Backbone 網路-ResNet 論文解讀
摘要
殘差網路(ResNet)的提出是為了解決深度神經網路的「退化」(優化)問題。
有論文指出,神經網路越來越深的時候,反傳回來的梯度之間的相關性會越來越差,最後接近白噪聲。即更深的折積網路會產生梯度消失問題導致網路無法有效訓練。
而 ResNet 通過設計殘差塊結構,調整模型結構,讓更深的模型能夠有效訓練更訓練。目前 ResNet 被當作目標檢測、語意分割等視覺演演算法框架的主流 backbone。
一,殘差網路介紹
作者提出認為,假設一個比較淺的折積網路已經可以達到不錯的效果,那麼即使新加了很多折積層什麼也不做,模型的效果也不會變差。但,之所以之前的深度網路出現退化問題,是因為讓網路層什麼都不做恰好是當前神經網路最難解決的問題之一!
因此,作者可以提出殘差網路的初衷,其實是讓模型的內部結構至少有恆等對映的能力(什麼都不做的能力),這樣可以保證疊加更深的折積層不會因為網路更深而產生退化問題!
1.1,殘差結構原理
對於 VGG 式的折積網路中的一個折積 block,假設 block 的輸入為 \(x\) ,期望輸出為 \(H(x)\),block 完成非線性對映功能。
那麼,如何實現恆等對映呢?
假設折積 block 的輸入為 \(x\) ,block 期望輸出為 \(H(x)\),我們一般第一反應是直接讓學習 \(H(x) = x\),但是這很難!
對此,作者換了個角度想問題,既然 \(H(x) = x\) 很難學習到,那我就將 \(H(x)\) 學習成其他的。因此,作者將網路設計為 \(H(x) = F(x) + x\),即直接把恆等對映作為網路的一部分。這就把前面的問題轉換成了學習一個殘差函數 \(F(x) = H(x) - x\)。
只要 \(F(x) = 0\),那不就實現了前面的目的-恆等對映: \(H(x) = x\)。而顯然,擬合殘差 \(F(x)\) 至少比擬合恆等對映容易得多,其通過 \(L2\) 正則就可以輕鬆實現。於是,就有了殘差塊結構(resdiual block)。
綜上,一句話總結殘差結構原理就是,與其學習 block 的輸出等於輸入,不如學習「輸出減去輸入」。
基本殘差塊結構如下圖所示:
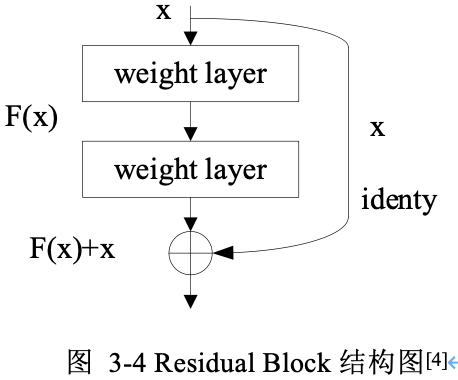
從圖中可以看出,一個殘差塊有 \(2\) 條路徑 \(F(x)\) 和 \(x\),\(F(x)\) 路徑擬合殘差 \(H(x)-x\),可稱為殘差路徑,\(x\) 路徑為恆等對映(identity mapping),稱其為」shortcut」。圖中的 \(⊕\) 為逐元素相加(element-wise addition),要求參與運算的 \(F(x)\) 和 \(x\) 的尺寸必須相同!
1.2,兩種不同的殘差路徑
在 ResNet 原論文中,殘差路徑的設計可以分成 \(2\) 種,
- 一種沒有
bottleneck結構,如圖3-5左所示,稱之為「basic block」,由 2 個 \(3\times 3\) 折積層構成。2 層的殘差學習單元其兩個輸出部分必須具有相同的通道數(因為殘差等於目標輸出減去輸入,即 \(H(x) - x\),所以輸入、輸出通道數目需相等)。 - 另一種有
bottleneck結構,稱之為 「bottleneck block」,對於每個殘差函數 \(F\),使用 \(3\) 層堆疊而不是 2 層,3 層分別是 \(1\times 1\),\(3\times 3\) 和 \(1\times 1\) 折積。其中 \(1\times 1\) 折積層負責先減小然後增加(恢復)維度,使 \(3\times 3\) 折積層的通道數目可以降低下來,降低引數量減少算力瓶頸(這也是起名 bottleneck 的原因 )。50層以上的殘差網路都使用了 bottleneck block 的殘差塊結構,因為其可以減少計算量和降低訓練時間。
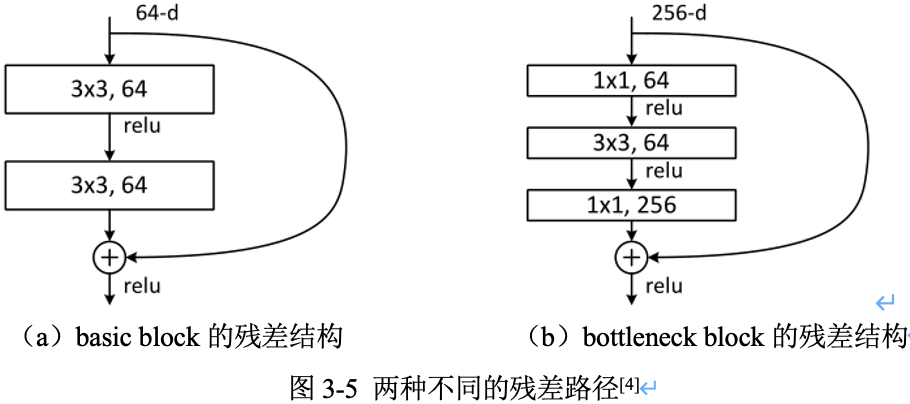
3 層的殘差學習單元是參考了 Inception Net 結構中的
Network in Network方法,在中間 \(3\times 3\) 的折積前後使用 \(1\times 1\) 折積,實現先降低維度再提升維度,從而起到降低模型引數和計算量的作用。
1.3,兩種不同的 shortcut 路徑
shortcut 路徑大致也分成 \(2\) 種,一種是將輸入 \(x\) 直接輸出,另一種則需要經過 \(1\times 1\) 折積來升維或降取樣,其是為了將 shortcut 輸出與 F(x) 路徑的輸出保持形狀一致,但是其對網路效能的提升並不明顯,兩種結構如圖3-6所示。
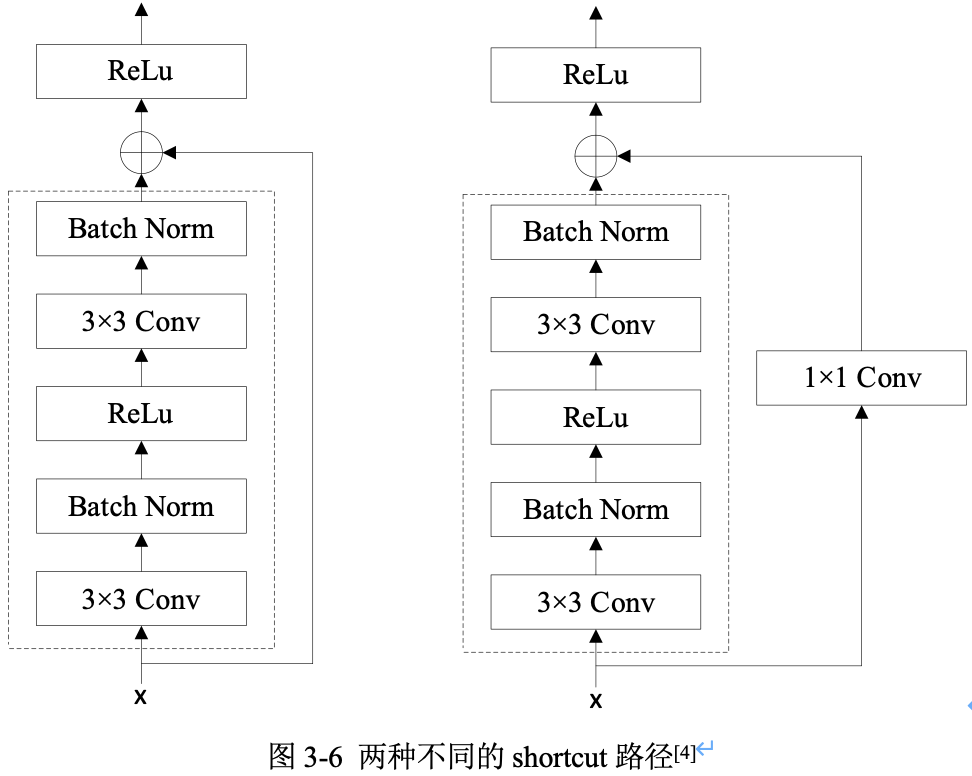
Residual Block(殘差塊)之間的銜接,在原論文中,\(F(x)+x\) 是經過 ReLU 後直接作為下一個 block 的輸入 \(x\)。
二,ResNet18 模型結構分析
殘差網路中,將堆疊的幾層折積 layer 稱為殘差塊(Residual Block),多個相似的殘差塊串聯構成 ResNet。ResNet18 和 ResNet34 Backbone用的都是兩層的殘差學習單元(basic block),更深層的ResNet則使用的是三層的殘差學習單元(bottle block)。
ResNet18 其結構如下圖所示。
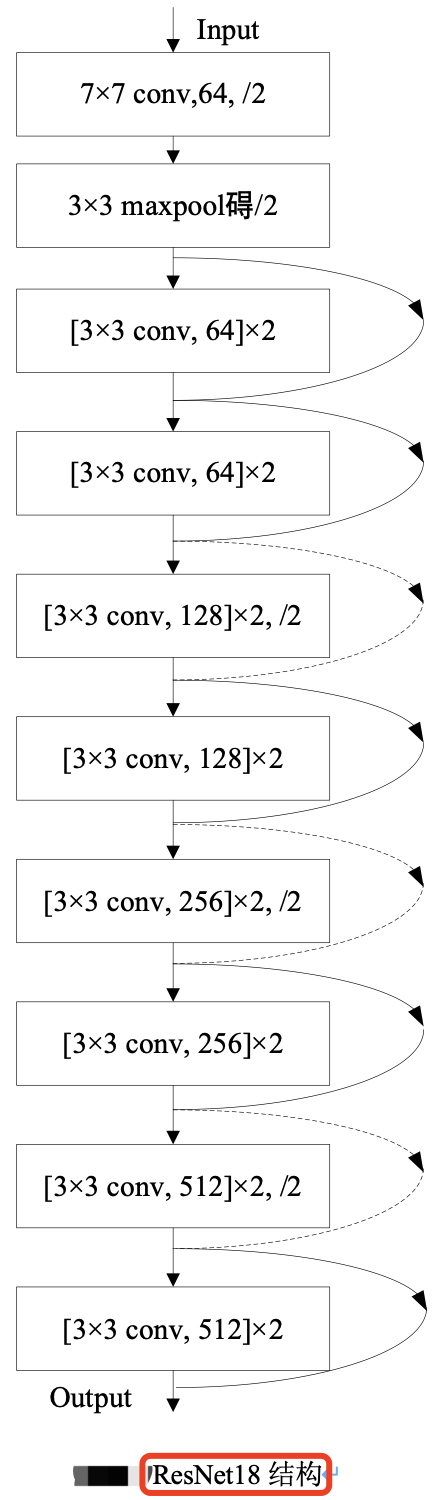
ResNet18 網路具體引數如下表所示。
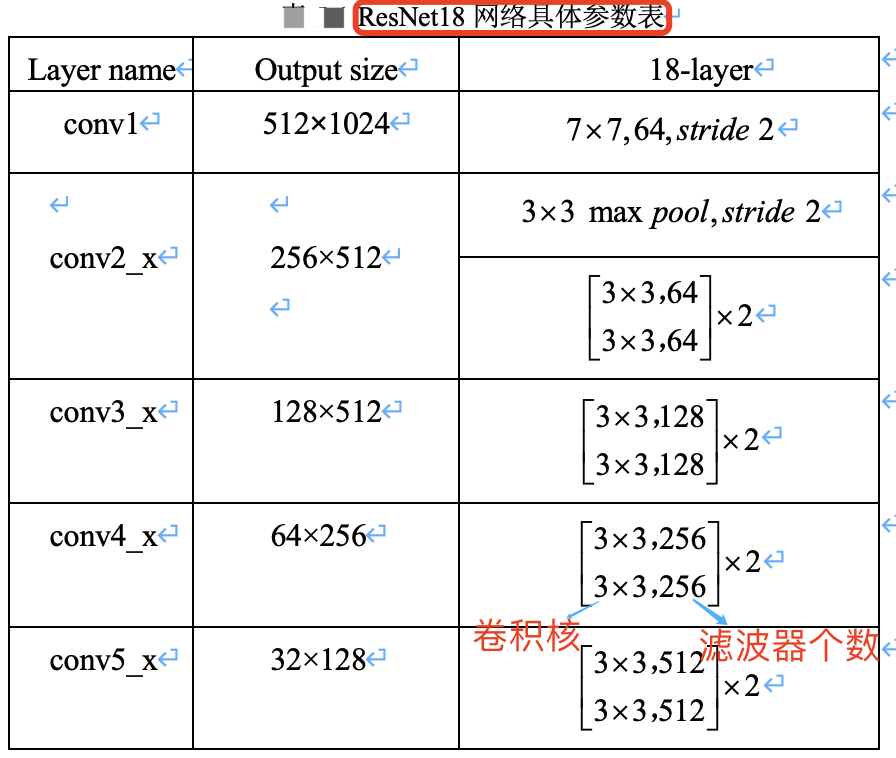
假設影象輸入尺寸為,\(1024\times 2048\),ResNet 共有五個階段。
- 其中第一階段的
conv1 layer為一個 \(7\times 7\) 的折積核,stride為 2,然後經過池化層處理,此時特徵圖的尺寸已成為輸入的1/4,即輸出尺寸為 \(512\times 1024\)。 - 接下來是四個階段,也就是表格中的四個
layer:conv2_x、conv3_x、conv4_x、conv5_x,後面三個都會降低特徵圖尺寸為原來的1/2,特徵圖的下取樣是通過步長為2的 conv3_1, conv4_1 和 conv5_1 執行。所以,最後輸出的 feature_map 尺寸為輸入尺寸降取樣 \(32 = 4\times 2\times 2\times 2\) 倍。
在工程程式碼中用 make_layer 函數產生四個 layer 即對應 ResNet 網路的四個階段。根據不同層數的 ResNet(N):
- 輸入給每個 layer 的
blocks是不同的,即每個階段(layer)裡面的殘差模組數目不同(即layers列表不同) - 採用的
block型別(basic還是bottleneck版)也不同。
本文介紹的 ResNet18,使用 basic block,其殘差模組數量(即units數量)是 [2, 2, 2, 2],又因為每個殘差模組中只包含了 2 層折積,故殘差模組總的折積層數為 (2+2+2+2)*2=16,再加上第一層的折積和最後一層的分類,總共是 18 層,所以命名為 ResNet18。
ResNet50 為 [3, 4, 6, 3]。
個人思考
看了後續的 ResNeXt、ResNetv2、Densenet、CSPNet、VOVNet 等論文,越發覺得 ResNet 真的算是 Backone 領域劃時代的工作了,因為它讓深層神經網路可以訓練,基本解決了深層神經網路訓練過程中的梯度消失問題,並給出了系統性的解決方案(兩種殘差結構),即系統性的讓網路變得更「深」了。而讓網路變得更「寬」的工作,至今也沒有一個公認的最佳方案(Inception、ResNeXt 等後續沒有廣泛應用),難道是因為網路變得「寬」不如「深」更重要,亦或是我們還沒有找到一個更有效的方案。
參考資料
版權宣告 ©
本文作者:嵌入式視覺
本文連結:https://www.cnblogs.com/armcvai/p/17146010.html
版權宣告:本文為「嵌入式視覺」的原創文章,首發於 github ,遵循 CC BY-NC-ND 4.0 版權協定,著作權歸作者所有,轉載請註明出處!
鼓勵博主:如果您覺得文章對您有所幫助,可以點選文章右下角【推薦】一下。您的鼓勵就是博主最大的動力!