slate原始碼解析(二)- 基本框架與資料模型
原始碼架構
首先來看下最核心的slate包下的目錄:
可以看到,作為一個開源富文字型檔,其原始碼是相當之少。在第一篇文章中說過,Slate沒有任何開箱即用的功能,只提供給開發者用於構建富文字所需的最基本的一套schema及操作API。因此原始碼的體量自然就要少許多。
我們來預覽上圖中各個目錄下檔案所負責的功能:
- interface:包含了所有Slate中使用到概念的型別定義以及這些型別所提供的方法API。這其中有用於表示Slate檔案樹結構的
editor.ts、node.ts、element.ts、text.ts,表示所有原子化操作的operation.ts,以及用於定位相關功能的point.ts、path.ts、range.ts、location.ts等。 - transforms:上面提到的
operation是Slate內部自己使用的原子化操作,但由於過於底層並不適合直接提供給開發者使用(slate-history庫就是基於operation來實現歷史記錄的)。便做多一層封裝,基於Slate自身的檔案樹結構提供了一套修改檔案內容的方法。transforms中的一個方法往往是一系列operation的集合。它分為這麼幾類應用:用於遊標操作的selection.ts、用於操作檔案樹中節點以及節點中文字內容的node.ts和text.ts、通用方法general.ts。 - utils:Slate內部使用的一些輔助函數。
型別拓展
在進一步深入原始碼之前,我們先來探究下Slate的custom-types機制。Slate將所有可供開發者自定義拓展的基礎型別以及它們的可拓展能力的實現都放在了interfaces/custom-types.ts下[原始碼]:
/**
* Extendable Custom Types Interface
*/
type ExtendableTypes =
| 'Editor'
| 'Element'
| 'Text'
| 'Selection'
| 'Range'
| 'Point'
| 'Operation'
| 'InsertNodeOperation'
| 'InsertTextOperation'
| 'MergeNodeOperation'
| 'MoveNodeOperation'
| 'RemoveNodeOperation'
| 'RemoveTextOperation'
| 'SetNodeOperation'
| 'SetSelectionOperation'
| 'SplitNodeOperation'
export interface CustomTypes {
[key: string]: unknown
}
export type ExtendedType<
K extends ExtendableTypes,
B
> = unknown extends CustomTypes[K] ? B : CustomTypes[K]
筆者在初次使用Slate的時候,依照檔案實現自己業務所需要的自定義型別,假設希望我們編輯器中的文字能夠有粗體和斜體的樣式。
而Slate下預設的文位元組點定義中,是隻有一個text欄位表示文字內容的[原始碼]:
export interface BaseText {
text: string
}
export type Text = ExtendedType<'Text', BaseText>
這是不夠的,依照檔案在自己的專案中加入以下程式碼,為文位元組點的定義加入兩個新欄位用來標識粗體與斜體:
declare module 'slate' {
interface CustomType {
Text: {
text: string
bold?: boolean
italic?: boolean
}
}
}
這樣就對Slate的文位元組點Text型別進行了拓展,並且後續使用相關的API時還能在編輯器/IDE中獲得智慧提示。
筆者當時很是疑惑如何通過TS實現這種機制的,便找到了custom-types.ts中的程式碼。看完後驚歎於其TS技巧,可以通過簡短的數十行就實現了這種型別拓展的能力。分為三個部分:
-
第一行的
type ExtendableTypes = 'Editor' | 'Element' | 'Text' |......定義了由一系列字串組成的聯合型別。它包括了Slate中所有允許開發者進行拓展的型別名稱。上面範例中的Text型別就是其中之一。 -
CustomTypes是一個以string作為key的對映型別,相當於包裹了任意名稱的欄位並且值都是unknown型別。unknown與any類似,都表示任何值;但不同的是對unknown型別值的任何操作都是非法的。利用interface宣告會自動合併的特性,對我們需要進行拓展的型別通過declare module可以覆蓋Slate內部CustomTypes的預設值unknown。 -
第三部分的
ExtendedType<K, B>泛型是最精華的部分。這裡面的型別變數K被約束為只能傳入ExtendableTypes中的值,型別變數B則無限制。後邊是賦值為一個條件型別:unknown extends CustomTypes[K] ? B : CustomTypes[K]。
unknown extends CustomTypes[K]表示CustomTypes中以K作為欄位的值是否為unknown;如果為true就將B作為預設型別返回。不為true的情況則是在開發者拓展了某個型別時發生。例如上面的Text型別,當K為"Text"時CustomTypes['Text']並不為unknown,那麼Slate會以我們覆寫的Text: { text: string, bold?: boolean, italic?: boolean }作為Text的真正定義。
因此ExtendedType<K, B>的作用簡單來說就是:當開發者拓展了型別K的時候就使用拓展的定義CustomTypes[K],否則就以B作為預設型別。我們在後續文章中要講解的型別都是基於它來提供可拓展能力的:
// text.ts
export type Text = ExtendedType<'Text', BaseText>
// element.ts
export type Element = ExtendedType<'Element', BaseElement>
// range.ts
export type Range = ExtendedType<'Range', BaseRange>
// editor.ts
export type Editor = ExtendedType<'Editor', BaseEditor>
export type Selection = ExtendedType<'Selection', BaseSelection>
// ......
text.ts
讓我們從最簡單的text看起[原始碼]:
/**
* `Text` objects represent the nodes that contain the actual text content of a
* Slate document along with any formatting properties. They are always leaf
* nodes in the document tree as they cannot contain any children.
*/
export interface BaseText {
text: string
}
export type Text = ExtendedType<'Text', BaseText>
export interface TextInterface {
equals: (text: Text, another: Text, options?: TextEqualsOptions) => boolean
isText: (value: any) => value is Text
isTextList: (value: any) => value is Text[]
isTextProps: (props: any) => props is Partial<Text>
matches: (text: Text, props: Partial<Text>) => boolean
decorations: (node: Text, decorations: Range[]) => Text[]
}
export const Text: TextInterface = {
equals(text: Text, another: Text, options: TextEqualsOptions = {}): boolean {
// ...
},
isText(value: any): value is Text {
// ...
},
// ...
}
除了text,其他諸如element、path等概念的檔案中也差不多是按照上面這種程式碼結構排版的。包含1.定義此概念的ExtendedType型別 2.定義該型別需要提供給開發者的API 3.以及這組API的具體實現:
export type XXType = XX
export interface XXTypeInterface {
// 該型別擁有的方法定義
}
export const XX: XXTypeInterface {
// 方法的具體實現
}
把視角拉回到Text。
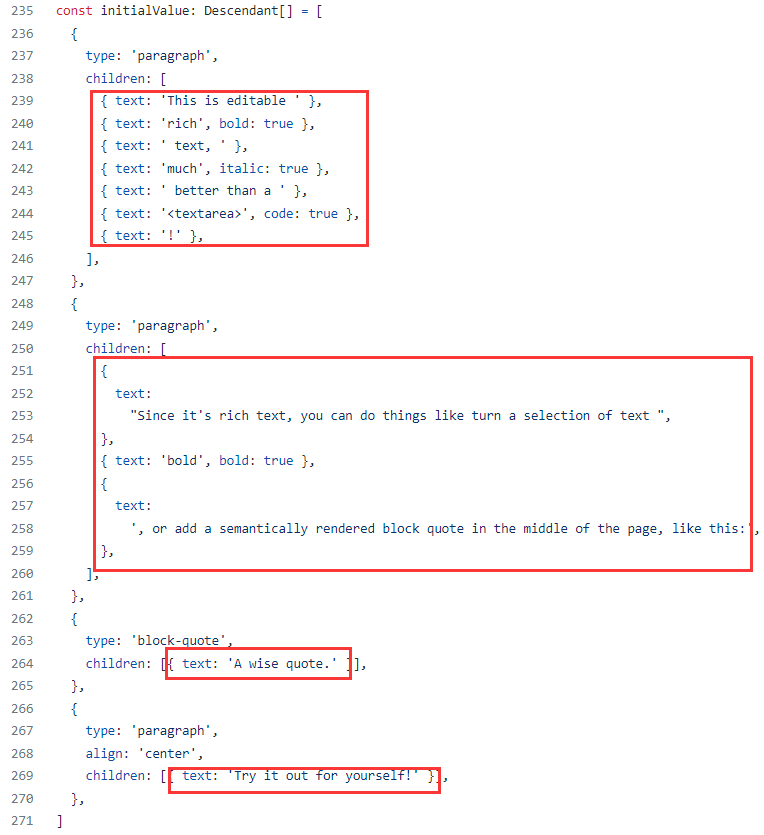
text節點代表了Slate檔案樹中的葉子節點,只能儲存文字內容,不能再包含任何子節點。開發者可以根據需要往其中新增別的欄位用以描述文字的樣式資訊。以官方範例中的原始碼實現來看[原始碼],下圖中紅圈的部分代表的都是text節點:
element.ts[原始碼]
Slate編輯器的內容是由Text和Element兩種型別組成的。element節點代表了除text文字外的非葉子節點。
/**
* `Element` objects are a type of node in a Slate document that contain other
* element nodes or text nodes. They can be either "blocks" or "inlines"
* depending on the Slate editor's configuration.
*/
export interface BaseElement {
children: Descendant[]
}
export type Element = ExtendedType<'Element', BaseElement>
Element預設的型別定義中只要求一個名為children的Descendant[]型別屬性。當然開發者一樣可以像前面範例那樣拓展新增其他的屬性。
Descendant型別代表Slate檔案樹中「可以作為子節點」的型別[原始碼]:
/**
* The `Descendant` union type represents nodes that are descendants in the
* tree. It is returned as a convenience in certain cases to narrow a value
* further than the more generic `Node` union.
*/
export type Descendant = Element | Text
可以看到Element和Descendant是相互關聯的。所以在element節點的children下再巢狀放置element節點也是允許的。這就是為什麼開發者可以很方便地通過Slate構建擁有複雜樹狀結構的檔案內容,因為只要依照Slate的型別規範走,它並不關注你的檔案樹的具體結構長什麼樣,你想巢狀地多深多複雜都可以。
在element.ts檔案頂部的註釋中說到,Element可以被定義為blocks或inlines形式。這一點是非常地貼近DOM元素的機制,併為開發者在富文字中渲染自定義元件時提供了更多樣的可能性。我們在後面還會再看到關於這兩個屬性的內容。
Editor
Slate編輯器的介面檔案editor.ts[原始碼]:
export type BaseSelection = Range | null
export type Selection = ExtendedType<'Selection', BaseSelection>
export type EditorMarks = Omit<Text, 'text'>
/**
* The `Editor` interface stores all the state of a Slate editor. It is extended
* by plugins that wish to add their own helpers and implement new behaviors.
*/
export interface BaseEditor {
children: Descendant[]
selection: Selection
operations: Operation[]
marks: EditorMarks | null
// Schema-specific node behaviors.
isInline: (element: Element) => boolean
isVoid: (element: Element) => boolean
normalizeNode: (entry: NodeEntry) => void
onChange: () => void
// Overrideable core actions.
addMark: (key: string, value: any) => void
apply: (operation: Operation) => void
deleteBackward: (unit: TextUnit) => void
deleteForward: (unit: TextUnit) => void
deleteFragment: (direction?: TextDirection) => void
getFragment: () => Descendant[]
insertBreak: () => void
insertSoftBreak: () => void
insertFragment: (fragment: Node[]) => void
insertNode: (node: Node) => void
insertText: (text: string) => void
removeMark: (key: string) => void
}
export type Editor = ExtendedType<'Editor', BaseEditor>
Slate編輯器範例中包含的資料只有下面這些:
-
children:是一個
Descendant型別的陣列,我們在前文中介紹過了。children組成的樹狀結構就是整個富文字的內容。 -
selection:表示編輯器中游標選區的資訊。在原始碼的最頂部可以看到,
Selection其實是由Range包裝而來的型別。
通過Range跳轉到它的定義[原始碼]:export interface BaseRange { anchor: Point focus: Point }它包含兩個屬性
anchor和focus,分別代表了錨點和聚焦點。從這些中可以看出,Slate編輯器中的selection、range以及range裡的anchor/focus也都是從DOM API那邊「借鑑」過來的。 -
operations:由我們前面介紹過的
Operation型別組成的一個陣列。operation由editor.apply方法產生並存入operations陣列中,並在一次Flushing後清空(Flushing是Slate中的概念,可以理解為在同步程式碼中執行多次apply產生的多個operation存入在operations中,然後在下一次微任務中觸發onChange方法並清空operations陣列 [原始碼])。 -
marks:用於暫存當前的文字樣式資訊。當呼叫
editor.addMarks方法後,會將開發者傳入的自定義屬性合併進這個marks物件,在下次輸入文字時拆分出新的文位元組點並且新文位元組點中會帶有marks中的屬性。
儘管Editor中只有這四樣資料,但這些就足以供開發者實現富文字應用下的大多數場景了。如果還嫌不夠,則可以利用其外掛機制對Slate editor進行包裝,覆寫(override)內部方法的行為,以及對Editor介面進行拓展,向其中加入任何你想要的自定義資料:)
再往下看是註釋有Schema-specific node behaviors的四個方法。它們是基於Slate的schema約定會在特定時機會呼叫的方法:
- isInline/isVoid:方法用於內部判斷節點是否為行內元素/void元素
- normalizeNode:在編輯器內容修改後對發生變動的節點呼叫
normalizeNode(node),以此來檢查並調整不符合Slate規範要求的節點。normalize是深入理解Slate的schema過程中一個非常重要的概念,筆者會在後續寫到Operation部分的時候會著重講解關於normalize的內容 - onChange:當編輯器內容內容修改後(甚至是遊標
selection的變動)都會觸發該方法
可以在create-editor.ts原始碼中看到下面三個方法的具體實現:
isInline: () => false,
isVoid: () => false,
onChange: () => {},
isInline和isVoid的實現都只是簡單地返回false值。這兩個方法往往是由開發者根據業務場景來做覆蓋的;例如我們需要能夠在富文字應用中渲染一些不可編輯(void)的行內(inline)元素如圖片、標籤和連結等複雜元件時就需要覆寫這兩個方法來判定上述節點的狀態為inline/void。
onChange的方法體中完全沒有任何內容。筆者暫時還未遇到過需要覆寫onChange方法的場景,但有一個現成的例子就在slate-react庫中:slate-react下的with-react.ts[原始碼]檔案中:
e.onChange = () => {
// COMPAT: React doesn't batch `setState` hook calls, which means that the
// children and selection can get out of sync for one render pass. So we
// have to use this unstable API to ensure it batches them. (2019/12/03)
// https://github.com/facebook/react/issues/14259#issuecomment-439702367
ReactDOM.unstable_batchedUpdates(() => {
const onContextChange = EDITOR_TO_ON_CHANGE.get(e)
if (onContextChange) {
onContextChange()
}
onChange()
})
}
呼叫了onContextChange函數。onContextChange函數由slate.tsx[原始碼]提供實現,在這裡會呼叫我們傳遞給<Salte onChange={xxx} />元件的onChange回撥以及觸發React重渲染<Editable />元件富文字內容。
再再往下呢,同樣也是可供外部覆寫的方法。除了apply其他都是我們在實現富文字過程中可直接呼叫的便於操作文字內容的方法,僅從命名中大都能猜出其用處,筆者在這就不一一贅述了。它們中的大部分實現都是僅對Transforms類方法的封裝,在後續會有單獨Transforms篇的文章詳述,本篇就不專門展開說了。
node.ts
經過前面一連串關於Editor、Element、Text概念的解釋後,相信讀者應該也意識到了Slate中的許多概念都是非常貼近於DOM的。而我們最後要說的這個node,作為Slate中最重要的概念,更是如此。
從頂層的Editor,到中間的Element容器,再到底層的Text文字,Slate將這些統統都視為節點Node,並由它們組成一個node tree。這棵node tree是不限深度、無限子節點的。例如我們在前端專案中構建了一個包含有多個Slate編輯器的富文字應用,可以用下圖來描述node tree結構:

看起來與HTML DOM tree非常的相似。
接著我們看看node.ts[原始碼]中定義的型別:
/**
* The `Node` union type represents all of the different types of nodes that
* occur in a Slate document tree.
*/
export type Node = Editor | Element | Text
/**
* The `Descendant` union type represents nodes that are descendants in the
* tree. It is returned as a convenience in certain cases to narrow a value
* further than the more generic `Node` union.
*/
export type Descendant = Element | Text
/**
* The `Ancestor` union type represents nodes that are ancestors in the tree.
* It is returned as a convenience in certain cases to narrow a value further
* than the more generic `Node` union.
*/
export type Ancestor = Editor | Element
如我們前面說的那樣,Node是由Editor、Element和Text組成的聯合型別,Descendant與Ancestor分別代表可以成為子節點和可以成為父節點的節點型別;它們是為了定義父/子層級這兩種概念的合集而存在的。 Node、Descendant、Ancestor這三個型別在我們使用Slate開發的過程中會經常遇到,尤其是Descendant,畢竟在大部分場景下我們要操作的物件都是「子樹」。如果讀者有大量使用過Slate中的各式API,應該會時常看到這個型別的身影。
node.ts檔案的最下面還有兩個額外的型別定義[原始碼]:
export type NodeEntry<T extends Node = Node> = [T, Path]
/**
* Convenience type for returning the props of a node.
*/
export type NodeProps =
| Omit<Editor, 'children'>
| Omit<Element, 'children'>
| Omit<Text, 'text'>
NodeEntry型別是用以表示迭代物件的,是一個包含有兩個資料的陣列:一個是節點物件本身,以及一個表示該節點在tree中的路徑Path。在幾乎所有涉及遍歷操作的方法中都能看到這個型別。
NodeProps表示我們在Editor/Element/Text節點中拓展的所有自定義屬性。搭配Node.extractProps方法[原始碼]可以將某個節點物件中所有的自定義屬性提取出來:
/**
* Extract props from a Node.
*/
extractProps(node: Node): NodeProps {
if (Element.isAncestor(node)) {
const { children, ...properties } = node
return properties
} else {
const { text, ...properties } = node
return properties
}
}
小結
本篇從Slate庫的目錄結構開始,概述了各目錄下的檔案分類及作用。接著詳細介紹了組成Slate檔案樹的基本結構:text、element、editor和node。到這裡我們對Slate檔案樹的構成已經非常清晰了,接下來就該瞭解如何遍歷這棵檔案樹了。下篇文章筆者就將探究Slate中與定位(Position)和迭代(Iteration)相關的內容,敬請期待:)