13.一文徹底瞭解執行緒池
大家好,我是王有志。關注王有志,一起聊技術,聊遊戲,聊在外漂泊的生活。
最近搞了個交流群:共同富裕的Java人,核心功能是提供面試交流場所,分享八股文或面試心得,宗旨是「Javaer help Javaer」,希望能夠借他人之經驗,攻克我之面試,歡迎各位加入我們。
下面,我們開始今天的主題:執行緒池。執行緒池是面試中必問的八股文,我將涉及到到的問題分為3大類:
-
基礎使用
-
執行緒池是什麼?為什麼要使用執行緒池?
-
Executor框架是什麼?
-
Java提供了哪些執行緒池?
-
-
實現原理
-
執行緒池的底層原理是如何實現的?
-
建立執行緒池的引數有哪些?
-
執行緒池中的執行緒是什麼時間建立的?
-
-
系統設計
-
如何合理的設定執行緒池的大小?
-
如果伺服器宕機,怎麼處理佇列中的任務?
-
希望今天的內容能夠幫你解答以上的問題。
Tips:
-
本文使用Java 11原始碼進行分析;
-
文章會在原始碼中新增註釋,關鍵內容會有單獨的分析。
池化思想
在你的程式設計生涯中,一定遇到過各種各樣的「池」,如:資料庫連線池,常數池,以及今天的執行緒池。無一例外,它們都是藉助池化思想來管理計算機中的資源。
維基百科中是這樣描述「池化」的:
In resource management, pooling is the grouping together of resources (assets, equipment, personnel, effort, etc.) for the purposes of maximizing advantage or minimizing risk to the users. The term is used in finance, computing and equipment management.
「池化」指的是將資源匯聚到一起,以發揮優勢或降低風險。
接著來看維基百科中對「池」的描述:
In computer science, a pool is a collection of resources that are kept, in memory, ready to use, rather than the memory acquired on use and the memory released afterwards.A pool client requests a resource from the pool and performs desired operations on the returned resource. When the client finishes its use of the resource, it is returned to the pool rather than released and lost.
電腦科學中的「池」,是記憶體中儲存資源的集合,建立資源以備使用,停用時回收,而不是使用時建立,停用時丟棄。使用者端從池中請求資源,並執行操作,當不再使用資源時,將資源歸還到池中,而不是釋放或丟棄。
為什麼要使用「池」?
首先"池"是資源的集合,通過「池」可以實現對資源的統一管理;
其次,「池」記憶體放已經建立並初始化的資源,使用時直接從「池」內獲取,跳過了建立及初始化的過程,提高了響應速度;
最後,資源使用完成後歸還到「池」中,而非丟棄或銷燬,提高資源的利用率。
執行緒池
池化思想的引入是為了解決資源管理中遇到的問題,而執行緒池正是藉助池化思想實現的執行緒管理工具。那麼執行緒池可以幫助我們解決哪些實際的問題呢?
最直接的是控制執行緒的建立,不加以限制的建立執行緒會耗盡系統資源。不信的話你可以試試下面的程式碼:
public static void main(String[] args) {
while (true) {
new Thread(()-> {
}).start();
}
}
Tips:卡頓警告~~
其次,執行緒的建立和銷燬是需要時間的,藉助執行緒池可以有效的避免執行緒頻繁的建立和銷燬執行緒,提高程的序響應速度。
問題解答:執行緒池是什麼?為什麼要使用執行緒池?
Executor體系
Java中提供了功能完善的Executor體系,用於實現執行緒池。先來了解下Executor體系中的核心成員間的關係:
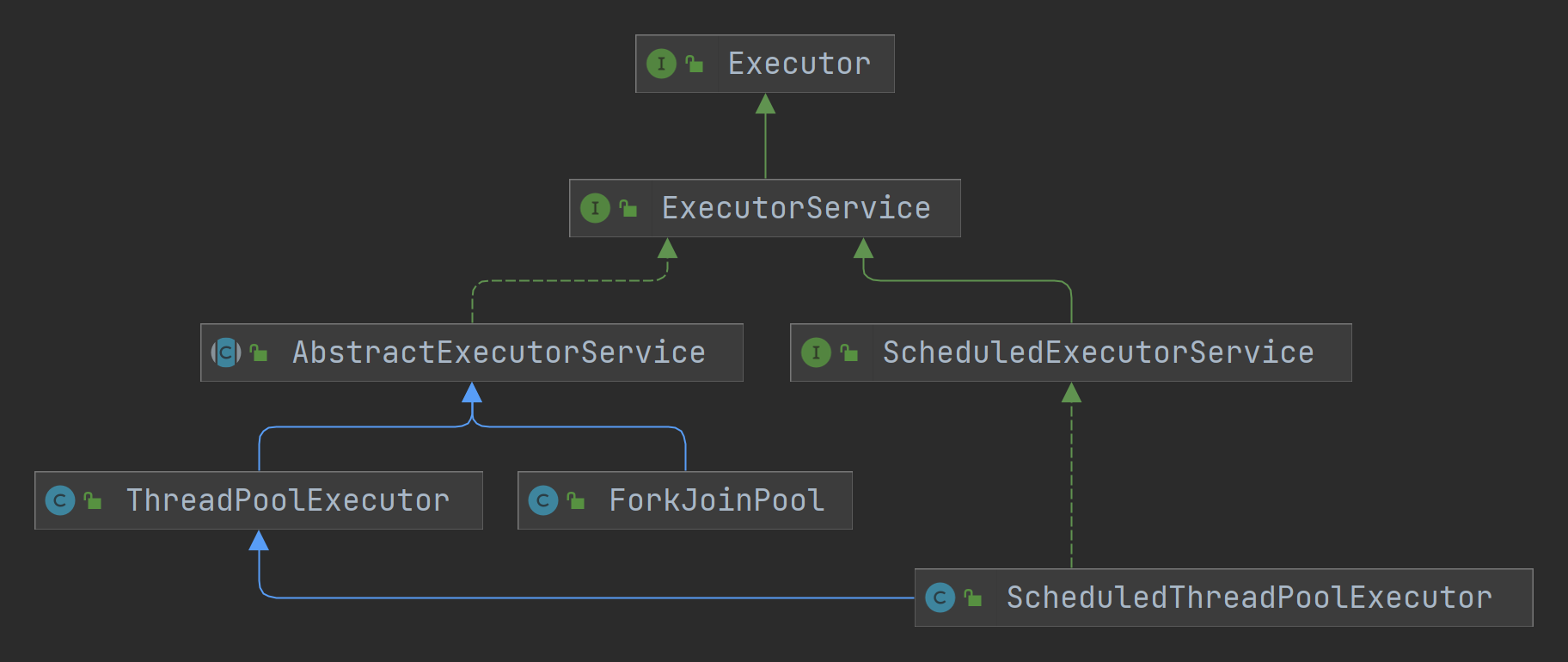
Executor體系的最頂層是Executor介面和ExecutorService介面,它們定義了Executor體系的核心功能。
Executor介面
Executor介面的註釋:
An object that executes submitted Runnable tasks. This interface provides a way of decoupling task submission from the mechanics of how each task will be run, including details of thread use, scheduling, etc. An Executor is normally used instead of explicitly creating threads.
Executor介面非常簡單,只定義了execute方法,主要目的是將Runnable任務與執行機制(執行緒,排程任務等)解耦,提供了執行Runnable任務的方法。
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*/
void execute(Runnable command);
}
ExecutorService介面
ExecutorService介面繼承了Executor介面,拓展了Executor介面的能力。ExecutorService介面的註釋:
An Executor that provides methods to manage termination and methods that can produce a Future for tracking progress of one or more asynchronous tasks.
ExecutorService介面關鍵方法的宣告:
public interface ExecutorService extends Executor {
/**
* Initiates an orderly shutdown in which previously submitted
* tasks are executed, but no new tasks will be accepted.
* Invocation has no additional effect if already shut down.
*/
void shutdown();
/**
* Attempts to stop all actively executing tasks, halts the
* processing of waiting tasks, and returns a list of the tasks
* that were awaiting execution.
* This method does not wait for actively executing tasks to
* terminate. Use {@link #awaitTermination awaitTermination} to
* do that.
*/
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
/**
* Blocks until all tasks have completed execution after a shutdown
* request, or the timeout occurs, or the current thread is
* interrupted, whichever happens first.
*/
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
/**
* Submits a Runnable task for execution and returns a Future
* representing that task. The Future's {@code get} method will
* return {@code null} upon <em>successful</em> completion.
*/
Future<?> submit(Runnable task);
}
對關鍵方法做一個說明:
-
繼承自
Executor介面:execute:執行Runnable任務;
-
ExecutorService介面定義的方法:-
submit:執行Runnable或Callable任務,並返回Future; -
shutdown:允許已提交的任務執行完畢,但不接受新任務的關閉; -
shutdownNow:嘗試關閉所有任務(正在/等待執行),並返回等待執行的任務。
-
Tips:其餘方法建議閱讀原始碼中的註釋,即便是提到的4個方法,也要閱讀註釋。
問題解答:Executor框架是什麼?
ThreadPoolExecutor核心流程
Executor體系中,大家最熟悉的一定是ThreadPoolExecutor實現了,也是我們能夠實現自定義執行緒池的基礎。接下來逐步分析ThreadPoolExecutor的實現原理。
構造執行緒池
ThreadPoolExecutor提供了4個構造方法,我們來看引數最全的那個構造方法:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
ThreadPoolExecutor的構造方法提供了7個引數:
-
int corePoolSize:執行緒池的核心執行緒數量,建立執行緒的數量小於等於corePoolSize時,會一直建立執行緒; -
int maximumPoolSize:執行緒池的最大執行緒數量,當執行緒數量等於corePoolSize後且佇列已滿,允許繼續建立\((maximumPoolSize-corePoolSize)\)個執行緒; -
long keepAliveTime:執行緒的最大空閒時間,當建立了超出corePoolSize數量的執行緒後,這些執行緒在不執行任務時能夠存活的時間,超出keepAliveTime後會被銷燬; -
TimeUnit unit:keepAliveTime的單位; -
BlockingQueue<Runnable> workQueue:阻塞佇列,用於儲存等待執行的任務; -
ThreadFactory threadFactory:執行緒工廠,用於建立執行緒,預設使用Executors.defaultThreadFactory()。 -
RejectedExecutionHandler handler:拒絕策略,當佇列已滿,且沒有空閒的執行緒時,執行的拒絕任務的策略。
Tips:有些小夥伴會疑問,如果每次執行一個任務,執行完畢後再執行新任務,執行緒池依舊會建立corePoolSize個執行緒嗎?答案是會的,後文解釋。
問題解答:建立執行緒池的引數有哪些?
主控狀態CTL與執行緒池狀態
ThreadPoolExecutor中定義了主控狀態CTL和執行緒池狀態:
/**
* The main pool control state, ctl, is an atomic integer packing
* two conceptual fields
* workerCount, indicating the effective number of threads
* runState, indicating whether running, shutting down etc
*/
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3; // 29
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;// 0001 1111 1111 1111 1111 1111 1111 1111
private static final int RUNNING = -1 << COUNT_BITS;// 111 0 0000 0000 0000 0000 0000 0000 0000
private static final int SHUTDOWN = 0 << COUNT_BITS;// 000 0 0000 0000 0000 0000 0000 0000 0000
private static final int STOP = 1 << COUNT_BITS;// 001 0 0000 0000 0000 0000 0000 0000 0000
private static final int TIDYING = 2 << COUNT_BITS;// 010 0 0000 0000 0000 0000 0000 0000 0000
private static final int TERMINATED = 3 << COUNT_BITS;// 011 0 0000 0000 0000 0000 0000 0000 0000
private static int runStateOf(int c) { return c & ~COUNT_MASK; }
private static int workerCountOf(int c) { return c & COUNT_MASK; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
CTL包含了兩部分內容:執行緒池狀態(runState,原始碼中使用rs替代)和工作執行緒數(workCount,原始碼中使用wc替代)。當看到位運運算元和「MASK」一起出現時,就應該想到應用了位掩碼技術。
主控狀態CTL的預設值是RUNNING | 0即:1110 0000 0000 0000 0000 0000 0000 0000。runStateOf方法返回低29位為0的CTL,與之對應的是執行緒池狀態,workerCountOf方法則返回高3位為0的CTl,用低29位表示工作執行緒數量,所以執行緒池最多允許536870911個執行緒。
Tips:
-
工作執行緒指的是已經建立的執行緒,並不一定在執行任務,後文解釋;
-
位運算的可以參考程式設計技巧:「高階」的位運算;
-
Java中二進位制使用二補數,注意原碼,反碼和二補數間的轉換。
執行緒池的狀態
註釋中對執行緒池的狀態做出了詳細的說明:
RUNNING: Accept new tasks and process queued tasks
SHUTDOWN: Don't accept new tasks, but process queued tasks
STOP: Don't accept new tasks, don't process queued tasks, and interrupt in-progress tasks
TIDYING: All tasks have terminated, workerCount is zero, the thread transitioning to state TIDYING will run the terminated() hook method
TERMINATED: terminated() has completed
-
RUNNING:接收新任務,處理佇列中的任務;
-
SHUTDOWN:不接收新任務,處理佇列中的任務;
-
STOP:不接收新任務,不處理佇列中的任務,中斷正在執行的任務;
-
TIDYING:所有任務已經執行完畢,並且工作執行緒為0,轉換到TIDYING狀態後將執行Hook方法
terminated(); -
TERMINATED:
terminated()方法執行完畢。
狀態的轉換
註釋中也對執行緒池狀態的轉換做出了詳細說明:
RUNNING -> SHUTDOWN On invocation of shutdown()
(RUNNING or SHUTDOWN) -> STOP On invocation of shutdownNow()
SHUTDOWN -> TIDYING When both queue and pool are empty
STOP -> TIDYING When pool is empty
TIDYING -> TERMINATED When the terminated() hook method has completed
我們通過一張狀態轉換圖來了解執行緒池狀態之間的轉換:

結合原始碼,可以看到執行緒池的狀態從RUNNING到TERMINATED其數值是單調遞增的,換句話說執行緒池從「活著」到「死透」所對應的數值是逐步增大,所以可以使用數值間的比較去確定執行緒池處於哪一種狀態。
使用執行緒池
我們已經對ThreadPoolExecutor有了一個整體的認知,現在可以建立並使用執行緒池了:
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 4, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>(6));
threadPoolExecutor.submit(() -> {
// 業務邏輯
});
這裡我使用最「簡單」的構造方法,我們看到線上程池中提交任務使用的是submit方法,該方法在抽象類AbstractExecutorService中實現:
public abstract class AbstractExecutorService implements ExecutorService {
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
}
submit的過載方法之間只有參數列的差別,實現邏輯是相同的,均是先封裝RunnableFuture物件,再呼叫ThreadPoolExecutor#execute方法。
問題解答:submit()和execute()方法有什麼區別?
execute方法
繼承自Executor介面的execute方法是執行緒池的關鍵方法:
public void execute(Runnable command) {
// 檢測待執行任務
if (command == null) {
throw new NullPointerException();
}
// 獲取主控狀態CTL
int c = ctl.get();
// STEP 1: 當工作執行緒數量小於核心執行緒時,執行addWorker方法
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true)) {
return;
}
c = ctl.get();
}
// 當工作執行緒數量大於核心執行緒數量時
// STEP 2: 首先判斷執行緒池是否處於執行狀態,接著嘗試新增到佇列中
if (isRunning(c) && workQueue.offer(command)) {
// 再次檢查執行緒池狀態
int recheck = ctl.get();
// 不再處於RUNNING,則從佇列中刪除當前任務,並執行拒絕策略
if (!isRunning(recheck) && remove(command)) {
reject(command);
} else if (workerCountOf(recheck) == 0) {
addWorker(null, false);
}
}
// STEP 3: 無法新增到佇列時,嘗試執行addWorker
else if (!addWorker(command, false))
// addWorker執行失敗,則執行拒絕策略
reject(command);
}
閱讀execute方法的原始碼時需要知道一個前提,addWorker方法會檢查執行緒池狀態和工作執行緒數量,並執行工作任務。接著來看execute方法的3種執行情況:
-
STEP 1:執行緒池狀態:RUNNING,工作執行緒數:小於核心執行緒數,此時執行
addWorker(command, true); -
STEP 2:執行緒池狀態:RUNNING,工作執行緒數:等於核心執行緒數,佇列:未飽和,新增到佇列中;
-
STEP 3:執行緒池狀態:RUNNING,工作執行緒數:等於核心執行緒數,佇列:已飽和,執行
addWorker(command, false)。
需要重點關注STEP 1的部分,還記得構造執行緒池最後的問題嗎?STEP 1便解釋了為什麼一個接一個的執行任務,依舊會建立出corePoolSize個執行緒。接著我們通過一張流程圖展示execute方法的執行流程:
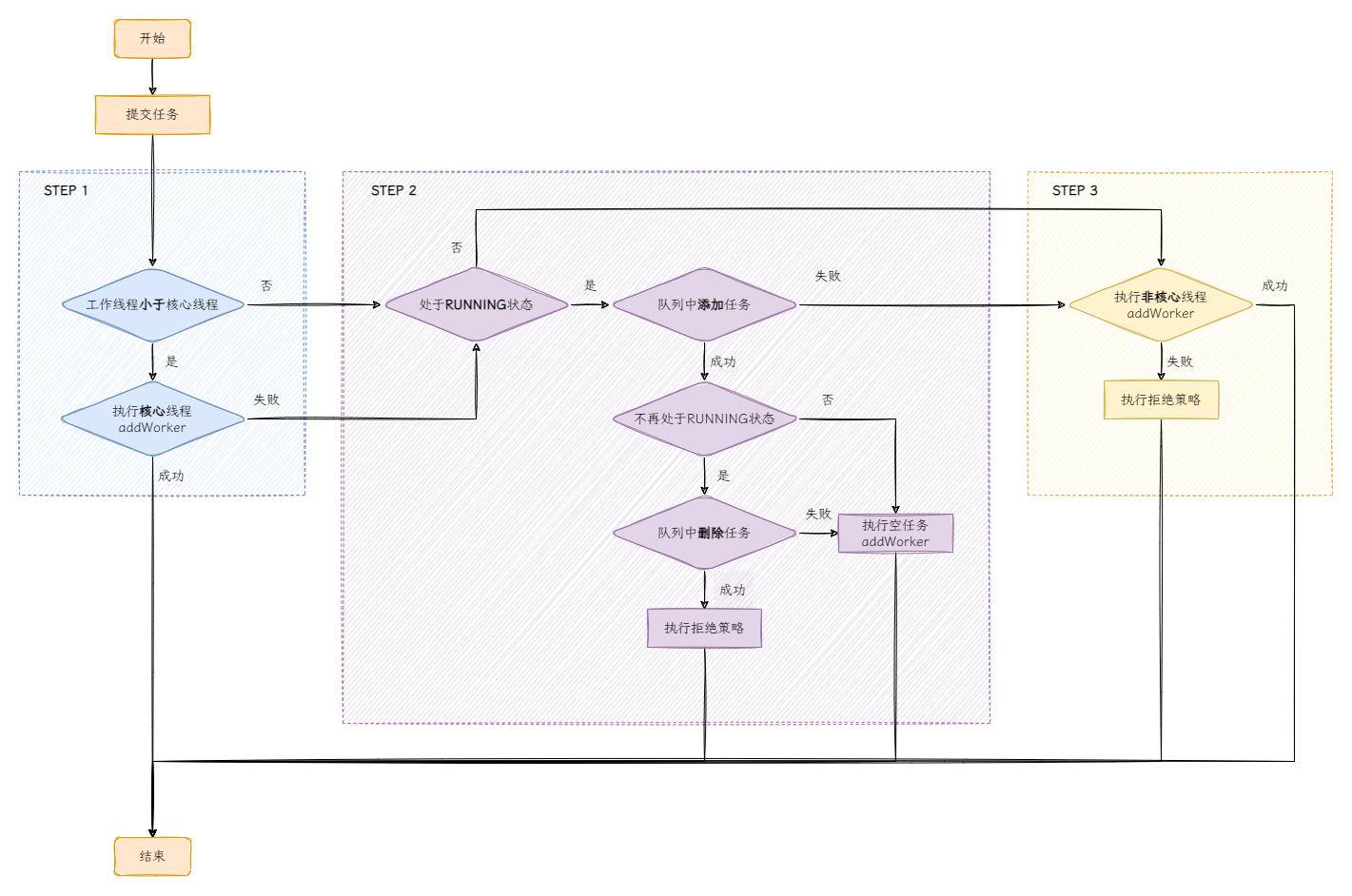
流程圖畫得比較「複雜」,因為有些判斷看似在一行中執行,實際上是藉助了&&運運算元短路的特性來決定是否執行,例如isRunning(c) && workQueue.offer(command)中,如果isRunning(c) == false則不會執行workQueue.offer(command)。
addWorker方法
private boolean addWorker(Runnable firstTask, boolean core)
返回值為布林型別表示是否成功執行,參數列中有兩個引數:
-
Runnable firstTask,待執行任務; -
boolean core,true表示最多允許建立corePoolSize個執行緒,false表示使用最多允許建立maximumPoolSize個執行緒。
在分析execute方法的過程中,我們提前「劇透」了addWorker方法的功能:
-
檢查執行緒池狀態和工作執行緒數量
-
執行工作任務
因此addWorker方法的原始碼部分我們分成兩部分來看。
Tips:再次強調本文使用Java 11原始碼進行分析,在addWorker方法的實現上Java 11與Java 8存在差異。
檢查執行緒池狀態和工作執行緒數量
第一部分是執行緒池狀態和工作執行緒數量檢查的原始碼:
retry:
// 獲取主控狀態CTL
for (int c = ctl.get();;) {
// 註釋1
// Java 11相對友好很多,減少了很多!的使用,看起來比較符合人的思維
// 這部分判斷可以分成兩部分:
// 1. 至少為SHUTDOWN狀態
// 2.條件3選1滿足:
// 2-1,至少為STOP狀態
// 2-2,firstTask不為空
// 2-3,workQueue為空
if (runStateAtLeast(c, SHUTDOWN) && (runStateAtLeast(c, STOP) || firstTask != null || workQueue.isEmpty())) {
return false;
}
for (;;) {
// core == true,保證工作執行緒數量小於核心執行緒數量
// core == false,保證執行緒數量小於最大執行緒數量
if (workerCountOf(c) >= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK)) {
return false;
}
// 增加工作執行緒數量並退出
if (compareAndIncrementWorkerCount(c)) {
break retry;
}
// 如果至少是SHUTDOWN狀態,則重新執行
c = ctl.get();
if (runStateAtLeast(c, SHUTDOWN)) {
continue retry;
}
}
}
註釋1的程式碼並不複雜,只是需要結合執行緒池在不同狀態下的處理邏輯來分析:
-
當狀態「至少」為SHUTDOWN時,什麼情況不需要處理?
-
新增新的任務(對應條件2-2)
-
佇列為空(對應條件2-3)
-
-
當狀態「至少」為STOP時,執行緒池應當立即停止,不接收,不處理。
Tips:執行緒池狀態的部分說執行緒池狀態從RUNNING到TERMINATED是單調遞增的,因此在Java 11的實現中才會出現runStateAtLeast方法。
執行工作任務
第二部分是執行工作任務的原始碼:
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 建立Worker物件
w = new Worker(firstTask);
// 從worker物件中獲取執行緒
final Thread t = w.thread;
if (t != null) {
// 上鎖
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int c = ctl.get();
// 執行緒池狀態檢查
// RUNNING狀態,或者「小於」STOP狀態(處理佇列中的任務)
if (isRunning(c) || (runStateLessThan(c, STOP) && firstTask == null)) {
// 執行緒狀態檢查
if (t.getState() != Thread.State.NEW) {
throw new IllegalThreadStateException();
}
// 將Worker物件新增到workers中
workers.add(w);
workerAdded = true;
int s = workers.size();
if (s > largestPoolSize) {
// 記錄執行緒池中出現過的最大執行緒數
largestPoolSize = s;
}
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
// 啟動執行緒
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted) {
// addWorker執行失敗
// addWorkerFailed中包含工作執行緒數減1的邏輯
addWorkerFailed(w);
}
}
return workerStarted;
結合兩部分程式碼,一個正向流程是這樣的:
-
檢查狀態:檢查是否允許建立
Worker,如果允許執行compareAndIncrementWorkerCount(c),CTL中工作執行緒數量+1; -
執行任務:建立
Worker物件,通過Worker物件獲取執行緒,新增到workers中,最後啟動執行緒。
回過頭看我們之前一直提到的工作執行緒,實際上是Worker物件,我們可以近似的將Worker物件和工作執行緒畫上等號。
問題解答:執行緒池中的執行緒是什麼時間建立的?
三調addWorker
execute方法中,有3種情況呼叫addWorker方法:
-
STEP 1:
addWorker(command, true) -
STEP 2:
addWorker(null, false) -
STEP 3:
addWorker(command, false)
STEP 1和STEP 3很好理解,STEP 1最多允許建立corePoolSize個執行緒,STEP 3最多允許建立maximumPoolSize個執行緒。STEP 2就比較難理解了,傳入了空任務然後呼叫addWorker方法。
什麼情況下會執行到addWorker(null, false)?
-
第1個條件:\(workerCount \geq corePoolSize\)。
-
第2個條件:
isRunning(c) && workQueue.offer(command) -
第3個條件:
workerCountOf(recheck) == 0
處於RUNNING狀態的條件不難理解,矛盾的是第1個條件和第3個條件。根據這兩個條件可以得到:\(corePoolSize \leq workCount = 0\),也就是說允許建立核心執行緒數為0的執行緒池。
接著我們來看addWorker(null, false)做了什麼?建立了Worker物件,新增到workers中,並呼叫了一次Thread.start,雖然沒有任何待執行的任務。
為什麼要建立一個Worker物件?別忘了,已經執行過workQueue.offer(command)了,需要保證執行緒池中至少有一個Worker,才能執行workQueue中的任務。
「工具人」Worker
實際上ThreadPoolExecutor維護的工作執行緒就是Worker物件,我們來看Worker類的原碼:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread;
Runnable firstTask;
volatile long completedTasks;
Worker(Runnable firstTask) {
setState(-1);
this.firstTask = firstTask;
// 通過預設執行緒工廠建立執行緒
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}
}
Worker繼承自AbstractQueuedSynchronizer,並實現了Runnable介面。
我們重點關注構造方法,尤其是this.thread = getThreadFactory().newThread(this),通過執行緒工廠建立執行緒,傳入的Runnable介面是誰?
是Worker物件本身,也就是說如果有worker.getThread().start(),此時會執行Worker.run方法。
Tips:
-
AbstractQueuedSynchronizer就是大名鼎鼎的AQS,Worker藉助AQS實現非重入獨佔鎖,不過這部分不是今天的重點; -
Woker物件與自身的成員變數thread的關係可謂是水乳交融,好好梳理下,否則會很混亂。
runWorker方法
runWorker方法傳入的是Worker物件本身,來看方法實現:
final void runWorker(Worker w) {
// 註釋1
Thread wt = Thread.currentThread();
// Worker物件中獲取執行任務
Runnable task = w.firstTask;
// 將Worker物件中的任務置空
w.firstTask = null;
w.unlock();
boolean completedAbruptly = true;
try {
// 註釋2
while (task != null || (task = getTask()) != null) {
w.lock();
// 執行緒池的部分狀態要中斷正在執行的任務
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted()) {
wt.interrupt();
}
try {
beforeExecute(wt, task);
try {
// 執行任務
task.run();
afterExecute(task, null);
} catch (Throwable ex) {
afterExecute(task, ex);
throw ex;
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
大家可能會對註釋1的部分比較迷惑,這個Thread wt = Thread.currentThread()是什麼鬼?別急,我帶你從頭梳理一下。
以使用執行緒池中的程式碼為例,假設是首次執行,我們看主執行緒做了什麼:

剛才也說了,Worker物件的執行緒在啟動後執行worker.run,也即是在runWorker方法中Thread.currentThread()是Worker物件的執行緒,並非主執行緒。
再來看註釋2的部分,第一次進入迴圈時,執行的task是Runnable task = w.firstTask,即初次判斷task != null,第二次進入迴圈時,task是通過task = getTask()獲取的。
執行緒池中,除了當前Worker正在執行的任務,還有誰可以提供待執行任務?答案是佇列,因此我們可以合理得猜測getTask()是獲取佇列中的任務。
getTask方法
private Runnable getTask() {
// 上次從佇列中獲取任務是否超時
boolean timedOut = false;
for (;;) {
// 執行緒池狀態判斷,某些狀態下不需要處理佇列中的任務
int c = ctl.get();
if (runStateAtLeast(c, SHUTDOWN) && (runStateAtLeast(c, STOP) || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// allowCoreThreadTimeOut是否允許核心執行緒超時銷燬,預設為false
// 通過allowCoreThreadTimeOut方法設定
// wc > corePoolSize為true表示啟用了非核心執行緒
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// wc > maximumPoolSize,可能的情況是因為同時執行了setMaximumPoolSize方法
// timed && timedOut為true時,表示上次獲取任務超時,當前需要進行超時控制
// wc > 1 || workQueue.isEmpty(),工作執行緒數量大於1或佇列為空
if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) {
// 減少工作執行緒數量
if (compareAndDecrementWorkerCount(c)) {
return null;
}
continue;
}
try {
// 註釋1
// 從佇列中獲取待執行任務
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
if (r != null) {
return r;
}
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
註釋1的部分有兩種獲取任務的方式:
-
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS),獲取隊首元素,如果當前佇列為空,則等待指定時間後返回null; -
workQueue.take(),獲取隊首元素,如果佇列為空,則一直等待,直到有返回值。
執行緒池只會在一種情況下使用workQueue.take,即不允許核心執行緒超時銷燬,同時執行緒池的工作執行緒數量小於核心執行緒數量,結合runWorker方法的原始碼我們可以得知,此時藉助了阻塞佇列的能力,保證runsWoker方法一直停留在task = getTask()上,直到getTask()返回響應的任務。
而在選擇使用workQueue.poll時存在兩種情況:
-
允許核心執行緒超時銷燬,即
allowCoreThreadTimeOut == true; -
當前工作執行緒數大於核心執行緒數,即執行緒池已經建立足夠數量的核心執行緒,並且佇列已經飽和,開始建立非核心執行緒處理任務。
結合runWorker方法的原始碼我們可以知道,如果佇列中的任務已經被消耗完畢,即getTask()返回null,則會跳出while迴圈,執行processWorkerExit方法。
processWorkerExit方法
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// runWorker執行失敗的場景
if (completedAbruptly) {
decrementWorkerCount();
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
// 從workers中刪除Worker
workers.remove(w);
} finally {
mainLock.unlock();
}
// 根據執行緒池狀態判斷是否結束執行緒池
tryTerminate();
int c = ctl.get();
// STOP之下的狀態,runWorker正常結束時completedAbruptly == false
// 保證至少有1個worker,用於處理佇列中的任務
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty()) {
min = 1;
}
if (workerCountOf(c) >= min){
return;
}
}
// runWorker異常退出時,即completedAbruptly == true
// 或者是workers存活少於1個
addWorker(null, false);
}
}
processWorkerExit方法做了3件事:
-
移除「多餘」的
Worker物件(允許銷燬的核心執行緒或者非核心執行緒); -
嘗試修改執行緒池狀態;
-
保證在至少存活1個
Worker物件。
Tips:我跳過了tryTerminate()方法的分析,對,是故意的~~
問題解答:執行緒池的底層原理是如何實現的?
銷燬非核心執行緒
設想一個場景:已經建立了足夠數量的核心執行緒,並且佇列已經飽和,仍然有任務提交時,會是怎樣的執行流程?
執行緒池建立非核心執行緒處理任務,當非核心執行緒執行完畢後並不會立即銷燬,而是和核心執行緒一起去處理佇列中的任務。那麼當所有的任務都處理完畢之後呢?
回到runWorker中,當所有任務執行完畢後再次進入迴圈,getTask中判斷工作執行緒數大於和核心執行緒數,此時啟用workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS),而keepAliveTime就是構建執行緒池時設定的執行緒最大空閒時間,當超過keepAliveTime後仍舊沒有獲得任務返回null,跳出runWorker的迴圈,執行processWorkerExit銷燬非核心執行緒。
ThreadPoolExecutor拾遺
目前我們已經詳細分析了執行緒池的執行流程,這裡我會補充一些前文未涉及到的內容,因為是補充內容,所以涉及不會詳細的解釋原始碼。
預建立執行緒
我們在提到執行緒池的優點時會特別強調一句,池內儲存了建立好的資源,使用時直接取出,但執行緒池好像依舊是首次接到任務後才會建立資源啊?
實際上,執行緒池提供prestartCoreThread方法,用於預建立核心執行緒:
public boolean prestartCoreThread() {
return workerCountOf(ctl.get()) < corePoolSize && addWorker(null, true);
}
如果你的程式需要做出極致的優化,可以選擇預建立核心執行緒。
關閉和立即關閉
ThreadPoolExecutor提供了兩個關閉的功能shutdown和shutdownNow:
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(SHUTDOWN);
// 中斷空閒執行緒
interruptIdleWorkers();
// ScheduledThreadPoolExecutor的hook
onShutdown();
} finally {
mainLock.unlock();
}
tryTerminate();
}
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP);
// 中斷所有執行緒
interruptWorkers();
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
兩者的差別還是很明顯的:
-
shutdown將執行緒池的狀態改為SHUTDOWN,而shutdownNow則改為STOP; -
shutdown不返回佇列中的任務,而shutdownNow返回佇列中的任務,因為STOP狀態不會再去執行佇列的任務; -
shutdown中斷空閒執行緒,而shutdownNow則是中斷所有執行緒。
從實現效果上來看關閉shutdown會更「溫和」一些,而立即關閉shutdownNow則更為「強烈」,彷彿語氣中帶著不容置疑。
拒絕策略
執行緒池不會無條件的接收任務,有兩種情況下它會拒絕任務:
-
核心執行緒已滿,新增到佇列後,執行緒池不再處於RUNNING狀態,此時從佇列刪除任務,並執行拒絕策略;
-
核心執行緒已滿,佇列已滿,非核心執行緒已滿,此時執行拒絕策略。
Java提供了RejectedExecutionHandler介面:
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
因此,我們可以通過實現RejectedExecutionHandler介面,完成自定義拒絕策略。另外,Java中也提供了4種預設拒絕策略:
-
AbortPolicy:直接丟擲異常; -
CallerRunsPolicy:提交任務的執行緒執行; -
DiscardOldestPolicy:丟棄佇列中最先加入的執行緒; -
DiscardPolicy:直接丟棄,就是啥也不幹。
原始碼非常簡單,大家自行閱讀即可。
Java提供了哪些執行緒池
如果不想自己定義執行緒池,Java也貼心的提供了4種內建執行緒池,預設執行緒池通過Executors獲取。
Java的命名中,s字尾通常是對應工具類,通常提供大量靜態方法,例如:Collections之於Collection。所以即便屬於Executor體系中的一員,但卻沒辦法在「族譜」上出現,打工人的悲慘命運。
FixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory);
}
固定大小執行緒池,核心執行緒數和最大執行緒數一樣,看起來都還不錯,主要的問題是通過無參構造器建立的LinkedBlockingQueue,它允許的最大長度是Integer.MAX_VALUE。
Tips:這也就是為什麼《阿里巴巴Java開發手冊》中不推薦的原因。
CachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), threadFactory);
}
可以說是「無限大」的執行緒池,接到任務就建立新執行緒,另外SynchronousQueue是非常特殊的佇列,不儲存資料,每個put操作對應一個take操作。我們來分析下實際可能發生的情況:
-
前提:大量並行湧入
-
提交第一個任務,進入佇列,判斷核心執行緒數為0,執行
addWorker(null, false),對應execute的SETP 2; -
提交第二個任務,假設第一個任務未結束,第二個任務直接提交到佇列中;
-
提交第三個任務,假設第一個任務未結束,無法新增到佇列中,執行
addWorker(command, false)對應execute的SETP 3。
也就是說,只要提交的夠快,就會無限建立執行緒。
SingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory));
}
只有一個執行緒的執行緒池,問題也是在於LinkedBlockingQueue,可以「無限」的接收任務。
ScheduledExecutor
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1));
}
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1, threadFactory));
}
用來執行定時任務,DelegatedScheduledExecutorService是對ScheduledExecutorService的包裝。
在Executor體系的「族譜」中,是有體現到ScheduledExecutorService和ScheduledThreadPoolExecutor的,這部分留給大家自行分析了。
除了以上4種內建執行緒池外,Java還提供了內建的ForkJoinPool:
public static ExecutorService newWorkStealingPool(int parallelism) {
return new ForkJoinPool(parallelism, ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool(Runtime.getRuntime().availableProcessors(), ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true);
}
這部分是Java 8之後提供的,我們暫時按下不表,放到後期關於Fork/Join框架中詳細解釋。
問題解答:Java提供了哪些執行緒池?
合理設定執行緒池
通常我們在談論合理設定執行緒池的時候,指的是設定執行緒池的corePoolSize和maximumPoolSize,合理的設定能夠最大化的發揮執行緒池的能力。
我們先來看美團技術團隊的調研結果:

無論是哪種公式,都是基於理論得出的結果,但往往理論到工程還有很長得一段路要走。
按照我的經驗,合理的設定執行緒池可以彙總成一句話:根據理論公式預估初始設定,隨後對核心業務進行壓測調整執行緒池設定。
Java也提供了動態調整執行緒池的能力:
public void setThreadFactory(ThreadFactory threadFactory);
public void setRejectedExecutionHandler(RejectedExecutionHandler handler);
public void setCorePoolSize(int corePoolSize);
public void setMaximumPoolSize(int maximumPoolSize);
public void setKeepAliveTime(long time, TimeUnit unit);
除了workQueue都能調整,本文不討論執行緒池動態調整的實現。
Tips:
-
調研結果源自於《Java執行緒池實現原理及其在美團業務中的實踐》;
-
該篇文章中也詳細的討論了動態化執行緒池的思路,推薦閱讀。
結語
執行緒池的大部分內容就到這裡結束了,希望大家夠通過本篇文章解答絕大部分關於執行緒池的問題,帶給大家一些幫助,如果有錯誤或者不同的想法,歡迎大家留言討論。不過今天的還是遺留了兩點內容:
-
阻塞佇列
-
Fork/Join框架
這些我會在後續的文章中和大家分享。
好了,今天就到這裡了,Bye~~