風險洞察之事件匯流排的探索與演進
作者:京東科技 劉紅申
一、事件匯流排介紹
事件匯流排,或稱其為資料管道,作為整個風險洞察資料流轉的重要一環,它承擔著風險實時資料統一標準化的重要職責。
在面對複雜多樣的上游資料,事件匯流排可以將複雜資料進行解析、轉換, 富化、分發等操作。底層核心運算元抽象為source、transform、sink三層架構, 支援各層運算元外掛式擴充套件, 並支援groovy、python等指令碼語言自定義設定,以及自定義jar包的上傳,擁有將上游資料單向接入多向輸出的能力,在數倉與上層應用的開展中,起著承上啟下的作用。
二、事件匯流排-遇到的技術挑戰與解決方案
技術難點與挑戰
風險洞察平臺執行初期,業務資料接入完全採用客製化化程式碼處理,通過程式碼設定消費MQ訊息,然後根據業務需求,完成其所需欄位的解析,最終資料落入Clickhouse。這種業務接入方式在早期是可以滿足業務所需,但是隨著風險洞察平臺在風控領域的不斷推進,業務的發展與資料不斷膨脹,面對風控資料的複雜多樣性、訊息平臺的差異性,資料接入客製化化成本也越來越高,同時資料轉化與計算邏輯的強耦合,大促時期吞吐量已然達到瓶頸,呈現出越來越多的痛點:
1. 資料結構差異性: 隨著風險洞察平臺使用業務方的的不斷增加,業務資料訊息體的複雜性也不盡相同,如複雜場景以天盾反欺詐場景為例,訊息體結構包含物件、物件字串而且還有陣列;簡單場景以內容安全為例,訊息體結構就是簡單平鋪的一層;面對風控資料的複雜多樣性,客製化資料的統一標準化已然迫在眉睫;
2. 程式碼邏輯重複性: 對訊息體的處理絕大多數逃離不了序列化與反序列化操作,然而隨著業務量的增多以及開發人員的不盡相同,業務程式碼是每日劇增且帶有參差性的,邏輯重複,維護成本高;
3. 解析寫入低效性: 同一個MQ訊息可能會對應很多的業務方,不同的業務方所需業務資料又千差萬別,如以天策MQ為例,實時資料中包含著金白條資料,金條與白條資料又區分著各自的業務線,如果單次訂閱MQ訊息,會導致邏輯處理極其複雜,不可維護;然而採用多次訂閱,又無法複用已有邏輯,且導致資料成倍增長,造成資源浪費,同時吞吐能力成為瓶頸;
4. 輸入輸出多樣性: 隨著風險洞察平臺被使用的越來越廣,來自於上游資料的生產方式也出現了多樣性,如JMQ2、FMQ、Kafka以及JMQ4等等,同時又為了給使用者更好的平臺使用體驗,不同業務資料又會被落入不同儲存中,如Clickhouse、R2m、Jes以及訊息佇列,如何快速支援這些元件成為了挑戰;
5. 業務需求易變性: 上游業務頻繁的策略調整與變更,對應到事件匯流排就意味著解析欄位以及底層表欄位頻繁的增刪改,正如欄位解析完全依賴於寫死且不同業務資料耦合著各自的業務邏輯,導致開發人員維護成本極高,開發週期長、上線影響廣;
技術解決方案
研發一套資料流轉服務,用其貫穿資料接入到數倉儲存的整個流程,再結合風險洞察平臺特性,以資料來源元件為基礎,作為資料流轉的入口與出口,具體方案如下:
• 資料統一標準化能力:統一標準化入口與出口。上游資料接入時,無論訊息體結構如何,經過事件匯流排處理後,都輸出為平鋪單層key-value結構;
• 程式碼邏輯規範化能力:針對風控策略本身易變的特性,採用靈活度更高的訊息體解析元件Jsonpath,任何訊息體處理第一步就是生成訊息體上下文物件,後續欄位的提取,都從這個上下文中獲取;
• 高吞吐解析寫入能力:一次解析,多路複用。MQ主題實現單次接入,根據不同的業務需求通過過濾下沉不同的業務表,如以天策金白條為例,提取金白條各自的INTERFACE_NAME作為條件,下沉到不同的業務表中;又如以高TPS行銷反欺詐場景為例,在下沉表的同時,下沉訊息佇列給Flink計算使用;減少重複解析,同時抽象各種運算元,針對不同的數倉寫入可做對應的頻次、批次、大小設定,提升吞吐量;
• 輸入輸出外掛化能力:輸入輸出外掛化,新的業務需求來時,可以快速擴充套件相應元件,以應對新需求;
• 低程式碼化熱載入能力:針對業務需求的頻繁變更,解決寫死問題,減少上線頻次,那就需要開發一套可設定化系統,支援指令碼開發與熱載入,同時內建函數外掛化,快速擴充套件共性函數;
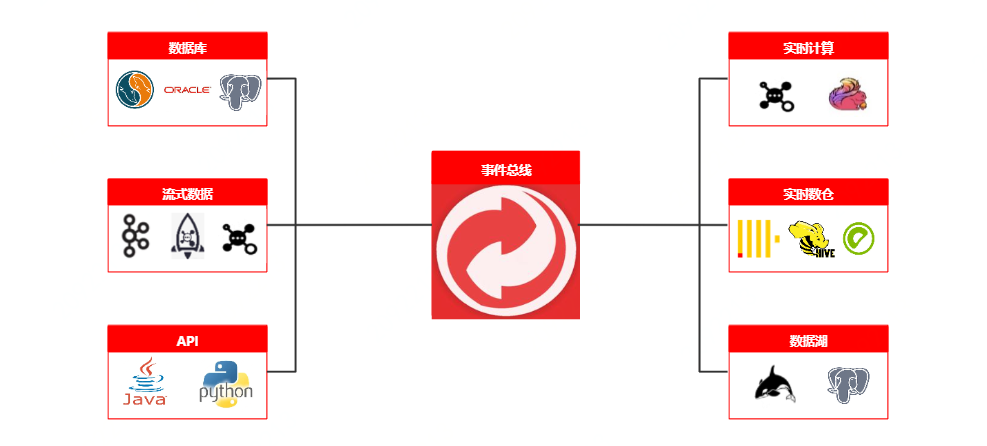
三、事件匯流排-整體架構圖

事件匯流排-架構介紹
事件匯流排整體架構抽象為三層,source、transform 和sink。 通過聯結器擴充套件機制實現資料引擎擴充套件, 並採用責任鏈模式處理資料鏈路, 外掛化管理函數、指令碼,實現實時訊息接入、過濾、富化、轉換、分發標準化處理, 並通過分組消費、降級機制保證架構高可用。
• 實時資料: 風險核心場景,目前事件匯流排業務資料的主要來源;
• 事件匯流排:
◦ Source:資料輸入層,風險業務資料的主要來源方式,目前大多數來源於JMQ2、JMQ4、FMQ等;
◦ Transform: 事件匯流排的核心處理層,同時也是自定義函數與自定義指令碼的解析層,該層抽象了大量的運算元,如,資料解析運算元、過濾運算元、富化運算元、轉換運算元等等當複雜訊息體資料經過一系列運算元之後,最終會轉化為單層key-value標準結構;
◦ Sink: 資料輸出層,經Transform元件轉換後,此時的資料可以發實時訊息給各個訊息佇列,也可以儲存到Clickhouse、Es、R2m等資料庫;
• 資料服務: 基於事件匯流排標準化後沉澱的資料所支撐的平臺應用;
事件匯流排-核心類圖介紹
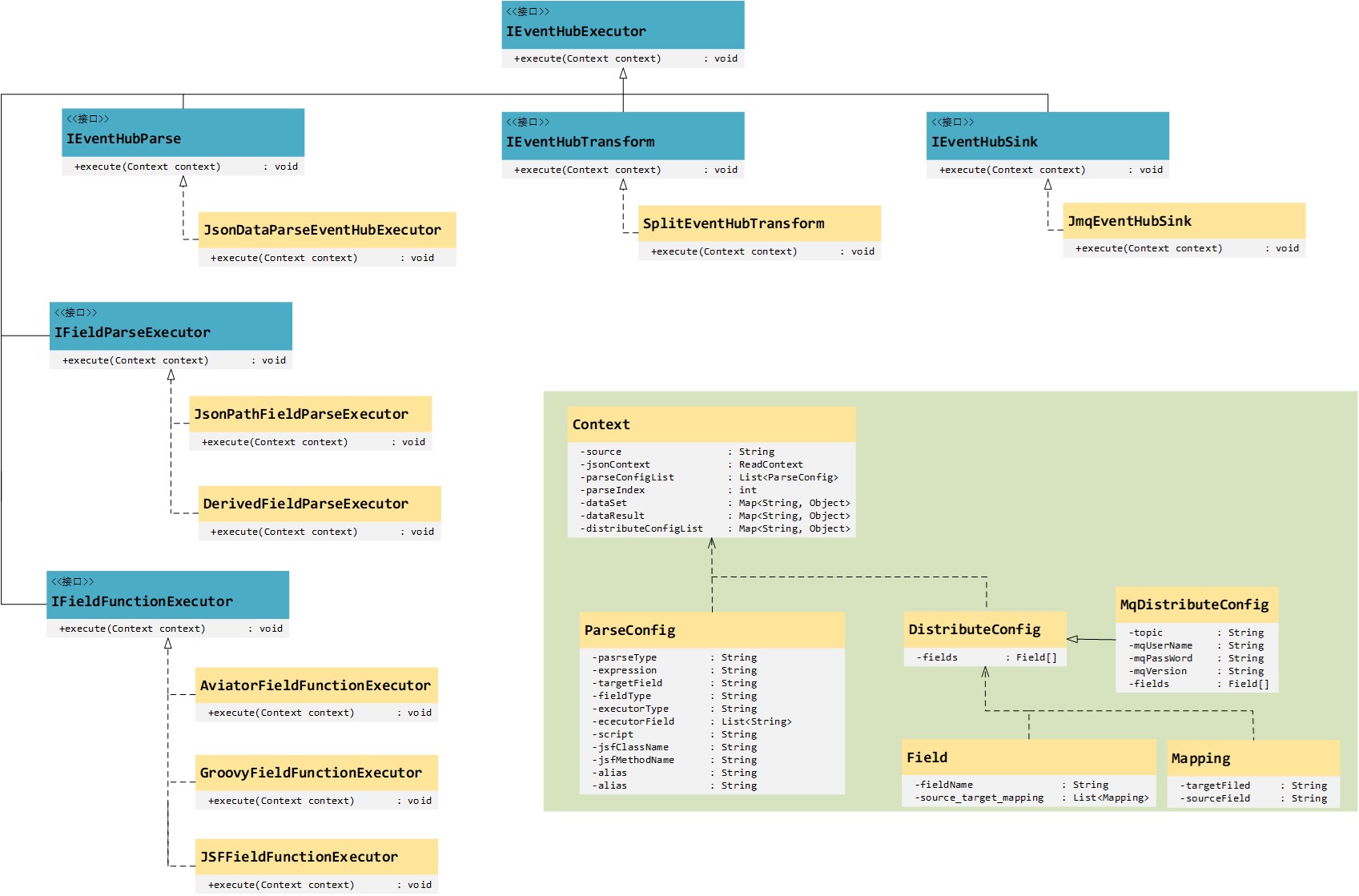
事件匯流排定義了一個頂層父介面IEventHubExecutor,並定義了一個execute方法,其三個主要子介面,IEventHubParse、IEventHubTransform與IEventHubSink分別對應於事件匯流排的三個組成部分,source、transform和sink。通過實現這三個子介面,便可以完成對不同中介軟體的適配問題。比如,目前事件匯流排僅支援解析的資料寫入到Clickhouse,但業務需求需要做檢索,那麼很顯然資料儲存在Es要優於儲存在Clickhouse,所以此時需要擴充套件一個JesEventHubSink來實現IEventHubSink即可。
其中Context作為上下文,貫穿了整個事件匯流排的執行過程,上下文中包含了解析過程中所需要的一起資訊,比如,從哪裡來的資料、要解析哪些欄位、解析好的資料送到那裡去等等。
事件匯流排-自定義函數介紹
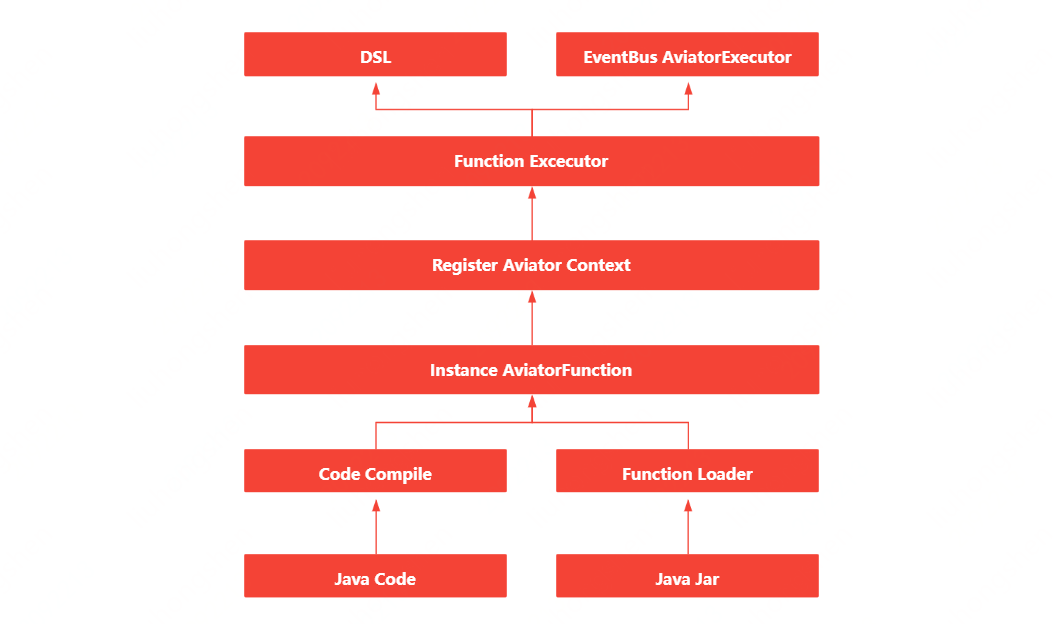
自定義函數的實現,其實藉助了開源框架Avaitor表示式,Aviator是一個輕量級、高效能的Java表示式執行引擎, 它動態地將表示式編譯成位元組碼並執行,主要用於各種表示式的動態求值。相比Groovy這樣的重量級指令碼語言,Aviator是非常輕量級的表示式執行引擎。
• 函數解析器:自定義函數支援指令碼編寫(指令碼採用groovy,同時為了更加「親民」,採用Java語法)與Jar包上傳兩種方式;
• 函數編譯器:編譯指令碼與解析jar包,生成對應的AvaitorFunction範例;
• 函數註冊器:將生成的AvaitorFunction範例註冊到Avaitor的上下文中;
• 函數執行器:通過實現FunctionExecutor,便可以對函數方便的呼叫;
事件匯流排-動態分組、一鍵降級與流量監控介紹
分組消費
事件匯流排解析能力的提升,也很大一部分歸結於分組消費的設計,對流量做到靈活分流,對機器做到物盡其用。動態分組,又分為物理分組與邏輯分組,如下圖:
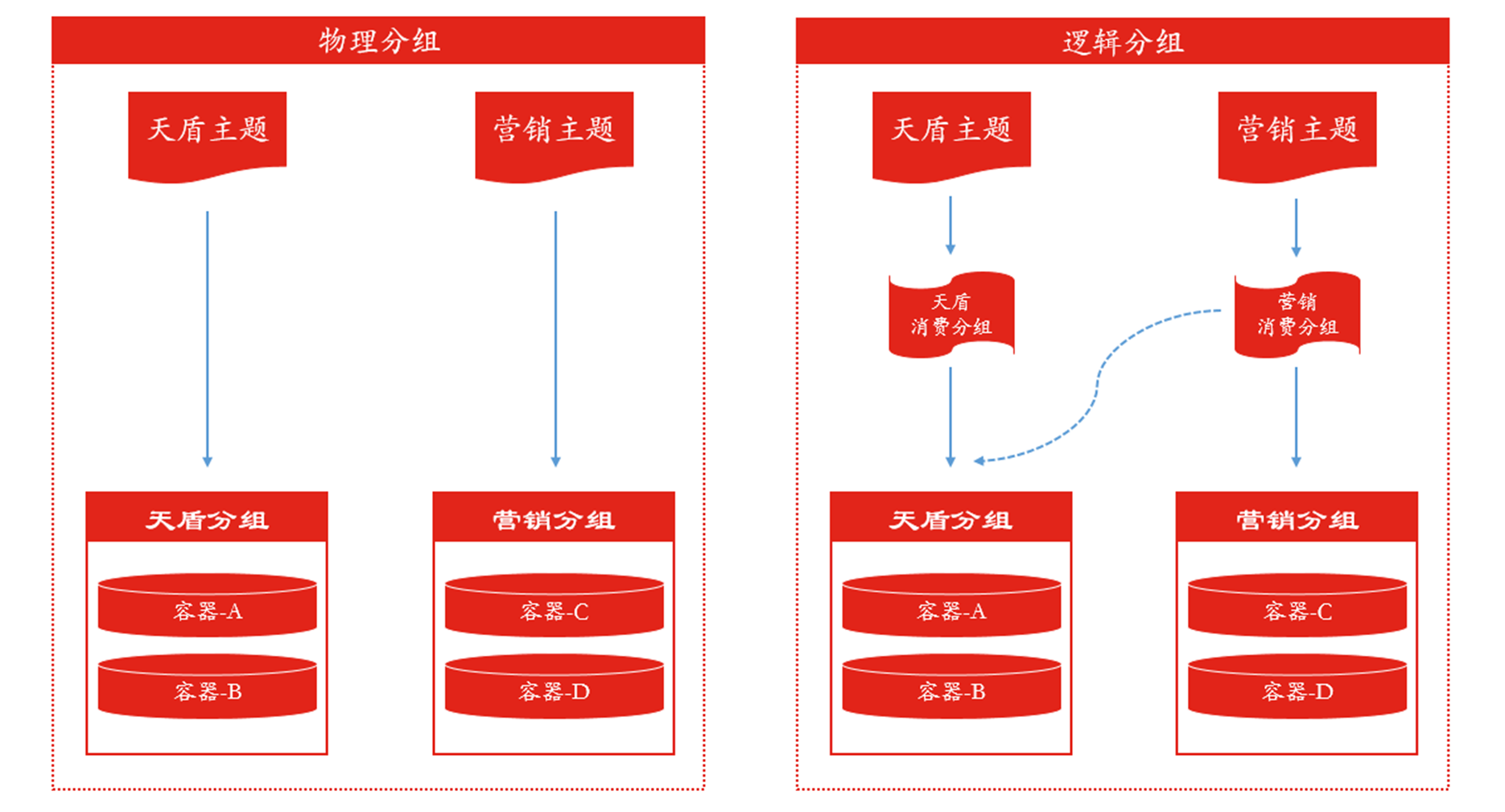
• 物理分組:單純依靠機器劃分,規定好哪些機器消費哪些主題,如,天盾分組就消費天盾主題,行銷分組就消費行銷主題。
• 邏輯分組:邏輯分組與物理分組的區別在於,邏輯分組在物理分組之上,又抽象出一個消費組的概念,用機器與消費組繫結,而非直接與主題繫結,這樣帶來的好處就是,可以更加方便的調配流量,如,行銷流量非常大,那麼可以直接動態調配,使天盾分組也去消費行銷主題,既能充分利用天盾分組機器,又能提高行銷主題消費能力。
一鍵降級
一鍵降級更多的用於大促期間,但是為了降的更加「人性化」,一鍵降級我們也做了分類:丟棄降級與積壓降級,如下圖:
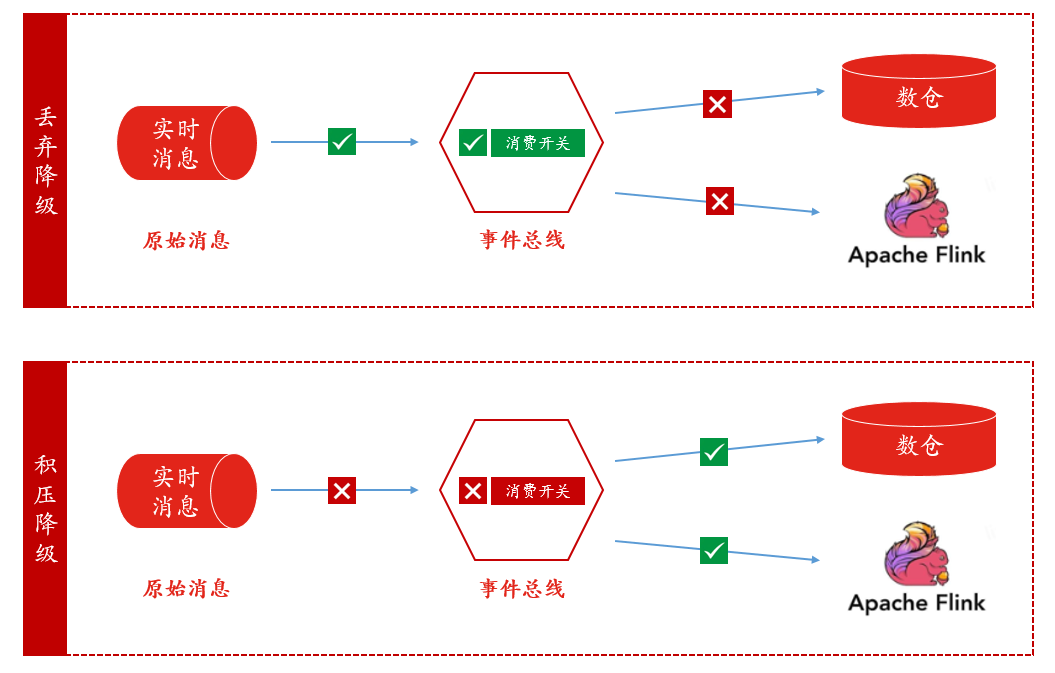
• 丟棄降級:所降級主題處於消費狀態,顧名思義,事件匯流排拿到了資料,就直接將資料丟棄,降級期間資料是不可找回的;丟棄降級可用於業務方並不在意一時資料的丟失或者壓測場景。
• 積壓降級:所降級主題處於非消費狀態,降級期間資料積壓在訊息平臺,降級過後,再開啟消費;積壓降級可用於業務方允許降級期間內沒有新資料,但是降級過後資料又可查場景。
流量監控
事件匯流排的流量監控現依賴於ump,對單個主題以及所有主題的入口都設有埋點,資料在每個關鍵流轉位置解析效能以及流量都能被監控,程式碼片段如下:
Profiler.registerInfo(this.getClass().getSimpleName(), UmpUtil.UMP_APP_NAME, false, true);
四、未來展望
自事件匯流排上線以來,已經經歷了多次大促考驗,大促解析量已達5000w/min,日常解析量也已2000w/min,伴隨著風險洞察平臺被越來越多的部門所使用,事件匯流排已然成為其重要組成部分,為了更好的提高解析效能,就需要去做更多的探索。同時,目前事件匯流排做的更多的是對實時資料的處理,未來我們也將推進flink-cdc等技術在事件匯流排中的應用。