Prometheus&Alertmanager告警推播
前言
儘管可以通過視覺化資料監控系統執行狀態,但我們無法時刻關注系統執行,因此需要一些實時執行的工具能夠輔助監控系統執行,當系統出現執行問題時,能夠通知我們,以此確保系統穩定性,告警便是作為度量指標監控中及其重要的一環。
Prometheus告警介紹
在Prometheus中,告警模組為Alertmanager,可以提供多種告警通道、方式來使得系統出現問題可以推播告警訊息給相關人員。
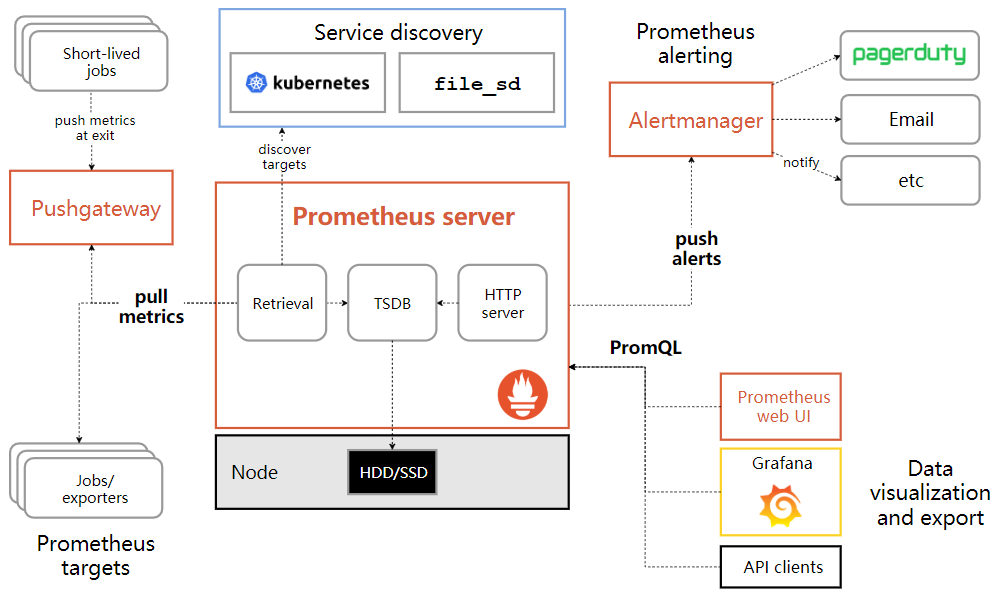
Prometheus Server中的告警規則會向Alertmanager傳送。Alertmanager管理這些告警,包括進行去重,分組和路由,以及告警的靜默和抑制,通過電子郵件、實時通知系統和聊天平臺等方法傳送通知。
- 定義告警規則(Alerting rule)
- 告警模組訊息推播(Alertmanager)
- 告警推播(Prometheus server推播告警規則到Alertmanager)
Alertmanager
Alertmanager是一個獨立的告警模組,接收Prometheus server發來的告警規則,通過去重、分組、靜默和抑制等處理,並將它們通過路由傳送給正確的接收器。
核心概念
- 分組(Grouping): 是Alertmanager把同型別的告警進行分組,合併多條告警合併成一個通知。當系統中許多範例出問題時又或是網路延遲、延遲導致網路抖動等問題導致連結故障,會引發大量告警,在這種情況下使用分組機制,把這些被觸發的告警合併為一個告警進行通知,從而避免瞬間突發性的接受大量告警通知,使得相關人員可以對問題快速定位,而不至於淹沒在告警中。
- 抑制(Inhibition): 是當某條告警已經傳送,停止重複傳送由此告警引發的其他異常或故障的告警機制,以避免收到過多無用的告警通知。
- 靜默(Silences): 可對告警進行靜默處理的簡單機制。對傳進來的告警進行匹配檢查,如果告警符合靜默的設定,Alertmanager 則不會傳送告警通知。
設定Alertmanager.yml
cd /opt
mkdir alertmanager
cd alertmanager
touch alertmanager.yml
組態檔主要包含以下幾個部分:
- 全域性設定(global):用於定義一些全域性的公共引數,如全域性的SMTP設定,Slack設定等內容;
- 模板(templates):用於定義告警通知時的模板,如HTML模板,郵件模板,企業微信模板等;
- 告警路由(route):根據標籤匹配,確定當前告警應該如何處理;
- 接收人(receivers):接收人是一個抽象的概念,它可以是一個郵箱也可以是微信,Slack或者Webhook等,接收人一般配合告警路由使用;
組態檔內容:
global:
resolve_timeout: 2m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: [email protected]
smtp_auth_username: [email protected]
smtp_auth_password: 授權碼
templates:
- /etc/alertmanager/template/*.tmpl
route:
group_by:
- alertname_wechat
group_wait: 10s
group_interval: 10s
receiver: wechat
repeat_interval: 1h
receivers:
- name: wechat
email_configs:
- to: [email protected]
send_resolved: true
wechat_configs:
- corp_id: wechat_corp_id
to_party: wechat_to_party
agent_id: wechat_agent_id
api_secret: wechat_apisecret
send_resolved: true
此處設定推播訊息到郵箱和企業微信,Alertmanager內建了對企業微信的支援。
https://prometheus.io/docs/alerting/latest/configuration/
設定訊息模板
cd /opt/alertmanager
mkdir template
cd template
touch wechat.tmpl
編輯檔案內容,設定模板格式
{{ define "wechat.default.message" }}
{{ range $i, $alert :=.Alerts }}
========監控報警==========
告警狀態:{{ .Status }}
告警級別:{{ $alert.Labels.severity }}
告警型別:{{ $alert.Labels.alertname }}
告警應用:{{ $alert.Annotations.summary }}
告警主機:{{ $alert.Labels.instance }}
告警詳情:{{ $alert.Annotations.description }}
觸發閥值:{{ $alert.Annotations.value }}
告警時間:{{ $alert.StartsAt.Format "2023-02-19 10:00:00" }}
========end=============
{{ end }}
{{ end }}
部署Alertmanager
docker run -d -p 9093:9093 --name StarCityAlertmanager -v /opt/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml -v /opt/alertmanager/template:/etc/alertmanager/template docker.io/prom/alertmanager:latest
告警通知測試
可通過請求Alertmanager Api模擬告警規則來推播告警通知。
curl --location 'http://Host:9093/api/v2/alerts' \
--header 'Content-Type: application/json' \
--data '[
{
"labels": {
"severity": "Warning",
"alertname": "記憶體使用過高",
"instance": "範例1",
"msgtype": "testing"
},
"annotations": {
"summary": "node",
"description": "請檢查範例1",
"value": "0.95"
}
},
{
"labels": {
"severity": "Warning",
"alertname": "CPU使用過高",
"instance": "範例2",
"msgtype": "testing"
},
"annotations": {
"summary": "node",
"description": "請檢查範例2",
"value": "0.90"
}
}
]'
傳送完畢,可以在企業微信和郵件中收到告警通知,如在郵箱中收到資訊。

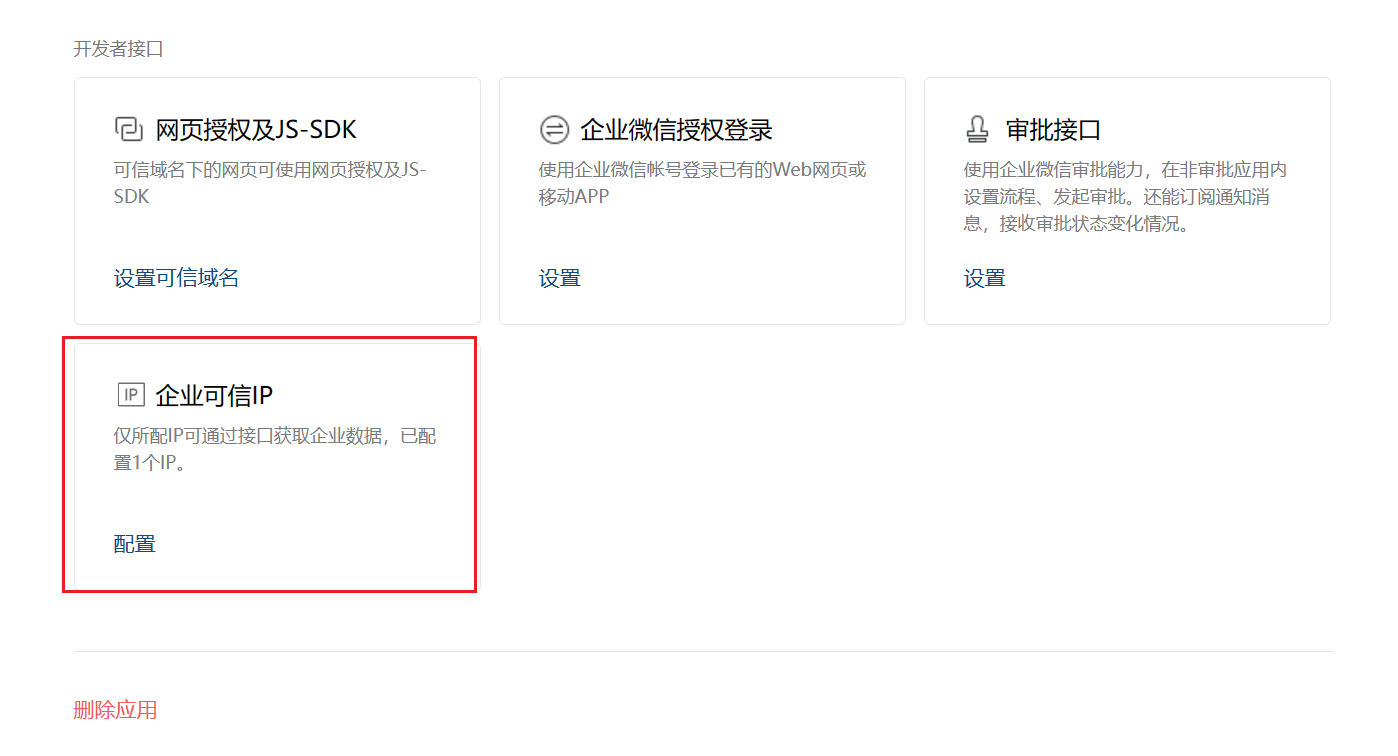
注意:如果告警設定完畢,但測試時企業微信怎麼也收不到訊息,需要設定企業自建應用底部可信IP選單
告警規則
設定告警規則
cd /opt/prometheus
touch rules.yml
告警規則內容
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 10s
labels:
name: instance
severity: Critical
annotations:
summary: ' {{ $labels.appname }}'
description: ' The service stops running '
value: '{{ $value }}%'
- name: Host
rules:
- alert: HostMemory Usage
expr: >-
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes +
node_memory_Buffers_bytes + node_memory_Cached_bytes)) /
node_memory_MemTotal_bytes * 100 > 80
for: 10s
labels:
name: Memory
severity: Warning
annotations:
summary: ' {{ $labels.appname }} '
description: ' The instance memory usage exceeded 80%. '
value: '{{ $value }}'
- alert: HostCPU Usage
expr: >-
sum(avg without
(cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by
(instance,appname) > 0.65
for: 10s
labels:
name: CPU
severity: Warning
annotations:
summary: ' {{ $labels.appname }} '
description: The CPU usage of the instance is exceeded 65%.
value: '{{ $value }}'
- alert: HostLoad
expr: node_load5 > 4
for: 10s
labels:
name: Load
severity: Warning
annotations:
summary: '{{ $labels.appname }} '
description: ' The instance load exceeds the default value for 5 minutes.'
value: '{{ $value }}'
- alert: HostFilesystem Usage
expr: 1-(node_filesystem_free_bytes / node_filesystem_size_bytes) > 0.8
for: 10s
labels:
name: Disk
severity: Warning
annotations:
summary: ' {{ $labels.appname }} '
description: ' The instance [ {{ $labels.mountpoint }} ] partitioning is used by more than 80%.'
value: '{{ $value }}%'
- alert: HostDiskio
expr: 'irate(node_disk_writes_completed_total{job=~"Host"}[1m]) > 10'
for: 10s
labels:
name: Diskio
severity: Warning
annotations:
summary: ' {{ $labels.appname }} '
description: ' The instance [{{ $labels.device }}] average write IO load of the disk is high in 1 minute.'
value: '{{ $value }}iops'
- alert: Network_receive
expr: >-
irate(node_network_receive_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*|virbr.*|ovs-system"}[5m])
/ 1048576 > 3
for: 10s
labels:
name: Network_receive
severity: Warning
annotations:
summary: ' {{ $labels.appname }} '
description: ' The instance [{{ $labels.device }}] average traffic received by the NIC exceeds 3Mbps in 5 minutes.'
value: '{{ $value }}3Mbps'
- alert: Network_transmit
expr: >-
irate(node_network_transmit_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*|virbr.*|ovs-system"}[5m])
/ 1048576 > 3
for: 10s
labels:
name: Network_transmit
severity: Warning
annotations:
summary: ' {{ $labels.appname }} '
description: ' The instance [{{ $labels.device }}] average traffic sent by the network card exceeds 3Mbps in 5 minutes.'
value: '{{ $value }}3Mbps'
- name: Container
rules:
- alert: ContainerCPU Usage
expr: >-
(sum by(name,instance)
(rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 60
for: 10s
labels:
name: CPU
severity: Warning
annotations:
summary: '{{ $labels.name }} '
description: ' Container CPU usage over 60%.'
value: '{{ $value }}%'
- alert: ContainerMem Usage
expr: 'container_memory_usage_bytes{name=~".+"} / 1048576 > 1024'
for: 10s
labels:
name: Memory
severity: Warning
annotations:
summary: '{{ $labels.name }} '
description: ' Container memory usage exceeds 1GB.'
value: '{{ $value }}G'
修改prometheus.yml,增加告警規則,如下alerting和rule_files部分,重啟prometheus。
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: ['Host:9093']
rule_files:
- "rules.yml"
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- 'Prometheus Server Host:9090'
labels:
appname: Prometheus
- job_name: node
scrape_interval: 10s
static_configs:
- targets:
- 'Metrics Host:9100'
labels:
appname: node
- job_name: cadvisor
static_configs:
- targets:
- 'Metrics Host:58080'
- job_name: rabbitmq
scrape_interval: 10s
static_configs:
- targets:
- 'Metrics Host:9419'
labels:
appname: rabbitmq
再次存取prometheus可以看到告警規則
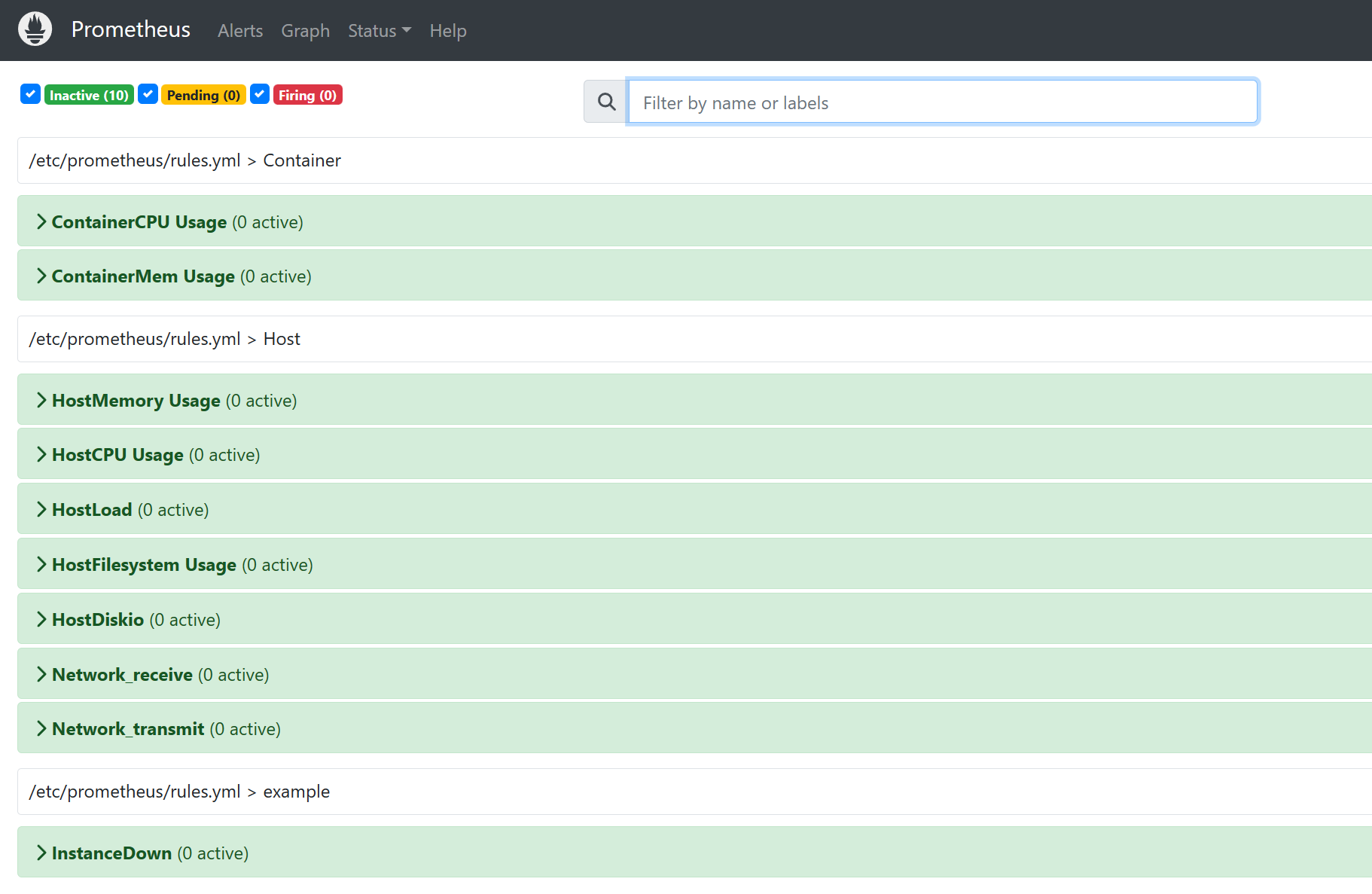
告警狀態
| 狀態 | 說明 |
|---|---|
| Inactive | 待啟用狀態,度量指標處在合適範圍內。 |
| Pending | 符合告警規則,但是低於設定的持續時間。這裡的持續時間即rule裡的FOR欄位設定的時間。該狀態下不傳送告警通知。 |
| Firing | 符合告警規則,而且超出設定的持續時間。該狀態下傳送告警到Alertmanager。 |
觸發告警
當系統達到預定告警條件並超出設定的持續時間,則觸發告警,推播告警訊息到Alertmanager。
此處設定系統CPU使用率超過限定條件,可以在prometheus中看到CPU使用率告警規則達到Pending狀態
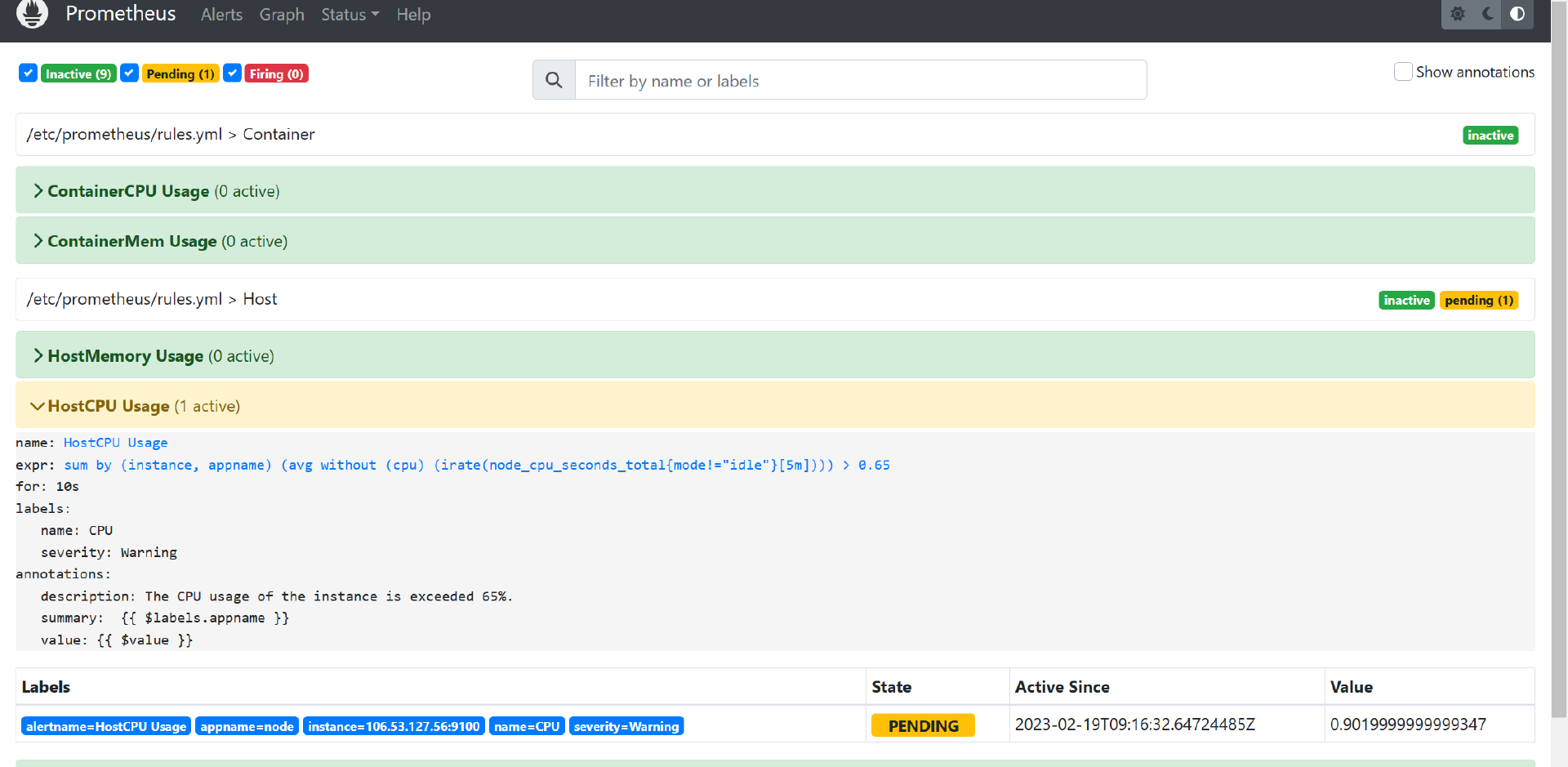
當超過設定的持續時間,狀態變更到Firing,訊息推播到Alertmanager

在Alertmanager Web中可以看到推播過來的告警資訊
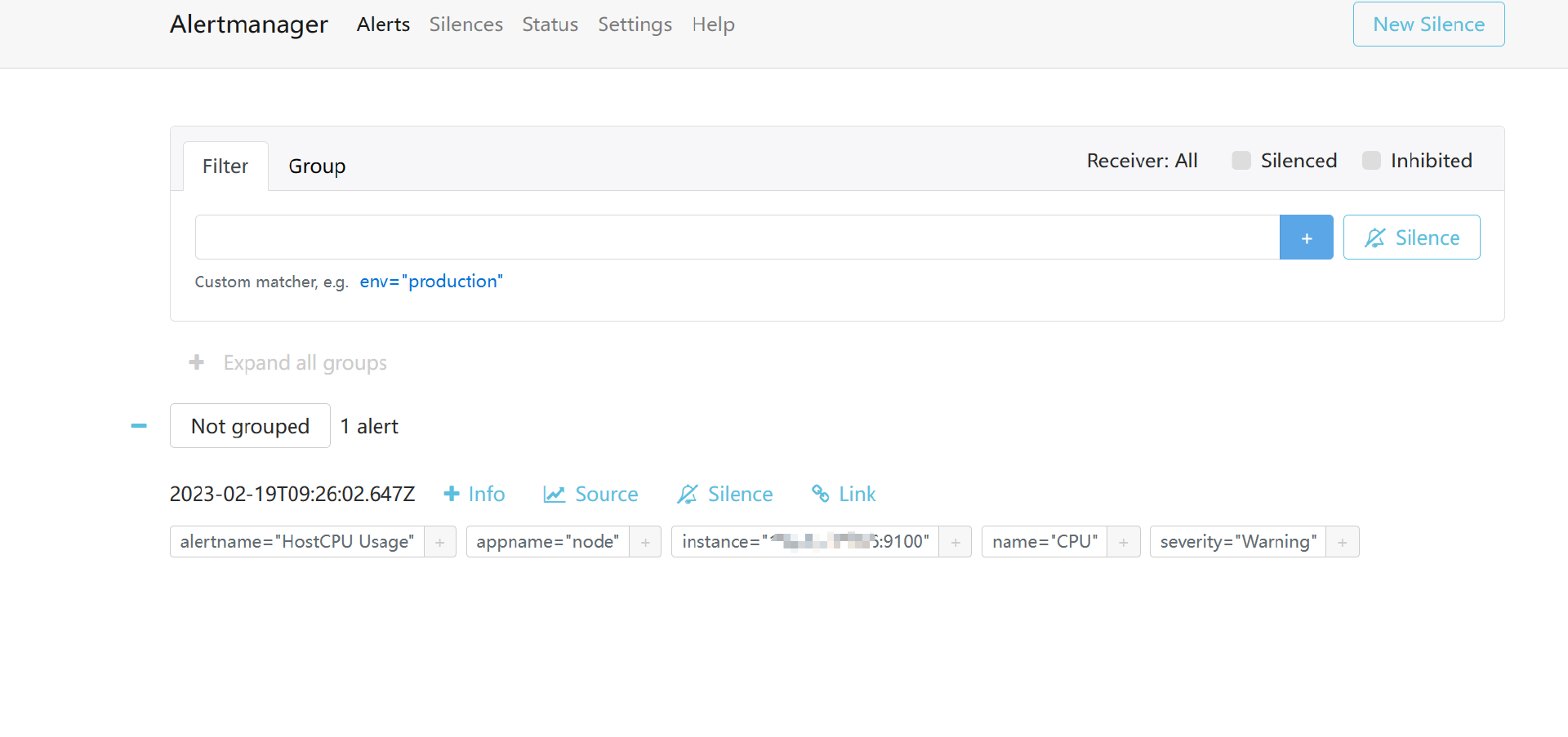
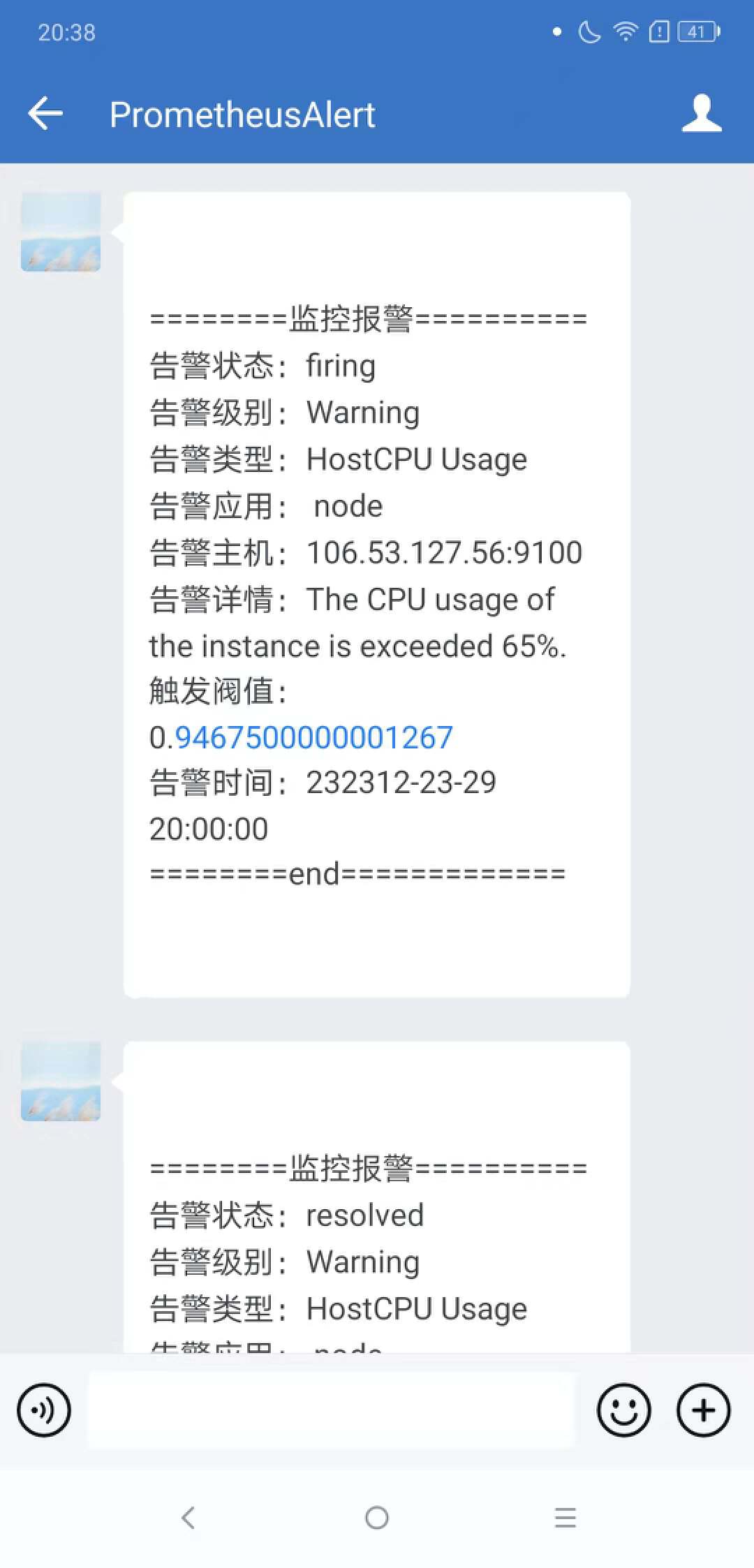
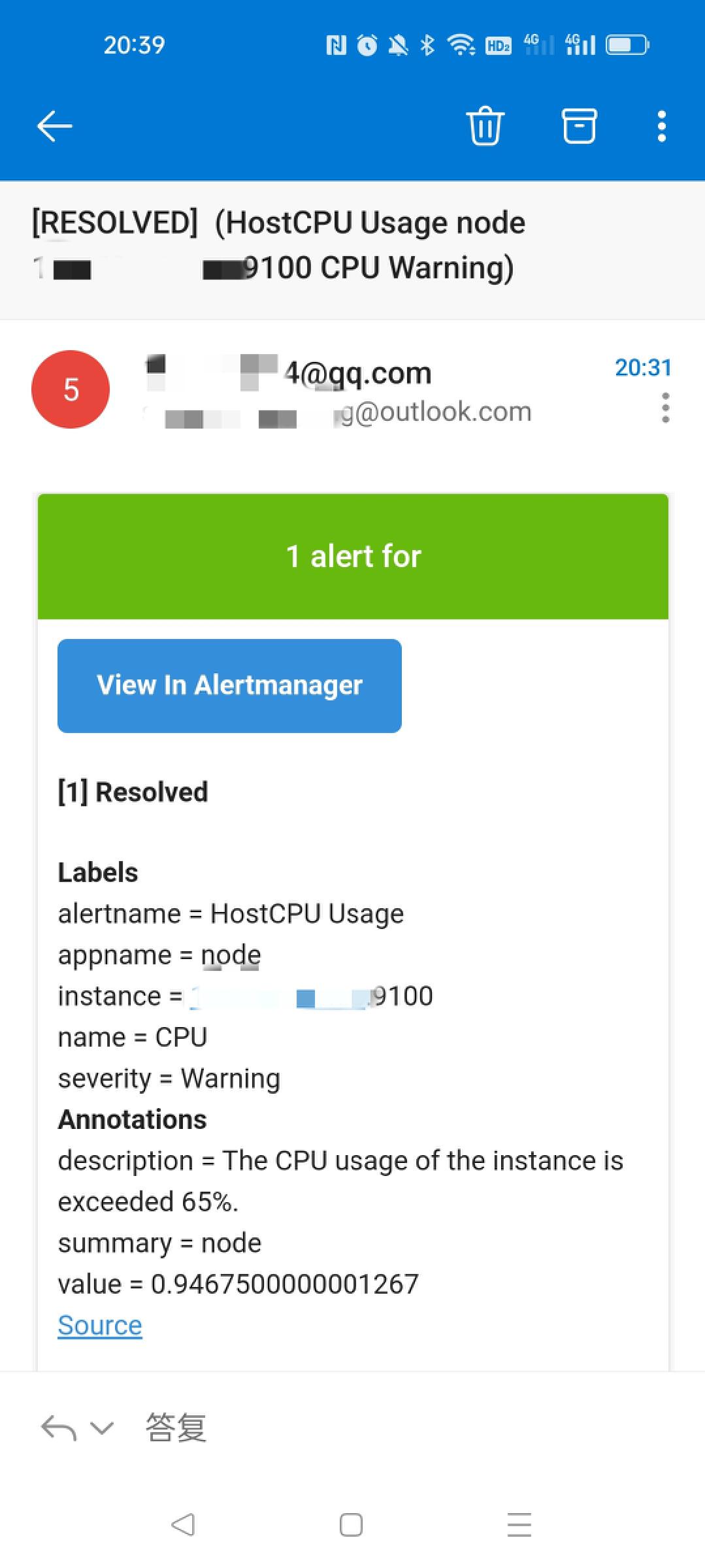
在企業微信和郵箱中也收到告警資訊
2023-02-23,望技術有成後能回來看見自己的腳步