深度學習基礎-優化演演算法詳解
前言
所謂深度神經網路的優化演演算法,即用來更新神經網路引數,並使損失函數最小化的演演算法。優化演演算法對於深度學習非常重要,如果說網路引數初始化(模型迭代的初始點)能夠決定模型是否收斂,那優化演演算法的效能則直接影響模型的訓練效率。
瞭解不同優化演演算法的原理及其超引數的作用將使我們更有效的調整優化器的超引數,從而提高模型的效能。
本文的優化演演算法特指: 尋找神經網路上的一組引數 $\theta $,它能顯著地降低損失函數 \(J(\theta )\),該損失函數通常包括整個訓練集上的效能評估和額外的正則化項。
本文損失函數、目標函數、代價函數不嚴格區分定義。
一,梯度下降優化演演算法
1.1,隨機梯度下降 SGD
梯度下降法是最基本的一類優化器,目前主要分為三種梯度下降法:標準梯度下降法(GD, Gradient Descent),隨機梯度下降法(SGD, Stochastic Gradient Descent)及批次梯度下降法(BGD, Batch Gradient Descent)。
深度學習專案中的 SGD 優化一般預設指批次梯度下降法。其演演算法描述如下:
-
輸入和超引數: \(\eta\) 全域性學習率
-
計算梯度:\(g_t = \nabla_\theta J(\theta_{t-1})\)
-
更新引數:\(\theta_t = \theta_{t-1} - \eta \cdot g_t\)
SGD 優化演演算法是最經典的神經網路優化方法,雖然收斂速度慢,但是收斂效果比較穩定。
下圖1展現了隨機梯度下降演演算法的梯度搜尋軌跡示意圖。可以看出由於梯度的隨機性質,梯度搜尋軌跡要很嘈雜(動盪現象)。
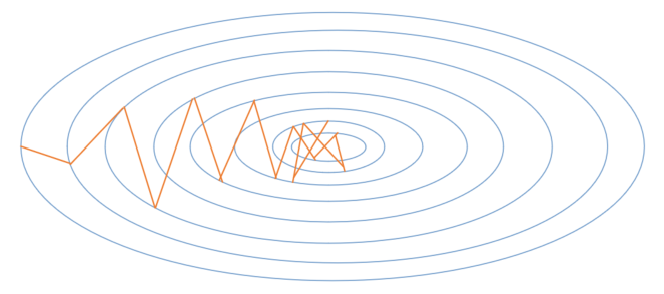
因此,在實際應用中,隨機梯度下降 SGD 法必須和動態學習率方法結合起來使用,否則使用固定學習率 + SGD的組合會使得模型收斂過程變得更復雜。
1.2,動量 Momentum
雖然隨機梯度下降仍然是非常受歡迎的優化方法,但其學習過程有時會很慢且其梯度更新方向完全依賴於當前 batch 樣本資料計算出的梯度,因而十分不穩定,因為資料可能有噪音。
受啟發於物理學研究領域研究,基於動量 Momentum (Polyak, 1964) 的 SGD 演演算法用於改善引數更新時可能產生的振盪現象。動量演演算法旨在加速學習,特別是處理高曲率、小但一致的梯度,或是帶噪聲的梯度。兩種演演算法效果對比如下圖 2所示。
花書中對動量演演算法對目的解釋是,解決兩個問題: Hessian 矩陣的病態條件和隨機梯度的方差。更偏學術化一點。
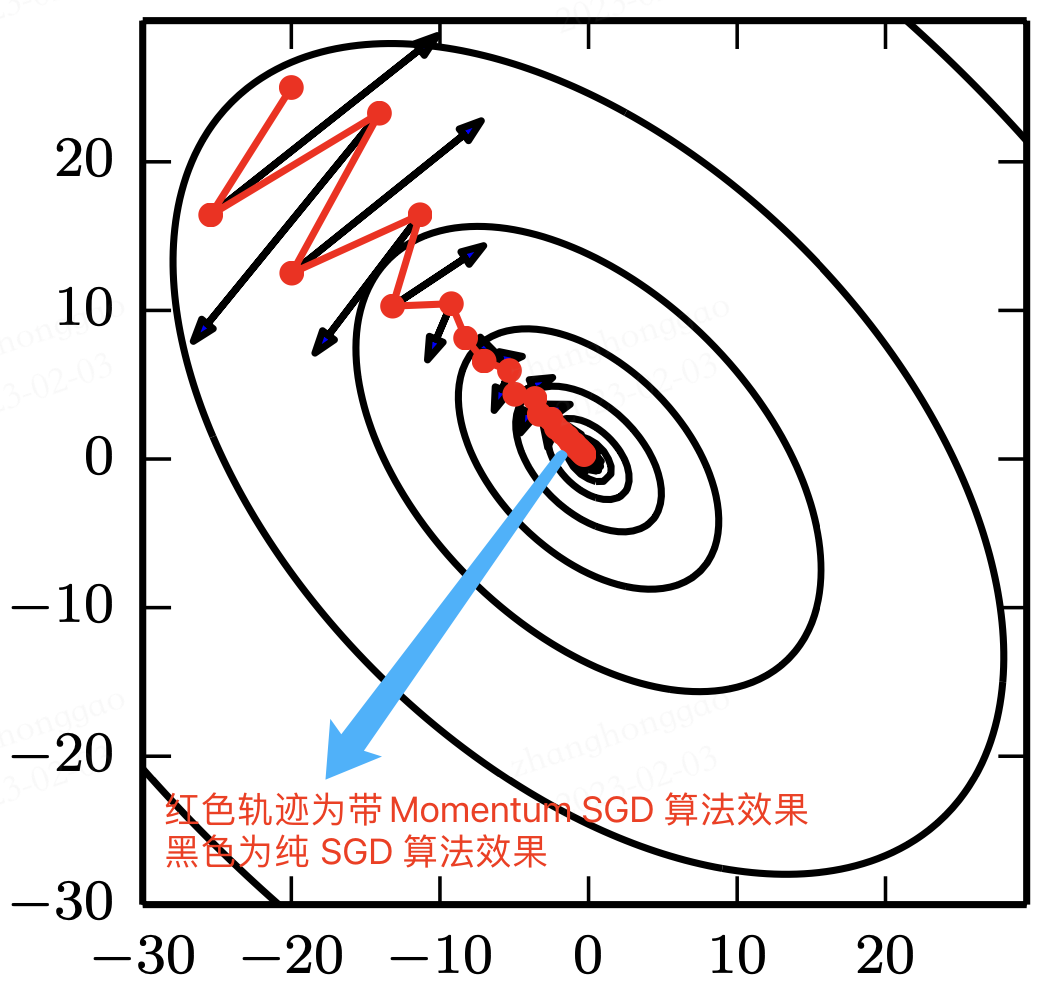
Momentum 演演算法的通俗理解就是,其模擬了物體運動時的慣性,即更新引數的時候會同時結合過去以及當前 batch 的梯度。演演算法在更新的時候會一定程度上保留之前更新的方向,同時利用當前 batch 的梯度微調最終的更新方向。這樣一來,可以在一定程度上增加穩定性,從而學習地更快,並且還有一定擺脫區域性最優的能力。
下圖3展現了動量演演算法的前進方向。
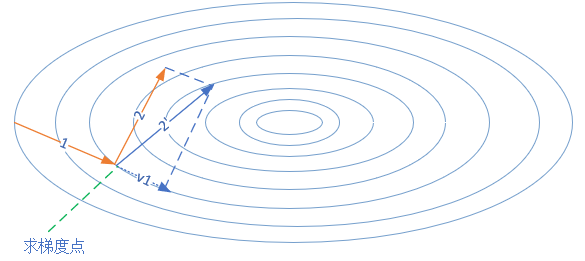
第一次的梯度更新完畢後,會記錄 \(v1\) 的動量值。在「求梯度點」進行第二次梯度檢查時,得到2號方向,與 \(v1\) 的動量組合後,最終的更新為 2' 方向。這樣一來,由於有 \(v1\) 的存在,會迫使梯度更新方向具備「慣性」,從而可以減小隨機樣本造成的震盪。
Momentum 演演算法描述如下:
1,輸入和引數:
- \(\eta\) - 全域性學習率
- \(\alpha\) - 動量引數,一般取值為 0.5, 0.9, 0.99,取
0,則等效於常規的隨機梯度下降法,其控制動量資訊對整體梯度更新的影響程度。 - \(v_t\) - 當前時刻的動量,初值為 0。
2,演演算法計算過程:
-
計算梯度:\(g_t = \nabla_\theta J(\theta_{t-1})\)
-
計算速度更新:\(v_t = \alpha \cdot v_{t-1} + \eta \cdot g_t\) (公式1)
-
更新引數:\(\theta_t = \theta_{t-1} - v_t\) (公式2)
注意,這裡的公式1和公式2和花書上的公式形式上略有不同,但其最終結果是相同的。本文給出的手工推導迭代公式,來源文章 15.2 梯度下降優化演演算法。
通過推導引數更新迭代公式,更容易理解演演算法,根據演演算法公式(1)(2),以\(W\)引數為例,有:
- \(v_0 = 0\)
- \(dW_0 = \nabla J(w)\)
- \(v_1 = \alpha v_0 + \eta \cdot dW_0 = \eta \cdot dW_0\)
- \(W_1 = W_0 - v_1=W_0 - \eta \cdot dW_0\)
- \(dW_1 = \nabla J(w)\)
- \(v_2 = \alpha v_1 + \eta dW_1\)
- \(W_2 = W_1 - v_2 = W_1 - (\alpha v_1 +\eta dW_1) = W_1 - \alpha \cdot \eta \cdot dW_0 - \eta \cdot dW_1\)
- \(dW_2 = \nabla J(w)\)
- \(v_3=\alpha v_2 + \eta dW_2\)
- \(W_3 = W_2 - v_3=W_2-(\alpha v_2 + \eta dW_2) = W_2 - \alpha^2 \eta dW_0 - \alpha \eta dW_1 - \eta dW_2\)
可以看出與普通 SGD 的演演算法 \(W_3 = W_2 - \eta dW_2\) 相比,動量法不但每次要減去當前梯度,還要減去歷史梯度\(W_0, W_1\) 乘以一個不斷減弱的因子\(\alpha\)、\(\alpha^2\),因為\(\alpha\)小於1,所以\(\alpha^2\)比\(\alpha\)小,\(\alpha^3\)比\(\alpha^2\)小。這種方式的學名叫做指數加權平均。
在實際模型訓練中,SGD 和動量法的比較如下表所示。
實驗效果對比圖來源於資料 1。
| 演演算法 | 損失函數和準確率 |
|---|---|
| SGD | 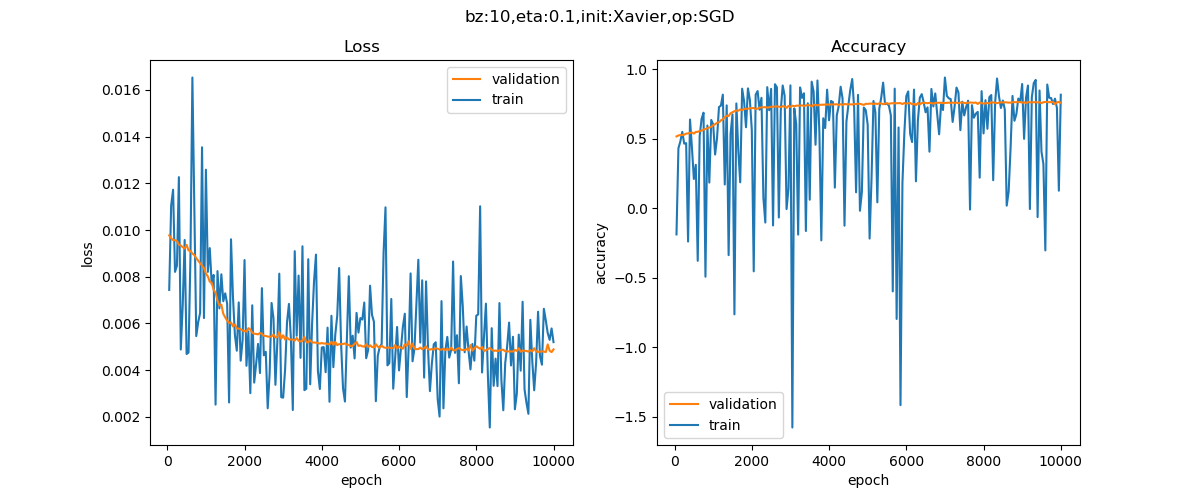 |
| Momentum | 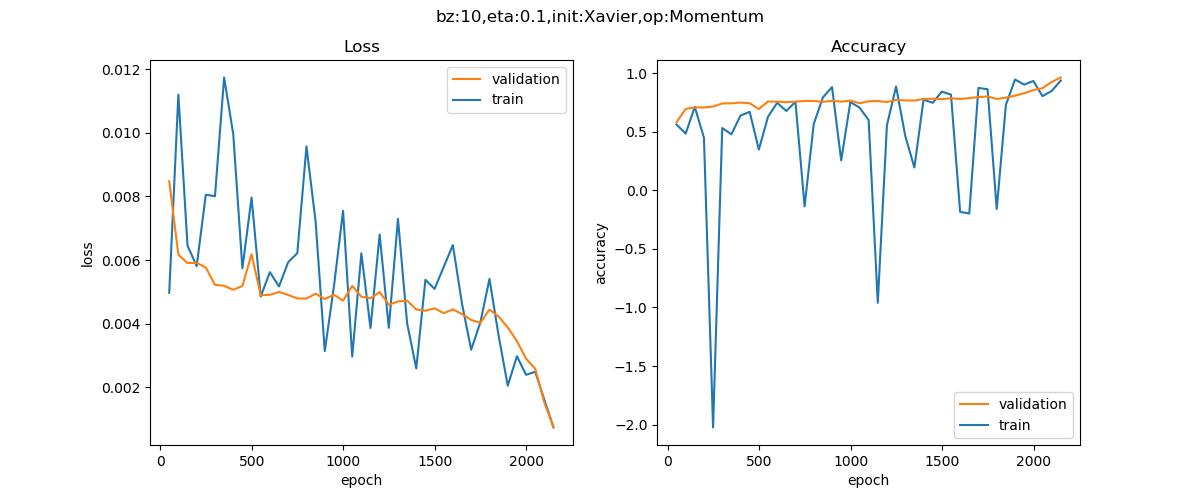 |
從上表的對比可以看出,同一個深度模型, 普通隨機梯度下降法的曲線震盪很嚴重,且經過 epoch=10000 次也沒有到達預定 0.001 的損失值;但動量演演算法經過 2000 個 epoch 就迭代結束。
1.3,Nesterov 動量
受 Nesterov 加速梯度演演算法 (Nesterov, 1983, 2004) 啟發,Sutskever et al. (2013) 提出了動量演演算法的一個變種,Nesterov 動量隨機下降法(NAG ,英文全稱是 Nesterov Accelerated Gradient,或者叫做 Nesterov Momentum 。
Nesterov 動量隨機梯度下降方法是在上述動量梯度下降法更新梯度時加入對當前梯度的校正,簡單解釋就是往標準動量方法中新增了一個校正因子。
NAG 演演算法描述如下:
1,輸入和引數:
- \(\eta\) - 全域性學習率
- \(\alpha\) - 動量引數,預設取值 0.9
- \(v\) - 動量,初始值為0
2,演演算法計算過程:
- 引數臨時更新:\(\hat \theta = \theta_{t-1} - \alpha \cdot v_{t-1}\)
- 網路前向傳播計算:\(f(\hat \theta)\)
- 計算梯度:\(g_t = \nabla_{\hat\theta} J(\hat \theta)\)
- 計算速度更新:\(v_t = \alpha \cdot v_{t-1} + \eta \cdot g_t\)
- 更新引數:\(\theta_t = \theta_{t-1} - v_t\)
1.4,程式碼實踐
Pytorch 框架中把普通 SGD、Momentum 演演算法和 Nesterov Momentum 演演算法的實現結合在一起了,對應的類是 torch.optim.SGD。注意,其更新公式與其他框架略有不同,其中 \(p\)、\(g\)、\(v\)、\(\mu\) 表示分別是引數、梯度、速度和動量。
# 和原始碼比省略了部分不常用引數
class torch.optim.SGD(params, lr=required, momentum=0, dampening=0,
weight_decay=0, nesterov=False)
1,功能解釋:
可實現 SGD 優化演演算法、帶動量 SGD 優化演演算法、帶 NAG(Nesterov accelerated gradient)動量 SGD 優化演演算法,並且均可擁有 weight_decay 項。
2,引數解釋:
-
params(iterable): 引陣列(引陣列的概念參考優化器基礎類別:Optimizer),即優化器要管理的那部分引數。 -
lr(float): 初始學習率,可按需隨著訓練過程不斷調整學習率。 -
momentum(float): 動量因子,通常設定為 0.9,0.8。 -
weight_decay(float): 權值衰減係數,也就是 L2 正則項的係數。 -
nesterov(bool)- bool 選項,是否使用 NAG(Nesterov accelerated gradient)。
訓練模型時常用設定如下:
torch.optim.SGD(lr=0.02, momentum=0.9, weight_decay=0.0001)
二,自適應學習率演演算法
神經網路研究員早就意識到學習率肯定是難以設定的超引數之一,因為它對深度學習模型的效能有著顯著的影響。
2.1,AdaGrad
在 AdaGrad (Duchi et al., 2011) 提出之前,我們對於所有的引數使用相同的學習率進行更新,它是第一個自適應學習率演演算法,通過所有梯度歷史平方值之和的平方根,從而使得步長單調遞減。它根據自變數在每個維度的梯度值的大小來調整各個維度上的學習率,從而避免統一的學習率難以適應所有維度的問題。
AdaGrad 法根據訓練輪數的不同,對學習率進行了動態調整。具體表現在,對低頻出現的引數進行大的更新(快速下降的學習率),對高頻出現的引數進行小的更新(相對較小的下降學習率)。因此,他很適合於處理稀疏資料。
AdaGrad 演演算法描述如下:
1,輸入和引數
- \(\eta\) - 全域性學習率
- \(\epsilon\) - 用於數值穩定的小常數,建議預設值為
1e-6 - \(r=0\) 初始值
2,演演算法計算過程:
-
計算梯度:\(g_t = \nabla_\theta J(\theta_{t-1})\)
-
累計平方梯度:\(r_t = r_{t-1} + g_t \odot g_t\)
-
計算梯度更新:\(\Delta \theta = {\eta \over \epsilon + \sqrt{r_t}} \odot g_t\)(和動手學深度學習給出的學習率調整公式形式不同)
-
更新引數:\(\theta_t=\theta_{t-1} - \Delta \theta\)
\(\odot\) 按元素相乘,開方、除法和乘法的運算都是按元素運算的。這些按元素運算使得目標函數自變數中每個元素都分別擁有自己的學習率。
AdaGrad 總結:在凸優化背景中,AdaGrad 演演算法具有一些令人滿意的理論性質。但是,經驗上已經發現,對於訓練深度神經網路模型而言,從訓練開始時積累梯度平方會導致有效學習率過早和過量的減小。AdaGrad 在某些深度學習模型上效果不錯,但不是全部。
Pytorch 框架中 AdaGrad 優化器:
class torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial _accumulator_value=0)
2.2,RMSProp
RMSProp(Root Mean Square Prop),均方根反向傳播。
RMSProp 演演算法 (Hinton, 2012) 和 AdaGrad 演演算法的不同在於, RMSProp演演算法使⽤了小批次隨機梯度按元素平⽅的指數加權移動平均來調整學習率。
RMSProp 演演算法描述如下:
1,輸入和引數:
- \(\eta\) - 全域性學習率,建議設定為0.001
- \(\epsilon\) - 用於數值穩定的小常數,建議預設值為1e-8
- \(\alpha\) - 衰減速率,建議預設取值0.9
- \(r\) - 累積變數矩陣,與\(\theta\)尺寸相同,初始化為0
2,演演算法計算過程(計算梯度和更新引數公式和 AdaGrad 演演算法一樣):
-
累計平方梯度:\(r = \alpha \cdot r + (1-\alpha)(g_t \odot g_t)\)
-
計算梯度更新:\(\Delta \theta = {\eta \over \sqrt{r + \epsilon}} \odot g_t\)
RMSProp 總結:經驗上,RMSProp 已被證明是一種有效且實用的深度神經網路優化演演算法。目前,它是深度學習從業者經常採用的優化方法之一。其初始學習率設定為 0.01 時比較理想。
Pytorch 框架中 RMSprop 優化器:
class torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e- 08, weight_decay=0, momentum=0, centered=False)
2.3,AdaDelta
AdaDelta 法也是對 AdaGrad 法的一種改進,它旨在解決深度模型訓練後期,學習率過小問題。相比計算之前所有梯度值的平方和,AdaDelta 法僅計算在一個大小為 \(w\) 的時間區間內梯度值的累積和。
RMSProp 演演算法計算過程如下:
1,引數定義:
-
Adadelta 沒有學習率引數。相反,它使用引數本身的變化率來調整學習率。
-
\(s\) - 累積變數,初始值 0
2,演演算法計算過程:
- 計算梯度:\(g_t = \nabla_\theta J(\theta_{t-1})\)
- 累積平方梯度:\(s_t = \alpha \cdot s_{t-1} + (1-\alpha) \cdot g_t \odot g_t\)
- 計算梯度更新:\(\Delta \theta = \sqrt{r_{t-1} + \epsilon \over s_t + \epsilon} \odot g_t\)
- 更新梯度:\(\theta_t = \theta_{t-1} - \Delta \theta\)
- 更新變化量:\(r = \alpha \cdot r_{t-1} + (1-\alpha) \cdot \Delta \theta \odot \Delta \theta\)
Pytorch 框架中 Adadelta 優化器:
class torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e- 06, weight_decay=0)
2.4,Adam
Adam (Adaptive Moment Estimation,Kingma and Ba, 2014) 是另一種學習率自適應的優化演演算法,相當於 RMSProp + Momentum 的效果,即動量項的 RMSprop 演演算法。
Adam 演演算法在 RMSProp 演演算法基礎上對小批次隨機梯度也做了指數加權移動平均。和 AdaGrad 演演算法、RMSProp 演演算法以及 AdaDelta 演演算法一樣,目標函數自變數中每個元素都分別擁有自己的學習率。
Adam 演演算法計算過程如下:
1,引數定義:
- \(t\) - 當前迭代次數
- \(\eta\) - 全域性學習率,建議預設值為0.001
- \(\epsilon\) - 用於數值穩定的小常數,建議預設值為1e-8
- \(\beta_1, \beta_2\) - 矩估計的指數衰減速率,\(\in[0,1)\),建議預設值分別為0.9和0.999
2,演演算法計算過程:
-
計算梯度:\(g_t = \nabla_\theta J(\theta_{t-1})\)
-
計數器加一:\(t=t+1\)
-
更新有偏一階矩估計:\(m_t = \beta_1 \cdot m_{t-1} + (1-\beta_1) \cdot g_t\)
-
更新有偏二階矩估計:\(v_t = \beta_2 \cdot v_{t-1} + (1-\beta_2)(g_t \odot g_t)\)
-
修正一階矩的偏差:\(\hat m_t = m_t / (1-\beta_1^t)\)
-
修正二階矩的偏差:\(\hat v_t = v_t / (1-\beta_2^t)\)
-
計算梯度更新:\(\Delta \theta = \eta \cdot \hat m_t /(\epsilon + \sqrt{\hat v_t})\)
-
更新引數:\(\theta_t=\theta_{t-1} - \Delta \theta\)
從上述公式可以看出 Adam 使用指數加權移動平均值來估算梯度的動量和二次矩,即使用了狀態變數 \(m_t、v_t\)。
怎麼理解 Adam 演演算法?
首先,在 Adam 中,動量直接併入了梯度一階矩(指數加權)的估計。將動量加入 RMSProp 最直觀的方法是將動量應用於縮放後的梯度。結合縮放的動量使用沒有明確的理論動機。其次,Adam 包括偏置修正,修正從原點初始化的一階矩(動量項)和(非中心的)二階矩的估計。RMSProp 也採用了(非中心的)二階矩估計,然而缺失了修正因子。因此,不像 Adam,RMSProp 二階矩估計可能在訓練初期有很高的偏置。 Adam 通常被認為對超引數的選擇相當魯棒,儘管學習率有時需要從建議的預設修改。
初學者看看公式就行,這段話我也是摘抄花書,目前沒有很深入理解。
Adam 演演算法實現步驟如下。

Adam 總結:由於 Adam 繼承了 RMSProp 的傳統,所以學習率同樣不宜設定太高,初始學習率設定為 0.01 時比較理想。
Pytorch 框架中 Adam 優化器:
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e- 08, weight_decay=0, amsgrad=False)
三,總結
3.1,PyTorch 的十個優化器
PyTorch 中所有的優化器基礎類別是 Optimizer 類,在 Optimizer 類中定義了 5 個 實用的基本方法,分別是
zero_grad():將梯度清零。step(closure):執行一步權重引數值更新, 其中可傳入引數 closure(一個閉包)。state_dict():獲取模型當前引數,以一個有序字典形式返回,key 是引數名,value 是引數。load_state_dict(state_dict):將 state_dict 中的引數載入到當前網路,常用於 finetune。add_param_group(param_group):給 optimizer 管理的引陣列中增加一組引數,可為該組引數客製化 lr, momentum, weight_decay 等,在 finetune 中常用。
PyTorch 基於 Optimizer 基礎類別構建了十種優化器,有常見的 SGD、ASGD、Rprop、 RMSprop、Adam 等等。注意 PyTorch 中的優化器和前文描述的優化演演算法略有不同,PyTorch 中 給出的優化器與原始論文中提出的優化方法,多少是有些改動的,詳情可直接閱讀原始碼。
3.2,優化演演算法總結
-
Adam 等自適應學習率演演算法對於稀疏資料具有優勢,且收斂速度很快;但精調引數的 SGD(+Momentum)往往能夠取得更好的最終結果。
-
用相同數量的超引數來調參,儘管有時自適應優化演演算法在訓練集上的 loss 更小,但是他們在測試集上的 loss 卻可能比 SGD 系列方法高。
-
自適應優化演演算法在訓練前期階段在訓練集上收斂的更快,但可能在測試集上的泛化性不好。
-
目前,最流行並且使用很高的優化演演算法包括 SGD、具動量的 SGD、RMSProp、 具動量的 RMSProp、AdaDelta 和 Adam。但選擇哪一個演演算法主要取決於使用者對演演算法的熟悉程度(更方便調節超引數)。
參考資料
- 《智慧之門-神經網路與深度學習入門》-15.2 梯度下降優化演演算法
- 《深度學習》-第八章 深度模型中的優化
- 《動手學深度學習》-優化演演算法
版權宣告 ©
本文作者:嵌入式視覺
本文連結:https://www.cnblogs.com/armcvai/p/17148427.html
版權宣告:本文為「嵌入式視覺」的原創文章,首發於 github ,遵循 CC BY-NC-ND 4.0 版權協定,著作權歸作者所有,轉載請註明出處!
鼓勵博主:如果您覺得文章對您有所幫助,可以點選文章右下角【推薦】一下。您的鼓勵就是博主最大的動力!