為什麼sleeping的對談會造成阻塞(2)
背景
客戶反饋系統突然從11:10開始執行非常緩慢,在SQL專家雲中看到大量的產生阻塞的活動對談,KILL掉阻塞的源頭馬上又出現新的源頭,實在沒有辦法只能重啟應用程式斷開所有資料庫連線才解決,請我們協助分析根本的原因。
現象
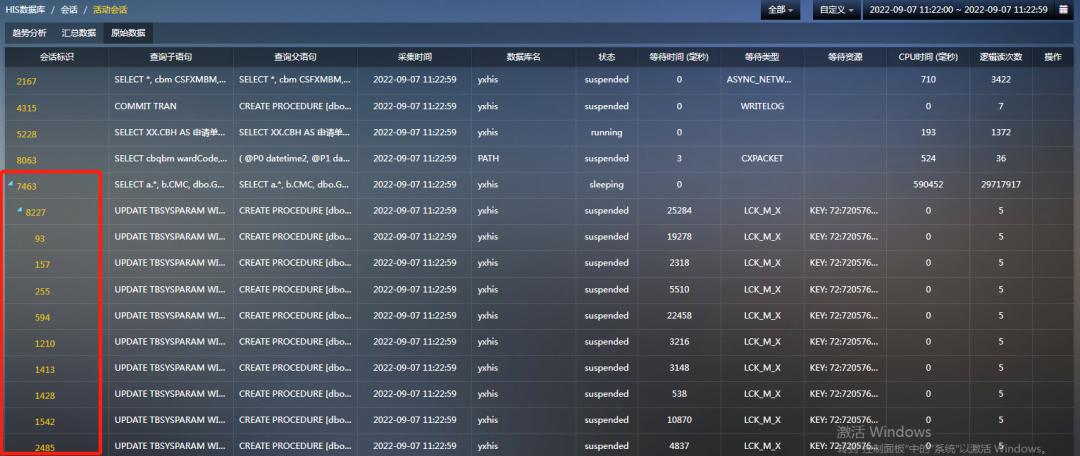
登入SQL專家雲,進入趨勢分析頁面,下鑽到11點鐘內一個小時的資料,看到從11:12開始出現阻塞,越來越嚴重。

分析
狀態為sleeping代表當前對談沒有執行SQL請求,之所以造成阻塞是因為對談以前開啟了一個或多個事務, 在事務中修改了一個或多個表的資料,對談對這些修改的資料行持有排他鎖,從而阻塞其他對談對該表的操作。如果這種狀態持續很長時間,很有可能是前端應用程式出現了異常,並且沒有健壯的例外處理機制,出錯後沒有回滾以前開啟的事務並關閉連線,導致阻塞一直存在。 前端應用程式出錯原因主要有兩種,一種是執行SQL語句時被阻塞等原因導致執行時間長併產生超時;一種是執行非資料庫存取邏輯時因為某些原因出錯了,例如轉換資料型別失敗、接收資料量太大導致記憶體溢位、存取別的介面報錯等。
本著這個經驗,對這些sleeping的對談進行回溯,發現這些對談在sleeping之前,都曾經被阻塞過很長時間,根據慢語句的特徵判斷是執行超時了。


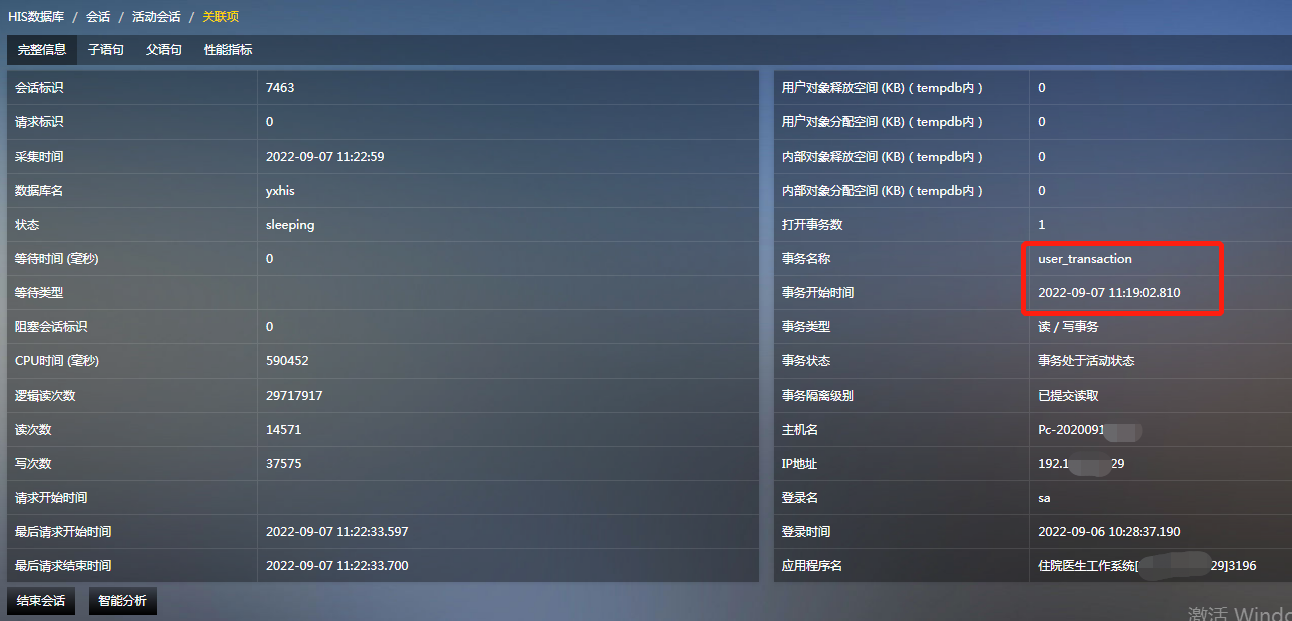
而且這些對談都存在開啟的事務,事務開始時間都在執行語句超時的時間之前。
通過對儲存過程進行分析,發現裡面在用TRY CATCH的方式處理事務,因此推斷該方式無法捕獲應用程式端的超時錯誤,導致事務和連線的洩露,因為儲存過程比較複雜,下面用一個測試來模擬。
測試
首先建立一個儲存過程,邏輯為先開始事務,然後依次對兩個表進行UPDATE,通過TRY CATCH的方法處理事務。
CREATE PROCEDURE dbo.usp_test AS BEGIN TRAN BEGIN TRY UPDATE dbo.Table_2 WITH(ROWLOCK) SET a = 'wang' UPDATE dbo.Table_1 WITH(ROWLOCK) SET a = 'wang' END TRY BEGIN CATCH IF @@ERROR = 0 BEGIN GOTO succeed END ELSE BEGIN GOTO error END END CATCH succeed: COMMIT TRAN RETURN 1 error: ROLLBACK TRAN RETURN 0
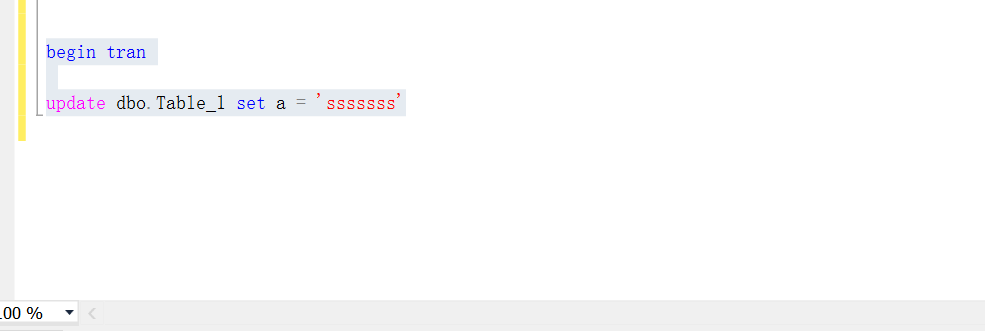
新建一個查詢,開始一個事務,然後執行UPDATE Table_1,不提交或者回滾事務,對錶Table_1的排他鎖一直存在, 用來模擬對錶Table_1的鎖定。
新建另一個查詢,注意,執行超時值設定為30秒(預設是0,代表永不超時)。這個新建立的對談ID是56。
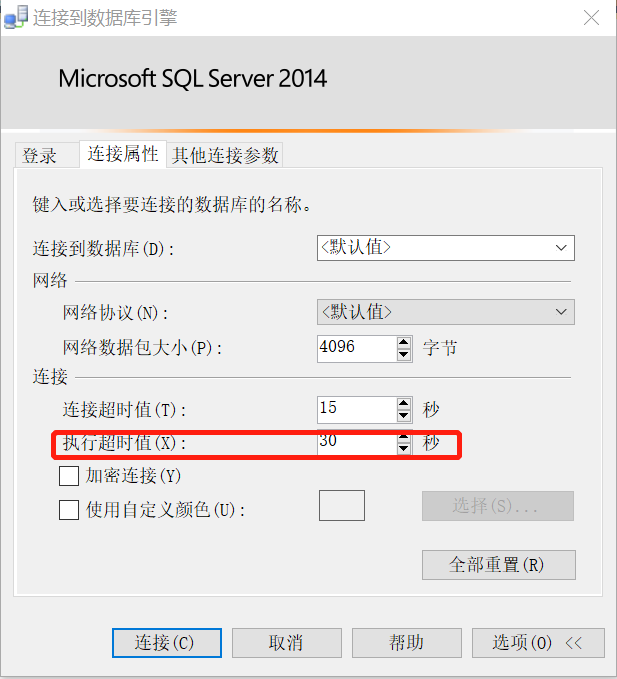
執行儲存過程usp_test。updat dbo.Table_2很快執行完,在執行updat dbo.Table_1時產生阻塞,等待30秒後出現超時的報錯。
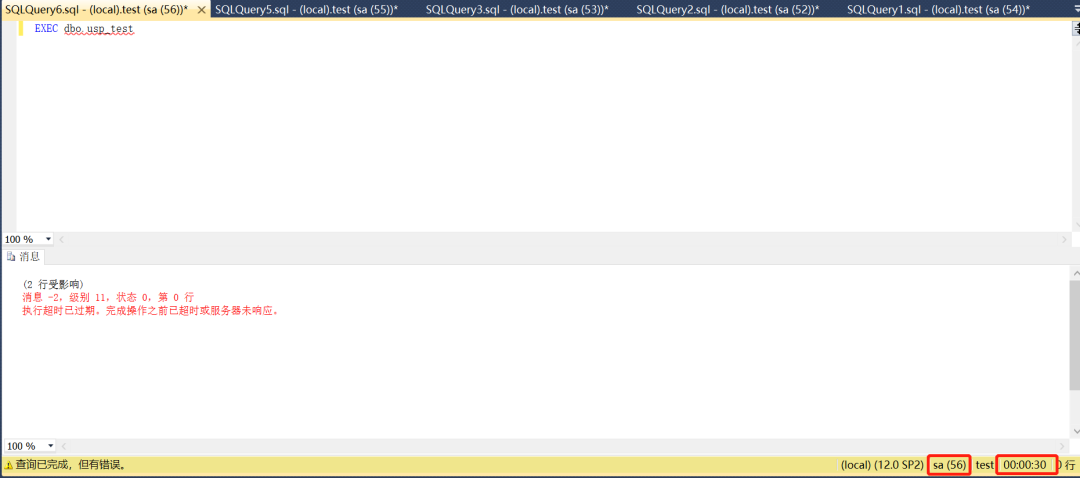
新建一個查詢,檢視對談56的事務資訊,可以看到存在一個開啟的事務。
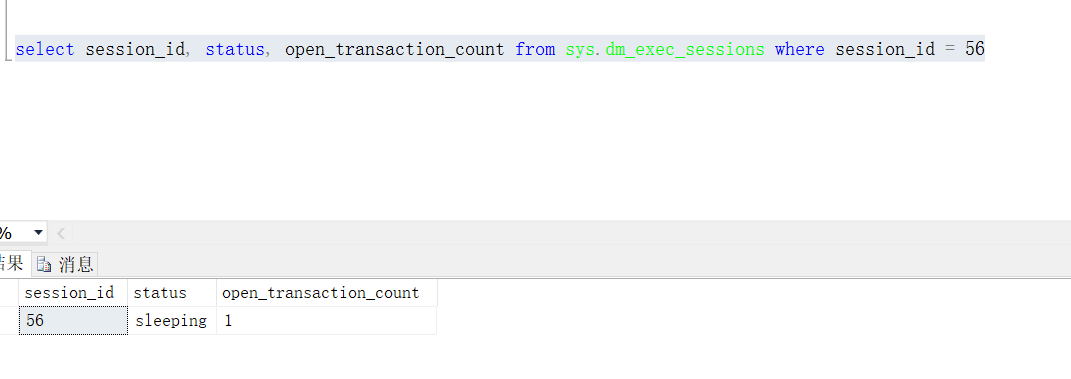
再通過sys.dm_tran_locks可以看到對談56還保持著對錶Table_2和Table_1的意向排他鎖以及Table_2上更改的兩行資料的排他鎖。此時在其他對談中對Table_2執行查詢和修改,都被對談56阻塞。
總結:「超時」錯誤是應用程式端的異常,資料庫驅動程式執行SQL語句時等待伺服器端的響應,等待時間達到設定的閾值後傳送一個終止執行的訊號給伺服器端並向上層應用程式丟擲異常。伺服器端接收到該訊號後終止語句的執行,並不會報錯,TRY CATCH是無法捕獲的,因此無法執行到SUCCEED處的COMMIT或者ERROR處的ROLLBACK,導致了事務的洩露,該事務中的對錶Table_2的排他鎖一直持有,其他對談對錶Table_2的操作會被阻塞,直到殺掉該對談。
解決
對於這類問題,根本的解決方法是修改應用程式,增加對於執行異常的捕獲,檢查是否存在事務並回滾,然後關閉資料庫連線。
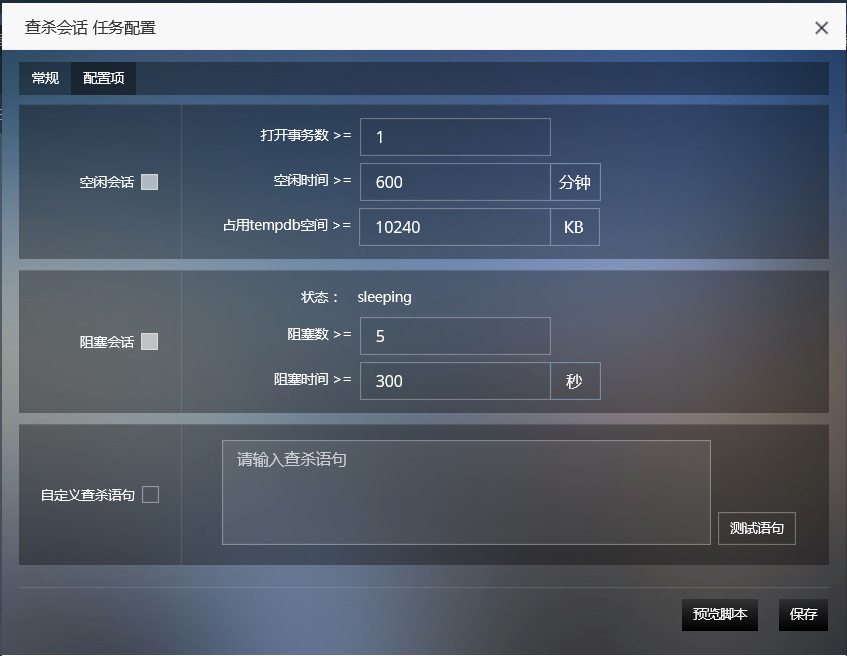
但是很多客戶是購買軟體廠商的產品,修改程式不容易實現或者週期很長。因此只能在資料庫端進行補償性的措施,就是設定一個自動查殺對談的作業,根據sleeping對談的特徵定期KILL掉。也可以在SQL專家雲中啟用自動查殺對談的功能。