解密遊戲推薦系統的建設之路
作者:vivo 網際網路伺服器團隊- Ke Jiachen、Wei Ling
本文從零開始介紹了遊戲推薦專案的發展歷程,闡述了大型專案建設中遇到的業務與架構問題以及開發工程師們的解決方案,描繪了遊戲推薦專案的特點以及業務發展方向,有著較好的參考與借鑑意義。
一、遊戲推薦的背景與意義
從資訊獲取的角度來看,搜尋和推薦是使用者獲取資訊的兩種主要手段,也是有效幫助產品變現的兩種方式,搜尋是一個非常主動的行為,並且使用者的需求十分明確,在搜尋引擎提供的結果裡,使用者也能通過瀏覽和點選來明確的判斷是否滿足了使用者需求。
然而,推薦系統接受資訊是被動的,需求也都是模糊而不明確的。
推薦系統的作用就是建立更加有效率的連線,更有效率地連線使用者與內容和服務,節約大量的時間和成本。以此背景,遊戲推薦系統由此誕生。
遊戲推薦系統從設計之初就作為遊戲分發的平臺,向公司內所有主要流量入口(遊戲中心、應用商店、瀏覽器、jovi等)分發遊戲,系統通過各種推薦演演算法及推薦策略,為使用者推薦下載付費意願較高且兼顧商業價值的遊戲,從而為公司帶來收入。發展至今天,該系統還具備類遊戲內容與素材的推薦功能。
二、遊戲推薦的初期模型
遊戲推薦的目的是推出使用者想要且兼顧商業價值的遊戲,以此來提高業務的收入指標。此處的商業價值是由運營側通過策略規則去把控的,而使用者意向遊戲則是通過演演算法排序得到的,演演算法排序所需要的特徵資料,以及推薦效果的反饋資料則由埋點資訊上報以供計算分析。
因此我們的模型可以分成四大塊:
-
運營推薦規則設定
-
演演算法模型訓練
-
推薦策略生效
-
資料埋點上報

模組間的互動如下:在策略生效前,運營會先在設定中心生成對應的設定規則,這些規則會以快取的形式儲存以供推薦高並介面呼叫。當用戶存取app應用某些特定頁面時,其後臺會帶著對應的場景資訊來請求遊戲推薦後臺,推薦後臺根據場景資訊對映相關設定(召回,標籤,過期,演演算法等..........)呼叫演演算法服務並進行資源排序,最終將推薦的結果反饋給app應用。
app應用在展示推薦頁面的同時,也將使用者相應的行為資料以及推薦資料的相關埋點進行上報。
三、業務增長與架構演進
隨著接入系統帶來的正向收益的提升,越來越多的業務選擇接入遊戲推薦系統,這使得我們支援的功能日益豐富。
目前遊戲推薦覆蓋的場景有分類、專題、榜單、首頁、搜尋等;包含的策略型別有干預、打散、資源配比、保量;支援的推薦型別更是豐富:聯運遊戲、小遊戲、內容素材、推薦理由。
這些豐富的使用場景使得業務的複雜度成本增長,令我們在效能,擴充套件性,可用性上面臨著新的挑戰,也推動著我們架構變革。
3.1 熵增環境下的通用組合策略
在0 到 1 的過程中,遊戲推薦聚焦於提高分發量,這時候考慮得更多的是怎麼把遊戲推出去,在程式碼實現上使用分層架構來劃分執行的業務。
但是在1 到 2 的過程中, 我們遊戲推薦不僅僅推薦遊戲,也推薦內容和素材;同時在策略呼叫上也更加靈活,不同場景其呼叫的策略是不同的,執行順序也是不同的;更重要的是加入了很多使用者個性化業務與動態規則,這些都使得現有業務程式碼急劇膨脹,擴充套件起來捉襟見肘,無從下手。因此我們急需一個高複用,易擴充套件,低程式碼的策略框架去解決這些問題。
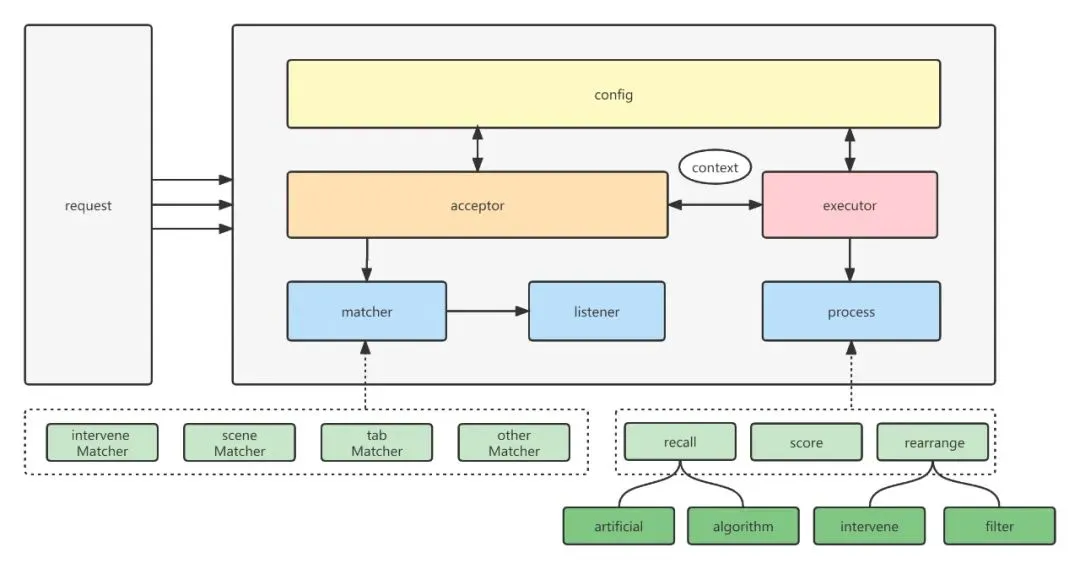 如圖所示,通用組合策略負責流轉的角色有兩個acceptor和executor,通訊媒介是推薦上下文context。負責執行邏輯的角色有三個matcher,listener和process,它們都有多個不同邏輯的實現類。當請求遊戲推薦系統時,acceptor會先從設定中動態查詢策略模板進行匹配,接著listener元件會執行相應的預處理邏輯。處理後acceptor通過上下文context將任務流轉給executor處理器。executor再根據設定,將process根據前置條件進行篩選並排列組合,最後埋點返回。
如圖所示,通用組合策略負責流轉的角色有兩個acceptor和executor,通訊媒介是推薦上下文context。負責執行邏輯的角色有三個matcher,listener和process,它們都有多個不同邏輯的實現類。當請求遊戲推薦系統時,acceptor會先從設定中動態查詢策略模板進行匹配,接著listener元件會執行相應的預處理邏輯。處理後acceptor通過上下文context將任務流轉給executor處理器。executor再根據設定,將process根據前置條件進行篩選並排列組合,最後埋點返回。
經過這套通用的策略,我們在實現一般業務的時候,只要擴充套件具體matcher和process,並在設定中心將場景和處理優先順序繫結起來,就能完成大部分的場景開發,這樣研發者可以更聚焦於某個邏輯流程的開發,而不用疲於梳理程式碼,並進行擴充套件設計。
3.2 多級快取與近實時策略
遊戲推薦系統服務於手機遊戲使用者,處於整個系統鏈路的下游,峰值流量在3W TPS左右 ,是個讀遠多於寫的系統。「讀」流量來自於使用者在各種推薦場景,列表、搜尋、下載錢下載後、榜單等,寫資料主要來源於運營相關策略的變更,所以我們面臨的一個重大挑戰就是如何在保證可用性的前提下應對高頻的讀請求。
為了保證系統的讀效能,我們採用了redis + 本地快取的設計。設定更新後先寫mysql,寫成功後再寫redis。本地快取定時失效,使用懶載入的方式從redis中讀取相關資料。這種設計能保證最終一致性,軟狀態時服務叢集資料存在短暫不一致的情況,早期對業務影響不大,可以認為是一個逐步放量的過程。
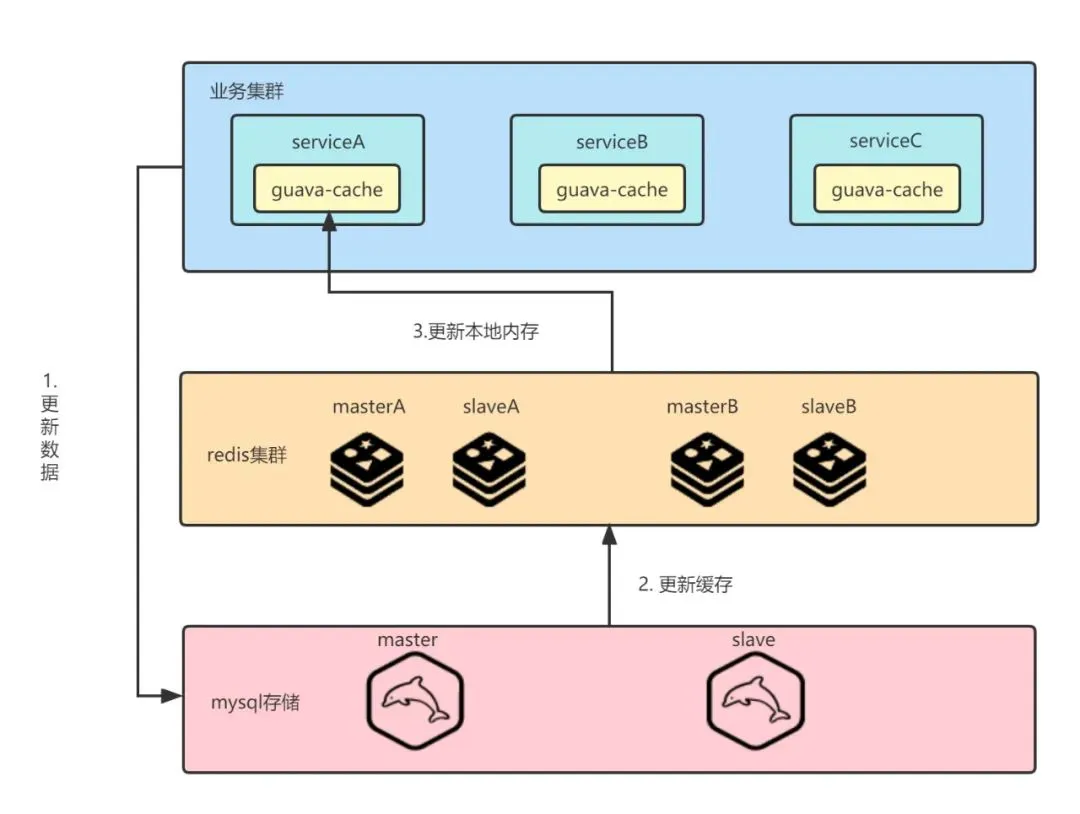 早期原先部署節點較少,整個系統達到最終一致性的時間較短,但隨著節點增加到數百臺,這個時間就變得不是那麼和諧了。
早期原先部署節點較少,整個系統達到最終一致性的時間較短,但隨著節點增加到數百臺,這個時間就變得不是那麼和諧了。
同時隨著業務複雜度的增加,常常是多個設定策略決定這一個推薦結果,此時本地快取的狀態極大影響了測試和點檢的便利,如果設定更改不能做到立馬更新本地快取,那就要等待漫長的一段時間才能開始驗證邏輯。因此,我們對快取結構做出瞭如下的調整:
 與先前不同的是,我們加入訊息佇列並通過設定版本號的比對來實現策略的實時更新同步,取得了很好的效果。
與先前不同的是,我們加入訊息佇列並通過設定版本號的比對來實現策略的實時更新同步,取得了很好的效果。
3.3 高並服務的垃圾回收處理
任何一個java服務都逃離不了FGC的魔咒,高並服務更是如此。很多服務每天兩位數的FGC更是家常便飯,顯然這對業務的穩定性和服務效能影響是巨大的。遊戲推薦這邊通過不斷實踐總結了一套較為通用的方法很好地解決了這個問題:
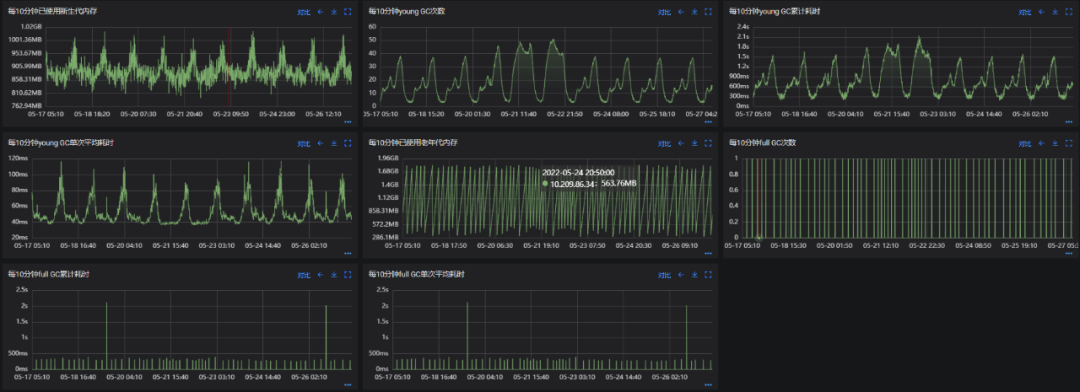
可以看到起初jvm設定較為常規:1G的年輕代,2G的老年代以及一些其他常見的多執行緒回收的設定,其結果就是每天10次的FGC,YGC單次耗時在100ms,FGC耗時在350 - 400ms。我們知道線上介面容忍的範圍一般是200ms以內,不超過300ms,這樣顯然是不達標的。
通過分析,我們發現高並服務的高頻FGC來源於這幾個方面:
-
大量的本地快取(堆內)佔據了老年代的空間,大大增加了老年代疊滿的頻率。
-
高並請求導致了物件的急速生成,年輕代空間不足以容納這劇增的物件,導致其未達到存活閾值(15次)就晉升至老年代。
-
引入的監控元件為了效能,常常延遲 1 - 2 min再將資料上報伺服器端,導致這部分資料也無法在年輕代被回收。
當然這還不是問題的全部,FGC還有個致命問題就是stop the world,這會導致業務長時間無法響應,造成經濟損失。反過來,就算FGC頻繁,stop the world 只有1ms,也是不會對業務造成影響的,因此不能單單以FGC的頻率來判斷jvm服務的gc效能的好壞。經過上面的探討,我們在實踐中得到了如下的解決方案:
-
不常變化的快取(小時級別)移到堆外,以此減少老年代疊滿的基礎閾值。
-
變化不那麼頻繁的快取(分鐘級別)更新的時候進行值對比,如果值一樣則不更新,以此減少老年代的堆積。
-
使用G1回收器:-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:InitiatingHeapOccupancyPercent=25
-XX:MaxNewSize=3072M -Xms4608M -Xmx4608M -XX:MetaspaceSize=512M
-XX:MaxMetaspaceSize=512M
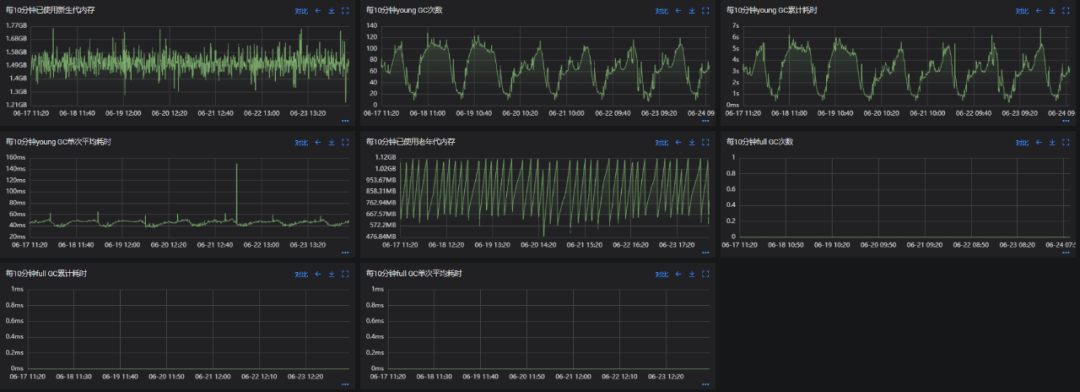
其效果如上所示,調整後各項指標都有很大的進步:由於年輕代中的複製演演算法使其垃圾清理速度較快,所以調大其容量使物件儘量在其中回收,同時設定每次清理的時間,使得mix gc控制在200ms以內。
3.4 限流降級與兜底策略
為了保證業務的可用性,大部分業務都會引入hystrix, sentinel, resilience4j 這類熔斷限流元件, 但這些元件也不能解決全部的問題。
對於遊戲推薦來說,一臺節點往往承載著不同的業務推薦,有些業務十分核心,有些不是那麼重要,限流降級的時候不是簡單的哪個服務限流多少問題,而是在權衡利弊的情況下,將有限的資源向哪些業務傾斜的問題,對此我們在分層限流上下足了功夫。
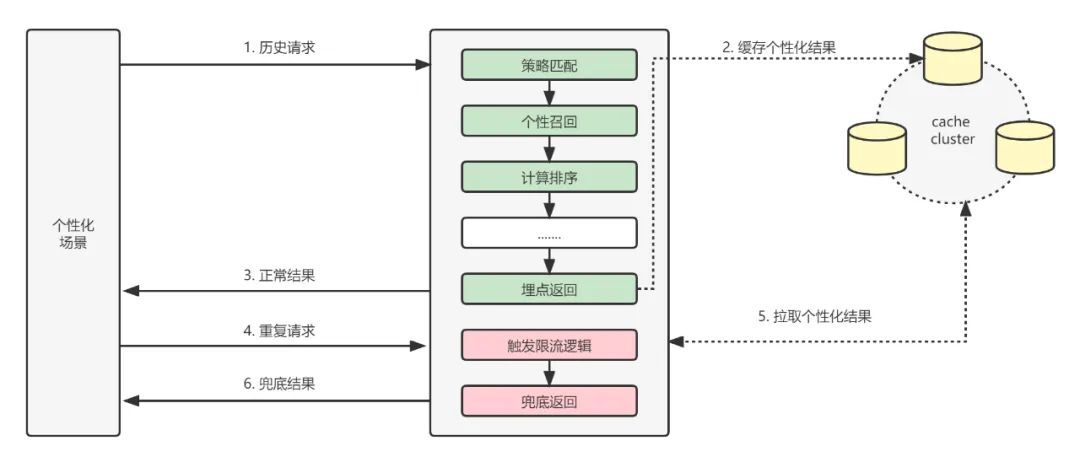
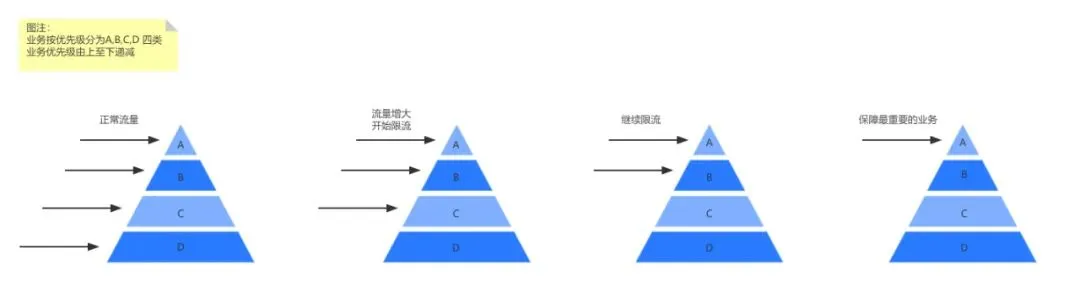 同時對於個性化業務來說,僅僅返回通用的兜底會使推薦同質化,因此我們的策略是將使用者的歷史資料儲存下來,並在下次兜底的時候作為推薦列表進行返回。
同時對於個性化業務來說,僅僅返回通用的兜底會使推薦同質化,因此我們的策略是將使用者的歷史資料儲存下來,並在下次兜底的時候作為推薦列表進行返回。
四、精細化運營模式的探索
在經歷過了0 到1 的開疆拓土 與 1 到 2 的高速增長後,遊戲的推薦架構已經趨於穩定。這時候我們更加關注效能的提高與成本的下降,因此我們開始著手於系統運營的精細化設計,這對推薦系統的良性發展是意義重大的。
精細化運營不僅能提高尾量遊戲的收入,提高運營人員的工作效率,還能實時快速反饋演演算法線上效果並立馬做出調整,做到一個業務上的閉環。首先就不得不提到遊戲推薦系統的分層正交實驗平臺,這是我們做精細化運營的基礎。
4.1 多層 hash 正交實驗平臺
遊戲推薦的關鍵就一個"準"字,這就需要通過精細化策略迭代來提升效率和準確度,從而不斷擴大規模優勢,實現正向迴圈。然而策略的改變並不是通過「頭腦風暴」空想的,而是一種建立在資料反饋上的機制,以帶來預期內的正向變化。這就需要我們分隔對照組來做A/Btest。
一般線上業務常見的A/B test是通過物理方式對流量進行隔離,這種方法常見於H5頁面的分流實驗,但面對複雜業務時卻存在著部署較慢,埋點解析困難等問題,其典型的架構方式如下:
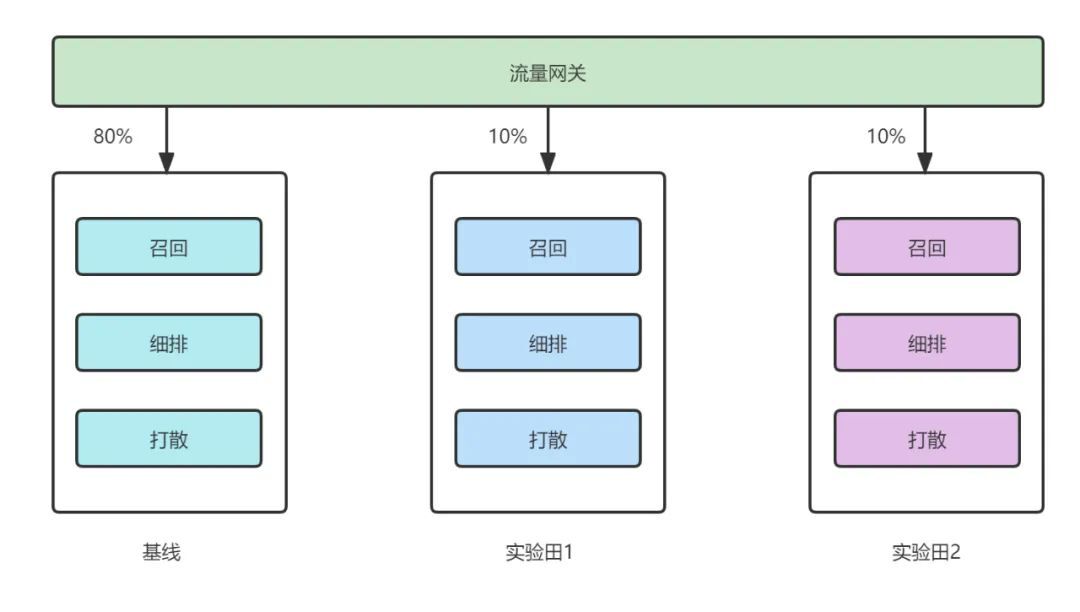
對於遊戲推薦來說,其完成一次推薦請求的流程比較複雜,涉及到多組策略,為了保證線上流量的效率與互斥,就不能採用簡單的物理分配流量的方式。
因此在業務層我們建立了一套多層hash正交實驗規則來滿足我們A/B test的要求。
其流量走勢如下圖所示,
與物理隔離流量,部署多套環境的方式不同,分層模型在分流演演算法中引入層級編號因子(A)來解決流量飢餓和流量正交問題。每一實驗層可以劃分為多個實驗田,當流量經過每一層實驗時,會先經過Function(Hash(A)) 來計算其分配的實驗田,這樣就能保證層與層之間的流量隨機且相互獨立。
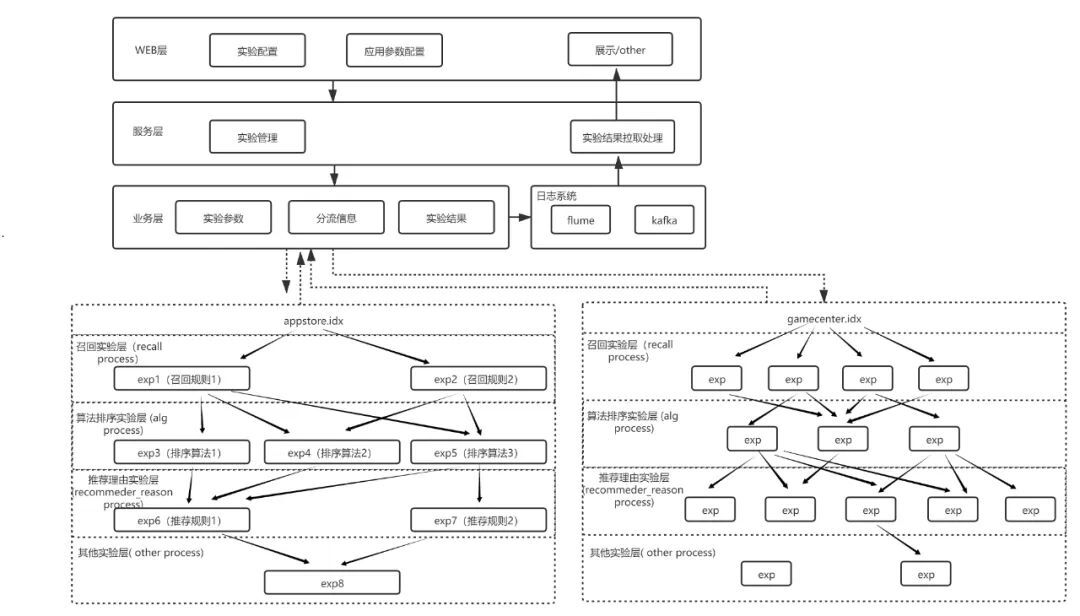
以上就是推薦業務和一般業務實驗流量隔離的不同之處,在實驗設計上我們又將一個完整的實驗週期分為以下幾個階段。在預備階段需要跟根據業務指標的需求,提出實驗假設,劃分好基線和實驗田的流量比例,並上線設定(放量)。
在實驗階段,線上流量進入後,服務會根據流量號段的匹配響應的策略進行執行,並將實驗資料上報。放量一段時候後,我們會根據上報的埋點資料進行資料分析,以確定此次策略的好壞。
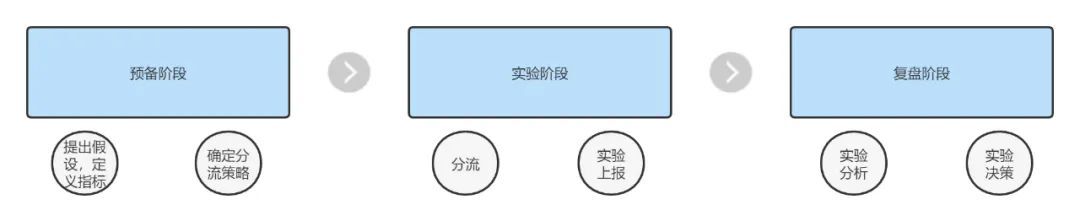
和實驗階段劃分相對應地,我們將實驗平臺劃分為實驗設定,埋點上報和實驗結果分析三個模組,在實驗設定模組,我們根據實驗需求來完成分流設定和業務場景的對映關係。
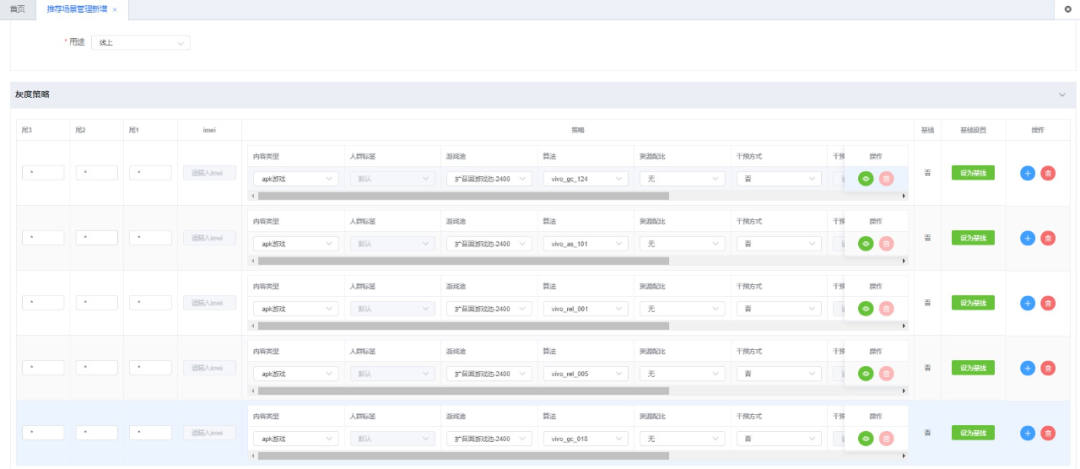
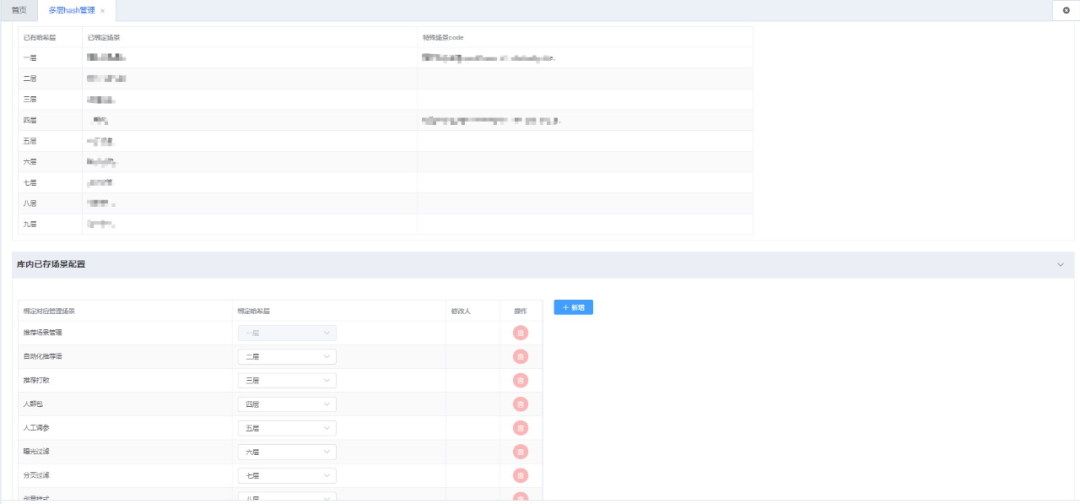
並在hash實驗管理中將業務層級劃分,以便流量的流通。
在埋點上報模組中,我們通過sdk的方式植入業務程式碼中,當流量進入該實驗田時就會進行分析和埋點上報,我們將上報的埋點分為遊戲和請求維度,節省上報流量的同時以滿足不同的分析需求:
遊戲維度:
{
"code": 0,
"data": [
{
"score": 0.016114970572330977,
"data": {
"gameId": 53154,
"appId": 1364982,
"recommendReason": null,
},
"gameps": "埋點資訊",
}
],
"reqId": "20200810174423TBSIowaU52fjwjjz"
}
請求維度:
{
"reqId":"20200810142134No5UkCibMdAvopoh",
"scene": "appstore.idx",
"imei": "869868031396914",
"experimentInfo": [
{
"experimentId": "RECOMMENDATION_SCENE",
"salt":"RECOMMENDATION_SCENE",
"imei": "3995823625",
"sinfo": "策略資訊"
},
{
"experimentId": "AUTO_RECOMMENDATION_REASON",
"salt":"RECOMMENDATION_SCENE",
"imei": "1140225751",
"sid": "3,4,5"
}
]
}
在實驗結果分析模組中,我們將採集的埋點的資料上報只巨量資料側,並由其進行分析計算,其結果指導這我們對實驗策略進行進一步的分析迭代。對於遊戲請求的上報格式,我們可以直接通過appId和gameps的資訊直接分析得出該類遊戲的推薦結果和使用者行為的關係。同時加入請求維度的分析(包含策略資訊),可以直接分析出決策對各項指標的影響。
4.2 召回優化之多路召回
召回在遊戲推薦業務中就是利用一定的規則去圈選一批遊戲,這是為了將海量的候選集快速縮小為幾百到幾千的規模。而召回之後的排序則是對縮小後的候選集進行精準排序,最終達到精準推薦的目的。
然而這種單路的召回在業務上卻有著很大的缺陷:
-
通常為了保證計算效率,圈選的數量在幾百個左右,由於數量限制其無法完全覆蓋完整的目標使用者候選集。
-
隨著業務的複雜度變高,召回策略的種類也開始膨脹,其召回規則是剝離的無法統一,這也意味著在某些業務場景下,在種類上無法覆蓋完全。
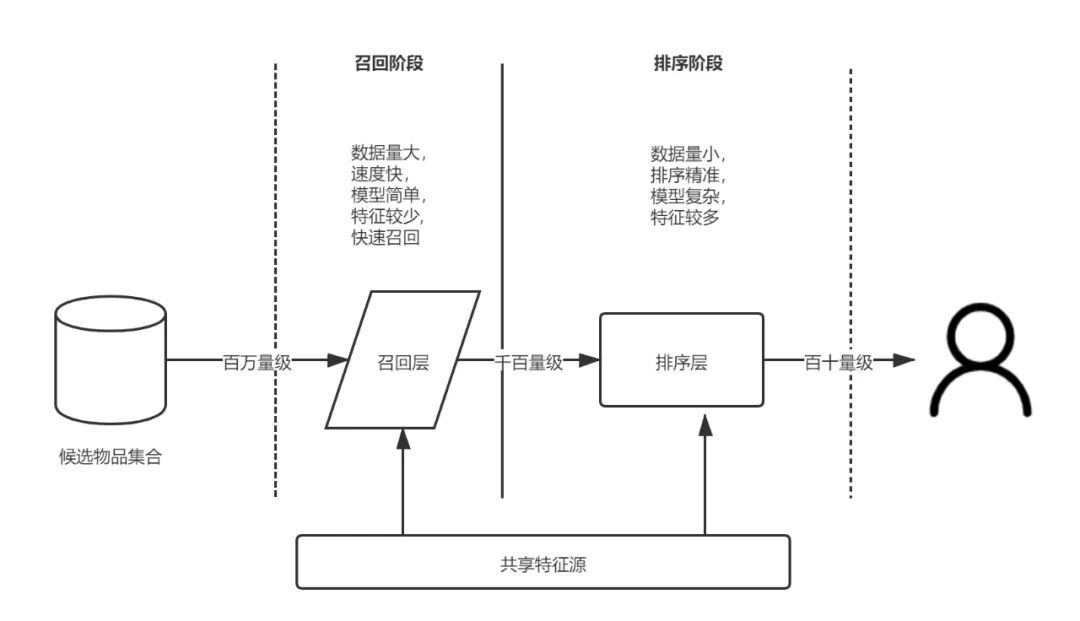
因此,權衡了計算效率和業務覆蓋度(召回率)的問題,我們逐步上線了多路召回功能。
在業務實現上,多路召回相容了原有的個性化召回、演演算法召回、遊戲池召回、分類/標籤/專題/同開發者)召回等召回路徑,通過圈選多個遊戲池做為召回策略,經過合併、過濾、補量、截斷等策略最終篩選出一批進行演演算法預估打分的遊戲。
本質上,多路召回利用各簡單策略保證候選集的快速召回,從不同角度設計的策略保證召回率接近理想狀態。
4.3 曝光干預之動態調參
一個推薦系統的效能如何,除了運營策略之外很大程度上取決於推薦演演算法的結果,而推薦演演算法的結果又是以曝光量,下載量,ctr等作為評價指標的。所以在遊戲推薦業務的生命週期中,推薦演演算法一直致力於優化這些指標。
但是在開發中有個實際問題就是,從演演算法結果的資料反饋,到程式碼改進上線這個時間週期較長,對一些需要快速響應的業務場景來說是不符合要求的。因此我們需要一套規則來對線上的演演算法結果做動態調整,以滿足業務的要求,這就是動態調參。
目前遊戲業務的營收中,曝光量是個極其重要的指標,而大盤在一段時間內的曝光量是確定的,太多或太少都會嚴重影響業務,由此推薦演演算法就會根據線上實時反饋的一些資料對遊戲的曝光進行調整。
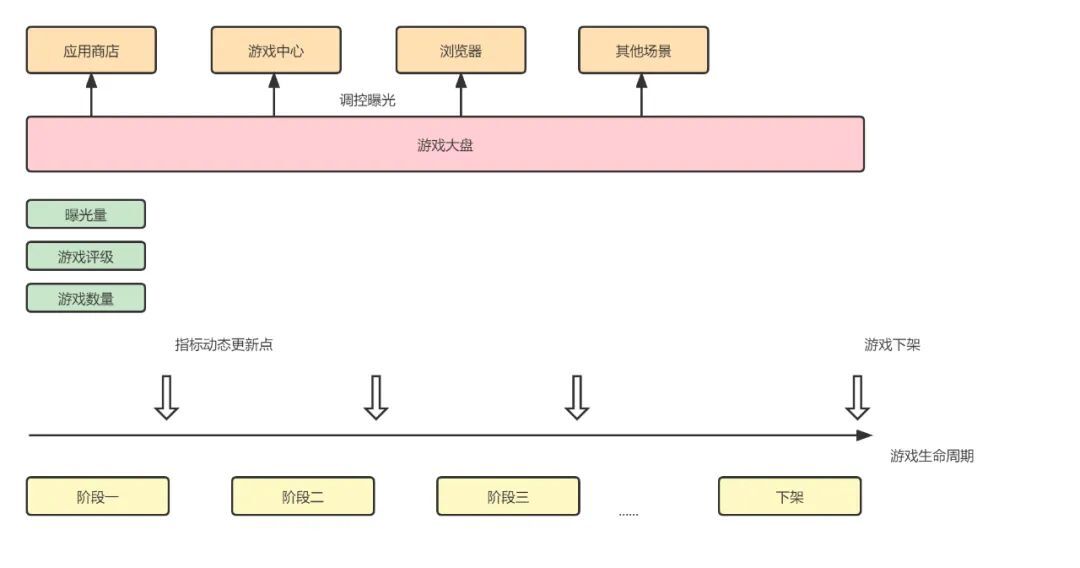
經過設計, 我們先將調參遊戲劃分為多個等級,並將遊戲的生命週期劃分為幾個時間段,同時在每個時間段內以遊戲曝光量,評級,數量等因素作為計算因子來計算曝光的分配權重。
接著系統根據實時採集的遊戲曝光資訊及所計算的遊戲目標曝光對實際曝光進行調整,最終實現遊戲曝光的動態調控。
對於正向調控來說,動態調參就是最有效的扶持機制,增加了遊戲曝光的同時提升了導流能力。對於負向調控,動態調參能對品質和要求不達標的遊戲,通過減少曝光的方式進行打壓,提升使用者體驗。
五、展望之智慧化建設
經過多年的探索實踐,遊戲推薦系統成就了一套完整的推薦體系。
在架構上的演進使得我們能更好地應對複雜多變的業務需求,在精細化運營上的探索與建設令我們能更加敏銳地把握住市場的變化以做出響應,這些建設也很好地反饋的反饋到了業務結果中,提升了眾多效能和收益指標,得到了業務方的一致好評。
但當分發效率和收入效益問題解決了之後,我們在思考自己還能做什麼,原先遊戲推薦做的比較多的是接入服務,在單鏈路上去做閉環提高效益,但這是遠遠不夠的。
在未來我們會考慮如何打造覆蓋搜廣推+ 智慧運營的全棧業務支撐系統(智慧禮券,智慧push,使用者反饋智慧處理系統),以提升平臺和渠道的價值。