小波去噪演演算法的簡易實現及其擴充套件(小波銳化、高斯拉普拉斯金字塔去噪及銳化)之二。
上一篇文章談及了GIMP裡實現的小波分解,但是這僅僅是把影象分解為多層的資料,如果快速的獲取分解資料以及後續怎麼利用這些資料,則是本文的重點。
一、我們先來看看演演算法速度的優化問題。
原始的GIMP實現需要將影象資料轉換為浮點數後,然後進行各級的模糊和圖層混合,這樣得到的結果是比較精確的,但是存在兩個方面的問題,一個是佔用了較多的記憶體,因為GIMP這個版本的小波分解各層是沒有改變資料的尺寸的,因此,如果使用浮點,佔用的記憶體要比位元組版本的大四倍,而且和層數有著密切的關係。第二個是浮點的處理還是稍微慢了點,雖然對現在的CPU來說,浮點數更易用SIMD指令集優化。但是如果有更好的資料型別的話,使用SIMD可以獲得更高的計算速度。
我們知道,位元組版本的模糊可以獲得很高的計算效率,這個場景的模糊是否可以使用呢,我個人分析認為,這個版本的演演算法已經不適合用位元組版本的模糊了,原因主要是精度太低了,因為他每次的結果都和上一次的模糊相關,而我們通過GIMP的可是化介面可以看到,中間的每一個層很多畫素都是靠近127的,這就說明細節方面的資訊都是很小的數值。
個人覺得,對於這個演演算法,我們可以把資料放大到unsigned short範圍,比如把原始的畫素值都擴大256倍,然後進行模糊,這樣模糊的精度就會大幅的提高,比如原始的9的畫素的加權累加值(歸一化後的權重)如果是100.3,那麼由於位元組版本取整的原因,最後的返回值為100,放大256倍後,則累加值變為25676.8,四捨五入取整後則為25677,而非100放大256倍的25600了,這樣多次模糊的精度就可以加以充分的保證(和浮點數比較還是有差異,但不影響結果)。
我們在稍微觀察下上一篇文章我們所提到的3*3的權重:

如果我們每個係數都放大16倍,我們會得到非常優化的一組權重係數:
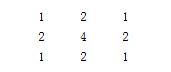
可以看到,權重係數裡全是1、2、4,這種係數如果被乘數是整形的話,都可以直接用移位實現,而放大16倍最後的除法,也可以直接由右移實現,那這種計算過程就完全避免了乘法,效率可想而知可以得到極大的提高。
我們在考慮一種特別的優化,因為權重整形化後的累加值是16,那麼如果每個元素的最大值不超過4096,則累計值也就不會超過65536,這個時候如果是用普通C語言實現,其實沒有啥區別,但是我們知道SIMD指令確有所不同,他針對不同的資料型別有不同的乘法和加法指令,其所能計算的覆蓋範圍也不同,如果能用16位元表達,則儘量用16位元表達。因此,考慮影象資料的特殊性,如果我們只把他們的資料範圍擴大16倍,則不會超出4096的範圍,就可以滿足前面的這個假設。
放大16倍是否能滿足精度的需求呢,沒有具體理論的分析啊,個人覺得啊,至少在層數不大於4層時,差異不會很大,大於4層,也應該可以接受,留待實踐檢測吧。
對於上一篇文章所說到的取樣點位置的問題,我們必須考慮邊緣位置處的資訊,因為隨著取樣範圍的擴大,會有更多的取樣點超出影象的有效範圍,這個時候一個簡單的辦法就是實現準備好一副擴充套件過邊界的影象,這裡的擴充套件方法通道都選擇邊緣映象,而非重複邊緣。考慮到層數不會太多,擴充套件部分的邊緣計算量和佔用記憶體也不會太誇張。
同時,我們在考慮到演演算法的特殊性,雖然取樣範圍很廣,但是真正用到的取樣點也只有9個,所以我們也可以使用類似於我在SSE影象演演算法優化系列九:靈活運用SIMD指令16倍提升Sobel邊緣檢測的速度(4000*3000的24位元影象時間由480ms降低到30ms) 一文中使用到的技術,分配三行臨時的記憶體,每次計算前填充好三行的資料,不過注意一點,由於取樣的三行的記憶體並不是在行方向上連續的,因此,也不能像那個文章那樣,可以重複利用兩行的記憶體了,而必須每次都填充。
理論上說,這種填充技術要比前面的分配一整片的記憶體的記憶體填充工作量大3倍左右,速度應該要慢一些,優點是佔用的中間記憶體少一些,但是實測,還是這種的速度快一些,或許是因為三行記憶體的大小有效,存取時的cache miss要好很多吧。
一個簡答的程式碼片段如下所示:
for (int Y = 0; Y < Height; Y++)
{
short *LinePD = Dest + Y * Width * Channel;
int PosY0 = ColOffset[Y] * Width * Channel, PosY1 = Y * Width * Channel, PosY2 = ColOffset[Y + Radius + Radius] * Width * Channel;
for (int X = 0, Index = 0; X < Radius; X++)
{
int PosX = RowOffset[X] * Channel;
memcpy(First + Index, Src + PosY0 + PosX, Channel * sizeof(unsigned short));
memcpy(Second + Index, Src + PosY1 + PosX, Channel * sizeof(unsigned short));
memcpy(Third + Index, Src + PosY2 + PosX, Channel * sizeof(unsigned short));
Index += Channel;
}
memcpy(First + Radius * Channel, Src + PosY0, Width * Channel * sizeof(unsigned short));
memcpy(Second + Radius * Channel, Src + PosY1, Width * Channel * sizeof(unsigned short));
memcpy(Third + Radius * Channel, Src + PosY2, Width * Channel * sizeof(unsigned short));
for (int X = 0, Index = (Width + Radius) * Channel; X < Radius; X++)
{
int PosX = RowOffset[X + Width + Radius] * Channel;
memcpy(First + Index, Src + PosY0 + PosX, Channel * sizeof(unsigned short));
memcpy(Second + Index, Src + PosY1 + PosX, Channel * sizeof(unsigned short));
memcpy(Third + Index, Src + PosY2 + PosX, Channel * sizeof(unsigned short));
Index += Channel;
}
int BlockSize = 8, Block = (Width * Channel) / BlockSize;
for (int X = 0; X < Block * BlockSize; X += BlockSize)
{
__m128i P0 = _mm_loadu_si128((__m128i *)(First + X));
__m128i P1 = _mm_loadu_si128((__m128i *)(First + X + Radius * Channel));
__m128i P2 = _mm_loadu_si128((__m128i *)(First + X + 2 * Radius * Channel));
__m128i P3 = _mm_loadu_si128((__m128i *)(Second + X));
__m128i P4 = _mm_loadu_si128((__m128i *)(Second + X + Radius * Channel));
__m128i P5 = _mm_loadu_si128((__m128i *)(Second + X + 2 * Radius * Channel));;
__m128i P6 = _mm_loadu_si128((__m128i *)(Third + X));
__m128i P7 = _mm_loadu_si128((__m128i *)(Third + X + Radius * Channel));
__m128i P8 = _mm_loadu_si128((__m128i *)(Third + X + 2 * Radius * Channel));
__m128i Sum0 = _mm_adds_epu16(_mm_adds_epu8(P0, P2), _mm_adds_epu16(P6, P8));
__m128i Sum1 = _mm_adds_epu16(_mm_adds_epu8(P1, P7), _mm_adds_epu16(P3, P5));
__m128i Sum2 = _mm_slli_epi16(P4, 2);
__m128i Sum = _mm_adds_epu16(_mm_adds_epu16(Sum0, Sum2), _mm_adds_epu16(Sum1, Sum1));
_mm_storeu_si128((__m128i *)(LinePD + X), _mm_srli_epi16(Sum, 4));
}
for (int X = Block * BlockSize; X < Width * Channel; X++)
{
LinePD[X] = (First[X] + First[X + (Radius + Radius) * Channel] + Third[X] + Third[X + (Radius + Radius) * Channel]
+ (First[X + Radius * Channel] + Second[X] + Second[X + (Radius + Radius) * Channel] + Third[X + (Radius) * Channel]) * 2
+ Second[X + Radius * Channel] * 4) / 16;
}
//for (int X = 0; X < Width; X++)
//{
// // 1 2 1
// // 2 4 2
// // 1 2 1
// for (int Z = 0; Z < Channel; Z++)
// {
// LinePD[Z] = (First[X * Channel + Z] + First[(X + Radius + Radius) * Channel + Z] + Third[X * Channel + Z] + Third[(X + Radius + Radius) * Channel + Z]
// + (First[(X + Radius) * Channel + Z] + Second[X * Channel + Z] + Second[(X + Radius + Radius) * Channel + Z] + Third[(X + Radius) * Channel + Z]) * 2
// + Second[(X + Radius) * Channel + Z] * 4) / 16;
// }
// LinePD += Channel;
//}
}
在小波分解的計算中,核心耗時的也就是這個模糊,其他的諸如圖層模式的混合,直接用SIMD指令也很是簡單。這裡不予以贅述。
二、小波資料的幾個簡單應用
(一)降噪
我們在搜尋GIMP的wavelet_decompse相關資訊時,搜到了一個叫krita的軟體,在其官網發現他有一個小波去噪的功能,而且這個軟體還是開源的,詳見網站https://krita.org/zh/。
稍微分析下其krita的程式碼,可以發現其分解的過程其實就是借鑑了GIMP的過程:
//main loop for(int level = 0; level < scales; ++level){ //copy original KisPaintDeviceSP blur = new KisPaintDevice(*original); //blur it KisWaveletKernel::applyWavelet(blur, rc, 1 << level, 1 << level, flags, 0); //do grain extract blur from original KisPainter painter(original); painter.setCompositeOpId(op); painter.bitBlt(0, 0, blur, 0, 0, rc.width(), rc.height()); painter.end(); //original is new scale and blur is new original results << original; original = blur; updater->setProgress((level * 100) / scales); }
精髓的1 << level也存在於這裡。
在其kis_wavelet_noise_reduction.cpp我們也可以看到這樣的程式碼:
for (float* it = begin; it < fin; it++) { if (*it > threshold) { *it -= threshold; } else if (*it < -threshold) { *it += threshold; } else { *it = 0.; } }
這裡有一個閾值的引數,即為外界客戶需要提供的引數。
後續我們在翻閱小波去噪的論文時,也多次發現類似的公式,其實這就是所謂的軟閾值處理:

那這裡的核心其實就是對小波分解後的每層資料,按其值大小進行一定的裁剪,注意這個裁剪最好不要處理Residual層。
我們嚴格的按照這個流程對GIMP的小波分解後的資料進行了降噪測試,其中幾個效果如下所示:



原圖 軟閾值,層數5,噪音閾值3 硬閾值,層數5,噪音閾值3
同樣引數下,軟閾值的去噪程度要比硬閾值大很多。
我們對照網上提供的matlab版本程式碼,似乎結果還是有蠻大的差異的。
close all; [A,map]=imread('C:\2.jpg'); x=rgb2gray(A); imshow(x); [c,s]=wavedec2(x,2,'sym4'); a1=wrcoef2('a',c,s,'sym4'); figure; imshow(uint8(a1)); a2=wrcoef2('a',c,s,'sym4',2); figure; imshow(uint8(a2));
我隨意拿了幾張人臉的圖去測試,結果意外發現,這個去噪和磨皮的效果有那麼幾分相似:
