一文詳解ATK Loss論文復現與程式碼實戰
摘要:該方法的主要思想是使用數值較大的排在前面的梯度進行反向傳播,可以認為是一種線上難例挖掘方法,該方法使模型講注意力放在較難學習的樣本上,以此讓模型產生更好的效果。
本文分享自華為雲社群《ATK Loss論文復現與程式碼實戰》,作者:李長安。
損失是一種非常通用的聚合損失,其可以和很多現有的定義在單個樣本上的損失 結合起來,如logistic損失,hinge損失,平方損失(L2),絕對值損失(L1)等等。通過引入自由度 k,損失可以更好的擬合資料的不同分佈。當資料存在多分佈或類別分佈不均衡的時候,最小化平均損失會犧牲掉小類樣本以達到在整體樣本集上的損失最小;當資料存在噪音或外點的時候,最大損失對噪音非常的敏感,學習到的分類邊界跟Bayes最優邊界相差很大;當採取損失最為聚合損失的時候(如k=10),可以更好的保護小類樣本,並且其相對於最大損失而言對噪音更加魯棒。所以我們可以推測:最優的k即不是k = 1(對應最大損失)也不是k = n(對應平均損失),而是在[1, n]之間存在一個比較合理的k的取值區間。
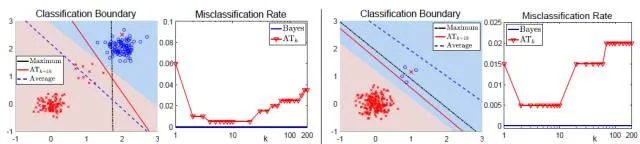
上圖結合模擬資料顯示了最小化平均損失和最小化最大損失分別得到的分類結果。可以看出,當資料分佈不均衡或是某類資料存在典型分佈和非典型分佈的時候,最小化平均損失會忽略小類分佈的資料而得到次優的結果;而最大損失對樣本噪音和外點(outliers)非常的敏感,即使資料中僅存在一個外點也可能導致模型學到非常糟糕的分類邊界;相比於最大損失損失,第k大損失對噪音更加魯棒,但其在k > 1時非凸非連續,優化非常困難。
由於真實資料集非常複雜,可能存在多分佈性、不平衡性以及噪音等等,為了更好的擬合資料的不同分佈,我們提出了平均Top-K損失作為一種新的聚合損失。

本專案最初的思路來自於八月份參加比賽的時候。由於資料集複雜,所以就在想一些難例挖掘的方法。看看這個方法能否帶來一個更好的模型效果。該方法的主要思想是使用數值較大的排在前面的梯度進行反向傳播,可以認為是一種線上難例挖掘方法,該方法使模型講注意力放在較難學習的樣本上,以此讓模型產生更好的效果。程式碼如下所示。
class topk_crossEntrophy(nn.Layer): def __init__(self, top_k=0.6): super(topk_crossEntrophy, self).__init__() self.loss = nn.NLLLoss() self.top_k = top_k self.softmax = nn.LogSoftmax() return def forward(self, inputs, target): softmax_result = self.softmax(inputs) loss1 = paddle.zeros([1]) for idx, row in enumerate(softmax_result): gt = target[idx] pred = paddle.unsqueeze(row, 0) cost = self.loss(pred, gt) loss1 = paddle.concat((loss1, cost), 0) loss1 = loss1[1:] if self.top_k == 1: valid_loss1 = loss1 index = paddle.topk(loss1, int(self.top_k * len(loss1))) valid_loss1 = loss1[index[1]] return paddle.mean(valid_loss1)
topk_loss的主要思想
- topk_loss的核心思想,即通過控制損失函數的梯度反傳,使模型對Loss值較大的樣本更加關注。該函數即為CrossEntropyLoss函數的具體實現,只不過是在計算nllloss的時候取了前70%的梯度
- 數學邏輯:挖掘反向傳播前 70% 梯度。
程式碼實戰
此部分使用比賽中的資料集,並帶領大家使用Top-k Loss完成模型訓練。在本例中使用前70%的Loss。
!cd 'data/data107306' && unzip -q img.zip # 匯入所需要的庫 from sklearn.utils import shuffle import os import pandas as pd import numpy as np from PIL import Image import paddle import paddle.nn as nn from paddle.io import Dataset import paddle.vision.transforms as T import paddle.nn.functional as F from paddle.metric import Accuracy import warnings warnings.filterwarnings("ignore") # 讀取資料 train_images = pd.read_csv('data/data107306/img/df_all.csv') train_images = shuffle(train_images) # 劃分訓練集和校驗集 all_size = len(train_images) train_size = int(all_size * 0.9) train_image_list = train_images[:train_size] val_image_list = train_images[train_size:] train_image_path_list = train_image_list['image'].values label_list = train_image_list['label'].values train_label_list = paddle.to_tensor(label_list, dtype='int64') val_image_path_list = val_image_list['image'].values val_label_list1 = val_image_list['label'].values val_label_list = paddle.to_tensor(val_label_list1, dtype='int64') # 定義資料預處理 data_transforms = T.Compose([ T.Resize(size=(448, 448)), T.Transpose(), # HWC -> CHW T.Normalize( mean = [0, 0, 0], std = [255, 255, 255], to_rgb=True) ]) # 構建Dataset class MyDataset(paddle.io.Dataset): """ 步驟一:繼承paddle.io.Dataset類 """ def __init__(self, train_img_list, val_img_list,train_label_list,val_label_list, mode='train'): """ 步驟二:實現建構函式,定義資料讀取方式,劃分訓練和測試資料集 """ super(MyDataset, self).__init__() self.img = [] self.label = [] self.valimg = [] self.vallabel = [] # 藉助pandas讀csv的庫 self.train_images = train_img_list self.test_images = val_img_list self.train_label = train_label_list self.test_label = val_label_list # self.mode = mode if mode == 'train': # 讀train_images的資料 for img,la in zip(self.train_images, self.train_label): self.img.append('data/data107306/img/imgV/'+img) self.label.append(la) else : # 讀test_images的資料 for img,la in zip(self.test_images, self.test_label): self.img.append('data/data107306/img/imgV/'+img) self.label.append(la) def load_img(self, image_path): # 實際使用時使用Pillow相關庫進行圖片讀取即可,這裡我們對資料先做個模擬 image = Image.open(image_path).convert('RGB') image = np.array(image).astype('float32') return image def __getitem__(self, index): """ 步驟三:實現__getitem__方法,定義指定index時如何獲取資料,並返回單條資料(訓練資料,對應的標籤) """ # if self.mode == 'train': image = self.load_img(self.img[index]) label = self.label[index] return data_transforms(image), label def __len__(self): """ 步驟四:實現__len__方法,返回資料集總數目 """ return len(self.img) #train_loader train_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='train') train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=4, shuffle=True, num_workers=0) #val_loader val_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='test') val_loader = paddle.io.DataLoader(val_dataset, places=paddle.CPUPlace(), batch_size=4, shuffle=True, num_workers=0) from res2net import Res2Net50_vd_26w_4s # 模型封裝 model_re2 = Res2Net50_vd_26w_4s(class_dim=4) import paddle.nn.functional as F import paddle modelre2_state_dict = paddle.load("Res2Net50_vd_26w_4s_pretrained.pdparams") model_re2.set_state_dict(modelre2_state_dict, use_structured_name=True) model_re2.train() epochs = 2 optim1 = paddle.optimizer.Adam(learning_rate=3e-4, parameters=model_re2.parameters()) class topk_crossEntrophy(nn.Layer): def __init__(self, top_k=0.7): super(topk_crossEntrophy, self).__init__() self.loss = nn.NLLLoss() self.top_k = top_k self.softmax = nn.LogSoftmax() return def forward(self, inputs, target): softmax_result = self.softmax(inputs) loss1 = paddle.zeros([1]) for idx, row in enumerate(softmax_result): gt = target[idx] pred = paddle.unsqueeze(row, 0) cost = self.loss(pred, gt) loss1 = paddle.concat((loss1, cost), 0) loss1 = loss1[1:] if self.top_k == 1: valid_loss1 = loss1 # print(len(loss1)) index = paddle.topk(loss1, int(self.top_k * len(loss1))) valid_loss1 = loss1[index[1]] return paddle.mean(valid_loss1) topk_loss = topk_crossEntrophy() from numpy import * # 用Adam作為優化函數 for epoch in range(epochs): loss1_train = [] loss2_train = [] loss_train = [] acc1_train = [] acc2_train = [] acc_train = [] for batch_id, data in enumerate(train_loader()): x_data = data[0] y_data = data[1] y_data1 = paddle.topk(y_data, 1)[1] predicts1 = model_re2(x_data) loss1 = topk_loss(predicts1, y_data1) # 計算損失 acc1 = paddle.metric.accuracy(predicts1, y_data) loss1.backward() if batch_id % 1 == 0: print("epoch: {}, batch_id: {}, loss1 is: {}, acc1 is: {}".format(epoch, batch_id, loss1.numpy(), acc1.numpy())) optim1.step() optim1.clear_grad() loss1_eval = [] loss2_eval = [] loss_eval = [] acc1_eval = [] acc2_eval = [] acc_eval = [] for batch_id, data in enumerate(val_loader()): x_data = data[0] y_data = data[1] y_data1 = paddle.topk(y_data, 1)[1] predicts1 = model_re2(x_data) loss1 = topk_loss(predicts1, y_data1) loss1_eval.append(loss1.numpy()) # 計算acc acc1 = paddle.metric.accuracy(predicts1, y_data) acc1_eval.append(acc1) if batch_id % 100 == 0: print('************Eval Begin!!***************') print("epoch: {}, batch_id: {}, loss1 is: {}, acc1 is: {}".format(epoch, batch_id, loss1.numpy(), acc1.numpy())) print('************Eval End!!***************')
總結
- 在該工作中,分析了平均損失和最大損失等聚合損失的優缺點,並提出了平均Top-K損失(損失)作為一種新的聚合損失,其包含了平均損失和最大損失並能夠更好的擬合不同的資料分佈,特別是在多分佈資料和不平衡資料中。損失降低正確分類樣本帶來的損失,使得模型學習的過程中可以更好的專注於解決複雜樣本,並由此提供了一種保護小類資料的機制。損失仍然是原始損失的凸函數,具有很好的可優化性質。我們還分析了損失的理論性質,包括classification calibration等。
- Top-k loss 的引數設定為1時,此損失函數將變cross_entropy損失,對其進行測試,結果與原始cross_entropy()完全一樣。但是我在實際的使用中,使用此損失函數卻沒使模型取得一個更好的結果。需要做進一步的實驗。