精華推薦 |【演演算法資料結構專題】「延時佇列演演算法」史上非常詳細分析和介紹如何通過時間輪(TimingWheel)實現延時佇列的原理指南

時間輪的介紹
時間輪(TimeWheel)是一種實現延遲功能(定時器)的精妙的高階演演算法,其演演算法應用範圍非常廣泛,在Java開發過程中常用的Dubbo、Netty、Akka、Quartz、ZooKeeper 、Kafka等各種框架中,各種作業系統的定時任務crontab排程都有用到,甚至Linux核心中都有用到,不誇張的是幾乎所有和時間任務排程都採用了時間輪的思想。
時間輪的作用
高效處理批次任務
時間輪可以高效的利用執行緒資源來進行批次化排程,把大批次的排程任務全部都繫結時間輪上,通過時間輪進行所有任務的管理,觸發以及執行。
降低時間複雜度
時間輪演演算法可以將插入和刪除操作的時間複雜度都降為O(1),在大規模問題下還能夠達到非常好的執行效果。
高效管理延時佇列
能夠高效地管理各種延時任務,週期任務,通知任務等,相比於JDK自帶的Timer、DelayQueue + ScheduledThreadPool來說,時間輪演演算法是一種非常高效的排程模型。
缺點:時間精確度的問題
時間輪排程器的時間的精度可能不是很高,對於精度要求特別高的排程任務可能不太適合。因為時間輪演演算法的精度取決於時間段「指標」單元的最小粒度大小,比如時間輪的格子是一秒跳一次,那麼排程精度小於一秒的任務就無法被時間輪所排程。
精度問題我們可以考慮後面提出的優化方案:多級時間輪。
時間輪的使用場景
- 排程模型,時間輪是為解決高效排程任務而產生的排程模型。例如,週期任務。
- 資料結構,通常由hash table和連結串列實現的資料結構。
- 延時任務、週期性任務應用場景主要在延遲大規模的延時任務、週期性的定時任務等。
- 通知任務等等。
時間輪的實現方案
為了充分發揮時間輪演演算法的效果和優勢,我們要從基礎上去分析和優化時間輪演演算法對比定時任務、任務佇列模式的運作基底。
減少執行緒分配
時間輪是一種高效來利用執行緒資源來進行批次化排程的一種排程模型,把大批次的排程任務全部都繫結到同一個的排程器上面,使用這一個排程器(執行緒)來進行所有任務的管理(manager),觸發(trigger)以及執行(runnable)。
CPU的負載和資源浪費減少
承接上面減少執行緒分配,最後可以使得當我們需要進行大量的排程任務或者延時任務,可以大大減少執行緒的分配,如果按照任務排程模式,每個任務都使用自己的排程器來管理任務的生命週期的話,可能會進行分配很多執行緒,從而會消耗CPU的資源並且很低效。
注意:問題就是如果這個排程器的排程執行緒出現了問題,會導致整體全域性崩潰。
延時任務或定時任務實現原理
如何實現定時任務 / 延時任務,定時的任務排程分兩種:
- 延時任務:一段時間後執行,即:相對時間。
- 定時任務:指定某個確定的時間執行,即:絕對時間。
對於延時任務和定時任務兩者之間是可以相互轉換的,例如當前時間是12點,定時在5分鐘之後執行,其實絕對時間就是:12:05,定時在12:05執行,相對時間就是5分鐘之後執行。
時間輪功能設計
時間輪實現定時/延時任務佇列,最終需要向上層提供如下介面:
- 新增定時/延時任務
- 刪除定時/延時任務
- 執行定時/延時任務
時間輪的資料結構
-
時間輪(HashedWheelTimer)是儲存定時任務的環形佇列,底層採用陣列實現,陣列中的每個元素可以存放個定時任務列表(HashedWheelBucket)。
-
HashedWheelBucket是環形的雙向連結串列,連結串列中的每一項表示的都是定時任務項(HashedWheelTimeout),其中封裝了真正的定時任務(TimerTask)。
單時間輪基本邏輯模型
時間輪演演算法是:不再任務佇列作為資料結構,輪詢執行緒不再負責遍歷所有任務,而是僅僅遍歷時間刻度。時間輪演演算法好比指標不斷在時鐘上旋轉、遍歷,如果一個發現某一時刻上有任務(任務佇列),那麼就會將任務佇列上的所有任務都執行一遍。
時間輪由多個時間格組成,每個時間格代表當前時間輪的基本時間跨度(tickDuration),時間輪的時間格個數是固定的。
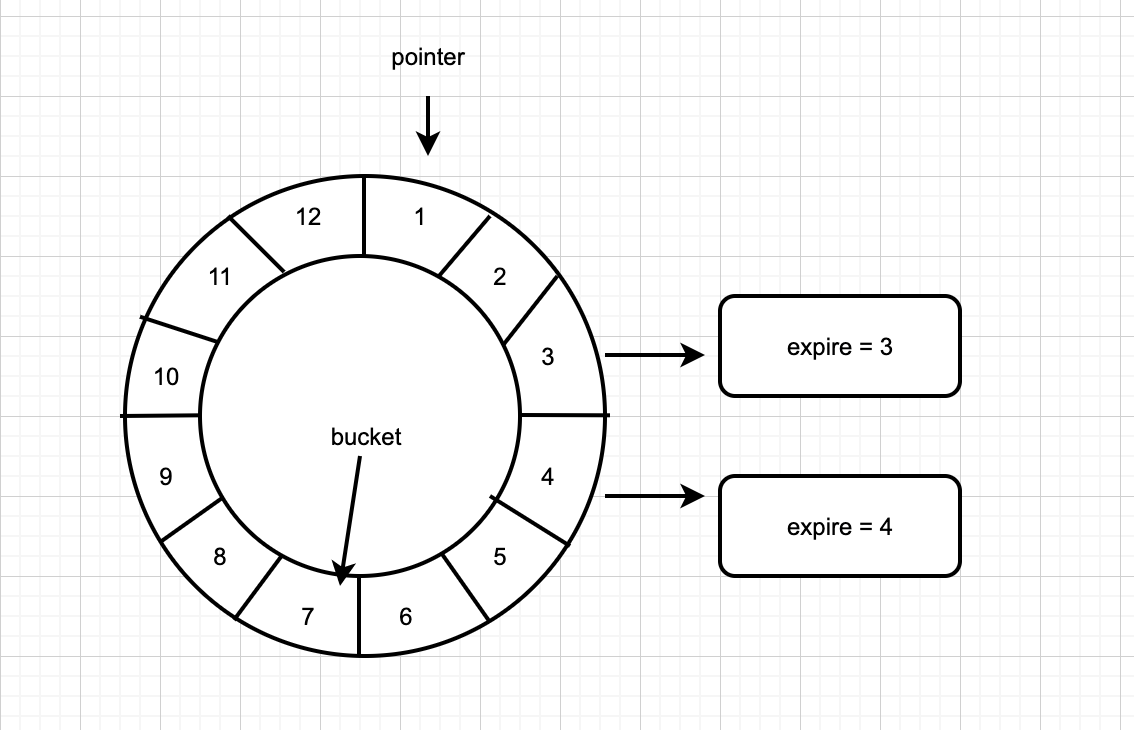
如上圖中相鄰bucket到期時間的間隔為bucket=1s,從0s開始計時,1s時到期的定時任務掛在bucket=1下,2s時到期的定時任務掛在bucket=2下,當檢查到時間過去了1s時,bucket=1下所有節點執行超時動作,當時間到了2s時,bucket=2下所有節點執行超時動作等等。
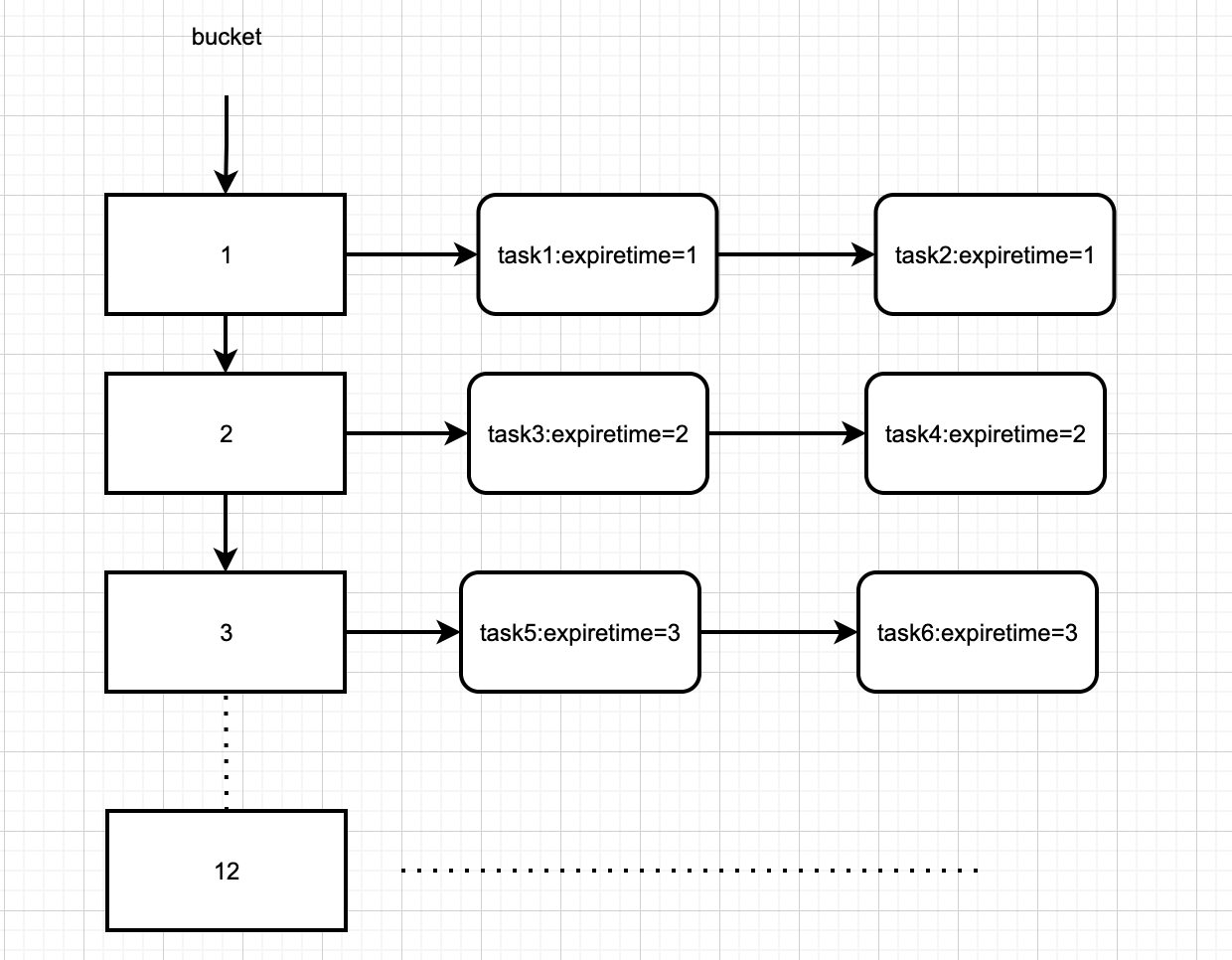
如上圖的時間輪通過陣列實現,可以很方便地通過下標定位到定時任務鏈路,因此,新增、刪除、執行定時任務的時間複雜度為O(1)。
時間輪資料結構模型
-
pointer : 指標,隨著時間的推移,指標不停地向前移動。
-
bucket : 時間輪由bucket組成,如上圖,有12個bucket。每個bucket都掛載了未來要到期的節點(即: 定時任務/延時任務)。
-
slot : 指相鄰兩個bucket的時間間隔。
-
tickDuration:slot的單位,1s(1HZ),如上圖,總共12個bucket,那麼兩個相鄰的bucket的時間間隔就是一秒。
時間輪使用一個錶盤指標(pointer),用來表示時間輪當前指標跳動的次數,可以用tickDuration * (pointer + 1)來表示下一次到期的任務,需要處理此時間格所對應的 TimeWheel中的所有任務。
時間輪處理邏輯
計算延時時間儲存
時間輪在啟動的時候會記錄一下當前啟動的時間賦值給startTime。時間輪在新增任務的時候首先會計算延遲時間(delayTime),比如一個任務的延遲時間為24ms,那麼會將當前的時間(currentTime)+24ms-時間輪啟動時的時間(startTime)。然後將任務封裝成TimeWheelElement加入到bucket佇列中。
- TimeWheelElement的總共延遲的次數:將每個任務的延遲時間(delayTime)/ tickDuration計算出pointer需要總共跳動的次數以及計算出該任務需要放置到時間輪(wheel)的槽位,然後加入到槽位連結串列最後將任務放置到時間輪wheel中。
讀取延時資料任務佇列
時間輪在執行的時候會將bucket佇列中存放的TimeWheelElement任務取出來進行遍歷,從而進行執行對應的任務體系機制。計算出當前時針走到的槽位的位置,並取出槽位中的連結串列資料,防止萬一,還可以再delayTime和當前的時間做對比,執行過期的資料。
單時間輪的問題和弊端
-
顯而易見,時間輪演演算法解決了遍歷效率低的問題。(現在,即使有 10k 個任務,輪詢執行緒也不必每輪遍歷10k個任務,而僅僅需要遍歷24個時間刻度)。
-
時間輪演演算法中,輪詢執行緒遍歷到某一個時間刻度後,總是執行對應刻度上任務佇列中的所有任務(通常是將任務扔給非同步執行緒池來處理),而不再需要遍歷檢查所有任務的時間戳是否達到要求。
記憶體和資源的消耗巨大
但這種單時間輪是存在限制的,只能設定定時任務到期時間在12s內的,這顯然是無法滿足實際的業務需求的。當然也可以通過擴充bucket的範圍來實現。例如,將bucket設定成 2^32個,但是這樣會帶來巨大的記憶體消耗,顯然需要優化改進。
輪詢執行緒仍然還會慢慢的出現遍歷效率低問題
當時間刻度增多,而任務數較少時,輪詢執行緒的遍歷效率會下降,例如,如果只有 50 個時間刻度上有任務,但卻需要遍歷 1440 個時間刻度。這違背了我們提出時間輪演演算法的初衷:解決遍歷輪詢執行緒遍歷效率低的問題。
浪費記憶體空間問題
在時間刻度密集,任務數少的情況下,大部分時間刻度所佔用的記憶體空間是沒有任何意義的。如果要將時間精度設為秒,那麼整個時間輪將需要 86400 個單位的時間刻度,此時時間輪演演算法的遍歷執行緒將遇到更大的執行效率低的問題。
輪數時間輪基本邏輯模型
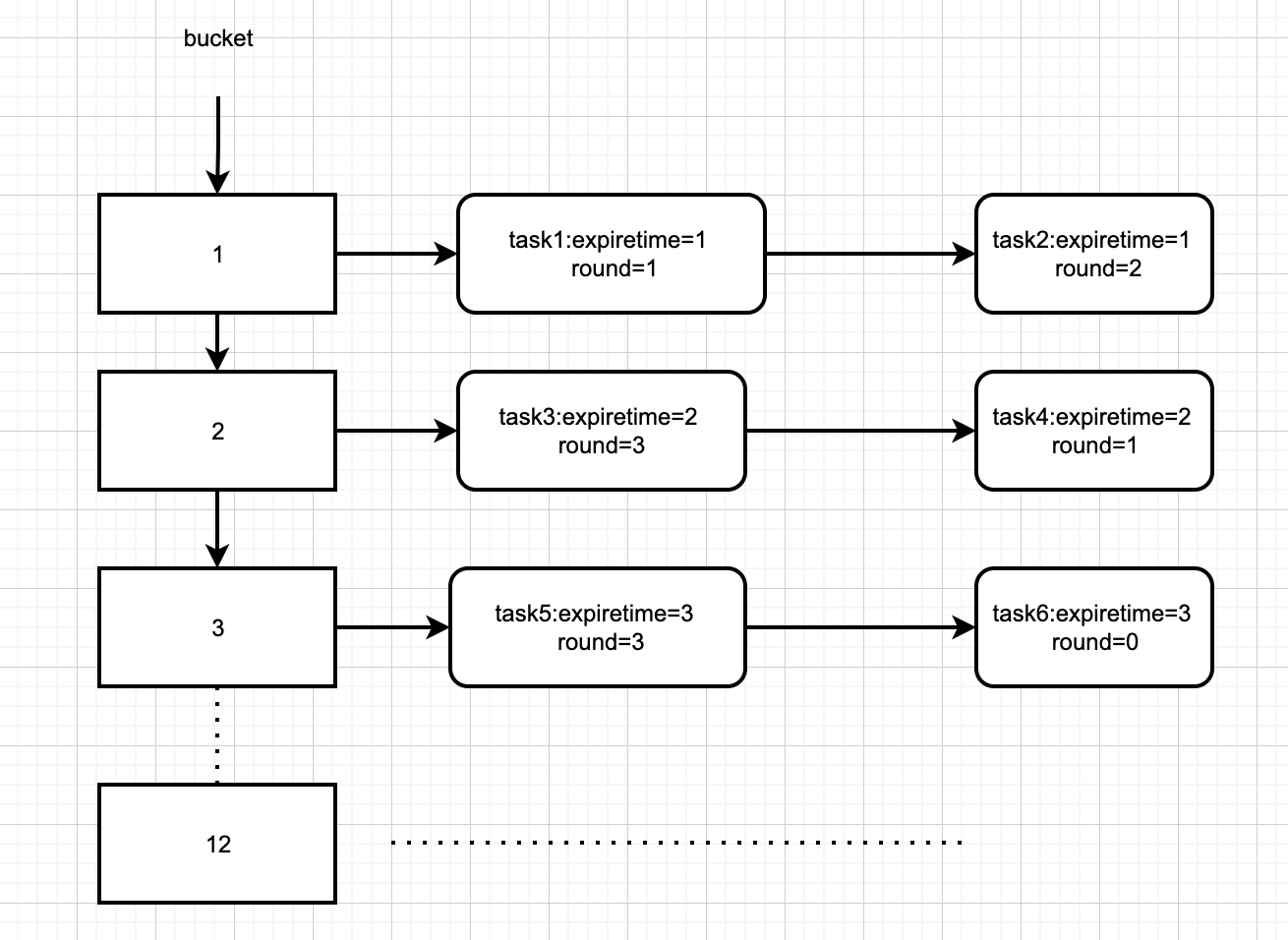
時間輪的時間刻度隨著時間精度而增加並不是一個好的問題解決思路,所以計劃將時間輪的精度設定為秒,時間刻度個數固定為60。每一個任務擁有一個round 欄位,基於單時間輪原理之下,我們在每個bucket塊下不單單儲存到期時間expire時間的任務,還會儲存一個新欄位round(expire%N=bucket的定時器(N為bucket個數))。
主要由一下兩個欄位組成
- expire:代表到期時間
- round:表示時間輪要在轉動幾圈之後才執行任務
執行bucket下的延時邏輯
當指標轉到某個bucket時,不能像簡單的單時間輪那樣直接執行bucket下所有的定時器,而是要去遍歷該bucket下的連結串列,判斷判斷時間輪轉動的次數是否等於節點中的round值,只有當expire和round都相同的情況下,才能執行該任務。

輪詢執行緒的執行邏輯是每隔一秒處理一個時間刻度上任務佇列中的所有任務,任務的 round欄位減 1,接著判斷如果 round 欄位的值變為 0,那麼將任務移出任務佇列,交給非同步執行緒池來執行對應任務。如果是重複執行任務,那麼再將任務新增到任務佇列中。
輪數計算的公式
輪詢執行緒遍歷一次時間輪需要60 秒,如果一個任務需要間隔x秒執行一次,那麼其 round 欄位的值為 x/60(整除),任務位於第 (x%60)(取餘)個刻度對應的任務佇列中。
例如,任務需要間隔 130 秒執行一次,那麼 round 欄位的值為 2,此任務位於第 10 號時間刻度的任務佇列中。
時間輪round次數:根據計算的需要走的(總次數- 當前tick數量)/ 時間格個數(wheel.length)。
提取計算對應的bucket下的任務資料
比如,tickDuration為1ms,時間格個數為20個,那麼時間輪走一圈需要20ms,那麼新增進一個延時為24ms的資料,如果當前的tick為0,那麼計算出的輪數為1,指標沒執行一圈就會將round取出來-1,所以需要轉動到第二輪之後才可以將輪數round減為0之後才會執行。
輪數時間輪的問題和缺點
改進版單時間輪是時間和空間折中的方案,不像單時間輪那樣有O(1)的時間複雜度,也不會像單時間輪那樣,為了滿足需求產生大量的bucket。但是這種方式雖然簡化了時間輪的刻度個數,但是並沒有簡化執行效率不高的問題。
執行效率不高的問題
改進版的時間輪如果某個bucket上掛載的定時器特別多,那麼需要花費大量的時間去遍歷這些節點,如果bucket下的連結串列每個節點的round都不相同,那麼一次遍歷下來可能只有極少數的定時器需要立刻執行的,因此很難在時間和空間上都達到理想效果。
時間輪每次處理一個時間刻度,就需要處理其上任務佇列的所有任務。其執行效率甚至與基於普通任務佇列實現的定時任務框架沒有區別。
層級時間輪基本邏輯模型
為了解決單時輪和輪數時間輪引起的效能問題和資源問題的另一種方式是在層次結構中使用多個定時輪,由多個層級來進行多次hash進行任務資料的傳遞,從而減少對應的時間和空間的複雜程度。
多級時間輪
【年、月、日、小時、分鐘、秒】級別的6個時間輪,每個時間輪分別有(10-年暫時定為10年)、12(月)、24(時)、60(分鐘)、60(秒)個刻度。子輪轉動一圈,父輪轉動一格,從父向子前進,無子過期。分層時間輪如下圖所示:

案例流程執行體系
任務需要在當天的17:30:20執行
- 任務新增於秒級別時鐘輪的第20號Bucket上,當其輪詢執行緒存取到第20號Bucket時,就將此任務轉移到分鐘級別時鐘輪的第30號Bucket上。
- 當分鐘級別的時鐘輪執行緒存取到第30號Bucket,就將此任務轉移到小時級別時鐘輪的第 7號Bucket上。
- 當小時級別時鐘輪執行緒存取到第7號bucket時。
最終會將任務交給非同步執行緒負責執行,然後將任務再次註冊到秒級別的時間輪中。
分層時鐘輪演演算法設計具有如下的優點
-
輪詢執行緒效率變高:首先不再需要計算round值,其次任務佇列中的任務一旦被遍歷,就是需要被處理的(沒有空輪詢問題)。
-
執行緒並行性好:雖然引入了並行執行緒,但是執行緒數僅僅和時鐘輪的級數有關,並不隨著任務數的增多而改變。
-
如果任務按照分鐘級別來定時執行,那麼當分鐘時間輪達到對應刻度時,就會將任務交給非同步執行緒來處理,然後將任務再次註冊到秒級別的時鐘輪上。
分層時間輪中的任務從一個時間輪轉移到另一個時間輪,實現層級輪演演算法可以借鑑了生活中水錶的度量方法,通過低刻度走得快的輪子帶動高一級刻度輪子走動的方法,達到了僅使用較少刻度即可表示很大範圍度量值的效果。
本文來自部落格園,作者:洛神灬殤,轉載請註明原文連結:https://www.cnblogs.com/liboware/p/17155012.html,任何足夠先進的科技,都與魔法無異。