推薦系統[八]演演算法實踐總結V2:排序學習框架(特徵提取標籤獲取方式)以及京東推薦演演算法精排技術實戰
0.前言
「排序學習(Learning to Rank,LTR)」,也稱「機器排序學習(Machine-learned Ranking,MLR)」 ,就是使用機器學習的技術解決排序問題。自從機器學習的思想逐步滲透到資訊檢索等領域之後,如何利用機器學習來提升資訊檢索的效能水平變成了近些年來非常熱門的研究話題,因此產生了各類基於機器學習的排序演演算法,也帶來了搜尋引擎技術的成熟和發展,如今,Learning to Rank已經成為搜尋、推薦和廣告領域非常重要的技術手段。
本文我們首先介紹排序學習的三種主要類別,然後詳細介紹推薦領域最常用的兩種高層排序學習演演算法框架:BPR和LambdaMART。因為排序學習的演演算法和實踐大都來源於資訊檢索,一些理論也必須從資訊檢索的領域說起,所以本文也會涉及一些的資訊檢索、搜尋方面的理論知識,但重點依然會放在推薦領域排序學習的應用思路。
0.1 排序學習
傳統的排序方法可粗略分為基於相似度和基於重要性進行排序兩大類,早期基於相關度的模型,通常利用 query 和 doc 之間的詞共現特性(如布林模型)、VSM(如 TF-IDF、LSI)、概率排序思想(如BM25、LMIR)等方式。基於重要性的模型,利用的是 doc 本身的重要性,如 PageRank、TrustRank 等。在之前《基於內容的推薦演演算法》和《文字內容分析演演算法》兩篇文章中,稍有涉及其中的知識點。
傳統的檢索模型所考慮的因素並不多,主要是利用詞頻、逆檔案頻率和檔案長度、檔案重要度這幾個因子來人工擬合排序公式,且其中大多數模型都包含引數,也就需要通過不斷的實驗確定最佳的引數組合,以此來形成相關性打分。這種方式非常簡單高效,但是也同時存在很多問題
- 很難融合多種資訊
- 手動調參工作量太大,如果模型引數很多,手動調參的可用性非常低
- 可能會過擬合
LTR則是基於特徵,通過機器學習演演算法訓練來學習到最佳的擬合公式,相比傳統的排序方法,優勢有很多:
- 可以根據反饋自動學習並調整引數
- 可以融合多方面的排序影響因素
- 避免過擬合(通過正則項)
- 實現個性化需求(推薦)
- 多種召回策略的融合排序推薦(推薦)
- 多目標學習(推薦)
1.排序學習框架
排序學習是一個典型的有監督機器學習過程,我們分別簡單來看一下排序學習在搜尋以及推薦領域中的框架和基本流程。
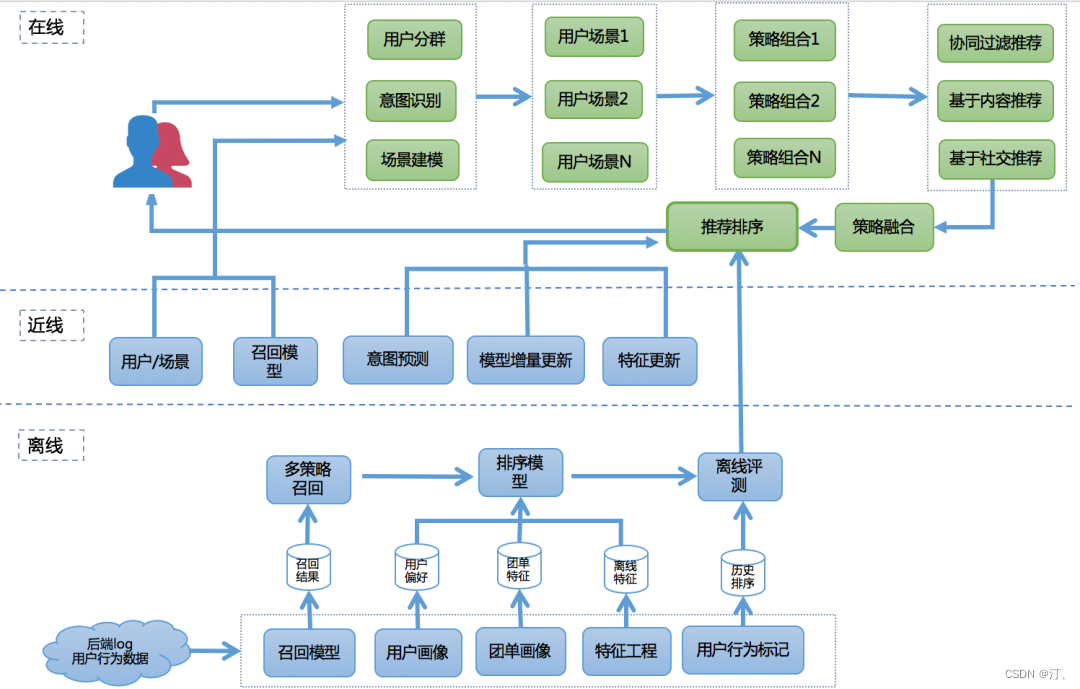
1.1 基本流程
在資訊檢索中,對每一個給定的查詢-檔案對,抽取特徵,通過紀錄檔挖掘或者人工標註的方法獲得真實資料標註。然後通過排序模型,使得輸入能夠和實際的資料相似。
排序學習在現代推薦架構中處於非常關鍵的環節,它可以完成不同召回策略的統一排序,也可將離線、近線、線上的推薦結果根據根據使用者所處的場景進行整合和實時調整,完成打分重排並推薦給使用者。
無論是搜尋還是推薦,排序學習模型的特徵提取以及訓練資料的獲取是非常重要的兩個過程,與常見的機器學習任務相比,也有很多特殊的地方,下面我們簡單介紹這兩個過程中可能需要考慮的問題。
1.2 特徵提取
在排序學習模型中,檔案都是轉化成特徵向量來表徵的,這便涉及一系列文字特徵提取的工作,我們這裡簡單介紹一些可能用到的特徵提取方法以及常用的特徵型別。
檔案的特徵通常可以從傳統排序模型獲得一些相關特徵或者相關度打分值,所以可分為兩種型別:
- 一是檔案本身的特徵,比如Pagerank值、內容豐富度、spam值、number of slash、url length、inlink number、outlink number、siterank,使用者停留時間、CTR、二跳率等。
- 二是Query-Doc的特徵:檔案對應查詢的相關度、每個域的tf、idf值,bool model,vsm,bm25,language model相關度等。
也可以對檔案分域,如對於一個網頁文字,特徵所在的檔案區域可以包括body域,anchor域,title域,url域,whole document域等。
通過各個域和各種特徵,我們可以組合出很多特徵,當然有些特徵是正相關有些是負相關,這需要我們通過學習過程去選取優化。
1.3 標籤獲取
特徵可以通過各種方式進行提取,但是Label的獲取就不是那麼容易了。目前主要的方式是人工標註或者紀錄檔提取,需注意的是,標註的型別與演演算法選擇以及損失函數都有很大關係。
1.3.1「人工標註」
人工標註比較靈活,但是若需要大量的訓練資料,人工標註就不太現實了,人工標註主要有以下幾種標註型別:
- 「單點標註」單點標註只關注單點,不考慮相互聯絡,單點標註又分三種不同的標註方式:優缺點 優點:標註的量少,為O(n) 缺點:難標,不好統一
- 對於每個查詢檔案直接打上絕對標籤,即相關度得分
- 二元標註相關和不相關
- 五級標註按照相關度劃分五級(同NDCG指標):即「最相關」、「相關」、「中性」、「不相關」、最不相關」,通常在模型訓練時會用數位來表示,如1~5
- 「兩兩標註」優缺點 優點:標註起來比較方便 缺點:標註量大,應該有
- 對於一個查詢Query,標註檔案d1比檔案d2是否更加相關,即
- 「列表標註」優缺點 優點:相對於上面兩種,標註的效果會很好 缺點:工作量巨大,人工幾乎無法完成(整體的檔案數量太大)
- 對於一個查詢Query,將人工理想的排序全部標好
1.3.2「紀錄檔抽取」
當搜尋引擎搭建起來之後,就可以通過使用者點選記錄來獲取訓練資料。對應查詢返回的搜尋結果,使用者會點選其中的某些網頁,我們可以假設使用者優先點選的是和查詢更相關的網頁,儘管很多時候這種假設並不成立,但實際經驗表明這種獲取訓練資料的方法是可行的。
比如,搜尋結果A、B、C分別位於第1、2、3位,B比A位置低,但卻得到了更多的點選,那麼B的相關性可能好於A。「這種點選資料隱含了Query到檔案的相關性好壞。所以一般會使用點選倒置的高低位結果作為訓練資料」。
但是紀錄檔抽取也存在問題:
- 使用者總是習慣於從上到下瀏覽搜尋結果
- 使用者點選有比較大的噪聲
- 一般頭查詢(head query)才存在使用者點選
1.4排序學習設計方法
排序學習的模型通常分為「單點法(Pointwise Approach)」、配對法(Pairwise Approach)「和」列表法(Listwise Approach)三大類,三種方法並不是特定的演演算法,而是排序學習模型的設計思路,主要區別體現在損失函數(Loss Function)、以及相應的標籤標註方式和優化方法的不同。
三種方法從ML角度的總覽:
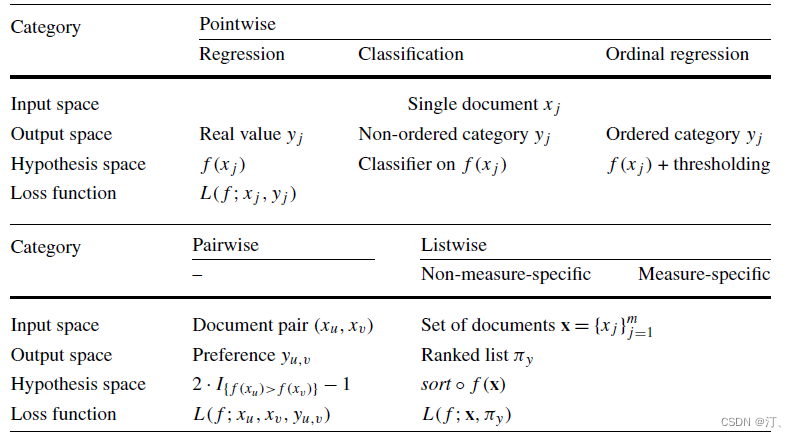
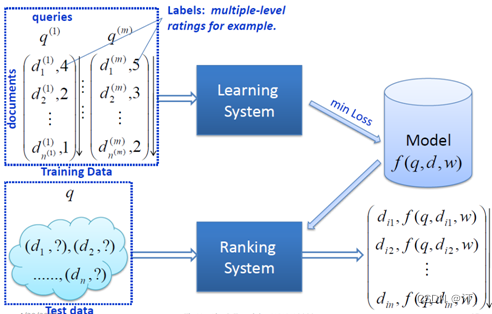
更多內容參考:推薦系統四:精排-詳解排序演演算法LTR (Learning to Rank): poitwise, pairwise, listwise相關評價指標,超詳細知識指南。
2.京東推薦演演算法精排技術實踐
前言:京東主站推薦的主要業務場景覆蓋APP中使用者購買前、購買中和購買後的全流程,日均千萬級DAU。不同業務場景下使用者需求不同,我們相應的優化目標也不同。首頁feeds和「我的京東」就是典型的購買前的場景,我們主要去優化點選以及瀏覽深度;購物車和商品詳情頁是購買中的場景,主要優化點選率以及轉化率;而訂單頁就是使用者購買後的主要場景,會重點優化跨品點選和轉化。
2.1 業務&場景

召回主要是包括主流的i2i和u2i召回,它的排序是數十億到萬的量級;粗排採用雙塔模型,主要兼顧精準性和系統延時,排序量是從萬到千的量級;在精排階段,我們會使用更復雜的特徵和模型結構,保證結果的精準性,它的排序量級是從千到百;重排模組則更多從整個序列的角度考慮問題,同時兼顧多樣性、新穎性,量級是從百到十
精排模組的挑戰主要有三個:
- 多目標:推薦系統通常有多個業務目標需要同時優化,包括點選率、轉化率、GMV、瀏覽深度和品類豐富度等。
- 使用者表達:使用者的偏好是多樣性的,精準表徵使用者當前的意圖是比較有挑戰的。
- 商品表達:商品資訊包括品牌、品類等屬性,也包括使用者行為的反饋資訊,還有商品的主圖和標題等。如何利用不同模態的資料也是目前比熱門的問題。
我們採用了多目標學習、使用者行為序列建模和多模態特徵等業界主流方法來優化這三個問題,並針對電商推薦的特性進行了一定改進和創新。
2.2 多目標優化
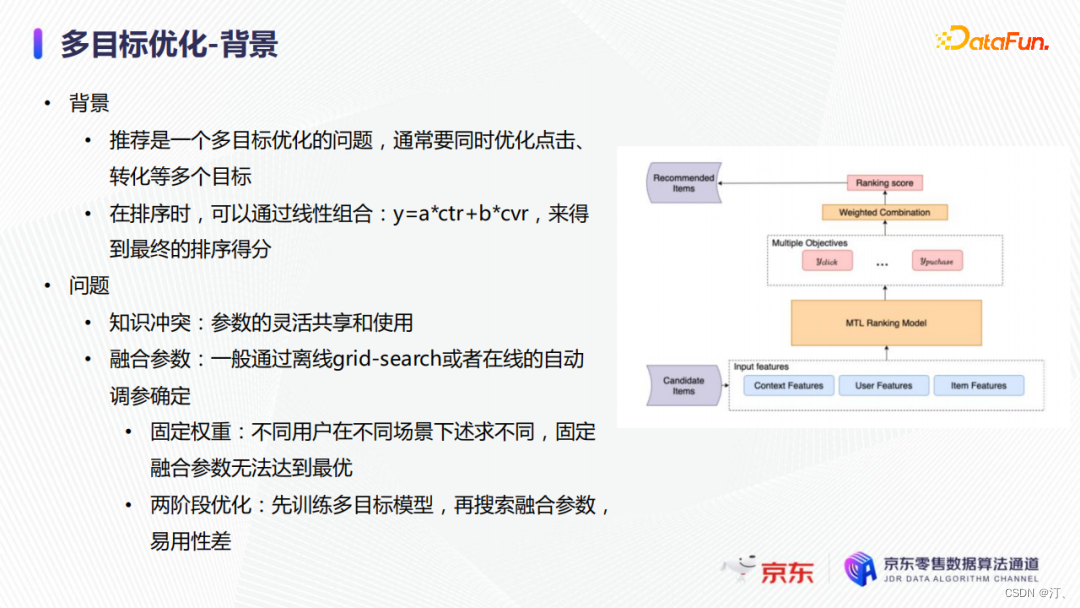
推薦是一個多目標優化問題,實際上線上上我們有大約七到八個目標需要優化。為了簡化呈現,這裡就以點選和轉化為例。上圖右側是傳統的多目標優化模型。最底層是模型的輸入特徵,中間是多目標模型,之後連線了一個combination層將不同的目標預測值結合到一起,最後使用其進行排序。
推薦領域多目標學習的主要問題有:
- 知識衝突,效果較好的MMoE/PLE等模型,主要通過更靈活的引數共用機制,為不同學習目標提供可選的稀疏結構來緩解知識衝突;
- 融合引數的優化,融合引數主要是用來組合不同目標的輸出用於排序,常用做法是通過離線grid search或者線上自動調參來搜尋一組固定引數。
在多目標融合排序上,我們認為固定引數有一定的問題。使用者在不同場景有不同的訴求,如有明確的購物意圖或者僅僅是閒逛,固定的融合引數就無法使模型整體效果達到最優。因此我們提出了一個個性化多目標融合的方法,可以根據使用者狀態自動輸出不同目標的融合權重。
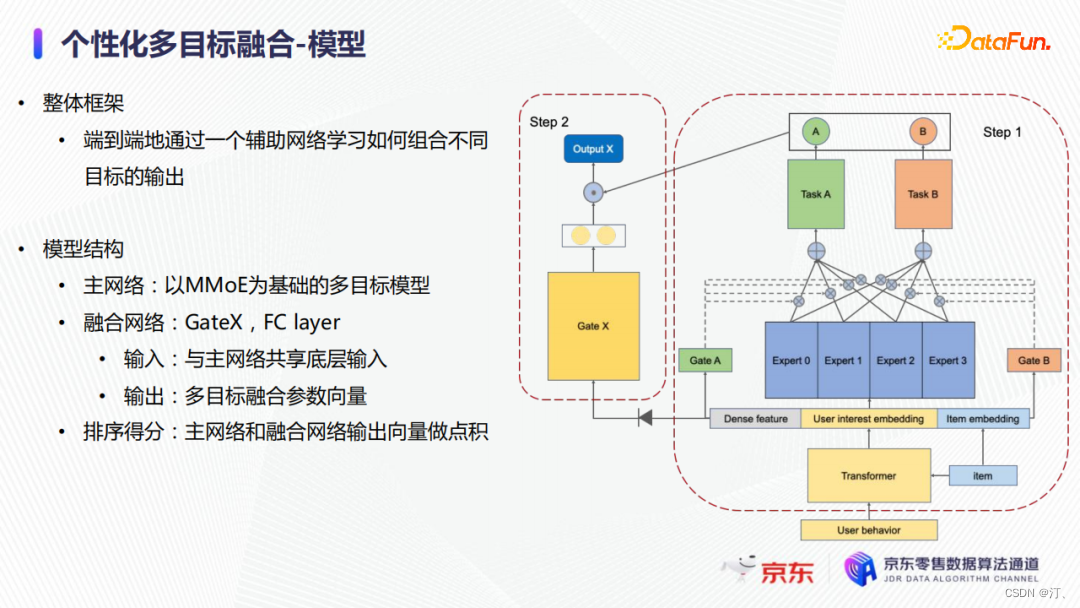
上圖右側是我們整體的模型架構,主網路是一個傳統的MMoE結構;我們額外加入了一個融合網路,通過一個Gate結構學習如何組合不同目標。融合網路的輸入是與主網路相同的底層特徵,輸出的是多目標融合引數向量,其最終會與主網路不同目標的預測值進行點積,作為最終的排序值。

融合網路的損失函數與主網路類似,主網路主要通過優化不同學習目標的引數來優化整體損失函數,而融合網路主要學習如何組合不同目標來使得模型在整體損失方向上達到最優。在模型訓練上,我們採用了交替訓練的方法。每10個batch訓練一次融合網路,而每個batch都會去訓練主網路。除此之外,我們還採用了梯度阻斷的技術,融合網路的梯度不反傳回底層的使用者行為序列建模和embedding layer,從而保證主網路的訓練不受融合網路訓練的影響。

通過加入融合網路的方法,我們希望模型在使用者有明確的購物慾望的時候,模型可以給轉化的輸出更多的權重,而當用戶沒有明確的購物慾望的時候,模型可以給點選更大的權重。為了驗證這個問題,我們進行了多組實驗。
- 首先通過分析融合網路的均值和標準差,我們發現模型端到端學習出的權重值與我們離線通過引數搜尋得到的最優值比較接近,結果較為合理;
- 此外融合網路的輸出具有樣本級別差異,到達了個性化效果。然後我們對比了閒逛和購買場景的輸出差異,在點選session下,點選融合權重平均是0.92,訂單session中對應的權重下降為0.89;
- 而在訂單session中,訂單的融合權重對比點選session會有比較大的提升。最終線上的效果也證明了模型可以精準識別使用者屬於偏買還是偏逛的型別,轉化率有了大幅提升。
- 除了首頁之外,我們還將該方法應用到直播和購物車等不同排序模型上,其轉化率都得到了明顯提升,證明了方法的有效性和通用性。
2.3 使用者行為序列建模
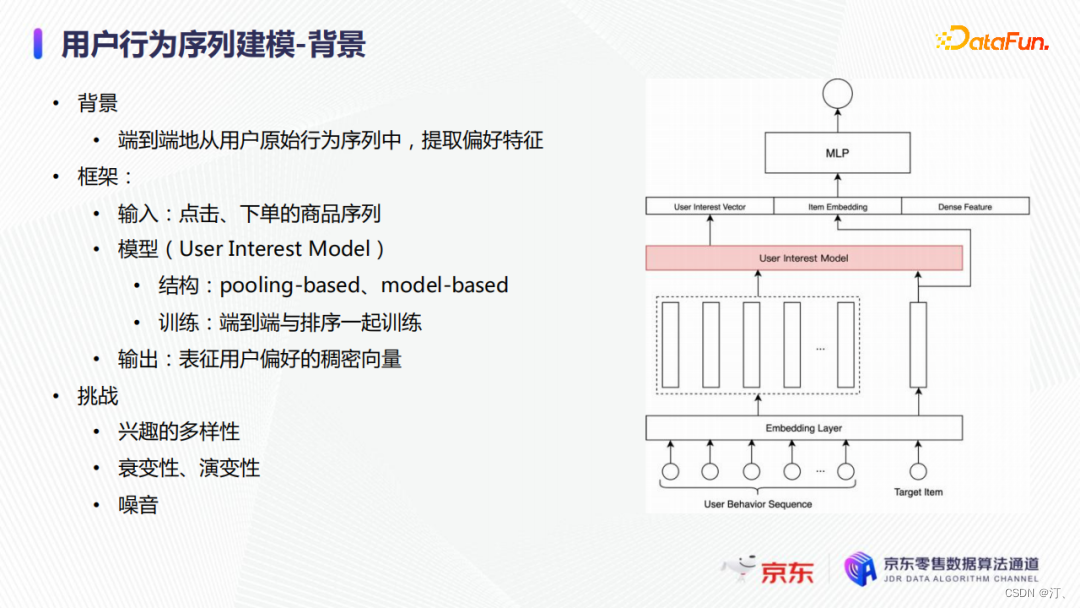
接下來介紹使用者行為序列建模的工作。整個使用者行為序列建模的目的是想從使用者的原始行為序列中學習使用者的偏好,這是個性化推薦中最重要的一個技術分支。它的整體技術框架如上圖所示,模型的輸入是使用者原始點選或者下單行為的序列,之後通過一個User Interest 模型來輸出表徵用戶偏好的稠密向量。User Interest模型可以是pooling-based也可以是model-based,一般與排序任務一起端到端訓練。
使用者行為序列建模的挑戰主要由以下幾點:
- 使用者的行為以及興趣是多種多樣的,我們需要從使用者的原始行為序列中將不同的興趣提取出來;
- 使用者的行為是隨著時間不斷變化的,比如在一個月前使用者感興趣的商品現在就失去興趣了,即具有衰變性和演變性;
- 資料具有噪音,因為不像NLP領域,文字的排列會受基本語法的約束,使用者的行為本身並沒有約束,導致序列中可能會包含噪音行為,即沒有特別關聯性的行為。比如昨天我還在瀏覽手機這一品類,今天我突然就去瀏覽水果。
- 模型應用線上上服務時存在比較明顯的效能問題,我們需要優化預測的時延。
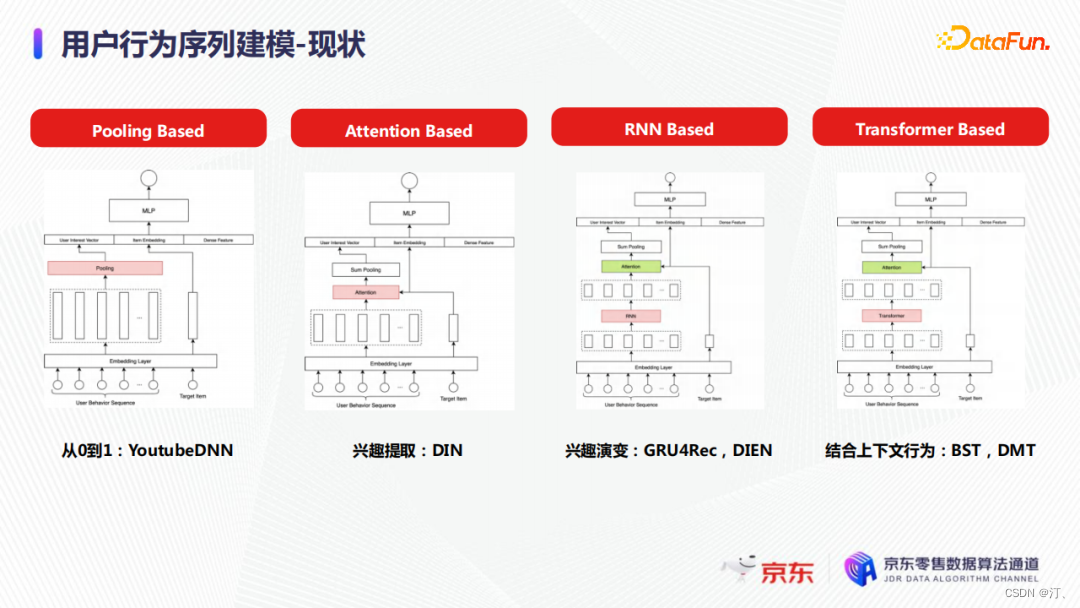
使用者行為序列建模在最近幾年發展較快。
- 第一個主要工作就是YoutubeDNN的Pooling Basded的方法,主要問題是資訊丟失嚴重,興趣表徵與待排商品也沒有任何相關性。為了解決這些問題,基於attention的模型(如DIN)被提出,它可以從使用者行為序列中挑選出與待排商品比較相關的行為特徵,主要問題是無法建模衰變性或者演變性,不同時間或者次序的行為表徵的興趣沒有差異性。
- 第二基於RNN-based的模型解決了這一問題,但是這類模型受順序推理的限制,無法建模較長的序列。在工業界RNN-based的序列模型通常只能對大約50個行為進行建模。
- 第三目前業界應用最廣泛的是基於Transformer的方法,它對使用者行為序列的表徵能力更強,且在一定程度上可以無視序列的長度。此外,雖然模型結構比RNN更復雜,但是由於模型自身已於並行的特點,它在工程上更好被優化。
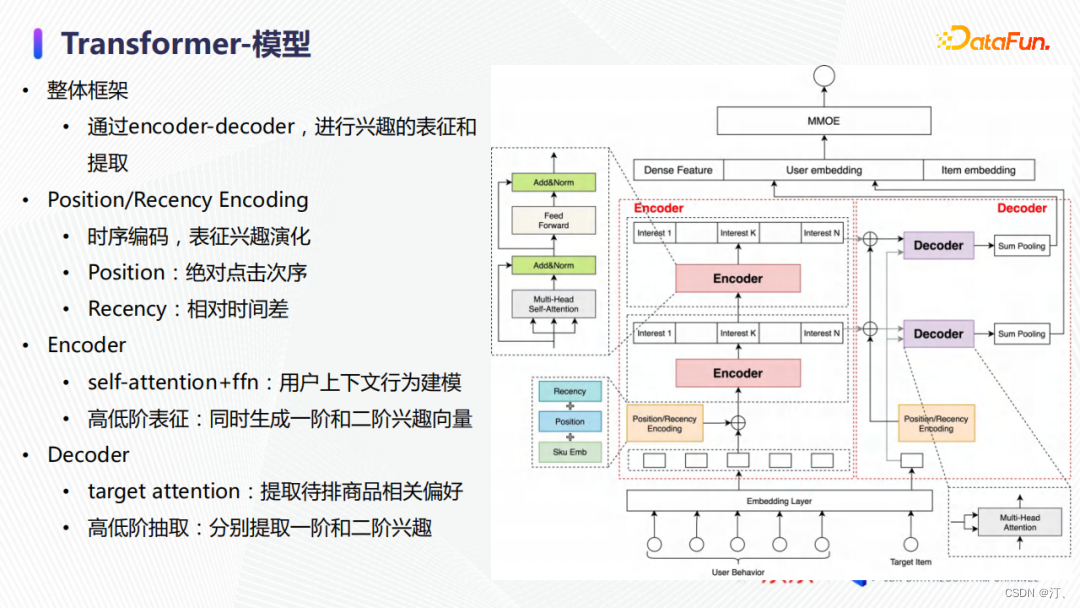
我們的行為序列建模模組主要以Transformer為基礎,並針對電商領域使用者行為的特性進行了相應優化。整體框架如上圖右側所示,採用一個encoder-decoder的結構來對使用者興趣進行表徵和提取。使用者的偏好是多樣性的,如何建模不同時期的偏好以及相應的演變是一個非常有挑戰的工作。原始NLP Transformer採用position encoding來補償模型所丟失的位置資訊。借鑑這一想法,我們在相同位置進行了時序編碼,除了位置資訊(position encoding),還增加了時間差(recency encoding)的編碼資訊,並通過直接相加來融合。Position和recency embedding與排序模型一起,端到端學習使用者行為次序和時間對興趣強弱的影響。
模型中encoder模組主要負責對使用者偏好進行表達,與原始Transformer類似,採用一個兩層的self-attention + ffn的網路結構。相同的商品在不同的使用者行為序列中代表的興趣有所不同,我們需要藉助使用者歷史中其他行為來表徵每個行為背後的精準意圖。與原始Transformer不同的是,我們借鑑特徵交叉的思想,同時保留了一階和二階興趣表徵向量。在decoder端,我們使用multi-head target attention,從encoder輸出的一階和二階向量中提取出與待排商品相關的一階和二階偏好。
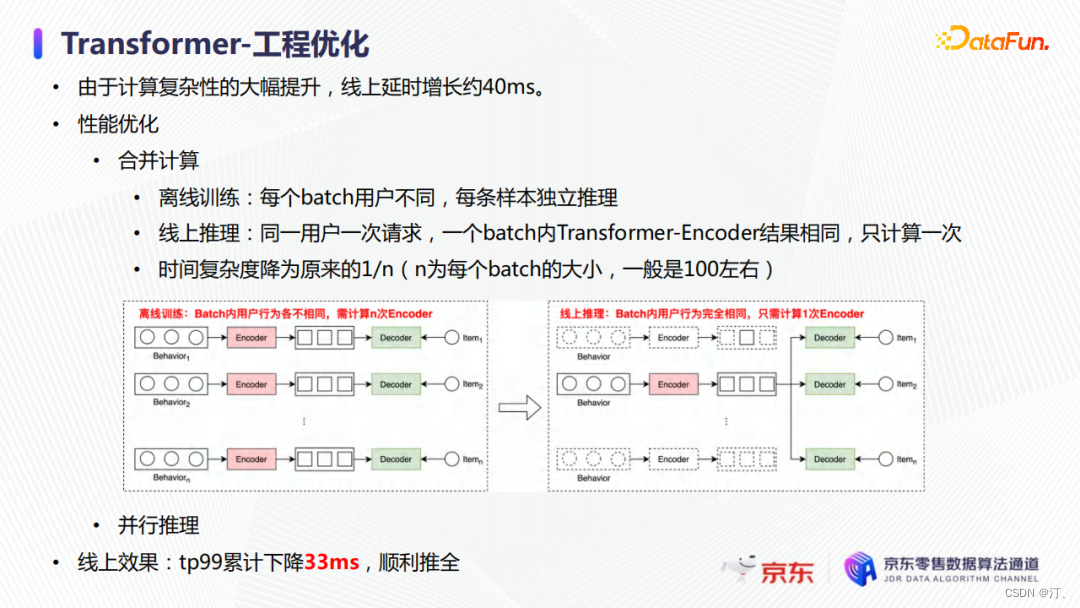
在工程上,由於模型計算複雜性的大幅提升,線上延時增加了約40毫秒,無法滿足上線要求。為了解決這個問題,我們通過合併計算和並行推理來優化線上延時。
- 在離線訓練時每個batch的樣本屬於不同的使用者,那麼我們需要對batch中每個的行為序列進行獨立的encoder推理,其時間複雜度是立方級的;
- 但是線上上推理時,同一使用者一次請求,一個batch內的encoder推理結果相同,那麼我們只要計算一次即可,時間複雜度就可以降低為平方級。
- 此外,通過調整計算圖的執行順序使得多個圖可以同時去推理。最終從線上效果來看,tp99累計可以下降至33毫秒,使得模型滿足全量上線要求。
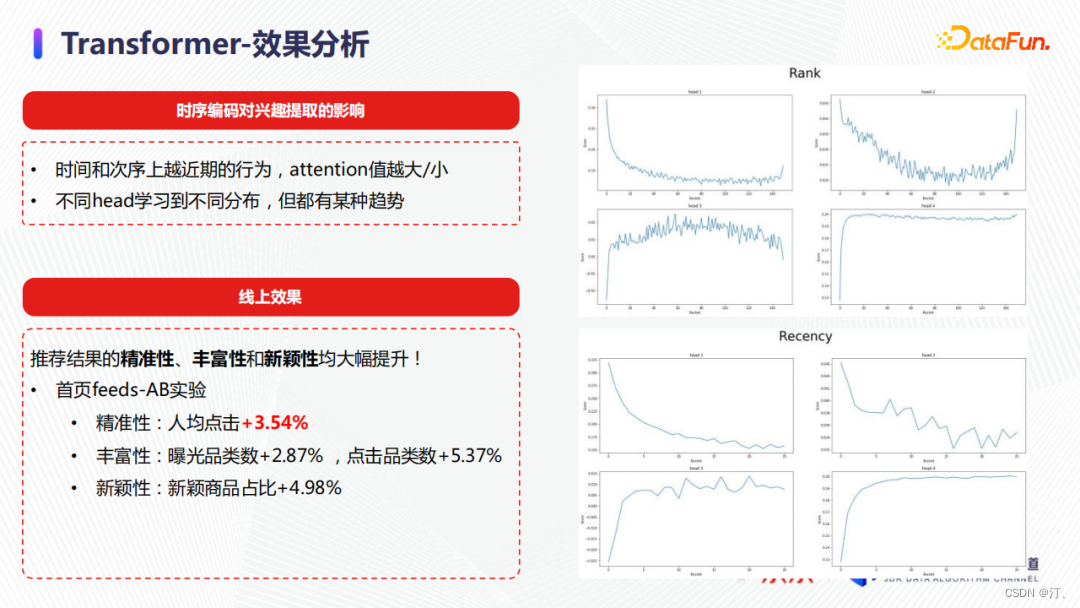
最後,我們對模型進行了離線分析,希望研究時序編碼是否在端到端學習中學習到足夠的資訊。從業務上來講,我們認為使用者越近期的行為對當前的使用者偏好影響越大。從上圖右側的結果展示了模型的多個head學習的資訊。我們可以看到行為次序越靠後,縱座標表示的attention值會有某種比較明顯的傾向性,表明模型確實學習到了興趣的演變特性。模型上線後,推薦結果的精準性、豐富性和新穎性均得到大幅提升。在首頁feed流,人均點選提升了3.5%,這也是我們使用深度模型後單次優化得到的最大提升。
2.4 精細行為建模

現在介紹一下我們在精細行為建模方向的工作。使用者的行為中往往包含較多的噪聲,包括一些誤點選操作,需要從充滿噪聲的序列中識別使用者的真實意圖,因此我們提出了基於精細行為的興趣建模來優化這一問題。
精細行為是使用者點選後在商品詳情頁的統計量和子行為資訊,包括停留時長、操作次數、檢視主圖、瀏覽評論等。
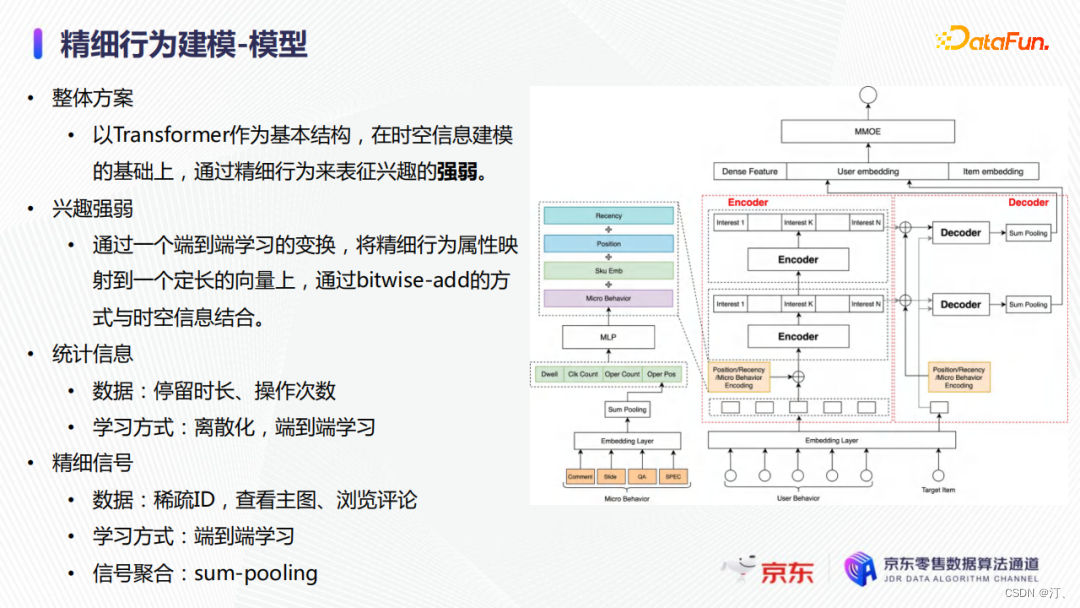
整體方案以前面提到的改進的Transformer為基礎,通過精細行為來建模使用者點選後的真正意圖和興趣強弱。如上圖所示,我們通過一個MLP將精細行為對映到一個定長的向量上,之後在通過bitwise-add的方式與時空編碼資訊結合。停留時長和運算元等統計資訊會進行離散化,並通過端到端學習。檢視主圖、瀏覽評論等精細行為直接學習ID表徵,並通過sum-pooling聚合。
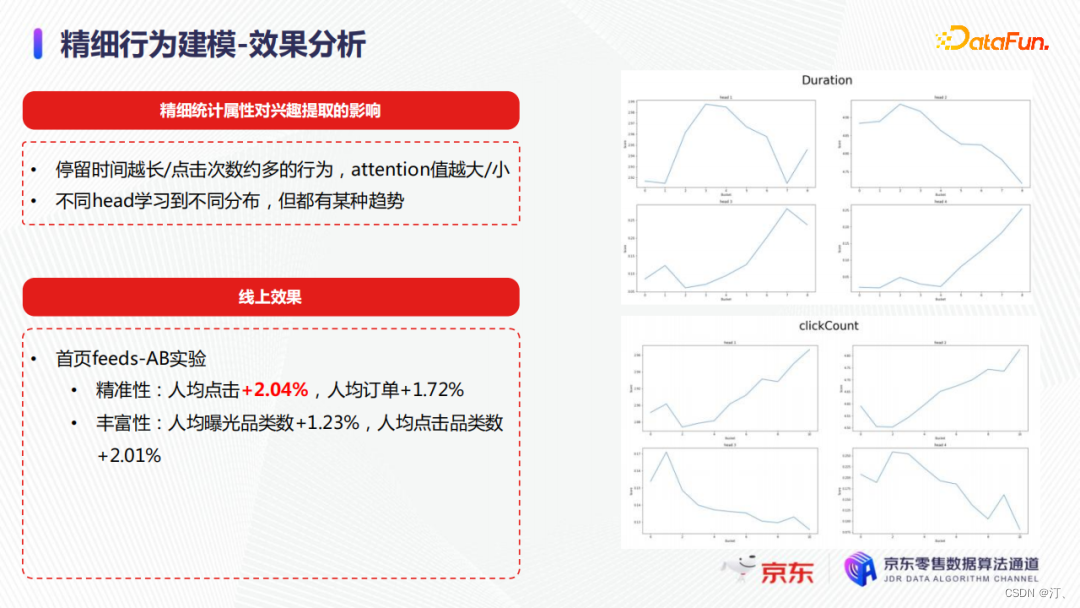
最後我們分析了精細統計屬性對興趣提取的影響,與之前的模型結論類似,我們也能觀察到停留時長和attention之間存在某種趨勢,停留越久attention值就越大。最終效果,在首頁feeds流,人均點選提升2%,轉化也提升了1.7%。
2.5多模態特徵

影響使用者點選決策的因素除了商品基本屬性,還受商品的主圖和標題的影響。
- 推薦系統存在冷啟動問題,比如一些新品是缺乏使用者反饋的,它們的特徵embedding處於欠擬合狀態。為了解決這個問題,我們引入了多模態特徵。多模態特徵可以帶來一定的資訊增益,商品的主圖和標題中非結構化的視覺和語意資訊可以比較好地表徵商品的狀態。
- 多模態特徵對緩解冷啟動問題效果較好,因為這一類特徵不需要使用者的反饋,它的特徵覆蓋率在我們的業務場景下較高。
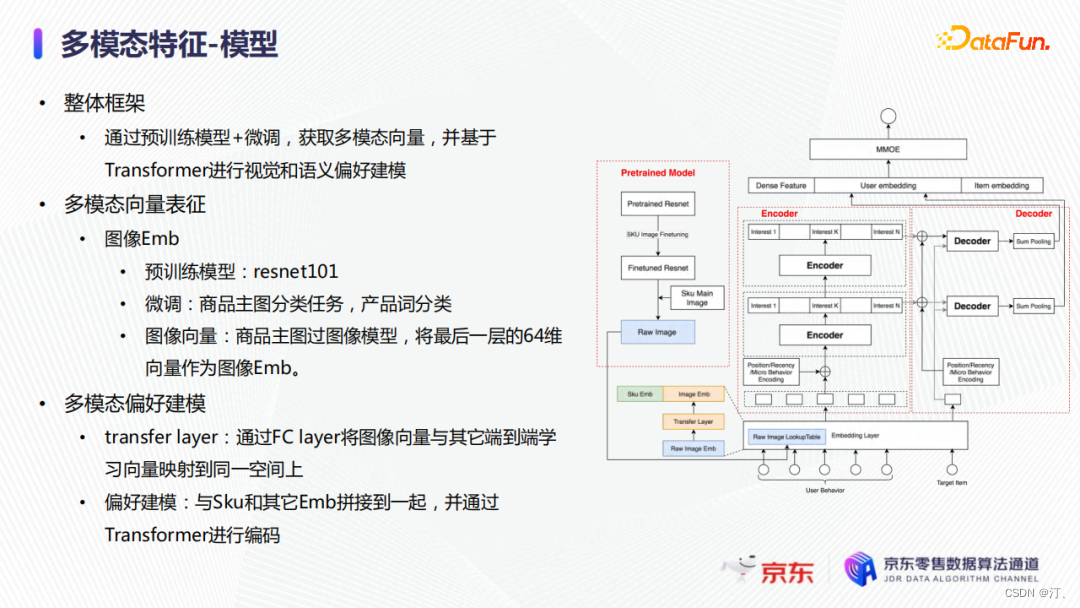
模型整體框架是通過預訓練模型+微調分別得到影象和文字向量,並基於Transformer進行視覺和語意偏好的建模。由於預訓練模型採用的是resnet101,它的訓練資料分佈和電商領域的圖片分佈有較大的差異,所以我們使用了電商主圖的產品詞分類資料對模型進行微調,使得模型能夠學習到電商商品的特徵。最終,我們把商品主圖輸入至影象模型,將最後一層64維向量作為影象embedding,應用於排序模型。
在進行多模態的偏好建模過程中,有兩個主要問題需要解決。
- 首先,影象embedding和其他端到端訓練的embedding來自於不同模型,這使得它們處於不同的特徵空間。
- 為了對齊向量空間,我們加入了一個transfer layer,採用了一個multi-gate multi-expert的結構,以商品的品類作為gate的輸入,選取不同的對映expert,將影象特徵與其他端到端的特徵進行對齊。
- 最終,我們會將轉變後的影象embedding和sku embedding拼接到一起,並通過上文提到的Transformer進行統一編碼。

最後我們對影象預訓練向量的質量進行了分析,具體做法是篩選一部分商品,觀察他們向量的相似度。通過上圖可以看到,感官上相近商品的相似度比較高,而當色差較大時相似度也會有相應的降低。如果是差異較大的商品,影象相似度也比較小。線上上效果方面,我們將該方法應用到了首頁feeds和首頁核心頻道,效果比較顯著,人均點選分別提升2.6%和5%。
3.專案答疑
Q1:多目標融合模型中實際線上上會有多少個目標?每個目標的量級不一樣,如何保證模型不受某一個目標主導?
A:在首頁,我們有6個目標。業務上,通常會有主要的優化目標,重要性不同;技術上,也會對不同目標進行相應的加權操作,使得他們的量級處於一個相對平衡的狀態。
Q2:線上會同時使用多目標模型的多路輸出嗎?
A:會的。個性化多目標模型中就是把多個目標的輸出融合後作為排序依據的。
Q3:能不能再詳細介紹一下多模態向量表徵中影象embedding的微調方法?
A:首先,我們的訓練資料是商品的主圖,對應的標籤是產品詞的分類。在京東的業務場景下,產品詞大概有十萬個類別。我們會把資料輸入到預訓練的模型中,凍結住除了最後一個分類層外的所有網路引數,只微調分類層。最後我們會將分類層輸出的64維向量取出,作為商品的影象embedding。
Q4:多模態融合模型有考慮去做聯合訓練嗎?
A:這是技術選型的問題,因為聯合訓練通常來說會是單獨使用影象的模型去做聯合訓練,或者單獨使用文字模型去做聯合訓練。但實際上我們要線上上使用的話,影象、文字以及其他一些模型輸出的embedding都會被使用,這就涉及到了三到四種不同模型的聯合訓練。這種做法優化起來十分困難,對於線上服務以及後續迭代都會有很大的影響。所以,實際上我們不會去採用多模態聯合訓練的方式。
Q5:可以再詳細介紹一下多目標融合模型中的損失函數的優化方式和設計思路嗎?
A:多目標融合模型的主網路和融合網路分別對應著兩個損失函數和兩個優化器。我們會分別訓練這兩部分網路,其中主網路輸出的是多目標的預測值,比如點選率和轉化率;另一個網路輸出的是多目標預測值的融合權重,比如點選率的權重和轉化率的權重。最終,模型使用點積的方式將多個目標的輸出融合為一個預測值。在優化思路上,我們希望主網路優化各個目標的引數來達到最優;融合網路不影響主網路的更新,它學習如何組合主網路不同目標的預測值,來使得最終的排序能在優化方向上最優。