高效字串匹配演演算法——BM 演演算法詳解(C++)
定義
BM 演演算法是由 Boyer 和 Moore 兩人提出的一種高效的字串匹配演演算法,被認為是一種亞線性演演算法(即平均的時間複雜度低於線性級別),其時間效率在一般情況下甚至比 KMP 還要快 3 ~ 5 倍。
原理
BM 演演算法跟其他的字串匹配演演算法相比,其中一個不同之處是在比對字元的時候,掃描的順序不是從左往右,而是從右往左的。
暴力匹配
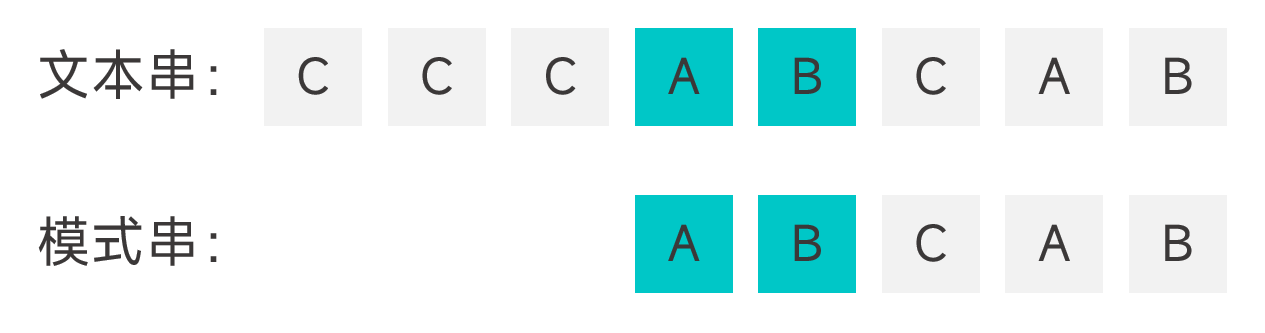
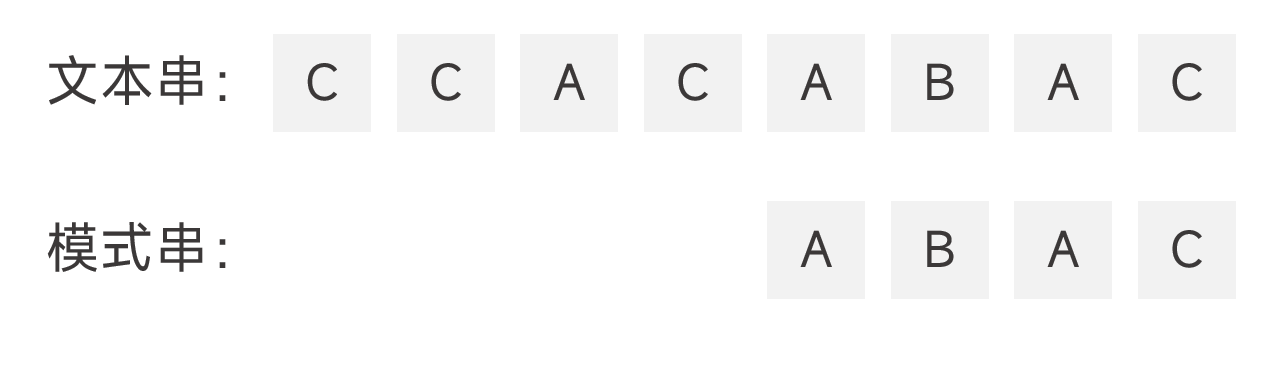
所謂暴力匹配,就是從右向左比對字元,當遇到不匹配的字元時,就將模式串往右移動一個字元,迴圈執行,直到所有字元都能匹配上(成功),或模式串的右邊界超過了文字串的右邊界(失敗)。如圖:



程式碼實現:
int brute(std::string t, std::string p) {
const int m = p.length(), n = t.length();
int align; // 模式串的對齊位置
int i; // 模式串中的下標
// 迴圈執行以下步驟,直到全部字元比對成功或模式串的右邊界超過了文字串的右邊界
for (align = 0; align + i < n && i >= 0; align++) {
// 從右向左逐個比對,直到全部字元比對成功或某個字元比對失敗
for (i = m - 1; i >= 0 && t[align + i] == p[i]; i--);
// 如果全部字元比對成功,則退出迴圈,否則就將模式串向右移動一個字元
if (i < 0) break;
}
return i < 0 // 如果比對成功的話
? align // 就返回模式串的對齊位置
: -1; // 否則就返回-1
}
設文字串的長度為 n,模式串的長度為 m,那麼顯然暴力匹配演演算法的時間複雜度為 \(O(mn)\)。
BM 演演算法利用了壞字元規則和好字尾規則,排除掉肯定不可能匹配上的位置,使得匹配失敗的時候模式串能夠跳躍儘可能多的距離,時間複雜度能夠大大降低。
壞字元規則
如果某次掃描比對的時候發現匹配失敗,那麼就稱文字串中匹配失敗的那個字元為壞字元(Bad character)。
所謂壞字元規則(Bad character shift),就是指當遇到壞字元的時候,在模式串中尋找能夠與之匹配的字元並將兩者對齊。


如果模式串中找不到能夠與之匹配的字元,那就直接將模式串越過匹配失敗的位置。


如果模式串中有多個字元能夠與壞字元匹配上,那就將最右邊的那個字元與壞字元對齊,這樣就能避免遺漏對齊位置。


好字尾規則
如果某次掃描比對的時候發現匹配失敗,那麼就稱模式串中匹配失敗的那個字元右側比對成功的字元所構成的字尾稱為好字尾(Good suffix)。
所謂好字尾規則(Good suffix shift),分為以下3種情況:
- 模式串中有能夠與好字尾匹配上的子串,將該子串與好字尾對齊。如果有多個能夠與好字尾匹配上的子串,選擇最靠右的那一個。


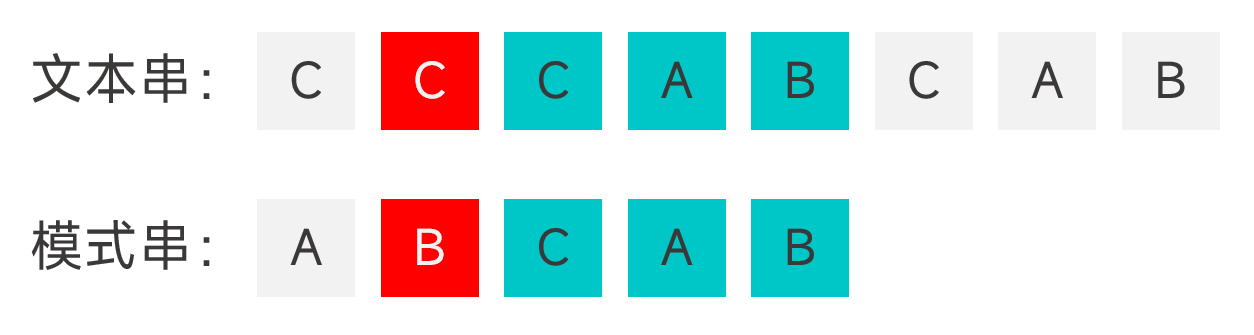
- 模式串中沒有能夠與好字尾匹配上的子串,但是模式串的某個字首能夠與好字尾的真字尾匹配,將該字首的最後一個字元與好字尾的最後一個字元對齊。
- 模式串中沒有能夠與好字尾匹配上的子串,且沒有哪個字首能夠與好字尾的真字尾匹配,直接將模式串越過好字尾的位置。

演演算法步驟
整個 BM 演演算法的步驟為:從後往前比對字元,如果遇到不匹配的字元,看壞字元規則和好字尾規則中哪個規則會使得模式串移動的距離更大,並相應的移動。
舉例:

(其中x為無關緊要的字元)
第一輪比對在倒數第2個字元的位置失敗了:

此時,分別運用好字尾規則和壞字元規則,發現運用壞字元規則移動的距離更遠:

重新開始新一輪的比對:

再次運用這兩個規則,發現好字尾規則移動的距離更遠。

開始第三輪比對,發現這次比對成功了。

至此,演演算法宣告結束。
程式碼實現
為了能夠快速得到某次比對失敗時,按照這兩個規則,模式串需要移動的位置,我們需要對模式串進行預處理,構建兩個輔助陣列。
預處理:構造 bc 陣列
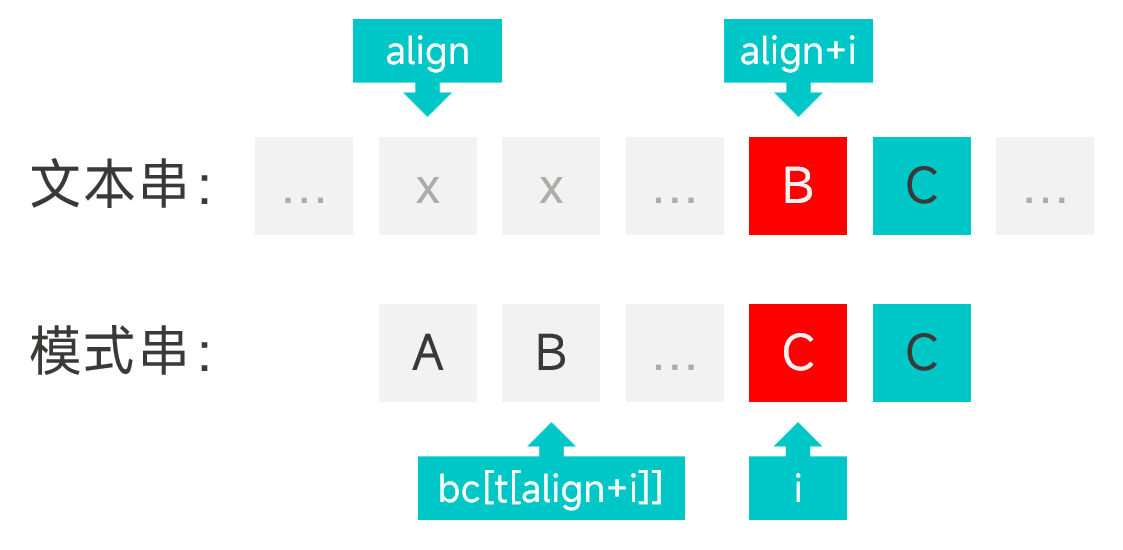
構造 bc 陣列用於壞字元規則,其中 bc[c] 表示壞字元 c 在模式串中的最大下標。如果模式串中不存在字元 c 則為 -1,這樣才能確保模式串移動的時候能夠剛好越過壞字元的位置。當然陣列的大小要足夠大,這樣才能容納文字串中的所有字元。
這樣,當遇到壞字元時,假設模式串中匹配失敗的字元的下標為 i,模式串的頭部在文字串中的對齊位置為 align,那麼模式串需要移動的距離為 i - bc[t[align + i]],如圖。
程式碼實現:
void buildBC(std::string &p, int range) { // range為字元集大小。對於英文的話,128就足夠了
const int m = p.length();
std::vector<int> bc(range, -1);
for (int i = 0; i < m; ++i) {
char c = p[i];
bc[c] = i;
}
return bc;
}
為什麼是從左往右呢,因為這樣的話,對於同一個字元,如果存在多個下標,大的下標才能覆蓋小的下標。
預處理:構造 gs 陣列
構造 gs 陣列用於好字尾規則,其中 gs[i] 表示如果模式串中下標為i的字元與文字串中的相應字元比對失敗的話,為了使好字尾對齊,模式串應該移動的距離。
然而,如果我們直接構造的話,時間成本為 \(O(m^3)\)!這顯然是不能接受的,於是我們需要用「空間換時間」的策略將時間成本降低。
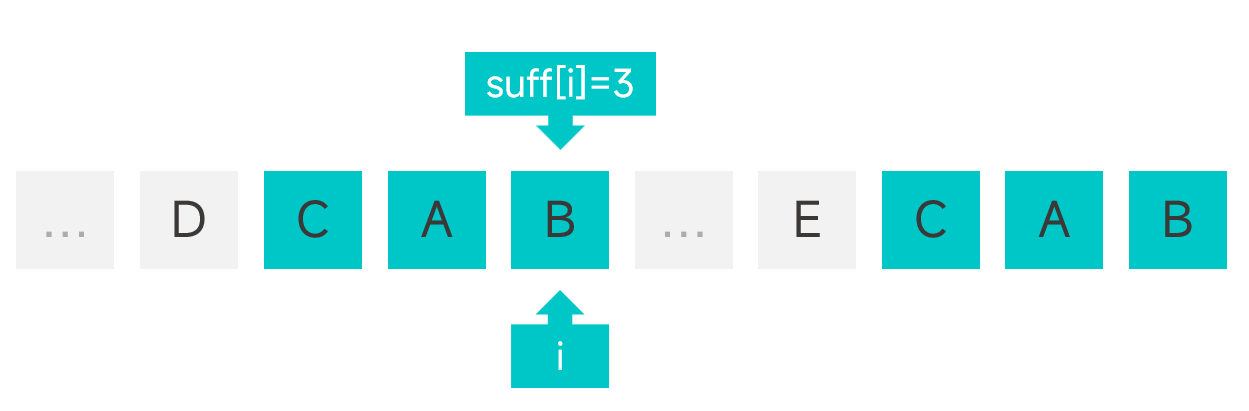
為此我們需要引入另外一個輔助陣列 suff,其中 suff[i] 為模式串中下標為i的字元左側(包括下標為 i 的字元)最多能有多少個字元能夠與模式串的字尾匹配,如圖:
程式碼如下:
std::vector<int> buildSuff(std::string &p) {
const int m = p.length();
std::vector<int> suff(m, 0);
suffix[m - 1] = m; // 對於最後一個字元,顯然該字元以左的所有字元都能與模式串的字尾匹配
for (int i = m - 2; i >= 0; i--) { // 從右往左掃描
int j = i, k = m - 1;
for (; j >= 0 && p[j] == p[k]; j--, k--); // 雙指標同步向左掃描
suffix[i] = i - j;
}
return suff;
}
時間複雜度為 \((n^2)\),但是最壞情況只有當模式串所有字元全都一樣的時候才會出現,一般情況下只會比 \(O(n)\) 略微多一點點,因此是可以接受的。
然後我們就可以利用 suff 陣列求得 gs 陣列了。構建 gs 陣列的部分也有講究。
我們首先需要計算第 3 種情況,然後是第二種,最後是第一種。為什麼呢,因為如果同一個字元同時滿足以上三種情況中的至少 2 種的話,位移距離:第三種情況 > 第二種 > 第一種,為了不遺漏對齊位置,我們要選擇最靠右的那個好字尾,那隻能用小的位移距離覆蓋大的位移距離。
第三種情況比較簡單,直接全都設為 m 就可以了。(C++ 裡面這一步在初始化的時候就可以完成)
std::vector<int> gs(m, m);
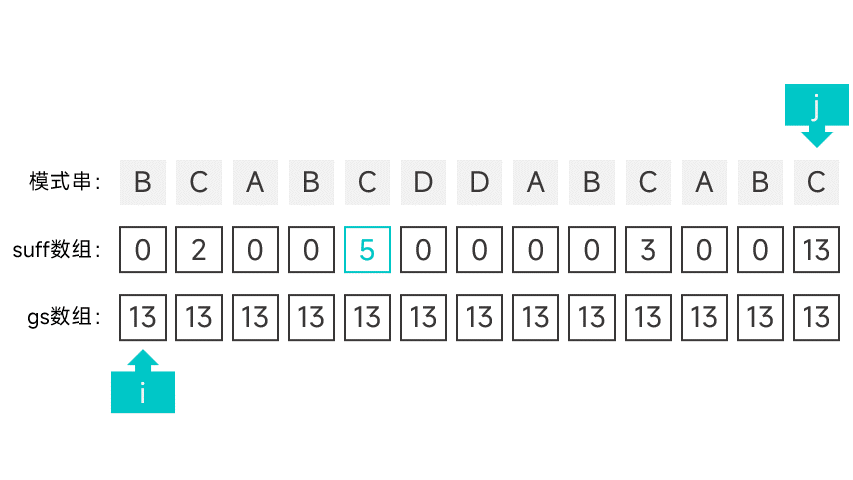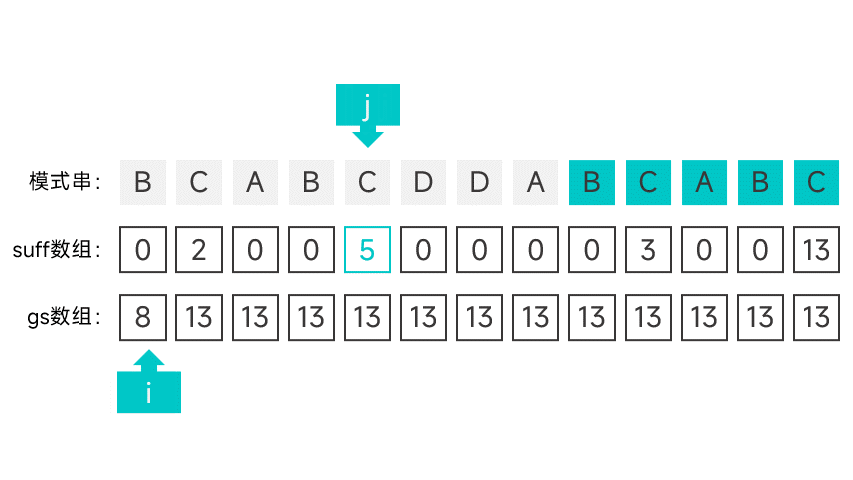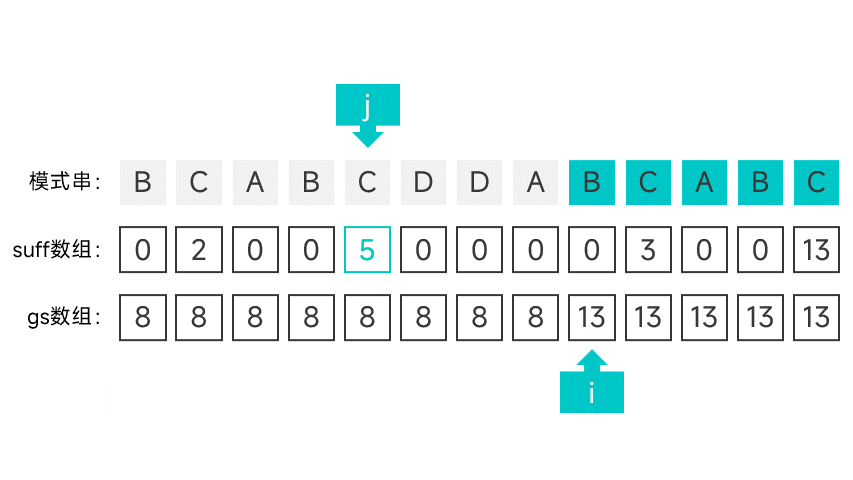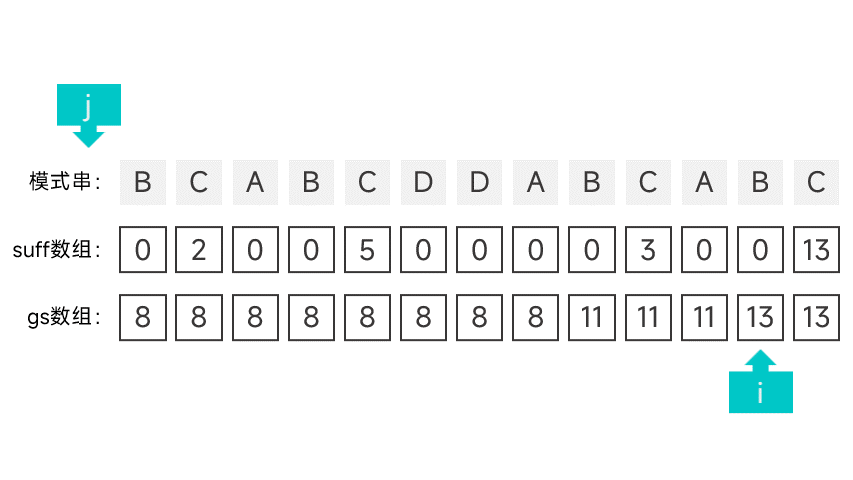
第二種情況有點講究,首先需要維護一個指標 i,初始時指向模式串的第一個字元。從右往左掃描字串,根據對應的 suff 陣列項判斷是否滿足第二種情況。怎麼判斷呢,看圖就知道了:

如果某個字元的 suff 陣列項剛好等於下標 + 1 的話(此時的陣列項記作 sufLen),那就說明該字元以左的所有字元組成的字首都能與模式串的字尾匹配。如果該字尾為某次比對中的好字尾的字尾,那就說明符合第二種情況。這就說明模式串中倒數第 sufLen 個字元(也就是下標為 m - suflen 的字元)的左邊某個字元如果發生匹配失敗,模式串應該右移 m - sufLen 個字元。
如果遇到符合第二種情況的字元的話,就將指標 i 指向的字元的 gs 陣列項設為 m - suflen,並向後移動一個字元,直到指標指向了 m - sufLen。
繼續向左掃描,重複以上操作,直到掃描到模式串的最左端。
動畫表示:
程式碼實現:
for (int i = 0, j = m - 1; j >= 0; j--) {
int sufLen = suff[j];
if (sufLen == j + 1) {
for (; i < m - sufLen; i++) {
if (gs[i] == m) { // 加上這一句條件判斷的目的是為了防止重複設定
gs[i] = m - sufLen;
}
}
}
}
有人會問,為什麼是從右向左掃描字串呢,是因為如果存在多個字元滿足第二種情況,那必然是右邊字元的 sufLen 大於左邊字元的 sufLen。sufLen 越大,m - sufLen 越小。而如果某個字元發生匹配失敗需要用到第二種情況的話,那必然優先選擇 m - sufLen 小的那個,也就是 sufLen 大的那個。那為什麼不像 bc 陣列和 suff 陣列構建演演算法那樣採用 「大的覆蓋小的」 的方法呢,是因為這樣的話每次都要設定一大片字元的 gs,反而會使時間複雜度上升到 \(O(n^2)\),不划算。
最後再來看第一種情況,從左往右掃描模式串,根據掃描到的字元的下標及 suff 陣列項可以方便的求出對應壞字元的下標及 gs 陣列項,如圖:
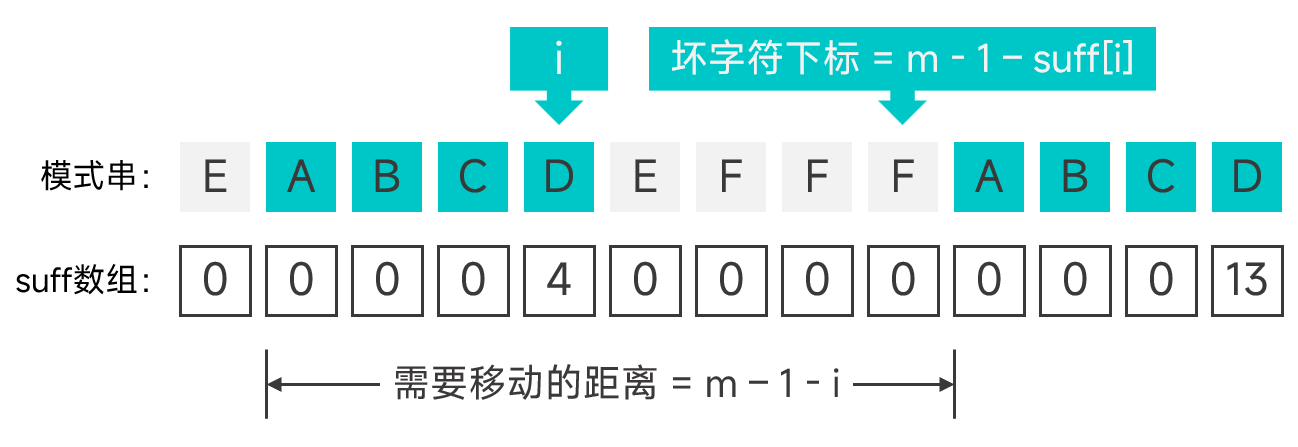
程式碼實現:
for (int i = 0; i < m - 1; ++i) {
int sufLen = suff[i];
gs[m - 1 - sufLen] = m - 1 - i;
}
至此,通過 suff 陣列構建 gs 陣列的完整實現程式碼:
std::vector<int> buildGS(std::string &p) {
const int m = p.length();
auto suff = buildSS(p);
std::vector<int> gs(m, m);
for (int i = 0, j = m - 1; j >= 0; j--) {
int sufLen = suffix[j];
if (sufLen == j + 1) {
for (; i < m - sufLen; i++) {
if (gs[i] == m) {
gs[i] = m - sufLen;
}
}
}
}
for (int i = 0; i < m - 1; ++i) {
int sufLen = suffix[i];
gs[m - 1 - sufLen] = m - 1 - i;
}
return gs;
}
主演演算法實現
int match(std::string t, std::string p, int range) {
const int m = p.length(), n = t.length();
// 兩個預處理陣列
auto bc = buildBC(p, range);
auto gs = buildGS(p);
int align = 0; // 模式串的對齊位置
int i = m - 1; // 模式串中的下標
while (align + i < n && i >= 0) {
for (; i >= 0 && t[align + i] == p[i]; i--); // 從右往左比對
if (i < 0) break; // 比對成功就退出迴圈
// 以下處理比對失敗的情況
int distBc = i - bc[t[align + i]]; // 根據壞字元規則得到的移動距離
int distGs = gs[i]; // 根據好字尾規則得到的移動距離
align += std::max(distBc, distGs); // 模式串的位移距離取兩者之間的較大者
i = m - 1; // 重新開始新一輪的比對
}
return i < 0 ? align : -1;
}
複雜度分析
空間複雜度
不計文字串和模式串本身所佔用的空間,演演算法的空間複雜度為 \(O(m + |\Sigma|)\),其中 m 為模式串的長度,\(|\Sigma|\) 為字元集的大小。其中 bc 陣列所佔用的空間為 \(O(|\Sigma|)\),gs 陣列則為 \(O(m)\)。
時間複雜度
最好:\(O(n/m)\),最壞:\(O(n+m)\),其中 n 和 m 分別為文字串和模式串的長度。
最好情況的一個範例:
文字串:AAAAAA...AAAA
模式串:AAB
每次比對,都會在倒數第一個字元發生匹配失敗。按照壞字元規則,模式串應該向右移動 m 個字元。所以,模式串的移動次數最多為 n / m。而每次比對的次數都是 1 次,因此這種情況下的時間複雜度為 \(O(n/m)\)。
最壞情況的一個範例:
文字串:AAAAAA...AAAA
模式串:BAA
每次比對,都會在第一個字元發生匹配失敗。按照好字尾規則,模式串應該向右移動 m 個字元。所以,模式串的移動次數最多為 n / m。而每次比對的次數都是 m 次,因此這種情況下的時間複雜度為 \(O(n/m*m)=O(n)\)。
本文來自部落格園,作者:YVVT_Real,轉載請註明原文連結:https://www.cnblogs.com/YWT-Real/p/17120732.html