萬字長文概述單目3D目標檢測演演算法
一,理論基礎-相機與影象
相機將三維世界中的座標點(單位為米)對映到二維影象平面(單位為畫素)的過程能夠用一個幾何模型進行描述,這個模型有很多種,其中最簡單的稱為針孔相機模型。相機的成像過程是也一個射影變換(透視或中心射影)過程,這個過程需要涉及到畫素座標系、平面座標系、相機座標系及世界座標系之間的相互轉換。
1.1,單目相機介紹
只使用一個攝像頭進行 3D 目標檢測的做法稱為單目3D目標檢測,單目相機即單個攝像頭,單目相機結構簡單,成本特別低,單目相機輸出的資料為我們常見的照片。照片本質上是拍照時的場景在相機的成像平面上留下的一個投影,它以二維的形式反映了三維的世界。
攝像機有很多種,但是基本原理是一樣的:把光學影象訊號轉變為電訊號,以便於儲存或者傳輸。單目相機儘管成本低,但是也存在無法直接通過單張圖片來計算場景中物體與我們之間距離的問題。
1.2,針孔相機模型
相機可以抽象為最簡單的形式:一個小孔和一個成像平面,小孔位於成像平面和真實的三維場景之間,任何來自真實世界的光只有通過小孔才能到達成像平面。因此,在成像平面和通過小孔看到的真實三維場景存在著一種對應關係,也就是影象中的二維畫素點和真實三維世界的三維點存在某種變換關係。找到了這種變換關係,就可以利用影象中的二維座標點的資訊來恢復場景的三維資訊。
圖2-2 是針孔相機(小孔成像)模型,為了簡化模型,將成像平面放在了小孔的前面,並且成的像也是正立的。小孔成像實際就是將相機座標系中的三維點變換到成像平面中的影象座標系中的二維點。
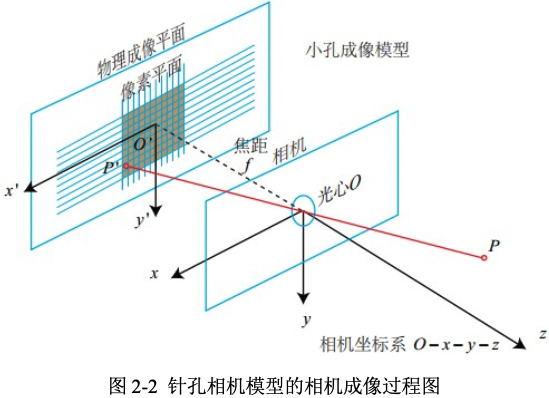
針孔相機模型涉及到四個座標系,分別是世界座標系(world),相機座標系(camera),影象物理座標系(image),畫素座標系(pixel),四個座標系的詳細定義如下:
- 世界座標系(world coordinate)\((x_w, y_w, z_w)\),是一個三維直角座標系,也稱為測量座標系,以其為基準可以表示相機和待測物體的空間3D位置,任意指定 \(x_w\)軸和 \(y_w\)軸。如果是自動駕駛資料集,以百度Apollo為例,其\(Z\) 軸通過車頂垂直於地面指向上方,\(Y\)軸在行駛的方向上指向車輛前方,\(X\)軸為自車面向前方時,指向車輛右側,車輛座標系的原點在車輛後輪軸的中心。
- 相機座標系(camera coordinate)\((x_c, y_c, z_c)\),,其座標原點位於相機的光心位置,\(Z\)軸為相機的光軸,與像平面垂直,\(X_c\)軸和 \(Y_c\)分別平行於投影面即成像影象座標系的 \(X\)軸和 \(Y\)軸。
- 影象物理座標系 \((x', y')\),其座標原點為投影成像平面的中心,\(X\) 軸和 \(Y\) 軸分別平行於成像影象平面的兩條垂直邊,其座標軸的單位為毫米(mm)。
- 畫素座標系 \((uov)\),從小孔向投影面方向看,投影面的左上角頂點為原點軸 \(O_{pix}\) ,\(uv\)分別平行於影象物理座標系的 \(x'\) 軸和 \(y'\) 軸。其座標軸的單位是畫素(整數形式)。
假設世界座標系的空間點 \(P\),經過小孔投影 \(O\)後,落在物理成像平面的投影點為。設 \(P\)的座標為\([X,Y,Z]^T\),\(O'\)為\([X', Y', Z']^T\),物理成像平面到小孔的距離為 \(f\)(焦距)。,根據三角形相似原理,可得以下公式:
式 2-1 描述了現實世界的空間點 \(P\)和成像平面的成像點\(P'\)的空間關係,但是在相機中我們得到的是一個個畫素,需要對平面上的物件進行取樣和量化,之後,才得到成像平面的成像點 \(P'\) 的畫素座標 \([u, v]^T\)。
可以知道,畫素平面與成像平面之間相差了一個縮放和一個原點的平移。假設畫素座標在 \(u\) 軸上縮放了 \(\alpha\) 倍,在\(v\)軸上縮放了 \(\beta\) 倍,並且原點平移了 \(c_x, c_y]^T\)。那麼成像點 \(P'\) 與畫素座標 \([u, v]^T\) 的關係為:

通過以上推導,我們得到了相機座標到畫素座標的轉換公式:(式2-5)。在式(2-5)中,把中間的量組成的矩陣稱為相機的內參矩陣(Camera Intrinsics)\(K\)。相機的內參一般是在出廠之後固定的,之後不再變化。有內參自然有外參,式(2-5)使用的是\(P\)在相機座標系下的座標,因為相機在運動,所以\(P\)的相機座標(記為\(P_c\))是它的世界座標(記為\(P_w\))結合相機當前的位姿轉換到相機座標系下的結果,相機的位姿可以由它的旋轉矩陣\(R\)和平移向量\(t\)來描述的,兩個座標系間的變換稱為歐式變換。
1.3,座標系間的歐式變換
歐式變換是世界座標系到相機座標系的變換。向量的旋轉我們可以用外積表示,與向量的旋轉類似,兩個座標系的旋轉也可以用外積表示,然後再加上平移,則可以統稱為座標系之間的變換[3]。線上性代數中,旋轉矩陣是用於在歐幾里得空間中進行旋轉的矩陣,而描述一個歐式空間的座標變換關係,可以用一個旋轉矩陣 \(R\) 和一個平移向量\(t\)表示,世界座標到相機座標的轉換公式如下。
這裡 \(P_{c}(x_c, y_c, z_c)\)為相機座標系下的座標,\(P_{w}(x_w, y_w, z_w)\)為世界座標系下的座標。式(2-6)的變換關係並不是線性的關係,所以我們要引入齊次座標和變換矩陣方便計算,重寫的公式(2-7)如下。該式中,\(T\)稱為變換矩陣(Transform Matrix)。
1.4,世界座標與畫素座標的轉換
通過前面兩小節,我們推得了相機座標到畫素座標和世界座標到相機座標的變換,則自然可以得到世界座標到畫素座標的變換公式。轉換公式如式(2-8)所示。這裡的變換矩陣 \(T = \begin{bmatrix} R & t \\ 0^T & 1 \end{bmatrix}\),其中 \([R|T]\)為相機外參,\(K\)為相機內參矩陣。
1.5,三維旋轉:尤拉角、旋轉矩陣之間的轉換
在求解目標 3D 中心點的結算模組用到了幾何投影的知識,那裡我們需要用到旋轉矩陣,演演算法只能預測出旋轉角度,但是 3D 世界座標到 2D 畫素座標的轉換(即前文的歐式變換)需要用到相機內參和旋轉矩陣,所以有必要給出尤拉角和旋轉矩陣之間的轉換公式。
尤拉角是由 Lenhard Euler 引入的,用於描述剛體方向的姿態角(旋轉角即物體圍繞座標系三個座標軸旋轉的角度),在 3 維歐幾里得空間中描述一個方向,需要三個引數:\(\left \{\theta,\phi ,\gamma \right \}\),\(\theta\) 是偏航角 yaw,繞 \(Y\) 軸旋轉;\(\phi\) 是偏航角 pitch,繞 \(Z\) 軸旋轉;\(\gamma\) 是偏航角 row,繞 \(X\) 軸旋轉。注意,不同領域叫法不同,\(Y, Z,X\) 和 yaw、pitch、roll 並沒有絕對的對應關係,其中,飛機姿態示意圖如圖2-3所示。
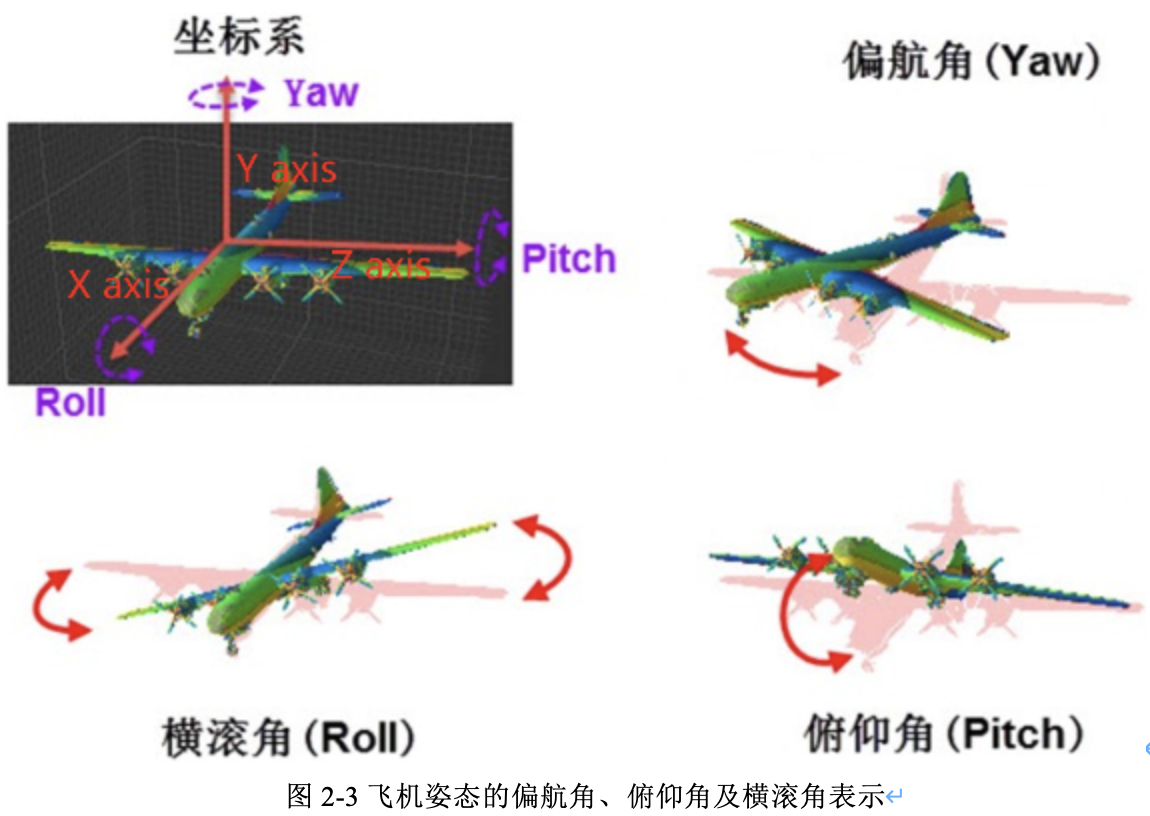
不同的座標系定義,會有不同的旋轉矩陣計算公式,因此需要根據實際情況計算旋轉矩陣和平移矩陣。旋轉矩陣可由尤拉角進行轉換得到,可以知道的是,尤拉角構造旋轉矩陣等同於直接把三個Elemental Rotation Matrix相乘,表示繞軸 \(Y,Z,X\) 順序的尤拉角為 \(\left \{ \theta ,\phi ,\gamma \right \}\) 的外部旋轉矩陣的計算公式(式2-9)[4]如下:

其中:
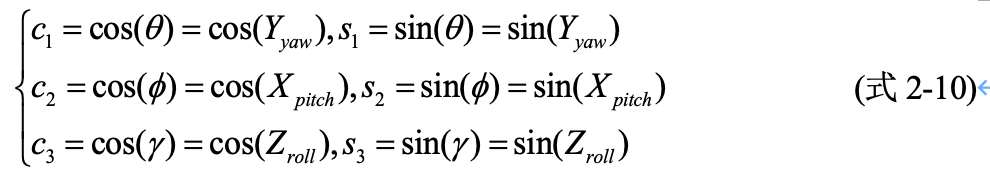
有了根據尤拉角計算旋轉矩陣的公式,在下章的內容中,就可以根據射影幾何原理實現待檢測目標的 3D 世界座標到 2D 畫素座標的轉換。尤拉角可以通過模型預測得到,再根據式(2-10)可以計算得到旋轉矩陣,再根據前面的座標轉換公式,就可以實現2D畫素座標到 3D 世界座標的轉換。
二,單目3D目標檢測概述
2.1,3D目標檢測演演算法介紹
按照感測器和輸入資料的不同, 3D目標檢測分類如圖2-1所示。從圖中可以看出,3D目標檢測的輸入資料以分為影象和點雲資料,分別使用的是鐳射、深度相機和單目相機、雙目相機等硬體。從成本上來說,單目相機是成本最低的,也是工業界迫切需要研究和發展的演演算法。
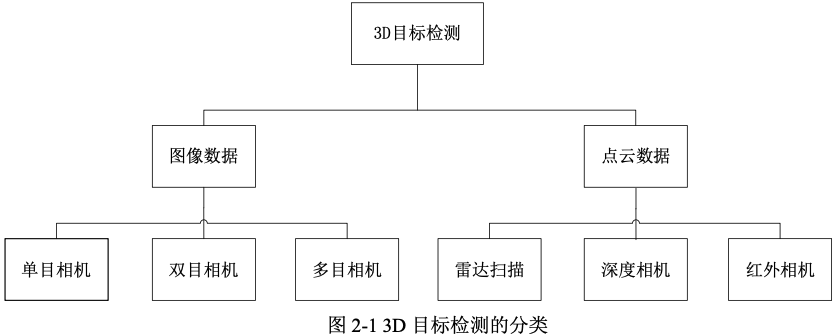
對於從鐳射雷達獲得的 3D 點雲資料,Chen[1]等人通過擴充套件 2D 檢測演演算法提出了一些利用3D 點雲特徵來估計物體 3D 空間位置的方法。相比於使用雷達或者深度相機,使用攝像機的硬體成本更低,但是需要進行影象點的反投影,計算點在空間中的位置。此外,相對於點雲資料,單目相機影象恢復深度的方法可以應用於室外大尺度場景,普通RGB-D深度相機存在視野小、噪聲大、測量範圍窄等問題。
對於單目攝像機的 3D 目標檢測問題,可以採用以深度學習為主的 2D bbox 預測及大小姿態估計網路演演算法+目標 3D 中心點解算模組[2]。因此,如何結合深度學習演演算法和射影幾何約束,是提升演演算法精度的關鍵。下文會介紹幾種單目影象進行 3D 目標檢測演演算法,來說明和討論如何實現基於單目相機影象的 3D 目標檢測。
2.2,單目3D目標檢測演演算法概述
3D 目標檢測主要是為了獲取物體的 3D bbox(bounding box)。3D bbox 的定義是在真實三維世界中包圍目標物體的最小長方體,理論上,一個 3D bbox 有 9 個自由度,3 個是位置,3 個是維度大小,3 個是旋轉角度。3D 目標檢測任務從宏觀上來講可以分為兩個部分:目標定位與目標姿態的描述。
目標定位可以複用 2D 目標檢測框架,對目標進行準確定位;因此在 3D 目標檢測任務中,如何對目標姿態進行準確描述是3D目標檢測演演算法的關鍵問題。對於目標姿態的描述資訊,一些研究工作引入了與2D影象對應的深度資訊圖, 利用2D影象和2D影象對應的深度資訊可以對目標所在空間進行描述,即可在 3D 場景上進行目標檢測。深度資訊即計算 2D 影象中框出的物體上的點在物理世界座標系中距離相機成像平面的距離,對於單目 RGB 影象,可以利用幾何約束(geometry)來求解,比如 Deep3DBox 和 Deep MANTA 演演算法。
在 Deep3DBox 中,已知 2D box、orientation、3D size,利用 3D box 投影到影象上的頂點和 2D box 的邊的對應關係可以求解出物體的 3D 座標。在 Deep MANTA 中,已知 2D keypoints、3D size,首先通過 CAD model 獲得 3D keypoints,然後求解 PnP 就可以得到物體的 3D 座標和 orientation。這類方法的 3D 定位精度本質上受限於重投影誤差,而 keypoints、2D box 的定位精度是有限的,所以目前也可能會存在演演算法瓶頸。
2.3,無人駕駛中的3D目標檢測任務
感知系統是自動駕駛系統的一個核心子系統,而目標檢測 Object Detection 就是感知系統的核心技術,感知系統要求我們根據不同的感測器設計不同的感知演演算法,從而準確的檢測出車輛前方的障礙物。例如在國內百度Apollo自動駕駛系統 中,有為 3D 點雲而設計的CNN-SEG演演算法,和為 2D 影象而設計的 YOLO-3D演演算法等。
常見的2D目標檢測是不適用於無人駕駛的規劃及控制任務的,而 3D 目標檢測可以獲取物體的 3D bbox(真實三維世界中包圍目標物體的最小長方體)。3D 目標檢測系統要求演演算法,能夠對實時視訊流中的單幀影象完成3D目標檢測,在有相機的內參和外參矩陣基礎上,將輸出結果對映到統一的世界座標系或者車身座標系中。
任意一個相機座標系下的目標 3d bbox,可以用 9 個自由度表示,即目標的中心點 \(T = \left \{ x, y, z \right \}\),長寬高 \(D = \left \{l, w, h \right \}\)},以及目標的姿態角(旋轉角)\(\left \{ \theta ,\phi ,\gamma \right \}\)。這種 9 自由度的參數列示與 3d bbox 的 8 個角點座標表示相比,其實是等價的,可以相互轉換,而且不需要的 \(8\times 3 = 24\) 個座標引數來表示,有利於減少複雜度。
同時,對一個相機座標系下 3D 目標,可以通過設定好的相機內參和經過轉換計算得來的外參矩陣,即根據射影幾何約束原理,將3D座標投射到 2D 影象上,得到 目標的2D畫素座標。
2.4,無人駕駛中的3D目標檢測的難點
儘管深入學習技術的應用已經給3D視覺目標檢測帶來了很大發展,但是3D目標檢測依然還有很多痛點問題有待解決,主要難點如下:
- 目標被遮擋,遮擋分為兩種情況,目標物體相互遮擋和目標物體被背景遮擋;
- 影象中存在很多小目標,相對輸入圖片大小,目標物體所佔畫素點極少;
- 目標被截斷,部分物體被圖片截斷,即在圖片中只能顯示部分物體;
- 目標的旋轉角度學習,在影象中物體的朝向不同,但是對應特徵可能相同。
三,主流單目3D檢測演演算法
3.1,Deep3Dbox演演算法介紹
Deep3Dbox 是一種用於在單目 RGB 影象(a single image)上進行 3D 目標檢測和姿態估計(pose estimation)的演演算法。相對於當前僅僅迴歸物體的 3D方向(orientation)的方法,該演演算法使用深度神經網路首次迴歸了目標相對穩定的3D屬性,並結合這些屬性和 2d bounding box 的幾何約束(geometric constraints),生成一個 3D bounding box。主要思想是基於 2D 的目標檢測框去擬合 3D 檢測框,預測量主要有三個:
- 三維框的大小(在\(x,y,z\) 軸上的大小);
- 旋轉角度;
- 置信度。
網路的第一個輸出使用一種新穎的 hybrid(混合)discrete-continuous(離散-連續)loss, (顯著優於 L2 loss)預測 3D 方向(orientation),網路的第二個輸出迴歸了物體的3D尺寸(dimension),相比於之前的模型,它準確度更高且能夠識別多種物體。
3.2,Deep MANTA演演算法介紹
Deep MANTA 演演算法[7]的通過一張圖片完成多項車輛分析任務,包括車輛檢測、區域性定位、視覺化特徵描述以及 3D 估計。基於 coarse-to-fine object proposal 提升車輛檢測效果。並且,Deep MANTA 網路可以檢測出半遮擋的車輛。在推斷過程中,網路的輸出作為一個魯棒的實時位姿估計演演算法的輸入,來進行姿態估計和三維車輛定位。演演算法主要特點有以下幾個方面:
- 演演算法的網路結構是基於
Faster R-CNN框架,網路不僅預測車輛包圍框,同時還預測車輛部件座標、部件可見性、車輛自身尺寸等豐富的資訊,同時使用影象車輛的特徵點座標來編碼車輛的 3D 資訊。 - 網路使用了級聯結構(
cascade)預測以上資訊,在共用底層特徵(feature map)的同時提供足夠的擬合能力預測多種資訊,並反覆迴歸包圍框,提高定位精度。 - 在網路推理(inference)時使用之前預測的資訊進行 2D/3D 匹配,從而得到車輛的 3D 姿態與位置資訊。
3.3,GS3D演演算法介紹
GS3D[5]是基於引導和表面(GS)的 3D 車輛檢測演演算法。該演演算法的基本流程也是先進行 2D 檢測,再通過一些先驗知識和投影幾何原理等計算3Dbbox 的尺寸和方位。該演演算法的重要創新點是充分利用了 3D 表面在 2D 影象的投影特徵,以方面模型進行區分判別。演演算法以單張 RGB 影象作為輸入,由粗略到精細的步驟逐步恢復車輛的 3D bbox。檢測流程如圖 2-4 所示:

3.4,M3D-RPN演演算法介紹
M3D-RPN演演算法[6]的主要思想在於提出將單目3D目標檢測問題重新構造為獨立的3D區域提議網路(RPN,類似Faster R-CNN的RPN網路),即 M3D-RPN 結構(Monocular 3D Region Proposal Network for Object Detection),來提高模型效能,利用2D和3D透檢視的幾何關係,允許3D邊框利用影象空間生成的折積特徵,該思想和Deep3Dbox 演演算法是一樣的,即在於結合投影幾何原理和2D影象特徵,得到目標的3D box。
同時 M3D-RPN 演演算法設計了深度-感知(depth-aware)的折積層,來解決繁瑣的3D引數估計問題,該方法可提取特定位置的特徵,從而改善了3D場景的理解效能。M3D-RPN的簡單架構圖如圖2-5所示,其用全域性折積(橙色)和區域性深度-覺察折積(藍色)的單個單目3D區域提議網路來預測多類3D邊框。
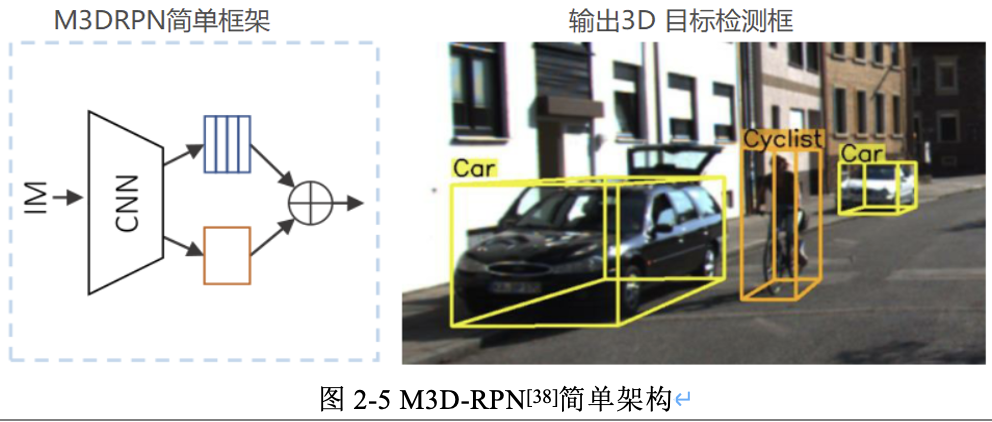
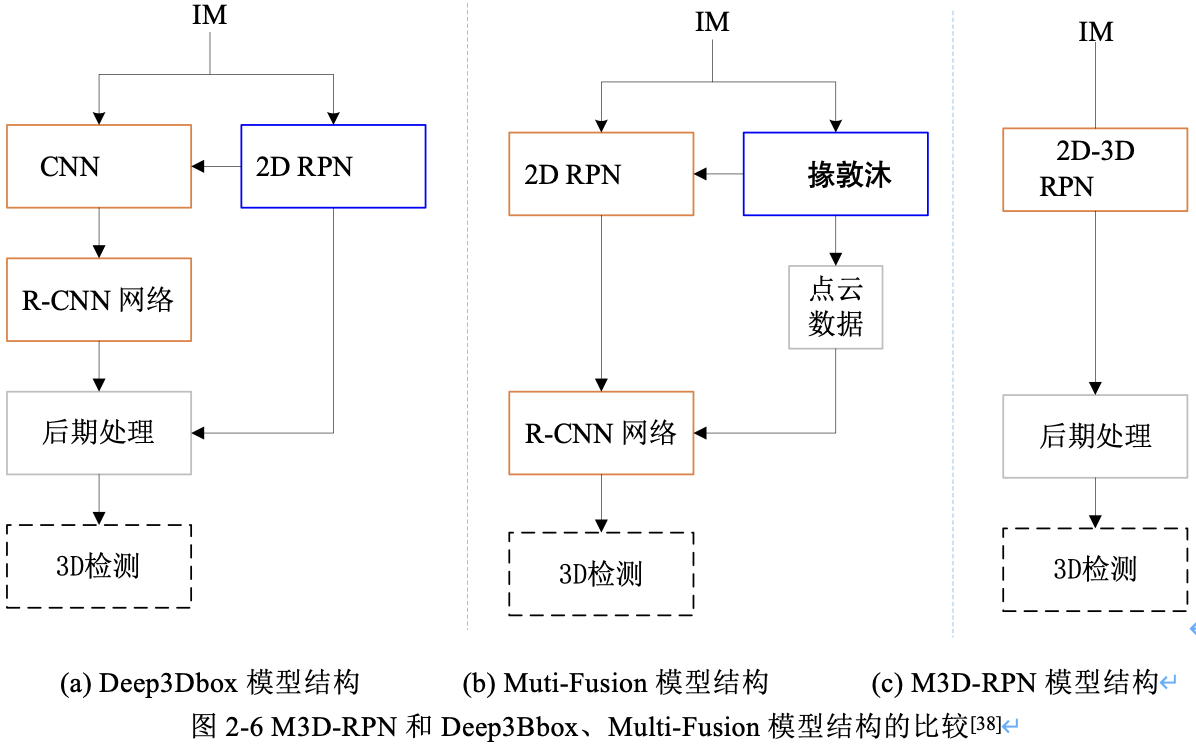
圖2-6 是 M3D-RPN 和以前演演算法: Deep3DBox、Multi-Fusion 的比較。從圖中可以看出,先前的工作由內部多步(橙色)和外部網路(藍色)組成,而 M3D-RPN 是端到端訓練的單步(single shot)網路。
四,總結
本文首先介紹了單目 3D 目標檢測的理論基礎,然後概述了單目 3D 目標檢測的內容,包括3D目標檢測演演算法根據輸入訊號不同的分類、 單目 3D 視覺目標檢測定義和難點,以及描述了無人駕駛中的3D目標檢測任務,最後介紹了幾個主流的單目 3D 目標檢測演演算法,並描述了這些演演算法的原理和相關檢測流程。總結可以發現主流的單目3D 目標檢測演演算法都有以下共同點:
- 都複用了 2D 目標檢測的結果;
- 都有結合投影幾何知識和利用2D影象特徵來得到目標的3D空間位置;
- 都有 3D 屬性引數迴歸網路。
值得注意的是,目前單目視覺 3D 目標檢測技術依然面臨著很多問題,因為演演算法不僅要找到物體在影象中出現的位置,還需要反投影到實際 3D 空間中,這個過程是需要有絕對的尺寸估計。
參考資料
- [1] X. Chen, K. Kundu, Y. Zhu, A. G. Berneshawi, H. Ma, S. Fidler, and R. Urtasun, 「3D object proposals for accurate object class detection」, in Neural Information Processing Systems, 2015.
- [2] 何志強. 基於深度估計的3D目標檢測與跟蹤演演算法研究[D].西安科技大學,2019.
- [3] 高翔,張濤等. 視覺SLAM十四講從理論到時間[M]. 電子工業出版社,2017.
- [4] Rotation matrix calculation [EB/OL]
- [5] Mousavian, Arsalan, Dragomir Anguelov, John Flynn and Jana Kosecka. 「3D Bounding Box Estimation Using Deep Learning and Geometry.」 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016): 5632-5640.
- [6] Brazil, Garrick and Xiaoming Liu. 「M3D-RPN: Monocular 3D Region Proposal Network for Object Detection.」 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (2019): 9286-9295.
- [7] Chabot, Florian, Mohamed Chaouch, Jaonary Rabarisoa, Céline Teulière and Thierry Chateau. 「Deep MANTA: A Coarse-to-Fine Many-Task Network for Joint 2D and 3D Vehicle Analysis from Monocular Image.」 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017): 1827-1836.
版權宣告 ©
本文作者:嵌入式視覺
本文連結:https://www.cnblogs.com/armcvai/p/17131688.html
版權宣告:本文為「嵌入式視覺」的原創文章,首發於 github ,遵循 CC BY-NC-ND 4.0 版權協定,著作權歸作者所有,轉載請註明出處!
鼓勵博主:如果您覺得文章對您有所幫助,可以點選文章右下角【推薦】一下。您的鼓勵就是博主最大的動力!