DIVFusion_ Darkness-free infrared and visible image fusion 論文解讀
研究
背景:
當前影象融合方法都是針對正常照明的紅外與可見光影象設計的,無法有效處理夜景下的情況。
而針對夜景下的融合可以分為以下兩個步驟,1 可見光影象增強,2 可見光影象與紅外影象融合。但是現存的弱光增強演演算法與融合算
法存在嚴重不相容,簡單的組合會導致一系列問題。如何建模消除兩種演演算法的不相容性,消除兩項任務之間的差距成為當前夜間紅外與可
見光影象融合的關鍵。
目的:
在網路中耦合增強和融合兩個任務,解決夜景下的影象融合問題,並且消除兩個任務之間的不相容性。
方法:
基於通道注意機制和Retinex理論去處理影象增強(消除夜景的影響)。
設計一種紋理-對比度增強融合的網路。
貢獻:
提出了一種新穎的視覺增強的紅外與可見光影象融合框架,尤其在極端低光條件下。
提出了場景照明解糾纏網路SIDNet(可以剝離影象中的退化的照度資訊)和紋理對比度增強網路TCEFNet(增強融合特徵的紋理資訊和對比度資訊)。
設計一種顏色一致性損失來保證融合影象的視覺質量(減少融合影象中的顏色失真,並注入更多的可見光影象資訊)。
融合結果具有好的明亮場景和高的對比度,沒有顏色失真。並且在高階視覺任務中得到好的結果。
Retinex理論
Retinex理論是一種顏色恆常性的計算理論。 作為人類視覺感知的一種模型,它假定觀察到的影象可以分解為反射率和照度,表示為I=R*L,其中,反射率R和照度L分別表示原始影象的反射率和照度。 反射率描述了物體在任何亮度條件下都可以被認為是一致的固有屬性。 照度取決於物體上的環境光。

由此,對於常見的影象增強策略,主要分為以下2點:
1,直接將反射分量作為增強結果
(先不論說是否能完全分解準確,反射分量往往會損失一部分資訊,影象會變得非常不真實)
2,對亮度資訊進行處理,再與反射分量重新組合
(為目前的主流演演算法,一方面,這樣可以不損失影象的本質屬性,而僅僅處理亮度低的部分)
Sobel運算元:邊緣檢測(通過影象梯度進行邊緣檢測)
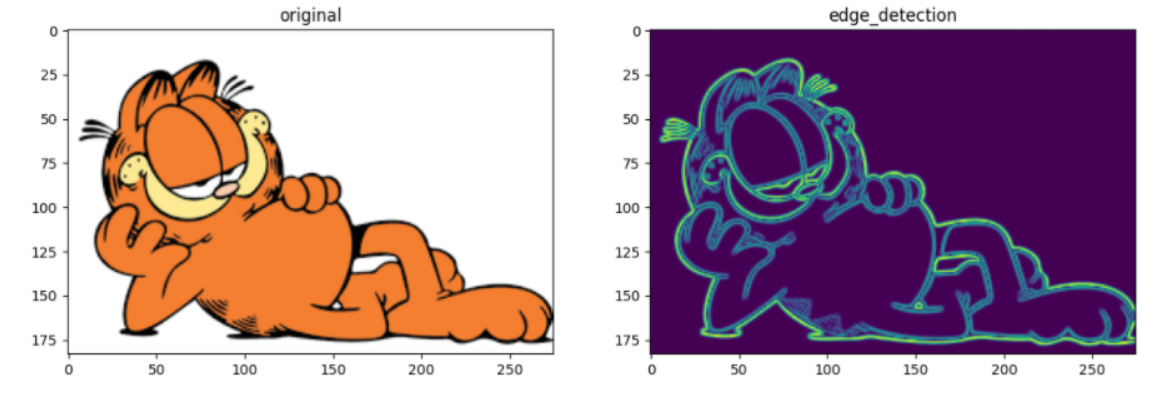
Laplacian運算元:也用於邊緣檢測(使用二階導數)
YCbCr顏色空間:YCbCr分別是指Y(亮度)Cb(藍色色度)Cr(紅色色度),YCbCr與RGB都是影象的顏色空間。
網路結構
本文設計了SIDNet和TCEFNet去最小化上述兩任務的差距。 SIDNet可以在特徵級上從源影象中把照度資訊剝離出來(剩餘的影象本身的性質就是增強後的圖片),保留有用的資訊用於後續。TCEFNet可以將特徵資訊進行整合,並且通過增強紋理和增強對比度兩方面提升照片的視覺感知。整體框架如下圖。
整體流程
1 紅外影象與可見光影象的Y通道在通道上進行拼接作為輸入,經過編碼器得到輸出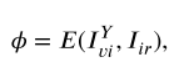 然後混合特徵被送到三個SEBlock塊(基於Retinex和注意力通道機制)得到三個輸出,分別是退化照度特徵、增強可見特徵、紅外特徵
然後混合特徵被送到三個SEBlock塊(基於Retinex和注意力通道機制)得到三個輸出,分別是退化照度特徵、增強可見特徵、紅外特徵 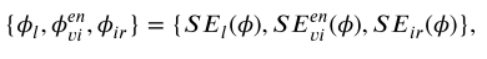 (在訓練階段三個特徵被送到三個解碼器可得到三張圖片
(在訓練階段三個特徵被送到三個解碼器可得到三張圖片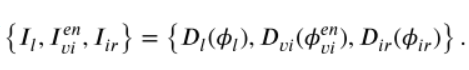 ,紅外特徵和增強可見特徵在通道維度上進行拼接作為SIDNet的輸出,
,紅外特徵和增強可見特徵在通道維度上進行拼接作為SIDNet的輸出,
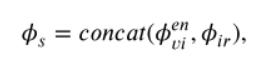 成為TCEFNet中GRM的輸入。
成為TCEFNet中GRM的輸入。
2 TCEFNet有GRM(負責紋理增強)和CEM(負責對比度增強)兩個模組,SIDNet的輸出作為GRM的輸入,GRM包括主流、第一殘差流(下面)、第二殘差流(上面)三方面,主流的輸入和第二殘差流的輸出進行逐元素相加(第一階段紋理增強),相加結果經過一系列的折積後與第一殘差流的輸出在通道維度上進行拼接(第二階段紋理增強) 得到GRM的輸出(紋理增強後的特徵):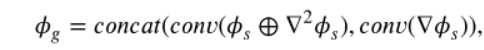
CEM使用不同的折積核對輸入進行折積,將結果進行拼接(不同大小的影象特徵可以直接在通道維度上拼接嗎)得到 然後通過Contrast Block (基於注意力機制的)得到權重向量並相乘得到輸出
然後通過Contrast Block (基於注意力機制的)得到權重向量並相乘得到輸出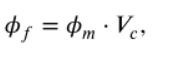 經過解碼器得到輸出:
經過解碼器得到輸出: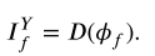 此時的輸出只是Y通道(YCbCr顏色空間中,Y表示亮度資訊)的可見光影象與紅外影象的融合結果(亮度較亮但缺失顏色資訊),將結果與原可見光影象的Cb、Cr在通道維度上進行拼接得到初始融合影象結果(結果會出現顏色失真),然後轉換到RGB顏色空間,
此時的輸出只是Y通道(YCbCr顏色空間中,Y表示亮度資訊)的可見光影象與紅外影象的融合結果(亮度較亮但缺失顏色資訊),將結果與原可見光影象的Cb、Cr在通道維度上進行拼接得到初始融合影象結果(結果會出現顏色失真),然後轉換到RGB顏色空間,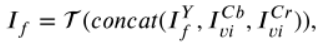
使用提出的顏色一致性損失函數進行調整,糾正顏色失真。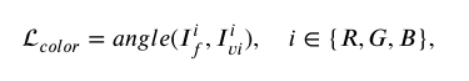
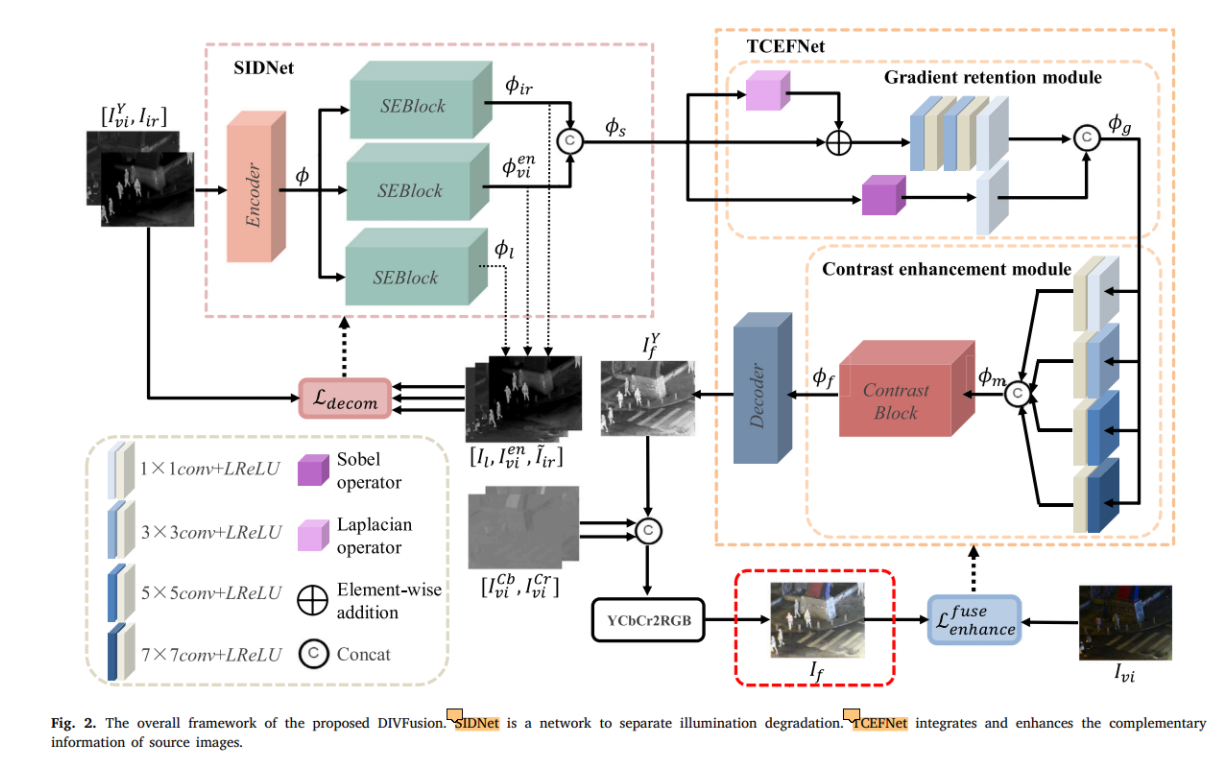
SIDNet
三個SEBlock結合Retinex理論可以從混合特徵中分離出來退化照度特徵、增強後的可見光特徵、紅外特徵。在訓練階段通過解碼器得到三個特徵的重建影象。

TCEFNet
TCEFNet包含兩個模組,GRM(梯度保留,影象紋理)、CEM(對比度增強,影象對比度)。GRM通過一個主流和兩個殘差流實現紋理增強。CEM通過計算得到有關對比度的權重,來實現對比度增強。

損失函數
針對SIDNet提出一種分解損失函數,前兩個是紅外與可見影象重建的損失函數, 他們使融合影象包含更多的互補資訊。 第三個第四個分別是相互一致性損失和光照平滑度損失,指導SIDNet從混合特徵生成退化照明分量。最後一個是感知損失(知覺損失),它約束增強可見特徵的生成。
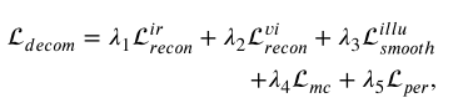
針對TCEFNet提出一種增強-融合損失函數, 第一個是紋理損失,旨在讓融合影象獲得更多的細節資訊從源影象。第二個是強度損失,它約束融合影象保留紅外影象中重要的目標資訊。第三個是顏色一致性損失(最後將融合影象從YCbCr顏色空間轉換到RGB顏色空間去處理顏色失真問題),它消除在增強和融合過程中的顏色失真。
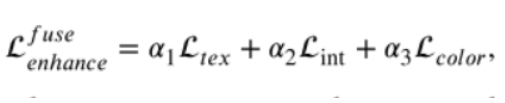
實驗
訓練
實驗資料集來自LLVIP資料集。並且把圖片裁剪成影象塊獲取更多的訓練資料。
訓練分為兩階段,第一階段訓練SIDNet,第二階段訓練TCEFNet。
測試
使用增強後的可見影象和紅外影象輸入到SOTA中與我們的方法進行比較。
泛化
通過測試其它公共資料集來得到模型一般化能力。
消融
對紋理損失,顏色一致性損失,梯度保留模組,對比度增強模組,SIDNet進行消融實驗。
擴充套件
使用本文的DIVFusion應用到高階視覺任務上(行人檢測),通過定性、定量的分析,發現本文的方法產生比較好的促進作用。將紅外影象、可見光影象、(SOTA+包括我們的方法)融合影象分別送到YOLO5影象檢測方法中去進行行人檢測任務,可以發現我們的方法達到了最好的效果,因此說明我們提出的融合模型有利於進行高階計算機視覺任務
結論
本文提出了一種基於視覺增強的夜間紅外與可見光影象融合演演算法,實現了影象融合與影象增強的耦合互利。具體來說,SIDNet 旨在將退化光照特徵與混合特徵分離,避免源影象的重要資訊丟失。然後,我們使用包含兩個特殊模組的 TCEFNet 在融合過程中獲得對比度增強和紋理保留。考慮到增強和融合任務不相容導致的顏色失真,我們設計了一個顏色一致性損失來調整融合影象的顏色分佈。與最先進方法的定性和定量比較驗證了我們方法的優越性,包括視覺感知、場景亮度和互補資訊整合。還進行了兩階段融合實驗,以說明我們的方法有效地幫助減輕了融合和增強任務之間的不相容性。此外,行人檢測實驗證明了我們的 DIVFusion 在高階計算機視覺任務中的潛力。
我們的方法以及其他方法的侷限性在於解決暴露降解的能力較差。我們提供了一個典型的例子來直觀地說明這一點,如圖13所示。儘管所有融合方法都無法消除前燈區域的過度曝光效果,但與其他演演算法相比,我們的方法在其他區域提供了更自然的視覺感知。一種可能的解決方案是通過高斯分佈對點光源進行建模,並設計分解網路以從可見影象中剝離過曝光圖。由於在過度曝光區域的可見影象中缺乏有效資訊,因此我們將在融合過程中整合更多資訊以從紅外影象中修復過度曝光區域。將來,我們將進一步設計一個照度調整模組,以解決紅外和可見光影象融合任務中的弱光和過度曝光退化問題。
