推薦系統[八]演演算法實踐總結V0:騰訊音樂全民K歌推薦系統架構及粗排設計
1.前言:召回排序流程策略演演算法簡介
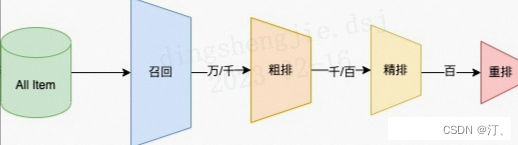
推薦可分為以下四個流程,分別是召回、粗排、精排以及重排:
- 召回是源頭,在某種意義上決定著整個推薦的天花板;
- 粗排是初篩,一般不會上覆雜模型;
- 精排是整個推薦環節的重中之重,在特徵和模型上都會做的比較複雜;
- 重排,一般是做打散或滿足業務運營的特定強插需求,同樣不會使用複雜模型;
-
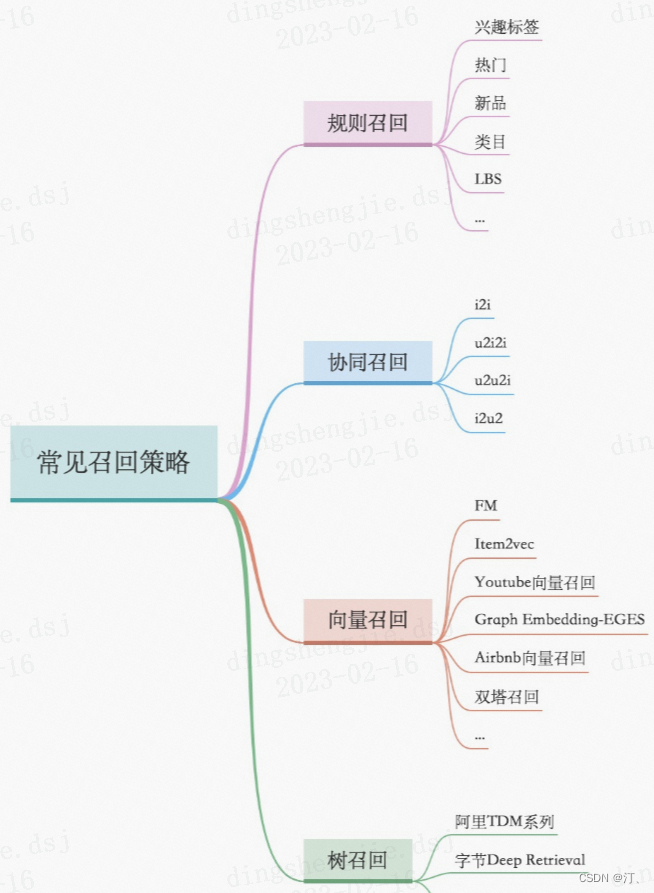
召回層:召回解決的是從海量候選item中召回千級別的item問題
- 統計類,熱度,LBS;
- 協同過濾類,UserCF、ItemCF;
- U2T2I,如基於user tag召回;
- I2I類,如Embedding(Word2Vec、FastText),GraphEmbedding(Node2Vec、DeepWalk、EGES);
- U2I類,如DSSM、YouTube DNN、Sentence Bert;
-
模型類:模型類的模式是將使用者和item分別對映到一個向量空間,然後用向量召回,這類有itemcf,usercf,embedding(word2vec),Graph embedding(node2vec等),DNN(如DSSM雙塔召回,YouTubeDNN等),RNN(預測下一個點選的item得到使用者emb和item emb);向量檢索可以用Annoy(基於LSH),Faiss(基於向量量化)。此外還見過用邏輯迴歸搞個預估模型,把權重大的交叉特徵拿出來構建索引做召回
-
排序策略,learning to rank 流程三大模式(pointwise、pairwise、listwise),主要是特徵工程和CTR模型預估;
- 粗排層:本質上跟精排類似,只是特徵和模型複雜度上會精簡,此外也有將精排模型通過蒸餾得到簡化版模型來做粗排
- 常見的特徵挖掘(user、item、context,以及相互交叉);
- 精排層:精排解決的是從千級別item到幾十這個級別的問題
- CTR預估:lr,gbdt,fm及其變種(fm是一個工程團隊不太強又對演演算法精度有一定要求時比較好的選擇),widedeep,deepfm,NCF各種交叉,DIN,BERT,RNN
- 多目標:MOE,MMOE,MTL(多工學習)
- 打分公式融合: 隨機搜尋,CEM(價效比比較高的方法),線上貝葉斯優化(高斯過程),帶模型CEM,強化學習等
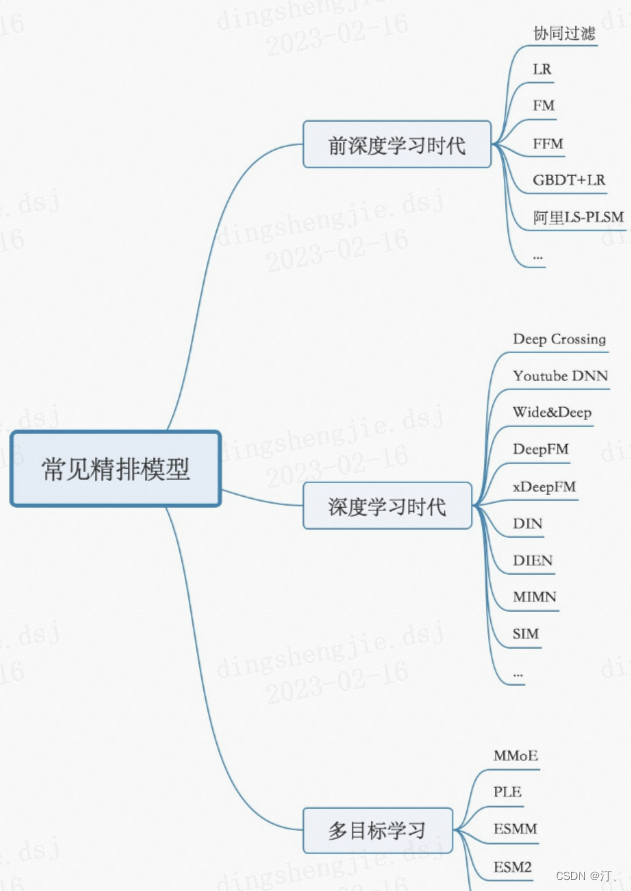
- 粗排層:本質上跟精排類似,只是特徵和模型複雜度上會精簡,此外也有將精排模型通過蒸餾得到簡化版模型來做粗排
-
重排層:重排層解決的是展示列表總體最優,模型有 MMR,DPP,RNN系列(參考阿里的globalrerank系列)
-
展示層:
- 推薦理由:統計規則、行為規則、抽取式(一般從評論和內容中抽取)、生成式;排序可以用湯普森取樣(簡單有效),融合到精排模型排等等
- 首圖優選:CNN抽特徵,湯普森取樣
-
探索與利用:隨機策略(簡單有效),湯普森取樣,bandit,強化學習(Q-Learning、DQN)等
-
產品層:互動式推薦、分tab、多種型別物料融合
2.業務背景
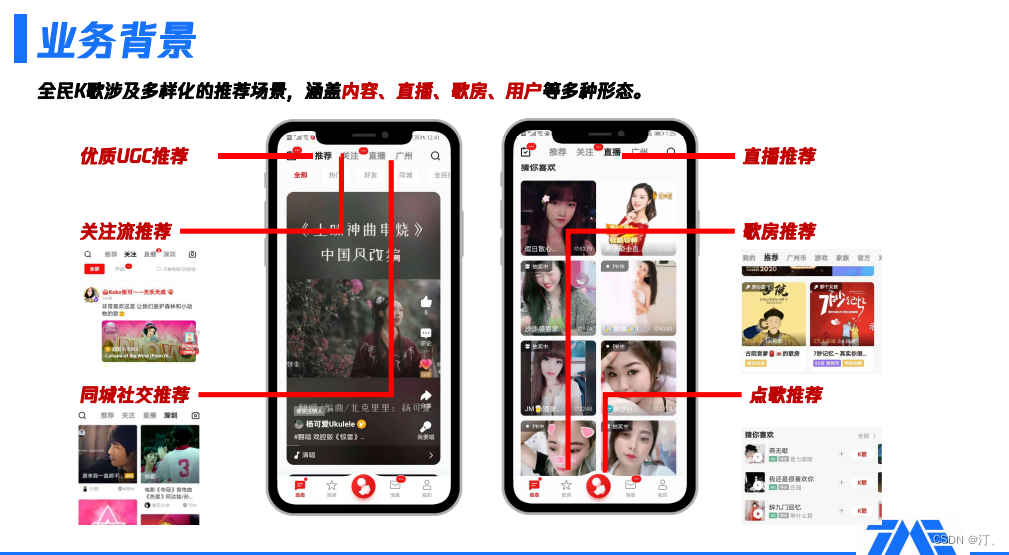
全民K歌涉及多樣化的推薦場景,涵蓋內容、直播、歌房、使用者等多種形態。
具體的推薦功能如上圖所示,主要包括以下幾類:
① 基於內容的推薦,包括優質UGC推薦、關注流推薦、同城社交推薦等功能模組。
-
優質UGC推薦,將平臺原生原創的優質音視訊內容進行推薦
-
關注流推薦,對關注的內容進行混排
-
同城社交推薦,基於同城的社交進行推薦
② 除了內容推薦外,我們也會負責一些其他型別的推薦,包括直播推薦、點歌推薦、歌房推薦和點評推薦,都是在K歌生態下獨有的推薦。
3.推薦系統架構及挑戰
推薦系統主要分為四個部分,包括召回層、粗排層、精排層及重排層。
3.1召回層
召回層的作用主要是從海量的item中篩選小量級的使用者可能感興趣的內容。在這個模組中最重要、大家瞭解最多的肯定就是召回模組本身。
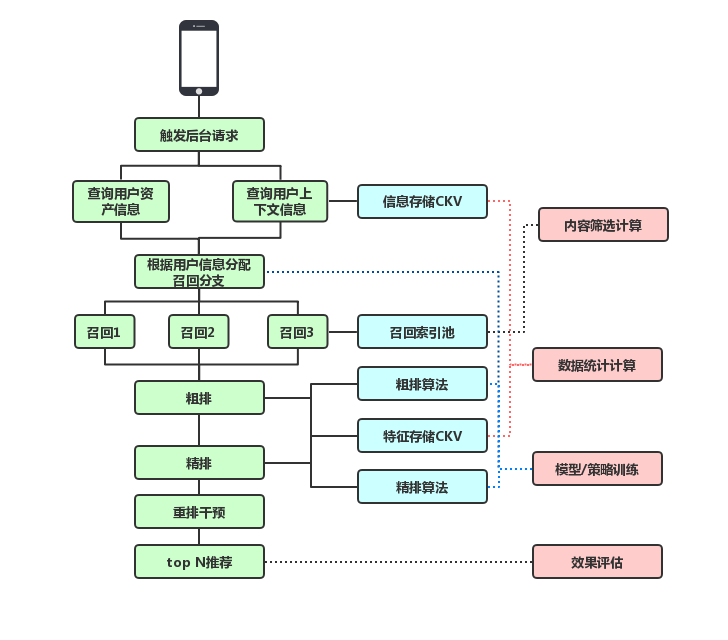
一般來說,我們線上的召回方法會分為索引類的召回、泛社交的召回以及模型的召回。
-
索引類的召回:主要根據畫像的結果做精準的ID類召回,比如對使用者感興趣的歌曲進行召回,以及使用者感興趣的創作者進行召回。
-
泛社交的召回:主要基於使用者在站內豐富的社交關係,比如使用者可能會關注一些其他的使用者,也可能加入一些家族,我們會根據這些社團的發現結果做泛化召回。
-
模型的召回:基於模型的召回的方法比較多,在後面會展開介紹。
除了召回模組之外,我們在召回層認為另外一個比較重要的是內容的比例篩選,因為我們整體的內容發表量比較大,每天可能有500萬的作品在平臺內發表,如何從中篩選出合適的內容,需要基於音視訊的理解,以及基於我們自己的流量策略來綜合發現。
3.2 粗排層
粗排層到精排層相當於是一個承上啟下的作用,它會把我們召回到的一些萬量級的作品進一步篩選到千量級,既要考慮打分的效能問題,又要考慮排序粗排精準度的問題。一般來說,粗排模型會用一些模型蒸餾的方法,包括特徵蒸餾或者基於模型本身的結構蒸餾,以及把這些不同的蒸餾方法組合起來等等。在粗排層,除了做粗排的打分外,我們還會重點做生態的控制,特別在一些內容推薦場景或者直播推薦場景中,我們會注重這裡面的內容生態,包括時效性,內容的調性,多樣性等等。
3.3 精排層
粗排層之後就來到了精排層,精排層主要根據千量級的作品進一步的進行精排打分來篩選到百量級的作品。在精排層,我們主要注意以下幾方面:
-
一個就是精排模型本身,我們早期也採用了類似LR的線性模型和LightGBM這樣的樹模型,之後隨著深度模型的技術發展,我們所有的場景都切換到了深度模型,並且隨著深度網路的設計複雜度,以及樣本規模的逐步增加,讓早期基於TF訓練的一些深度模型引擎,在訓練的速度以及對模型大小規模的限制,已經對我們產生了影響。所以我們現在已經過渡到基於引數伺服器框架下,訓練深度模型。
-
在精排前,除了模型怎麼訓練構造外,另外兩個比較重要的是特徵和樣本的構造,以及在這個場景下的多目標設計。特別是多目標的問題,可能還涉及到具體的網路結構如何做,以及最後的結果如何融合。
- 重排層
從精排層排序出百量級的作品後,就會進入到重排層。重排層會基於業務規則進行進一步的干預,比如同一首歌曲的視訊不能連續出現,同一個創作者的視訊不能連續出現等等。除了基於規則性的限制外,我們也會考慮使用模型化的方法做多樣性的打散,並且在第4部分,我們也會具體介紹DPP演演算法的原理和思想。除了模型方法之外,我們也在考慮通過list wise的方法做內容的重排。
4.粗排模組演演算法設計
4.1 粗排模組定位和方案路線
粗排模型和精排模型不同,它可能既需要解決模型預測的準確性,又需要解決模型預測的效率。接下來,為大家介紹我們整個推薦系統如何線上上真實運轉。
粗排模組主要包含兩部分:
-
第一部分是粗排的排序部分,這一部分主要就是為了解決一個大規模item的預排序問題。
-
第二個部分是多樣性控制部分,作為一個UGC平臺,我們需要考量內容在整個內容生態中的分發狀況,以及均衡的考量生產者跟消費者之間的關係。我們是通過多樣性調節演演算法來間接實現這個目的的。
讓我們再回顧下前面所提到的整個召回系統架構,我們可以看到它其實是一個典型的節點架構,從內容發現到召回,到粗排到精排,然後重排,最後把合適的內容推薦給使用者。由於我們是一個比較大的UGC生產平臺,從一個UGC平臺的角度來考慮,我們傾向於分發較為新的作品,因為新的作品的分發會為那些活躍的創作者帶來一定的流量激勵,使得生產端跟消費端產生聯動,促進了一種正向的迴圈。
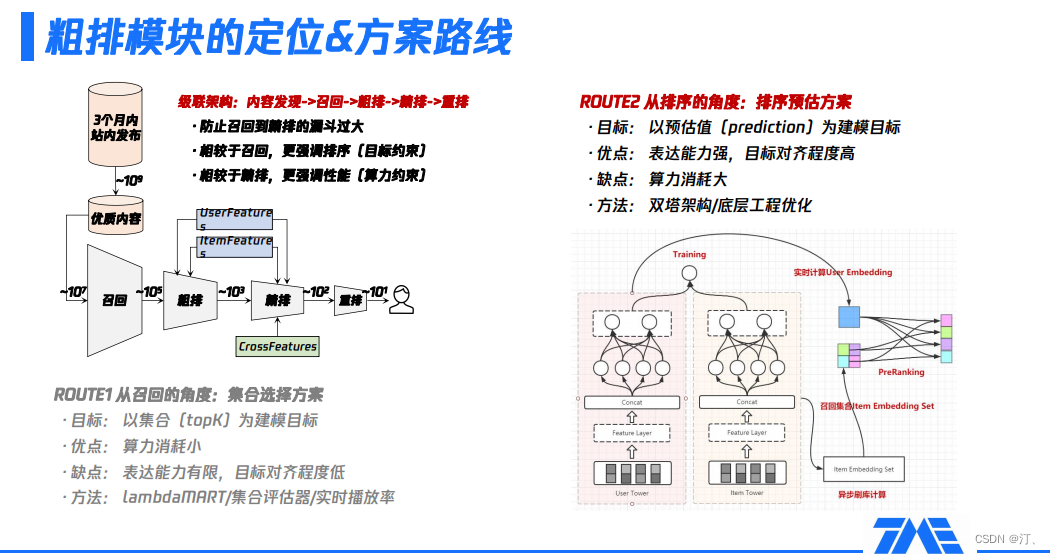
我們以三個月內的站內釋出作品為例,三個月內的站內釋出作品大概會到十的九次方量級,然後我們通過一些內容挖掘跟優質內容發現的方式,從中找到更為優質的一部分內容,這部分內容仍然有十的七次方量級,相當於從百萬量級的作品庫做興趣的召回。這是一個非常大的候選集場景,從優質內容的發現到召回,是整個UGC平臺和推薦系統的連線,背後承載著我們對整個UGC的分發、內容生態的理解。這一部分我們會在第三個環節去做進一步詳細的介紹。召回可以看到有十的七次方的候選集召回,通常完成召回過程之後仍然有十的五次方候選集,而精排通常只能去處理一個千級別的規模,所以我們看到這中間存在一個比較大的漏斗,很多時候會成為我們在效果或者一些收益上的瓶頸。這時,粗排模組的重要性就體現出來了。粗排模組的一個重要的作用就是防止召回到精排之間的漏斗過大,導致過多的資訊損失。
大家可能比較瞭解的是,召回跟精排召回更像是一個集合,選擇的過程更側重於選擇效率最高的方法,至於topk中item之間的先後順序,其實不是最關心的因素;而精排環節相對來說它更強調次序,也就是說item A跟item B的先後順序是非常敏感和關鍵的。
粗排夾在召回跟精排之間,它的定位是什麼?相比於召回,粗排更強調排序性,也就是更強調topk內部的排序關係;相對於精排,粗排更強調效能,因為精排通常有非常複雜的網路結構,非常大的引數量,這也意味著它在實際應用的過程中比較難去處理一個較大規模量級的候選集的打分,這時粗排就必須要解決這個問題,所以它在效能上會相較於精排有更多的要求。現在主流的粗排方案有兩條路線,這兩條路線是基於兩個出發點來思考的:
-
第一條路線是把粗排當成是召回的一種延伸,它的技術選型會像是一種集合,選擇的方案和目標是選出效率最高的子集。常用的方式,簡單的可以通過實時的serving或者一些實時的指標對召回排序的結果做一個選擇。總體來說,這條技術路線最大的優點是算力消耗非常小、效能非常好,但是它的缺點是本身的表達能力是有限的,可以明顯預估到它的天花板。
-
第二條路線是從精排的角度,把粗排當成是精排的遷移或壓縮,也就是說這是一條排序的路線,它的建模目標是預估值。這種方法的好處是它的表達能力很強,因為通常會用到一些比較複雜的網路結構,而且它跟精排的聯動性是更好的,可以讓粗排跟精排的目標保持某種程度上的一致性。同時,它的缺點也凸顯出來了,就是我們用到了複雜的方法,算力的消耗一定也會相應的提升。因此,需要著重解決的是如何在有限的算力下儘可能地突破錶達能力上限。在這種路線下,我們通常會在架構選擇上選擇雙塔結構模型。
4.2 粗排雙塔模型實踐
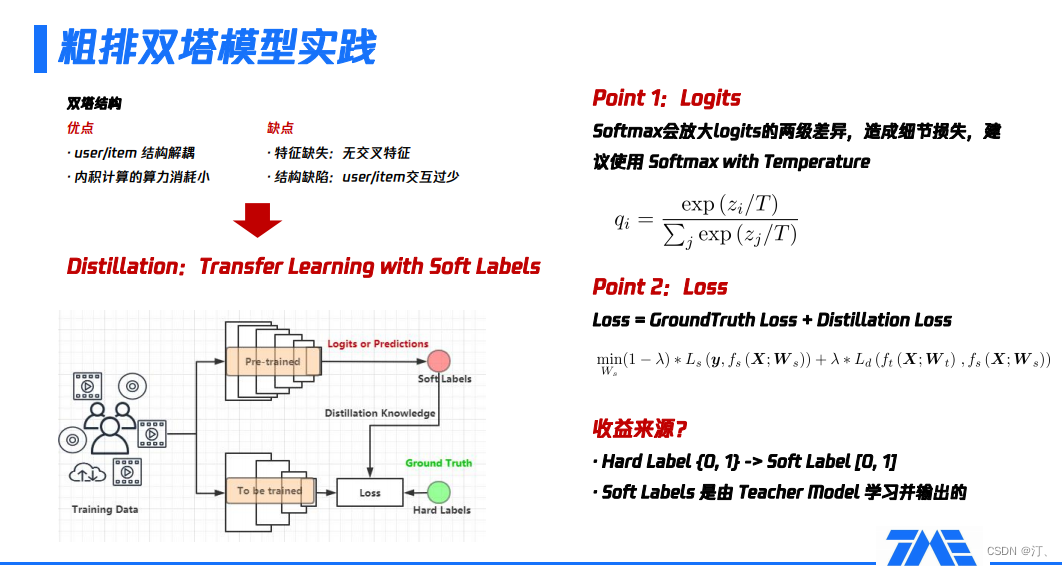
我們通過把user和item的feature進行結構解耦與分開建模,然後完成整個架構的設計,在模型訓練完畢之後,我們會通過user serving實時的產出user embedding,再通過索引服務把該使用者所有的候選集合的ID給取出來,最後在userembedding跟item embedding之間做內積的運算,得到一個粗排的預估值,作為整個粗排階段的排序依據。
這麼做的優勢是user/item 結構是解耦的,內積計算的算力消耗小。
同時,它的缺點也非常的明顯:
-
第一個是它在特徵表達上是缺失的,因為user跟item解耦之後,很難使用一些交叉特徵,一旦用了交叉特徵,有多少item就得進行多少次預估,這違背了我們使用雙塔模型的初衷。
-
第二個是它在結構上也是有缺陷的,我們回憶一下上面這幅框架圖,可以看到user跟item的互動非常少,這會限制它的表達能力的上限。
如果我們選擇了這種技術方案,我們可以保障它的效能,但是我們需要進一步的考慮如何避免這種簡易的結構所帶來的效果上的損失。在這種情況下,我們通常會使用一些模型蒸餾的方式。
模型蒸餾有兩個關鍵詞,第一個是它本質上是一種遷移學習,也就是transfer learning,第二個是transfer的方式是通過所謂的label,區別於我們平時理解的樣本label離散值,變為了0到1之間的一個連續值。常見的蒸餾模型架構,會有涉及到兩個模型,第一個模型叫做教師模型,叫做teacher,第二個模型是學生模型,叫做student。這兩個模型的總體思路是teacher模型是一個非常大、非常複雜、學習到的東西非常多的模型,teacher模型會把學習到的知識傳導給student模型,受限於某些原因,該模型沒有辦法做得很複雜,或者它的規模必須限制在一定範圍內的子模型。
具體流程如下:
-
準備訓練樣本,對teacher模型預訓練,即得到了teacher模型;
-
把teacher模型最後一層或倒數第二層的輸出結果,作為傳遞給student模型的資訊,這部分通常是logits或softmax的形式,也叫做soft labels;
-
把soft labels傳導到student模型,作為模型loss的一部分,因為student模型除了要擬合teacher模型傳遞的資訊,也要去擬合樣本真實的分佈。
針對上述流程裡涉及到了幾個概念,有如下的進一步解釋:
- 關於logits:它是teacher模型層層對映後的一個抽象度很高且資訊濃度很大的結果,是整個知識傳遞的媒介。在logits後,通常會接一個softmax,但是softmax會放大logits的兩極差異,造成細節損失,而這些細節恰恰是幫助student模型更好學習的關鍵。為了克服以上問題,我們選用了改進的softmax,即softmax with temperature
$q_i=\frac{\exp \left(z_i / T\right)}{\sum_j \exp \left(z_j / T\right)}$
這裡,引入一個超引數T控制整個softmax分佈的陡峭或平滑程度,間接控制蒸餾的強度。通常,T要設定成多少沒有一個定論,與實際場景相關,依賴相應場景下的一些實驗設計。
- 關於loss:預訓練好teacher模型後,轉而關注student模型,它的最小化loss由兩部分構成,一部分是儘可能擬合teacher模型的輸出結果,另一部分是儘可能擬合真實樣本。由於student模型的表達能力有限,直接用student模型擬合真實樣本可能學不好或者學偏;teacher模型傳遞過來的資訊對student模型做了約束和糾正,指導student模型的優化方向,進而加強了student模型的學習能力。
整個模型蒸餾的收益表現如下:
引入soft labels的概念,不再是原本的非零即一狀況,需要考慮正樣本有多正和負樣本有多負。這看起來類似把分類問題轉換成迴歸問題,但實質並不是。如果構建樣本時,用迴歸的方式構建,通常會基於作品的完播率或規則組合等,人工敲定樣本的迴歸值,這種方式過於主觀,沒有一個非常合理或可矯正的指標進行後續比對;而模型蒸餾的soft labels是基於teacher 模型,即由teacher 模型對真實樣本進行充分訓練後給出,包含更多的隱含資訊且不受人為主觀因素影響。
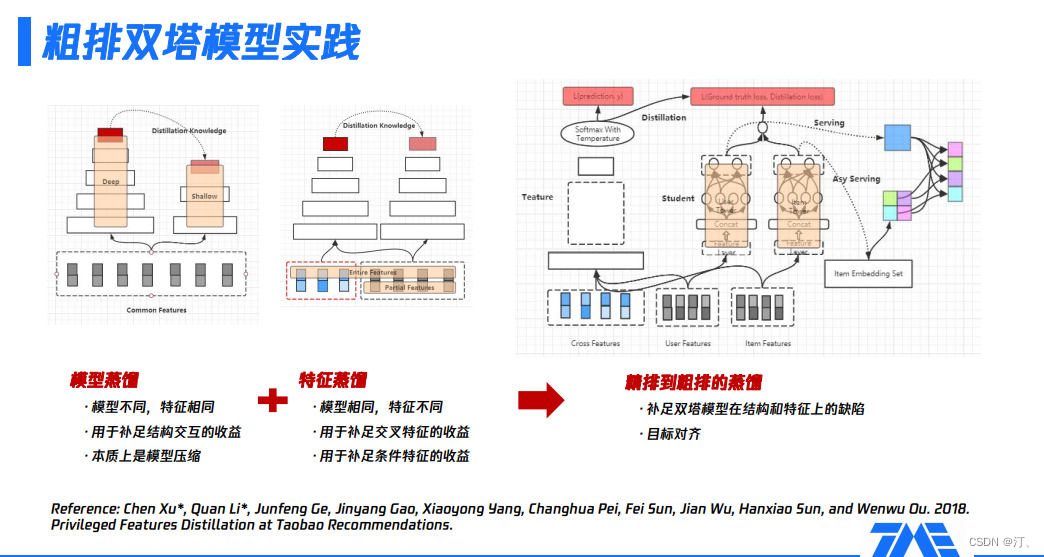
具體的,來看看我們如何做粗排模組的蒸餾,主要是分為兩個大的方向:
-
模型蒸餾,主要適用於模型不同但特徵相同的情況,比如,包含多個場景的框架裡,某些場景對效能有要求;由於有一些額外的外部限制,使某場景無法用很複雜引數量非常大的模型,可以用一個子模型使用全部特徵。此時,模型蒸餾主要是彌補子模型缺少複雜結構或互動結構導致的部分收益損失,本質上是一種模型壓縮方案。
-
特徵蒸餾,主要適用於模型相同但特徵不同的情況,比如,在某些場景,無法使用全量特徵 ( 如交叉特徵 ) 或部分特徵必須是剪裁過的,即特徵沒被完全利用,存在一部分損失。這時,通過一個更大的teacher模型學習全量特徵,再把學到的知識遷移到子模型,即彌補了上述的部分特徵損失。
基於以上描述可知,粗排模組可以通過蒸餾的方式,補足雙塔模型在結構和特徵上的缺陷。接下來的問題就是如何找到一個合適的teacher模型?精排模型通常是一個被充分訓練的、引數量很大、表達能力很強的模型,如果通過蒸餾精排模型獲取粗排模型,那麼目標的一致性和學習能力的上限都符合我們預期的。
-
teacher模型是精排模型,該模型使用全量的特徵,包括三大類,即user側特徵、item側特徵及它們的交叉特徵;曲線框裡是一些複雜的拓撲結構;最後的softmax with temperature就是整個精排模型的輸出內容,後續會給到粗排模型進行蒸餾。
-
中間的粗排模型,user tower只用user features,item tower只用item features,即整體上看,模型未使用交叉特徵。在user tower和item tower互動後,加上精排模型傳遞過來的logits資訊,共同的構成了粗排模型的優化目標。整個粗排模型的優化目標,同時對真實樣本和teacher資訊進行了擬合。
-
右側展示的是訓練完粗排模型後,線上上產出user serving,通過user serving產出user embedding,再與item embedding做內積運算,完成整個排序的過程。上述流程即實現了粗排和精排的聯動過程,並且訓練完粗排模型就可以進行一個非常高效的serving,進行粗排排序。
4.3. 線上的粗排雙塔模型
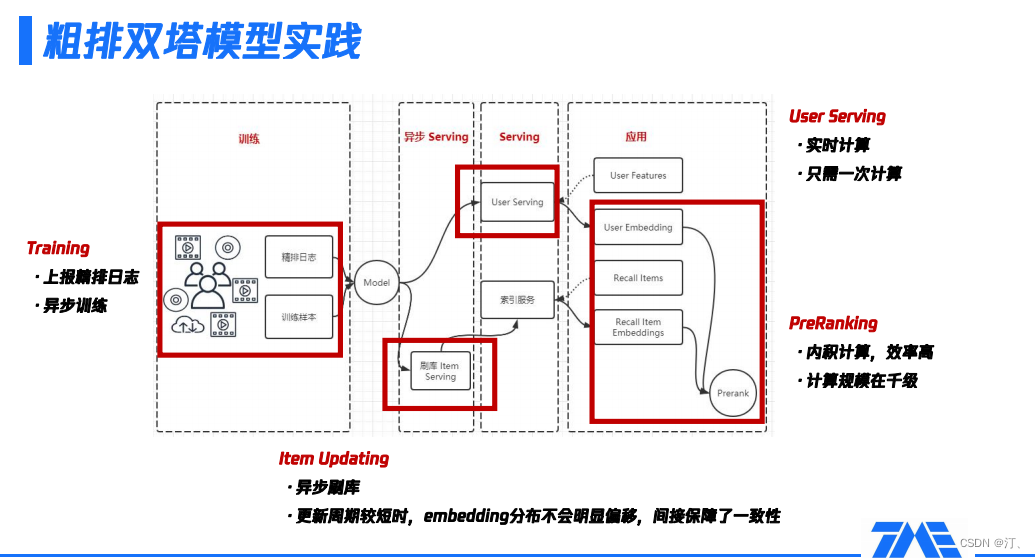
實踐中,粗排模型訓練時,依賴的精排輸出結果來自上報精排紀錄檔。如果在離線重新對樣本進行預估再輸出,其實是對線下資源的浪費,所以通常線上上精排預估時,就把一些結果作為紀錄檔進行上報。粗排模型非同步訓練,產出模型提供給Serving。
Serving環節主要包括非同步Serving和User Serving兩部分,具體功能如下:
-
非同步Serving,主要通過刷庫Item Serving捕獲所有的item embedding,以非同步的方式反覆刷庫。大家經常會問的一個問題:如果模型更新了,item embedding有的是新的,有的是舊的,版本不一致怎麼辦?如果更新週期比較短,item embedding的分佈不會發生較明顯的偏移,即相鄰版本比較接近,這間接保障了一致性,不需要版本是強一致性的,只要更新週期比較短就可以。
-
User Serving,當用戶請求推薦引擎後,獲取該使用者的user features,然後請求User Serving產出user embedding;同時,會拿到該使用者的所有召回item集合,基於刷庫結果產出的索引服務,取到所有的item embedding。由此可見,User Serving的最大優勢是可以做實時計算且只需計算一次,效率非常高。並且,雙塔粗排Serving階段是做內積運算,這種高效的計算方式也使它更適合大規模的預排序場景。

整個粗排模組上線後,我們關注的兩類指標:互動類指標和播放類指標,都有非常明顯的正向提升,具體的指標提升幅度可以參考上圖的線上實驗結果。
一般,粗排模組的表現和實際場景有較大的相關性:在候選集非常大的推薦場景下,粗排到精排間的漏斗有好幾個量級,這時粗排模組會帶來非常顯著的收益;在候選集比較小的推薦場景下,從召回到精排間的漏斗不是很大,這時粗排的收益可能就比較有限。
4.4 進一步優化

-
首先,上述粗排蒸餾過程本質上是pointwise,但通過上報精排紀錄檔可以拿到精排模型給出的完整再推薦列表,用pairwise學習精排排出來的序,可以進一步逼近精排結果,能更多的提取精排傳遞出的資訊。
-
其次,前面雖然不斷地用teacher模型和student模型描述整個過程,但實際效果上student模型不一定低於teacher模型。換一個角度,student模型其實是基於teacher模型做進一步訓練,所以student模型的表徵能力有可能超過teacher模型。事實上,如何讓student模型通過反覆的蒸餾,效果超過teacher模型,在模型蒸餾領域也有許多相關方法。
-
最後,粗排到底是召回的延伸,還是精排的壓縮跟前置?雖然召回和精排都是一個檢索的過程,但二者實際側重點還有一些不同,比如,召回在多樣性上有更多的考量,精排更強調排序次序的精準性,而粗排處於這兩個環節之間,如何利用粗排模組更好地平衡召回和精排?通常而言,會考慮設計多樣性調節演演算法解決這一問題。
5.多樣性調節演演算法設計
5.1 推薦多樣性的意義

樣性的概念在推薦系統裡常被提到,在不同視角下,推薦多樣性對應著不同的問題。
-
在系統角度下,多樣性是一種popularity bias,即流行度的偏置。流量在UGC作品上的分佈,體現了系統層面的多樣性:一個多樣性弱的系統,更像是中心化分發的,只分發非常頭部、非常類似的一部分作品;而一個多樣性強的系統,則是一個去中心化分發的,會更多地兼顧中長尾內容流量的供給。實際上,在推薦系統中普遍會遇到如下問題:如果沒有對推薦系統做額外的干預和糾偏,不可避免地會使推薦系統往多樣性弱的方向發展。從資料層面解釋,有豐富資料的那部分內容會在推薦過程被反覆加強,使整個推薦迴圈鏈路越縮越小,馬太效應越來越嚴重。對於一個ugc平臺,需要考量生產者或創作者的利益,而這種聚集在部分創作者身上的馬太效應是我們不願意看到的。
-
在使用者角度下,多樣性就是Explore&Exploit問題,對使用者做興趣的探索與聚焦。如果多樣性弱,推薦的item同質化嚴重,都很像,那麼推薦系統可能沒辦法發現使用者的真實興趣,因為系統可能都沒給使用者推薦過這類item;如果多樣性強,那麼使用者的推薦流裡的內容會很不一樣,壞處可能是使用者在持續消費過程的興趣聚焦程度不同,比如使用者看了五個item,明明對其中某一兩個item更感興趣,但和這一兩個item相似的item的後續推播密度卻跟不上,這對使用者體驗是有損的。如果不做額外的優化,使用者角度的多樣性會越來越小,因為通常選用的pointwise模型會導致同質化的現象,比如說使用者喜歡的item是樂器類的,則pointwise在每一個單點上的預估都覺得樂器是最好的,最後可能連續給使用者推了5個樂器,在單點上收益最高不代表使用者對整個推薦結果 ( 5~10個item ) 的滿意度是最高的,所以這裡也需要做多樣性控制,提升使用者的滿意度。
5.2 多樣性控制的方案路線
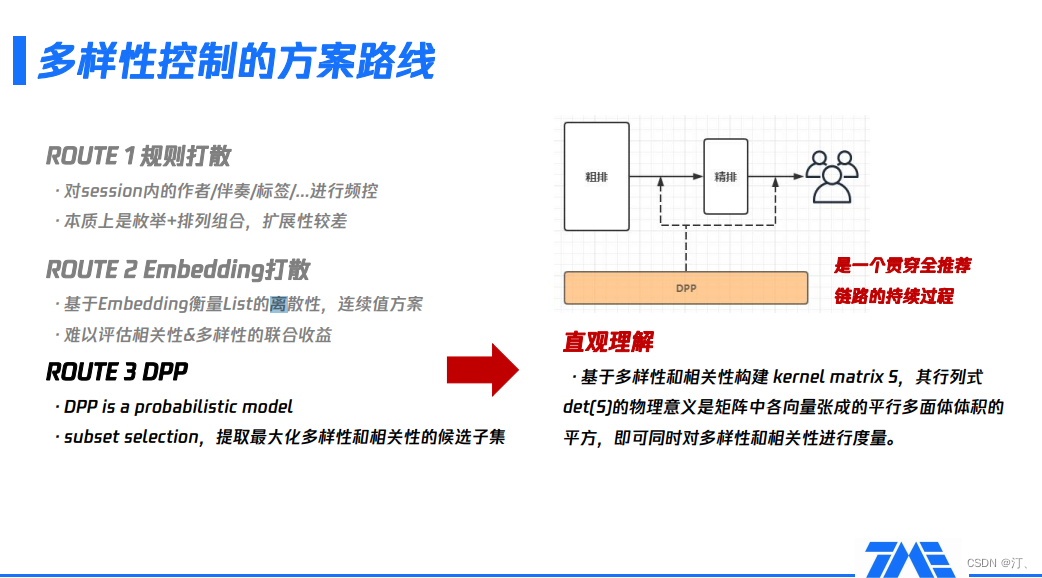
在具體實現上,多樣性有三個主流的技術方案:規則打散、embedding打散和DPP,下面會詳細介紹:
-
基於規則打散,比如從item裡抽象出發布作者、標籤、伴奏等特徵,基於這些特徵去做一個session內的頻控。這種方法的好處是易實現,缺點也非常明顯,該方案本質上是進行列舉加排列組合,擴充套件性非常差,永遠沒辦法列舉所有可能的情況,列舉出來的情況不一定能真實表徵兩個item間的相似或差異程度有多大。
-
基於embedding打散,一個連續值的方案。好處是它可以基於embedding對候選集做離散性的評估,相當於此時可以用向量化的方式表達item。缺點在於它雖然可以衡量離散性或多樣性,但難以衡量相關性,從而無法實現聯合的收益評估。事實上,多樣性只是我們的一個目標,相關性也很重要,如果推了很多不同的東西,但和使用者不怎麼相關,可能會適得其反。
-
DPP概率模型,本質上是一種集合選擇技術,選擇出一個子集使得多樣性和相關性聯合建模的收益最大。直觀理解,先基於多樣性和相關性構建一個矩陣,該矩陣行列式的物理含義是矩陣中各向量張成的平行多面體體積的平方,這樣就把問題轉換成了一種可度量的方式:要想同時最大化多樣性和相關性,只需要最大化平行多面體的體積。
5.3 DPP 技術細節

DPP演演算法的具體實現比較複雜,這裡主要介紹兩個關鍵點:
①基於多樣性和相關性構建矩陣L,該矩陣的行列式等價於最終要度量的目標。如何去定義相關性和多樣性?
-
多樣性(diversity)是指兩個item相似不相似,如果很相似就不多樣。利用兩個item各自的item embedding計算內積,即表示兩個item的相似度。
-
相關性(relativity)是一個候選item與當前使用者的匹配程度。在不同環節的實現有差異:在粗排層的DPP,一般是基於user embedding和item embedding計算內積。在精排層的DPP,需要精排的CTR或CVR預估結果,因為這些預估結果反映了當前使用者對候選item的喜愛程度。
基於上述定義的相關性和多樣性就可以構建矩陣L:使用者與itemi的相關性 ( 偏好程度 )、使用者與itemj的相關性 ( 偏好程度 )、itemi與itemj的多樣性三者乘積。通過最大化矩陣L,就可以實現相關性和多樣性的聯合度量。
②如何優化求矩陣L行列式的複雜度,該行列式的原始計算複雜度是三階,線上難以支撐這樣的運算效能消耗,可以通過貪婪演演算法把計算複雜度進一步降低至一階。
-
先進行矩陣分解,基於分解的結果將計算複雜度降低到二階。
-
用增量的方式更新引數,繞過求解線性方程組的部分,將複雜度進一步降低到一階。
由此,行列式的求解過程由三階降低到一階,滿足了線上的效能,上圖最下方給出的paper就是相關方向的論述。
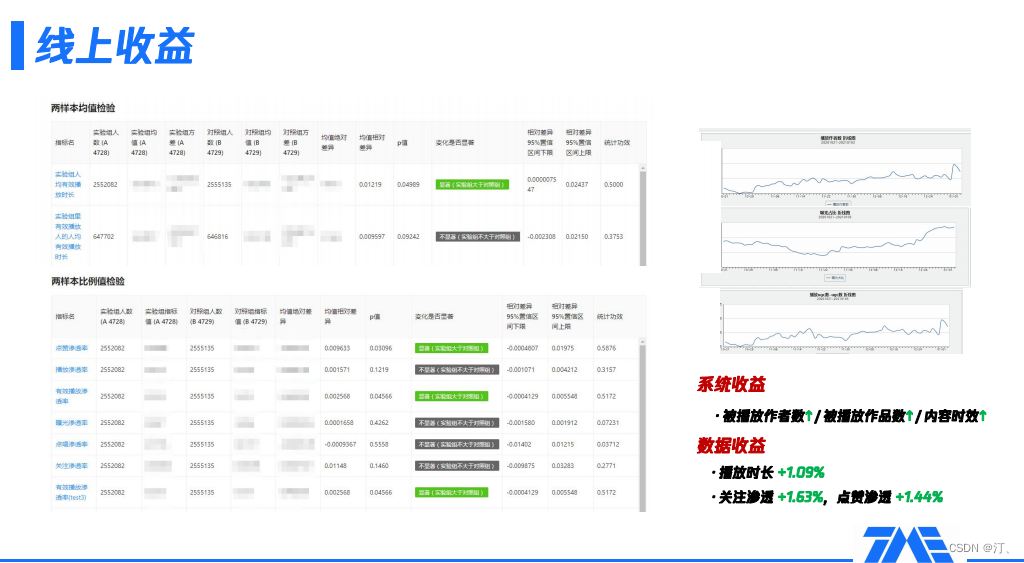
線上上做多樣性的相關實驗,我們較關注的系統和資料兩部分,都有明顯收益:
-
系統收益,作為一個ugc平臺,會考量推薦系統分發覆蓋了多少創作者、覆蓋了多少作品以及內容的時效性,從上圖右側三條曲線可見,在加入多樣性的控制後,三個指標都有穩步的提升。
-
資料收益,有關播放時長、關注滲透、點贊滲透相關的指標都有1~2個點的提升,這也體現了多樣性是有必要的,因為它相當於對pointwise進行了簡單的listwise化,形象化闡述就是,使用者瀏覽多個session時,多樣性調節避免了同質化內容扎堆。
5.4 DPP優化

針對上述基於多樣性和相關性構建矩陣L的過程,有兩方面可以做進一步優化:
-
多樣性本質上是定義什麼樣的item是相似的,用相似矩陣刻畫這種相似關係。在我們K歌平臺,會做一些內容的混排,比如音訊跟視訊的混排,如果在原始的item embedding構建出來的item similarity matrix基礎上,加入一些預設的先驗資訊,判斷什麼樣的item是更相似的,比如音訊跟音訊間更相似,視訊跟視訊間更相似,那麼它最後的度量目標就加入了對作品型別的考量,這就間接實現了內容的混排。
-
相關性本質上是定義什麼樣的item更匹配當前使用者,之前都是從消費者的角度去考量使用者更喜歡什麼樣的item,而我們作為一個ugc平臺,很多時候也要考量什麼樣的item更適合被分發,比如某item是不是更有平臺的畫風,更符合我們對內容分發的理解,這時,就是從平臺系統或者生產者的角度去理解什麼樣的item更應該被優先推薦。如果已知一部分item更需要被優先推薦,在構建使用者跟item間的相關性分時,可以對relativity score加調節權重進行干預,實現流量分配。比如,如果要使樂器類item比其他item有更高的權重,這時,可以調高樂器類item和使用者的匹配權重。
綜上可知,DPP不只是一個多樣性或相關性的度量,它本身是一種調控方式,具體調控的量和業務場景相關,具有非常大的挖掘空間。