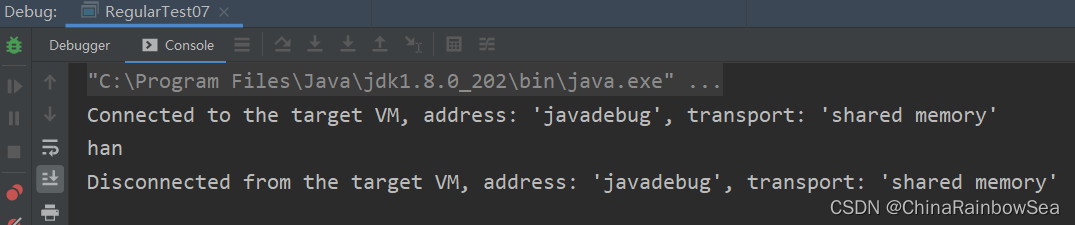
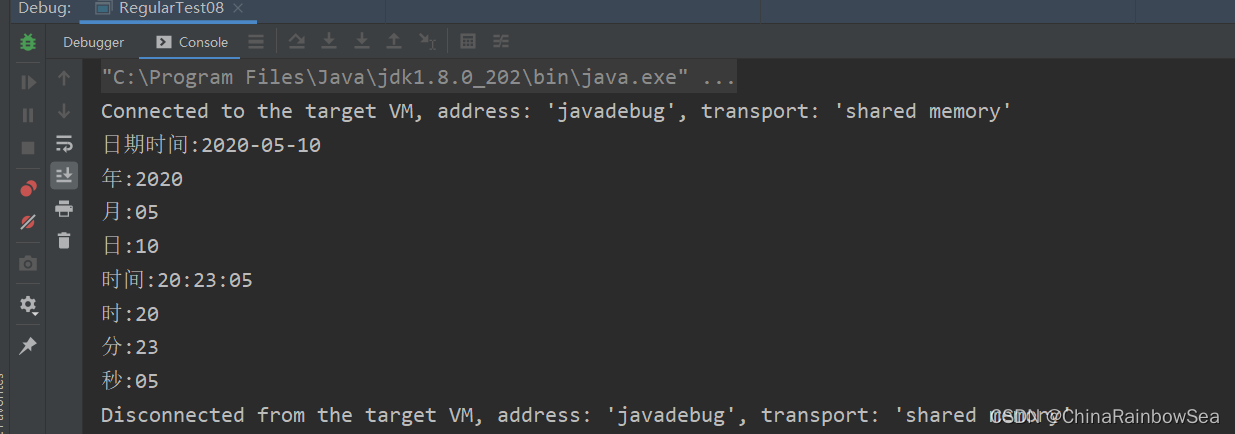
這裡有個時間格式 2020-05-10 20:23:05。假設我們想要使用正則提取出裡面的日期和時間。

我們可以寫出如圖所示的正則,將日期和時間都括號括起來。這個正則中一共有兩個分組,日期是第 1 個,時間是第 2 個。
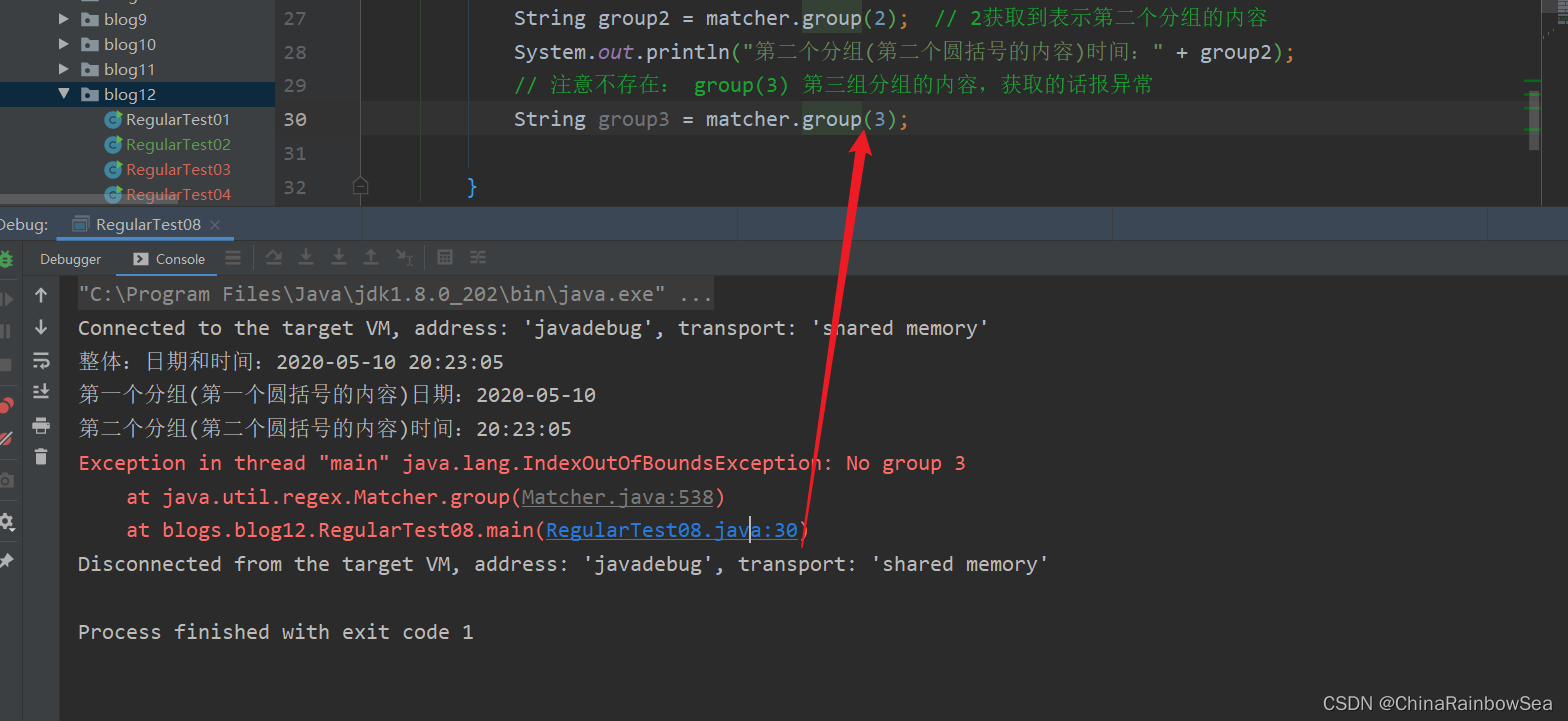
注意: 不要分組越界了。就是說不要去存取沒有分組的 group()的內容。比如說:你只分了兩組,分別是 1,2 但是你卻存取了一個不存在的分組 3,會報異常:java.lang.IndexOutOfBoundsException:
補充:
public String group(int group); // Matcher 類中的物件方法,獲取到分組/捕獲到的分組中的內容。
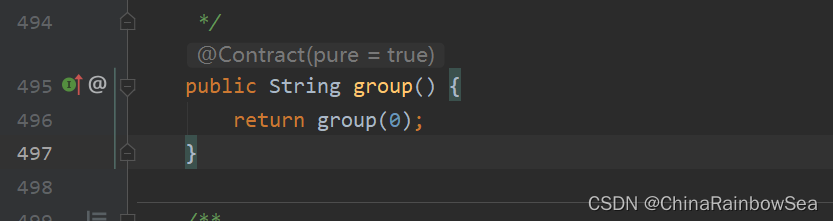
- group(0)/() :表示獲取到符合正規表示式中整體的子字串內容。如果不傳引數預設呼叫的還是 group(0)的,原始碼中可以看出來如下:
- group(1) :表示獲取到從整體符合正規表示式的子字串的基礎上,進行第一個分組中的內容。
- group(2) :表示獲取到從整體符合正規表示式的子字串的基礎上,進行第二個分組中的內容。
- group(3) ... 第3組,第4組,第5組都是以此類推的。
- 注意不要越界了:不然報:
java.lang.IndexOutOfBoundsException異常。
舉例:
package blogs.blog12;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 分組
*/
public class RegularTest08 {
public static void main(String[] args) {
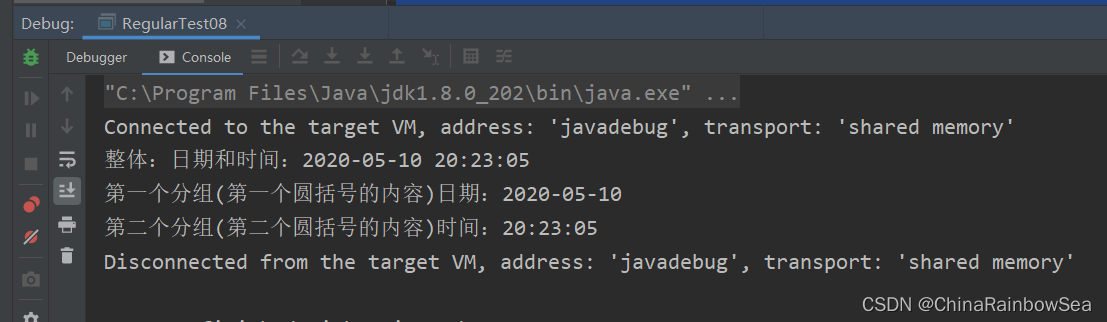
String content = "2020-05-10 20:23:05";
String regStr = "(\\d{4}-\\d{2}-\\d{2}).(\\d{2}:\\d{2}:\\d{2})";
// 1.建立正規表示式物件
Pattern pattern = Pattern.compile(regStr);
// 2. 建立匹配器物件
Matcher matcher = pattern.matcher(content);
// 3.迴圈匹配獲取
while (matcher.find()) {
String group = matcher.group(0); // 0 / 不傳引數,預設獲取是整體正規表示式匹配的內容
System.out.println("整體:日期和時間:" + group);
String group1 = matcher.group(1); // 1 獲取到表示第一個分組內容
System.out.println("第一個分組(第一個圓括號的內容)日期:" + group1);
String group2 = matcher.group(2); // 2獲取到表示第二個分組的內容
System.out.println("第二個分組(第二個圓括號的內容)時間:" + group2);
}
}
}
注意不存在: group(3) 第三組分組的內容,獲取的話報異常
4.2 命名分組
前面我們講了分組編號,但由於編號得數在第幾個位置,後續如果發現正則有問題,改動了括號的個數,還 可能導致編號發生變化,因此一些程式語言提供了 命名分組(named grouping),這樣和數位相比更容易辨識,不容易出錯。命名分組的格式為 (?P<分組名>正則)。使用了命名分組,你即可以使用你命名的名稱 / 自動編號的序號獲取到對應分組中的內容。
命名的注意事項:
不能包含任何標點符號,並且不能以數位開頭,可以使用單引號代替尖括號。例如 ('?' name)。
比如在獲取四個連續的數位中,再分組獲取兩個連續的數位: 數值為 8899
8899
"(?<g1>\\d\\d)(?<g2>\\d\\d)";
補充:
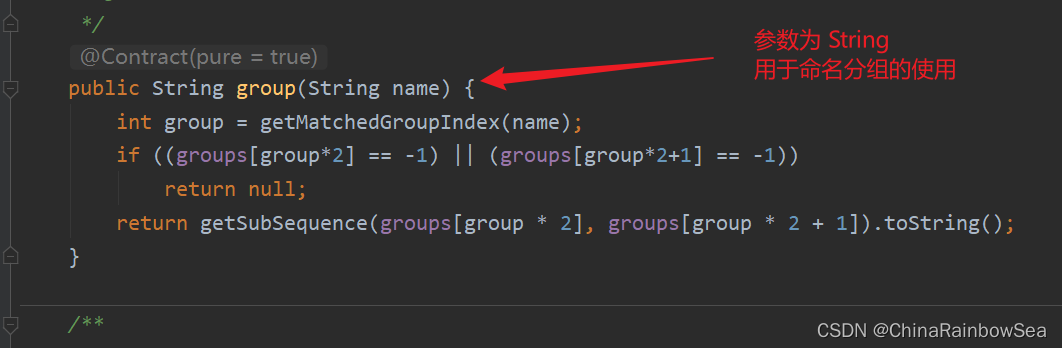
public String group(String name); // Matcher 類中的物件方法,通過設定的分組名獲取到對應匹配的分組內容。
舉例:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 分組
*/
public class RegularTest08 {
public static void main(String[] args) {
String content = "9988fasjiofas";
//String regStr = "(\\d\\d)(\\d\\d)"; // 匹配 4 個數位的字串
// 命名分組: 即可以給分組取名:
String regStr = "(?<num1>\\d\\d)(?<num2>\\d\\d)"; // 注意命名不可以數位開頭
// 建立正則物件
Pattern pattern = Pattern.compile(regStr); // String實現了該引數的介面
// 建立匹配器
Matcher matcher = pattern.matcher(content);
// 迴圈匹配
while (matcher.find()) {
String group = matcher.group(0); // 整體分組
System.out.println(group);
//String group1 = matcher.group(1); // 第一分組
String group1 = matcher.group("num1"); // 第一分組
System.out.println(group1);
//String group2 = matcher.group(2); // 第二分組
String group2 = matcher.group("num2"); // 第二分組 可以用命名也可以用編號
System.out.println(group2);
}
}
}
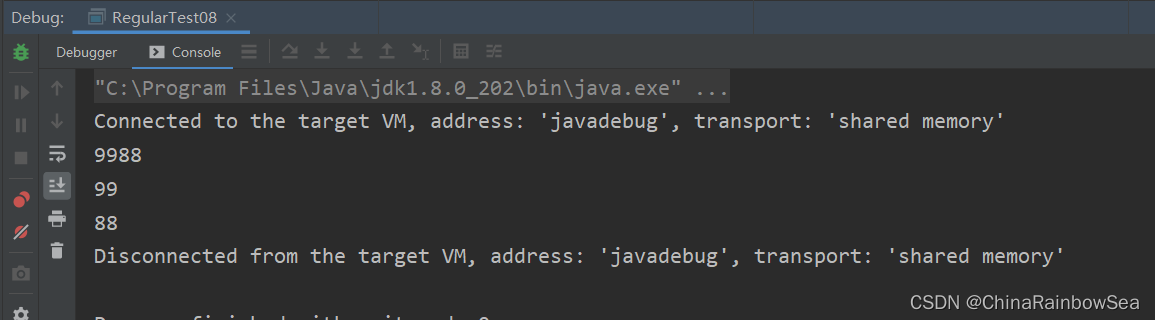
需要注意的是,剛剛提到的方式命名分組和前面一樣,給這個分組分配一個編號,不過你可以使用名稱,不用編號,實際上命名分組的編號已經分配好了。不過命名分組並不是所有語言都支援的,在使用時,你需要查閱所用語言正則說明檔案,如果支援,那你才可以使用。
4.3 特殊分組 / 不儲存子組
在括號裡面的會儲存成子組,但有些情況下,你可能只想用括號將某些部分看成一個整體,後續不用再用它,類似這種情況,在實際使用時,是沒必要儲存子組的。這時我們可以在括號裡面使用 ?: 不儲存子組。
如果正則中出現了括號,那麼我們就認為,這個子表示式在後續可能會再次被參照,所以 不儲存子組可以提高正則的效能。除此之外呢,這麼做還有一些好處,由於子組變少了,正則效能會更好,在 子組計數時也更不容易出錯。
那到底啥是不儲存子組呢?我們可以理解成,括號只用于歸組,把某個部分當成「單個元素」,不分配編號,後面不會再進行這部分的參照。

具體的說明如下:
表格中的 pattern 表示匹配的內容/正規表示式。注意: 該格式中的 ( ) 圓括號是不表示分組的,因為該分組的內容是不會儲存起來的,更無法捕獲到的。
| 格式 | 說明 |
|---|---|
| (?:pattern) | 匹配 pattern ,但不捕獲該匹配的子表示式,即它是一個非捕獲匹配,不儲存不供以後使用,這對於用 」or「 字元(|) 組合模式部件的情況很有用。例如:industr(?:y|ies) 是比 'industry|industries' 更經濟的表示式 |
| (?=pattern) | 它是一個非捕獲匹配,例如:Windows(?=95|98|NT|2000) 匹配 Windows 2000 中的 」Windows" ,但不匹配 「Windows 3.1" 中的 Windows |
| (?!pattern) | 該表示式匹配不處於匹配 pattern 的字串的起始點的搜尋字串。它是一個非捕獲匹配。例如:Windows(?!95|98|NT|200) 匹配 」Windows 3.1" 中的 」Windows ",但不匹配Windows 2000 中的 「Windows」 |
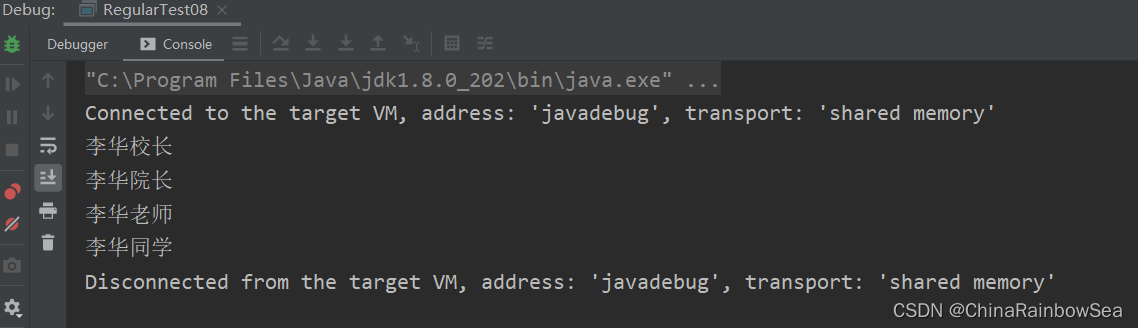
舉例:(?:pattern) 的使用 從」李華校長 李華院長 李華老師 李華同學 「的字串中找到 李華校長 李華院長 李華老師 李華同學
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 分組
*/
public class RegularTest08 {
/**
* 1. 找到李華校長 李華院長 李華老師 李華同學 子字串
*
*/
public static void main(String[] args) {
String content = "李華校長 李華院長 李華老師 李華同學";
String regStr = "李華(?:校長|院長|老師|同學)";
// 建立正則物件
Pattern pattern = Pattern.compile(regStr);
// 建立匹配器物件
Matcher matcher = pattern.matcher(content);
// 迴圈
while (matcher.find()) {
String group = matcher.group(0);
//String group1 = matcher.group(1); 特殊分組中的括號不表示分組,沒有分組就無法捕獲到分組內容了
System.out.println(group);
}
}
}
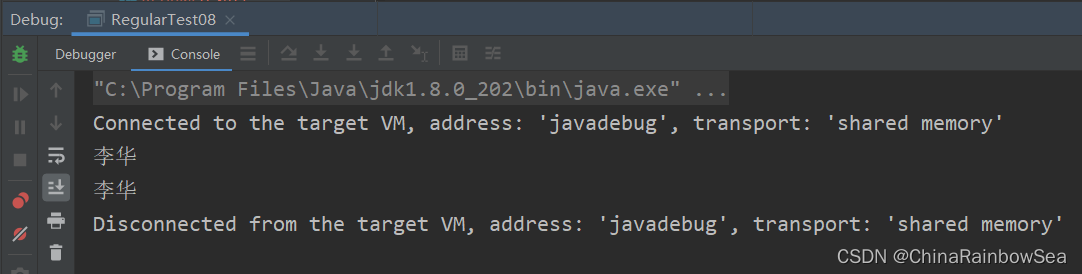
舉例:(?=pattern) 的使用 。從「李華校長 李華院長 李華老師 李華同學 「字串中找到身份為校長院長」名為李華的名字。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 分組
*/
public class RegularTest08 {
/**
* 從「李華校長 李華院長 李華老師 李華同學 「字串中找到身份為校長院長」名為李華的名字。
*
*/
public static void main(String[] args) {
String content = "李華校長 李華院長 李華老師 李華同學";
String regStr = "李華(?=校長|院長)";
// 建立正則物件
Pattern pattern = Pattern.compile(regStr);
// 建立匹配器物件
Matcher matcher = pattern.matcher(content);
// 迴圈
while (matcher.find()) {
String group = matcher.group(0);
//String group1 = matcher.group(1); 特殊分組中的括號不表示分組,沒有分組就無法捕獲到分組內容了
System.out.println(group);
}
}
}
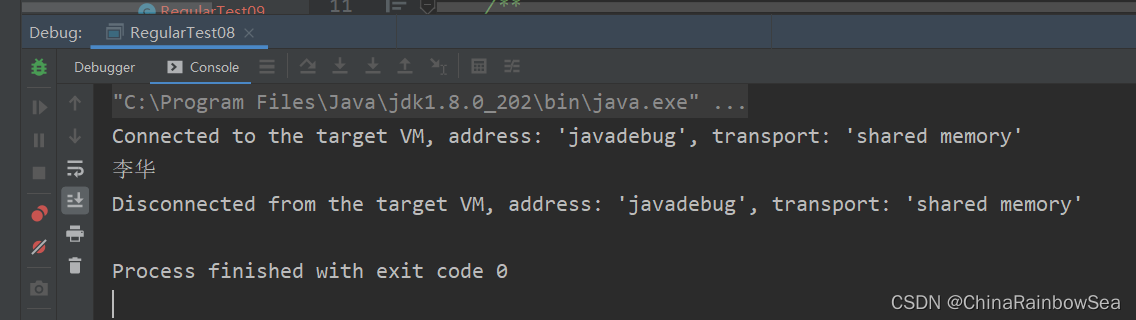
舉例:(?!pattern)的使用 。 從「李華校長 李華院長 李華老師 李華同學 「字串中找到身份不是院長,校長,老師的李華姓名
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 分組
*/
public class RegularTest08 {
/**
* 從「李華校長 李華院長 李華老師 李華同學 「字串中找到身份不是院長,校長,老師的李華姓名
*
*/
public static void main(String[] args) {
String content = "李華校長 李華院長 李華老師 李華同學";
String regStr = "李華(?!校長|院長|老師)";
// 建立正則物件
Pattern pattern = Pattern.compile(regStr);
// 建立匹配器物件
Matcher matcher = pattern.matcher(content);
// 迴圈
while (matcher.find()) {
String group = matcher.group(0);
//String group1 = matcher.group(1); 特殊分組中的括號不表示分組,沒有分組就無法捕獲到分組內容了
System.out.println(group);
}
}
}
4.4 分組中的括號巢狀
前面講完了子組和編號,但有些情況會比較複雜,比如在括號巢狀的情況裡,我們要看某個括號裡面的內容是第幾個分組怎麼辦?不要擔心,其實方法很簡單,我們只需要數左括號(開括號)是第幾個,就可以確定是第幾個子組。
在阿里雲簡單紀錄檔系統中,我們可以使用正則來匹配一行紀錄檔的行首。假設時間格式是 2020-05-10 20:23:05 。

日期分組編號是 1,時間分組編號是 5,年月日對應的分組編號分別是 2,3,4,時分秒的分組編號分別是 6,7,8。
舉例: 對 2020-05-10 20:23:05 日期時間進行 8 次分組。分為日期:年月日,時間:時分秒。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 分組
*/
public class RegularTest08 {
/**
*
* 對 2020-05-10 20:23:05 日期時間進行 8 次分組。分為日期:年月日,時間:時分秒。
*/
public static void main(String[] args) {
String content = "2020-05-10 20:23:05";
String regStr = "((\\d{4})-(\\d{2})-(\\d{2})).((\\d{2}):(\\d{2}):(\\d{2}))";
// 1.建立正規表示式物件
Pattern pattern = Pattern.compile(regStr);
// 2. 建立匹配器物件
Matcher matcher = pattern.matcher(content);
// 3.迴圈匹配遍歷
while(matcher.find()) {
System.out.println("日期時間:" + matcher.group(1));
System.out.println("年:" + matcher.group(2));
System.out.println("月:" + matcher.group(3));
System.out.println("日:" + matcher.group(4));
System.out.println("時間:" + matcher.group(5));
System.out.println("時:" + matcher.group(6));
System.out.println("分:" + matcher.group(7));
System.out.println("秒:" + matcher.group(8));
}
}
}
5. 正規表示式的實現的原理分析:
下面我們來分析一下關於 正規表示式在Java中的 Patter 類和 Matcher 類中方法的呼叫的底層實現的機制,原理。
5.1 正規表示式中不含分組的原理分析
首先我們來分析沒有分組中的正規表示式的原理
分析如下程式碼:
package blogs.blog12;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Java中正規表示式底層的實現原理
*/
public class RegularTest09 {
public static void main(String[] args) {
String content = "1995年5月23日,JAVA語言誕生(雛形)1996年,1997分別推出JDK1.0,JDK1.1版。" +
"1999年,JAVA被分成J2SE,J2EE,J2ME2000年," +
"JDK1.4釋出2004年9月30日18:00PM,J2SE1.5釋出,成為Java語言發展史上的又一里程碑。" +
"為了表示該版本的重要性,J2SE1.5更名為Java SE 5.0 2005年," +
"JAVA版本正式更名為JAVAEE,JAVASE, JAVAME2006年12月," +
"SUN公司釋出JRE6.0 2009年04月20日,Oracle以74億美元收購Sun。取得java的版權。 " +
"2010年9月,JDK7.0已經發布,增加了簡單閉包功能。 " +
"2011年7月,甲骨文公司釋出java7的正式版。2014年," +
"甲骨文公司釋出了Java8正式版";
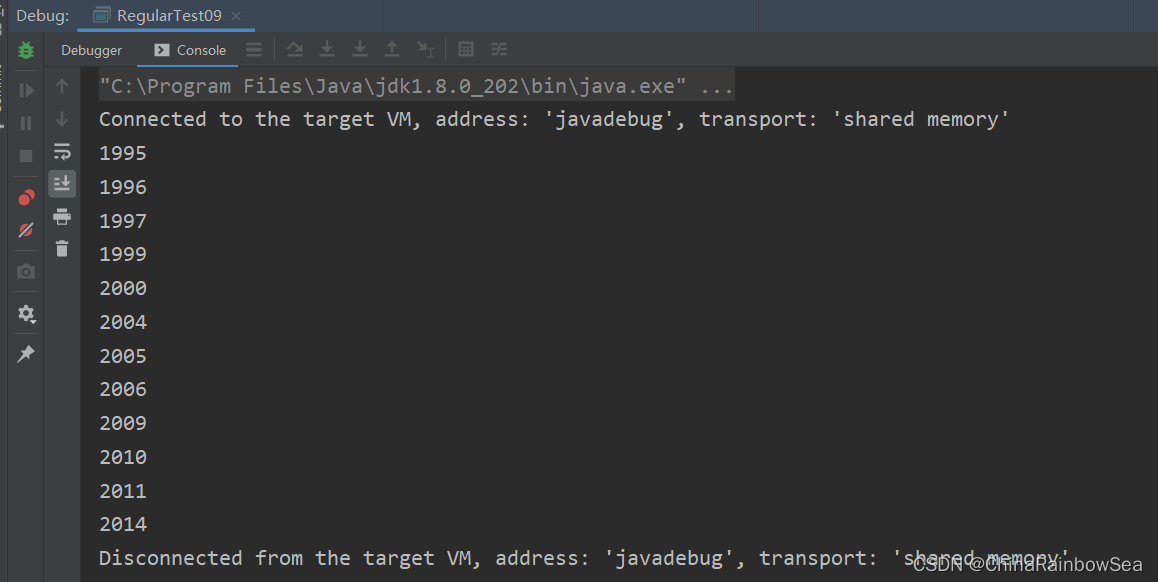
// 這裡我編寫一個獲取連續4個數位的子字串
String regStr = "\\d\\d\\d\\d";
// 1. 建立正規表示式物件
Pattern pattern = Pattern.compile(regStr);
// 2. 建立匹配器物件
Matcher matcher = pattern.matcher(content);
// 3.迴圈遍歷匹配
while(matcher.find()) {
String group = matcher.group();
System.out.println(group);
}
}
}
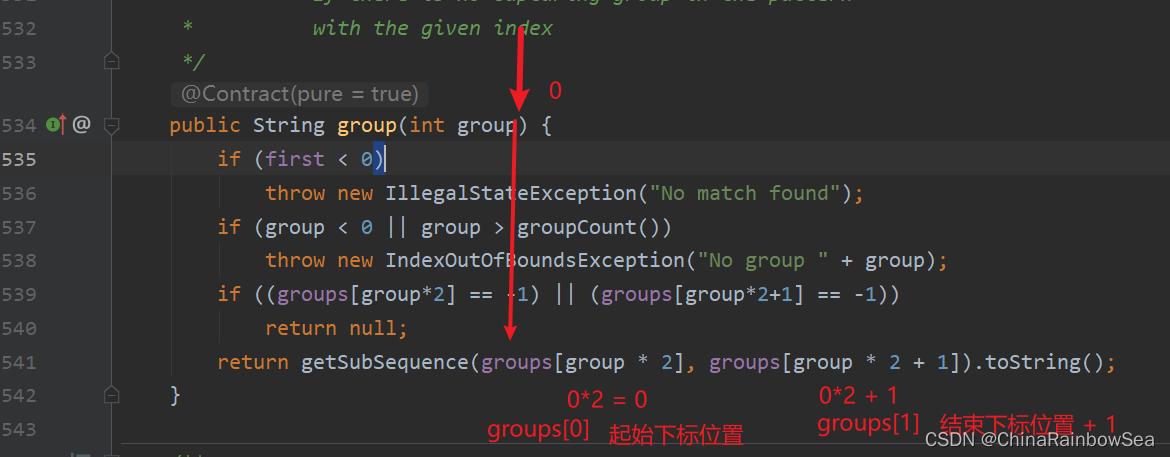
分析:
(matcher.find() 方法的執行的任務流程:
-
根據我們指定的/編寫的正規表示式的規則,定位到滿足我們正規表示式中的子字串(比如這裡是:1995)找4個連續的數位字串
-
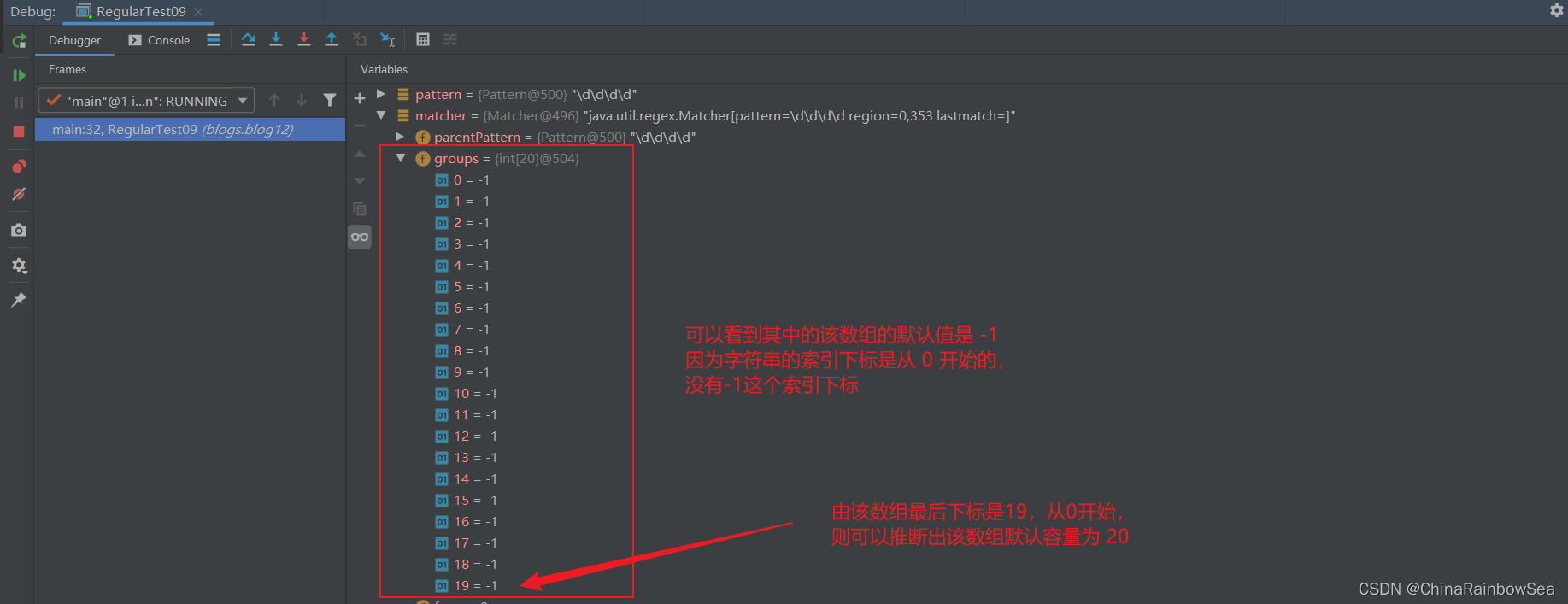
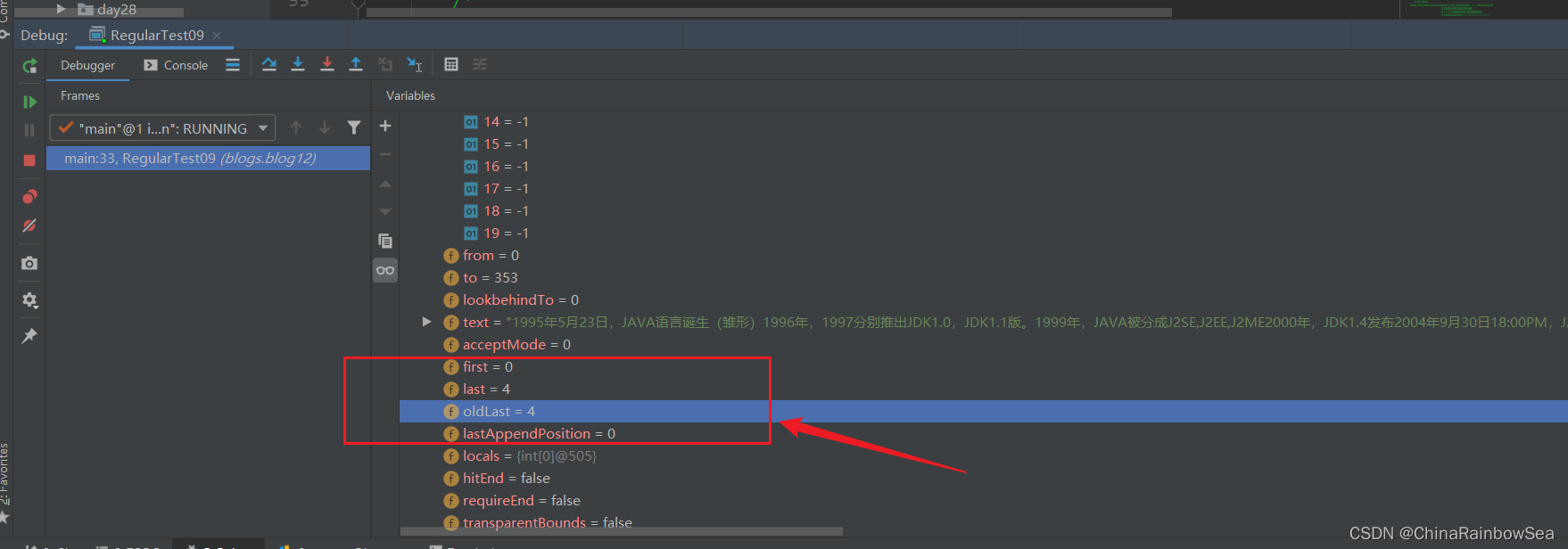
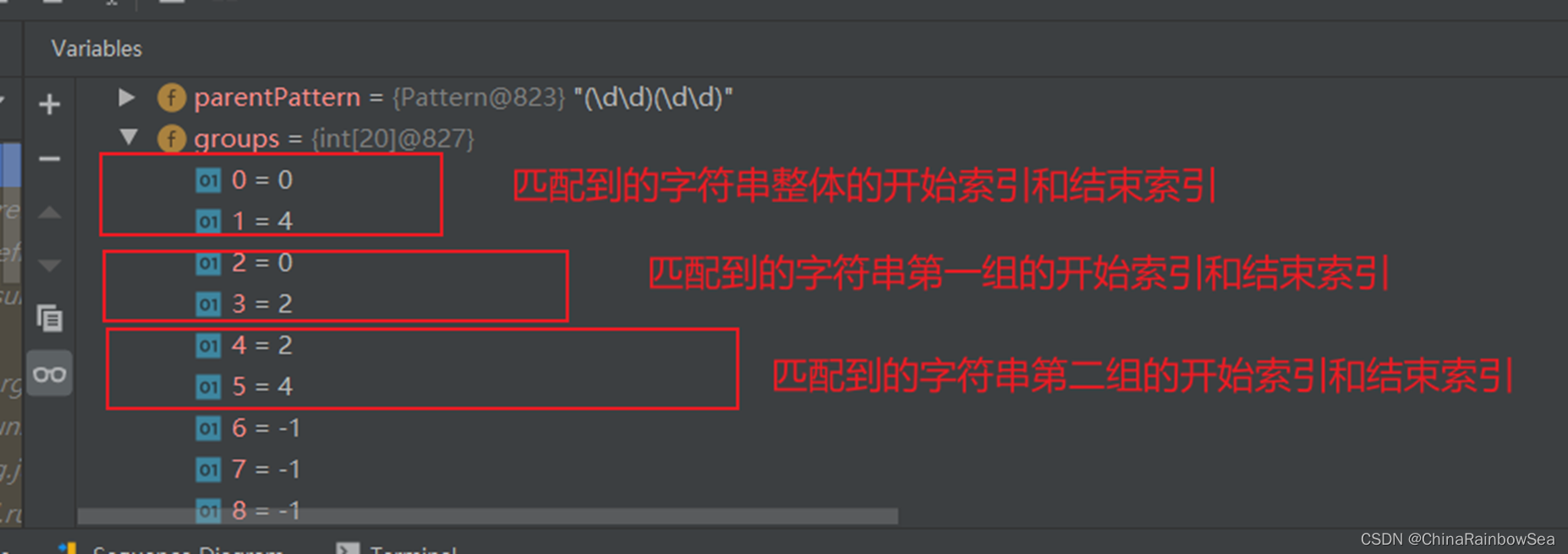
找到後,將該子字串的開始索引 (這裡的1995 的起始下標是 0 )下標和 結束索引 (這裡的1995 的結束下標是 3 )下標位置,記錄到 Matcher 物件中的 int[] groups 陣列中。
- groups[0] = 0 ,把該找到的子字串下標位置儲存到 groups[0] 中。再把該子字串的「結束的索引 + 1」 的值,這裡為 4 ,即下次執行 find() 時,就從 4 索引開始匹配了。
- 注意:groups[20] 陣列預設容量是 20 ,如果不足會自動擴容,其中的預設值是 -1(字串的索引下標是從 0 開始的,沒有-1 這個下標索引)。如下是我們 Debug 偵錯的結果
- 同時記錄 odLast 的賦值為該子字串的結束索引下標 + 1 的值,這裡是 3 + 1 = 4 ,即下次執行 find() 方法時,就從 4 索引下標開始匹配了。
-
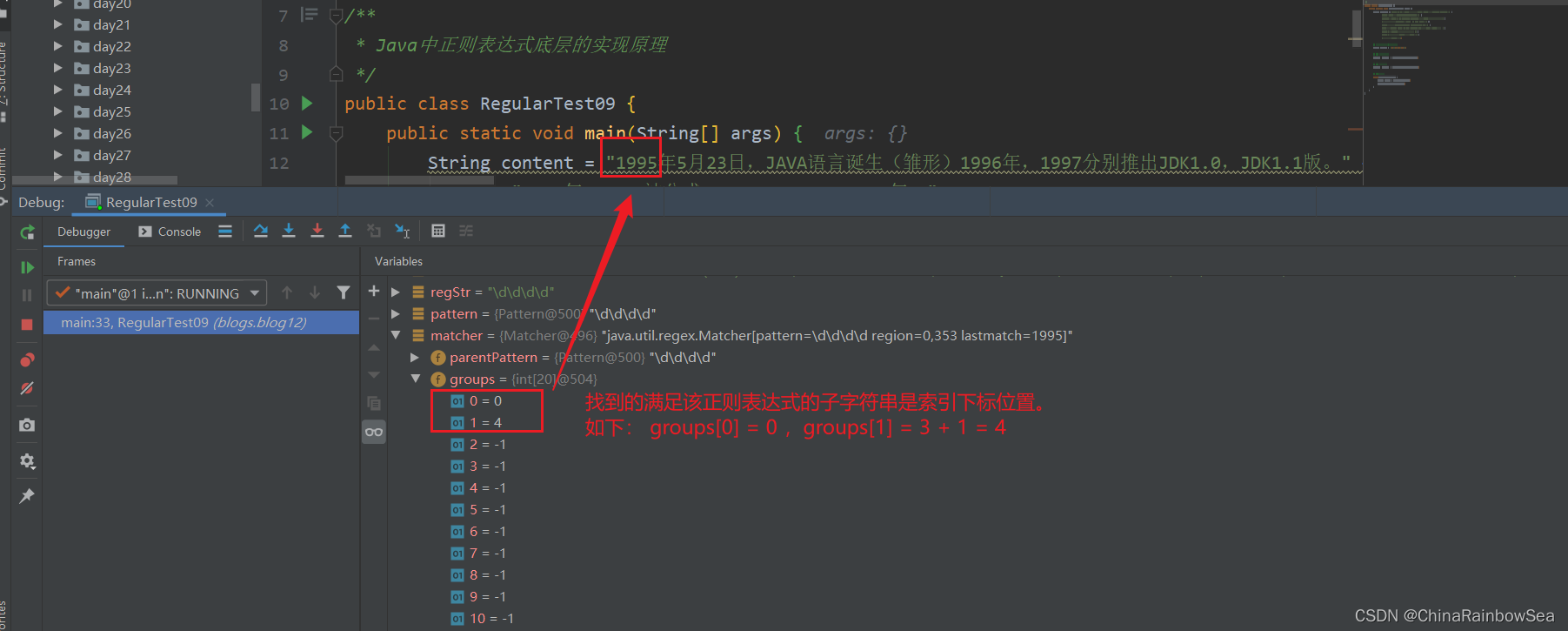
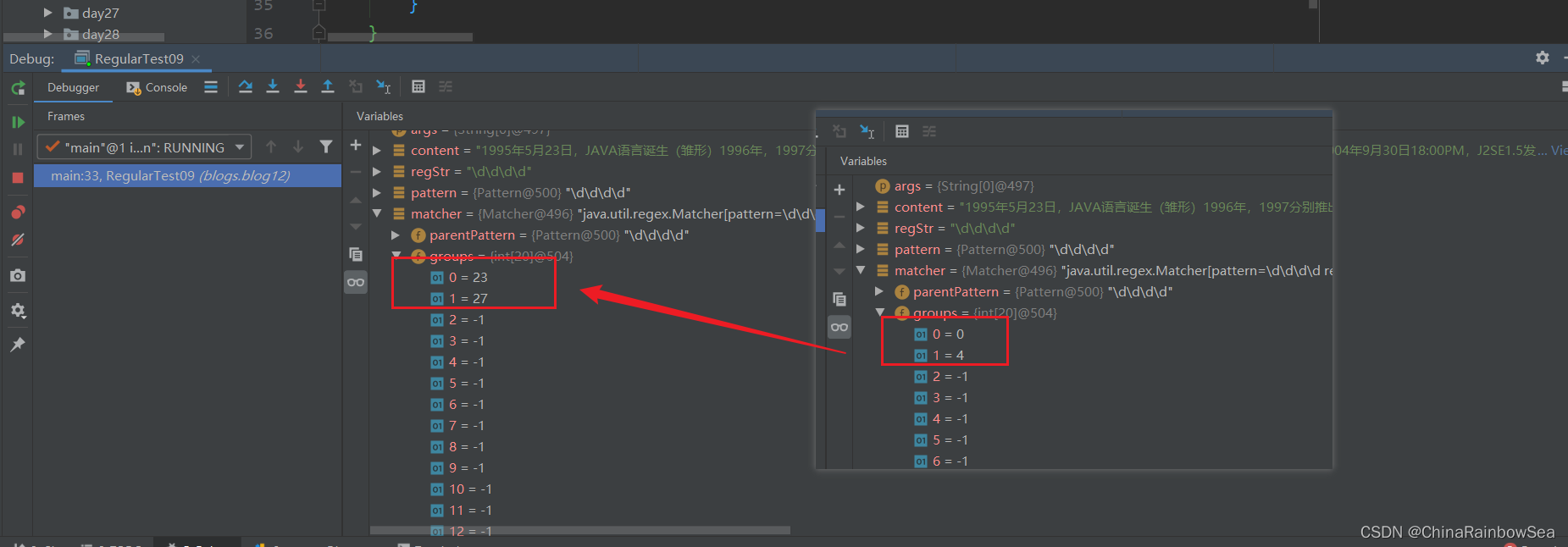
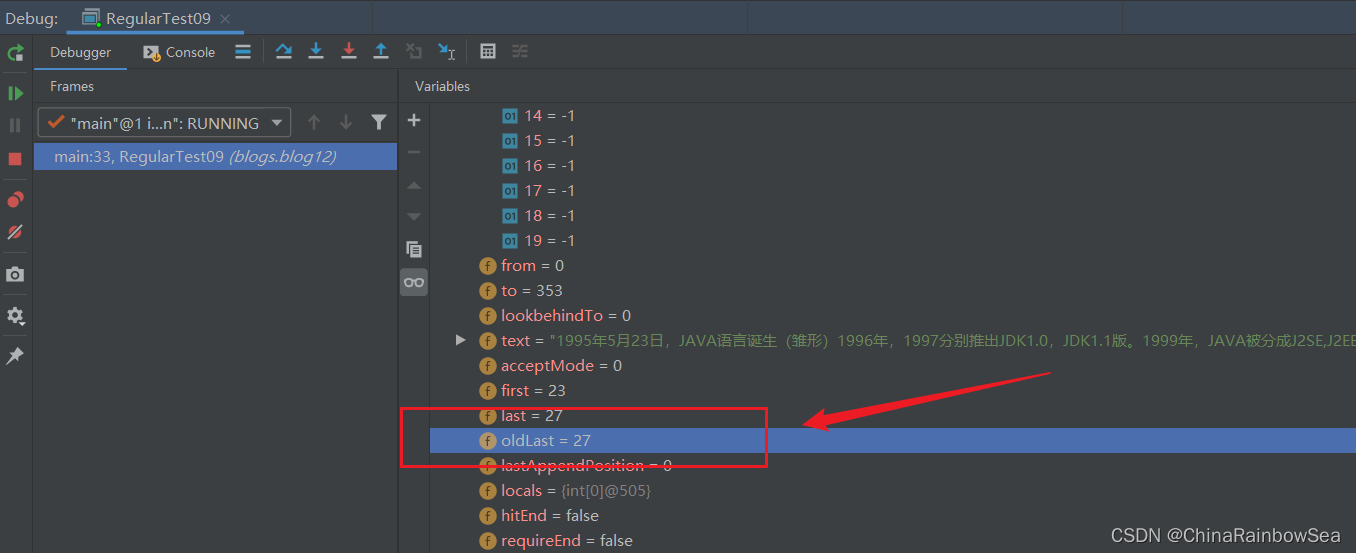
再次執行 find() 方法,從 oldLast 的值 開始匹配(這裡是 4 )。覆蓋第一個找到符合正規表示式的子字串索引的在 groups[0]和groups[1] 陣列當中的內容,這裡因為沒有分組所以對應的索引下標位置是僅僅只會儲存到 groups[0]和groups[1] 陣列下標位置。
- groups[0] = 23 值是:該匹配字串的開始下標位置
- groups[1] = 27 值是:把該子字串的「結束的索引」 + 1的值。這裡是 26 + 1 = 27。
- 同樣 其中的 odLast 的賦值為該子字串的結束索引下標 + 1 的值,這裡是 26 + 1 = 27 ,即下次執行 find() 方法時,就從 27 索引下標開始匹配了。
如下是我們 Debug 偵錯的結果
- ........ 如果再次執行 find() 方法,仍然是按照上面的方式找尋的。
Matcher 類中的 group()方法的原始碼分析:
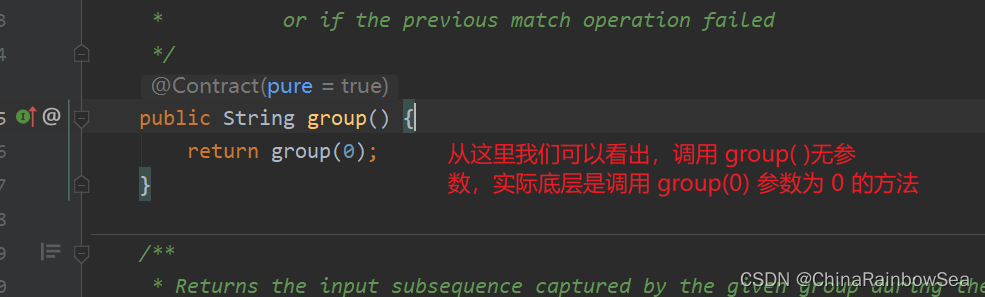
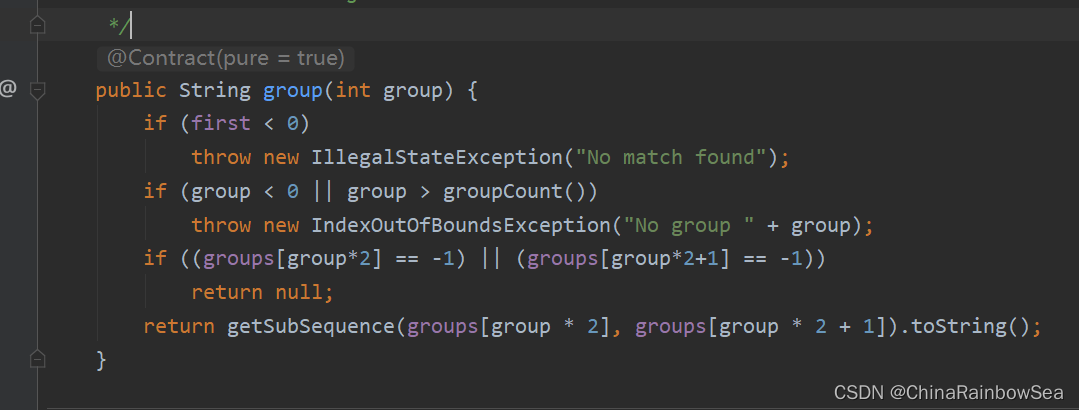
public String group(int group) {
if (first < 0)
throw new IllegalStateException("No match found");
if (group < 0 || group > groupCount())
throw new IndexOutOfBoundsException("No group " + group);
if ((groups[group*2] == -1) || (groups[group*2+1] == -1))
return null;
return getSubSequence(groups[group * 2], groups[group * 2 + 1]).toString();
}
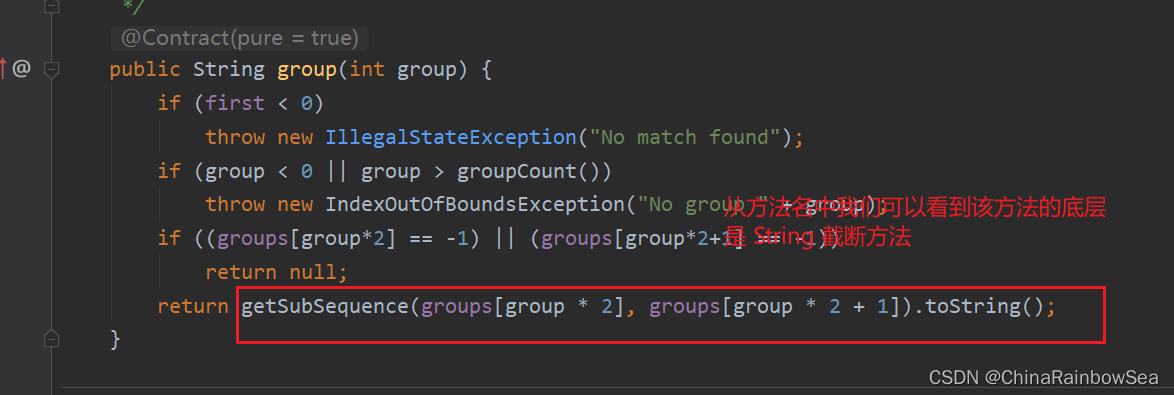
從原始碼上 傳入引數 0 走一下
5.2 正規表示式中含分組的原理分析
以如下程式碼分析:該程式碼的作用:將4個連續的數位字元,再分組為 2 個連續的數位字元
package blogs.blog12;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Java中正規表示式底層的實現原理
*/
public class RegularTest09 {
public static void main(String[] args) {
String content = "1995年5月23日,JAVA語言誕生(雛形)1996年,1997分別推出JDK1.0,JDK1.1版。" +
"1999年,JAVA被分成J2SE,J2EE,J2ME2000年," +
"JDK1.4釋出2004年9月30日18:00PM,J2SE1.5釋出,成為Java語言發展史上的又一里程碑。" +
"為了表示該版本的重要性,J2SE1.5更名為Java SE 5.0 2005年," +
"JAVA版本正式更名為JAVAEE,JAVASE, JAVAME2006年12月," +
"SUN公司釋出JRE6.0 2009年04月20日,Oracle以74億美元收購Sun。取得java的版權。 " +
"2010年9月,JDK7.0已經發布,增加了簡單閉包功能。 " +
"2011年7月,甲骨文公司釋出java7的正式版。2014年," +
"甲骨文公司釋出了Java8正式版";
// 這裡我編寫一個獲取連續4個數位的子字串
String regStr = "(\\d\\d)(\\d\\d)";
// 1. 建立正規表示式物件
Pattern pattern = Pattern.compile(regStr);
// 2. 建立匹配器物件
Matcher matcher = pattern.matcher(content);
// 3.迴圈遍歷匹配
while(matcher.find()) {
String group = matcher.group(0); // 獲取整體正規表示式內容
System.out.println(group);
String group1 = matcher.group(1); // 獲取在符合匹配整體正規表示式內容的基礎上,再的第1個分組(編號是從左往右)
System.out.println(group1);
String group2 = matcher.group(2);
System.out.println(group2); // 獲取在符合匹配整體正規表示式內容的基礎上,再的第2個分組(編號是從左往右)
}
}
}
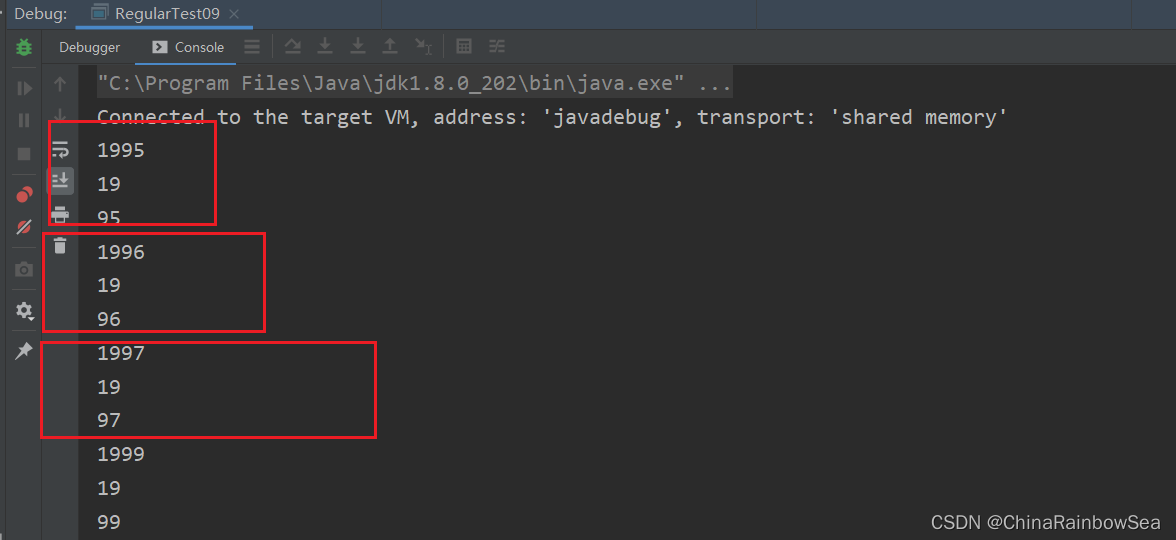
分析: 如下是我們 Debug 偵錯的結果
從結果上看,我們再進行分析:
正規表示式中含有的分組,其 matcher.find() 方法的執行流程和上面沒有進行分組的流程是一樣的。同樣的地方就不多贅述了。
這裡我們來說說不同的地方。
分組: 比如(\d\d)(\d\d)
正規表示式中有()表示分組,第1個()表示第1組,第2個表示第2組...(注意:編號分組是從左向右的圓括號開始的)
根據指定的規則,定位滿足正規表示式規則的子字串(比如 (19)(98))
注意是先從整體上匹配正規表示式,也就是沒有分組的時候: \d\d\d\d ,只有到整體都匹配了
才會再該整體的基礎上,再進行分組
找到後:將子字串的開始索引記錄到 matcher物件的屬性 int[] groups陣列當中
- groups[0] 記錄的是整體匹配正規表示式的子字串的起始位置;(1995) 0
- groups[1] 記錄的是整體匹配正規表示式的子字串的結束下標索引 +1 (1995) 3+1= 4
- groups[2] 記錄的是再整體匹配正規表示式的基礎上再分組的第1個分組的子字串的起始下標位置: (1995)(19) 0
- groups[3] 記錄的是再整體匹配正規表示式的基礎上再分組的第1個分組的子字串的結束下標位置 + 1:(1995)(19) 1+1=2
- groups[4] 記錄的是再整體匹配正規表示式的基礎上再分組的第2個分組的子字串的起始下標位置: (1995)(95) 2
- groups[3] 記錄的是再整體匹配正規表示式的基礎上再分組的第2個分組的子字串的結束下標位置 + 1:(1995)(95) 3+1=4
- 第3組,第4組 ...... 都還是以此類推 。
6. 正規表示式:分組,捕獲,反向參照
分組: 我們可以用圓括號 「()」 組成一個比較複雜的匹配模式,那麼一個圓括號的部分我們可以看作是一個子表示式/一個分組。
捕獲: 把正規表示式中子表示式/分組匹配的內容,儲存到記憶體中以數位編號/顯式命名的組裡。方便後面參照,從左向右,以分組的左括號為標誌,第一個出現的分組的組號為 1,第二個為 2,依次類推。組0 代表的是整個正規表示式。
反向參照: 圓括號的內容被捕獲後,可以在這個括號後被重複使用,從而寫出一個比較實用的匹配模式。這個我們稱為反向參照。這種參照即可以是在正規表示式內部使用,也可以在正則表示式的外部使用。內部反向參照使用 \\分組號,外部反向參照使用 $分組號。
反向參照與捕獲組匹配的輸入字串的部分儲存在記憶體中,以便以後通過反向參照進行呼叫。反向參照在正規表示式中指定為反斜槓(\), 後跟數位,表示要呼叫的組的編號。例如,表示式 (\d\d) 定義了一行匹配一行中的兩位數的捕獲組,後者可以通過反向參照在表示式中呼叫該捕獲組 \1。注意:因為Java中的 想要表示 \ 反斜槓,是用兩個 \\兩個反斜槓表示的。
反向參照 的主要作用就是:重複使用分組中的內容,因為分組中的內容是會儲存起來的,所以我們可以使用反向參照重複使用。
要匹配任何2位數,後跟完全相同的兩位數,您將使用 (\\d)\\1 正規表示式:
package blogs.blog12;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 反向參照:
*
*/
public class RegularTest10 {
public static void main(String[] args) {
String content = "hello jack14 tom11 jack222222 yyy 5225, 1551 xxx";
// 反向參照在正規表示式內部中使用的 \\ 反斜槓的格式。
String regStr = "(\\d)\\1"; // 11,22 兩個連續的數位 \\1反參照:表示重複使用第一個分組號中的內容
// 建立正則物件
Pattern pattern = Pattern.compile(regStr);
// 建立比較器物件
Matcher matcher = pattern.matcher(content);
while(matcher.find()) {
String group = matcher.group();
System.out.println(group);
}
}
}
舉例: 要匹配個位與千位相同,十位與百位相同的數: 5225, 1551 (\\d)(\\\d)\\2\\1
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 反向參照:
*
*/
public class RegularTest10 {
public static void main(String[] args) {
String content = "hello jack14 tom11 jack222222 yyy 5225, 1551 xxx";
// 反向參照在正規表示式內部中使用的 \\ 反斜槓的格式。
// 要匹配個位與千位相同,十位與百位相同的數: 5225, 1551 (\\d)(\\d)\\2\\1
String regStr = "(\\d)(\\d)\\2\\1"; // \\1反參照:表示重複使用第一個分組號中的內容
// \\2 反參照:表示重複使用第2個分組號中的內容
// 建立正則物件
Pattern pattern = Pattern.compile(regStr);
// 建立比較器物件
Matcher matcher = pattern.matcher(content);
while(matcher.find()) {
String group = matcher.group();
System.out.println(group);
}
}
}
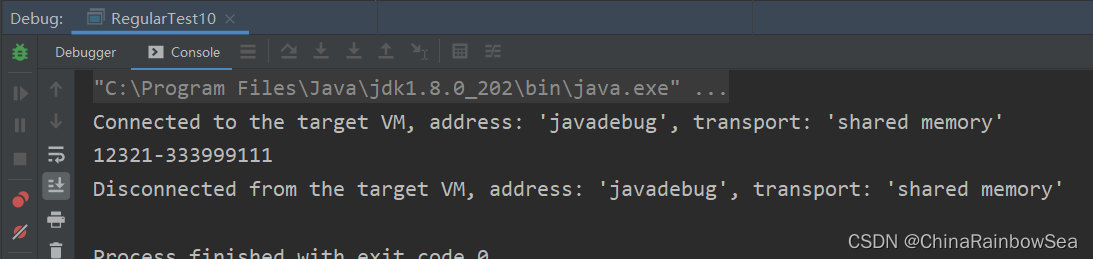
舉例: 請在字串中檢索商品編號,形式如: 12321-333999111 要求滿足前面是一個五位數,然後一個1號,然後是一個九位數,連續的每三位要相同。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 反向參照:
*/
public class RegularTest10 {
/**
* 請在字串中檢索商品編號,形式如: 12321-333999111
* 要求滿足前面是一個五位數,然後一個1號,然後是一個九位數,連續的每三位要相同。
*/
public static void main(String[] args) {
String content = " 12321-333999111";
String regStr = "\\d{5}-(\\d)\\1{2}(\\d)\\2{2}(\\d)\\3{2}";
// 建立正則物件
Pattern pattern = Pattern.compile(regStr);
// 建立比較器物件
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
String group = matcher.group();
System.out.println(group);
}
}
}
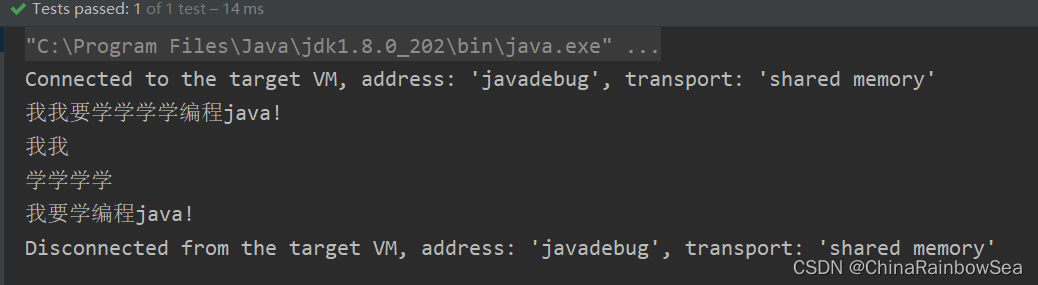
7. 正規表示式:案例練習講解
- 正規表示式:經典的結巴程式把類似:"我...我要...學學學學...程式設計java!";通過正規表示式 修改成 "我要學程式設計Java"
package blogs.blog12;
import org.junit.Test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest11 {
/**
* 正規表示式:經典的結巴程式
* 把類似:"我...我要...學學學學...程式設計java!";
* 通過正規表示式 修改成 "我要學程式設計Java"
*/
@Test
public void test() {
String content = "我...我要...學學學學...程式設計java!";
// 1.去掉所有的.
String regStr = "\\.";
// 正則物件
Pattern pattern = Pattern.compile(regStr);
// 匹配器物件
Matcher matcher = pattern.matcher(content);
// 1. 去掉所有的. 使用 matcher.replaceAll("") 替換為 空
content = matcher.replaceAll("");
// 2. 去重複的子,我我要學學學學程式設計Java
// 思路:
//(1)使用(.)\\1+ 找到重複的
//(2)使用 反向參照$1 來替換匹配到的內容: 因為是在正規表示式外部了,反向參照格式是 $
pattern = Pattern.compile("(.)\\1+");
matcher = pattern.matcher(content);
System.out.println(content);
// 迴圈
while(matcher.find()) {
String group = matcher.group(0);
System.out.println(group);
}
//(2)使用 反向參照$1 來替換匹配到的內容: 因為是在正規表示式外部了,反向參照格式是 $
content = matcher.replaceAll("$1"); //將 我我替換成 單個我,將學學學學替換成單個學
System.out.println(content);
}
}
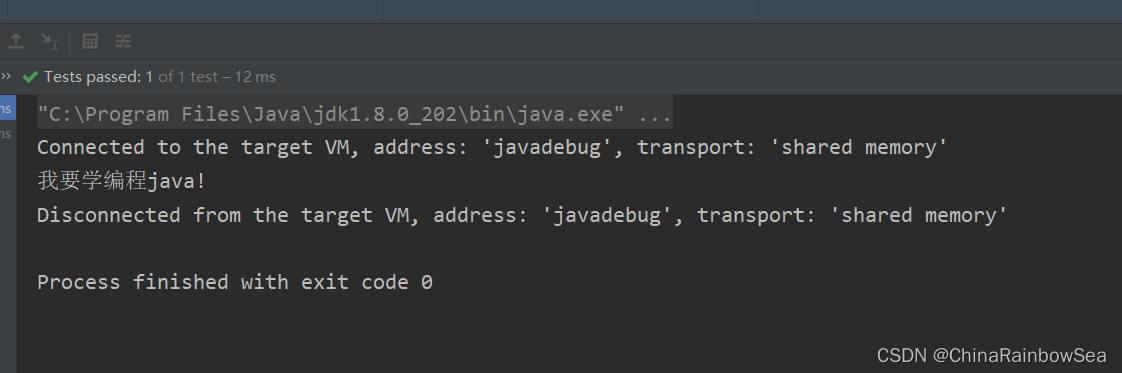
方式二:一條語句完成
import org.junit.Test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest11 {
/**
* 方式二
*/
// 方式2 一條語句完成:
@Test
public void test2() {
String content = "我...我要...學學學學...程式設計java!";
// 1.去除.
content = Pattern.compile("\\.+").matcher(content).replaceAll("");
content = Pattern.compile("(.)\\1+").matcher(content).replaceAll("$1");
System.out.println(content);
}
}
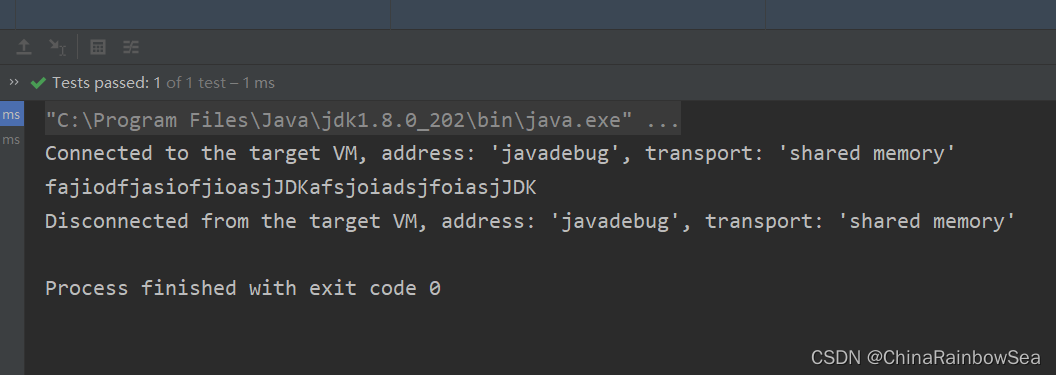
- 替換功能;String 類 public String replaceAll(String regex,String replacement),引數1是正規表示式,引數2是字串,將如下文字 JDK1.3 JDK1.4 統一替換成 JDK,fajiodfjasiofjioasjJDK1.3afsjoiadsjfoiasjJDK1.4。
import org.junit.Test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest11 {
/**
* 替換功能;
* String 類 public String replaceAll(String regex,String replacement)
* 引數1是正規表示式,引數2是字串
* 將如下文字 JDK1.3 JDK1.4 統一替換成 JDK
* fajiodfjasiofjioasjJDK1.3afsjoiadsjfoiasjJDK1.4
*/
@Test
public void test3() {
String content = "fajiodfjasiofjioasjJDK1.3afsjoiadsjfoiasjJDK1.4";
// 使用正規表示式,將JDK1.3和JDK1.4替換成JDK
String regStr = content.replaceAll("JDK1\\.3|JDK1\\.4", "JDK");
System.out.println(regStr);
}
}
- 要求: 驗證一個手機號,要求必須是以138 139 開頭的,使用 String 類 public boolean matchers(String regex) {} 方法。
import org.junit.Test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest11 {
/**
* 要求: 驗證一個手機號,要求必須是以138 139 開頭的
* 使用 String 類 public boolean matchers(String regex) {} 方法
*/
@Test
public void test4() {
String content = "13812312123";
boolean matches = content.matches("(138|139)\\d{8}");
System.out.println(matches);
}
}
- 使用 String 類 public String[] split(String regex),將 "hello#abc-jack12smith~北京’,要求按照 # 或者 -或者 ~ 或者數位來分割
import org.junit.Test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest11 {
/**
* 使用 String 類 public String[] split(String regex)
* 將 "hello#abc-jack12smith~北京’
* 要求按照 # 或者 -或者 ~ 或者數位來分割
*/
@Test
public void test5() {
String content = "hello#abc-jack12smith~北京";
String[] split = content.split("#|-|~|\\d+");
for (String regStr : split) {
System.out.println(regStr);
}
}
}
- 驗證電子郵件格式是否合法規定電子郵件規則為:
- 只能有一個@
- @前面是使用者名稱,可以是a-z,A-Z,0-9 _字元
- @後面是域名,並且域名只能是英文字母,比如: sohu.com 或者 tsinghua.org.cn
- 寫出對應的正規表示式,驗證輸入的字串是否為滿足規則。
import org.junit.Test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest11 {
/**
* 驗證電子郵件格式是否合法
* 規定電子郵件規則為:
* 1. 只能有一個@
* 2. @前面是使用者名稱,可以是a-z,A-Z,0-9 _字元
* 3. @後面是域名,並且域名只能是英文字母,比如: sohu.com 或者 tsinghua.org.cn
* 4.寫出對應的正規表示式,驗證輸入的字串是否為滿足規則。
*/
@Test
public void test6() {
String content = "[email protected]";
String regStr = "[\\w-]+@([a-zA-Z]+\\.)+[a-zA-Z]+";
boolean matches = content.matches(regStr);
System.out.println(matches);
}
}
- 要求:驗證是不是整數或者小數這個題目要考慮正數和負數: 123 -345 34.89 -87.9 -0.01 0.45
import org.junit.Test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest11 {
/**
* 要求:驗證是不是整數或者小數
* 這個題目要考慮正數和負數
* 123 -345 34.89 -87.9 -0.01 0.45
*/
@Test
public void test7() {
//String content = "123 -345 34.89 -87.9 -0.01 0.45";
String content = "0.56";
// 思路先寫簡單的正規表示式
// 在逐步完善
//String regStr = "^\\d+$"; // 判斷數值
//String regStr = "^[-+]?\\d+(\\.\\d+)?$"; // 包含正負和小數
// 處理特殊情況 000123.45
String regStr = "^[-+]?([1-9]\\d*|0)(\\.\\d+)?$"; // 包含正負和小數
boolean matches = content.matches(regStr);
System.out.println(matches);
}
}
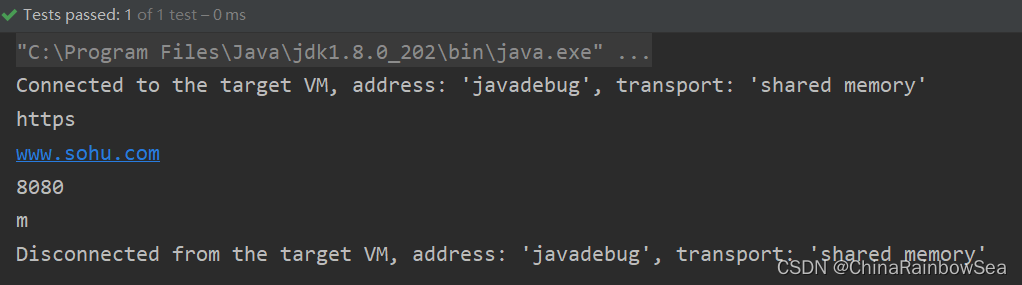
- 對 url 進行解析:https://www.sohu.com:8080/abc/index.htm
獲取協定 https
獲取域名: www.sohu.com
埠: 8080
檔名: index.htm
import org.junit.Test;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegularTest11 {
/**
* 對 url 進行解析:
* https://www.sohu.com:8080/abc/index.htm
* 獲取協定 https
* 獲取域名: www.sohu.com
* 埠: 8080
* 檔名: index.htm
*/
@Test
public void test8() {
String content = "https://www.sohu.com:8080/abc/index.htm";
String regStr = "^([a-zA-Z]+)://([a-zA-z.]+):(\\d+)[\\w-/]*/([\\w.])+$";
//String regStr = "^([a-zA-Z]+)://([a-zA-z.]+):(\\d+)[\\w-/]*/([\\w.%¥#(特殊符號)])+$"; 不夠的時候還可以加
// 正則物件
Pattern pattern = Pattern.compile(regStr);
// 匹配器
Matcher matcher = pattern.matcher(content);
if(matcher.matches()) { // 整體匹配,成功獲取資訊
String group = matcher.group(1);
System.out.println(group);
String group2 = matcher.group(2);
System.out.println(group2);
String group3 = matcher.group(3);
System.out.println(group3);
String group4 = matcher.group(4);
System.out.println(group4);
} else {
System.out.println("匹配失敗");
}
}
}
8. 正規表示式:優化建議
8.1 儘量準確表示匹配範圍
比如我們要匹配引號裡面的內容,除了寫成 ".+?" 之外,我們可以寫成 "[^"]+"。使用 [^"] 要比使用點號好很多,雖然使用的是貪婪模式,但它不會出現點號將引號匹配上,再吐出的問題。
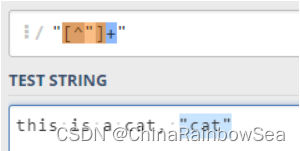
上面 的區別如下:
".+":如果使用貪婪模式,那麼將會導致第一遍,將最後一個引號"吃掉,再回溯(吐出來)匹配正則裡面的最後一個引號".+?":使用了非貪婪模式,不會導致發生回溯"[^"]+":貪婪模式,引號開頭結尾,中間用中括號選用非引號的字元出現 1 到多次,也不會發生回溯
8.2 提取出公共部分
通過上面對 NFA 引擎的學習,相信你應該明白 (abcd|abxy) 這樣的表示式,可以優化成 ab(cd|xy),因為 NFA 以正則為主導,會導致字串中的某些部分重複匹配多次,影響效率。
因此我們會知道 th(?:is|at) 要比 this|that 要快一些,但從可讀性上看,後者要好一些,這個就需要用的時候去權衡,也可以新增程式碼註釋讓程式碼更容易理解。
類似地,如果是錨點,比如 (^this|^that) is 這樣的,錨點部分也應該獨立出來,可以寫成比如 ^th(is|at) is 的形式,因為錨點部分也是需要嘗試去匹配的,匹配次數要儘可能少。
8.3 出現可能性大的放左邊
由於正則是從左到右看的,把出現概率大的放左邊,域名中 .com 的使用是比 .net 多的,所以我們可以寫成. (?:com|net)\b ,而不是 \.(?:net|com)\b。
8.4 只在必要時才使用子組
在正則中,括號可以用於歸組,但如果某部分後續不會再用到,就不需要儲存成子組。通常的做法是,在寫好正則後,把不需要儲存子組的括號中加上 ?: 來表示只用于歸組。如果儲存成子組,正則引擎必須做一些額外工作來儲存匹配到的內容,因為後面可能會用到,這會降低正則的匹配效能。
8.5 警惕巢狀的子組重複
如果一個組裡麵包含重複,接著這個組整體也可以重複,比如 (.*)* 這個正則,匹配的次數會呈指數級增長,所以儘量不要寫這樣的正則。
8.6 避免不同分支重複匹配
在多選分支選擇中,要避免不同分支出現相同範圍的情況
9. 資料:常用的正規表示式格式
一、校驗數位的表示式
1 數位:^[0-9]*$
2 n位的數位:^\d{n}$
3 至少n位的數位:^\d{n,}$
4 m-n位的數位:^\d{m,n}$
5 零和非零開頭的數位:^(0|[1-9][0-9]*)$
6 非零開頭的最多帶兩位小數的數位:^([1-9][0-9]*)+(.[0-9]{1,2})?$
7 帶1-2位小數的正數或負數:^(\-)?\d+(\.\d{1,2})?$
8 正數、負數、和小數:^(\-|\+)?\d+(\.\d+)?$
9 有兩位小數的正實數:^[0-9]+(.[0-9]{2})?$
10 有1~3位小數的正實數:^[0-9]+(.[0-9]{1,3})?$
11 非零的正整數:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
12 非零的負整數:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
13 非負整數:^\d+$ 或 ^[1-9]\d*|0$
14 非正整數:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
15 非負浮點數:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
16 非正浮點數:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
17 正浮點數:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
18 負浮點數:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
19 浮點數:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
二、校驗字元的表示式
1 漢字:^[\u4e00-\u9fa5]{0,}$
2 英文和數位:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
3 長度為3-20的所有字元:^.{3,20}$
4 由26個英文字母組成的字串:^[A-Za-z]+$
5 由26個大寫英文字母組成的字串:^[A-Z]+$
6 由26個小寫英文字母組成的字串:^[a-z]+$
7 由數位和26個英文字母組成的字串:^[A-Za-z0-9]+$
8 由數位、26個英文字母或者下劃線組成的字串:^\w+$ 或 ^\w{3,20}$
9 中文、英文、數位包括下劃線:^[\u4E00-\u9FA5A-Za-z0-9_]+$
10 中文、英文、數位但不包括下劃線等符號:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
11 可以輸入含有^%&',;=?$\"等字元:[^%&',;=?$\x22]+
12 禁止輸入含有~的字元:[^~\x22]+
三、特殊需求表示式
1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
3 InternetURL:[a-zA-z]+://[^\s]* 或 ^https://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
4 手機號碼:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
5 電話號碼("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
6 國內電話號碼(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
7 身份證號:
15或18位元身份證:^\d{15}|\d{18}$
15位身份證:^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$
18位元身份證:^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{4}$
8 短身份證號碼(數位、字母x結尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$
9 帳號是否合法(字母開頭,允許5-16位元組,允許字母數位下劃線):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
10 密碼(以字母開頭,長度在6~18之間,只能包含字母、數位和下劃線):^[a-zA-Z]\w{5,17}$
11 強密碼(必須包含大小寫字母和數位的組合,不能使用特殊字元,長度在8-10之間):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
12 日期格式:^\d{4}-\d{1,2}-\d{1,2}
13 一年的12個月(01~09和1~12):^(0?[1-9]|1[0-2])$
14 一個月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
15 錢的輸入格式:
16 1.有四種錢的表示形式我們可以接受:"10000.00" 和 "10,000.00", 和沒有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
17 2.這表示任意一個不以0開頭的數位,但是,這也意味著一個字元"0"不通過,所以我們採用下面的形式:^(0|[1-9][0-9]*)$
18 3.一個0或者一個不以0開頭的數位.我們還可以允許開頭有一個負號:^(0|-?[1-9][0-9]*)$
19 4.這表示一個0或者一個可能為負的開頭不為0的數位.讓使用者以0開頭好了.把負號的也去掉,因為錢總不能是負的吧.下面我們要加的是說明可能的小數部分:^[0-9]+(.[0-9]+)?$
20 5.必須說明的是,小數點後面至少應該有1位數,所以"10."是不通過的,但是 "10" 和 "10.2" 是通過的:^[0-9]+(.[0-9]{2})?$
21 6.這樣我們規定小數點後面必須有兩位,如果你認為太苛刻了,可以這樣:^[0-9]+(.[0-9]{1,2})?$
22 7.這樣就允許使用者只寫一位小數.下面我們該考慮數位中的逗號了,我們可以這樣:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
23 8.1到3個數位,後面跟著任意個 逗號+3個數位,逗號成為可選,而不是必須:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
24 備註:這就是最終結果了,別忘了"+"可以用"*"替代如果你覺得空字串也可以接受的話(奇怪,為什麼?)最後,別忘了在用函數時去掉去掉那個反斜槓,一般的錯誤都在這裡
25 xml檔案:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
26 中文字元的正規表示式:[\u4e00-\u9fa5]
27 雙位元組字元:[^\x00-\xff] (包括漢字在內,可以用來計算字串的長度(一個雙位元組字元長度計2,ASCII字元計1))
28 空白行的正規表示式:\n\s*\r (可以用來刪除空白行)
29 HTML標記的正規表示式:<(\S*?)[^>]*>.*?|<.*? /> (網上流傳的版本太糟糕,上面這個也僅僅能部分,對於複雜的巢狀標記依舊無能為力)
30 首尾空白字元的正規表示式:^\s*|\s*$或(^\s*)|(\s*$) (可以用來刪除行首行尾的空白字元(包括空格、製表符、換頁符等等),非常有用的表示式)
31 騰訊QQ號:[1-9][0-9]{4,} (騰訊QQ號從10000開始)
32 中國郵政編碼:[1-9]\d{5}(?!\d) (中國郵政編碼為6位數位)
33 IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址時有用)
10. 總結
- 正規表示式中預設是一個
\斜杆的,不過在Java中一個斜杆 需要兩個\\才能表示。 - 正規表示式預設是區分大小寫的,可以設定不區分大小寫的
- 正規表示式中預設是貪婪匹配:預設是匹配最多的可能結果。可以設定為非貪婪匹配
- 正規表示式中的分組/命名分組,預設分組編號是從左邊第一個圓括號開始計數的,預設的 group[0] 是正規表示式整體,注意不要越界存取了。
- Java中執行正規表示式的原理流程。
- 反向參照的使用的格式:正規表示式內部
\\分組號,正規表示式外部使用格式是 :$分組號。
11. 最後: