ViT簡述【Transformer】
Transformer在NLP任務中表現很好,但是在CV任務中應用還很有限,基本都是作為CNN的一個輔助,Vit嘗試使用純Transformer結構解決CV的任務,併成功將其應用到了CV的基本任務--影象分類中。
因此,簡單而言,這篇論文的主旨就是,用Transformer結構完成影象分類任務。
結構概述
基本結構如下:
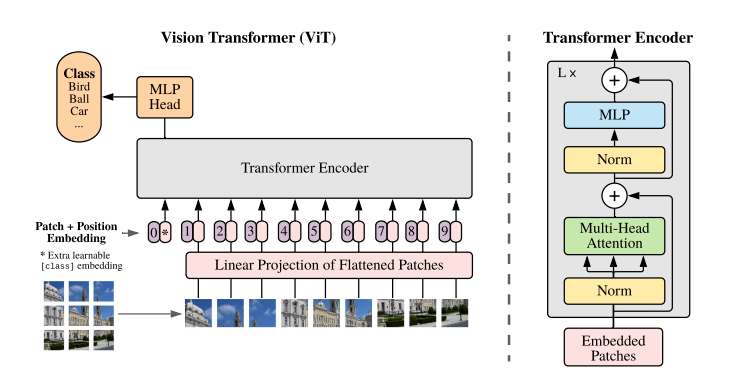
核心要點:
- 影象切patch
- Patch0
- Position Embedding
- Multi-Head Attention
影象切patch
在NLP任務中,將自然語言使用Word2Vec轉為向量(Embedding)送入模型進行處理,在CV中沒有對應的序列化token,因此作者採用將原始影象切分為多個小塊,然後將每個小塊兒內的資訊展平的方式。
假設輸入的shape為:(1, 3, 288, 288)
切分為9個小塊,則每個小塊的shape為:(1, 3, 32, 32)
然後將每個小塊展平,則每個小塊為(1, 3072),有9個小塊,所以Linear Projection of Flattened Patched的shape為:(1, 9, 3072)輸出shape為(1, 9, 1024),再加上Position Embedding,Transformer Encoder的輸入shape為(1, 10, 1024),也就是圖中Embedded Patches的shape。
Patch0
為什麼需要有Patch0?
這是因為需要對1-9個patches資訊的整合,最後送入MLP Head的只有Patch0。
Position Embedding
影象被切分和展開後,丟失了位置資訊,對於影象處理任務來說,這是很怪異的,因此,作者這裡採用在每個Patch上增加一個位置資訊的方式,將位置資訊納入考慮。
Multi-Head Attention
參考Attention的基本結構。[Todo, Link]
程式碼[Pytorch]
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img)
print(preds.shape) # 1000,與ViT定義的num_classes一致
ViT類引數解析:
- dim:Linear Projection的輸出維度:1024
- depth:有多少個Transformer Blocks
- heads:Multi-Head的Head數
- mlp_dim:Transformer Encoder內部的MLP的維度
- dropout
- ......
ViT的forward函數:
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
輸入端的切分主要由下面這句話完成:
x = self.to_patch_embedding(img)
==>
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
#由傳入引數: image_size = 256, patch_size = 32
# Rearrange完成的shape變換為(b, c, 256, 256) -> (b, 64, 1024*c)
# nn.LayerNorm
# nn.Linear: (b, 64, 1024*c) --> (b, 64, 1024)
Rearrange用更加可理解的方式實現transpose的功能:
We don't write:
y = x.transpose(0, 2, 3, 1)We write comprehensible code:
y = rearrange(x, 'b c h w -> b h w c')