演演算法基礎模板
時空複雜度分析
一般ACM或者筆試題的時間限制是1秒或2秒。在這種情況下,C++程式碼中的操作次數控制在107~108為最佳。下面給出在不同資料範圍下,程式碼的時間複雜度和演演算法該如何選擇:
- n ≤ 30,指數級別,dfs+剪枝,狀態壓縮dp
- n ≤ 100 => O(n3),floyd,dp,高斯消元
- n ≤ 1000 =>O(n2),O(n2logn),dp,二分,樸素版Dijkstra、樸素版Prim、Bellman-Ford
- n ≤ 10000 => o(n * \(\sqrt{n}\)),塊狀連結串列、分塊、莫隊
- n ≤ 100000 => O(nlogn) => 各種sort,線段樹、樹狀陣列、set/map、heap、拓撲排序、dijkstra+heap、prim+heap、Kruskal、spfa、求凸包、求半平面交、二分、CDQ分治、整體二分、字尾陣列、樹鏈剖分、動態樹
- n ≤ 1000000 =>O(n),以及常數較小的O(nlogn)演演算法 => 單調佇列、hash、雙指標掃描、並查集,kmp、AC自動機,常數比較小的O(nlogn)的做法: sort、樹狀陣列、heap、dijkstra、spfa
- n ≤ 10000000 => o(n),雙指標掃描、kmp、AC自動機、線性篩素數
- n ≤ 109=> o(\(\sqrt{n}\)),判斷質數
- n ≤ 1018 => o(logn),最大公約數,快速冪,數位DP
- n ≤ 101000 => o((logn)2),高精度加減乘除
- n ≤ 10100000 => o(logk x loglogk),k表示位數,高精度加減、FFT/NTT
基礎演演算法-模板
排序
//快排
void quick_sort(int q[], int l, int r){
if (l >= r) return;
int i = l - 1, j = r + 1, x = q[l + r >> 1];
while (i < j){
do i ++; while (q[i] < x);
do j --; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j);
quick_sort(q, j + 1, r);
}
//歸排
void merge_sort(int q[], int l, int r){
if (l >= r) return;
int mid = l + r >> 1;
merge_sort(q, l, mid);
merge_sort(q, mid + 1, r);
int k = 0, i = l, j = mid + 1;
while (i <= mid && j <= r)
if (q[i] <= q[j]) tmp[k ++] = q[i ++];
else tmp[k ++] = q[j ++];
while(i <= mid) tmp[k ++] = q[i ++];
while(j <= r) tmp[k ++] = q[j ++];
for (i = l, j = 0; i <= r; i ++, j ++) q[i] = tmp[j];
}
二分
// 整數二分
bool check(int x){} // 查詢x是否滿足某種性質
// 區間[l, r]被劃分成[l, mid]和[mid + 1, r]時使用:符合條件的第一個位置
int bsearch_1(int l, int r){
while (l < r){
int mid = l + r >> 1;
if (check(mid)) r = mid; // check(mid) 判斷 [l,mid] 這個區間是否滿足條件
else l = mid + 1;
}
return l;
}
// 區間[l, r]被劃分成[l, mid - 1]和[mid, r]時使用:符合條件的最後一個位置
int bsearch_2(int l, int r){
while (l < r){
int mid = l + r + 1 >> 1; // + 1 的原因是 l + r >> 1 有可能 == l , l = mid 這條就會導致死迴圈
if (check(mid)) l = mid; // check(mid) 判斷 [mid,r] 這個區間是否滿足條件
else r = mid - 1;
}
return l;
}
// 浮點數二分
double bsearch_3(double l, double r){
const double eps = 1e-6; // 查詢的精度
while (r - l > eps){
double mid = (l + r) / 2;
if (check(mid)) r = mid;
else l = mid;
}
return l;
}
高精度
// 加法
vector<int> add_plus(vector<int> &a, vector<int> &b){ //陣列元素都是倒置
if (a.size() < b.size()) return add_plus(b,a);
vector<int> c;
int t = 0;
for (int i = 0; i < a.size(); i ++){
t += a[i];
if (i < b.size()) t += b[i];
c.push_back(t % 10);
t /= 10;
}
if (t) c.push_back(t);
return c;
}
//減法 C = A - B, 滿足A >= B, A >= 0, B >= 0
vector<int> sub(vector<int> &a, vector<int> &b){
vector<int> c;
for (int i = 0, t = 0; i < a.size(); i ++ ){
t = a[i] - t;
if (i < b.size()) t -= b[i];
c.push_back((t + 10) % 10);
if (t < 0) t = 1;
else t = 0;
}
while (c.size() > 1 && c.back() == 0) c.pop_back();
return c;
}
//高精×低精 C = A * b, A >= 0, b >= 0
vector<int> mul(vector<int> &a, int b){
vector<int> c;
int t = 0;
for (int i = 0; i < a.size() || t; i ++ ){
if (i < a.size()) t += A[i] * b;
c.push_back(t % 10);
t /= 10;
}
while (c.size() > 1 && c.back() == 0) c.pop_back();
return c;
}
//高精÷低精 A / b = C ... r, A >= 0, b > 0
vector<int> div(vector<int> &a, int b, int &r){
vector<int> c;
r = 0;
for (int i = a.size() - 1; i >= 0; i -- ){
r = r * 10 + A[i];
c.push_back(r / b);
r %= b;
}
reverse(c.begin(), c.end());
while (c.size() > 1 && c.back() == 0) c.pop_back();
return c;
}
字首和
//一維
s[i] = s[i - 1] + a[i];
[x1,x2]的和 sum = s[x2] - s[x1 - 1];
//二維
s[i][j] += s[i - 1][j] + s[i][j - 1] - s[i - 1][j - 1];
[(x1,y1),(x2,y2)]的和 sum = s[x2][y2] - s[x2][y1 - 1] - s[x1 - 1][y2] + s[x1 - 1][y1 - 1];
差分
//一維差分 思路: 存數按詢問方式操作
給區間[l, r]中的每個數加上c: B[l] += c, B[r + 1] -= c
//二維差分
給以(x1, y1)為左上角,(x2, y2)為右下角的子矩陣中的所有元素加上c:
S[x1, y1] += c, S[x2 + 1, y1] -= c, S[x1, y2 + 1] -= c, S[x2 + 1, y2 + 1] += c
位運算
① &: 與 ② |: 或 ③ ^: 互斥或同0異1 ④ ~: 取反 ⑤ <<: 左移 ⑥ >>: 右移
//求n的二進位制的第k位數位:n >> k & 1; 19 10011
cout << (19 >> 4 & 1) << endl; //1
cout << (19 >> 3 & 1) << endl; //0
cout << (19 >> 2 & 1) << endl; //0
cout << (19 >> 1 & 1) << endl; //1
cout << (19 >> 0 & 1) << endl; //1
//求n的二進位制的最後一位1的位置lowbit(n) = n&-n; 20 10100
cout << (20&-20) << endl;//4
雙指標
for (int i = 0, j = 0; i < n; i ++ ){
while (j < i && check(i, j)) j ++ ;
// 具體問題的邏輯
}
常見問題分類:
(1) 對於一個序列,用兩個指標維護一段區間
(2) 對於兩個序列,維護某種次序,比如歸併排序中合併兩個有序序列的操作
離散化
vector<int> alls; // 儲存所有待離散化的值
sort(alls.begin(), alls.end()); // 將所有值排序
alls.erase(unique(alls.begin(), alls.end()), alls.end()); // 去掉重複元素
// 二分求出x對應的離散化的值
int find(int x) // 找到第一個大於等於x的位置{
int l = 0, r = alls.size() - 1;
while (l < r){
int mid = l + r >> 1;
if (alls[mid] >= x) r = mid;
else l = mid + 1;
}
return r + 1; // 對映到1, 2, ...n
}
區間合併
void merge(vector<PII> &segs){
vector<PII> res;
sort(segs.begin(), segs.end());
int st = -2e9, ed = -2e9;
for (auto seg : segs){
if (ed < seg.first){
if (st != -2e9) res.push_back({st, ed});
st = seg.first, ed = seg.second;
}
else ed = max(ed, seg.second);
}
if (st != -2e9) res.push_back({st, ed});
segs = res;
}
資料結構-模板
單連結串列
// head儲存連結串列頭,e[]儲存節點的值,ne[]儲存節點的next指標,idx表示當前用到了哪個節點
int head, e[N], ne[N], idx;
// 初始化
void init(){
head = -1;
idx = 0;
}
// 在連結串列頭插入一個數a
void insert(int a){
e[idx] = a, ne[idx] = head, head = idx ++ ;
}
// 在結點k後插入一個數x
void add(int k, int x){
e[idx] = x, ne[idx] = ne[k], ne[k] = idx ++ ;
}
// 將頭結點刪除,需要保證頭結點存在
void remove(){
head = ne[head];
}
雙連結串列
// e[]表示節點的值,l[]表示節點的左指標,r[]表示節點的右指標,idx表示當前用到了哪個節點
int e[N], l[N], r[N], idx;
// 初始化
void init(){
//0是左端點,1是右端點
r[0] = 1, l[1] = 0;
idx = 2;
}
// 在節點a的右邊插入一個數x
void insert(int a, int x){
e[idx] = x;
l[idx] = a, r[idx] = r[a]; // 新節點連舊
l[r[a]] = idx, r[a] = idx ++; // 舊節點連新
}
// 刪除節點a
void remove(int a){
l[r[a]] = l[a];
r[l[a]] = r[a];
}
// 遍歷單連結串列
for (int i = h[k]; i != -1; i = ne[i])
x = e[i];
單調棧
//常見模型:找出每個數左邊離它最近的比它大/小的數
int stk[N],tt = 0; // 棧中存資料或下標
for (int i = 1; i <= n; i ++){
int x; cin >> x;
while (tt && stk[tt] >= x) tt -- ; // 左邊比它小的數
stk[ ++ tt] = i; // 把當前值放在合適地方
}
單調佇列
//常見模型:找出滑動視窗中的最大值/最小值
int a[N],q[N]; // q[N] 存的是a陣列的下標
int hh = 0, tt = -1; // hh 隊頭(左) tt 隊尾(右)
for (int i = 0; i < n; i ++){
while (hh <= tt && check_out(q[hh])) hh ++ ; // 判斷隊頭是否滑出視窗
while (hh <= tt && check(q[tt], i)) tt -- ; // 捨去不合理資料
q[ ++ tt] = i; // 把當前資料的座標插入適合的地方
}
KMP
// s[1-m]是長文字,p[1-n]是模式串,m是s的長度,n是p的長度
// 求next
for (int i = 2, j = 0; i <= n; i ++){
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j+1]) j ++;
ne[i] = j;
}
// 匹配
for (int i = 1, j = 0; i <= m; i ++){
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j ++;
if (j == n) {
printf("%d ",i - n);
j = ne[j];
}
}
Tree樹
int son[N][26], cnt[N], idx;
// 0號點既是根節點,又是空節點
// son[][]儲存樹中每個節點的子節點 【實質是多開*26空間記錄每個節點的資訊】【這個26是根據提目要求具體有所變化】
// cnt[]儲存以每個節點結尾的單詞數量
// idx 節點編號
// 插入一個字串
void insert(char *str){
int p = 0;
for (int i = 0; str[i]; i ++ ){
int u = str[i] - 'a';
if (!son[p][u]) son[p][u] = ++ idx;// 該節點是否存過
p = son[p][u];
}
cnt[p] ++;
}
// 查詢字串出現的次數
int query(char *str){
int p = 0;
for (int i = 0; str[i]; i ++ ){
int u = str[i] - 'a';
if (!son[p][u]) return 0;
p = son[p][u];
}
return cnt[p];
}
並查集
(1)樸素並查集:
int p[N]; //儲存每個點的祖宗節點
// 返回x的祖宗節點
int find(int x){
if (p[x] != x) p[x] = find(p[x]); // 路徑壓縮
return p[x];
}
// 初始化,假定節點編號是1~n
for (int i = 1; i <= n; i ++ ) p[i] = i;
// 合併a和b所在的兩個集合:
p[find(a)] = find(b);
(2)維護size的並查集:
int p[N], size[N];
//p[]儲存每個點的祖宗節點, size[]只有祖宗節點的有意義,表示祖宗節點所在集合中的點的數量
// 返回x的祖宗節點
int find(int x){
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
// 初始化,假定節點編號是1~n
for (int i = 1; i <= n; i ++ ){
p[i] = i;
size[i] = 1;
}
// 合併a和b所在的兩個集合:
size[find(b)] += size[find(a)];
p[find(a)] = find(b);
(3)維護到祖宗節點距離的並查集:
int p[N], d[N];
//p[]儲存每個點的祖宗節點, d[x]儲存x到p[x]的距離
// 返回x的祖宗節點
int find(int x){
if (p[x] != x){
int u = p[x]; // u記錄舊的父節點
p[x] = find(p[x]); // 路徑壓縮,新父節點變成根節點了
d[x] += d[u]; // x到新父節點的距離等於x到舊父節點的距離加上舊父節點到根節點的距離
}
return p[x];
}
// 初始化,假定節點編號是1~n
for (int i = 1; i <= n; i ++ ){
p[i] = i;
d[i] = 0;
}
// 合併a和b所在的兩個集合:
p[find(a)] = find(b);
d[find(a)] = distance; // 根據具體問題,初始化find(a)的偏移量
// 240. 食物鏈 ------ (3)維護到祖宗節點距離的並查集
#include <bits/stdc++.h>
using namespace std;
const int N = 50010;
int n, m;
int p[N], d[N];
int find(int x) {
if (p[x] != x) {
int u = p[x]; // u記錄舊的父節點
p[x] = find(p[x]); // 路徑壓縮,新父節點變成根節點了
d[x] += d[u]; // x到新父節點的距離等於x到舊父節點的距離加上舊父節點到根節點的距離
}
return p[x];
}
int main(){
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++ ) p[i] = i;
int res = 0;
while (m -- ){
int t, x, y;
scanf("%d%d%d", &t, &x, &y);
if (x > n || y > n) res ++ ;
else{
int px = find(x), py = find(y);
if (t == 1) { //x和y是同類
if (px == py && (d[x] - d[y]) % 3) res ++ ; //如果d[x]=d[y]說明距離相等
else if (px != py) { //更新
p[px] = py;
d[px] = d[y] - d[x]; //(d[x]+?-d[y])%3==0
}
}else { //x和y不是同類
if (px == py && (d[x] - d[y] - 1) % 3) res ++ ;
else if (px != py) {
p[px] = py;
d[px] = d[y] + 1 - d[x]; //(d[x]+?-d[y]-1)%3==0
}
}
}
}
printf("%d\n", res);
return 0;
}
堆
// h[N]儲存堆中的值, h[1]是堆頂,x的左兒子是2x, 右兒子是2x + 1
// ph[k]儲存第 k 個插入的點在堆中的位置
// hp[J]儲存堆中下標為 J 的點是第幾個插入的
int h[N], ph[N], hp[N], size;
// 交換兩個點,及其對映關係
void heap_swap(int i, int j){ // 交換i節點和j節點(附帶更新是第幾個插入的節點)
swap(ph[hp[i]],ph[hp[j]]); //更新 i 和 j ph 資訊
swap(hp[i], hp[j]); //更新 i 和 j hp 資訊
swap(h[i], h[j]); //交換 i 和 j 數值
}
void down(int u){ // 向下更新
int t = u;
if (u * 2 <= size && h[u * 2] < h[t]) t = u * 2; // 左孩子
if (u * 2 + 1 <= size && h[u * 2 + 1] < h[t]) t = u * 2 + 1; // 右孩子
if (u != t){
heap_swap(u, t);
down(t); // 向下遞迴繼續更新
}
}
void up(int u){ // 向上更新
while (u / 2 && h[u] < h[u / 2]){
heap_swap(u, u / 2);
u >>= 1;
}
}
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);
雜湊表
(1) 拉鍊法
int h[N], e[N], ne[N], idx;
// 向雜湊表中插入一個數
void insert(int x){
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx ++;
}
// 在雜湊表中查詢某個數是否存在
bool find(int x){
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
if (e[i] == x)
return true;
return false;
}
(2) 開放定址法
int h[N];
// 如果x在雜湊表中,返回x的下標;如果x不在雜湊表中,返回x應該插入的位置
int find(int x){
int t = (x % N + N) % N; // N 一般取 大於資料範圍的素數
while (h[t] != null && h[t] != x){
t ++ ;
if (t == N) t = 0;
}
return t;
}
字串雜湊
核心思想:將字串看成P進位制數,P的經驗值是131或13331,取這兩個值的衝突概率低
小技巧:取模的數用2^64,這樣直接用unsigned long long儲存,溢位的結果就是取模的結果
typedef unsigned long long ULL;
ULL h[N], p[N]; // h[k]儲存字串前k個字母的雜湊值, p[k]儲存 P^k mod 2^64
// 初始化
p[0] = 1;
for (int i = 1; i <= n; i ++ ){
h[i] = h[i - 1] * P + str[i];// 這個str[i]只要不是0就行任意值都行,因此不需要轉成1-26
p[i] = p[i - 1] * P;
}
// 計運算元串 str[l ~ r] 的雜湊值
// 由於h陣列的特殊定義,h陣列前面都是雜湊值的高位,所以l-r的雜湊值可以通過
// 類似, l=123,r=123456,r-l雜湊值等於123456-123000
ULL get(int l, int r){
return h[r] - h[l - 1] * p[r - l + 1];
}
STL
vector:變長陣列,倍增的思想
vector<int> a(10),a(10,1); // 長度10,且初始化為1
vector<int> a[10]; // 10個vector
【size()返回元素個數】 【empty()返回是否為空】 【clear()清空】 【front()/back()】
【push_back()/pop_back()】 【begin()/end()】 【[陣列]】 【支援比較運算,按字典序】
pair<int, int>
【first, 第一個元素】 【second, 第二個元素】
【支援比較運算,以first為第一關鍵字,以second為第二關鍵字(字典序)】
【p = make_pair(10,20); p = {10,20};】
string,字串
【size()/length()返回字串長度】 【empty()】 【clear()】
【substr(起始下標,(子串長度))返回子串】 【c_str()返回字串所在字元陣列的起始地址】
queue, 佇列
【size()】 【empty()】 【push()向隊尾插入一個元素】 【front()返回隊頭元素】
【back() 返回隊尾元素】 【pop() 彈出隊頭元素】
priority_queue, 優先佇列,預設是大根堆 【黑科技:插入負數就是小根堆】
【size()】 【empty()】 【push()插入一個元素】 【top()返回堆頂元素】
【pop()彈出堆頂元素】 【定義成小根堆的方式:priority_queue<int, vector<int>, greater<int>> q;】
stack, 棧
【size()】 【empty()】 【push()向棧頂插入一個元素】 【top()返回棧頂元素】 【pop()彈出棧頂元素】
deque, 雙端佇列
【size()】 【empty()】 【clear()】 【front()/back()】 【push_back()/pop_back()】
【push_front()/pop_front()】 【begin()/end()】 【[陣列/隨機存取]】
set, map, multiset, multimap, 基於平衡二元樹(紅黑樹),動態維護有序序列
【size()】 【empty()】 【clear()】 【begin()/end()】 【++,-- 返回前驅和後繼,時間複雜度 O(logn)】
set(無重複)/multiset(可重複)
【insert() 插入一個數】 【find() 查詢一個數】 【count() 返回某一個數的個數】
【erase()】
(1) 輸入是一個數x,刪除所有x O(k + logn)
(2) 輸入一個迭代器,刪除這個迭代器
lower_bound()/upper_bound()
【lower_bound(x) 返回大於等於x的最小的數的迭代器】
【upper_bound(x) 返回大於x的最小的數的迭代器】
map/multimap
【insert() 插入的數是一個pair】 【erase() 輸入的引數是pair或者迭代器】 【find()】
【[下標索引] 注意multimap不支援此操作。 時間複雜度是 O(logn)】 【lower_bound()/upper_bound()】
unordered_set, unordered_map, unordered_multiset, unordered_multimap, 雜湊表
和上面類似,增刪改查的時間複雜度是 O(1)
不支援 lower_bound()/upper_bound(), 迭代器的++,--
bitset, 圧位
bitset<10000> s;
~, &, |, ^
>>, <<
==, !=
[]
count() 返回有多少個1
any() 判斷是否至少有一個1
none() 判斷是否全為0
set() 把所有位置成1
set(k, v) 將第k位變成v
reset() 把所有位變成0
flip() 等價於~
flip(k) 把第k位取反
搜尋與圖論-模板
樹與圖的儲存
樹是一種特殊的圖,與圖的儲存方式相同。
對於無向圖中的邊ab,儲存兩條有向邊a->b, b->a。
因此我們可以只考慮有向圖的儲存。
-
鄰接矩陣: g[a][b]儲存邊a->b
-
鄰接表:
// 對於每個點k,開一個單連結串列,儲存k所有可以走到的點。h[k]儲存這個單連結串列的頭結點 int h[N], e[N], ne[N], idx; // 新增一條邊a->b void add(int a, int b){ e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ; } // 初始化 idx = 0; memset(h, -1, sizeof h);
樹與圖的遍歷
時間複雜度O(n + m), n表示點數,m表示邊數
-
深度優先搜尋
int dfs(int u){ st[u] = true; // st[u] 表示點u已經被遍歷過 for (int i = h[u]; i != -1; i = ne[i]){ int j = e[i]; if (!st[j]) dfs(j); } } -
寬度優先搜尋
queue<int> q; st[1] = true; // 表示1號點已經被遍歷過 q.push(1); while (q.size()){ int t = q.front(); q.pop(); for (int i = h[t]; i != -1; i = ne[i]){ int j = e[i]; if (!st[j]){ st[j] = true; // 表示點j已經被遍歷過 q.push(j); } } }
拓撲排序
時間複雜度 O(n+m),n表示點數,m表示邊數
int q[N],d[N]; // q模擬佇列,d記錄入度
bool topsort(){
int hh = 0, tt = -1;
for (int i = 1; i <= n; i ++ )
if (!d[i])
q[ ++ tt] = i; // 度為0的點隊尾入隊
while (hh <= tt){
int t = q[hh ++ ]; // 隊頭出隊
for (int i = h[t]; i != -1; i = ne[i]){
int j = e[i];
if (-- d[j] == 0) // 度為0的點入隊
q[ ++ tt] = j;
}
}
// 如果所有點都入隊了,說明存在拓撲序列;否則不存在拓撲序列。
return tt == n - 1; // 1 說明有n個節點入過佇列
}
樸素dijkstra演演算法
時間複雜是O(n2+m), n表示點數, m表示邊數
int g[N][N]; // 儲存每條邊
int dist[N]; // 儲存1號點到每個點的最短距離
bool st[N]; // 儲存每個點的最短路是否已經確定
// 求1號點到n號點的最短路,如果不存在則返回-1
int dijkstra(){
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for (int i = 0; i < n - 1; i ++ ){
int t = -1; // 在還未確定最短路的點中,尋找距離最小的點
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
// 用t更新其他點的距離
for (int j = 1; j <= n; j ++ )
dist[j] = min(dist[j], dist[t] + g[t][j]);
st[t] = true;
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
堆優化版dijkstra
時間複雜度O(mlogn), n表示點數, m表示邊數
typedef pair<int, int> PII;
int n; // 點的數量
int h[N], w[N], e[N], ne[N], idx; // 鄰接表儲存所有邊
int dist[N]; // 儲存所有點到1號點的距離
bool st[N]; // 儲存每個點的最短距離是否已確定
// 求1號點到n號點的最短距離,如果不存在,則返回-1
int dijkstra(){
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap;
heap.push({0, 1}); // first儲存距離,second儲存節點編號
while (heap.size()){
auto t = heap.top();
heap.pop();
int ver = t.second, distance = t.first;
if (st[ver]) continue;
st[ver] = true;
for (int i = h[ver]; i != -1; i = ne[i]){
int j = e[i];
if (dist[j] > distance + w[i]){
dist[j] = distance + w[i];
heap.push({dist[j], j});
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
Bellman-ford演演算法
時間複雜度O(nm), n表示點數, m表示邊數
int n, m; // n表示點數,m表示邊數
int dist[N]; // dist[x]儲存1到x的最短路距離
struct Edge{ // 邊,a表示出點,b表示入點,w表示邊的權重
int a, b, w;
}edges[M];
// 求1到n的最短路距離,如果無法從1走到n,則返回-1。
int bellman_ford(){
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
// 如果第n次迭代仍然會鬆弛三角不等式,就說明存在一條長度是n+1的最短路徑,由抽屜原理,路徑中至少存在兩個相同的點,說明圖中存在負權迴路。
for (int i = 0; i < n; i ++ ){
for (int j = 0; j < m; j ++ ){
int a = edges[j].a, b = edges[j].b, w = edges[j].w;
if (dist[b] > dist[a] + w)
dist[b] = dist[a] + w;
}
}
if (dist[n] > 0x3f3f3f3f / 2) return -1;
return dist[n];
}
求邊數限制的最短路演演算法 通過k次鬆弛,所求得的最短路,就是邊數限制的最短路
const int N = 510, M = 10010;
struct Edge{
int a, b, c;
}edges[M];
int n, m, k;
int dist[N];
int last[N];
void bellman_ford(){
memset(dist, 0x3f, sizeof dist); // 初始化
dist[1] = 0;
for (int i = 0; i < k; i ++ ){
// 為了防止發生串聯 如: 1→2→3,在一次迴圈裡1更新2,2有就可能更新3,這是不允許的,所以儲存初始dist陣列
memcpy(last, dist, sizeof dist);
for (int j = 0; j < m; j ++ ){
auto e = edges[j];
dist[e.b] = min(dist[e.b], last[e.a] + e.c); // 鬆弛
}
}
}
int main(){
scanf("%d%d%d", &n, &m, &k);
for (int i = 0; i < m; i ++ ){
int a, b, c;
scanf("%d%d%d", &a, &b, &c);
edges[i] = {a, b, c};
}
bellman_ford();
//不可dist[n]==0x3f3f3f3f 因為有可能出現1到不了2,2到3為負數,所以大於無窮的一半就可以判定無法到達
if (dist[n] > 0x3f3f3f3f / 2) puts("impossible");
else printf("%d\n", dist[n]);
return 0;
}
spfa 演演算法
佇列優化的Bellman-Ford演演算法: 時間複雜度平均情況下O(m),最壞情況下O(nm), n表示點數, m表示邊數
int n; // 總點數
int h[N], w[N], e[N], ne[N], idx; // 鄰接表儲存所有邊
int dist[N]; // 儲存每個點到1號點的最短距離
bool st[N]; // 儲存每個點是否在佇列中
// 求1號點到n號點的最短路距離,如果從1號點無法走到n號點則返回-1
int spfa(){
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
queue<int> q;
q.push(1);
st[1] = true; // st 陣列記錄哪些點在佇列裡
while (q.size()){
auto t = q.front();
q.pop();
st[t] = false;
for (int i = h[t]; i != -1; i = ne[i]){
int j = e[i];
if (dist[j] > dist[t] + w[i]){ // 鬆弛:對於佇列中所有符合條件的邊進行鬆弛
dist[j] = dist[t] + w[i];
if (!st[j]){ // 如果佇列中已存在j,則不需要將j重複插入
q.push(j); // 只要是符合條件就進佇列
st[j] = true;
}
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
spfa 求負環
int n; // 總點數
int h[N], w[N], e[N], ne[N], idx; // 鄰接表儲存所有邊
int dist[N], cnt[N]; // dist[x]儲存1號點到x的最短距離,cnt[x]儲存1到x的最短路中經過的點數
bool st[N]; // 儲存每個點是否在佇列中
// 如果存在負環,則返回true,否則返回false。
bool spfa(){
// 不需要初始化dist陣列,因為不用求具體數值,只需要向量的比較就行
// 原理:如果某條最短路徑上有n個點(除了自己),那麼加上自己之後一共有n+1個點,由抽屜原理一定有兩個點相同,所以存在環。
queue<int> q;
for (int i = 1; i <= n; i ++ ){ // 求整個圖中的負環
q.push(i);
st[i] = true;
}
while (q.size()){
auto t = q.front();
q.pop();
st[t] = false;
for (int i = h[t]; i != -1; i = ne[i]){
int j = e[i];
if (dist[j] > dist[t] + w[i]){ // 鬆弛
dist[j] = dist[t] + w[i];
cnt[j] = cnt[t] + 1;
if (cnt[j] >= n) return true; // 如果從1號點到x的最短路中包含至少n個點(不包括自己),則說明存在環
if (!st[j]){
q.push(j);
st[j] = true;
}
}
}
}
return false;
}
Floyd演演算法
// 初始化:
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
if (i == j) d[i][j] = 0;
else d[i][j] = INF;
// 演演算法結束後,d[a][b]表示a到b的最短距離
void floyd(){
for (int k = 1; k <= n; k ++ )
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
// 輸出結果
if(g[a][b] > INF/2)puts("impossible");
else printf("%d\n",g[a][b]);
樸素版Prim演演算法
時間複雜度是O(n2+m), n表示點數,m表示邊數
用堆優化版prim,和用堆優化版Dijkstra差不多
int n; // n表示點數
int g[N][N]; // 鄰接矩陣,儲存所有邊
int dist[N]; // 儲存其他點到當前最小生成樹的距離
bool st[N]; // 儲存每個點是否已經在生成樹中
// 如果圖不連通,則返回INF(值是0x3f3f3f3f), 否則返回最小生成樹的樹邊權重之和
int prim(){
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
int res = 0;
for (int i = 0; i < n; i ++ ){
int t = -1;
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
if (dist[t] == INF) return INF;
res += dist[t];
st[t] = true;
// 放在下面,是因為資料中有自環,容易造成誤算
for (int j = 1; j <= n; j ++ ) dist[j] = min(dist[j], g[t][j]); // 把t所連且距離更短的放入集合
}
return res;
}
堆優化版Prim
不用刻意優化
const int N = 510, INF = 0x3f3f3f3f;
int n, m;
int g[N][N];
bool st[N];
int prim(){
int res = 0, cnt = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap;
heap.push({0,1});
while (heap.size()){
auto t = heap.top();
heap.pop();
if(st[t.second]) continue;
st[t.second] = true;
res += t.first;
cnt ++;
for (int i = 1; i <= n; i ++){
if (!st[i] && g[t.second][i] != INF){
heap.push({g[t.second][i], i});
}
}
}
if(cnt != n)return INF;
return res;
}
Kruskal演演算法
int n, m; // n是點數,m是邊數
int p[N]; // 並查集的父節點陣列
struct Edge{ // 儲存邊
int a, b, w;
bool operator< (const Edge &W)const{
return w < W.w;
}
}edges[M];
int find(int x){ // 並查集核心操作
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int kruskal(){
sort(edges, edges + m);
for (int i = 1; i <= n; i ++ ) p[i] = i; // 初始化並查集
int res = 0, cnt = 0;
for (int i = 0; i < m; i ++ ){
int a = edges[i].a, b = edges[i].b, w = edges[i].w;
a = find(a), b = find(b);
if (a != b){ // 如果兩個連通塊不連通,則將這兩個連通塊合併
p[a] = b;
res += w;
cnt ++ ;
}
}
if (cnt < n - 1) return INF;
return res;
}
二分圖-染色判定法
- 二分圖定義: 圖中不存在奇數環;或圖可被分為兩部分,兩部分內部不存在邊,只在中間存在邊。
- 時間複雜度是O(n + m), n表示點數,m表示邊數
int n; // n表示點數
int h[N], e[M], ne[M], idx; // 鄰接表儲存圖
int color[N]; // 表示每個點的顏色,0表示未染色,1表示白色,2表示黑色
// 引數:u表示當前節點,c表示當前點的顏色
bool dfs(int u, int c){
color[u] = c;
for (int i = h[u]; i != -1; i = ne[i]){
int j = e[i];
if (!color[j] && !dfs(j, 3 - c)) return false;
else if (color[u] == color[j]) return false;
}
return true;
}
bool check(){
bool flag = true;
for (int i = 1; i <= n; i ++ )
if (!color[i] && !dfs(i, 0)){
flag = false;
break;
}
return flag;
}
二分圖-匈牙利演演算法
- 匈牙利演演算法為了解決二分圖兩部分的節點的最大匹配數。
- 匈牙利演演算法: 二分圖的兩部分,一方男同志,一方女同志,兩方匹配,一方按順序匹配,有心儀的女生(即有邊),即匹配成功,到某個男生匹配時,發現心儀的女生已經匹配了,那麼這個男生就要女生問問她的配偶是否有備胎,遞回去問備胎是否單身....。若備胎也沒匹配,那麼她男朋友和他備胎在一起,直到所有有聯絡的人都問完。---給人找到下家,才去挖牆腳。(做錯不重要,重要的是錯過)
- 時間複雜度是O(nm), n表示點數,m表示邊數
int n1, n2; // n1表示第一個集合中的點數,n2表示第二個集合中的點數
int h[N], e[M], ne[M], idx; // 鄰接表儲存所有邊,匈牙利演演算法中只會用到從第一個集合指向第二個集合的邊,所以這裡只用存一個方向的邊
bool st[N]; // 男生匹配每個女生只嘗試一次
int match[N]; // 該女生匹配了哪個男生
bool find(int x){
for (int i = h[x]; i != -1; i = ne[i]){
int j = e[i];
if (!st[j]){
st[j] = true; // 只嘗試一次
if (match[j] == 0 || find(match[j])){ // 沒匹配或者物件有備胎
match[j] = x; // 匹配成功
return true;
}
}
}
return false;
}
// 求最大匹配數,依次列舉第一個集合中的每個點能否匹配第二個集合中的點
int res = 0;
for (int i = 1; i <= n1; i ++ ){
memset(st, false, sizeof st); // 每個都嘗試
if (find(i)) res ++ ;
}
數學知識-模板
試除法判定質數
時間複雜度大O(sqrt(n))
bool is_prime(int x){
if (x < 2) return false;
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
return false;
return true;}
試除法分解質因數
時間複雜度O(log(n) - sqrt(n))
void divide(int x){
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0){ // i 一定是質數,因為合數在前面已經除完了
int s = 0;
while (x % i == 0) x /= i, s ++ ;
cout << i << ' ' << s << endl;
}
if (x > 1) cout << x << ' ' << 1 << endl;// 一個數最多有一個大於sqrt(n)的質因子,因為若是有兩個那麼乘積就大於n了
cout << endl;
}
樸素篩法求素數
時間複雜度O(nlog(log(n)))近似O(n)
int primes[N], cnt; // primes[]儲存所有素數
bool st[N]; // st[x]儲存x是否被篩掉
void get_primes(int n){
for (int i = 2; i <= n; i ++ ){
if (st[i]) continue;
primes[cnt ++ ] = i;
for (int j = i + i; j <= n; j += i) // 只需要以素數篩就可以,因為前面的素數會將後面的合數篩掉
st[j] = true;
}
}
線性篩法求素數
原理: n只會被它的最小質因子篩掉 時間複雜度 O(n)
int primes[N], cnt; // primes[]儲存所有素數
bool st[N]; // st[x]儲存x是否被篩掉
void get_primes(int n){
for (int i = 2; i <= n; i ++ ){
if (!st[i]) primes[cnt ++ ] = i;
// 用已經篩出的素數去篩,保證了每次都是最小質因子篩掉合數
/*
primes[j]<=n/i是合理的, 因為j永遠小於i, 即primes已存的素數都是小於i的
1、當 i 是合數, 那麼一定在下面的break出去, 因為一定有最小質因子。
2、當 i 是質數, 如果不從primes[j] <= n / i退出,那一定在下面break退出(因為總會j++到primes[j] == i時)
*/
for (int j = 0; primes[j] <= n / i; j ++ ){
st[primes[j] * i] = true; //在下面註釋
if (i % primes[j] == 0) break; // 只能被自己最小質因子篩掉
}
}
}
註釋:
- 若i % primes[j] == 0 那麼primes[j] 一定是 i 的最小質因子,此時i可以直接被篩掉,且primes[j] * i 的最小質因子也是primes[j]。
- 若i % primes[j] != 0 說明前面篩出的素數都不是i最小質因子,但primes[j] * i 的最小質因子也是 primes[j]。
- 總之,primes[j] * i 的最小質因子始終是 primes[j] 對應程式碼 st[primes[j] * i] = true;
試除法求所有約數
時間複雜度為O(logn)
vector<int> get_divisors(int x){
vector<int> res;
for (int i = 1; i <= x / i; i ++ )
if (x % i == 0){
res.push_back(i);
if (i != x / i) res.push_back(x / i);
}
sort(res.begin(), res.end());
return res;
}
約數個數和約數之和
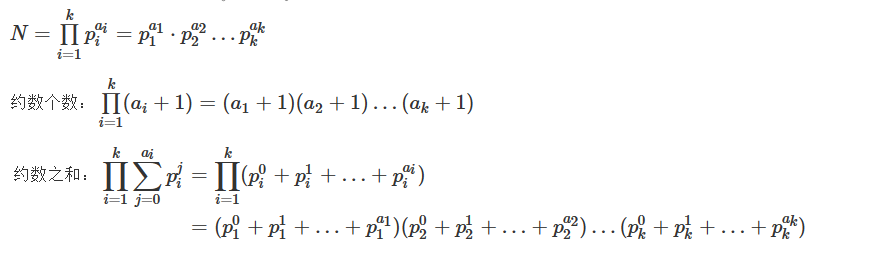
如果 N = p1^c1 * p2^c2 * ... *pk^ck // p為質因子
約數個數:(c1 + 1) * (c2 + 1) * ... * (ck + 1) // 組合數
// 按照組合數選數, 展開的每一項就是約數, 總和就是約數之和
約數之和:(p1^0 + p1^1 + ... + p1^c1) * ... * (pk^0 + pk^1 + ... + pk^ck)
const int N = 110;
const int mod = 1e9+7;
int main(){
int n; cin >> n;
unordered_map<int, int> primes;
while (n --){
int x; cin >> x;
for (int i = 2; i <= x / i; i ++){
while (x % i == 0){
primes[i] ++;
x /= i;
}
}
if (x > 1) primes[x] ++;
}
LL res = 1;
// 約數個數
for (auto prime:primes)res = res * (prime.second + 1) % mod;
cout << res << endl;
res = 1;
// 約數之和
for (auto prime:primes){
int p = prime.first,k = prime.second;
LL t = 1;
while (k --) t = (t * p + 1) % mod; // 這裡要取模所以用等比數列前n項和不合適
res = res * t % mod;
}
cout << res << endl;
return 0;
}
歐幾里得演演算法
假設d為任意兩個數的最大公約數
- 定理: 若d|a 和 d|b, 即d|ax + by
|: 整除的意思 ↔ d|a a整除b裴蜀定理: 對於任意正整數a, b, 一定存在非零整數x, y, 使得ax + by = (a, b) 即a, b組合的最小的正整數為a和b的最大公約數。 - 推理: a mod b = a - a / b * b = a - c * b
令c = a / b - 論證: (b, a % b) == (b, a - c * b) 由(1)得 d|(a - c * b) 和 d|b 得d|(a- c * b + c * b),即d|a,
所以(b, a % b) == (a, b)(a,b)即a和b最大公約數 - 結論: (a, b) == (a, a % b)
int gcd(int a, int b){ // (a,b) == (a, a % b) 遞迴下去, 即求最大公約數 遞迴結束條件 b == 0
return b ? gcd(b, a % b) : a;// b不等於0, 返回gcd(b, a % b), 否者返回a, 因為a和0的最大公約數為a
}
尤拉函數
-
極性函數證明

-
容斥原理證明


程式碼如下
int phi(int x){
int res = x;
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0){
res = res / i * (i - 1); // res / i * (i - 1) == res * (1 - 1 / i);
while (x % i == 0) x /= i;
}
if (x > 1) res = res / x * (x - 1);
return res;
}
篩法求尤拉篩
int primes[N], cnt; // primes[]儲存所有素數
int euler[N]; // 儲存每個數的尤拉函數
bool st[N]; // st[x]儲存x是否被篩掉
void get_eulers(int n){
euler[1] = 1; // 定義的
for (int i = 2; i <= n; i ++ ){
if (!st[i]){
primes[cnt ++ ] = i;
euler[i] = i - 1; // 質數的尤拉值為 i - 1
}
for (int j = 0; primes[j] <= n / i; j ++ ){
int t = primes[j] * i;
st[t] = true;
if (i % primes[j] == 0){ // primes[j] 是 i的最小質因子
/*
phi[i] = i*(1-1/p1)*(1-1/p2)*...*(1-1/pk),且primes[j]是i的質因子,
所以phi[t] = primes[j]*i*(1-1/p1)*(1-1/p2)*...*(1-1/pk) = primes[j]*phi[i]
*/
euler[t] = euler[i] * primes[j];
break;
}
/*
解釋一:
i 不能整除 primes[j], 那麼 i 就和 primes[j] 互質, 根據積性函數得 φ(t) = φ(i) * φ(primes[j])
解釋二:
i 不能整除 primes[j], 但是primes[j]仍是t的最小質因子, 因此不僅需要將基數N修正為primes[j]倍, 還需要 補上1 - 1 / primes[j]這一項, 因此最終結果phi[i] * (primes[j] - 1)
*/
euler[t] = euler[i] * (primes[j] - 1);
}
}
}
快速冪
求 m^k mod p,時間複雜度 O(log(k))
原理: 預處理m的1,2,4,8,16....次方,進行k的二進位制規律進行組合相乘
int qmi(int m, int k, int p){
int res = 1 % p, t = m;
while (k){ // k次, k轉成二進位制
if (k&1) res = res * t % p; // 每次看末位是否為1,為1則進行累乘
t = t * t % p;
k >>= 1;
}
return res;
}
快速冪求逆元(p質數)
≡ : 同餘
a / b ≡ a * x (mod p)
兩邊同乘b可得 a ≡ a * b * x (mod p)
即 1 ≡ b * x (mod p)
同 b * x ≡ 1 (mod p)
由費馬小定理可知,當p為質數時
b(p-1) ≡ 1 (mod p)
拆一個b出來可得 b * b(p-2) ≡ 1 (mod p)
故當n為質數時,b的乘法逆元 x = b(p-2)
LL qmi(int m, int k, int p){
LL res = 1 % p, t = m;
while (k){
if (k&1) res = res * t % p;
t = t * t % p;
k >>= 1;
}
return res;
}
int main(){
int n;
scanf("%d", &n);
while (n -- ){
int a, p;
scanf("%d%d", &a, &p);
if (a % p == 0) puts("impossible"); // 質數只和自己的倍數不互質
else printf("%lld\n", qmi(a, p - 2, p));
}
return 0;
}
擴充套件歐幾里得演演算法
證明1:

寫法一
int exgcd(int a, int b, int &x, int &y){//返回gcd(a,b) 並求出解(參照帶回)
if(b==0){
x = 1, y = 0;
return a;
}
int x1,y1,gcd;
gcd = exgcd(b, a%b, x1, y1);
x = y1, y = x1 - a/b*y1; // 遞迴回溯回時記錄答案
return gcd;
}
寫法二
// 求x, y,使得ax + by = gcd(a, b)
int exgcd(int a, int b, int &x, int &y){
if (!b){
x = 1; y = 0; // 當 b = 0時, a和b的最大公約數為 a, 係數為 x = 1, y = 0;
return a;
}
int d = exgcd(b, a % b, y, x);
y -= (a / b) * x; // y = y' - a/b * x' y'和x'都是回溯上層的結果
return d;
}
線性同餘方程
求同餘方程ax ≡ b(mod m)的係數 x
推理: ax ≡ b(mod m)↔(ax % m = b % m),知存在yk使得 ax = myk + b,得ax - myk = b,令 y = -yk,即 ax + my = b。ax + my = b有解的必要條件是gcd(a, m)|b。設求出ax0 + my0 = gcd(a,m) ,即得 x = b / gcd(a,m) * x0 = b * x0 / gcd(a, m)
while (n -- ){
int a, b, m;
scanf("%d%d%d", &a, &b, &m);
int x, y;
int d = exgcd(a, m, x, y);
if (b % d) puts("impossible"); // 說明b不能整除gcd(a, m)
else printf("%d\n", (LL)b * x / d % m); // 題目要求在int範圍內,且(a*x)%m = (a*(x%m))%m, 所以最後需要%m
}
擴充套件歐幾里得求逆元(p非質數)
求ax ≡ 1 (mod p)的x,根據線性同餘方程等價求ax + py = 1的x
while (n--) {
cin >> a >> p;
if (exgcd(a, p, x, y) == 1) cout << (x + p) % p << endl;
else cout << "impossible" << endl;//如果 exgcd(a,p,x,y) != 1, 說明ax+py=1無解, 因為1只能整除1
}
高斯消元
// a[N][N]是增廣矩陣
int gauss(){
int c, r;
for (c = 0, r = 0; c < n; c ++ ){
int t = r;
for (int i = r; i < n; i ++ )//找到絕對值最大的行,尋找最大的數值是因為可以避免係數變得太大,精度較高.
if (fabs(a[i][c]) > fabs(a[t][c]))
t = i;
if (fabs(a[t][c]) < eps) continue;
for (int i = c; i <= n; i ++ ) swap(a[t][i], a[r][i]); // 將絕對值最大的行換到最頂端 r
for (int i = n; i >= c; i -- ) a[r][i] /= a[r][c]; // 將當前行的首位變成 1
for (int i = r + 1; i < n; i ++ ) // 用當前行將下面所有的列消成 0
if (fabs(a[i][c]) > eps)
for (int j = n; j >= c; j -- )
a[i][j] -= a[r][j] * a[i][c];
r ++ ;
}
if (r < n){
for (int i = r; i < n; i ++ )
if (fabs(a[i][n]) > eps) // 最後一列有非零則無解
return 2; // 無解
return 1; // 有無窮多組解
}
for (int i = n - 1; i >= 0; i -- )
for (int j = i + 1; j < n; j ++ )
a[i][n] -= a[i][j] & a[j][n]; // 回解每個未知數
return 0; // 有唯一解
}
遞推法求組合數
\(C_{m}^{n}\) = \(C_{m-1}^{n}\) + \(C_{m-1}^{n-1}\) : m個數選n個,可分為兩種情況,某數x,① 確定選 x 再在m-1箇中選n-1個,即\(C_{m-1}^{n-1}\)② 確定不選 x 再在m-1箇中選n個\(C_{m-1}^{n}\)
資料範圍: 10000次詢問,1 <= b <= a <= 2000
// c[a][b] 表示從a個蘋果中選b個的方案數
for (int i = 0; i < N; i ++ )
for (int j = 0; j <= i; j ++ )
if (!j) c[i][j] = 1; // c[i][0] = 1;
else c[i][j] = (c[i - 1][j] + c[i - 1][j - 1]) % mod;
預處理逆元的方式求組合數
首先預處理出所有階乘取模的餘數fact[N],以及所有階乘取模的逆元infact[N]
如果取模的數是質數,可以用費馬小定理求逆元
資料範圍: 10000次詢問,1 <= b <= a <= 105
int qmi(int a, int k, int p){ // 快速冪模板
int res = 1;
while (k){
if (k & 1) res = (LL)res * a % p;
a = (LL)a * a % p;
k >>= 1;
}
return res;
}
// 預處理階乘的餘數和階乘逆元的餘數
fact[0] = infact[0] = 1;
for (int i = 1; i < N; i ++ ){
fact[i] = (LL)fact[i - 1] * i % mod;
infact[i] = (LL)infact[i - 1] * qmi(i, mod - 2, mod) % mod;
}
Lucas定理求組合數
若p是質數,則對於任意整數 1 <= m <= n,有: \(C_{m}^{n}\) = \(C_{m\%p}^{n\%p}\) * \(C_{m/p}^{n/p}\) (mod p)
資料範圍: 20次詢問,1 <= b <= a <= 1018,1 <= p <= 105
int qmi(int a, int k, int p){ // 快速冪模板
int res = 1 % p;
while (k){
if (k & 1) res = (LL)res * a % p;
a = (LL)a * a % p;
k >>= 1;
}
return res;
}
int C(int a, int b, int p){ // 通過定理求組合數C(a, b)
if (a < b) return 0;
LL x = 1, y = 1; // x是分子,y是分母
for (int i = a, j = 1; j <= b; i --, j ++ ){
x = (LL)x * i % p;
y = (LL) y * j % p;
}
return x * (LL)qmi(y, p - 2, p) % p;
}
int lucas(LL a, LL b, int p){
if (a < p && b < p) return C(a, b, p);
return (LL)C(a % p, b % p, p) * lucas(a / p, b / p, p) % p;
}
分解質因數法求組合數
當我們需要求出組合數的真實值,而非對某個數的餘數時,分解質因數的方式比較好用:
-
篩法求出範圍內的所有質數
-
通過 C(a, b) = a! / b! / (a - b)! 這個公式求出每個質因子的次數。 \(\lfloor {n \over p} \rfloor\) + \(\lfloor {n \over p^{2}} \rfloor\) + \(\lfloor {n \over p^{3}} \rfloor\) + ... \(\lfloor {n \over p^{k}(p^{k}\leqslant n)} \rfloor\)
n*(n-1)*(n-2)*...2*1 中 p 的次數: p為質因子
- \({n \over p}\) 代表 1 - n 中 p倍數的數位個數 1p,2p,3p,...xp \({\leqslant}\) n 這個x=\({n \over p}\)
- \({n \over p^{2}}\) 代表1 - n/p 中 p倍數的數位個數1p,2p,...mp\({\leqslant}\) n/p 其中m=\({n \over p^{2}}\)
- .....
- \({n \over p^{k}}\) 代表1 - n/pk-1 中 p倍數的數位個數1p,2p,3p,....,kp\({\leqslant}\) n/pk-1 其中k=\({n \over p^{k}}\) (迴圈結束條件: pk+1 > n)
- 所以 n! 中p的次數是 \(\lfloor {n \over p} \rfloor\) + \(\lfloor {n \over p^{2}} \rfloor\) + \(\lfloor {n \over p^{3}} \rfloor\) + ... \(\lfloor {n \over p^{k}(p^{k}\leqslant n)} \rfloor\)
-
用高精度乘法將所有質因子相乘
// 線性篩求素數
int primes[N], cnt;
int sum[N];
bool st[N];
void get_primes(int n){
for (int i = 2; i <= n; i ++ ){
if (!st[i]) primes[cnt ++ ] = i;
for (int j = 0; primes[j] <= n / i; j ++ ){
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
// 求n!中的次數(核心程式碼)
int get(int n, int p){
int res = 0;
while (n){
res += n / p; // 累計一次p的數量
n /= p; // 增加一次方
}
return res;
}
// 高精度乘低精度模板
vector<int> mul(vector<int> a, int b){
vector<int> c;
int t = 0;
for (int i = 0; i < a.size(); i ++ ){
t += a[i] * b;
c.push_back(t % 10);
t /= 10;
}
while (t){
c.push_back(t % 10);
t /= 10;
}
return c;
}
/*************************************************************************/
get_primes(a); // 預處理範圍內的所有質數
for (int i = 0; i < cnt; i ++ ){// 求每個質因數的次數
int p = primes[i];
sum[i] = get(a, p) - get(b, p) - get(a - b, p); // 分子的p次數 減去 分母p的次數
}
// 剩餘的質因子相乘(高精度乘低精度)
vector<int> res;
res.push_back(1);
for (int i = 0; i < cnt; i ++ ) // 用高精度乘法將所有質因子相乘
for (int j = 0; j < sum[i]; j ++ )
res = mul(res, primes[i]);
卡特蘭數(組合數)
給定n個0和n個1,它們按照某種順序排成長度為2n的序列,滿足任意字首中0的個數都不少於1的個數的序列的數量為:Cat(n) = \(C_{2n}^{n} \over n + 1\)
將01序列置於座標系中,起點定於原點。若0表示向右走,1表示向上走,那麼任何字首中0的個數不少於1的個數就轉化為,路徑上的任意一點,橫座標大於等於縱座標。題目所求即為這樣的合法路徑數量。
下圖中,表示從(0,0)走到(n, n)的路徑,在綠線及以下表示合法,若觸碰紅線即不合法。
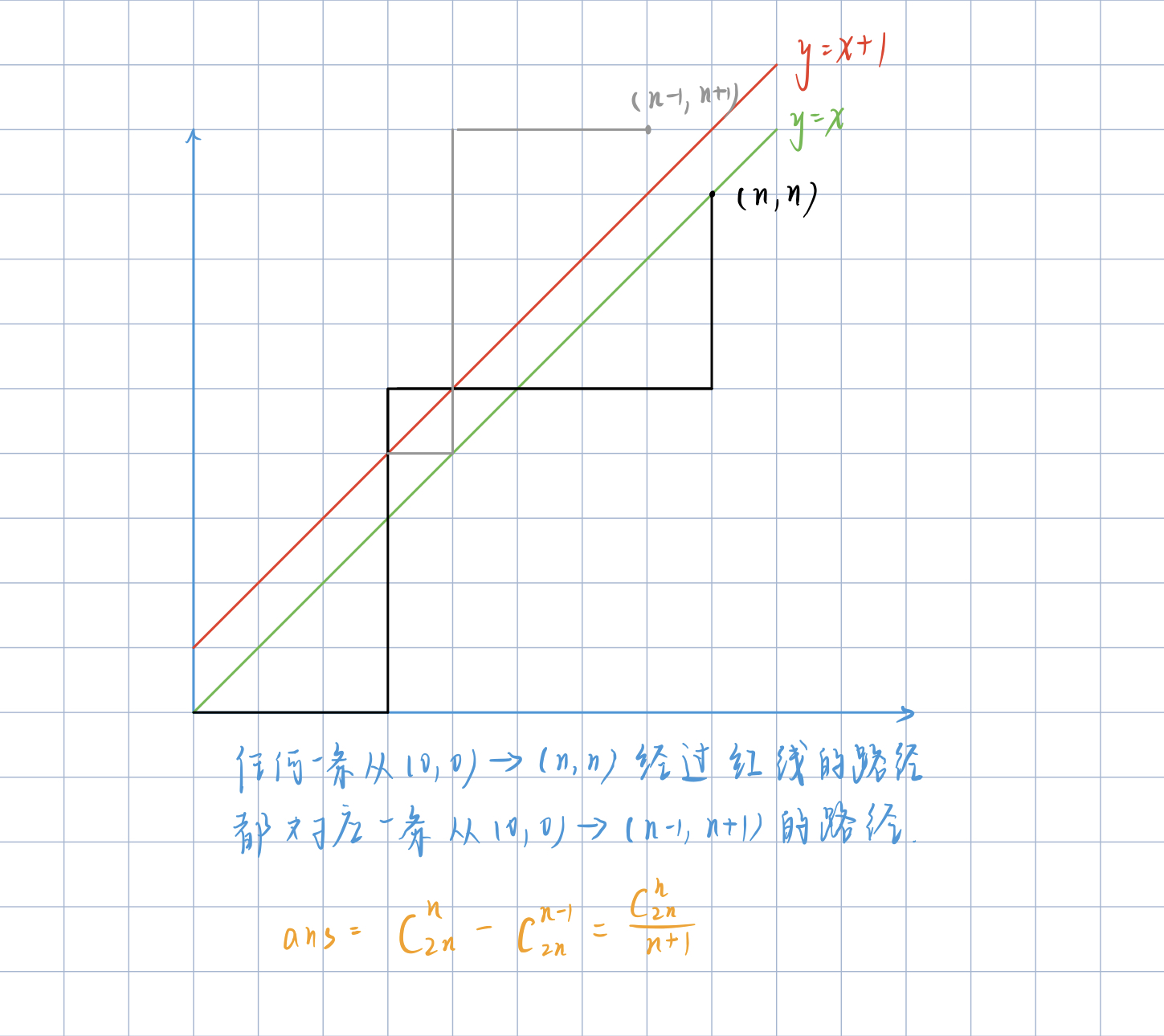
由圖可知,任何一條不合法的路徑(如黑色路徑),都對應一條從(0,0)走到(n - 1,n + 1)的一條路徑(如灰色路徑)。而任何一條(0,0)走到(n - 1,n+1)的路徑,也對應了一條從(0,0)走到(n,n)的不合法路徑。
結論: 所有(0,0)到(n,n)且不經過紅線的路線即為答案,所有經歷紅線併到達(n,n)的路線數 等價於 所有從(0,0)到(n-1,n+1)路線數,因為(0,0)到(n-1,n+1)一定經歷紅線。
證明: \(C_{2n}^{n}\) - \(C_{2n}^{n-1}\) = \(C_{2n}^{n} \over n + 1\)
\(C_{2n}^{n}\) - \(C_{2n}^{n-1}\) = \((2n)! \over n! n!\) - \((2n)! \over (n-1)!(n+1)!\) = \((2n)!(n+1) - (2n)!n\over (n+1)!n!\) = \((2n)! \over (n+1)!n!\) = \(1 \over n+1\)\((2n)!\over n!n!\) = \(C_{2n}^{n} \over n + 1\)
int a = n * 2, b = n;
int res = 1;
// 2n!/(n+1)!n! = 2n*(2n-1)*...*(2n-n+1)/(n+1)!
for (int i = a; i > a - b; i -- ) res = (LL)res * i % mod; // 2n*(2n-1)*...*(2n-n+1)
for (int i = 1; i <= b + 1; i ++ ) res = (LL)res * qmi(i, mod - 2, mod) % mod; // res*((n+1)!的逆元)
cout << res << endl;
容斥原理

應用: 能被整除的數
給定一個整數n和m個不同的質數p1,p2,... ,pm,請你求出1~n中能被p1,p2,...,pm中的至少一個數整除的整數有多少個。
解題思路:

實現思路:

// 二進位制列舉
#include <iostream>
using namespace std;
typedef long long LL;
const int N = 20;
int p[N], n, m;
int main() {
cin >> n >> m;
for(int i = 0; i < m; i ++) cin >> p[i];
int res = 0;
//列舉從1 到 1111...(m個1)的每一個集合狀態, (至少選中一個集合)
for(int i = 1; i < 1 << m; i ++) {
int t = 1; //選中集合對應質數的乘積
int s = 0; //選中的集合數量
//列舉當前狀態的每一位
for(int j = 0; j < m; j ++){
//選中一個集合
if(i >> j & 1){
if((LL)t * p[j] > n){
t = -1;
break;//乘積大於n, 則n / t = 0, 跳出這輪迴圈
}
s++; //有一個1, 集合數量+1
t *= p[j];
}
}
if(t == -1) continue;
if(s & 1) res += n / t; //選中奇數個集合, 則係數應該是1, n/t為當前這種狀態的集合數量
else res -= n / t; //反之則為 -1
}
cout << res << endl;
return 0;
}
博弈論-NIM遊戲
經典NIM遊戲


for(int i = 0; i < n; i++) {
int x;
scanf("%d", &x);
res ^= x;
}
if(res) puts("Yes");
else puts("No");
NIM遊戲拓展
題目描述: 現在,有一個n級臺階的樓梯,每級臺階上都有若干個石子,其中第 i 級臺階上有 a 個石子(i ≥ 1)。兩位玩家輪流操作,每次操作可以從任意一級臺階上拿若干個石子放到下一級臺階中(不能不拿)。已經拿到地面上的石子不能再拿,最後無法進行操作的人視為失敗。問如果兩人都採用最優策略,先手是否必勝。
最優策略:
- 把所有奇數臺階看做經典NIM遊戲,若是所有奇數臺階互斥或和為0,則必敗,否者先手將奇數臺階拿走若干石子到下一臺階(偶數臺階),把所有奇數臺階的互斥或和恢復為 0 。
- 將經典NIM遊戲中的拿走某堆中若干,看做兩種情況,① 拿奇數臺階到下一臺階(偶數臺階),就相當於NIM遊戲中拿走某堆中若干 ② 拿偶數臺階到下一臺階(奇數臺階),那後手就將拿過去的都拿到下一臺階(偶數),那麼奇數臺階又恢復互斥或為0的狀態。
- 為什麼不用偶數臺階計算?因為最後都落到0號臺階且不能再移動,0號臺階是偶數臺階。
int f = 0;
for (int i = 1,x; i <= n; i++){
cin >> x;
if(i%2)f^=x;
}
if (f)puts("Yes");
else puts("No");
博弈論-SG函數
例子: 若干堆石子,每一次只能拿2, 5個,其他規則和NIM遊戲相同
SG函數過程:
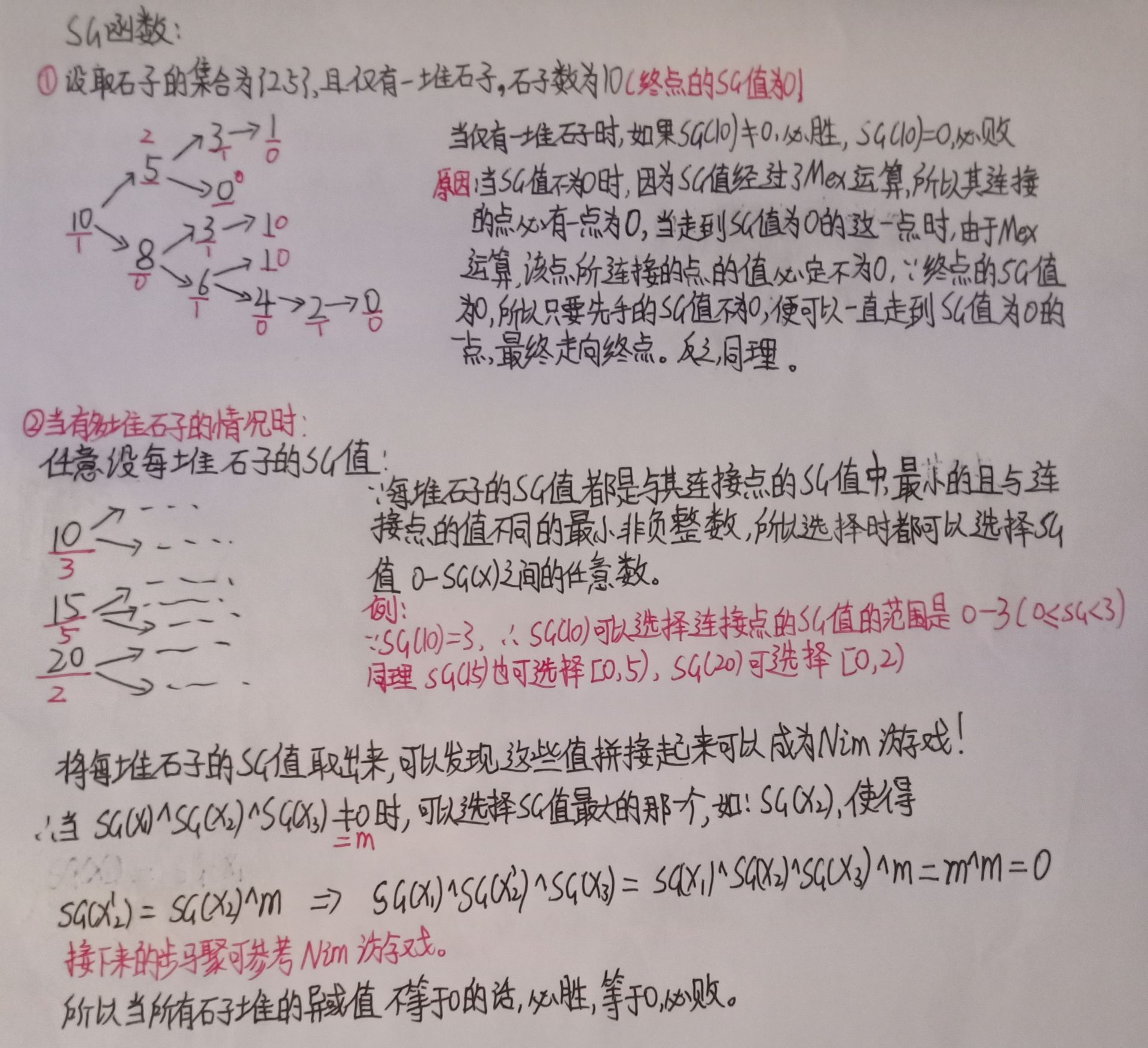
結合程式碼重點理解Mex運算,以及SG函數如何利用Mex運算

應用一: 集合-Nim遊戲
給定n堆石子以及一個由k個不同正整數構成的數位集合S。
現在有兩位玩家輪流操作,每次操作可以從任意一堆石子中拿取石子,每次拿取的石子數量必須包含於集合S,最後無法進行操作的人視為失敗。
問如果兩人都採用最優策略,先手是否必勝。
#include <iostream>
#include <cstring>
#include <algorithm>
#include <unordered_set>
using namespace std;
const int N=110,M=10010;
int n,m;
int f[M],s[N];//s儲存的是可供選擇的集合,f儲存的是所有可能出現過的情況的sg值
int sg(int x){
if(f[x] != -1) return f[x];// 如果此sg值出現過就不再重複計算
unordered_set<int> S; // set代表的是有序集合,記錄所有子節點的sg值
for(int i = 0;i < m;i ++){
int sum = s[i];
if(x >= sum) S.insert(sg(x - sum));// 當x大於sum是才可以"拿"遞迴下去
}
/*************************************重點Mex運算***************************************
迴圈完之後可以進行選出最小的沒有出現的自然數的操作,這裡就保證了sg值可以像Nim遊戲一樣,
Nim遊戲中可以拿任意數量,sg(x)節點可以走到小於它的任何節點,這是一個有向圖
***************************************************************************************/
for(int i=0;;i++)
if(!S.count(i)) return f[x] = i;
}
int main(){
cin >> m;
for (int i = 0;i < m;i ++)
cin >> s[i];
cin >> n;
memset(f,-1,sizeof(f));//初始化f均為-1,方便在sg函數中檢視x是否被記錄過
int res = 0;
for (int i = 0;i < n; i++){
int x;
cin >> x;
res ^= sg(x);//觀察互斥或值的變化,基本原理與Nim遊戲相同
}
if(res) printf("Yes");
else printf("No");
return 0;
}
應用二: 拆分-Nim遊戲
題目描述:
給定n堆石子,兩位玩家輪流操作,每次操作可以拿走其中的一堆石子,然後重新放置兩堆規模更小的石子(新堆規模可以為0,且兩個新堆的石子總數可以大於取走的那堆石子數),最後無法進行操作的人視為失敗。
問如果兩人都採用最優策略,先手是否必勝。加黑解釋: 新的兩堆,不是以原來的石子分的,是重新放的兩堆石子,只是要求這兩堆每一堆都小於原來那堆的數量。
題目分析:
相比於集合-Nim,這裡的每一堆可以變成小於原來那堆的任意大小的兩堆,即ai可以拆分成(bi, bj),為了避免重複規定bi >= bj,
相當於一個局面拆分成了兩個局面,由SG函數理論,多個獨立局面的SG值,等於這些局面SG值的互斥或和。因此需要儲存的狀態就是sg(bi)^sg(bj) (與集合-Nim的唯一區別)
int f[N];
unordered_set<int> S;
/*****************************為什麼可以把 S 定義成全域性變數********************************
因為這個sg函數的特殊性, 求sg(100)時, 它會將1-100的所有sg(1)-sg(100)都計算出來,
當 x <= 100 的都會直接return f[x]; 當x > 100 的會因為sg是遞迴性質, 因此會按順序求出sg(101),
sg(102),...,sg(x), 所以把S設定成全域性變數更好.
**************************************************************************************/
int sg(int x){
if(f[x] != -1) return f[x];
for(int i = 0 ; i < x ; i++)
for(int j = 0 ; j <= i ; j++)//規定j不大於i,避免重複
//相當於一個局面拆分成了兩個局面,由SG函數理論,多個獨立局面的SG值,等於這些局面SG值的互斥或和
S.insert(sg(i) ^ sg(j));
for(int i = 0 ; ; i++)
if(!S.count(i))
return f[x] = i;
}
動態規劃-模型
揹包問題
01揹包
每件物品只能選一次,在不超過體積 j 的前提下可以選擇的最大價值
樸素版
int v[N],w[M];
int f[N][N]; // 在1-i中選出體積不超過j的最大價值
for (int i = 1; i <= n; i ++){
for (int j = 0; j <= m; j ++){
f[i][j] = f[i - 1][j]; // 不選第i個物品: 只從1-i-1中選, 且體積不超過j
if (j > v[i]) f[i][j] = max(f[i][j],f[i - 1][j - v[i]] + w[i]); // 選第i個物品: f[i - 1][j - v[i]] + w[i]
}
}
cout << f[n][m] << endl;
優化版
int v[N],w[M];
int f[N];
for (int i = 1; i <= n; i ++){
for (int j = m; j >= v[i]; j --) // 倒著迴圈保證f[j-v[i]]是上一輪的資料沒有被覆蓋
/*
1. 本輪沒選第i個物品 f[i - 1][j] == f[j]
2. 本輪選第i個物品 f[i - 1][j - v[i]] + w[i] == f[j - v[i]] + w[i]
3. 兩者取max
*/
f[j] = max(f[j], f[j - v[i]] + w[i]);
}
cout << f[m] << endl;
完全揹包
每件物品可以被選無數個,在不超過體積 j 的前提下可以選擇的最大價值
樸素版
int v[N],w[M];
int f[N][N]; // 在1-i中選出體積不超過j的最大價值
for (int i = 1; i <= n; i ++)
for (int j = 0; j <= m; j ++)
for (int k = 0; k * v[i] <= j; k ++)
f[i][j] = max(f[i][j], f[i - 1][j - k * v[i]] + k * w[i]);
cout << f[n][m] << endl;
優化版1
int v[N],w[M];
int f[N][N]; // 在1-i中選出體積不超過j的最大價值
for (int i = 1; i <= n; i ++)
for (int j = 0; j <= m; j ++){
/*
f[i][j] = max{f[i-1][j],f[i-1][j-v]+w,f[i-1][j-2*v]+2*w,f[i-1][j-3*v]+3*w,...}
f[i][j-v] = max{ f[i-1][j-v] ,f[i-1][j-2*v]+ w,f[i-1][j-3*v]+2*w,...}
所以 f[i][j] = max{f[i-1][j],f[i][j-v]+w}
*/
f[i][j] = f[i - 1][j];
if (j >= v[i]) f[i][j] = max(f[i][j], f[i][j - v[i]] + w[i]);
}
cout << f[n][m] << endl;
優化版2
int v[N],w[M];
int [N]; // 在1-i中選出體積不超過j的最大價值
for (int i = 1; i <= n; i ++)
for (int j = v[i]; j <= m; j ++){ // 和01揹包唯一的區別就是迴圈的順序
/*
1. f[i][j] = f[i - 1][j]; == f[j] = f[j]
2. f[i][j] = max(f[j], f[i][j - v[i]] + w[i]); == f[j] = max(f[j], f[j - v[i]] + w[i])
3. 迴圈不用倒著是因為f[i][j - v[i]]就是需要本層已經更新過的, 因此不用擔心覆蓋問題
*/
f[j] = max(f[j], f[j - v[i]] + w[i]);
}
cout << f[m] << endl;
多重揹包
每件物品可以被選xi個,在不超過體積 j 的前提下可以選擇的最大價值
樸素版 時間複雜度O(n*m*s)
int v[N], w[N], s[N];
int f[N][N];
for (int i = 1; i <= n; i ++)
for (int j = 0; j <= m; j ++)
for (int k = 0; k <= s[i] && k * v[i] <= j; k ++)
f[i][j] = max(f[i][j], f[i - 1][j - k * v[i]] + k * w[i]);
cout << f[m] << endl;
為什麼不用完全揹包優化的方法優化多重揹包?

優化版 時間複雜度O(n*m*log(s)) 利用二進位制將多重揹包優化成01揹包
例子: x = 200 = 1 + 2 + 4 + 8 + 16 + 32 + 64 + 73,且200以內所有的數都可以用這些陣列和表示
// N = 1000*log(2,2000)
int n,m,cnt;
int v[N],w[N];
int f[N];
for (int i = 0; i < n; i ++){
int a, b, s; cin >> a >> b >> s;
int k = 1;
while (k <= s){
cnt ++;
v[cnt] = a * k;
w[cnt] = b * k;
s -= k;
k *= 2;
}
if (s > 0){
v[++ cnt] = a * s;
v[cnt] = b * s;
}
}
for (int i = 1; i <= cnt; i ++)
for (int j = m; j >= v[i]; j --)
f[j] = max(f[j], f[j - v[i]] + w[i]);
cout << f[m] << endl;
分組揹包
每組有多種物品,每種物品只有一個,每組只能選一個,,在不超過體積 j 的前提下可以選擇的最大價值
多重揹包是每組選幾個,而分組揹包是每組選哪個。
f[i][j] = max{f[i - 1][j], f[i - 1][j - ki] + w[i][ki]} 類似01揹包
int n,m;
int v[N][N],w[N][N];
int f[N],s[N];
for (int i = 1; i <= n; i ++)
for (int j = m; j > 0; j --)
for (int k = 1; k <= s[i]; k ++)
if (v[i][k] <= j) f[j] = max(f[j], f[j - v[i][k]] + w[i][k]);
cout << f[m] << endl;
PS: 第三重回圈和第二重回圈是不可以換位子的,因為第二重回圈是從m開始的,為了避免覆蓋上層,而不能使用上層。如果換位置,f[j] 就會迴圈s[i]次導致上層資料被覆蓋。但是如果是沒有進行一維優化的話,用二維i,j,k就可以交換位置了,那樣就不會覆蓋上層資料。
線性DP
數位三角形
for (int i = n - 1; i >= 1; i --)
for (int j = 1; j <= i; j ++)
a[i][j] += max(a[i + 1][j], a[i + 1][j + 1]);
cout << a[1][1] << endl;
最長上升子序列
資料範圍 1 <= N <= 1000
int n,a[1010],f[1010],g[1010]; // g[i] 記錄 f[i] 是從哪個狀態轉移過來的, 最後可以倒著推出序列是什麼
for(int i = 1; i <= n; i ++){
f[i] = 1;
g[i] = 0; // 以i為起點的最長子序列
for(int j = 1; j < i; j ++)
if(a[j] < a[i] && f[i] < f[j] + 1){
f[i] = f[j] + 1; // 若是a[j] < a[i] 那麼以i結尾的最長子序列長度 = f[j] + 1
g[i] = j;
}
}
int ans = 0;
for(int i = 1; i <= n; i ++) ans = max(ans, f[i]);
cout << ans << endl;
資料範圍 1 <= N <= 100000
/************************** DP ----> 貪心 **************************
q陣列下標: 代表最長子序列長度
q陣列的值: 記錄下標len的子序列最後一個數的最小值
因為q陣列的定義可知,所以q[len]一定小於q[len+1],因此陣列q具有單調遞增性質,
可以利用二分找到第一個大於a[i]的值, q[i + 1] = a[i]
*******************************************************************/
int n,a[N],q[N];
int len = 0;
for (int i = 0; i < n; i ++ ){
int l = 0, r = len;
while (l < r){
int mid = l + r + 1 >> 1;
if (q[mid] < a[i]) l = mid;
else r = mid - 1;
}
len = max(len, r + 1);
q[r + 1] = a[i];
}
printf("%d\n", len);
最長公共子序列
閆式DP分析
- 狀態表示f[i, j]
① 集合: 所有在第一個序列的前i個字母出現,且在第二個序列的前j個字母出現的子序列
② 屬性: Max - 狀態計算: f[i, j] 分為4種狀態 00(i不選, j不選),01(i不選, j選),10(i選, j不選),11(i選, j選)
00: 這個狀態好表示 f[i, j] = f[i - 1, j - 1]
01: 這個狀態表示為 f[i, j] = f[i - 1, j]
10: 這個狀態通過為 f[i, j] = f[i, j - 1]
11: 這個狀態好表示 f[i, j] = f[i - 1, j - 1] + 1 - 通過對f[i, j]的定義,可以發現f[i - 1, j - 1] 這種狀態屬於 f[i - 1, j] 和 f[i, j - 1] 這兩種狀態中。
int n, m;
char a[N], b[N];
int f[N][N];
scanf("%s%s", a + 1, b + 1);
for (int i = 1; i <= n; i ++) // 雙重回圈--二維dp
for (int j = 1; j <= m; j ++){
f[i][j] = max(f[i - 1][j], f[i][j - 1]);
if (a[i] == b[j]) f[i][j] = max(f[i][j], f[i - 1][j - 1] + 1);
}
cout << f[n][m] << endl;
/*
acbd
abedc
*/
最短編輯距離
題意: 兩個字串a, b,有三種操作: 增,刪,改。問最少的操作次數使得字串a變成b
- 狀態表示 f[i, j]
- 集合: 所有將a[1~i]變成b[1~j]的操作方式
- 屬性: Min
- 狀態計算
- 刪除: f[i - 1, j] + 1 要保證a[0,i - 1] 和 b[0,j] 相等的條件下
- 增加: f[i, j - 1] + 1 要保證a[0,i] 和 b[0,j - 1] 相等的條件下
- 修改: f[i - 1, j - 1] + 1不同 or 0相同 要保證 a[0,i - 1] 和 b[0,j - 1] 相等的條件下
int f[N][N];
char a[N],b[N];
scanf("%s%s", a + 1, b + 1);
// 初始化
for(int i = 0; i <= m; i ++)f[0][i] = i; // a[0,0] 到 b[0,i] 需要新增操作i次
for(int i = 0; i <= n; i ++)f[i][0] = i; // a[0,i] 到 b[0,0] 需要刪除操作i次
for(int i = 1; i <= n; i ++){
for(int j = 1; j <= m; j ++){
if(a[i] != b[j]) f[i][j] = f[i - 1][j - 1] + 1; // a[i] == b[i] 修改 +1
else f[i][j] = f[i - 1][j - 1]; // 修改
f[i][j] = min(f[i][j], min(f[i - 1][j] + 1,f[i][j - 1] + 1)); // 比較三種情況選出最小值
}
}
cout << f[n][m] << endl;
區間DP-石子合併
-
題意: 合併 N 堆石子,每次只能合併相鄰的兩堆石子,求最小代價
-
解題思路:
關鍵點: 最後一次合併一定是左邊連續區間和右邊連續區間進行合併
-
狀態表示: f[i][j] 表示將 i 到 j 這一區間的石子合併成一個區間的集合,屬性時Min
-
狀態計算:
f[i][j] = min{f[i][ki] + f[ki + 1][j] + s[j] - s[i - 1]} (i ≤ ki ≤ j - 1) 至少 ki 把[i, j]分成兩個區間
-
int s[N];
int f[N][N];
for (int i = 1; i <= n; i ++ ) s[i] += s[i - 1]; // 字首和
for (int len = 2; len <= n; len ++ ) // 列舉區間長度
for (int i = 1; i + len - 1 <= n; i ++ ){
int l = i, r = i + len - 1;
f[l][r] = 1e8;
for (int k = l; k < r; k ++ ) //k ∈ [l, r - 1]
f[l][r] = min(f[l][r], f[l][k] + f[k + 1][r] + s[r] - s[l - 1]);
}
printf("%d\n", f[1][n]);
記憶化搜尋做法
int dp(int i, int j) {
if (i == j) return 0; // 判斷邊界
int &v = f[i][j];
if (v != -1) return v;// 減枝避免重複計算,因為下面迴圈會出現區間重疊
v = 1e8;
for (int k = i; k < j; k ++)
v = min(v, dp(i, k) + dp(k + 1, j) + s[j] - s[i - 1]);
return v;
}
memset(f, -1, sizeof f);
cout << dp(1, n) << endl;
區間DP常用模板
for (int len = 1; len <= n; len ++) { // 區間長度
for (int i = 1; i + len - 1 <= n; i ++) { // 列舉起點
int j = i + len - 1; // 區間終點
if (len == 1) {
dp[i][j] = 初始值
continue;
}
for (int k = i; k < j; k ++) { // 列舉分割點,構造狀態轉移方程
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k + 1][j] + w[i][j]);
}
}
}
計數類DP-整數劃分
問題描述: 一個正整數n可以表示成若干個正整數之和,形如:n = n1 + n2 + … + nk,其中 n1 ≥ n2 ≥ … ≥ nk, k≥1,我們將這樣的一種表示稱為正整數 n 的一種劃分,現在給定一個正整數n,請你求出n共有多少種不同的劃分方法
方法一
/***************************利用完全揹包的推理***********************
f[i][j]: 表示前i個整數(1,2…,i)恰好拼成j的方案數
f[i][j] = f[i-1][j]+f[i-1][j-i]+f[i-1][j-i*2]...f[i-1][j-i*s] i*s <= j < i*(s+1)
f[i][j-i] = f[i-1][j-i]+f[i-1][j-i*2]...f[i-1][j-i*s]
得出轉移方程 f[i][j] = f[i-1][j]+f[i][j-i]
優化維度 f[j] = f[j]+f[j-i]
******************************************************************/
int f[N];
f[0] = 1; //總和為0的方案數,也就是f[i][0]前i個整數(1,2…,i)恰好拼成0的方案數,只有一種就是一個都不選
for (int i = 1; i <= n; i ++)
for (int j = i; j <= n; j ++)
f[j] = (f[j] + f[j - i]) % mod;
cout << f[n] << endl;
方法二
/*********************計數DP****************************
f[i][j]表示和為i,恰好選j個數的方案數
劃分為兩種情況
1.最小值為1 那把為1的情況去掉 就是f[i-1][j-1]這種情況的方案數
2.最小值大於1 那把i個數都減去1 就是f[i-j][j] 這個情況的方案數
轉移方程: f[i][j] = f[i-1][j-1] + f[i-j][j]
ans = f[n][1] + f[n][2] + ... + f[n][n]
*******************************************************/
int f[N][N];
f[1][1] = 1; //初始化源頭
for (int i = 2; i <= n; i ++)
for (int j = 1; j <= i; j ++)
f[i][j] = (f[i - 1][j - 1] + f[i - j][j]) % mod;
int res = 0;
for (int i = 1; i <= n; i++)res = (res + f[n][i]) % mod; //列舉每種情況相加
cout << res << endl;
數位統計DP-計數問題
題目描述:
給定兩個整數 a 和 b,求 a 和 b 之間的所有數位中0~9的出現次數。
例如,a=1024,b = 1032,則a和b之間共有9個數如下:
1024 1025 1026 1027 1028 1029 1030 1031 1032
其中0出現10次,1出現10次,2出現7次,3出現3次等等...
演演算法思想: 字首和,數位dp
例如 n = abcdefg 求 0 ~ n 中x出現的次數,記作count(n, x),核心思想是計算x在abcdefg上每一位出現的次數之和
計算x在數位'd'這個位置出現的次數
-
① 'abc'位置是[000, abc - 1] 此時ans += abc*10^3
② 當x = 0時要特判,因為多算了000x這種情況,所以ans -= 10^3
-
'abc'位置是abc時
- ③ d < x 時,那麼abcxefg就大於abcdefg,此時不符合條件不計入ans
- ④ d = x 時,那麼efg就是所求x在數位d所在位置的次數 ans += efg+1 (000 ~ efg)
- ⑤ d > x 時,那麼efg所在的位置可以填任何數位, ans += 1000 (000 ~ 999)
最後將x在n的每一位上計算的次數相加,就是0~n中x出現的次數
所以求 a~b之間的x出現的次數,利用字首和原理,即等於求0~b出現x的次數減去0~a-1出現x的次數: ans = count(b, x) - count(a - 1, x)
int get(vector<int> num, int l, int r){ // 計算num[l],num[l+1],...,num[r]十進位制數
int res = 0;
for (int i = l; i >= r; i --) res = res * 10 + num[i];
return res;
}
int power10(int x){ // 計算10^x
int res = 1;
while (x -- ) res *= 10;
return res;
}
int count(int n, int x){ // 計算0~n中x出現的次數
if (!n) return 0;
vector<int> num; // 把n的每一位拆分放進num陣列中
while (n){
num.push_back(n % 10);
n /= 10;
}
n = num.size();
int res = 0;
for (int i = n - 1 - !x; i >= 0; i --){
if (i < n - 1){ // 計算i的字首是0 ~ (abc-1)
res += get(num, n - 1, i + 1) * power10(i); //① 0~(abc-1)數量等於abc res+="字首數量"*power10(i)
if (!x) res -= power10(i); //② 如果x是0, 那麼就會多數一種情況000xefg, 即多加一個 power10(i)
}
if (num[i] == x) res += get(num, i - 1, 0) + 1; //④ 字首是abc且d = x
else if (num[i] > x) res += power10(i); //⑤ 字首是abc且d > x
}
return res;
}
int main(){
int a, b;
while (cin >> a >> b , a){
if (a > b) swap(a, b);
for (int i = 0; i <= 9; i ++)
cout << count(b, i) - count(a - 1, i) << ' ';
cout << endl;
}
return 0;
}
狀態壓縮DP
蒙德里安的猜想-DP
題意: n x m的棋盤可以擺放不同的1 × 2小方格的種類數。
題目分析:
- 擺放方塊的時候,先放橫著的,再放豎著的。總方案數等於只放橫著的小方塊的合法方案數。
- 如何判斷,當前方案數是否合法? 所有剩餘位置能否填充滿豎著的小方塊。可以按列來看,每一列內部所有連續的空著的小方塊需要是偶數個。
- 這是一道動態規劃的題目,並且是一道狀態壓縮的dp: 用一個N位的二進位制數,每一位表示一個物品,0/1表示不同的狀態。因此可以用0 →2N -1中的所有數來列舉列全部的狀態。
狀態表示: f[i][j]表示已經將前i-1列擺好,且從第i-1列,伸出到第i列的狀態是j的所有方案。其中j是一個二進位制數,用來表示第i-1列轉化成第i列的狀態(j對應二進位制中的1表示從i-1列橫著放一個方塊,0表示從i-1類到i列沒變化),其位數和棋盤的行數一致。
狀態轉移: f[i][j] += f[i - 1][ki] (0 ≤ ki ≤ 2n-1) 表示第i列的狀態j的方案數等於所有符合條件的第i-1列的狀態ki之和。其中狀態ki 表示第i-2列轉化到第i-1列的狀態,狀態j表示第i-1列轉化到第i列的狀態
typedef long long LL;
const int N = 12, M = 1 << N;
int n, m;
LL f[N][M];// 第一維表示列, 第二維表示所有可能的狀態
vector<int> state[M];
bool st[M];//儲存每種狀態是否有奇數個連續的0, 如果奇數個0是無效狀態, 如果是偶數個零置為true
int main(){
while (cin >> n >> m, n || m){
// 預處理(一): 預處理出[0,1<<n]中每個數的n位中連續0的數量是否為偶數 1 表示伸出 0 表示不伸出
for (int i = 0; i < 1 << n; i ++ ){
int cnt = 0;
bool is_valid = true;
for (int j = 0; j < n; j ++ )
if (i >> j & 1){
if (cnt & 1){
is_valid = false;
break;
}
cnt = 0; // 這一步可以不寫, 因為上面if不滿足的話, cnt一定是偶數
}
else cnt ++ ;
if (cnt & 1) is_valid = false;
st[i] = is_valid;
}
// 預處理(二): 預處理出f[k-1,i]到f[k,j]狀態轉移的所有合法方案, 此時屬於減少不必要的列舉
for (int i = 0; i < 1 << n; i ++ ){
state[i].clear();
for (int j = 0; j < 1 << n; j ++ )
/*
i & j == 1 說明i和j的n位上有同時為1的情況, 這是不允許的, 若是i的某位為1,
說明在那個位置有從i的前一種狀態伸出, 那麼此時就不能在這個位置填一個塊伸出到j對應位置
st[i|j]==true 標明在i轉換成j狀態後,i中剩餘連續的0是否符合偶數,因為剩下的0要填豎著的方塊
例如i='10101' j='01000' i|j=='11101' 這個就是不符合條件的, 即i不能轉化為j, 排除
*/
if ((i & j) == 0 && st[i | j])
state[i].push_back(j);
}
memset(f, 0, sizeof f);
f[0][0] = 1;
/*******************************為什麼f[0][0] = 1**********************************
1. 題目中輸入引數的列數是從1開始到m,即範圍為1~m,但我們寫的時候是將其先對映到陣列0~m-1裡
2. 對於第一列,也就是陣列中的第0列,是需要初始化的;也就是我們需要初始化f[0][x] = ?回到定義,
f[0][x] 表示從-1列伸到0列(此處說的都是陣列下標)狀態為x的方案。
3. 我們發現,合法的方案只能是不伸過來,因為根本沒有-1列。即x只能取0的時候方案合法,f[0][0] = 1;
接著dp過程就從第1列(陣列下標)開始。
4. 那麼答案為什麼是f[m][0] 呢,因為橫放的時候方塊最多夠到第m-1列(陣列下標),不能從m-1再往外伸,
所以是f[m][0];
**********************************************************************************/
for (int i = 1; i <= m; i ++ )
for (int j = 0; j < 1 << n; j ++ )
for (auto k : state[j])
f[i][j] += f[i - 1][k]; // 列舉所有符合從i-1的k狀態且能成功轉化i的j狀態, 並累加
cout << f[m][0] << endl;
}
return 0;
}
蒙德里安的猜想-記憶化搜尋
定義狀態: dp[i][j]表示前i - 1列的方格都已完全覆蓋,第i列方格被第i - 1列伸出的方塊覆蓋後狀態為j的所有方案數。
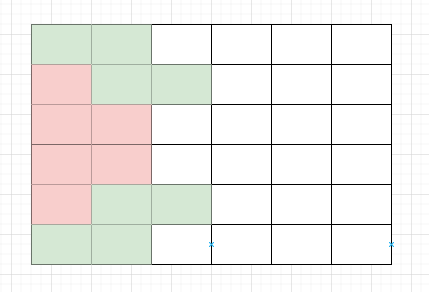
例如,上圖表示的就是dp[3][010010]的狀態(紅色為2 * 1方塊,綠色為1 * 2方塊) 0 表示沒有覆蓋,1 表示覆蓋。
狀態轉移:
我們採用由底至上的遞推方式,即由當前狀態推出下一列狀態的方案數。
以某一列的狀態而言
- 【情況一】如果當前行的格子已被上一列伸出的方塊覆蓋,則跳過
- 【情況二】如果當前行的格子未被覆蓋,說明可以放一個1 * 2的方塊
- 【情況三】如果當前行的格子和下一行的格子都未被覆蓋,說明可以放一個2 * 1的方塊
- 【總結】此列所有行的格子都覆蓋完後,我們便可以得出下一列的合法狀態
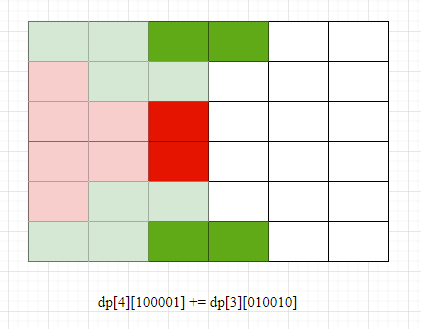
如上圖,我們對第3列的狀態進行搜尋後可到達的其中一種狀態
為什麼要搜尋?
根據dp陣列的定義可知,第一列不可能被上一列伸出的方塊覆蓋,所以初始化為dp[1][000] = 1,搜尋下一列可得:
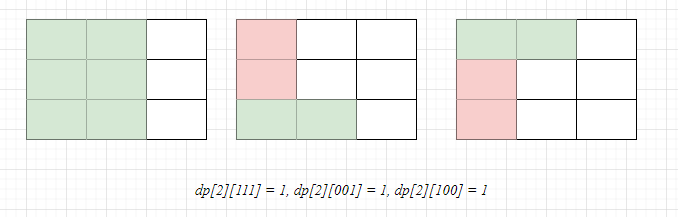
可知第二列可到達的狀態只有3種,於是進行第三列的搜尋時只需從這3種狀態開始dfs,當前階段總是影響下一階段,我們只對可到達的進行討論,並不需要列舉每一種情況。
時間複雜度:
- 外層迴圈時間: m * (1<<n) = 11*2^11
- 遞迴時間: 最壞情況是一個不滿的二元樹 20+21+22+...+210 = (211 - 1)
- 總時間 = 外層迴圈時間*遞迴時間 ≈ 10 * 211 * 211 = 46137344 ≈ 4e7
int n, m;
long long dp[12][2500];
void dfs(int row, int col, int state, int next) {
//row為當前行, col為當前列, state為當前列的狀態, next為可到達的下一列的狀態
//當前列全覆蓋後可到達的下一個狀態加上當前狀態的方案數
if (row == n) {
//當前列所有行都已覆蓋完畢
dp[col + 1][next] += dp[col][state];
return;
}
//情況一: 如果當前行(state二進位制中第row位等於1)的格子已被覆蓋,跳過
if (state & (1 << row)) dfs(row + 1, col, state, next);
else {
//當前行未被覆蓋,可放一個1*2的方塊
dfs(row + 1, col, state, next | (1 << row));// 情況二
//當前行和下一行都未被覆蓋,可放一個2*1的方塊
if (row + 1 < n && (state & (1 << (row + 1))) == 0) dfs(row + 2, col, state, next);// 情況三
}
}
int main() {
while (scanf("%d%d", &n, &m) && n && m) {
if (n > m) swap(n, m);
//因為n行m列和n列m行的方案數等價, 所以我們不妨將min(n, m)作為二進位制列舉的指數, 減少方案數
memset(dp, 0, sizeof(dp));
dp[0][0] = 1;
for (int i = 0; i < m; i++) {
for (int j = 0; j < (1 << n); j ++) {
if (dp[i][j] > 0) { //篩選出之前搜尋過可到達的狀態
dfs(0, i, j, 0);
}
}
}
//因為下標從0開始,所以dp[m][0]表示第m + 1列沒有任何第m列的方塊伸出的方案數
cout << dp[m][0] << endl;
}
return 0;
}
最短Hamilton路徑
題目描述: 給定一張n個點的帶權無向圖,點從0 ~ n-1標號,求起點0到終點n-1的最短Hamilton路徑。Hamilton路徑的定義是從0到n-1不重不漏地經過每個點恰好一次。
狀態表示: f[i][j]
- 集合: 所有從0走到j,走過的所有點是i的所有路徑
- 屬性: Min
狀態計算: 0→...→k→j f[ i ][ j ] = min(f[ i ][ j ], f[ i - (1 << j) ][ ki ] + w[ ki ][ j ])
int f[M][N],w[N][N];
int main(){
cin >> n;
for (int i = 0; i < n; i ++)
for (int j = 0; j < n; j ++)
cin >> w[i][j];
memset(f, 0x3f, sizeof f); // 初始化費用最大值
f[1][0] = 0; // 0 到 0 路徑只有 0 的費用是 0
//for (int i = 0; i < 1 << n; i ++)
for (int i = 1; i < 1 << n; i += 2) //優化: 0001 + 10 = 0011 因為第0位始終只有是1才是合法的, 所以+2是符合條件的
for (int j = 0; j < n; j ++)
if (i >> j & 1) // i的第j位二進位制是否為1
for (int k = 0; k < n; k ++) // 節點j的前一個路徑節點k
if(i - (1 << j) >> k & 1) // i - 1 << j 的第k位是否為1
f[i][j] = min(f[i][j], f[i - (1 << j)][k] + w[k][j]);
cout << f[(1 << n) - 1][n - 1] << endl; // f[11...11][n - 1]是答案
return 0;
}
樹形DP-沒有上司的舞會
題目描述: Ural大學有N名職員,編號為1~N。他們的關係就像─棵以校長為根的樹,父節點就是子節點的直接上司。每個職員有一個快樂指數,用整數Hi給出,其中1≤i≤N。現在要召開一場週年慶宴會,不過,沒有職員願意和直接上司一起參會。在滿足這個條件的前提下,主辦方希望邀請一部分職員參會,使得所有參會職員的快樂指數總和最大,求這個最大值。
狀態表示: f[u][0],f[u][1]
- 集合: f[u][0]表示以u為根節點且u不參加的快樂指數最大值,f[u][1]表示以u為根節點且u參加的快樂指數最大值
- 屬性: Max
狀態計算: f[u][0] += max(f[ui][0], f[ui][1]),f[u][1] += f[ui][0]
最後的結果ans = max(f[u, 0], f[u, 1]])
void dfs(int u){
f[u][0] = 0; // 不加當前結點
f[u][1] = a[u]; // 加上當前結點
for(int i = h[u]; i != -1; i = ne[i]){
int j = e[i];
dfs(j); // 一直遞迴到最深處
f[u][0] += max(f[j][0], f[j][1]); // 不加當前結點,那麼他的子結點就可以選或者不選
f[u][1] += f[j][0]; // 加上當前結點,那麼他的子結點只能不選
}
}
for(int i = 1; i <= n; i++) if(!ru[i]) root = i; // 找出根節點
dfs(root);
printf("%d\n", max(f[root][0], f[root][1]));
記憶化搜尋
題目描述: 一張n*m的圖,圖上每一個點都有一個高度,a點走到b點的要求是a點高度要大於b點高度,求某個點可以走的最大步數。
5 5
1 2 3 4 5
16 17 18 19 6
15 24 25 20 7
14 23 22 21 8
13 12 11 10 9
如上圖最大的步數是從25走,螺旋路線,最遠走到1,一共25步
int n, m;
int g[N][N],f[N][N];
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
int dp(int x, int y){
int &v = f[x][y];
if (v != -1) return v;
v = 1; // 最次也可以走一步
for (int i = 0; i < 4; i ++ ){
int a = x + dx[i], b = y + dy[i];
if (a >= 1 && a <= n && b >= 1 && b <= m && g[x][y] > g[a][b])
v = max(v, dp(a, b) + 1);
}
return v;
}
memset(f, -1, sizeof f);
int res = 0;
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= m; j ++ )
res = max(res, dp(i, j));
printf("%d\n", res);
貪心-思想
區間問題
區間選點
題目描述: 給定N個閉區間[ai,bi],請你在數軸上選擇儘量少的點,使得每個區間內至少包含一個選出的點。輸出選擇的點的最小數量。位於區間端點上的點也算作區間內。
struct Range{
int l, r;
bool operator< (const Range &W)const{
return r < W.r;
}
}range[N];
sort(range, range + n);
int res = 0, ed = -2e9;
for (int i = 0; i < n; i ++ )
if (range[i].l > ed){
res ++ ;
ed = range[i].r;
}
printf("%d\n", res);
最大不相交區間數量
題目描述: 給定N個閉區間[ai,bi],請你在數軸上選擇若干區間,使得選中的區間之間互不相交(包括端點)。輸出可選取區間的最大數量。
計算方法和區間選點一模一樣。
struct Range{
int l, r;
bool operator< (const Range &W)const{
return r < W.r;
}
}range[N];
sort(range, range + n);
int res = 0, ed = -2e9;
for (int i = 0; i < n; i ++ )
if (range[i].l > ed){
res ++ ;
ed = range[i].r;
}
printf("%d\n", res);
區間分組
題目描述: 給定N個閉區間[ai,bi],請你將這些區間分成若干組,使得每組內部的區間兩兩之間(包括端點)沒有交集,並使得組數儘可能小。輸出最小組數。
思路:
- 將所有區間按左端點從小到大排序
- 從前往後處理每個區間,判斷能否將其放到某個現有的組中L[i] > Max_r
- 如果不存在這樣的組,則開新組,然後再將其放進去;
- 如果存在這樣的組,將其放進去,並更新當前組的Max_r
sort(range, range + n);
priority_queue<int, vector<int>, greater<int>> heap;// 小根堆裡存在每個組右端點
for (int i = 0; i < n; i ++ ){
auto r = range[i];
if (heap.empty() || heap.top() >= r.l) heap.push(r.r);// 最小的右端點都大於r.l那就需要新開一個組
else{ // 否者就把這個組加入右端點最小的那個組, 並且更新
heap.pop();
heap.push(r.r);
}
}
printf("%d\n", heap.size());
區間覆蓋
題目描述: 給定N個閉區間[ai, bi]以及一個線段區間[s, t],請你選擇儘量少的區間,將指定線段區間完全覆蓋。輸出最少區間數,如果無法完全覆蓋則輸出 -1。
核心思想: 在左端點l都小於等於st的情況下, 取右端點最大的小區間
- 將所有區間按照左端點從小到大進行排序
- 從前往後列舉每個區間,在所有能覆蓋
start的區間中,選擇右端點的最大區間,然後將start更新成右端點的最大值這—步用到了貪心決策
int n;
int st, ed;
struct Range{
int l, r;
bool operator< (const Range &W)const{
return l < W.l;
}
}range[N];
sort(range, range + n);
int res = 0;
bool success = false;
int i = 0;
while (i < n){
int r = -2e9;
/*********************************************************************************
int r = -2e9 不能放在外面
例如:
4 10
2
4 5
11 12 這個樣例不會執行裡面的while,i 不會 ++, 且if (r < st) 永遠不會執行, 就會陷入死迴圈
**********************************************************************************/
while (i < n && range[i].l <= st){ //在左端點l都小於等於st的情況下, 取右端點最大的小區間
r = max(r, range[i].r);
i ++ ;
}
if (r < st){ // 若 r < st 即說明while迴圈結束條件是 i < n, 所以說明所有的區間都不在[st, ed]裡面
res = -1;
break;
}
res ++ ; // 成功找到合適的一個區間預設res ++
if (r >= ed){ // 若 r >= ed 說明已經找到一個合適的區間, 此時退出, 貪心停止
success = true;
break;
}
st = r; // st值設定成當前尋找的符合條件的右端點
}
if (!success) res = -1;
printf("%d\n", res);
Huffman樹-合併果子
priority_queue<int, vector<int>, greater<int>> heap;
while (n --){
int x;
scanf("%d", &x);
heap.push(x);
}
int res = 0;
while (heap.size() > 1){
int a = heap.top(); heap.pop();
int b = heap.top(); heap.pop();
res += a + b;
heap.push(a + b);
}
printf("%d\n", res);
排序不等式-排隊打水
題目描述: 有n 個人排隊到1個水龍頭處打水,第i個人裝滿水桶所需的時間是t,請問如何安排他們的打水順序才能使所有人的等待時間之和最小?
sort(t, t + n);
reverse(t, t + n);
LL res = 0;
for (int i = 0; i < n; i ++ ) res += t[i] * i;
printf("%lld\n", res);
絕對值不等式-貨倉選址
題目描述: 在—條數軸上有N家商店,它們的座標分別為A1~ AN。現在需要在數軸上建立一家貨倉,每天清晨,從貨倉到每家商店都要運送一車商品。為了提高效率,求把貨倉建在何處,可以使得貨倉到每家商店的距離之和最小。
sort(a,a + t);
int ans = 0;
for(int i = 0; i < t; i ++)
/*
1. 當n為奇數時, 站點放在中位數a[t/2]時ans最小
2. 當n為偶數時, 站點放在範圍為a[(t-1)/2]~a[t/2]中任意位置都行,設[a,b]中有一個x,即|a - x| + |b - x| = b - a
3. 所以無論n為奇數還是偶數, ans都是最小
*/
ans += abs(a[i] - a[t/2]);
cout << ans << endl;
/*
1 2 3 4 5 6
4 - 1 + 4 - 2 + 4 - 3 = 6
*/
推公式-耍雜技的牛
題目描述: 農民約翰N頭奶牛(編號為1..N)計劃逃跑並加入馬戲團,為此它們決定練習表演雜技。奶牛們不是非常有創意,只提出了一個雜技表演:
疊羅漢,表演時,奶牛們站在彼此的身上,形成一個高高的垂直堆疊。奶牛們正在試圖找到自己在這個堆疊中應該所處的位置順序。
這N頭奶牛中的每一頭都有著自己的重量Wi以及自己的強壯程度Si。一頭牛支撐不住的可能性取決於它頭上所有牛的總重量(不包括它自己)減去它的身體強壯程度的值,現在稱該數值為風險值,風險值越大,這隻牛撐不住的可能性越高。您的任務是確定奶牛的排序,使得所有奶牛的風險值中的最大值儘可能的小。
貪心思路: 按照wi+si從小到大的順序排,最大的危險係數一定是最小的。
typedef pair<int, int> PII;
const int N = 50010;
int n;
PII cow[N];
int main(){
scanf("%d", &n);
for (int i = 0; i < n; i ++ ){
int s, w;
scanf("%d%d", &w, &s);
cow[i] = {w + s, w};
}
sort(cow, cow + n);
int res = -2e9, sum = 0;
for (int i = 0; i < n; i ++ ){
int s = cow[i].first - cow[i].second, w = cow[i].second;
res = max(res, sum - s);
sum += w;
}
printf("%d\n", res);
return 0;
}