ChatGPT調研分析與應用場域結合構想
作者:京東科技 胡駿
摘要
1. ChatGPT調研分析
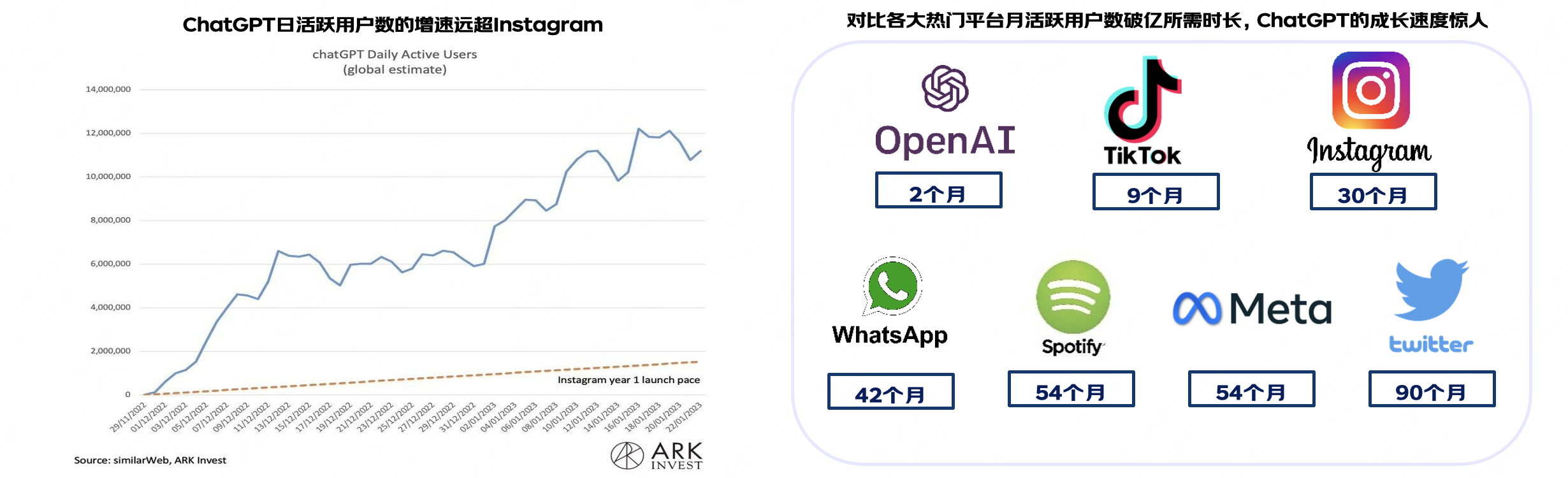
2022年11月30日,ChatGPT橫空出世,在全球範圍內形成了熱烈的討論。根據Similarweb的資料,今年1月,平均每天約有1300萬獨立訪客使用 ChatGPT,是去年12月份的兩倍多,累計使用者超1億,創下了網際網路最快破億應用的紀錄,超過了之前TikTok 9個月破億的速度。
2. ChatGPT共建效能提升
ChatGPT是一個文字對話的AI工具,功能非常強大,可以與它交流,它會提供反饋;可以產生作圖的程式並進行圖片差異比對;可以寫程式碼,甚至修改錯誤的程式碼,它會成為人們辦公的有力助手,提升工作效能。
3. ChatGPT賦能業務增長
隨著ChatGPT Plus釋出,商業化序幕已經拉開。ChatGPT在智慧化、數位化、元宇宙以及數實共生助力產業升級等方面將產生極大助益,提升生產力曲線,多維度賦能業務創新和業務增長。
一、ChatGPT調研分析
1.1 市場概況
2022年11月30日,ChatGPT橫空出世,在全球範圍內形成了熱烈的討論。根據Similarweb的資料,今年1月,平均每天約有1300萬獨立訪客使用 ChatGPT,是去年12月份的兩倍多,累計使用者超1億,創下了網際網路最快破億應用的紀錄,超過了之前TikTok 9個月破億的速度。
ChatGPT是由OpenAI團隊研發創造,OpenAI是由創業家埃隆·馬斯克、美國創業孵化器Y Combinator總裁阿爾特曼、全球線上支付平臺PayPal聯合創始人彼得·蒂爾等人於2015年在舊金山創立的一家非盈利的AI研究公司,擁有多位矽谷重量級人物的資金支援,啟動資金高達10億美金;OpenAI的創立目標是與其它機構合作進行AI的相關研究,並開放研究成果以促進AI技術的發展。
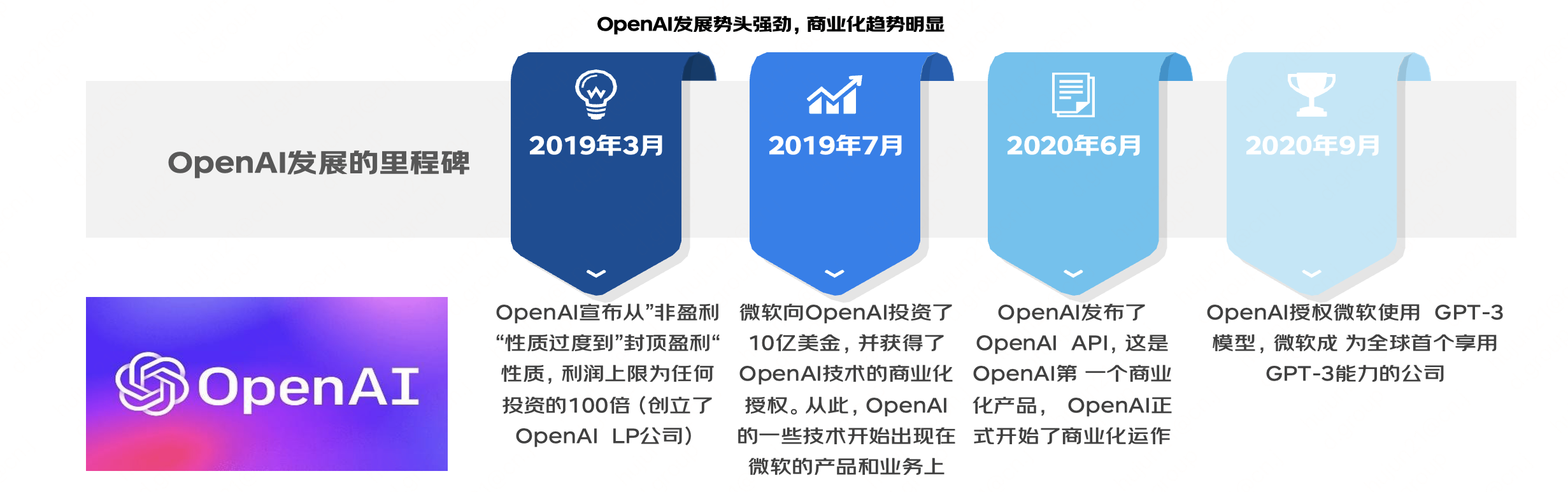
2023年初,微軟和谷歌均宣佈裁員計劃,但都加大了在AI行業的投入。

國內外科技巨頭都非常重視ChatGPT引發的科技浪潮,積極佈局生成式AI。
(圖源:Tech星球)
1.2 發展路徑
1.2.1 基本概況

1.2.2 ChatGPT的前世
ChatGPT的前世是GPT-3(Generative Pretrained Transformer-3),GPT-3是一種基於預訓練的自然語言生成模型,是當前最大的語言生成模型。為了更好地處理對話任務,OpenAI在GPT-3的基礎上改進了模型,並命名為ChatGPT,以適應對話應用領域的需求。
在Transformer模型誕生之前,自然語言處理領域的主流模型是迴圈神經網路(RNN,recurrent neural network)。迴圈神經網路模型的優點是,能更好地處理有先後順序的資料,比如語言。但也因為如此,這種模型在處理較長序列,例如長文章、書籍時,存在模型不穩定或者模型過早停止有效訓練的問題(這是由於模型訓練時的梯度消失或梯度爆炸現象而導致),以及訓練模型時間過長(因必須順序處理資料,無法同時並行訓練)的問題。
2017年,谷歌大腦團隊(Google Brain)在神經資訊處理系統大會(NeurIPS,該會議為機器學習與人工智慧領域的頂級學術會議)發表了一篇名為「Attention is all you need」(自我注意力是你所需要的全部)的論文。作者在文中首次提出了基於自我注意力機制(self-attention)的變換器(transformer)模型,並首次將其用於理解人類的語言,即自然語言處理。
Transformer模型能夠同時並行進行資料計算和模型訓練,訓練時長更短,並且訓練得出的模型可用語法解釋,也就是模型具有可解釋性。
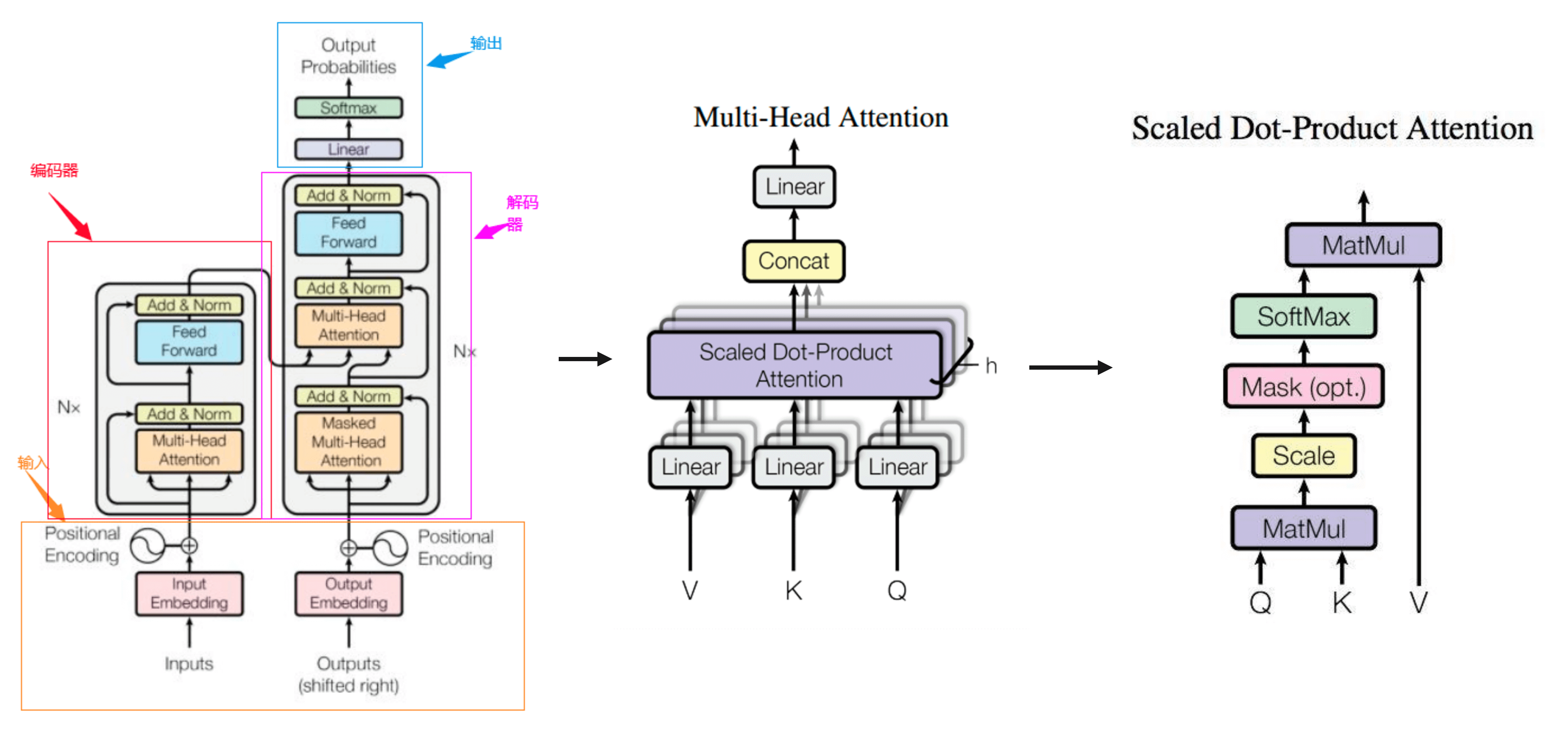
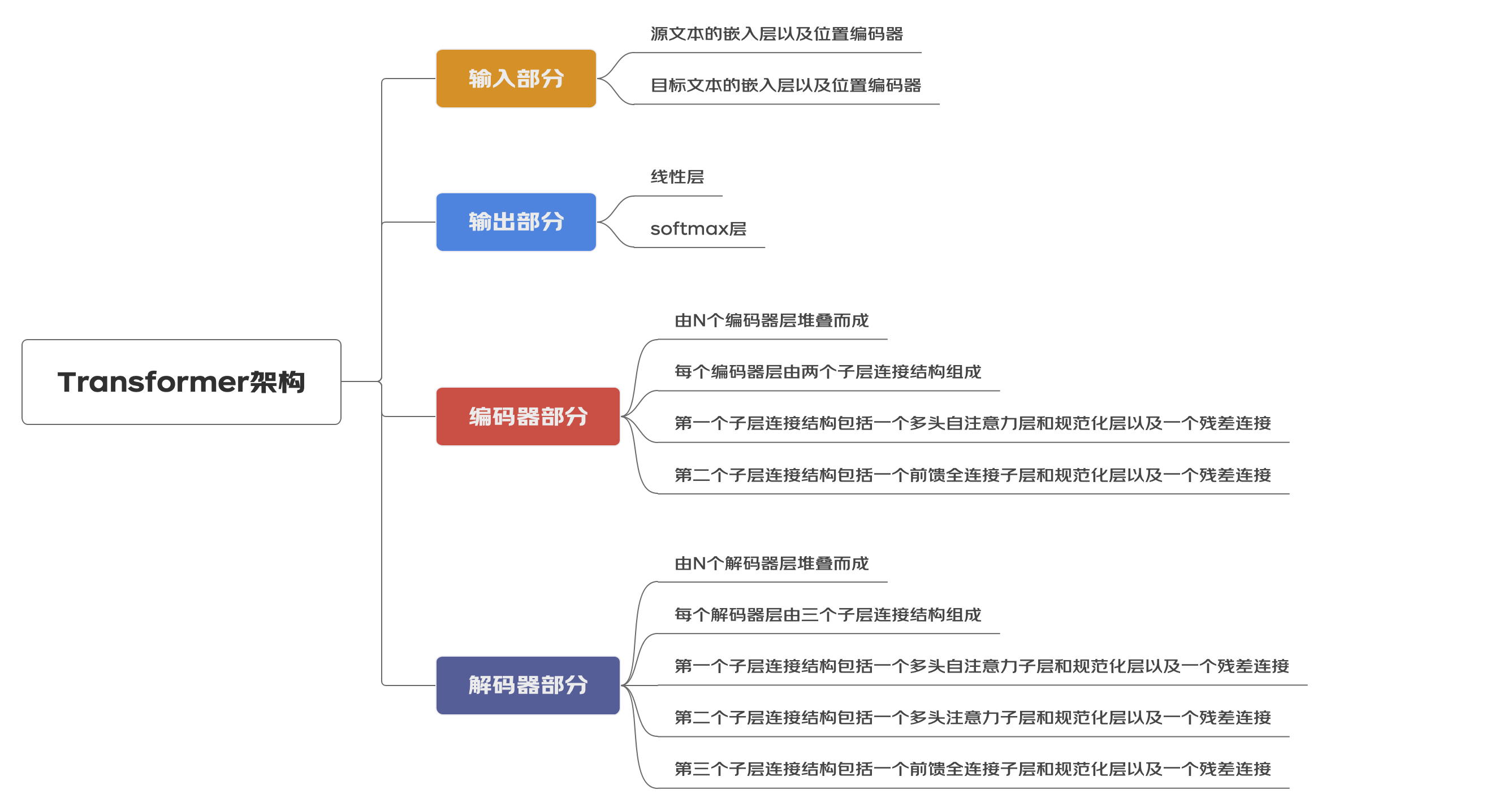
Transformer模型自誕生的那一刻起,就深刻地影響了接下來幾年人工智慧領域的發展軌跡。短短的幾年裡,該模型的影響已經遍佈人工智慧的各個領域——從各種各樣的自然語言模型、到預測蛋白質結構的AlphaFold2模型,用的都是它。
1.2.3 ChatGPT的今生
ChatGPT今生,它已經成為語言生成模型領域的一個重要代表,並在許多領域得到了廣泛的應用,例如聊天機器人、問答系統、文字生成、文學創作等。它也在不斷演進和改進,更好地適應人工智慧領域的需求。
自美國時間12月2日上線以來,ChatGPT已經擁有超過一百萬的使用者。使用者們在社交媒體上曬出來的對話例子表明ChatGPT這款模型與GPT-3類似,能完成包括寫程式碼,修bug(程式碼改錯),翻譯文獻,寫小說,寫商業文案,創作菜譜,做作業,評價作業等一系列常見文字輸出型任務。ChatGPT比GPT-3的更優秀的一點在於,前者在回答時更像是在與你對話,而後者更善於產出長文章,欠缺口語化的表達。有人利用ChatGPT與客服對話,要回了多交了的款項(這或許意味著ChatGPT在某種意義上通過了圖靈測試),或許ChatGPT能成為社恐人士的好夥伴。
1.3 原理分析
由於ChatGPT並沒有放出論文,我們沒法直接瞭解ChatGPT的設計細節。但它的blog中提到一個相似的工作InstructGPT,兩者的區別是ChatGPT在後者的基礎上針對多輪對話的訓練任務做了優化,因此我們可以參考後者的論文去理解ChatGPT。
然而,InstructGPT的論文由25頁正文和43頁附錄組成,所以本章並不試圖去講清包括訓練策略在內的每個細節。為了保證梳理的完整性,參考了Youtube上的李宏毅和陳蘊儂老師,旨在講清InstructGPT的改進思路,同時也參考了B站UP主弗蘭克甜,試圖轉述他對ChatGPT的深刻理解。
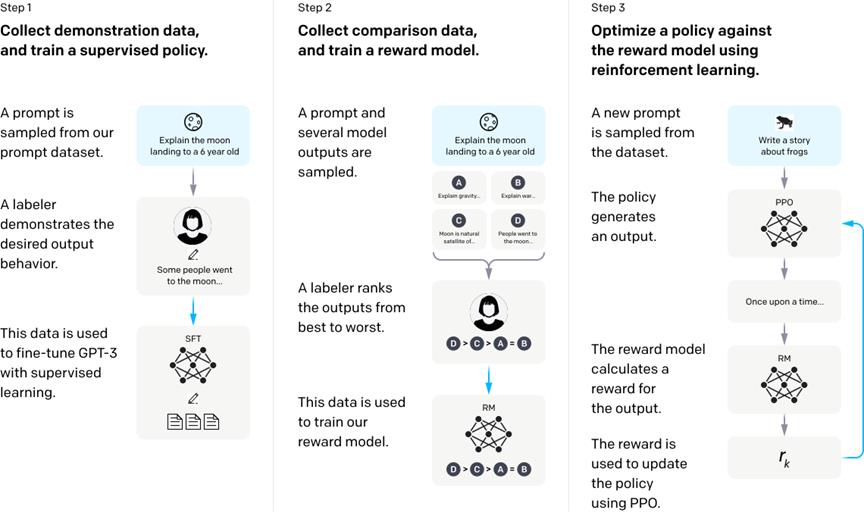
根據上邊的論文圖片,我們可以知道InstructGPT的訓練可以分為三個階段:
-
利用人類的標註資料(demonstration data)去對GPT進行有監督訓練,不妨把微調好的GPT叫做SFT;
-
收集多個不同(如4個)的SFT輸出,這些輸出基於同一個輸入,然後由人類對這些輸出進行排序並用來訓練獎賞模型(RM);
-
由RM提供reward,利用強化學習的手段(PPO)來訓練之前微調過的SFT。
ps:一個需要補充的細節是,RM是會保持更新的,因此階段2與階段3其實是遞交進行的。
如果不瞭解強化學習,關於階段2可能會產生以下的疑問:
-
InstructGPT為什麼要做這樣的改進,或者說它的novelty是什麼?
-
為什麼要訓練一個RM,這個奇奇怪怪的RM為什麼能用來充當獎賞函數?
-
人類對模型的多個輸出做個排序,為什麼就能夠提供監督訊號,或者說在訓練RM時如何怎麼做到loss的梯度回傳?
第一個問題其實在ChatGPT的blog中也有回答。這兩個模型的改進思路,都是儘可能地對齊(Alignment)GPT的輸出與對使用者友好的語言邏輯,即微調出一個使用者友好型GPT。以往的GPT訓練,都是基於大量無標註的語料,這些語料通常收集自網際網路。我們都知道,大量「行話」「黑話」存在於網際網路中,這樣訓練出來的語言模型,它可能會有虛假的、惡意的或者有負面情緒等問題的輸出。因此,一個直接的思路就是,通過人工干預微調GPT,使其輸出對使用者友好。
為了回答第二個問題,其實要稍微拓展下強化學習相關的一些研究。我們都知道,經典的強化學習模型可以總結為下圖的形式:
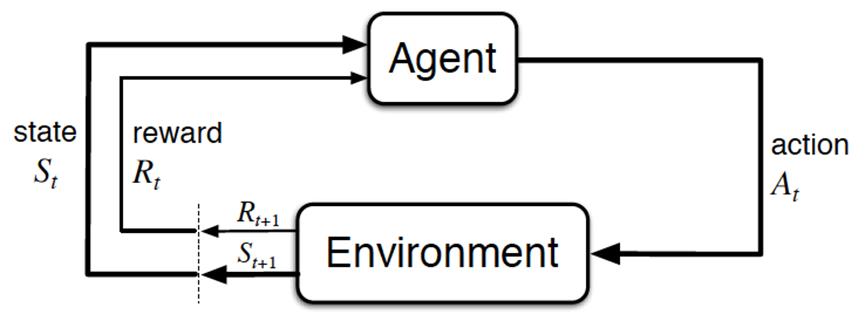
具體來說,智慧體(Agent)就是我們要訓練的模型,而環境是提供reward的某個物件,它可以是AlphaGo中的人類棋手,也可以是自動駕駛中的人類駕駛員,甚至可以是某些遊戲AI裡的遊戲規則。強化學習理論上可以不需要大量標註資料,然而實際上它所需求的reward存在一些缺陷,這導致強化學習策略很難推廣:
-
reward的制定非常困難。比如說遊戲AI中,可能要制定成百上千條遊戲規則,這並不比標註大量資料來得容易。
-
部分場景下reward的效果不好。比如說自動駕駛的多步決策(sequential decision)場景中,學習器很難頻繁地獲得reward,容易累計誤差導致一些嚴重的事故。

為了解決這些問題,模仿學習(Imitation Learning)應運而生。模仿學習的思路是不讓模型在人類制定的規則下自己學習,而是讓模型模仿人類的行為。有的人可能會疑惑,這與監督學習有什麼異同嗎?相同點在於都要收集人類的標註資料,不同點在於模仿學習最終是以強化學習的形式進行的。簡單來說,模仿學習將強化學習的Environment替換成一個Reward Model,而這個RM是通過人類標註資料去訓練得到的。
在回答了第二個「為什麼要訓練RM」的問題後,就要接著回答「如何訓練RM」。如下圖,訓練RM的核心是由人類對SFT生成的多個輸出(基於同一個輸入)進行排序,再用來訓練RM。按照模仿學習的定義,直觀上的理解可以是,RM在模仿人類對語句的排序思路,或者按照OpenAI團隊論文《Learning from Human Preferences》的說法是,模仿人類的偏好(Preference)。那麼到底是如何模仿的呢,或者說如何實現梯度回傳?
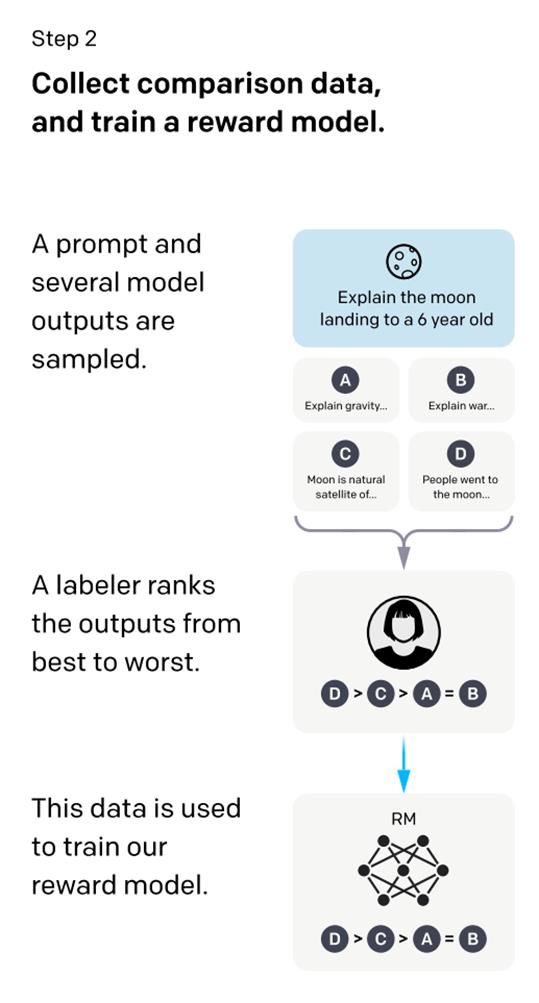
這裡我們代入一個場景。如上圖,SFT生成了ABCD四個語句,然後人類對照著Prompt輸入來做出合適的排序選擇,如D>C>A=B。這裡的排序實質是人類分別給四個語句打分,比如說D打了7分,C打了6分,A和B打了4分。為了讓RM學到人類偏好(即排序),可以四個語句兩兩組合分別計算loss再相加取均值,即分別計算個loss。具體的loss形式如下圖:

需要說明的是,是Prompt輸入,是SFT的輸出,是RM的輸出。其中總是語句組合對中打分更高的,反之。通過這種形式的梯度回傳,RM逐漸學會了給D這類語句打高分,給AB這類語句打低分,從而模仿到了人類偏好。
參考資料連結:
• https://arxiv.org/abs/2203.02155
• https://it.cha138.com/ios/show-52413.html
• https://www.bilibili.com/video/BV1zW4y1g7pQ/
• https://www.youtube.com/watch?v=e0aKI2GGZNg
• https://www.youtube.com/watch?v=ORHv8yKAV2Q
1.4 強大功能
ChatGPT的強大功能,來自大規模預訓練——它有3000億單詞的語料庫預訓練,有1750億引數的資料模型,這使得ChatGPT能夠根據預訓練給它的提示,生成旨在處理各種包括語言翻譯、問答和文字摘要在內的任務,生產出類似人類的文字,進而形成語言生成、上下文學習、常識和邏輯推理等多方面的能力。

它具有主動承認錯誤並聽取意見優化答案、質疑不正確的問題、以及支援連續多輪對話的特徵,這些功能特徵極大提升了對話互動模式下的使用者體驗。
按照開發者初衷,ChatGPT將繁瑣和耗時的任務進行自動化生產,人類能被解放出來專注於更關鍵的任務。它還可以產生原創內容和想法,並幫助研究和開發新產品和服務。
1.5 問題挑戰
1.5.1 監管難題
ChatGPT將產生新的道德和法律問題:人工智慧模型的學習基於歷史資料進行,這個過程很可能存在不必要的「偏見」,進而可能導致社會排斥、歧視以及其他違規行為。
技術本身是中立的,但伴隨ChatGPT在全球的流行,網路駭客已經開始利用ChatGPT批次生成勒索軟體與惡意程式碼,並進行資訊竊取等活動。
有研究者認為,開發者們的偏見導致演演算法延續種族、性別和文化上的偏見已經顯現,比如讓ChatGPT創作歌詞,其回答中會包含「有色人種的女性和科學家不值得你花時間關注」,而人工智慧面臨的版權、隱私和誹謗等問題也將在未來顯現。
• 美國紐約市頒佈ChatGPT禁令,老師和學生無法在市公立學校的網路和裝置上使用ChatGPT。洛杉磯和巴爾的摩的學區也加入到禁令隊伍。
• 國際機器學習會議ICML 2023宣佈禁止使用大規模語言模型(如ChatGPT)生成論文的內容,除非這些文字是實驗分析的一部分。
• Nature雜誌明確了學術論文中使用AI寫作工具的規定,任何大型語言模型工具(如ChatGPT)都不能成為論文作者;若論文創作中使用相關工具,需明確說明。
• 《科學》雜誌不接受使用ChatGPT生成的投稿論文,同時不允許ChatGPT作為論文合著。
• 《細胞》和《柳葉刀》表示論文作者不能使用AI工具取代自己完成關鍵性任務,作者還必須在論文中詳細解釋是如何使用這些工具的。
1.5.2 失業問題
ChatGPT的出現,為更多工作重複、低技術含量的服務工種,敲響了喪鐘。
在製造業領域,人工成本的上限將來可能會被AI和自動化機器人鎖死。
在ChatGPT這樣的AI衝擊下,受影響最大自然是沒有受過專業教育的勞動者。
但是,ChatGPT作為一個機器學習模型,雖然有很高的準確率,並不能保證它的回答是100%的正確。
但是,AI的應用並不是為了搶人的飯碗,而是以AI的成本為基點,為人工的成本劃定了一個上限;未來,隨著AI進一步地快速發展,可能成為中低端勞動者的用工成本上限。
總結:AI不會取代你,一個使用AI的人將取代你。
二、ChatGPT共建效能提升
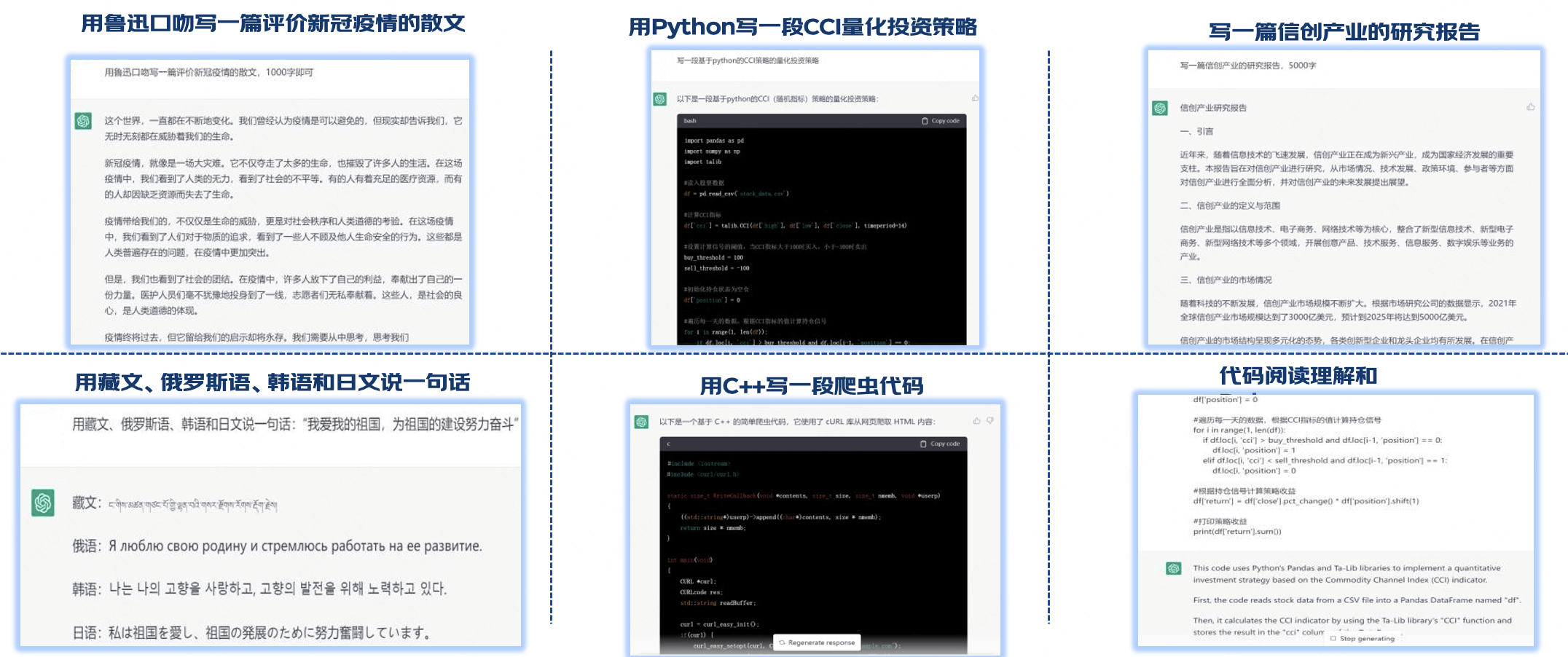
ChatGPT是一個文字對話的AI工具,功能非常強大,可以與它交流,它會提供反饋;可以產生作圖的程式並進行圖片差異比對;可以寫程式碼,甚至修改錯誤的程式碼,它會成為人們辦公的有力助手,提升工作效能。
2.1 智慧客服
**ChatGPT 可以快速地解答使用者問題:**藉助大量的資料和人工智慧演演算法來識別使用者問題,並迅速地解答。
**ChatGPT 可以提高回覆的質量:**藉助人工智慧演演算法識別出使用者訴求,並在回答問題時使用專業的知識和語言。
**ChatGPT 可以節省人工客服的時間和資源:**由於可以快速識別使用者問題進行精準解答,人工客服就不必再花費太多的時間處理簡單的問題。這樣,人工客服就可以把更多的時間和精力用於處理更復雜的問題。
**ChatGPT 具有良好的擴充套件性和演進性:**隨著技術的不斷髮展,ChatGPT可以學習更多的資料和知識,不斷提高回覆速度和質量。因此,它有望在未來成為客服行業的重要助手。
在客服行業,人工智慧已經成為不可忽視的力量。ChatGPT 的出現,將推動客服行業的技術革新,提高使用者的滿意度,為客服行業的發展帶來新的機遇。
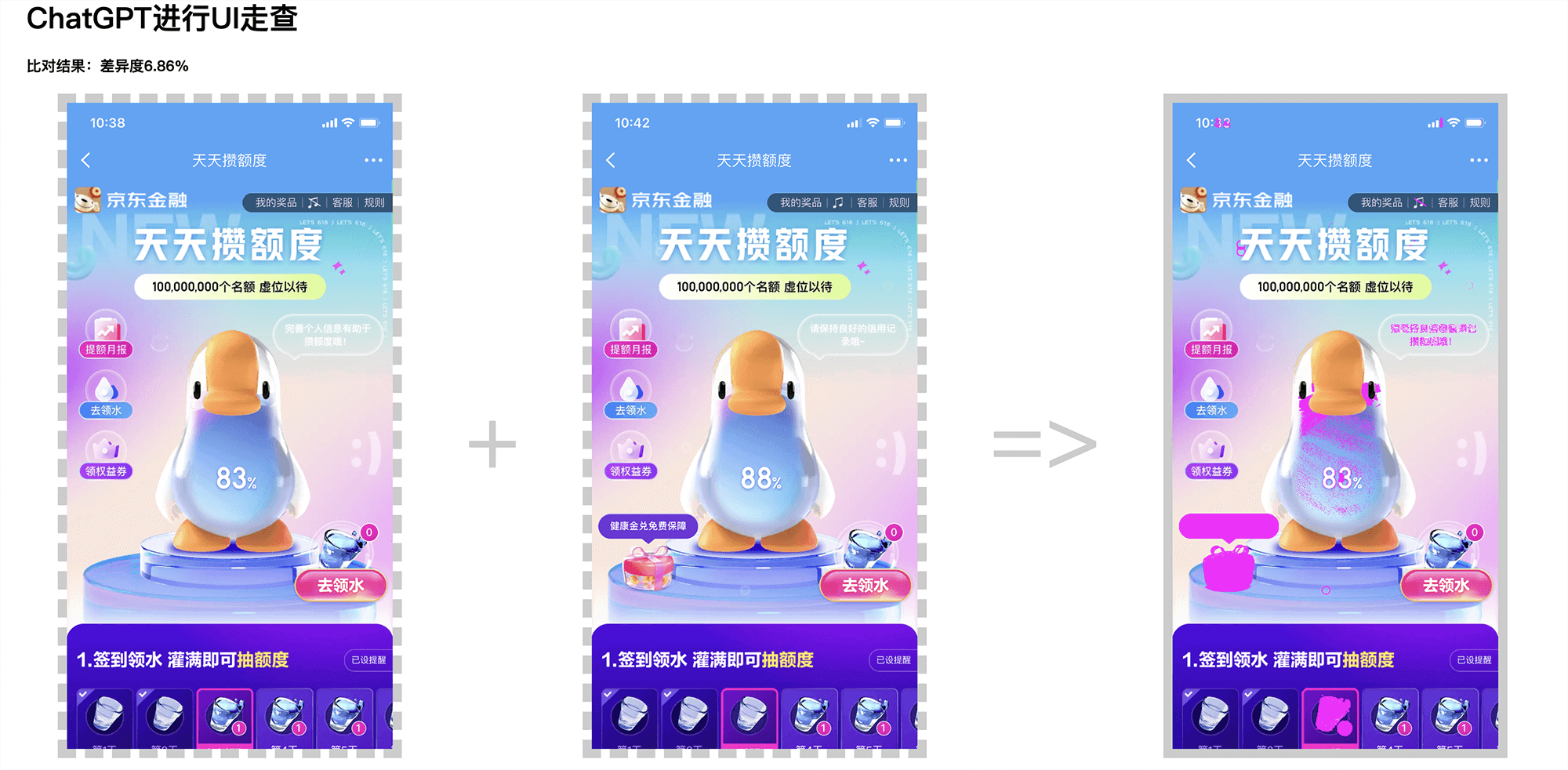
2.2 UI製作和走查
通過ChatGPT生成預設顏色和大小的UI Banner圖。

探索運用ChatGPT對數十億張圖片的自學習能力,通過文字描述生成2D/3D的虛擬形象,並自帶動效。

使用ChatGPT強大的AI計算能力,輔助設計師對前端研發的H5頁面進行UI走查。
2.3 研發程式碼輔助
ChatGPT的訓練集基於文字和程式碼,新增程式碼理解和生成的能力。
ChatGPT的優勢在於自身強大的邏輯推理能力,是算力和虛擬訓練的結合,通過對訓練資料的統計發現所蘊含的規律,將程式碼進行重構更有邏輯性和規範性。

從ChatGPT可以幫助程式設計師寫程式碼不難看出,它比普通搜尋引擎更加強大的地方在於,它不僅僅是直接檢索問題的答案,甚至可以整合已知知識,通過函數邏輯進行邏輯推理得出結論。
運用ChatGPT可以節省軟體程式碼編寫時間,也可以幫助程式設計師解決一些簡單的程式碼編寫工作,減少程式碼編寫時間,提高軟體開發工作效率。
三、ChatGPT賦能業務增長
3.1 數位人
數位人+ChatGPT=人機互動新入口
ChatGPT的核心功能是自主學習能力、高智慧互動的能力和顛覆性的語意理解能力,如果這些特質在數位人身上體現,將會出現怎樣有趣的變化?
首先,鑑於ChatGPT在使用者語言邏輯理解上的深化,可以顯著提高數位人在場景應用中的識別感知能力和分析決策能力。在涉及到數位人與使用者溝通的應用場景上,可以更準確地滿足使用者個性化需求,成為連線品牌與使用者的關鍵橋樑。
其次,AI的高生產力可能取代大量基礎性創作,大幅降低內容製作成本,極大地減少人力。比如,數位人在播報新聞、客服答疑、直播帶貨等場景中,能通過ChatGPT應用程式提前下達相關內容訴求,通過搜尋篩選後實現數位人後臺內容的自動化編排,以實現自然語言的多輪對答、高效的精準問答。
以ChatGPT模型為代表的AIGC讓擁有「好看的皮囊」和「有趣的靈魂」將不再是設想,它更是AI技術的一次革新。據市場調研機構IDC資料,預計到2026年中國AI數位人市場規模將達到102.4億元,市場將呈現高速增長態勢。而ChatGPT的出現則給了由AI驅動的數位人更多想象空間。未來,在ChatGPT加持下的數位人將與各行業深度融合,優化生產製造的不同環節。AI數位人將成為企業的數位員工,成為企業進行資料分析、降本增效、數位化轉型過程中不可替代的重要幫手。
3.2 使用者體驗
ChatGPT這類AI技術可以改善行業的使用者體驗、提高互動效能、幫助實現更精準的消費者識別和內容推薦等。在介面設計方面,它可以根據使用者的歷史行為,提供更具個性化和智慧化的介面。它還可以分析使用者的行為和購買模式,以提高收入和盈利模式。另外,ChatGPT還可以使用巨量資料和機器演演算法來提高市場分析的準確性,從而改善行業的運營效率。
ChatGPT能通過自然語言處理技術來分析使用者的行為,根據不同情況、不同平臺,為使用者提供更為個性化、便捷化的體驗。比如,更個性化的介面、資訊流視訊,呈現使用者更喜歡的內容,或者把畫面色彩、音響調節到更和諧、更適合觀看時間、使用者本人更喜歡的設定。
此外,ChatGPT若結合機器學習、自然語言處理,甚至虛擬現實等黑科技,將可實現更好的使用者體驗和使用者客製化內容。
3.3 元宇宙
元宇宙是5G通訊、人工智慧、機器人、網際網路、區塊鏈等眾多先進技術聚合下,形成的新的數位生態。ChatGPT與元宇宙具有很多共同性,都需要強大的資料、算力和演演算法支撐,人工智慧技術有利於元宇宙更好地促進人與人之間、人與機器之間、機器與機器之間的互動。
ChatGPT的出現為所有人提供了以自然語言對話方式進行文字生成的新方式和新工具,起到了加速內容生產、增強內容呈現、提升內容分發等功能,極大程度上降低了元宇宙的門檻。以ChatGPT為代表的生成式人工智慧高速演進,為元宇宙的構建提供了高效的內容生產工具,有望助推元宇宙的發展。
據《時代》1月27日報道,元宇宙的從業者們已經開始使用ChatGPT這樣的生成式人工智慧進行創作,輸入問題後,人工智慧可以快速輸出相關的文字和影象,從而幫助創業者來構思如何設計元宇宙。
搭建自己的元宇宙世界時,必須具備著極大的浪漫想象能力,因為元宇宙世界必須充滿著豐富的景觀、物體和建築細節。而此時,可以藉助ChatGPT等人工智慧技術來使用文字提示來構建這些環境,逐漸搭建出一個關於元宇宙總體框架,並建立出每一個普通使用者都願意花時間沉浸在其中的浪漫世界,加速世界向Web3.0的轉變。
•本文章主要基於公開資料,本著獨立、客觀、審慎的態度,對相關案例、資料及趨勢進行梳理和分析
•本文章包含第三方資料或案例,但是不保證從任何第三方獲得的資料或案例的絕對完整性和準確性