UTF-8編碼
介紹 UTF-8 編碼
UTF-8 是一種針對 Unicode 的可變長度字元編碼。
針對 Unicode:UTF-8 是 Unicode 的實現方式之一。相當於 Unicode 規定了字元對應的程式碼值,這個程式碼值需要轉換為位元組序列的形式,用於資料儲存、傳輸。程式碼值到位元組序列的轉換工作由 UTF-8 來完成。
可變長度字元編碼:UTF-8 使用一至四個位元組對 Unicode 字元集中的所有有效程式碼點進行編碼。
- UTF-8 使用 1 個位元組表示 ASCII 字元;
- UTF-8 使用 2 個位元組表示帶有附加符號的拉丁文、希臘文等;
- UTF-8 使用 3 個位元組表示其他基本多文種平面(BMP)中的字元(包含了大部分常用字,如大部分的漢字);
- UTF-8 使用 4 個位元組表示 Unicode 輔助平面的字元。
技術是為了解決問題而生的,UTF-8 編碼是為了解決什麼問題而設計的呢?UTF-8 是為了相容 ASCII 編碼而設計的。
ASCII 編碼使用 1 個位元組表示 ASCII 字元,而 Unicode 最初規定使用 2 個位元組來表示所有的 Unicode 字元。如果使用 2 個位元組來表示 ASCII 字元的話,那麼含有大量 ASCII 字元的文字將浪費大量的儲存空間。
UTF-8 編碼使用 1 個位元組來表示 ASCII 字元,而且字面與 ASCII 碼的字面一一對應,這使得原來處理 ASCII 字元的軟體無須或只須做少部分修改,即可繼續使用。
UTF-8 編碼的規則
Unicode 和 UTF-8 之間的轉換關係表(x 字元表示碼點佔據的位)
| 碼點的位數 | 碼點起值 | 碼點終值 | Byte 1 | Byte 2 | Byte 3 | Byte 4 | Byte 5 | Byte 6 | |
|---|---|---|---|---|---|---|---|---|---|
| 7 | U+0000 | U+007F | 1 | 0xxxxxxx | |||||
| 11 | U+0080 | U+07FF | 2 | 110xxxxx | 10xxxxxx | ||||
| 16 | U+0800 | U+FFFF | 3 | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| 21 | U+10000 | U+1FFFFF | 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| 26 | U+200000 | U+3FFFFFF | 5 | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| 31 | U+4000000 | U+7FFFFFFF | 6 | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |

UTF-8 編碼的規則:
- 在 ASCII 碼範圍內的程式碼點,UTF-8 使用 1 個位元組表示。
- 大於 ASCII 碼範圍的程式碼點,UTF-8 使用多個位元組表示。UTF-8 使用第一個位元組的前幾位表示該 Unicode 字元的位元組長度(第一個位元組的開頭 1 的數目就是該 Unicode 字元的位元組長度),其餘位元組的前兩位固定為 10,作為標記
- 如果第一個位元組的前兩位為 1,第三位為 0(110xxxxx),則表示 UTF-8 使用 2 個位元組表示該 Unicode 字元;
- 如果第一個位元組的前三位為 1,第四位為 0(1110xxxx),則表示 UTF-8 使用 3 個位元組表示該 Unicode 字元;
- 依此類推;
- 如果第一個位元組的前六位為 1,第七位為 0(1111110x),則表示 UTF-8 使用 6 個位元組表示該 Unicode 字元;
UTF-8 編碼的位元組含義:對於 UTF-8 編碼中的任意位元組 B:
- 如果 B 的第一位為 0(0xxxxxxx),則 B 獨立的表示一個 ASCII 字元;
- 如果 B 的第一位為 1,第二位為 0(10xxxxxx),則 B 為一個多位元組表示的字元中的一個位元組;
- 如果 B 的前二 / 三 / 四 / 五 / 六位為 1,其餘位為 0,則 B 為二 / 三 / 四 / 五 / 六個位元組表示的字元中的第一個位元組。
UTF-8 編碼範例
Unicode/UTF-8-character table (utf8-chartable.de)
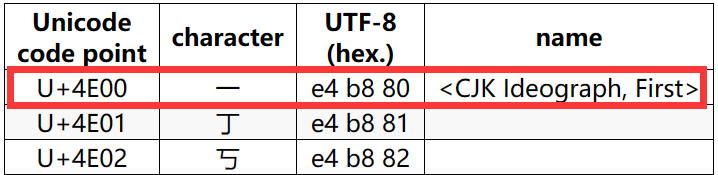
通過 UTF-8 編碼表,我們可以看到中文字元 「一」 的 Unicode 程式碼點為 "U+4E00",UTF-8 編碼結果為 "e4 b8 80",
對中文字元 「一」 進行 UTF-8 編碼,是如何得到 "e4 b8 80" 的呢?我們下面來看。
"4E00" 的二進位制表示為 "0100 1110 0000 0000"。
UTF-8 使用 3 個位元組表示常用的漢字,因此中文字元對應的位元組序列格式為:"1110xxxx 10xxxxxx 10xxxxxx"
於是中文字元 「一」 的 UTF-8 編碼結果為 "11100100 10111000 10000000",它的十六進位製表示為 "e4 b8 80"
public static void main(String[] args) throws UnsupportedEncodingException {
byte[] bytes = "一".getBytes("UTF-8");
// [-28, -72, -128]
System.out.println(Arrays.toString(bytes));
}
UTF-8 編碼的優劣侷限
UTF-8 編碼的優點
UTF-8 和 ASCII 相容:ASCII 是 UTF-8 的一個子集。因為一個純 ASCII 字串也是一個合法的 UTF-8 字串,所以現存的 ASCII 文字不需要轉換。為傳統的擴充套件 ASCII 字元集設計的軟體通常可以不經修改或很少修改就能與 UTF-8 一起使用。
任何面向位元組的字串搜尋演演算法都可以用於 UTF-8 的資料(只要輸入僅由完整的 UTF-8 字元組成)。UTF-8 可以保證一個字元的位元組序列不會包含在另一個字元的位元組序列中。而有些比較舊的可變長度字元編碼(如Shift JIS)沒有這個特質,故它們的字串搜尋演演算法變得相當複雜。
UTF-8 字串可以由一個簡單的演演算法可靠地識別出來。由於 UTF-8 位元組序列的設計,如果一個疑似為字串的序列被驗證為 UTF-8 編碼,那麼我們可以有把握地說它是 UTF-8 字串。一個字串在任何其它編碼中表現為合法的 UTF-8 的可能性很低,可能性隨著字串長度的增長而減小。 舉例說明,字元值 C0、C1、F5 至 FF 從來沒有出現。為了更好的可靠性,可以使用正規表示式來統計非法過長和替代值(可以檢視W3 FAQ: Multilingual Forms上的驗證 UTF-8 字串的正規表示式)。
UTF-8 編碼可以通過遮蔽位 和 移位元運算快速讀寫:遮蔽位是指將位元組的高位置零,以便獲取低位的值;移位元運算是指將位元組的低位移動到高位,以便獲取高位的值。這樣,可以快速讀取和寫入 UTF-8 編碼的字元。
UTF-8 編碼的缺點
UTF-8 編碼不利於使用正規表示式進行讀音檢索
正規表示式可以進行很多高階的英文模糊檢索。比如,[a-h] 表示 a 到 h 間的所有字母。
同樣 GBK 編碼的中文也可以這樣利用正規表示式,比如在只知道一個字的讀音而不知道怎麼寫的情況下,也可用正規表示式檢索,因為 GBK 編碼是按讀音排序的。雖然正規表示式檢索並未考慮中文的多音字,但是由於中文的多音字數量不多,不少多音字還是同音不同調型別的多音字,所以大多數情況下正規表示式檢索是還可以接受的。
但是 Unicode 漢字不是按讀音排序的,它是按部首排序,所以不利於用正規表示式進行讀音檢索。在只知道一個字的部首而不知道如何發音的情況下,UTF-8 可用正規表示式檢索而 GBK 不行。
UTF-8 的 ASCII 字元只佔用一個位元組,比較節省空間,但是更多字元的 UTF-8 編碼佔用的空間就要多出1/2,特別是中文、日文和韓文(CJK)這樣的方塊文字,它們大多需要三個位元組。
無法根據 Unicode 字元數判斷出 UTF-8 文字佔用的位元組數。因為 UTF-8 是一種可變長度字元編碼。
參考資料
本文來自部落格園,作者:真正的飛魚,轉載請註明原文連結:https://www.cnblogs.com/feiyu2/p/UTF-8.html