Redis與MySQL雙寫一致性如何保證? (美團二面)
前言
四月份的時候,有位朋友去美團面試,他說被問到Redis與MySQL雙寫一致性如何保證? 這道題其實就是在問快取和資料庫在雙寫場景下,一致性是如何保證的?本文將跟大家一起來探討如何回答這個問題。
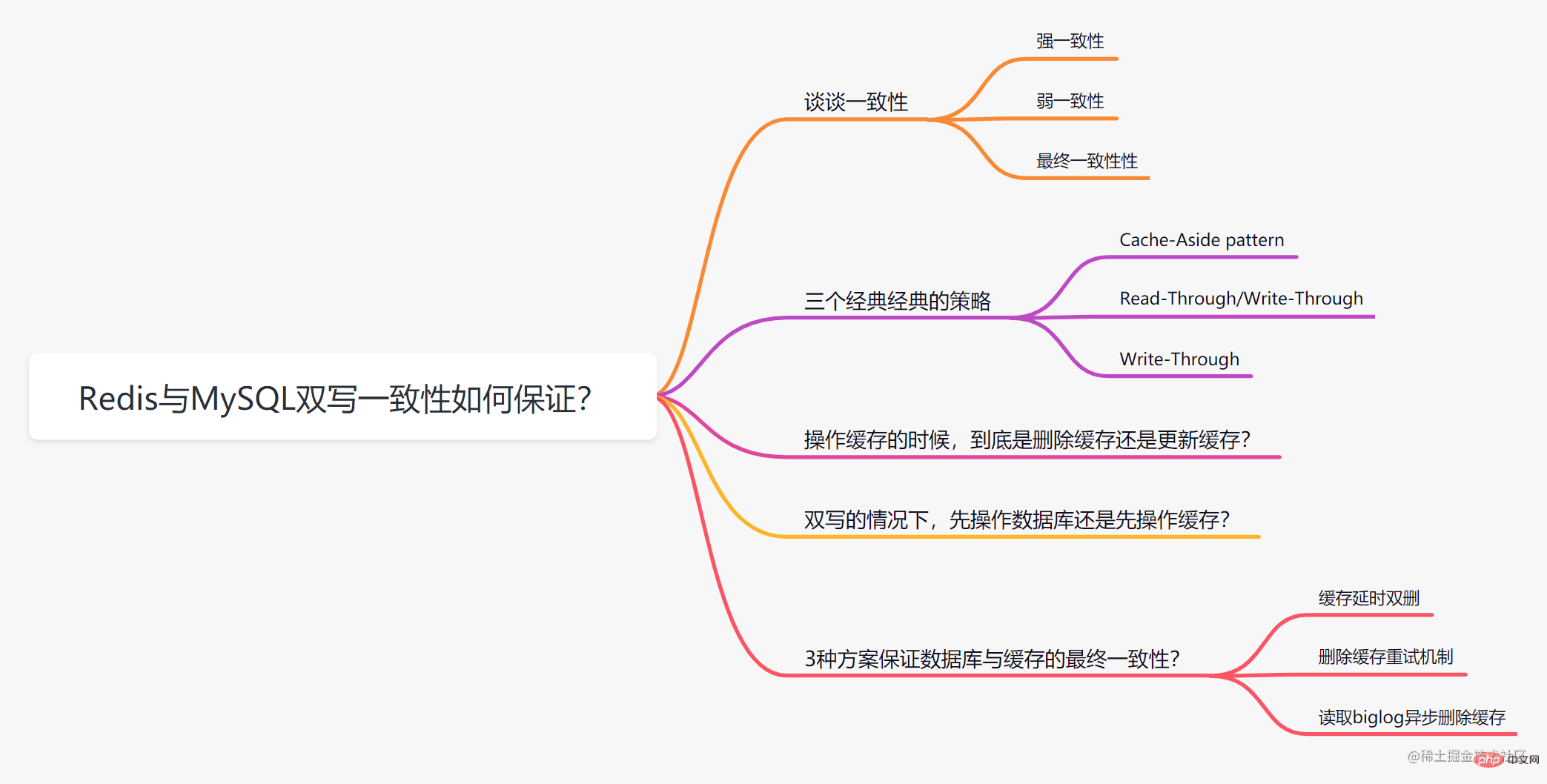
談談一致性
一致性就是資料保持一致,在分散式系統中,可以理解為多個節點中資料的值是一致的。
- 強一致性:這種一致性級別是最符合使用者直覺的,它要求系統寫入什麼,讀出來的也會是什麼,使用者體驗好,但實現起來往往對系統的效能影響大
- 弱一致性:這種一致性級別約束了系統在寫入成功後,不承諾立即可以讀到寫入的值,也不承諾多久之後資料能夠達到一致,但會盡可能地保證到某個時間級別(比如秒級別)後,資料能夠達到一致狀態
- 最終一致性:最終一致性是弱一致性的一個特例,系統會保證在一定時間內,能夠達到一個資料一致的狀態。這裡之所以將最終一致性單獨提出來,是因為它是弱一致性中非常推崇的一種一致性模型,也是業界在大型分散式系統的資料一致性上比較推崇的模型
三個經典的快取模式
快取可以提升效能、緩解資料庫壓力,但是使用快取也會導致資料不一致性的問題。一般我們是如何使用快取呢?有三種經典的快取模式:
- Cache-Aside Pattern
- Read-Through/Write through
- Write behind
Cache-Aside Pattern
Cache-Aside Pattern,即旁路快取模式,它的提出是為了儘可能地解決快取與資料庫的資料不一致問題。
Cache-Aside讀流程
Cache-Aside Pattern的讀請求流程如下:
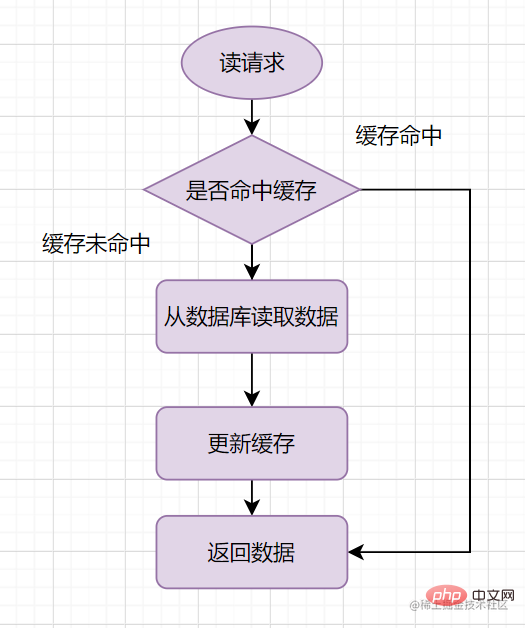
- 讀的時候,先讀快取,快取命中的話,直接返回資料
- 快取沒有命中的話,就去讀資料庫,從資料庫取出資料,放入快取後,同時返回響應。
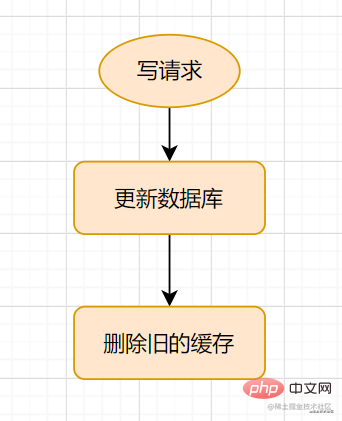
Cache-Aside 寫流程
Cache-Aside Pattern的寫請求流程如下:
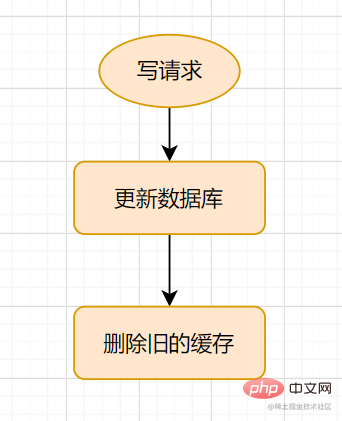
更新的時候,先更新資料庫,然後再刪除快取。
Read-Through/Write-Through(讀寫穿透)
Read/Write Through模式中,伺服器端把快取作為主要資料儲存。應用程式跟資料庫快取互動,都是通過抽象快取層完成的。
Read-Through
Read-Through的簡要流程如下
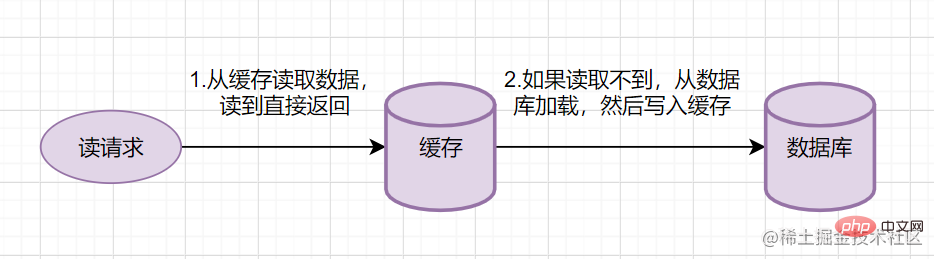
- 從快取讀取資料,讀到直接返回
- 如果讀取不到的話,從資料庫載入,寫入快取後,再返回響應。
這個簡要流程是不是跟Cache-Aside很像呢?其實Read-Through就是多了一層Cache-Provider,流程如下:
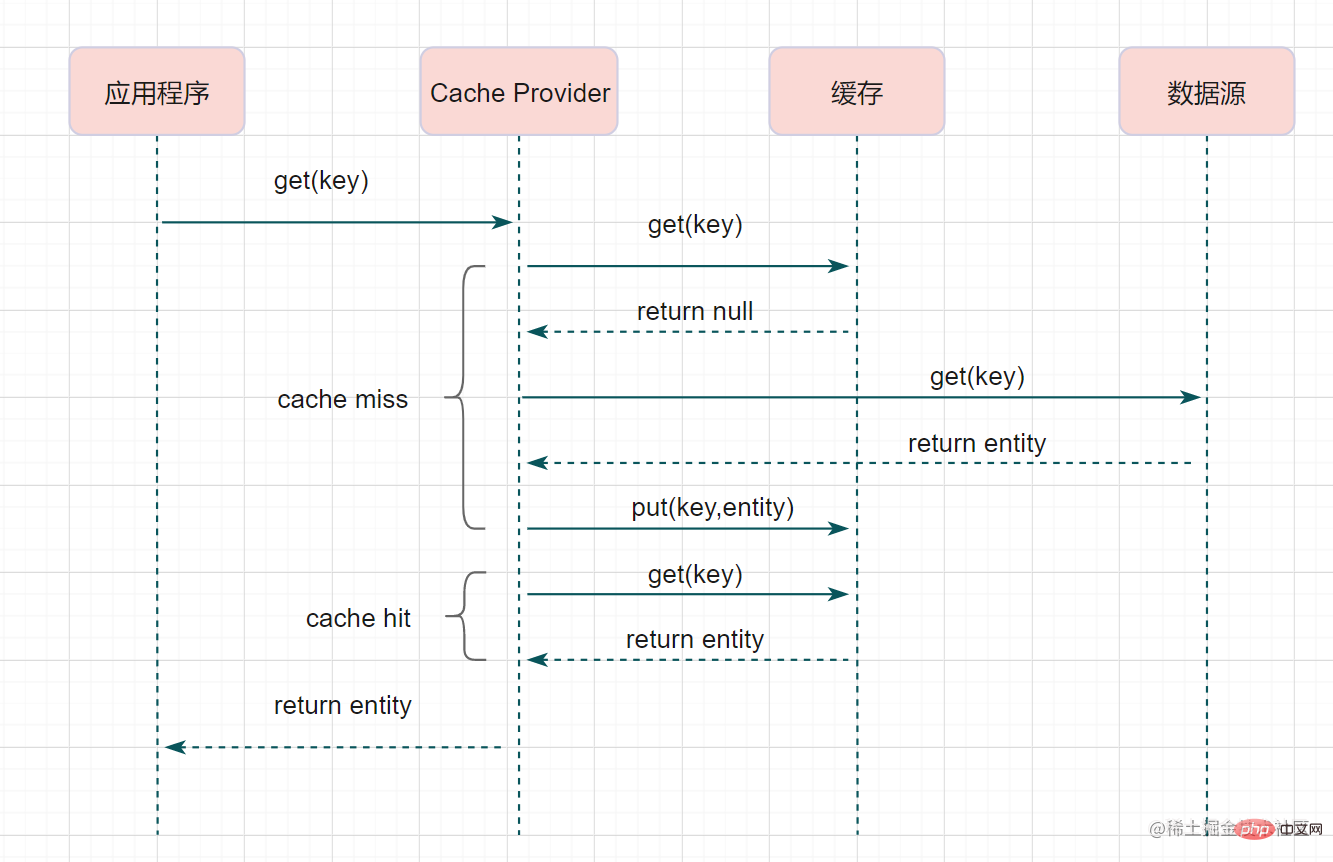
Read-Through實際只是在Cache-Aside之上進行了一層封裝,它會讓程式程式碼變得更簡潔,同時也減少資料來源上的負載。
Write-Through
Write-Through模式下,當發生寫請求時,也是由快取抽象層完成資料來源和快取資料的更新,流程如下: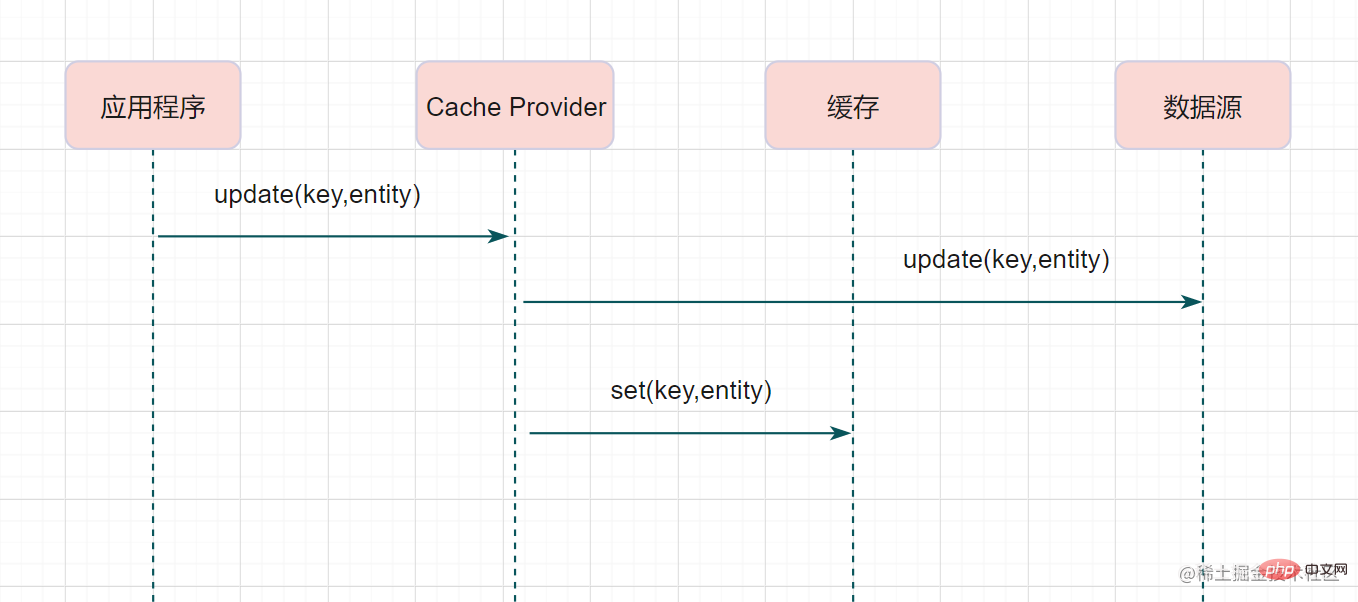
Write behind (非同步快取寫入)
Write behind跟Read-Through/Write-Through有相似的地方,都是由Cache Provider來負責快取和資料庫的讀寫。它兩又有個很大的不同:Read/Write Through是同步更新快取和資料的,Write Behind則是隻更新快取,不直接更新資料庫,通過批次非同步的方式來更新資料庫。
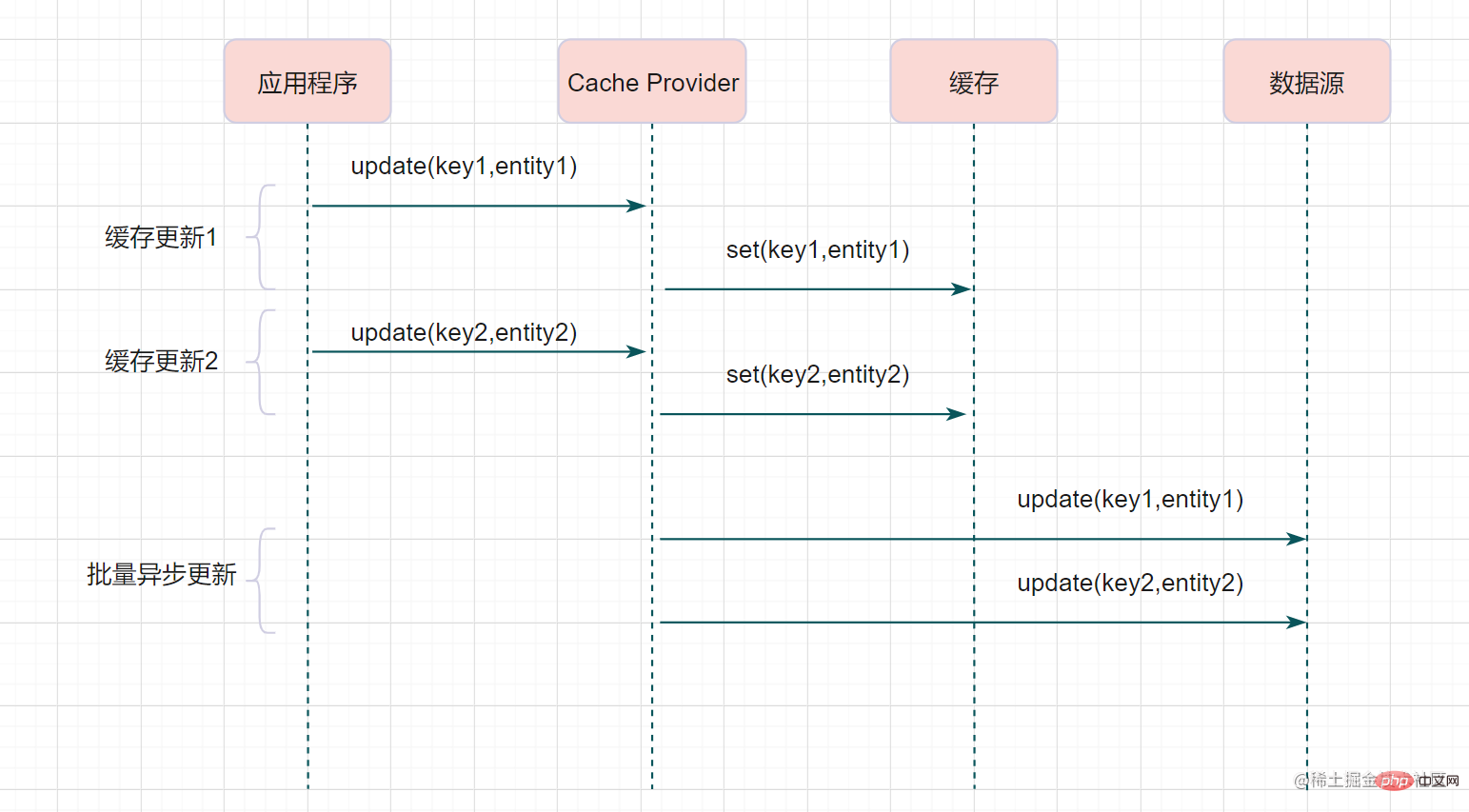
這種方式下,快取和資料庫的一致性不強,對一致性要求高的系統要謹慎使用。但是它適合頻繁寫的場景,MySQL的InnoDB Buffer Pool機制就使用到這種模式。
操作快取的時候,刪除快取呢,還是更新快取?
一般業務場景,我們使用的就是Cache-Aside模式。 有些小夥伴可能會問, Cache-Aside在寫入請求的時候,為什麼是刪除快取而不是更新快取呢?
我們在操作快取的時候,到底應該刪除快取還是更新快取呢?我們先來看個例子:
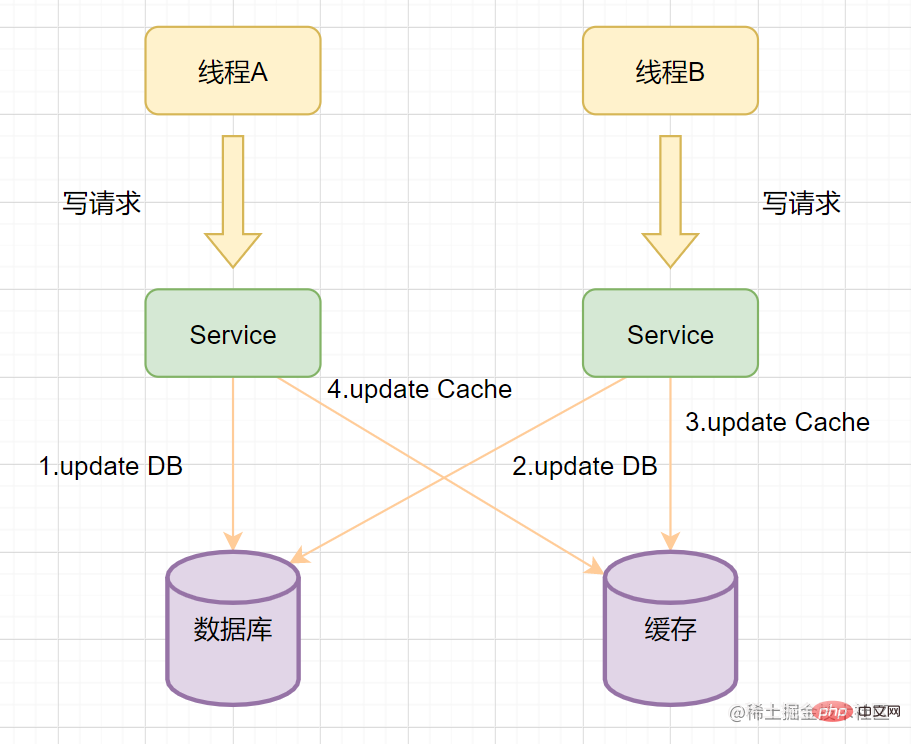
- 執行緒A先發起一個寫操作,第一步先更新資料庫
- 執行緒B再發起一個寫操作,第二步更新了資料庫
- 由於網路等原因,執行緒B先更新了快取
- 執行緒A更新快取。
這時候,快取儲存的是A的資料(老資料),資料庫儲存的是B的資料(新資料),資料不一致了,髒資料出現啦。如果是刪除快取取代更新快取則不會出現這個髒資料問題。
更新快取相對於刪除快取,還有兩點劣勢:
- 如果你寫入的快取值,是經過複雜計算才得到的話。更新快取頻率高的話,就浪費效能啦。
- 在寫資料庫場景多,讀資料場景少的情況下,資料很多時候還沒被讀取到,又被更新了,這也浪費了效能呢(實際上,寫多的場景,用快取也不是很划算了)
雙寫的情況下,先運算元據庫還是先操作快取?
Cache-Aside快取模式中,有些小夥伴還是有疑問,在寫入請求的時候,為什麼是先運算元據庫呢?為什麼不先操作快取呢?
假設有A、B兩個請求,請求A做更新操作,請求B做查詢讀取操作。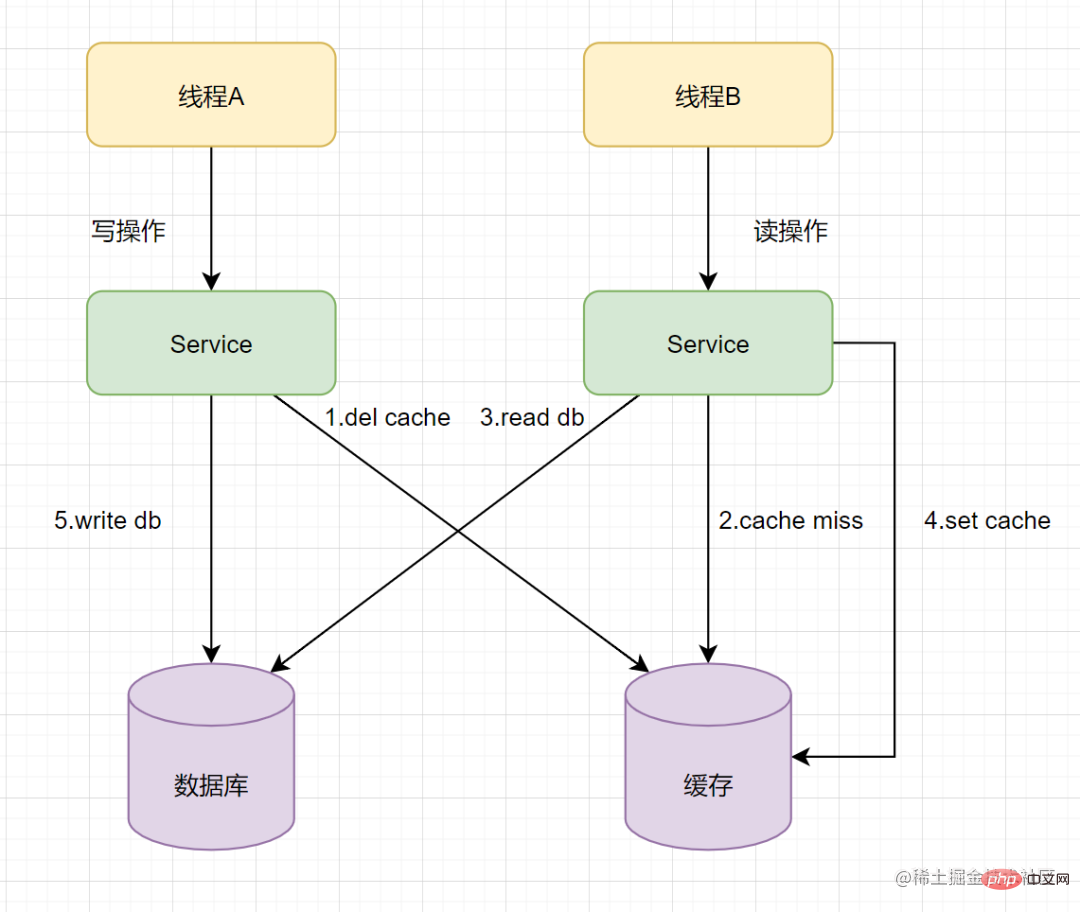
- 執行緒A發起一個寫操作,第一步del cache
- 此時執行緒B發起一個讀操作,cache miss
- 執行緒B繼續讀DB,讀出來一個老資料
- 然後執行緒B把老資料設定入cache
- 執行緒A寫入DB最新的資料
醬紫就有問題啦,快取和資料庫的資料不一致了。快取儲存的是老資料,資料庫儲存的是新資料。因此,Cache-Aside快取模式,選擇了先運算元據庫而不是先操作快取。
快取延時雙刪
有些小夥伴可能會說,不一定要先運算元據庫呀,採用快取延時雙刪策略就好啦?什麼是延時雙刪呢?
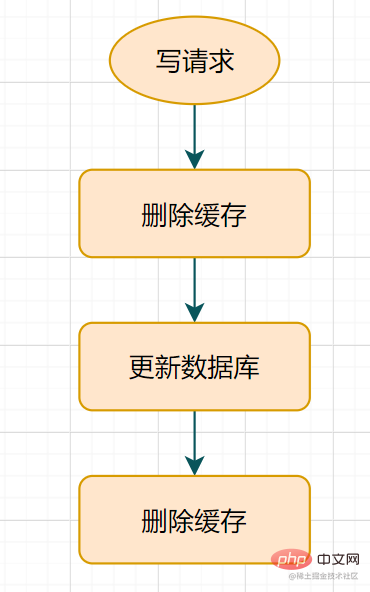
- 先刪除快取
- 再更新資料庫
- 休眠一會(比如1秒),再次刪除快取。
這個休眠一會,一般多久呢?都是1秒?
這個休眠時間 = 讀業務邏輯資料的耗時 + 幾百毫秒。 為了確保讀請求結束,寫請求可以刪除讀請求可能帶來的快取髒資料。
刪除快取重試機制
不管是延時雙刪還是Cache-Aside的先運算元據庫再刪除快取,如果第二步的刪除快取失敗呢,刪除失敗會導致髒資料哦~
刪除失敗就多刪除幾次呀,保證刪除快取成功呀~ 所以可以引入刪除快取重試機制
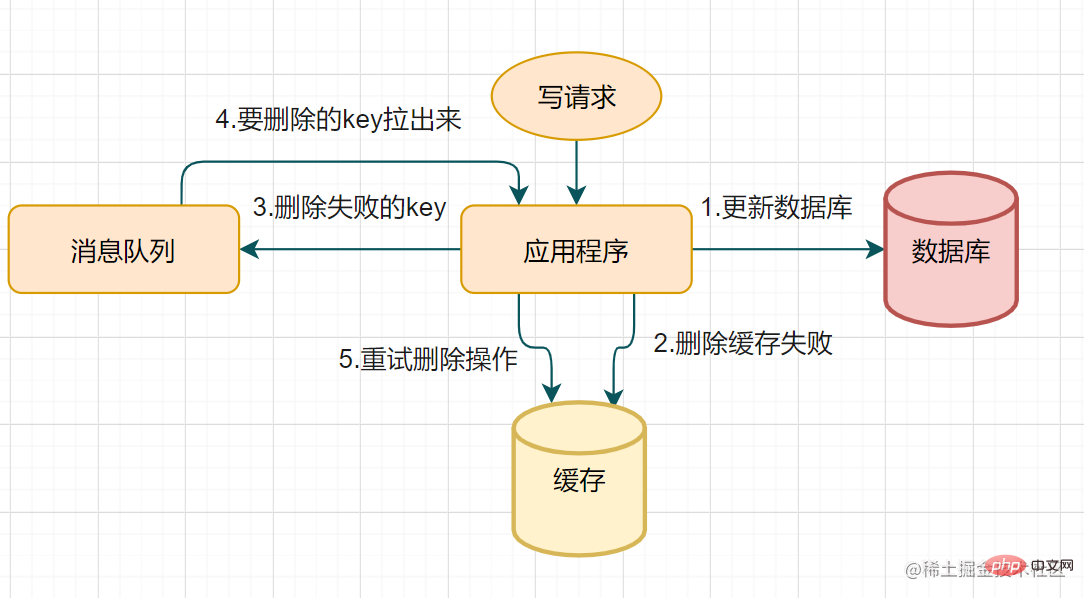
- 寫請求更新資料庫
- 快取因為某些原因,刪除失敗
- 把刪除失敗的key放到訊息佇列
- 消費訊息佇列的訊息,獲取要刪除的key
- 重試刪除快取操作
讀取biglog非同步刪除快取
重試刪除快取機制還可以,就是會造成好多業務程式碼入侵。其實,還可以通過資料庫的binlog來非同步淘汰key。
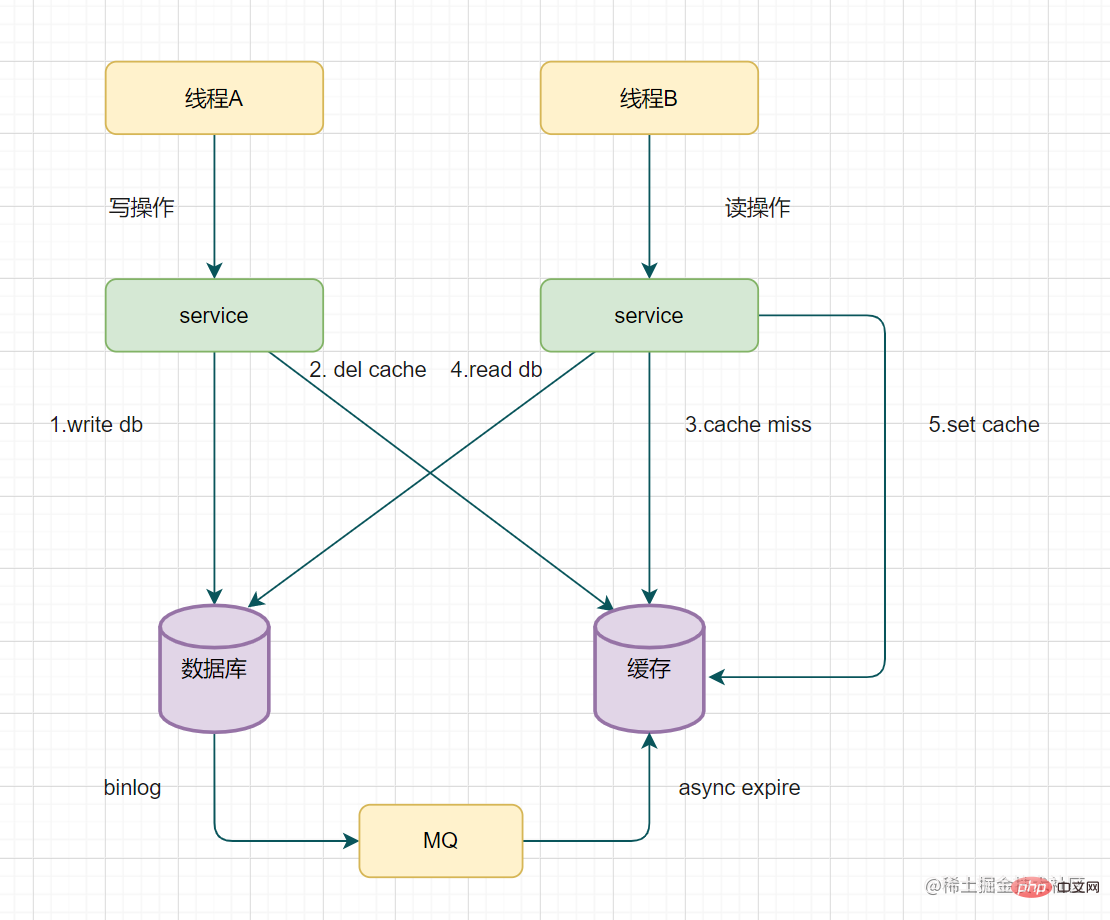
以mysql為例 可以使用阿里的canal將binlog紀錄檔採集傳送到MQ佇列裡面,然後通過ACK機制確認處理這條更新訊息,刪除快取,保證資料快取一致性
推薦學習:《》以上就是Redis與MySQL雙寫一致性如何保證? (美團二面)的詳細內容,更多請關注TW511.COM其它相關文章!