TikTok 推薦引擎強大的祕密
作者:Heorhii Skovorodnikov
深入研究TikTok令人驚歎的實時推薦系統的內部工作原理,瞭解是什麼使它成為該領域最好的產品之一。
為什麼TikTok的feed如此讓人上癮?祕訣在於他們的推薦引擎,這正是使TikTok成為最大的社交媒體平臺之一的原因。
似乎feed可以讀取你的思想,讓你在應用程式中停留更長時間。最近,TikTok決定讓每個人都知道一個祕密,並在一篇題為 「Monolith:帶有無碰撞嵌入表的實時推薦系統[https://arxiv.org/pdf/2209.07663.pdf]」 的論文中釋出了它的模型Monolith。
線上推薦系統是一種演演算法,用於根據使用者的興趣和喜好向使用者提供個性化的建議。這些系統通常被線上零售商和媒體公司用於向用戶推薦產品或內容。
在這篇文章中,我們將深入研究TikTok令人驚歎的推薦系統的內部工作原理,並瞭解是什麼,讓它成為該領域最好的系統之一.
目前的設計存在什麼問題?
構建可延伸的實時推薦系統對於許多企業在其產品或網站中構建良好的體驗至關重要。然而,目前的深度學習框架(TensorFlow或PyTorch)不能很好地用於實時生產場景。這是因為:
- 在依賴動態稀疏特徵的推薦系統中,基於靜態引數和密集計算的模型更新並不適合較好的推薦效能。
- 常見的方法是將批次訓練階段和服務階段(在使用者與產品互動期間)完全分開設計,防止模型與客戶反饋實時互動。
TikTok的團隊通過3個步驟解釋了他們的解決方案:
- 他們製作了一個無碰撞的嵌入表,同時通過新增可exponable embedding 和 frequency filtering(頻率過濾)來進一步優化它,以減少其記憶體消耗,讓其高效,並適合分發到使用者;
- 他們提供了一個可用於生產環境的,且具有高容錯性線上訓練架構;
- 他們通過實驗證明,系統的可靠性可以與實時學習來互相平衡;
聽起來有點嚇人嗎? 不要擔心,我們將通過對每個元件的拆解分析,在本文結束時,你將有信心地理解,為什麼你可以在應用程式中浪費大量時間。準備好了嗎? 我們要發車啦。
Embeddings and Hash maps
TikTok的研究人員觀察到,對於推薦系統來說,資料大多是categorical(分散) 和sparse(稀疏)的。
這意味著,如果我們使用像單詞嵌入這樣的ML方法嵌入資料,我們將無法通過推薦資料提供的獨特特性數量來實現,相比之下,由於詞彙量有限,語言模型可以做到這一點。
根據YouTube和Instagram推薦系統的實際經驗,雜湊技巧被認為是大規模推薦系統的最佳方法。讓我們深入研究《Monolith》中所使用的細節。
那麼HashMap呢?
雜湊對映是一種資料結構,它允許通過一個特殊的雜湊函數將資料片段快速對映到一個值。
雜湊對映速度很快,被大型平臺用於高效編碼資料,那麼單體應用如何使其更好呢? 雜湊對映有一個固有的權衡,這個資料結構的原始設計稱為碰撞(collision)。
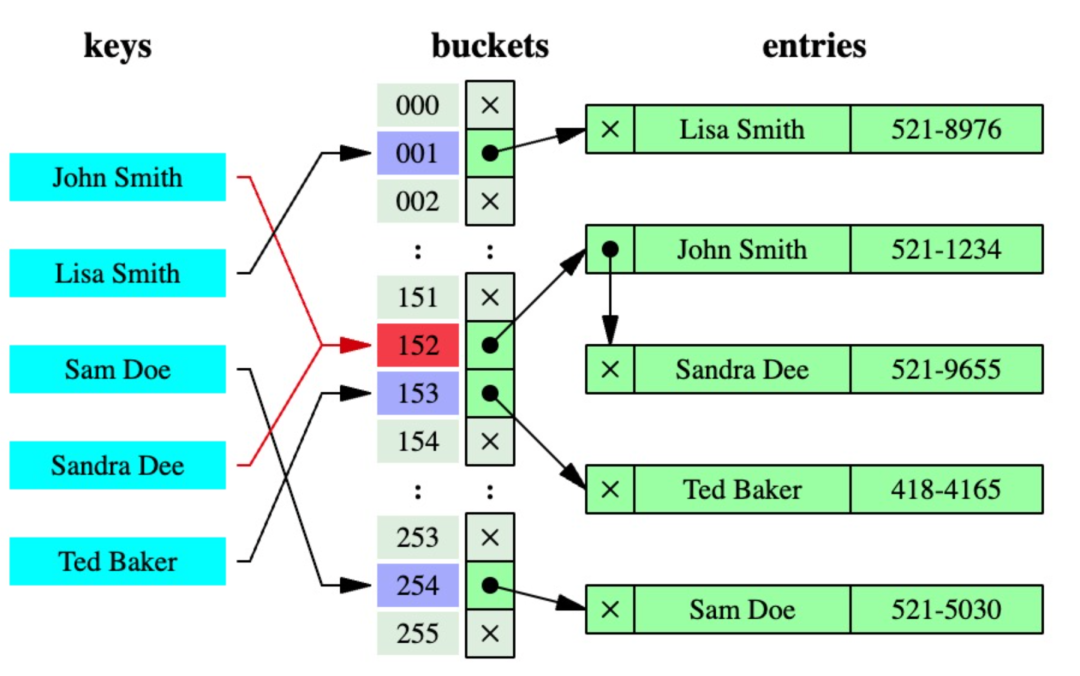
當兩個或多個資料通過雜湊函數對映到相同的輸出值時,就會發生衝突。當使用雜湊函數索引資料時,這可能會導致問題,因為多個資料塊將被對映到相同的位置。TikTok的團隊開發了一個 cuckoo hashmap,來解決這個問題。

在 cuckoo hashmap 中,就像在標準hash map中一樣,每個資料都被分配一個唯一的鍵,並且鍵被雜湊以確定它在陣列中的位置。如果該位置已經被另一段資料佔據,則現有資料將被「踢出」(類似於現實生活中杜鵑對巢中蛋的行為),並且必須使用第二個雜湊函數在陣列中找到一個新的位置。這個過程將繼續,直到所有資料都成功插入陣列,或者直到達到最大迭代次數為止。上面給出了一個例子。這裡兩個雜湊表T0和T1用於儲存雜湊資料。值A被雜湊並插入到T0中,但是由於B已經佔據了這個位置,然後將其逐出,並試圖將其插入到T1中,這個過程將重複,直到插入所有值或重新雜湊以避免迴圈插入。這個過程可以避免碰撞,對生產模型的效能有重要影響。
為了完成他們的embedding系統設計,研究人員新增了一些附加功能來進一步優化過程,特別是減少雜湊所需要的記憶體需求:
-
用於過濾hashmap中的id的概率過濾器。由於一個重要的觀察是,在來自TikTok id的資料中,id是長尾分佈的,熱門id可能出現數百萬次,而不受歡迎的id出現不超過10次,因此可以合理地假設它們不會影響最終的模型質量,因此可以清除。
-
一個ID存在計時器,控制舊ID和過期ID的刪除。這可能是由於使用者不再活躍,或短視訊過時。為這些id儲存嵌入不能以任何方式幫助模型,因此清除記憶體是明智的。
線上訓練
現在,由於我們已經瞭解了資料在模型中是如何表示的,我們需要了解如何訓練和更新資料。Monolith線上訓練的系統架構的總體示意圖如下:

它看起來很複雜,但實際上,它都圍繞著一個非常簡單的過程,這個過程是更大架構的基礎,推動了整個訓練系統架構的核心。
TensorFlow的分散式Worker-ParameterServer(或簡稱PS)模型是以分散式方式訓練機器學習模型的一種方式,其中多臺機器(或一臺機器上的程序)一起工作來訓練模型,如下圖所示:

在這個模型中,有兩種型別的程序:工作程序和引數伺服器程序。
- 工作程序負責執行訓練模型所需的計算,例如計算梯度或更新模型引數。
- 引數伺服器負責儲存模型的當前狀態,例如模型權重或偏差。
訓練分為批次訓練和線上訓練兩個階段:
-
批次訓練階段。 該階段的工作原理如下:在每個訓練步驟中,訓練工作者從儲存中讀取一個小批次的訓練樣例,向PS請求引數,計算向前和向後傳遞,最後將更新後的引數推入訓練PS。當需要修改模型架構並重新訓練模型時,批次訓練對於訓練歷史資料非常有用;
-
線上訓練階段。 模型部署到線上服務後,訓練不會停止,而是進入線上訓練階段。訓練工作者不再從儲存中讀取小批次範例,而是實時地使用實時資料並更新訓練PS,訓練PS定期將其引數同步到服務PS,這將立即在使用者端生效。
Streaming引擎
為了確保Monolith能夠在批次訓練和線上訓練之間無縫切換,它使用了一個Streaming引擎元件:

為了收集實時使用者反饋,研究團隊使用Kafka佇列,其中一個佇列記錄使用者操作(點選,點贊等),另一個佇列記錄來自模型伺服器的功能。然後使用Apache Flink joiner連線兩個,這些打包的資料被轉換成訓練資料,然後由另一個Kafka佇列讀取,這些訓練範例用於批次處理訓練和線上訓練:
- 在批次訓練過程中,Kafka佇列中的資料被轉儲到Hadoop分散式檔案儲存(HDFS)中,在積累了一定數量的訓練資料後,再傳送給訓練工作者
-線上訓練的過程更簡單:資料直接從Kafka佇列中讀取
訓練操作完成後,PS收集引數,並根據選定的同步計劃更新服務PS,而服務PS又更新使用者端的模型。
線上 Joiner
Joiner 過程實際上有點複雜,我們應該注意一些事情:

記憶體快取和KV(Key-Value)儲存,是兩個有助於穩定使用者操作和來自伺服器的功能之間的延遲的元件,這是因為它們都到達,而不考慮彼此的到達時間,因此需要快取來正確地配對它們。但是如果使用者需要很長時間才能完成一個操作呢? 那麼快取就不是一個好主意,因此一些值儲存在磁碟上,以便再次配對。當用戶操作紀錄檔到達時,它首先查詢記憶體中的快取,然後查詢鍵值儲存,以防缺少快取。
還要注意最後一步,即 負例取樣(Negative Sampling)。因為在訓練過程中有積極和消極的例子。在推薦系統中,正例是使用者喜歡或表現出興趣的專案,而負例是使用者不喜歡或表現出興趣的專案。但是它們的數量可能是不平衡的,因此糾正資料集中的這種偏差是很重要的。
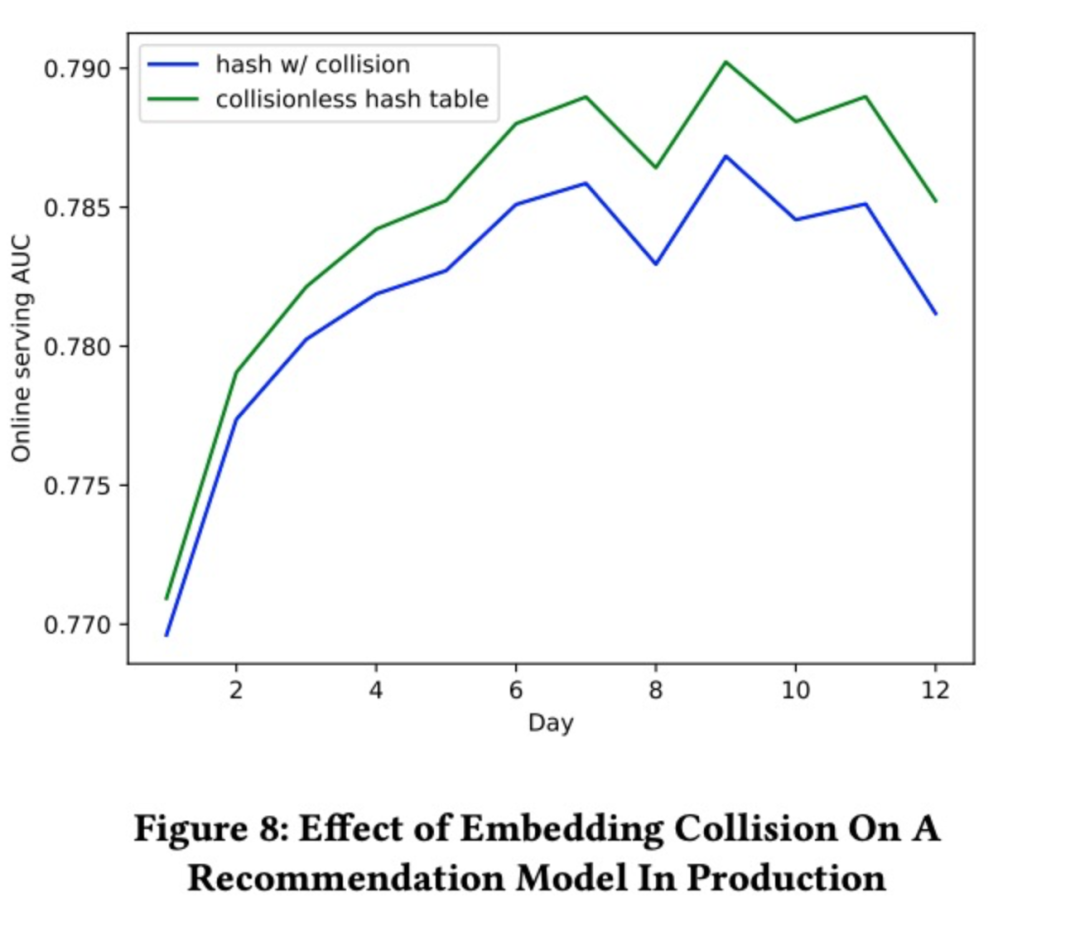
就是這樣。你已經瞭解了Monolith中的所有元件。現在是最後一個部分,研究人員證明了線上學習的有效性。
實時學習
在這裡,團隊還比較了模型,在不同同步時間間隔下的效能,以驗證其效能:

正如我們在上面看到的,線上訓練,對於具有動態反饋的推薦系統擁有更好的效能,是至關重要的。
寫在最後
感謝閱讀我對TikTok實時推薦系統工作原理的深入研究。
我希望你覺得有趣,並學到了一點新的東西。
原文:https://www.shaped.ai/blog/the-secret-sauce-of-tik-toks-recommendations
論文:Monolith:帶有無碰撞嵌入表的實時推薦系統,https://arxiv.org/pdf/2209.07663.pdf
關注 熵減駭客 ,一起學習成長
