(三) MdbCluster分散式記憶體資料庫——節點狀態變化及分片調整
2023-02-22 18:00:33
(三) MdbCluster分散式記憶體資料庫——節點狀態變化及分片調整
昨天我們在測試節點動態擴縮容時,發現了一個小bug。開始時我想當然「頭疼醫頭,腳疼醫腳」地安排開發在問題發生的地方修掉這個bug。早上剛好要一起開會,順便討論起這個bug。我們在白板畫出了系統的架構圖,從bug的發生點,一個環節一個環節的往上追溯原因。意外的發現bug的源頭離bug發生的地方已經過5,6個環節了。如果沒有這個會,開發修bug的時候可能會從最下面開始一個環節一個環節向上修,也許一個星期後才會發現最終的問題。
這裡想分享的兩點:
1. 當一個系統變得龐大,已超過一個人維護能力,並且有一組人不斷在為這個系統貢獻新程式碼時。一旦發現程式執行不如預期,一定有很多的方式來修復這個bug。但能找到bug的根源,在離bug最近的地方,用最少的程式碼進行修復,體現了一個程式設計師對這個系統的駕馭能力。這樣做最大也最直接的好處是可以減少修復舊bug時引入新bug,並避免大規模的迴歸測試。
2. 偵錯程式不一定要通過debug工具或者加偵錯紀錄檔的辦法。如果有幸這個系統是自己寫的,通過bug的現象,回憶自己寫過的程式碼或設計方案,可以更快的分析定位出問題的根本原因。我自己經常用這個辦法,並且屢試不爽。之前總流傳一個好的程式設計師和一個差的程式設計師效率可以差10倍,現實中我也經常看到這種情況,應該這也是其中的原因之一吧。
我想這就是《人月神話》裡面說的: 「程式設計師,就像詩人一樣,幾乎僅僅工作在單純的思考中。程式設計師憑空地運用自己的想象,來建造自己的城堡。」
我們接著討論上節列出的問題:
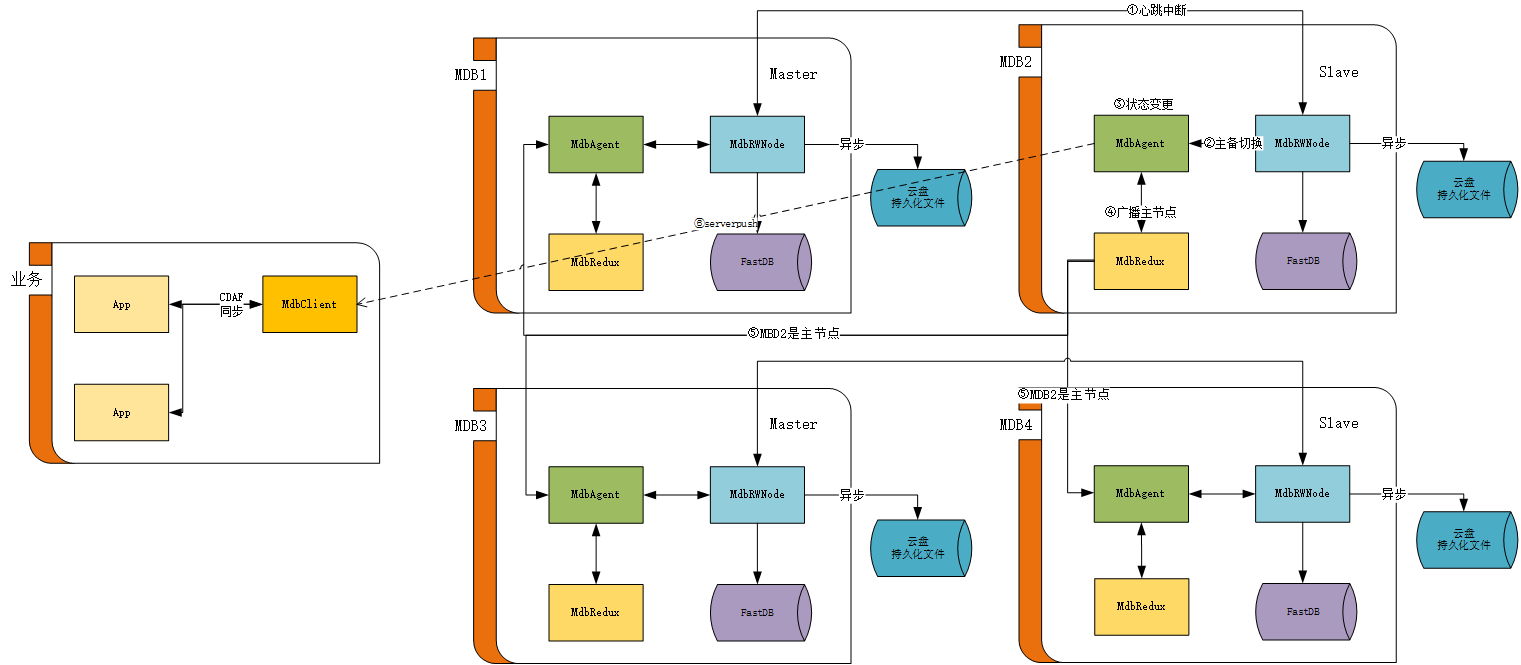
三、當某個節點狀態和數量發生變化時,其它節點如何感知?
考慮到節點主備切換、擴縮容時,節點的狀態,分割區(slot)資料的狀態變化很多。我們增加了一個MdbRedux程序,專門用於通知各種狀態的變化,以及節點的狀態查詢。節點內的MdbRedux與叢集的每個MdbAgent都有通訊鏈路,可以保證狀態變更通知的廣播。可能有人會問,節點間鏈路是怎麼發現和建立的?我們的系統是基於部落格前面文章提到的《c++分散式應用框架》開發的。鏈路是可以自動發現和建立的。
舉個主備切換的例子。當MDB1節點發生異常時,備節點 MDB2的MdbRWNode感知到異常,通知MdbAgent,MdbAgent更新自己的狀態,並通知MdbRedux對其它節點的MdbAgent進行狀態更新廣播。從而達到每個節點的狀態一致。最後,MdbAgent會通過serverpush,將狀態變更推播給MdbClient。
四、擴容和縮容時,分片是如何調整的?
擴縮容的時候分為兩步,一是根據擴縮容的情況生成執行計劃。二是根據生成的執行計劃,遷移資料。
這邊舉一個最簡單的由2個節點擴容為3個節點的場景。生成執行計劃的演演算法的目的也很簡單:通過儘量少的遷移來使每個節點承擔的資料儘量平均。例子裡面的演演算法從Node1遷移[5461, 8190]到Node3,從Node2遷移[13653,16383]到Node3。從而使3個節點的slot數大概為5461。這個演演算法避免了從Node1到Node2的資料遷移。
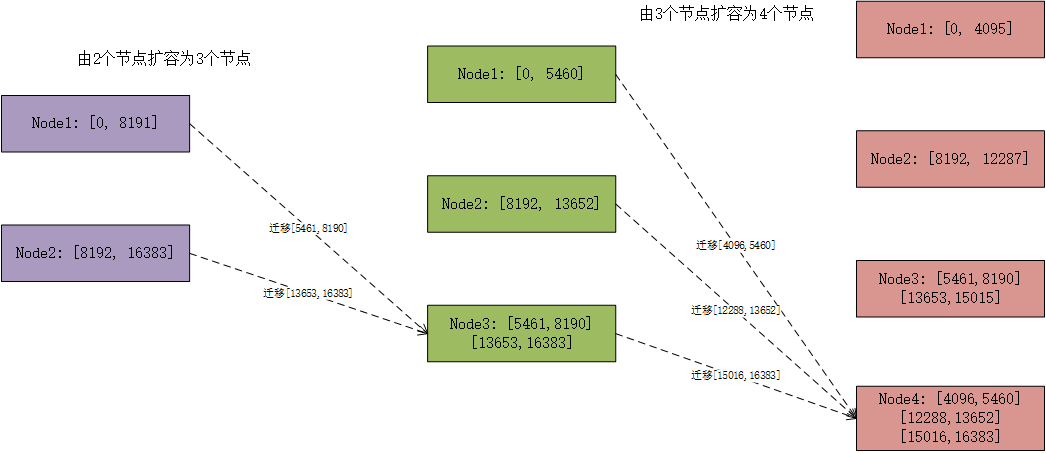
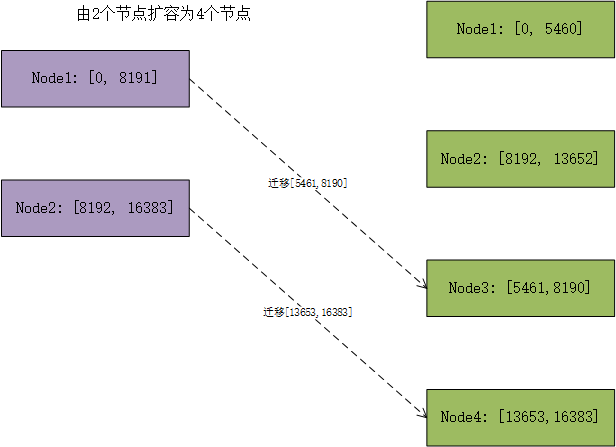
同理由2個點節擴容為4個節點時,僅發生Node1到Node3和Node2到Node4的遷移。此時還附帶了另一個好處,這樣的遷移是可以並行執行的。
可見,隨著擴縮容的次數和節點個數不同,每個分片裡面的slot會被切得不連續,片段會很多。當然這在系統裡面是沒有問題的。因為每個slot都是單獨管理的。但演演算法為了維護時候簡單一些,每次做擴縮容生成執行計劃的時候,都會盡量去考慮合併相臨的slot,如果某個slot單獨落在某個節點,也會進行調整。以最大程度保證分片資料的清晰簡潔。
關於資料遷移的部分,我們後面單獨列章節來講。