拋磚系列之k8s HorizontalPodAutoscaler(HPA)

前言
「大夥得眼裡有活,看見同事忙的時候要互相幫助,這樣我們團隊才能快速成長,出成績,多幹點活沒壞處的,領導都看在眼裡記在心裡,不會虧待大夥。」
看到這也許你還有點懵,不是要講k8s的HorizontalPodAutoscaler?怎麼以一段經典pua開頭,哈哈,彆著急,接著往下看。
「高可用、高並行、大流量」這些曾經似乎只會出現在網際網路業務中的高大上詞彙,現在已然是隨處可見,不管真實業務場景會不會出現,對外宣稱時都會標榜這類特性,要支援這類特性有一個極其基礎的能力是必須具備的,那就是擴容,而擴容一般又分為垂直擴容和水平擴容,最為廣泛的屬水平擴容。
水平擴容俗稱加機器,對比現實工作中就是加人,加人從觸發方式上來說分為主動和被動,主動就是一些熱心腸(眼裡有活)的同事看你太忙了過來幫你,這種概率較小,一般來說大概率是領導覺得你忙不過來了把你的活分一部分出去給其他人,這種就是被動觸發加人。
回到網際網路的世界中,當單機飽和了以後,就需要加機器,我經歷過的公司都是運維人工操作,決策依據為一些可以體現繁忙度的監控指標,如qps、cpu利用率、記憶體佔用等,對於一些爆炸性事件,這種人工操作就有些捉襟見肘,如大家屢見不鮮的明星頭條新聞導致服務宕機的情況,假如能利用機器來自動化的感知壓力進而擴容,就能更好的提高服務質量。
偶爾間發現了k8s的HorizontalPodAutoscaler可以實現自動水平擴容,就花時間簡單實踐了一下,在這裡拋磚一波,希望能給大家帶來些許幫助。
概念介紹
本節摘自k8s官網
在 Kubernetes 中,HorizontalPodAutoscaler 自動更新工作負載資源 (例如 Deployment 或者 StatefulSet), 目的是自動擴縮工作負載以滿足需求。
水平擴縮意味著對增加的負載的響應是部署更多的 Pod。這與 「垂直(Vertical)」 擴縮不同,對於 Kubernetes, 垂直擴縮意味著將更多資源(例如:記憶體或 CPU)分配給已經為工作負載執行的 Pod。
如果負載減少,並且 Pod 的數量高於設定的最小值, HorizontalPodAutoscaler 會指示工作負載資源(Deployment、StatefulSet 或其他類似資源)縮減。
水平 Pod 自動擴縮不適用於無法擴縮的物件(例如:DaemonSet。)
HorizontalPodAutoscaler 被實現為 Kubernetes API 資源和控制器。
資源決定了控制器的行為。在 Kubernetes 控制平面內執行的水平 Pod 自動擴縮控制器會定期調整其目標(例如:Deployment)的所需規模,以匹配觀察到的指標, 例如,平均 CPU 利用率、平均記憶體利用率或你指定的任何其他自定義指標。
HorizontalPodAutoscaler 是如何工作的?
本節摘自k8s官網
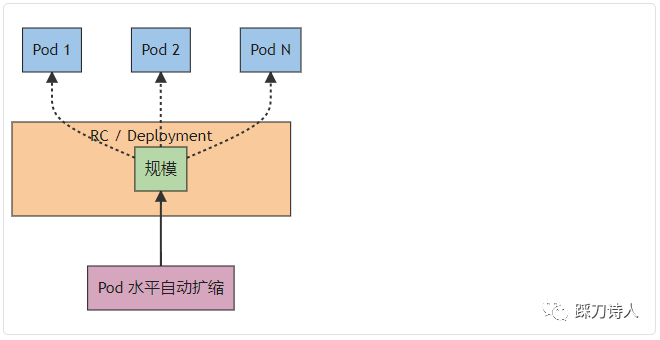
Kubernetes 將水平 Pod 自動擴縮實現為一個間歇執行的控制迴路(它不是一個連續的過程)。間隔由 kube-controller-manager 的 --horizontal-pod-autoscaler-sync-period 引數設定(預設間隔為 15 秒)。
在每個時間段內,控制器管理器都會根據每個 HorizontalPodAutoscaler 定義中指定的指標查詢資源利用率。控制器管理器找到由 scaleTargetRef 定義的目標資源,然後根據目標資源的 .spec.selector 標籤選擇 Pod, 並從資源指標 API(針對每個 Pod 的資源指標)或自定義指標獲取指標 API(適用於所有其他指標)。
-
對於按 Pod 統計的資源指標(如 CPU),控制器從資源指標 API 中獲取每一個 HorizontalPodAutoscaler 指定的 Pod 的度量值,如果設定了目標使用率,控制器獲取每個 Pod 中的容器資源使用情況, 並計算資源使用率。如果設定了 target 值,將直接使用原始資料(不再計算百分比)。接下來,控制器根據平均的資源使用率或原始值計算出擴縮的比例,進而計算出目標副本數。
需要注意的是,如果 Pod 某些容器不支援資源採集,那麼控制器將不會使用該 Pod 的 CPU 使用率。下面的演演算法細節章節將會介紹詳細的演演算法。
-
如果 Pod 使用自定義指示,控制器機制與資源指標類似,區別在於自定義指標只使用原始值,而不是使用率。
-
如果 Pod 使用物件指標和外部指標(每個指標描述一個物件資訊)。這個指標將直接根據目標設定值相比較,並生成一個上面提到的擴縮比例。在 autoscaling/v2 版本 API 中,這個指標也可以根據 Pod 數量平分後再計算。
HorizontalPodAutoscaler 的常見用途是將其設定為從聚合 API (metrics.k8s.io、custom.metrics.k8s.io 或 external.metrics.k8s.io)獲取指標。metrics.k8s.io API 通常由名為 Metrics Server 的外掛提供,需要單獨啟動。有關資源指標的更多資訊, 請參閱 Metrics Server。
對 Metrics API 的支援解釋了這些不同 API 的穩定性保證和支援狀態。
HorizontalPodAutoscaler 控制器存取支援擴縮的相應工作負載資源(例如:Deployment 和 StatefulSet)。這些資源每個都有一個名為 scale 的子資源,該介面允許你動態設定副本的數量並檢查它們的每個當前狀態。有關 Kubernetes API 子資源的一般資訊, 請參閱 Kubernetes API 概念。
演練
準備測試映象
程式碼邏輯很簡單,建立SpringBoot工程stress-test,包含一個Controller,暴露一個介面cpu-test,佔著cpu執行一分鐘。
package com.example.stresstest.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import java.util.concurrent.TimeUnit;
@Controller
public class GreetingController {
@GetMapping("/cpu-test")
public String greeting() {
Long i = System.currentTimeMillis();
while(true){
if (System.currentTimeMillis() - i > TimeUnit.MINUTES.toMillis(1)){
break;
}
}
return "finish";
}
}
將stress-test打包成映象push到映象倉庫(我這裡用的是公司內的,讀者可以自行選擇)。
部署Stress-test
通過resources.limit.cpu: "1"限制最大能佔用的cpu為1核
kubectl create -f stress-test-deployment.ymal
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: stress-test
name: stress-test
namespace: jc-test
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 1
selector:
matchLabels:
app: stress-test
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
annotations:
labels:
app: stress-test
spec:
containers:
image: xxx/stress-test.1.0
imagePullPolicy: IfNotPresent
name: stress-test
resources:
limits:
cpu: "1"
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: docker-registry
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
建立 HorizontalPodAutoscaler
針對stress-test建立了一個HPA,監控的指標為cpu平均利用率,當cpu平均利用率到達80%以後開始自動擴容,最大副本數maxReplicas為3,當cpu平均利用率平緩以後會縮容到minReplicas。
kubectl create -f stress-test-hpa.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-stress-test
namespace: jc-test
spec:
maxReplicas: 3
metrics:
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: stress-test
測試
看下測試之前的副本個數,只有一個
kubectl get deployment stress-test -n jc-test NAME READY UP-TO-DATE AVAILABLE AGE stress-test 1/1 1 1 13d
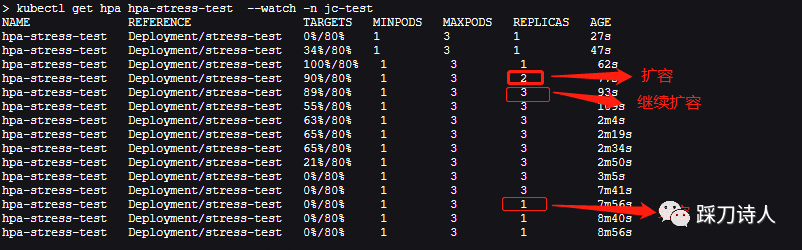
curl http://127.0.0.1:8080/cpu-test 存取測試介面,該介面會佔著cpu執行一分鐘,意味著cpu利用率會達到100%,大約15s以後檢視副本數的變化,已經變成兩個副本,多開幾個視窗存取/cpu-test,最終副本數會到達3 。
kubectl get deployment stress-test -n jc-test NAME READY UP-TO-DATE AVAILABLE AGE stress-test 2/2 2 2 13d
看下HPA的效果
kubectl get hpa hpa-stress-test--watch
一點淺見
看案例確實比較簡單,但是具體要如何落地呢,這裡談談自己的一點看法。
1.容量預估,結合業務預期通過壓測等手段知道當前要部署的資源數量,比如筆者之前團隊業務預期是一天1000萬筆訂單,而訂單會分攤到早中晚的各一個小時完成,所以預估下qps=1000萬/3/3600=926,通過壓測單臺服務能承受是qps是120,所以部署8臺就足夠了,但是為了防止一些突發情況,會多預留20%左右的資源,最終部署10臺;
2.遠取指標,以第一步壓測得出的qps為例,如果服務的qps到達120,說明目前已處於飽和狀態,可以拿平均qps=120來作為是否擴容的標準;
3.設定HPA引數,比如min=5,max=10,qps=120,意味著最小數量是5臺,最大數量是10,也許你會問10臺如果還不夠用呢,這的確是一個好問題,那我再調大點?似乎合情合理,但是有沒有想過你的上游能不能承受,你依賴的基礎資源能不能承受,微服務一般無狀態可以隨意擴容,但資料庫、redis可就沒那麼輕鬆了,所以說max不能只考慮自己,要全域性思考,再者說如果接入層做了限流,max已經被圈定在一個可控的範圍內,設定太大反而是浪費資源,綜合來說max也就是第一步容量預估得出的10,再多了上游不一定能扛得住,如果確實業務增長的比較快,那就得重新做容量預估,投入更多的資源來支援。
單獨的說max似乎有點雞肋,得結合min來說,max是為擴容,min是為縮容,什麼場景下才需要縮容呢?為了節省資源,伺服器白天可以用來跑線上業務,到了晚上使用者都休息了線上業務是不是就空閒了,這時就可以把線上業務少部署幾臺以備不時之需,其餘的資源留給一些離線業務去用,比如T+1的報表、定時任務等,這正是min的使用場景,同樣的min也不能設定太小,因為服務的啟動也需要一點時間,在啟動的這個過程中是不能提供服務的。
HPA的本質就是計算機世界中的pua,眼裡有活-通過HPA自動加機器,節省資源-通過HPA自動減機器。
總結
HPA體現了一種降本增效的思想,這種思想和現實世界高度吻合,「公司不養閒人,大家得眼裡有活,自動補位。」
本文只作為拋磚,囉嗦一點自己的看法,提到的知識實屬皮毛,還請去k8s官網取其精華。
推薦閱讀
https://mp.weixin.qq.com/s/F3JndqsH9VxNSn4mAKoMjQ 美團彈性伸縮系統的技術演進與落地實踐
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/ Pod 水平自動擴縮
https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/ HorizontalPodAutoscaler 演練
