推薦系統[八]演演算法實踐總結V1:淘寶逛逛and阿里飛豬個性化推薦:召回演演算法實踐總結【冷啟動召回、復購召回、使用者行為召回等演演算法實戰】
0.前言:召回排序流程策略演演算法簡介
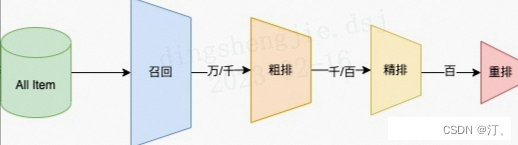
推薦可分為以下四個流程,分別是召回、粗排、精排以及重排:
- 召回是源頭,在某種意義上決定著整個推薦的天花板;
- 粗排是初篩,一般不會上覆雜模型;
- 精排是整個推薦環節的重中之重,在特徵和模型上都會做的比較複雜;
- 重排,一般是做打散或滿足業務運營的特定強插需求,同樣不會使用複雜模型;
-
召回層:召回解決的是從海量候選item中召回千級別的item問題
- 統計類,熱度,LBS;
- 協同過濾類,UserCF、ItemCF;
- U2T2I,如基於user tag召回;
- I2I類,如Embedding(Word2Vec、FastText),GraphEmbedding(Node2Vec、DeepWalk、EGES);
- U2I類,如DSSM、YouTube DNN、Sentence Bert;

-
模型類:模型類的模式是將使用者和item分別對映到一個向量空間,然後用向量召回,這類有itemcf,usercf,embedding(word2vec),Graph embedding(node2vec等),DNN(如DSSM雙塔召回,YouTubeDNN等),RNN(預測下一個點選的item得到使用者emb和item emb);向量檢索可以用Annoy(基於LSH),Faiss(基於向量量化)。此外還見過用邏輯迴歸搞個預估模型,把權重大的交叉特徵拿出來構建索引做召回
-
排序策略,learning to rank 流程三大模式(pointwise、pairwise、listwise),主要是特徵工程和CTR模型預估;
- 粗排層:本質上跟精排類似,只是特徵和模型複雜度上會精簡,此外也有將精排模型通過蒸餾得到簡化版模型來做粗排
- 常見的特徵挖掘(user、item、context,以及相互交叉);
- 精排層:精排解決的是從千級別item到幾十這個級別的問題
- CTR預估:lr,gbdt,fm及其變種(fm是一個工程團隊不太強又對演演算法精度有一定要求時比較好的選擇),widedeep,deepfm,NCF各種交叉,DIN,BERT,RNN
- 多目標:MOE,MMOE,MTL(多工學習)
- 打分公式融合: 隨機搜尋,CEM(價效比比較高的方法),線上貝葉斯優化(高斯過程),帶模型CEM,強化學習等

- 粗排層:本質上跟精排類似,只是特徵和模型複雜度上會精簡,此外也有將精排模型通過蒸餾得到簡化版模型來做粗排
-
重排層:重排層解決的是展示列表總體最優,模型有 MMR,DPP,RNN系列(參考阿里的globalrerank系列)
-
展示層:
- 推薦理由:統計規則、行為規則、抽取式(一般從評論和內容中抽取)、生成式;排序可以用湯普森取樣(簡單有效),融合到精排模型排等等
- 首圖優選:CNN抽特徵,湯普森取樣
-
探索與利用:隨機策略(簡單有效),湯普森取樣,bandit,強化學習(Q-Learning、DQN)等
-
產品層:互動式推薦、分tab、多種型別物料融合
1.淘寶逛逛召回演演算法實踐總結
內容化這幾年越來越成為電商的重點,使用者來到網購的時候越來越不侷限在只有明確需求的時候,而更多的是沒有明確需求的時候,就像是逛街一樣。逛逛就是在這樣的背景下誕生的內容化產品,打造出有用、有趣、潮流、奇妙、新鮮的內容,為消費者提供全新的內容消費體驗。在這個場景下的內容召回有很多問題需要探索,其中主要的特點和挑戰有:
-
強時效性:內容推薦場景下的內容新舊汰換非常快,新內容的使用者行為少,很難用使用者歷史行為去描述新內容,而使用者行為正是老內容投放主要的依賴。所以當不能依靠使用者行為資料來建模內容之間關係的時候,我們必須要找到其他可以表徵內容的方法。
-
多興趣表徵:多興趣表徵,特別是多峰召回是這幾年比較主流的一個趨勢。但是目前多峰模型中峰的數量是固定的,當用戶行為高度集中的時候,強制的將使用者行為拆分成多向量,又會影響單個向量的表達能力。如何去平衡不同使用者行為特點,特別是收斂和發散的興趣分佈,就成了此類任務的挑戰。
在設計優化方向的時候,我們重點考慮上面描述問題的解法(召回本身也需要兼顧精準性和多樣性,所以單一召回模型顯然無法滿足這些要求,我們的思路是開發多個互補的召回模型)。詳細的介紹在後面的章節以及對應的後續文章中展開:
-
跨域聯合召回:除了單純把多域的資訊平等輸入到模型中,如何更好利用跨域之間的資訊互動就變的尤為重要。目前有很多優秀的工作在討論這樣的問題,比如通過使用者語意,通過差異學習和輔助loss等。我們提出了基於異構序列融合的多興趣深度召回模型CMDM(a cross-domain multi-interest deep matching network),以及雙序列融合網路Contextual Gate DAN 2種模型結構來解決這個問題。
-
語意&圖譜&多模態:解決時效性,最主要的問題就是怎麼去建模新內容,最自然的就是content-based的思想。content-based的關鍵是真正理解內容本身,而content-based裡主要的輸入資訊就是語意,影象,視訊等多模態資訊。目前有許多工作在討論這樣的問題,比如通過認知的方式來解決,多模態表徵學習,結合bert和高階張量等方式等等。在語意召回上,我們不僅僅滿足於語意資訊的融入,還通過Auxiliary Sequence Mask Learning去對行為序列進行高階語意層面的提純。更進一步,我們利用內容圖譜資訊來推薦,並且引入了個性化動態圖譜的概念。對於新老內容上表達能力的差異問題,我們通過multi-view learning的思想去將id特徵和多模態特徵做融合。
-
泛多峰:為了解決多峰強制將興趣拆分的問題,我們考慮到單峰和多峰的各自特點,特別是在泛化和多樣性上各自有不同的建模能力。基於此,我們提出了泛多峰的概念。
1.1 跨域聯合召回
1.1.1 基於異構序列融合的多興趣深度召回
在單一推薦場景下,深度召回模型只需要考慮使用者在當前場景下的消費行為,通過序列建模技術提取使用者興趣進而與目標商品或內容進行匹配建模。而在本推薦場景下,深度召回模型需要同時考慮使用者內容消費行為和商品消費行為,進行跨場景建模。為此,我們提出了CMDM多興趣召回模型架構,能夠對使用者的跨場景異構行為序列進行融合建模。在CMDM中,我們設計了用於異構序列建模的層級注意力模組,通過層級注意力模組提取的多個使用者興趣向量與目標內容向量進行匹配建模。
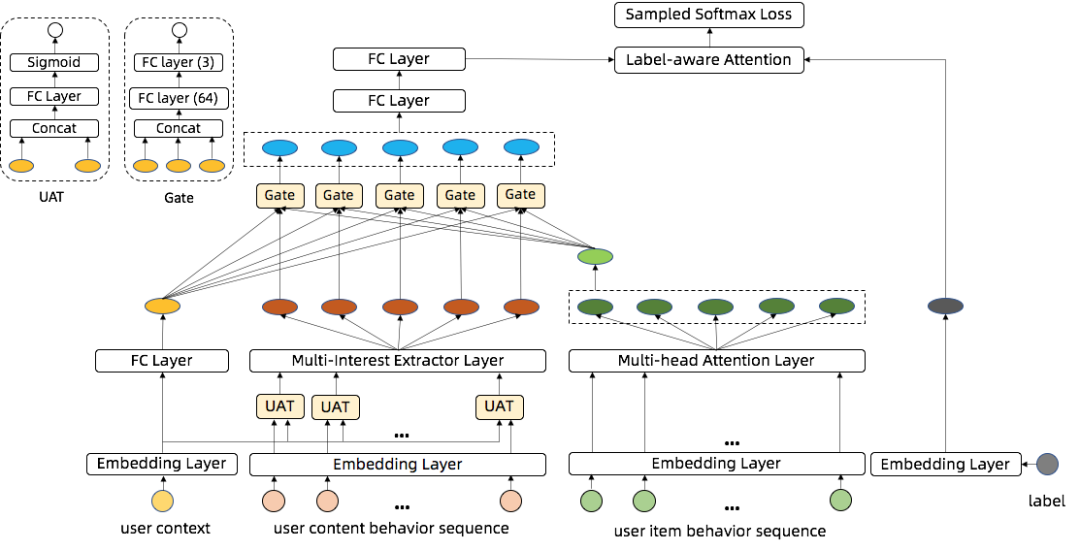
1.1.2 雙序列融合網路Contextual Gate DAN
除了通過層次注意力的方式,異構序列中還有個特點就是在時間上更接近交叉並存的狀態。為了學習到兩個序列之間的資訊交叉,充分融合商品點選序列和內容點選序列,我們從自然語言處理的VQA任務中得到啟發。VQA是用自然語言回答給定影象的問題的任務,常用做法是在圖片上應用視覺注意力,在文字上應用文字注意力,再分別將圖片、文字多模態向量輸入到一個聯合的學習空間,通過融合對映到共用語意空間。而DAN結構是VQA任務中一個十分有效的模型結構,DAN通過設計模組化網路,允許視覺和文字注意力在共同作業期間相互引導並共用語意資訊。我們對DAN結構進行了改進,設計了Contextual Gate DAN 雙序列融合網路:

1.2 語意&圖譜&多模態
1.2.1 多模態語意召回
在內容推薦場景內,存在大量新內容需要冷啟動,我們主要通過語意和多模態2種方式。相對於搜尋任務,語意匹配是一個從單點到多點,解空間更大更廣的問題。首先是使用者行為的不確定性,內容推薦場景下使用者決策空間更大更廣,從而導致使用者對推薦系統的反饋訊號本身就存在較大的不確定性;再就是語意空間表達的對齊問題,這裡的對齊包含兩個方面,第一個方面是單個序列裡的內容表達的語意標籤提取方式差別大(比如cpv、分詞、語意標籤、多模態表徵等等),另外一個方面是多序列(內容和商品等)之間的語意空間對齊問題。多模態的召回方式融合了文字,影象,音訊等大量模式跨域資訊,由於與內容互動解耦,在緩解內容冷啟動上具有一定的優勢。多模態召回主要是通過理解內容多模態表徵,先後進行了collaborative filtering、聚類中心召回、個性化多模態表徵相關的探索工作,在多樣性方面取得了一定的效果,深度語意召回方面針對使用者行為去噪和更好的表達語意資訊角度出發,迭代了cate-aware和query-aware和序列mask 自監督任務的模型。

1.2.2 行為稀疏場景下的圖模型實踐
更進一步,我們利用內容圖譜資訊來推薦。知識圖譜構建的出發點就是對使用者的深度認知,能夠幫助系統以使用者需求出發構建概念,從而可以幫助理解使用者行為背後的語意和邏輯。這樣可以將使用者的每次點選行為,都用圖譜的形式極大的豐富,圖譜帶來的可解釋的能力還可以大大加快模型的收斂速度。知識圖譜有個特點,就是其中的資訊是相對固定的,或者說是靜態的,因為知識圖譜基本是由先驗資訊構成的。但是從各個使用者的角度,知識圖譜的資料中的連結重要度並不相同。比如一個電影,有的使用者是因為主演看的,有的使用者是因為導演看的,那麼這個電影連線的主演邊和導演邊的權重就因人而異了。我們提出了一種新的方法來融合使用者動態資訊和靜態圖譜資料。每個行為都用圖譜擴充套件,這樣行為序列變成行為圖譜序列, 並且加入KnowledgeGraph-guided gating的自適應的生成式門控圖注意力,去影響知識圖譜融入到模型中的點邊的權重。

1.2.3 融合多模態資訊的跨模態召回
針對新內容冷啟動的問題,我們提出了跨模態召回模型來兼顧content-based和behaviour-based的召回各自的優點。在跨模態召回模型構建前,我們首先引入了多模態meta資訊為主的「語意」 deep collaborative filtering召回,兩者的顯著差別主要在target side的特徵組成中相較與behaviour-based的特徵,多模態特徵構建的模型去除了影響較大的內容id類的特徵,將這些特徵更換為了來自多模態預訓練技術得到的多模態表徵輸入。除了上面的變化,我們還加入了triplet loss的部分使得embedding空間更具有區分度,效率指標也有了較大幅度的提升。

1.3 使用者多興趣表徵(多模型簇聯合學習):泛多峰
多峰召回模型通過對使用者側產生多個表徵不同「興趣」的向量進行多個向量的召回,是對於單峰的一個拓展,將單個使用者的表達擴充套件成了多個興趣表達, 更精確地刻畫了使用者, 從而取得更好的效果。我們通過對於單峰模型及多峰模型的觀察發現,使用者行為高度集中的序列單峰模型的線上效率相對於多峰模型會更有優勢,而那些使用者序列類目豐富度較高的則多峰模型的效率明顯佔優。所以這裡提出了泛多峰u2i模型的概念,嘗試將多峰模型容易擬合行為序列類目豐富度較高的使用者,而單峰模型則更容易擬合行為序列類目豐富度較為集中的使用者的優勢進行結合。使得單一模型能夠通過產生不同演演算法簇的多個不同表徵的向量在不同簇的內容向量中進行召回,從而具備這兩種召回正規化的優點。

1.4 提升優化:
▐ 認知推薦
我們正在嘗試,將圖譜用於user embedding投影,投影的平面空間就是語意空間,這樣做到可控多維度語意可解釋embedding。另外,對於召回,取樣方式對模型效果影響非常大,結合知識圖譜來進行graph-based Learning to sample的優化,對於正負樣本的選取更加做到關聯可控,加快迭代速度,提升效果。
▐ 興趣破圈
在內容化推薦領域,僅僅相似度提高的優化,會導致使用者沒有新鮮感,對平臺粘性變低。如何幫助使用者探索他更多的興趣,是現在內容化推薦亟待解決的另一個問題。一種做法是興趣近鄰,從已有興趣出發,慢慢通過興趣之間的相似,擴充套件使用者未知的領域,可以參考MIND,CLR一些思路。另一種做法是對興趣構建推理引擎,在對已有興趣推理過程建模之後,加入擾動來探索使用者可能新的興趣。
2.阿里飛豬個性化推薦:召回篇
常見的有基於user profile的召回,基於協同過濾的召回,還有最近比較流程的基於embedding向量相似度的topN召回等等。方法大家都知道,但具體問題具體分析,對應到旅行場景中這些方法都面臨著種種挑戰。例如:旅行使用者需求週期長,行為稀疏導致訓練不足;行為興趣點發散導致效果相關性較差;冷啟動使用者多導致整體召回不足,並且熱門現象嚴重;同時,具備旅行特色的召回如何滿足,例如:針對有明確行程的使用者如何精準召回,差旅使用者的週期性復購需求如何識別並召回等。
本次分享將介紹在飛豬旅行場景下,是如何針對這些問題進行優化並提升效果的。主要內容包括:⻜豬旅行場景召回問題、冷啟動使用者的召回、行程的表達與召回、基於使用者行為的召回、週期性復購的召回。
2.1 飛豬旅行場景召回問題
推薦系統流程
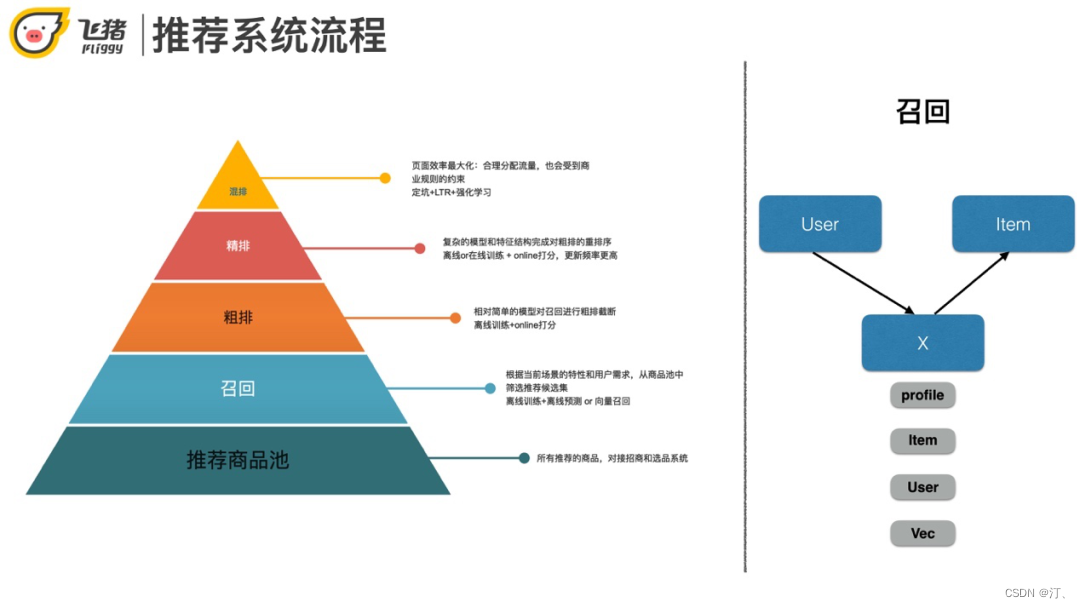
首先介紹推薦的整體流程。整體上分為5個階段。從全量的商品池開始,之後依此是召回階段,粗排/精排階段,最後的混排模組根據業務實際情況而定,並不是大多數推薦系統必須的。粗排和精排在另外一次分享中已經介紹過了,本次分享主要介紹一下飛豬推薦系統的召回問題,召回可以說決定了推薦系統效果的上限。
下面說一下召回和粗排/精排的區別。從召回到粗排再到精排模組,商品的資料量是遞減的,模型的複雜度會增高。具體會體現在輸入特徵數量和模型複雜度的增加,更新往往也會更頻繁。對應的訓練和上線的方式也會不同,拿召回來講,出於效能的考慮,往往採用離線訓練+打分或者離線訓練得到向量表達+向量檢索的方式,而排序階段為了更好的準確率和線上指標,更多的是離線訓練+實時打分,甚至線上學習的方式。
召回的本質其實就是將使用者和商品從不同維度關聯起來。常見的方法比如content-base匹配,或者item/user based的協同過濾,還有最近比較流行的向量化召回。向量化召回常用做法是用深度學習將使用者和商品都表達成向量,然後基於內積或歐式距離通過向量檢索的方式找到和使用者最匹配的商品。
2.1.1 飛豬推薦場景

飛豬的推薦頁面有很多,比如首頁,支付成功頁,訂單列表頁,訂單詳情頁都有猜你喜歡。不同頁面對應了不同的場景,使用者在不同場景下需求不同,也有一定的交叉。比如首頁偏重逛/種草,但支付完成後推薦一些與訂單相關的商品會更好。
我們大致可以把使用者分為三類:無行為、有行為,還有一種是飛豬場景下特殊的一類"有行程"。
2.1.2 主要問題

本次分享的主要內容就是針對這三類使用者在推薦過程中存在的問題+週期性復購場景 ( 出差/回家 ) 的解決。
航旅場景下的召回存在以下問題:
-
冷啟動:航旅商品的熱門現象嚴重,user profile缺乏。
-
相關性vs搭配性:航旅場景下要求搭配性比較高,傳統的I2I只偏重相關性。但使用者的行程需求不是單點的,比如買了飛機票還要看住宿。行程受上下文影響比較多,比如季節、使用者近期行為等。
-
相關性不足:航旅使用者的行為稀疏又發散,目前的召回結果噪音較多。
下面會對我們在優化過程中碰到的相關問題一一介紹。我們知道,召回處於推薦鏈路的底端,對召回常規的離線評估方式有預測使用者未來點選的TopN準確率或者使用者未來點選的商品在召回佇列中平均位置等等。但是在工業系統中,為了召回的多樣性和準確率,都是存在多路召回的,離線指標的提高並不代表線上效果的提升,一種常見的評估某路召回效果的方式就是對比同類召回通道的線上點選率,這種評估更能真實反映線上的召回效果,基於篇幅的考慮,後面的介紹主要展示了線上召回通道點選率的提升效果。
2.2 冷啟動使用者召回

2.2.1 User冷啟動召回
使用者冷啟動召回主要有以下幾種方案:Global Hot、Cross Domain、基於使用者屬性的召回。
-
全域性熱門:缺點是和user無關,相關性差。
-
Cross domain:一種做法是基於不同域 ( 例如飛豬和淘寶 ) 共同使用者的行為將不同域的使用者對映到同一個向量空間,然後藉助其他域的豐富行為提升本域冷啟動使用者的召回效果。
-
基於使用者屬性:單一屬性的缺點是熱門現象嚴重,個性化不足。我們採用了基於多屬性組合的方法。
2.2.2 UserAttr2I

在這裡介紹我們的方案UserAttr2I,使用類似排序模型的方法,輸入使用者+商品的屬性,預測使用者是否會點選一個商品。
開始用線性FTRL模型,效果不是很好。原因是線性模型無法學習高階特徵,並且解釋性比較差。針對這兩個問題,通過DeepNet提高泛化性,同時用GBDT來做特徵篩選。

下面對比雙塔結構和深度特徵交叉兩種方案,優缺點如圖所示。最終選擇了第二種,原因是目標使用者是冷啟動,能用到的特徵比較少。如果放棄挖掘使用者和寶貝之間的關係會導致相關性比較差。模型結構如下:
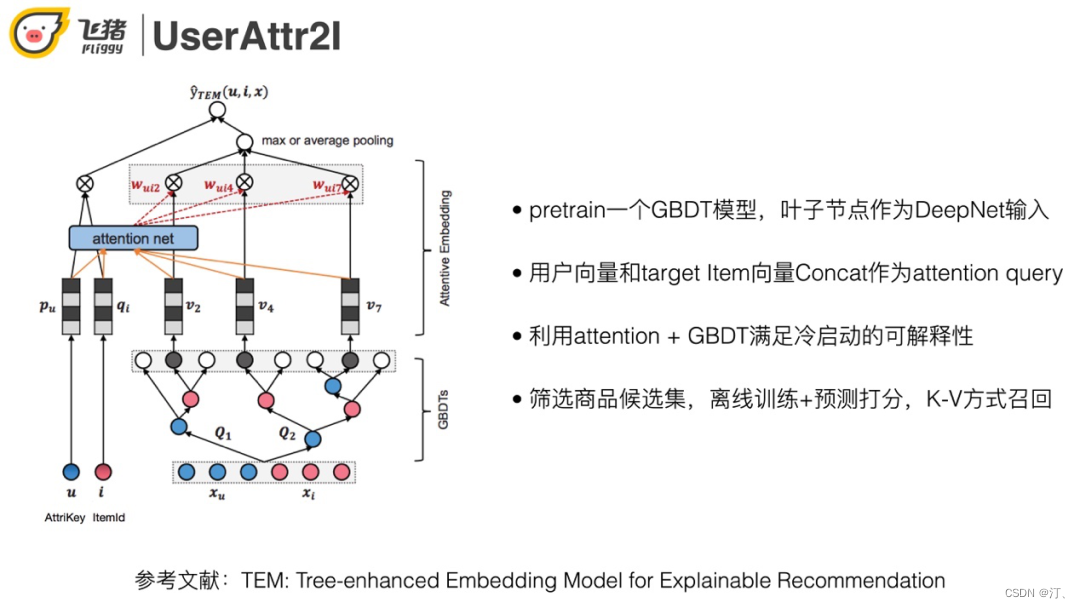
通過attention操作以及GBDT的葉子節點即可滿足冷啟動的可解釋性。

對比其他冷啟動的召回方式,Attribute2I的點選率最高。
2.3 行程的表達與召回
2.3.1 Order2I
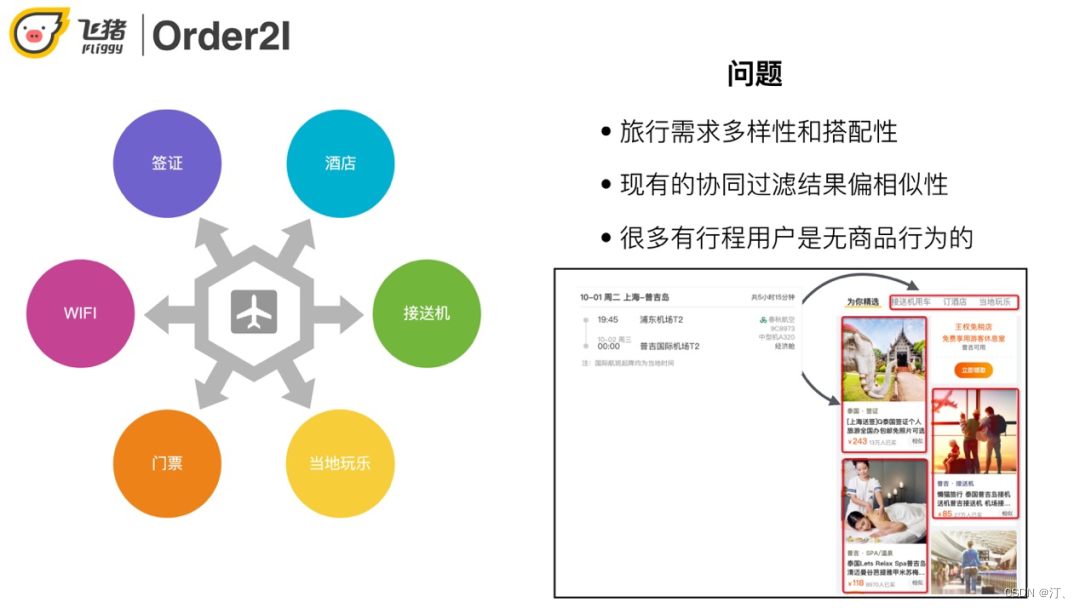
在飛豬場景下使用者有類似如下的需求:買了去某地的機票,使用者很可能需要與之搭配的簽證/wifi/酒店等等,而協同過濾通常只能推出同型別商品,比如門票推門票,酒店推酒店。另外飛豬不像淘寶使用者可能會經常逛,有比較豐富的歷史行為資訊可以供我們去分析和計算,飛豬使用者通常是"買完即走"。

通過資料分析我們發現訂單附近的行為資料和訂單有較高搭配關係,我們通過Graph Embedding的方式學習訂單和寶貝的Embed,以此來學習搭配關係。
難點有以下幾個:
-
如何挖掘反映搭配關係的資料集合
-
搭配的限制性比較強,如果僅僅基於使用者行為構建圖,由於使用者行為噪音多,會造成較多badcase
-
如果完全基於隨機遊走學習Embed,最後的召回結果相關性差,因此需要行業知識的約束
-
資料稀疏,覆蓋商品少,冷啟動效果差
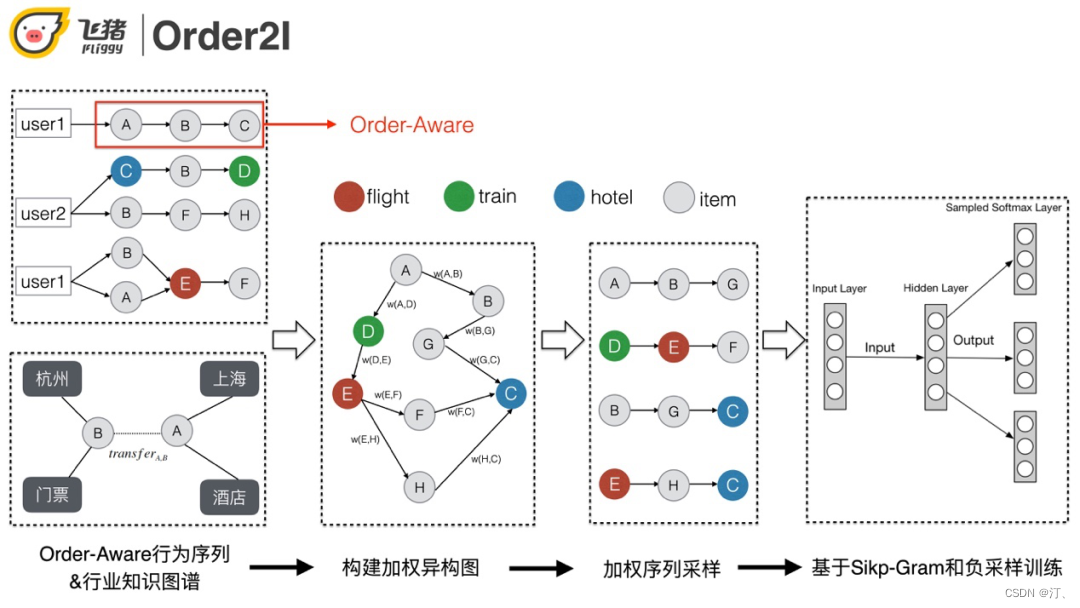
解決方案:
利用航旅知識圖譜以及使用者的行為序列進行加權異構圖的構建 ( 機票/火車票節點利用業務線+出發地+目的地唯一標示、寶貝&酒店利用其id唯一標示 )。之後的流程和傳統的Graph Embedding類似。

具體過程:
① 以訂單粒度對使用者的行為做拆分和聚合,同時加入點選行為緩解稀疏問題。
② 邊的權重的計算同時考慮知識圖譜和使用者行為,這種做法一方面可以增加約束控制效果,另一方面也可以抑制稀疏,解決冷啟動的問題。
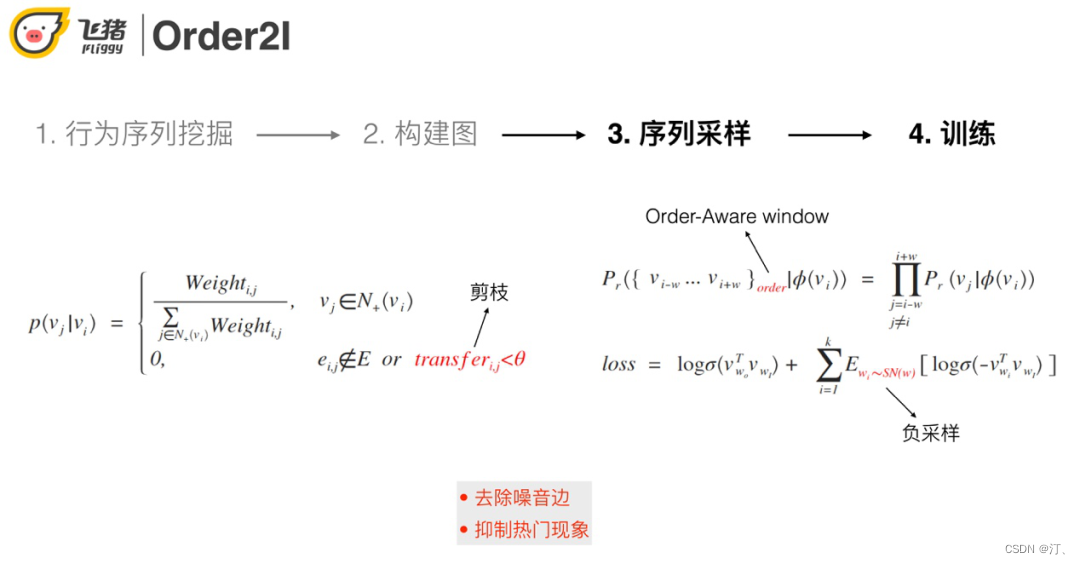
③ 序列取樣過程中會基於轉移概率進行剪枝操作,用來抑制噪聲和緩解熱門問題。
④ skip-gram+負取樣訓練。

這裡有一個具體的case,使用者訂了一張去曼谷的機票,order2I召回了曼谷的一些自助餐,落地籤,熱門景點等,體現了較好的搭配性。整體的指標上order2I的點選率也明顯高於其他方式。
2.3.2 journey2I
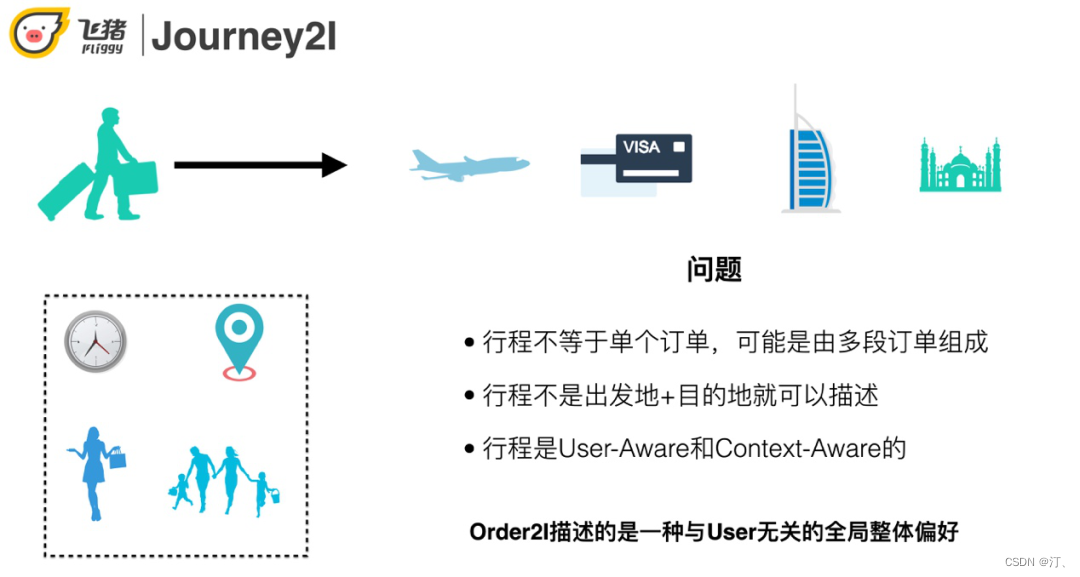
Order2I將訂單進行向量化表達,從而進行召回。但是它還有一些問題:使用者的某次行程可能由多個訂單組成,甚至有的訂單只是中轉的作用,Graph Embedding還是基於單個訂單進行搭配的推薦;使用者的某次行程不是一個出發地+目的地就能描述的,它不僅與行程本身屬性 ( 例如出發/到達時間,目的地,行程意圖等 ) 相關,還與使用者的屬性和偏好 ( 例如年齡,是否是親子使用者 ) 相關。因此行程既是User-Aware又是Context-Aware的。而Order2I學習的還是一種全域性的整體偏好,與使用者無關,不夠個性化。因此我們嘗試在行程的粒度做召回,綜合考慮使用者屬性、行程意圖、上下文等因素,更個性化的召回與使用者這次行程以及使用者自身強相關的的寶貝。

以行程為粒度,對多個訂單做聚合,並且增加行程相關的特徵。融入使用者的基礎屬性特徵和歷史行為序列。豐富行程特徵並引入attention機制。採用雙塔模型離線儲存商品向量,線上做向量化召回。模型結構如下:

模型左邊主要是利用行程特徵對訂單序列以及使用者的歷史行為序列進行attention操作,用於識別關鍵訂單以及使用者關鍵行為。在此基礎上融合行程特徵和使用者屬性特徵學習使用者該段行程的Embed。模型右邊是商品特徵,經過多層MLP之後學習到的寶貝Embed。兩邊做內積運算,利用交叉熵損失進行優化,這樣保證召回的結果不僅與行程相關還與使用者行為相關。

兩個同樣是上海到西安的使用者。使用者1點選了歷史博物館和小吃,不僅召回了與機票搭配的接送機,還召回了與行為行為相關的小吃街附近的酒店以及歷史博物館相關的寶貝。
使用者2點選了一個接送機,除了召回接送機還召回了機場附近的酒店和熱門的POI景點門票。可以看出基於使用者的不同行為,召回結果不僅滿足搭配關係還與使用者行為強相關。

從指標來看Journey2I相對Order2I有進一步明顯的提升。
2.4 基於使用者行為的召回
2.4.1 Session-Based I2I
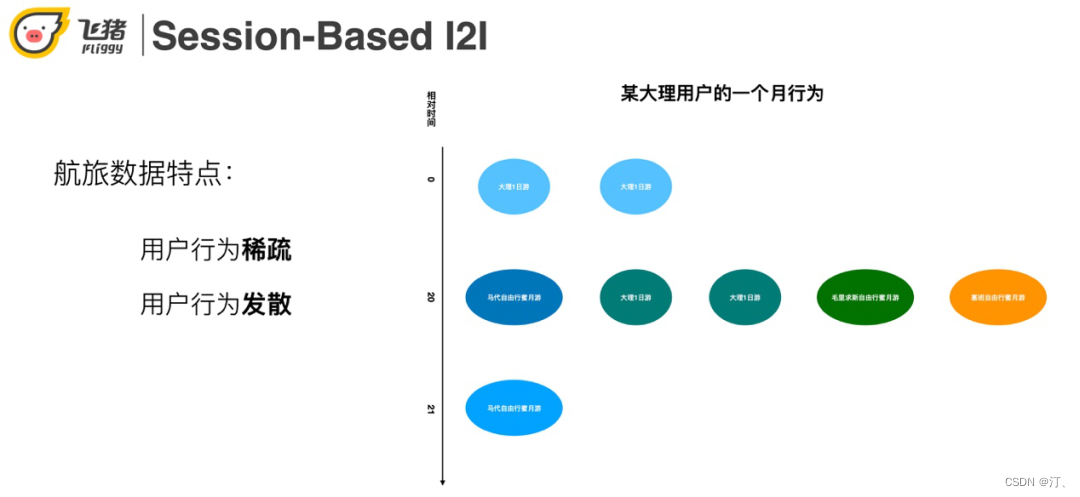
航旅使用者的行為有稀疏和發散的特點。利用右圖一個具體的使用者範例來說明這兩個特點:使用者在第一天點選了兩個大理一日遊,第20天點選了一些馬爾地夫蜜月相關的商品,第21天又點選了大理的一日遊。稀疏性體現在一個月只來了3次,點選了8個寶貝。發散性體現在使用者大理一日遊和出國蜜月遊兩個topic感興趣。

在使用者有行為的情況下進行召回,我們常採用的方法是基於User-Rate矩陣的協同過濾方法 ( 如ItemCF,Swing。ItemCF認為同時點選兩個商品的使用者越多則這兩個商品越相似。Swing是在阿里多個業務被驗證過非常有效的一種召回方式,它認為user-item-user的結構比itemCF的單邊結構更穩定 ),但是由於航旅使用者行為稀疏,基於User-Rate矩陣召回結果的準確率比較低,泛化性差。針對這兩個問題我們可以通過擴充歷史資料來增加樣本覆蓋。航旅場景因為使用者點選資料比較稀疏,需要比電商 ( 淘寶 ) 擴充更多 ( 時間更長 ) 的資料才夠。這又帶來了興趣點轉移多的問題。在這裡我們採用對行為序列進行session劃分,保證相關性。
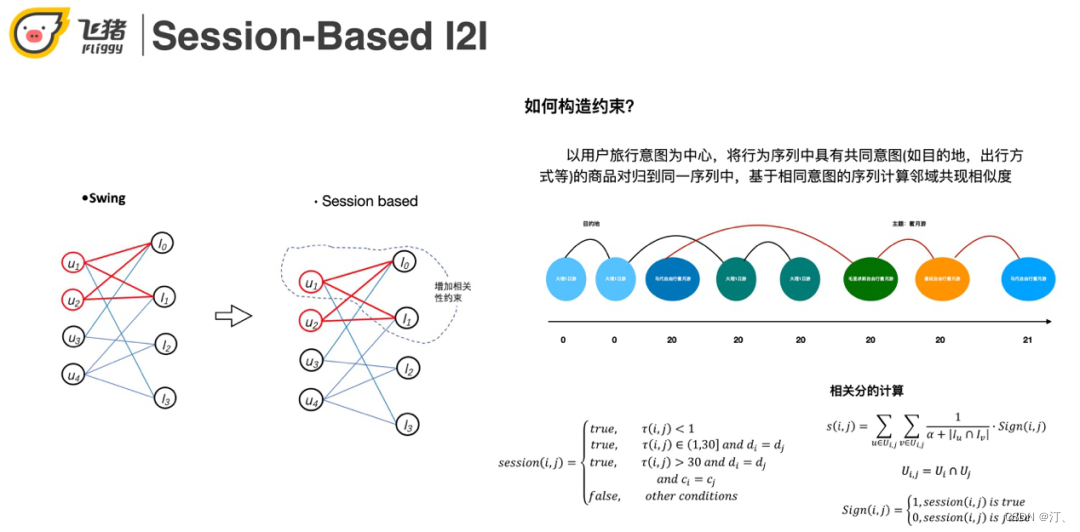
這裡以swing為例講解一下構造約束的方式。我們以使用者的行為意圖為中心,將表示共同意圖的商品聚合在一個序列中,如上圖對使用者行為序列的切分。
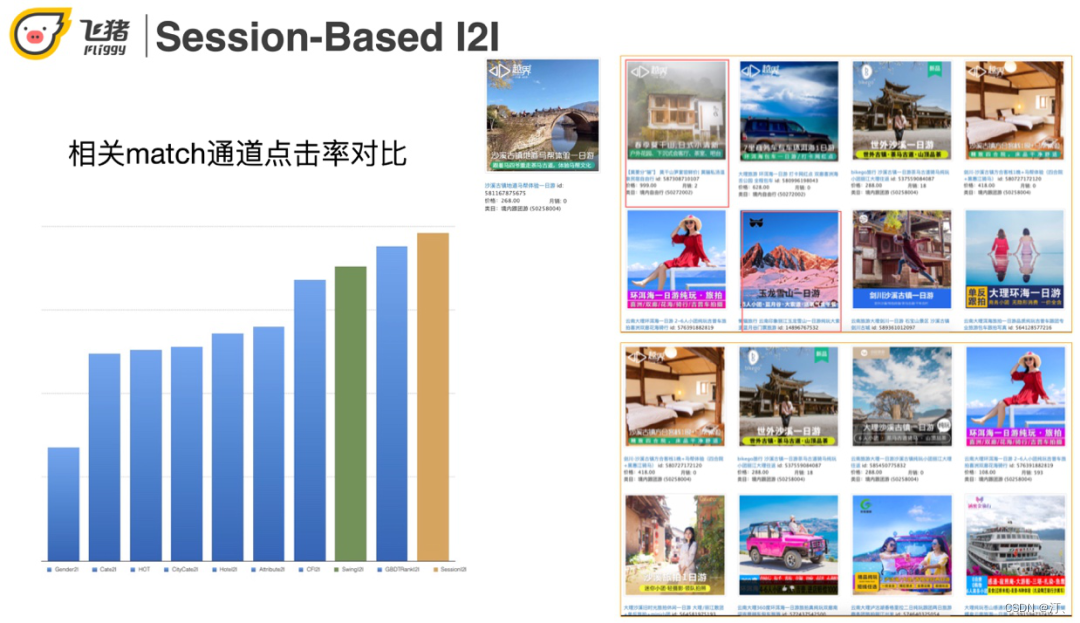
在這個case中,上面是傳統swing的召回結果,下面是基於session的召回結果。當trigger是沙溪古鎮一日遊的時候,上面有一個杭州莫干山和玉龍雪山一日遊,這兩個不相關結果的出現是因為它們是熱門商品,也稱哈利波特效應。下面的召回結果就都是和沙溪古鎮相關的了。從指標來看,session-based召回比swing和itemCF都高。
2.4.2 Meta-Path Graph Embedding

基於I2I相關矩陣的優點是相關性好,缺點是覆蓋率比較低。而Embed的方式雖然新穎性好但是相關性差。右邊的case是Embed的召回結果,上海迪士尼樂園召回了一個珠海長隆的企鵝酒店和香港迪士尼。我們期望的應該是在上海具有親子屬性,或者在上海迪士尼附近的景點。
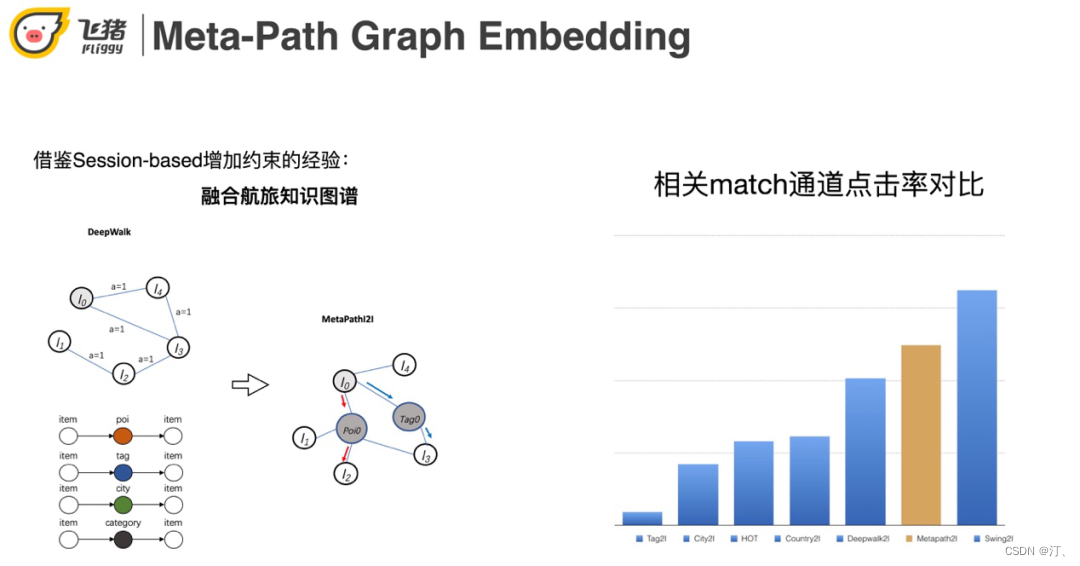
解決Embed相關性低的方式借鑑了session-based召回的經驗,將航旅知識圖譜融合,構建航旅特定的Meta-Path。效果上看meta-path的效果是比deepwalk更好。
2.5週期性復購的召回
復購場景的需求來自於:飛豬有大量的差旅和回家使用者,該部分使用者的行為有固定模式,會在特定的時間進行酒店和交通的購買,那麼該如何滿足這部分使用者的需求?
2.5.1 Rebuy2I

我們的目標是在正確的時間點來給使用者推出合適的復購商品,下面以酒店為例具體講解 ( 其他的品類原理類似 )。

輸入使用者在飛豬的酒店歷史購買資料,輸出是使用者在某個時間點對某個酒店的復購概率。當有多個可復購酒店時,按照概率降序排序。

常見做法有以下幾種:
-
利用酒店本身的復購概率
-
基於使用者購買歷史的Retarget
-
利用Poission-Gamma分佈的統計建模

首先取使用者對酒店的購買歷史,利用矩估計/引數估計計算酒店的購買頻次 ( 引數α和β )。接下來就可以調整每個使用者的購買概率,k是購買次數,t是第一次購買距離最近一次購買的時間間隔。最後代入Possion分佈計算復購概率,加入使用者的平均購買週期來緩解剛剛完成購買的酒店復購概率最大的問題。
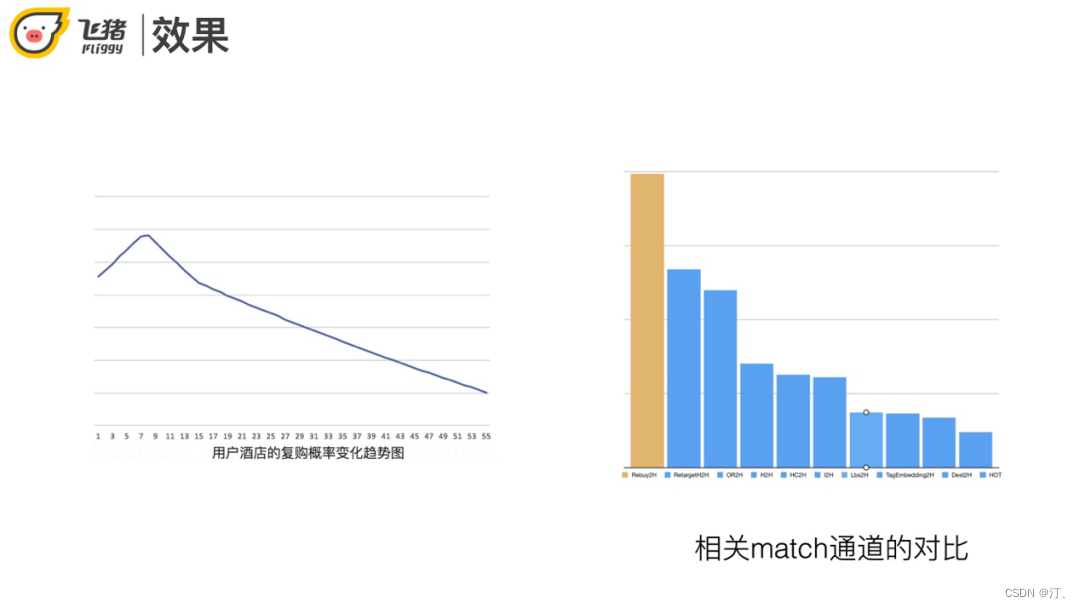
從左圖可以看出在購買一段時間以後,復購概率達到最大值,之後遞減。實際使用中復購單獨作為一路召回,效果比前面提到的retarget和熱門召回更好。
2.6 總結

最後總結一下做好召回的幾個思路:
首先要基於業務場景,來發掘使用者需求,發現自有場景的特點。接下來通過case和資料分析來發現問題,通過理解模型結構或者特徵背後的動機進行鍼對性的改進。最後在召回和排序之間找到邊界,效果和效能之間做好trade-off。
2.7 Q&A
Q:Journey2i的雙塔模型如何負取樣,正負比例如何控制?
A:關於召回的負取樣是一個非常值得研究的問題。我們也做了很多嘗試,例如我們曾經嘗試過按照排序的套路用曝光樣本做負樣本,但是效果很差。然後也進行了全域性負取樣,效果要明顯好於曝光的方式,但是負樣本如何採也值得一提,採得太隨機,你的負樣本容易太easy,模型的auc可能虛高,因此也要新增一些hard的樣本,在journey2i中就是那些屬於本次行程相關城市目的地的商品,但是使用者不太可能購買的商品,具體的方式這裡不展開介紹了。Facebook在KDD2020中有篇論文也對召回的取樣問題做了詳細的介紹,推薦閱讀。關於正負比例,我們的經驗是沒有絕對的答案,需要在優化過程中摸索,不過一般只要抽樣方式ok,正負比例的變化不會對最終結果有太大的影響。
Q:Journey2I無法考慮互動特徵,是否會有影響?
A:肯定會有影響。理論上講,沒有Journey和target item的互動特徵,auc和準確率肯定會打折扣,但是需要針對具體問題具體分析,做召回的優化和排序有個很明顯的不同就是需要在效能、準確率、多樣性上做trade-off。
Q:meta-path,session-base解決問題和出發點是什麼?
A:session-base解決的是擴充稀疏的資料後會帶來興趣發散的問題。舉個極端的例子,有個使用者每個月都出差,去到不同的地點。召回結果就會混合多個地點。Meta-path解決的是相關性低的問題。