解密Prompt系列2. 凍結Prompt微調LM: T5 & PET & LM-BFF
這一章我們介紹固定prompt微調LM的相關模型,他們的特點都是針對不同的下游任務設計不同的prompt模板,在微調過程中固定模板對預訓練模型進行微調。以下按時間順序介紹,支援任意NLP任務的T5,針對文字分類的兩篇PET和LM-BFF。
在小樣本場景,固定prompt微調LM對比常規微調的優點,在分類任務上比較直觀我能想到的有三點(在下面PET中會細說)
- 無需額外的分類層的引數引入,微調成本低
- 標籤詞本身前置語意資訊的引入,無需重頭學習可類比MRC
- 微調和預訓練的Gap更小,任務轉化成LM任務後一致性高
T5
- paper: 2019.10 Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- Task: Everything
- Prompt: 字首式人工prompt
- Model: Encoder-Decoder
- Take Away: 加入字首Prompt,所有NLP任務都可以轉化為文字生成任務
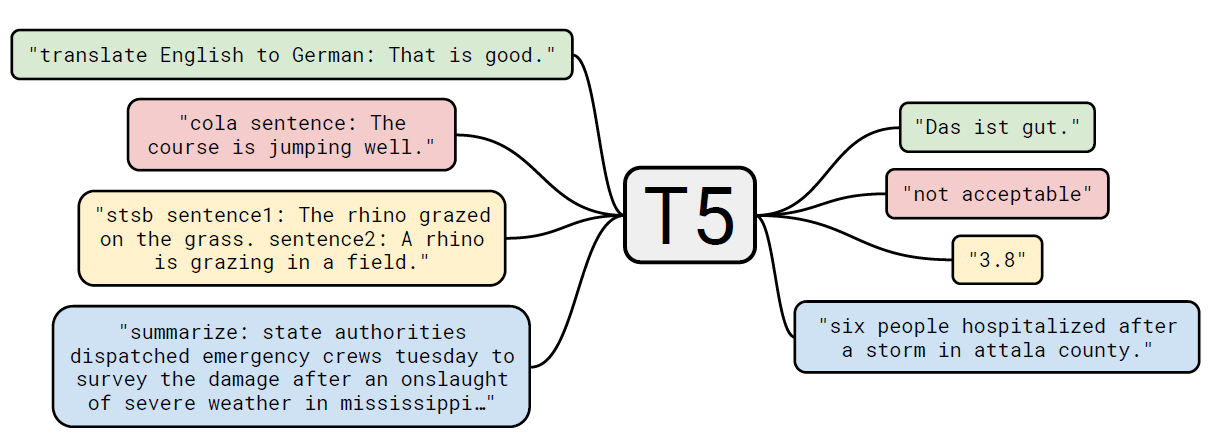
T5論文的初衷如標題所言,是為了全面公平的對比不同預訓練和遷移策略的貢獻和效果,避免在A模型上效果不好的預訓練目標在B上可能效果更優的情況,對比項包括
- 預訓練目標:語言模型,亂序還原,MLM(不同的掩位元速率),Span掩碼, etc
- 預訓練資料:構建C4資料集,從C4抽取不同領域語料來訓練
- 模型架構: Encoder-Decoder,Decoder Only,Encoder Only
- 遷移策略:逐步解凍,全量微調,區域性微調
- 其他:多工預訓練,模型大小
說句題外話,再看論文結果發現Encoder-Decoder的模型結果+SpanMLM損失函數效果最好。不知道這是否是谷歌押注T5,而沒有像OpenAI一樣選擇Deocder結構的原因。
具體對比結果這裡不細說,本文只關注T5為了公平對比以上差異,提出的Text2Text的通用建模框架:用相同的模型,相同的預訓練,相同的損失函數和解碼方式,把文字分類,摘要,翻譯,QA都轉化成了生成任務,而轉化的方式就是通過加入字首prompt。
針對不同的下游微調任務,我們看下T5提出的Text2Text是如何構建prompt模板的
- WMT英語到德語的翻譯任務,輸入是'translate English to German:'+input, 輸出是翻譯結果
- CNN Mail摘要任務: 文字摘要任務,輸入是‘Summarize:'+input,輸出是摘要
- MNLI任務:輸入是'mnli hypothesis:'+假設+'premise:'+敘述,輸出是contradiction, entailment,neutral
- STS文字相似任務:輸入是'stsb sentence1:'+input1+‘sentence2:’+input2, 輸出是1~5的打分(離散化)
- 問答SQuAD任務:輸入是'question:'+提問+ 'context:'+上下文,輸出是答案
不難發現在T5的時代,prompt模板的構建還比較粗糙,更多是單純的任務名稱+任務型別來區分不同的NLP任務,只是讓模型在解碼時多一層條件概率,既給定不同prompt字首在解碼時採用不同的條件概率(attention)。並沒有太多從語意和上下文關聯的角度去進行prompt模板的構建,我猜這是T5在論文中提到他們嘗試了不同的prompt模板發現效果影響有限的原因(哈哈因為都不太好所以沒啥差異),不不能否定T5在通用LM上做出的貢獻~
PET-TC(a)
- paper a: 2020.1 Exploiting Cloze Questions for Few Shot Text Classification and Natural
- prompt: 單字完形填空式人工Prompt
- Task: Text Classification
- Model: Roberta-large, XLM-R
- Take Away: 加入完形填空式Prompt把文字分類任務轉化成單字MLM
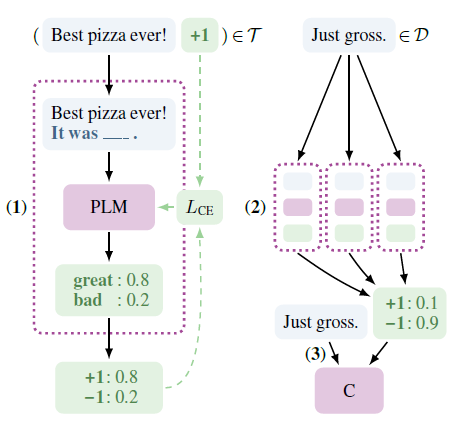
和第一章的LAMA相似,PET-TC也是把輸入對映成完形填空式的prompt模板,對掩碼詞進行預測作為分類標籤。不過PET沒有直接使用prompt,而是用了半監督的方案。用多個prompt模板微調模型後,對大規模無監督資料進行預測,然後在偽標籤上進行常規的模型微調,哈哈繞了一個圈最後還是輸出的常規微調的模型。我大膽猜測作者很看好prompt正規化在微調時引入的前置語意資訊,以及無額外引數的設定,但是對不同prompt和answer模板帶來的不穩定性感到頭疼,於是搞出這麼個折中的方法~
prompt & Answer Engineer
PET針對每個資料集人工設計了prompt模板和Answer詞對標籤的對映。針對單雙文字輸入分別舉兩個例子,以下a,b為原始輸入文字,'_'位置為MASK詞
- 單輸入:Yelp評論1~5星打分,標籤詞分別為terrible, bad,okay,good,great

- 雙輸入:AG's News新聞四分類問題, 標籤詞分別為分類名稱Worlds,Sports, Business, Science/Tech,

可以看出作者構建prompt模板的思路是儘可能還原文字所在的上下文場景,Answer詞的選取是一對一的構建模式,每個label只選取一個詞來表示。
固定prompt微調LM
完形填空式的prompt模板在微調時的優勢,我認為主要有以下三點
- 沒有額外引數的引入,常規微調需要引入hidden_size * label_size的額外引數(classify head)作為每個標籤對應的空間表徵,這部分需要針對下游任務重頭學習。而完形填空的token是在原始vocab中的,於是只需要調整標籤詞的預訓練表徵讓它在label上線性可分即可
- 前置語意資訊的引入,因為標籤詞的選取本身符合label的原始語意,例如以上YELP評論打分中的5個形容詞本身就是隱含了評論質量資訊的,所以會引入部分前置資訊,避免重頭學習,這一點和MRC有些相似
- 預訓練和微調的一致性高,都是解決完形填空問題,學習目標一致
微調的損失函數是交叉熵,作者沒有引入額外引數,而是把MASK位置上模型的預估logits在label上歸一化來得到分類預測。例如上面的AG新聞分類任務,先得到MASK位置worlds,sports,business,science這四個詞的預測logits,然後歸一化得到預估概率,再和分類標籤計算交叉熵。
為了避免災難遺忘作者在下游任務微調時加入了預訓練的MLM任務,於是微調的損失函數如下
半監督+蒸餾
這部分的設計可以和prompt的部分分開來看,是一個半監督方案。以上每個任務對應的多個prompt模板,分別固定prompt微調LM得到一版模型,然後在大量的未標註樣本上進行預測,再對多個模型的預測值進行加權得到偽標籤。
最終在為標籤上使用常規的微調方案(加classifier head),訓練模型作為輸出,這一步類比知識蒸餾。所以PET最後輸出的還是常規的監督微調模型,Prompt只是被當做了一種半監督方案。效果上在小樣本的設定上比直接使用監督微調都有一定的效果提升。
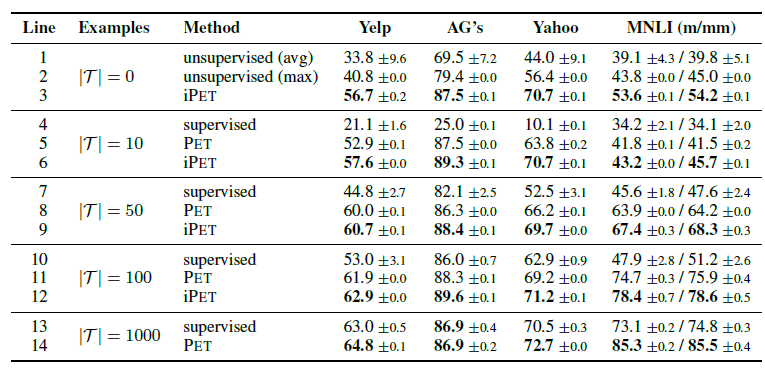
作者還做了iPET對以上過程通過迭代逐步擴巨量資料集,提高偽標籤準確率的方案,不過這麼麻煩的實現一點都不適合我這種懶人,哈哈就不細說了~
針對PET有幾點疑問
- 完形填空類的prompt,在微調過程中可能的災難遺忘,是否因為對label詞的微調偏離了詞在原始文字中語意表徵,以及和其他詞的相對位置
- prompt模板差異帶來的效果差異尚未解決,人工構建的prompt模板不一定是最優的
- Answer詞單token,以及和label一一對應的設定,限制性較強。這部分在後面的續作裡作者做了改良
後面介紹的幾個模型,大多是基於PET上述問題的改良~
PET-TC(B)
- paper b: 2020.9 It’s not just size that matters: Small language models are also few-shot learners.
- Prompt: 多字完形填空式人工Prompt
- Task:Text Classification
- Model: Albert-xxlarge-v2
- Take Away: 支援多字的完形填空Prompt,效果超越GPT3
這篇paper和上面的PET-TC是同一作者,算是上文的續作,主要優化了Answer詞單token設定,支援多個token作為標籤詞,不過限制性依舊較強是預先設定任務最大的token數,然後使用最大token數作為MASK數量,而非動態的任意數量的MASK填充。
論文對推理和訓練中的多MASK填充做了不同的處理。在推理中需要向前傳導K次,如下圖所示
- 使用標籤最大的label詞長度K,生成k個MASK位置
- 對K個位置同時預估得到K個預估詞,選取概率最高的1個詞進行填充
- 針對填充後的新文字,對剩餘K-1個位置再進行預估
- 直到所有位置都被填充,分類概率由所有填充標籤詞的概率累乘得到

在訓練過程中為了提升效率,論文使用了一次向前傳導對多個位置同時完成預估,這時MASK長度是所有標籤的最大長度。例如情感分類問題terr##ble長度為2,great長度為1,這時MASK填充長度為2,great只取第一個MASK詞的概率,後面的忽略,概率計算如下
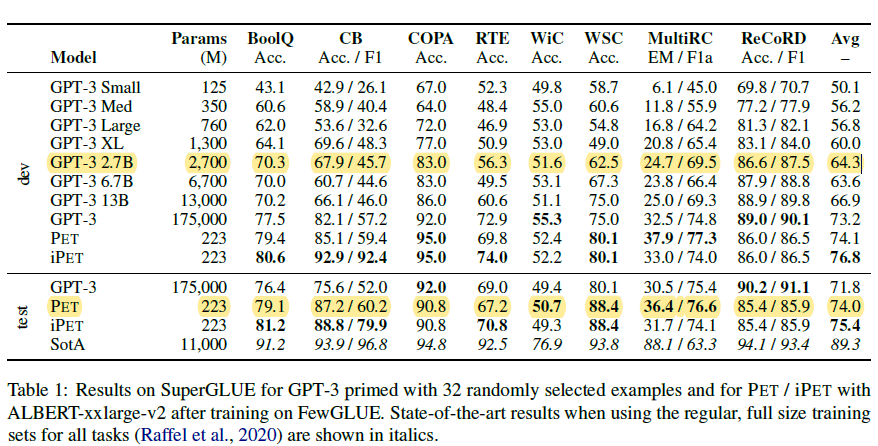
其他部分和PET基本一樣這裡不再重複。效果上這篇論文換成了Albert-xxlarge-v2模型和GPT-3 few-shot在superGLUE上進行效果對比。不過以下引數對比並不太合理,雖然Albert是層共用引數,但是推理速度並無提升,12層的xxlarge模型參與計算的引數量級應該是223M*12~2B,所以並不是嚴格意義上的小模型。調整引數後,32個小樣本上PET的效果也是超過同等量級甚至更大的GPT3在few-shot上的效果的
LM-BFF
- paper: 2020.12 Making Pre-trained Language Models Better Few-shot Learners
- Prompt: 完形填空自動搜尋prompt
- Task: Text Classification
- Model: Bert or Roberta
- Take Away: 把人工構建prompt模板和標籤詞優化為自動搜尋
LM-BFF是陳丹琦團隊在20年底提出的針對few-shot場景,自動搜尋模板和觸發詞的Prompt方案,prompt模板延續了PET的完型填空形式,把人工構建prompt和標籤詞的構建優化成了自動搜尋。論文先是驗證了相同模板不同標籤詞,和相同標籤詞不同模板對模型效果都有顯著影響,如下
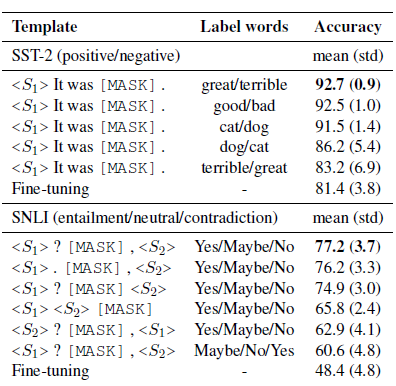
以下介紹自動搜尋的部分
標籤詞搜尋
考慮在全vocab上搜尋標籤詞搜尋空間太大,在少量樣本上直接微調選擇最優的標籤詞會存在過擬合的問題。作者先通過zero-shot縮小候選詞範圍,再通過微調選擇最優標籤詞。
如下,固定prompt模板(L),作者用訓練集中每個分類(c)的資料,在預訓練模型上分別計算該分類下MASK詞的概率分佈,選擇概率之和在Top-k的單詞作為候選詞。再結合所有分類Top-K的候選詞,得到n個標籤詞組合。這裡的n和k都是超參,在100~1000不等。
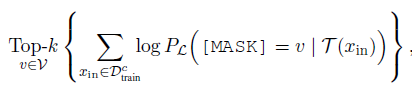
然後在n個候選標籤詞組合中,針對微調後在驗證集的準確率,選擇效果最好的標籤詞組合。
prompt模板搜尋
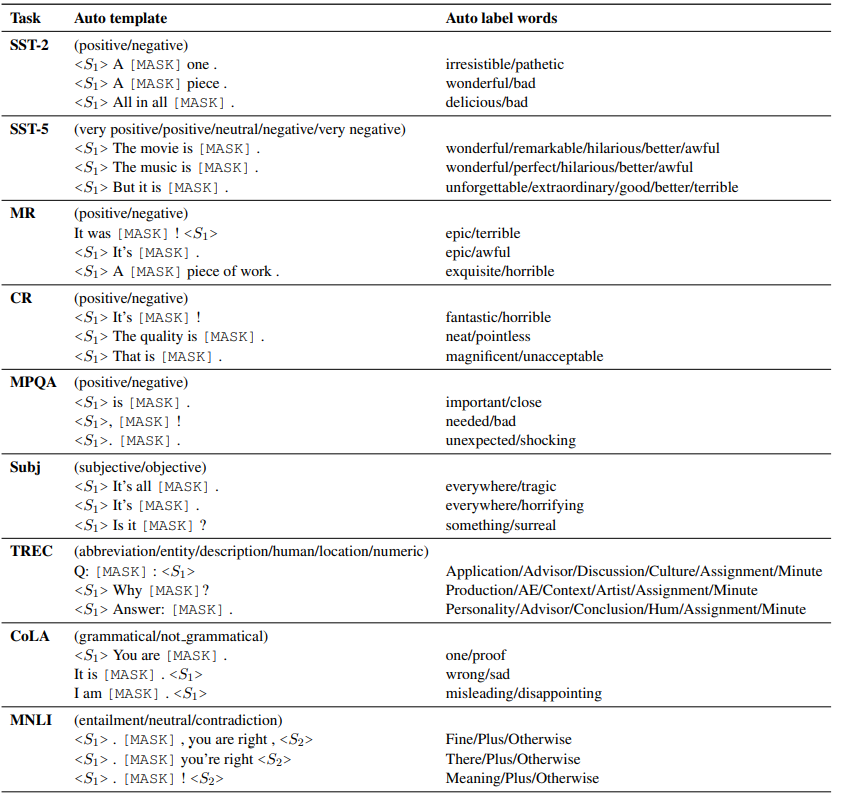
固定標籤詞,作者使用T5來進行模板生成,讓T5負責在標籤詞前、後生成符合上下文語意的prompt指令,再在所有訓練樣本中選擇整體表現最優的prompt模板。
如下, 固定二分類的標籤詞是great和terrible,T5的模型輸入為Input+MASK+標籤對應標籤詞+MASK,讓模型來完成對MASK部分的填充。現在預訓練模型中通過Beam-Search得到多個模板,再在下游任務中微調得到表現最好的一個或多個prompt模板

以上自動搜尋prompt和標籤詞得到的部分結果如下,該說不說這種方案得到的標籤詞,至少直觀看上去比AutoPrompt合(人)理(類)不(能)少(懂):
固定prompt微調LM

經過以上搜素得到最優標籤詞組合和prompt模板後,作者的微調過程模仿了GPT3的few-shot構建方式。如上圖,先把輸入填充進prompt模板,再從各個分類中各取樣1個樣本作為指令樣本拼接進輸入,為待預測文字補充更豐富的上下文,一起輸入模型。在訓練和推理時,補充的指令樣本都是從訓練集中取樣。
同時為了避免加入的指令樣本和待預測樣本之間差異較大,導致模型可能直接無視接在prompt後面的指令樣本,作者使用Sentence-Bert來篩選語意相似的樣本作為指令樣本。
效果上,作者給出了每類取樣16個樣本的小樣本場景下, Roberta-Large的效果,可以得到以下insights
- 部分場景下自動模板是要優於手工模板的,整體上可以打平,自動搜尋是人工成本的平價替代
- 加入指令樣本對效果有顯著提升
- 在16個樣本的few-shot場景下,prompt微調效果是顯著優於常規微調和GPT3 few-shot效果的
