Istio 升級後踩的坑
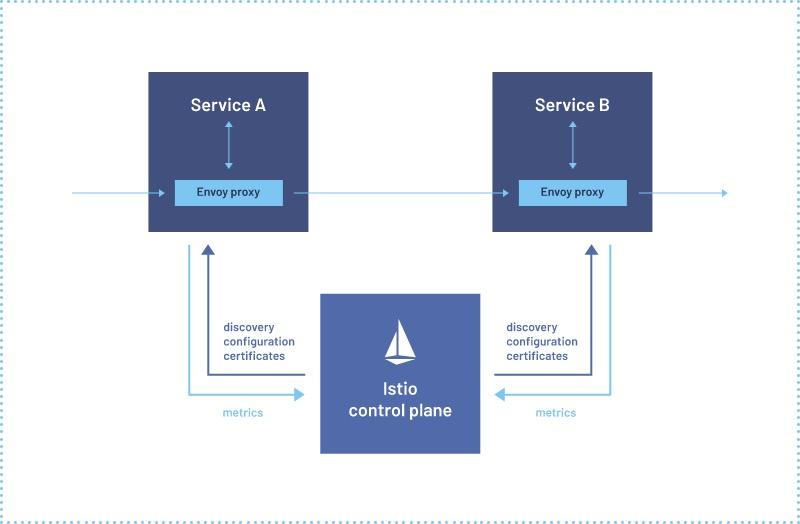
背景
前段時間我們將 istio 版本升級到 1.12 後導致現有的應用監控有部分資料丟失(頁面上顯示不出來)。
- 一個是應用基礎資訊丟失。
- 再一個是應用 JVM 資料丟失。
- 介面維度的監控資料丟失。


修復
基礎資訊
首先是第一個基礎資訊丟失的問題,頁面上其實顯示的是我們的一個聚合指標istio_requests_total:source:rate1m。
聚合後可以將多個指標合併為一個,減少系統壓力
具體可以參考 Istio 的最佳實踐 Observability Best Practices 有詳細說明。
spec:
groups:
- interval: 30s
name: istio.service.source.istio_requests_total
rules:
- expr: |
sum(irate(istio_requests_total{reporter="source"}[1m]))
by (
destination_app,
source_workload_namespace,
response_code,
source_app
)
record: istio_requests_total:source:rate1m
本質上是通過以上四個維度進行統計 istio_requests_total;但在升級之後檢視原始資料發現丟失了 destination_app, source_app 這兩個 tag。
至於為啥丟失,查了許久,最後在升級後的資原始檔 stats-filter-1.12.yaml 中找到了答案:

升級後新增了 tags_to_remove 標記,將我們所需要的兩個 tag 直接刪掉了。
後續在當前 namespace 下重新建一個 EnvoyFilter 資源覆蓋掉預設的便能恢復這兩個 tag,修復後監控頁面也顯示正常了。
EnvoyFilter 是實時生效的,並不需要重建應用 Pod。
JVM 監控
JVM 資料丟失的這個應用,直接進入 Pod 檢視暴露出的 metric,發現資料都有,一切正常。
jvm_memory_pool_bytes_used{pool="Code Cache",} 1.32126784E8
jvm_memory_pool_bytes_used{pool="Metaspace",} 2.74250552E8
jvm_memory_pool_bytes_used{pool="Compressed Class Space",} 3.1766024E7
jvm_memory_pool_bytes_used{pool="G1 Eden Space",} 1.409286144E9
jvm_memory_pool_bytes_used{pool="G1 Survivor Space",} 2.01326592E8
jvm_memory_pool_bytes_used{pool="G1 Old Gen",} 2.583691248E9
說明不是資料來源的問題,那就可能是資料採集節點的問題了。
進入VictoriaMetrics 的 target 頁面發現應用確實已經下線,原來是採集的埠不通導致的。
我們使用 VictoriaMetrics 代替了 Prometheus。

而這個埠 15020 之前並未使用,我們使用的是另外一個自定義埠和端點來採集資料。
經過查閱發現 15020 是 istio 預設的埠:

原來在預設情況下 Istio 會為所有的資料面 Pod 加上:
metadata:
annotations:
prometheus.io/path: /stats/prometheus
prometheus.io/port: "15020"
這個註解用於採集資料,由於我們是自定義的端點,所以需要修改預設行為:

在控制面將 --set meshConfig.enablePrometheusMerge=false 設定為 false,其實官方檔案已經說明,如果不是使用的標準 prometheus.io 註解,需要將這個設定為 false。
修改後需要重建應用 Pod 方能生效。
有了 url 這個 tag 後,介面監控頁也恢復了正常。
介面維度
介面維度的資料丟失和基本資料丟失的原因類似,本質上也是原始資料中缺少了 url 這個 tag,因為我們所聚合的指標使用了 url:
- interval: 30s
name: istio.service.source.url.istio_requests_total
rules:
- expr: |
sum(irate(istio_requests_total{reporter="source"}[1m]))
by (
destination_app,
source_workload_namespace,
response_code,
source_app,
url
)
最終參考了 MetricConfig 自定義了 URL 的tag.
{
"dimensions": {
"url": "request.url_path"
},
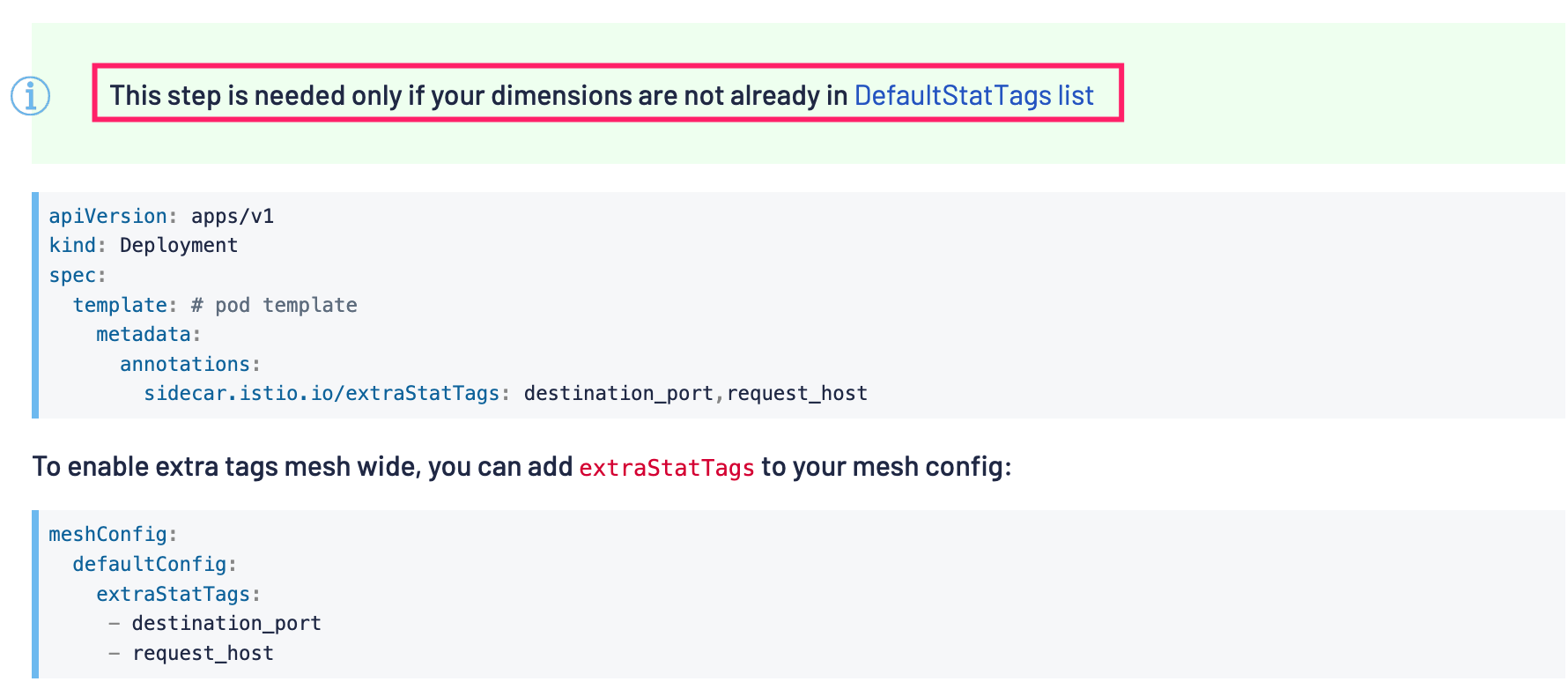
但這也有個大前提,當我們 tag 的指標沒有在預設 tag 列表中時,需要在 Deployment 或者是 Istio 控制面中全域性加入我們自定義的 tag 宣告。
比如這裡新增了 url 的 tag,那麼就需要在控制面中加入:
meshConfig:
defaultConfig:
extraStatTags:
- url
修改了控制面後需要重新構建 Pod 後才會生效。
EnvoyFilter的問題
檢視MetricConfig的設定後發現是可以直接去掉指標以及去掉指標中的 tag ,這個很有用,能夠大大減低指標採集系統 VictoriaMetrics 的系統負載。
於是參考了官方的範例,去掉了一些 tag,同時還去掉了指標:istio_request_messages_total。
{
"tags_to_remove": [
"source_principal",
"source_version",
"destination_principal",
"destination_version",
"source_workload",
"source_cluster",
]
},
{
"name": "istio_request_messages_total",
"drop": true
}
但並沒有生效,於是換成了在 v1.12 中新增的 Telemetry API。
使用 Telemetry API
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: mesh-istio-test
namespace: istio-test
spec:
# no selector specified, applies to all workloads
metrics:
- overrides:
- match:
metric: GRPC_REQUEST_MESSAGES
mode: CLIENT_AND_SERVER
disabled: true
但是參考了官方檔案後發現依然不能生效,GRPC_REQUEST_MESSAGES 所對應的 istio_request_messages_total 指標依然存在。
接著在我領導檢視 Istio 原始碼以及相關 issue 後發現 Telemetry API 和 EnvoyFilter 是不能同時存在的,也就是說會優先使用 EnvoyFilter;這也就是為什麼我之前設定沒有生效的原因。

後初始化 EnvoyFilter
正如這個 issue 中所說,需要刪掉現在所有的 EnvoyFilter;刪除後果然就生效了。
新的 Telemetry API 不但語意更加清晰,功能也一樣沒少,藉助他我們依然可以自定義、刪除指標、tag 等。
apiVersion: telemetry.istio.io/v1alpha1
kind: Telemetry
metadata:
name: mesh-istio-telemetry-test
namespace: test
spec:
metrics:
- overrides:
- match:
metric: GRPC_RESPONSE_MESSAGES
mode: CLIENT_AND_SERVER
disabled: true
- tagOverrides:
url:
value: "request.url_path"
- match:
metric: ALL_METRICS
tagOverrides:
source_workload:
operation: REMOVE
比如以上設定便可以刪除掉 GRPC_RESPONSE_MESSAGES 指標,新增一個 url 的指標,同時在所有指標中刪除了 source_workload 這個 tag。
藉助於這一個宣告檔案便能滿足我們多個需求。
裁剪指標
後續根據我們實際需求借助於 Telemetry API 裁剪掉了許多指標和 tag,使得指標系統負載下降了一半左右。
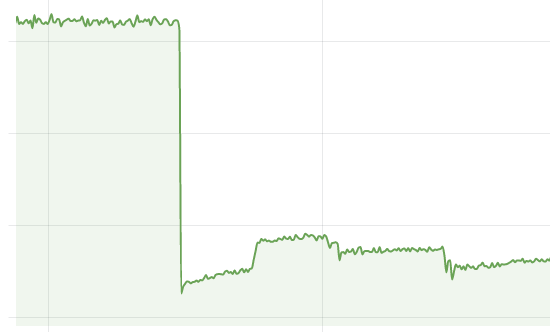
效果相當明顯。
總結
本次定位修復 Istio 升級後帶來的指標系統問題收穫巨大,之前對 Istio 一直只停留在理論階段,只知道他可以實現傳統微服務中對介面粒度的控制,完美彌補了 k8s 只有服務層級的粗粒度控制;
這兩週下來對一個現代雲原生監控系統也有了系統的認識,從 App->Pod->sidecar->VictoriaMetrics(Prometheus)->Grafana 這一套流程中每個環節都可能會出錯;
所以學無止境吧,幸好藉助公司業務場景後續還有更多機會參與實踐。
作者: crossoverJie

歡迎關注博主公眾號與我交流。
本文版權歸作者所有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出, 如有問題, 可郵件(crossoverJie#gmail.com)諮詢。