關於我在學習LFU的時候,在開源專案撿了個漏這件事。
你好呀,我是歪歪。
這篇文章帶大家盤一下 LFU 這個玩意。
為什麼突然想起聊聊這個東西呢,因為前段時間有個讀者給我扔過來一個連結:
我一看,好傢伙,這不是我親愛的老朋友,Dubbo 同學嘛。
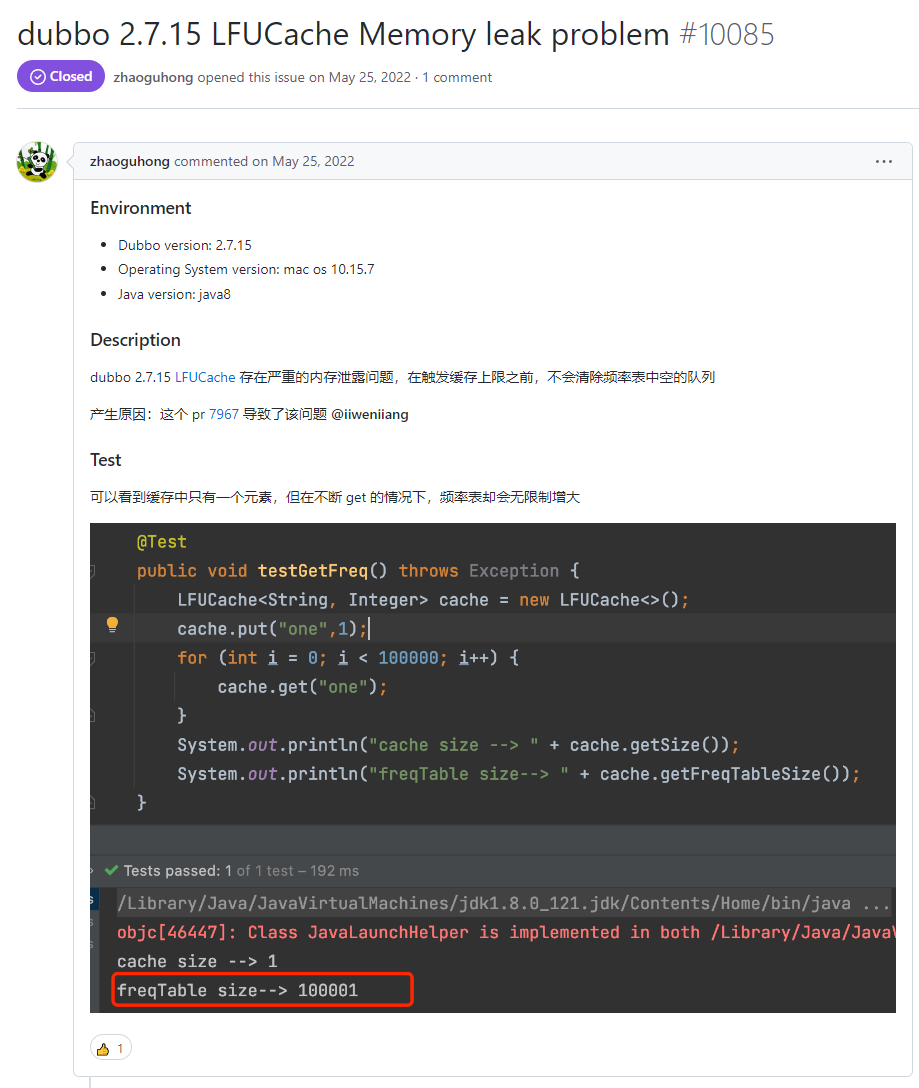
點進去一看,就是一個關於 LFU 快取的 BUG:
https://github.com/apache/dubbo/issues/10085
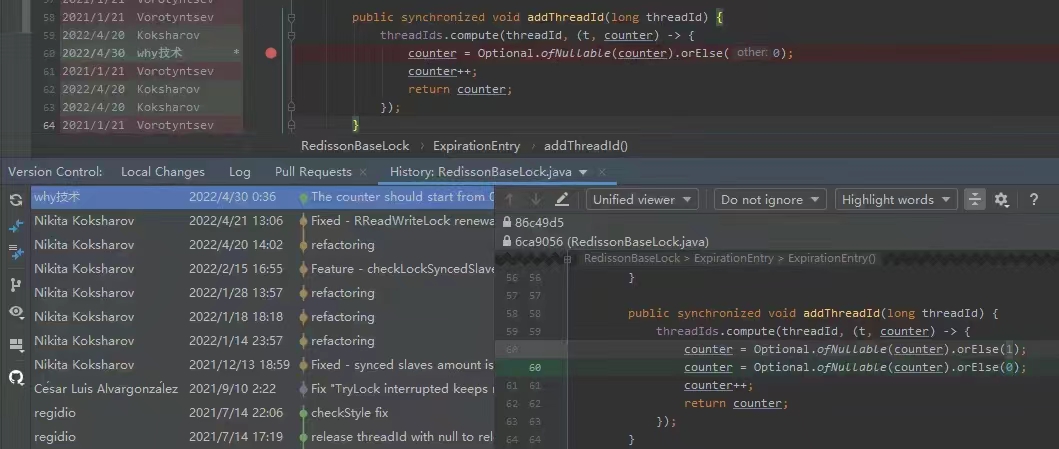
你知道的,我就喜歡盤一點開源專案的 BUG,看看有沒有機會,撿撿漏什麼的。在我輝煌的「撿漏」歷中,曾經最濃墨重彩的一筆是在 Redisson 裡面,發現作者在重構程式碼的時候,誤把某個方法的計數,從預設值為 0,改成了為 1。
這個 BUG 會直接導致 Redission 鎖失去可重入的性質。我發現後,原始碼都沒下載,直接在網頁上就改回去了:
我以為這可能就是巔峰了。
但是直到我遇到了 Dubbo 的這個 LFUCache 的 BUG,它的修復方案,只是需要交換兩行程式碼的順序就完事兒了,更加簡單。
到底怎麼回事呢,我帶你盤一把。
首先,剛剛提到 BUG,因為這一次針對 LFU 實現的優化提交:
https://github.com/apache/dubbo/pull/7967
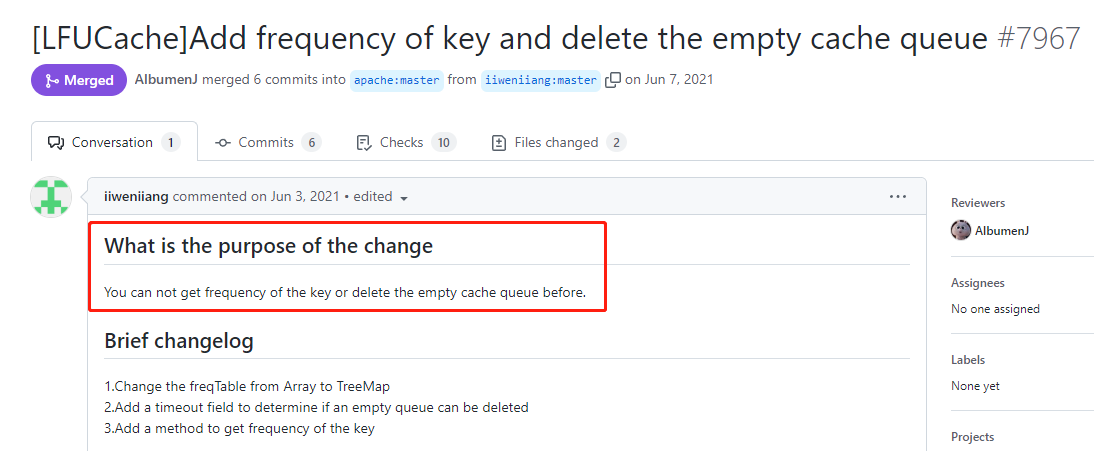
通過連結我們知道,這次提交的目的是優化 LFUCache 這個類,使其能通過 frequency 獲取到對應的 key,然後刪除空快取。
但是帶了個記憶體洩露的 BUG 上去,那麼這個 BUG 是怎麼修復的呢?
直接給對應的提交給回滾掉了:

但是,回滾回來的這一份程式碼,我個人覺得也是有問題的,使用起來,有點不得勁。
在為你解析 Dubbo 的 LFU 實現的問題之前,我必須要先把 LFU 這個東西的思路給你盤明白了,你才能絲滑入戲。

LRU vs LFU
在說 LFU 之前,我先給簡單提一句它的好兄弟:LRU,Least Recently Used,最近最少使用。
LRU 這個演演算法的思想就是:如果一個資料在最近一段時間沒有被存取到,那麼在將來它被存取的可能性也很小。所以,當指定的空間已存滿資料時,應當把最久沒有被存取到的資料淘汰。
聽描述你也知道了,它是一種淘汰演演算法。
如果說 LRU 是 Easy 模式的話,那麼把中間的字母從 R(Recently) 變成 F(Frequently),即 LFU ,那就是 hard 模式了。
如果你不認識 Frequently 沒關係,畢竟這是一個英語專八的詞彙。
我,英語八級半,我可以教你:
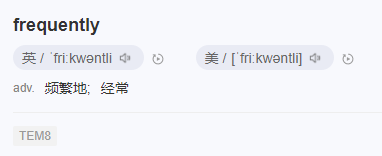
這是一個 adv,副詞,是指在句子中表示行為或狀態特徵的詞,用以修飾動詞、形容詞、其他副詞或全句,表示時間、地點、程度、方式等概念。
在 LFU 裡面,表示的就是頻率,它翻譯過來就是:最不經常使用策略。

LRU 淘汰資料的時候,只看資料在快取裡面待的時間長短這個維度。
而 LFU 在快取滿了,需要淘汰資料的時候,看的是資料的存取次數,被存取次數越多的,就越不容易被淘汰。
但是呢,有的資料的存取次數可能是相同的。
怎麼處理呢?
如果存取次數相同,那麼再考慮資料在快取裡面待的時間長短這個維度。
也就是說 LFU 演演算法,先看存取次數,如果次數一致,再看快取時間。
給你舉個具體的例子。
假設我們的快取容量為 3,按照下列資料順序進行存取:

如果按照 LRU 演演算法進行資料淘汰,那麼十次存取的結果如下:
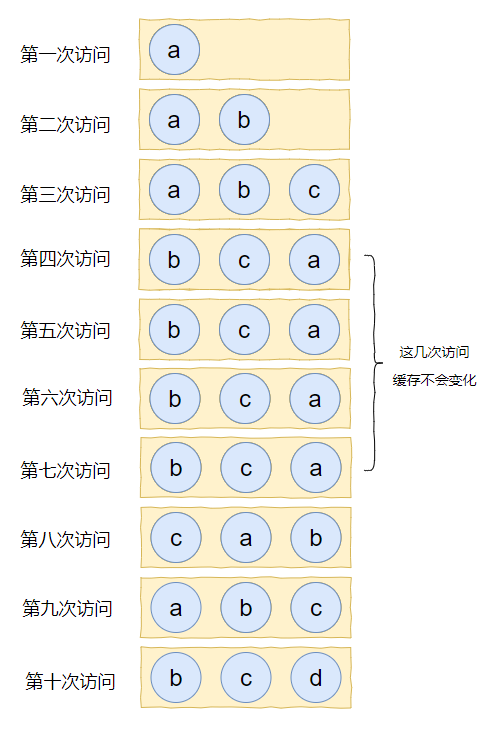
十次存取結束後,快取中剩下的是 b,c,d 這三個元素。
你仔細嗦一下,你有沒有覺得有一絲絲不對勁?

十次存取中元素 a 被存取了 5 次,說明 a 是一個經常要用到的東西,結果按照 LRU 演演算法,最後元素 a 被淘汰了?
如果按照 LFU 演演算法,最後留在快取中的三個元素應該是 b,c,a。
這樣看來,LFU 比 LRU 更加合理,更加巴適。
好的,題目描述完畢了。假設,要我們實現一個 LFUCache:
class LFUCache {
public LFUCache(int capacity) {
}
public int get(int key) {
}
public void put(int key, int value) {
}
}
那麼思路應該是怎樣的呢?

一個雙向連結串列
如果是我去面試,在完全沒有接觸過 LFU 演演算法之前,面試官出了這麼一道題,讓我硬想,我能想到的方案也只能是下面這樣的。
因為前面我們分析了,這個玩意既需要有頻次,又需要有時間順序。
我們就可以搞個連結串列,先按照頻次排序,頻次一樣的,再按照時間排序。
因為這個過程中我們需要刪除節點,所以為了效率,我們使用雙向連結串列。
還是假設我們的快取容量為 3,還是用剛剛那組資料進行演示。
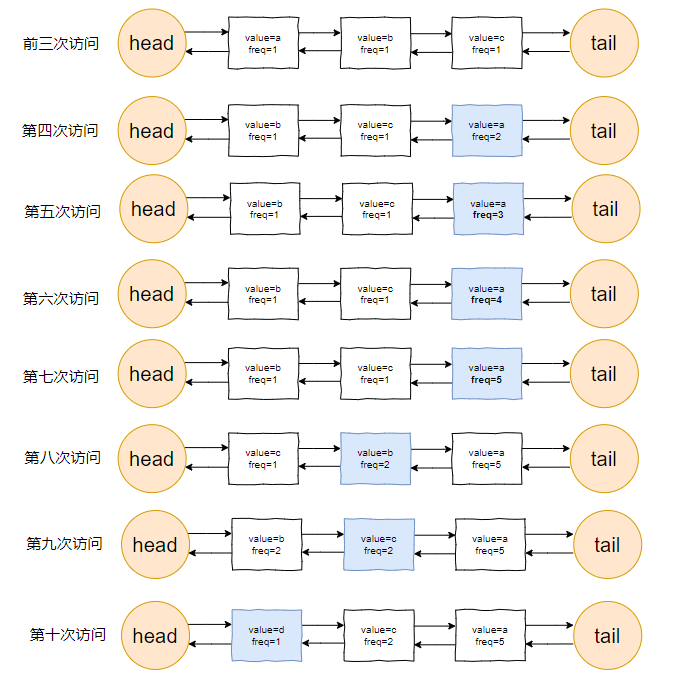
我們把頻次定義為 freq,那麼前三次存取結束後,即這三個請求存取結束後:

每個元素的頻次,即 freq 都是 1。所以連結串列裡面應該是這樣的:

由於我們的容量就是 3,此時已經滿了。
那我問你一個問題:如果此時來任意一個不是 a 的元素,誰會被踢出快取?

就這問題,你還思考個毛啊,這不是一目瞭然的事情嗎?
對於目前三個元素來說,value=a 是頻次相同的情況下,最久沒有被存取到的元素,所以它就是 head 節點的下一個元素,隨時等著被淘汰。
但是你說巧不巧,
接著過來的請求就是 value=a:

當這個請求過來的時候,連結串列中的 value=a 的節點的頻率(freq)就變成了2。
此時,它的頻率最高,最不應該被淘汰,a 元素完成了自我救贖!
因此,連結串列變成了下面這個樣子,沒有任何元素被淘汰了。
連結串列變化的部分,我用不同於白色的顏色(我色弱不知道這是個啥顏色,藍色嗎?)標註出來:

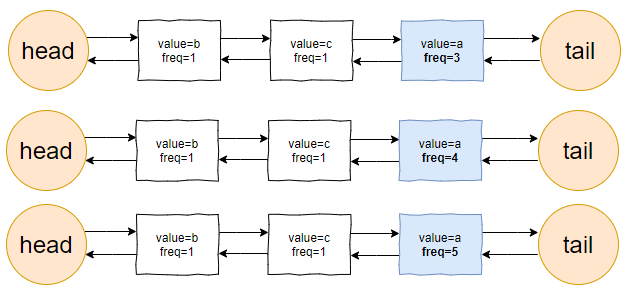
接著連續來了三個 value=a 的請求:

此時的連結串列變化就集中在 value=a 這個節點的頻率(freq)上。
為了讓你能絲滑跟上,我把每次的 freq 變化都給你畫出來。這行為,實錘了,妥妥的暖男作者:
接著,這個 b 請求過來了:

b 節點的 freq 從 1 變成了 2,節點的位置也發生了變化:

然後,c 請求過來:

這個時候就要特別注意了:

你說這個時候會發生什麼事情?
連結串列中的 c 當前的存取頻率是 1,當這個 c 請求過來後,那麼連結串列中的 c 的頻率就會變成 2。
你說巧不巧,此時,value=b 節點的頻率也是 2。
撞車了,那麼你說,這個時候怎麼辦?
前面說了:頻率一樣的時候,看時間。
value=c 的節點是正在被存取的,所以要淘汰也應該淘汰之前被存取的 value=b 的節點。
此時的連結串列,就應該是這樣的:

然後,最後一個請求過來了:

d 元素,之前沒有在連結串列裡面出現過,而此時連結串列的容量也滿了。
那麼刺激的就來了,該進行淘汰了,誰會被「優化」掉呢?
一看連結串列,哦,head 的下一個節點是 value=b:

然後把 value=d 的節點插入:

最終,所有請求完畢。
留在快取中的是 d,c,a 這三個元素。
最後,匯個總,整體的流程就是這樣的:
當然,這裡只是展示了連結串列的變化。
前面說了,這是快取淘汰策略,快取嘛,大家都懂,是一個 key-value 鍵值對。
所以前面的元素 a,b,c 啥的,其實對應的是我們放的 key-value 鍵值對。也就是應該還有一個 HashMap 來儲存 key 和連結串列節點的對映關係。
這個點比較簡單,用腳趾頭都能想到,我也就不展開來說了。
按照上面這個思路,你慢慢的寫程式碼,應該是能寫出來的。
上面這個雙連結串列的方案,就是扣著腦殼硬想,大部分人能直接想到的方案。
但是,面試官如果真的是問這個問題的話,當你給出這個回答之後,他肯定會追問:有沒有時間複雜度為 O(1) 的解決方案呢?

雙雜湊表
如果我們要拿出時間複雜度為 O(1) 的解法,那就得細細的分析了,不能扣著腦殼硬想了。
我們先分析一下需求。
第一點:我們需要根據 key 查詢其對應的 value。
前面說了,這是一個快取淘汰策略,快取嘛,用腳趾頭都能想到,用 HashMap 儲存 key-value 鍵值對。
查詢時間複雜度為 O(1),滿足。
第二點:每當我們操作一個 key 的時候,不論是查詢還是新增,都需要維護這個 key 的頻次,記作 freq。
因為我們需要頻繁的操作 key 對應的 freq,頻繁地執行把 freq 拿出來進行加一的操作。
獲取,加一,再放回去。來,請你大聲的告訴我,用什麼資料結構?
是不是還得再來一個 HashMap 儲存 key 和 freq 的對應關係?
第三點:如果快取裡面放不下了,需要淘汰資料的時候,把 freq 最小的 key 刪除掉。
注意啊,上面這句話,看黑板,我再強調一下:把 freq 最小的 key 刪除掉。

freq 最小?
我們怎麼知道哪個 key 的 freq 最小呢?
前面說了,我們有一個 HashMap 儲存 key 和 freq 的對應關係。我們肯定是可以遍歷這個 HashMap,來獲取到 freq 最小的 key。
但是啊,朋友們,遍歷出現了,那麼時間複雜度還會是 O(1) 嗎?
那怎麼辦呢?
注意啊,高潮來了,一學就廢,一點就破。
我們可以搞個變數來記錄這個最小的 freq 啊,記為 minFreq,在對快取操作的過程中持續的對其進行維護,不就行了?

現在我們有最小頻次(minFreq)了,需要獲取到這個最小頻次對應的 key,時間複雜度得為 O(1)。
來,朋友,請你大聲的告訴我,你又想起了什麼資料結構?
是不是又想到了 HashMap?
好了,我們現在有三個 HashMap 了,給大家介紹一下:
一個儲存 key 和 value 的 HashMap,即HashMap<key,value>。
一個儲存 key 和 freq 的 HashMap,即HashMap<key,freq>。
一個儲存 freq 和 key 的 HashMap,即HashMap<freq,key>。
它們每個都是各司其職,目的都是為了時間複雜度為 O(1)。
但是我們可以把前兩個 HashMap 合併一下。
我們弄一個物件,物件裡面包含兩個屬性分別是 value、freq。
假設這個物件叫做 Node,它就是這樣的,頻次預設為 1:
class Node {
int value;
int freq = 1;
//建構函式省略
}
那麼現在我們就可以把前面兩個 HashMap ,替換為一個了,即 HashMap<key,Node>。
同理,我們可以在 Node 裡面再加入一個 key 屬性:
class Node {
int key;
int value;
int freq = 1;
//建構函式省略
}
因為 Node 裡面包含了 key,所以可以把第三個 HashMap<freq,key> 替換為 HashMap<freq,Node>。
當我們有了封裝了 key、value、freq 屬性的 Node 物件之後,我們的三個 HashMap 就變成了兩個:
一個儲存 key 和 Node 的 HashMap,即 HashMap<key,Node>
一個儲存 freq 和 Node 的 HashMap,即 HashMap<freq,Node>
你捋一捋這個思路,是不是非常的清晰,有了清晰的思路,去寫程式碼是不是就事半功倍了。
好,現在我告訴你,到這一步,我們還差一個邏輯,而且這個邏輯非常的重要,你現在先彆著急往下看,先再回顧一下目前整個推理的過程和最後的思路,想一想到底還差啥?

...
...
...

...
到這一步,我們還差了一個非常關鍵的資訊沒有補全,就是下面這一個點。
第四點:可能有多個 key 具有相同的最小的 freq,此時移除這一批資料在快取中待的時間最長的那個元素。
在這個需求裡面,我們需要通過 freq 查詢 Node,那麼操作的就是 HashMap<freq,Node> 這個雜湊表。
上面說[多個 key 具有相同的最小的 freq],也就是說通過 minFreq ,是可以查詢到多個 Node 的。
所以HashMap<freq,Node> 這個雜湊表,應該是這樣的:HashMap<freq,集合
這個能想明白吧?
一個坑位下,掛了一串節點。
此時的問題就變成了:我們應該用什麼集合來裝這個 Node 物件呢?
不慌,我們又接著分析嘛。
先理一下這個集合需要滿足什麼條件。
我們通過 minFreq 獲取這個集合的時候,也就是佇列滿了,要從這個集合中刪除資料的時候
首先,需要刪除 Node 的時候。
因為這個集合裡面裝的是存取頻次一樣的資料,那麼希望這批資料能有時序,這樣可以快速的刪除待的時間最久的 Node。
有序,有時序,能快速查詢刪除待的時間最久的 key。
LinkedList,雙向連結串列,可以滿足這個需求吧?
另外還有一種大多數情況是一個 Node 被存取的時候,它的頻次必然就會加一。
所以還要考慮存取 Node 的時候。
比如下面這個例子:
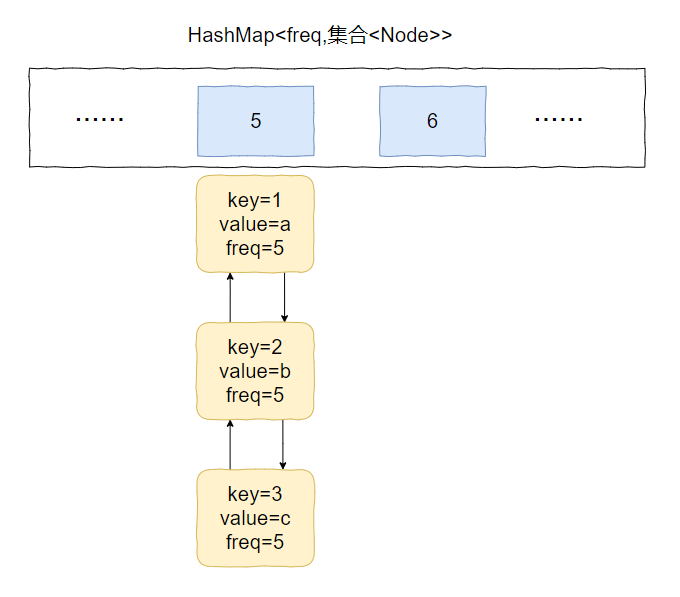
假設最小存取頻次,minFreq=5,而 5 這個坑位對應了 3 個 Node 物件。
此時,我要存取 value=b 的物件,那麼該物件就會從 minFreq=5 的 value 中移走。
然後頻次加一,即 5+1=6。
加入到 minFreq=6 的 value 集合中,變成下面這個樣子:
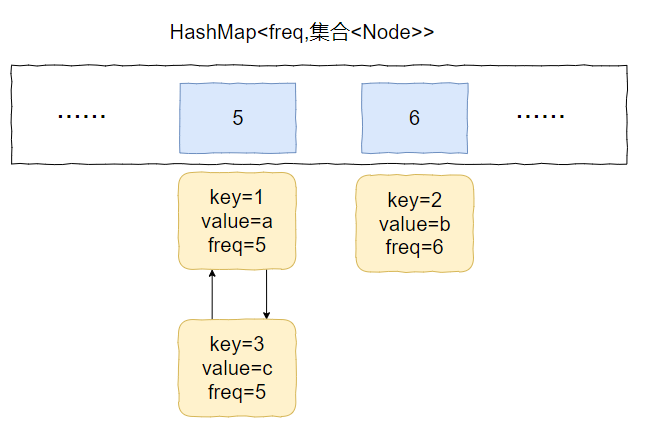
也就是說我們得支援任意 node 的快速刪除。
LinkedList 不支援任意 node 的快速刪除,這玩意需要遍歷啊。

當然,你可以自己去手擼一個符合要求的 MySelfLinkedList。
但是,在 Java 集合類中,其實有一個滿足上面說的有序的、支援快速刪除的集合。
那就是 LinkedHashSet,它是一個基於 LinkedHashMap 實現的有序的、去重集合列表。
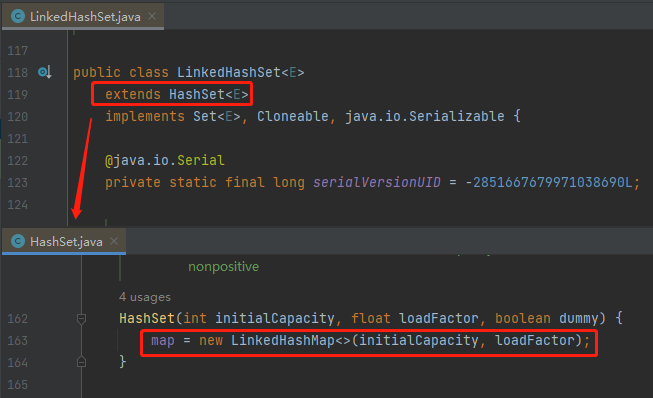
底層還是一個 Map,Map 針對指定元素的刪除,O(1)。
所以,HashMap<freq,集合>,就是HashMap<freq,LinkedHashSet>。
總結一下。
我們需要兩個 HashMap,分別是
HashMap<key,Node> HashMap<freq,LinkedHashSet >
然後還需要維護一個最小存取頻次,minFreq。
哦,對了,還得來一個引數記錄快取支援的最大容量,capacity。
然後,沒了。
有的小夥伴肯定要問了:你倒是給我一份程式碼啊?

這些分析出來了,程式碼自己慢慢就擼出來了,這一份程式碼應該就是絕大部分面試官問 LFU 的時候,想要看到的程式碼了。
另外,關於 LFU 出現在面試環節,我突然想起一個段子,我覺得還有一絲道理:
面試官想要,我會出個兩數之和,如果我不想要你,我就讓你寫LFU。
我這裡主要帶大家梳理思路,思路清晰後再去寫程式碼,就算面試的時候沒有寫出 bug free 的程式碼,也基本上八九不離十了。
所以具體的程式碼實現,我這裡就不提供了,網上一搜多的很,關鍵是把思路弄清楚。
這玩意就像是你工作,關鍵的是把需求梳理明白,然後想想程式碼大概是怎麼樣的。
至於具體去寫的時候,到處粘一粘,也不是不可以。再或者,把設計檔案寫出來了,程式碼落地就讓小弟們照著你的思路去幹就行了。
應該把工作精力放在更值得花費的地方:比如 battle 需求、寫檔案、寫週報、寫 PPT、舔領導啥的...

Dubbo 的 LFU
到這裡,你應該是懂了 LFU 到底是個啥玩意了。
現在我帶你看看 Dubbo 裡面的這個 LFU,它的實現方案並沒有採取我們前面分析出來的方案。
它另闢蹊徑,搞了一個新花樣出來。它是怎麼實現的呢?我給你盤一下。
Dubbo 是在 2.7.7 版本之後支援的 LFU,所以如果你要在本地測試一把的話,需要引入這個版本之後的 Maven 依賴。

我這裡直接是把 Dubbo 原始碼拉下來,然後看的是 Master 分支的程式碼。
首先看一下它的資料結構:
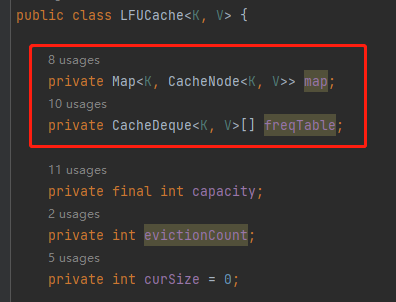
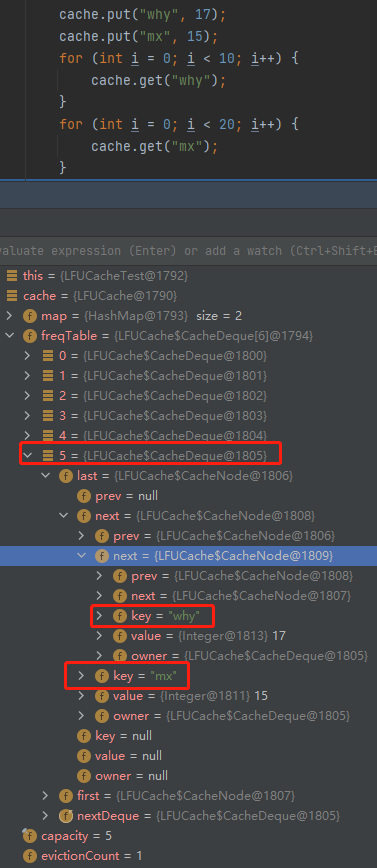
它有一個 Map,是存放的 key 和 Node 之間的對映關係。然後還有一個 freqTable 欄位,它的資料結構是陣列,我們並沒有看到一個叫做 minFreq 的欄位。
當我的 LFUCache 這樣定義的時候:
new LFUCache<>(5, 0.2f);
含義是這個快取容量是 5,當滿了之後,「優化」 5*0.2 個物件,即從快取中踢出 1 個物件。
通過 Debug 模式看,它的結構是這樣的:
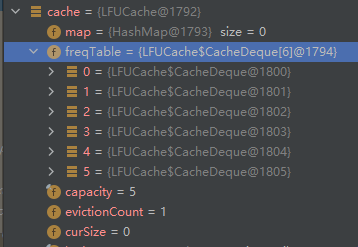
我們先主要關注 freqTable 欄位。
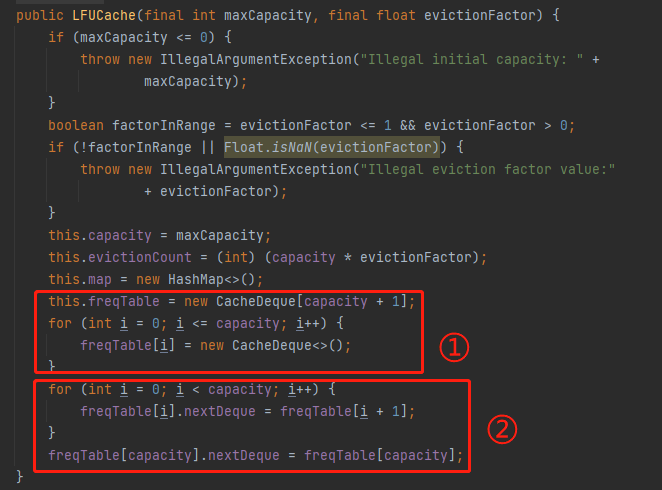
在下面標號為 ① 的地方,表示它是一個長度為 capacity+1 的陣列,即長度為 6,且每個位置都 new 了一個 CacheDeque 物件。
標號為 ② 的地方,完成了一個單向連結串列的維護動作:
freqTable 具體拿來是幹啥用的呢?
用下面這三行程式碼舉個例子:
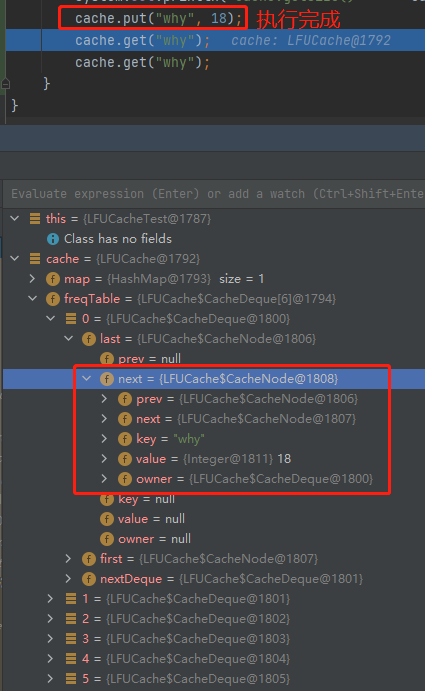
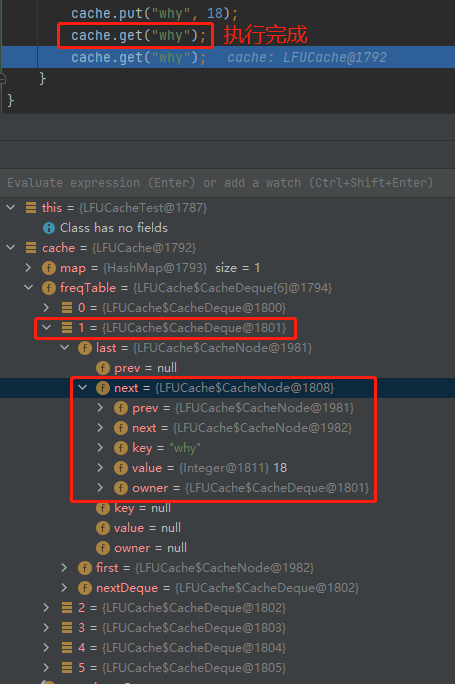
cache.put("why", 18);
cache.get("why");
cache.get("why");
當第一行執行完成之後,why 這個元素被放到了 freqTable 的第一個坑位,即陣列的 index=0 裡面:
當第二行執行完成之後,why 這個元素被放到了 freqTable 的第二個坑位裡面:
當第三行執行完成之後,why 這個元素被放到了 freqTable 的第三個坑位裡面:
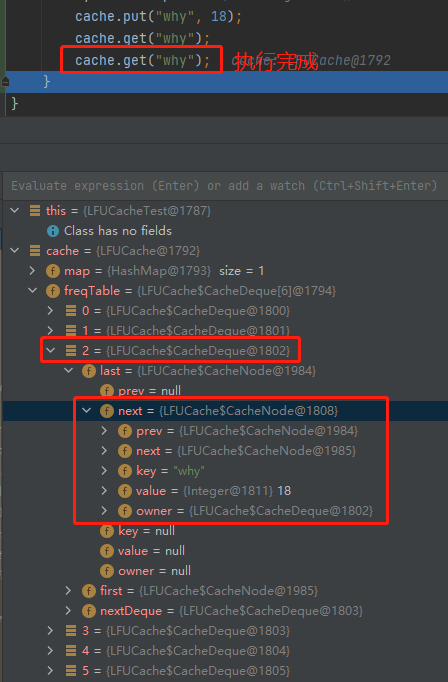
有沒有點感覺了?
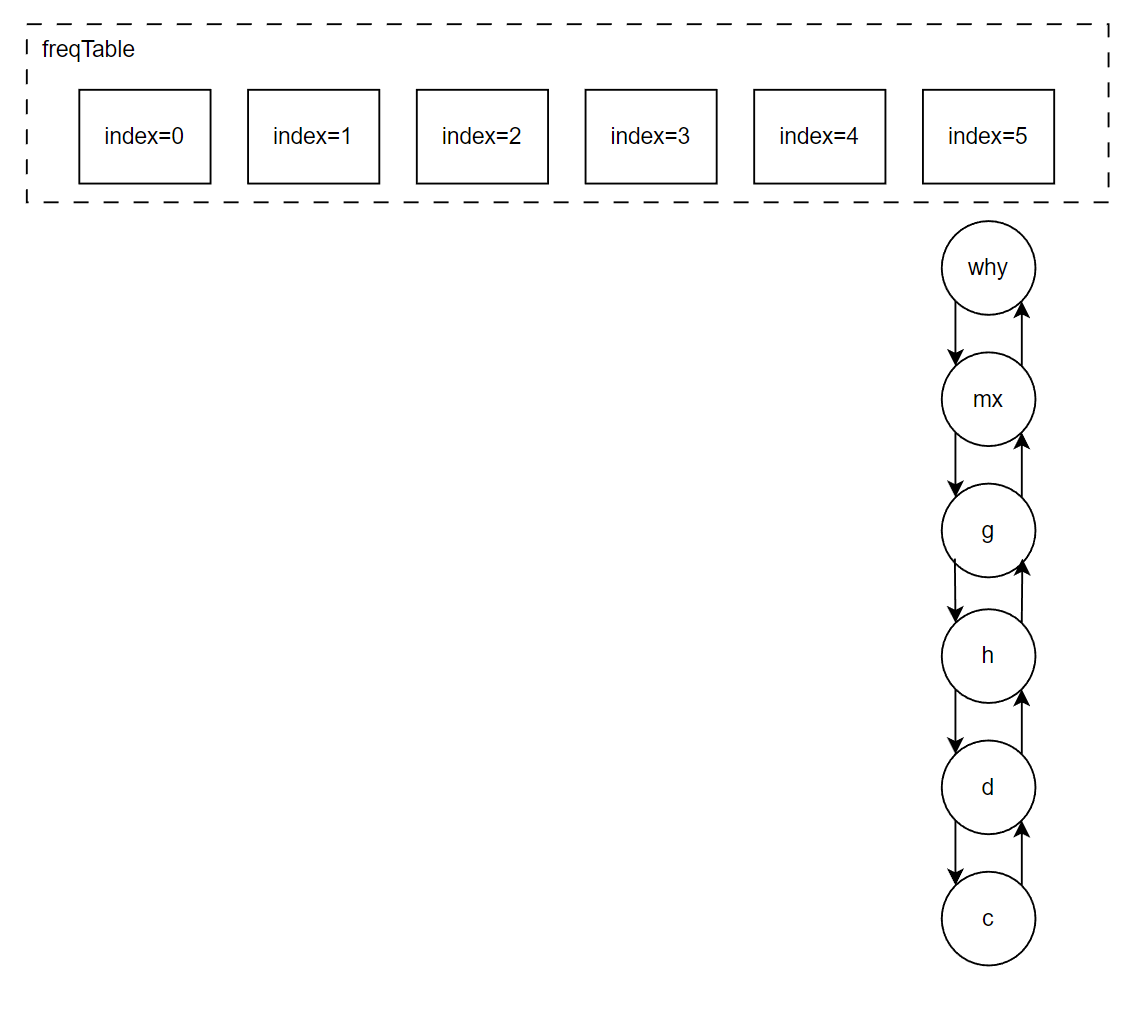
freqTable 這個陣列,每個坑位就是對應不同的頻次,所以,我給你搞個圖:
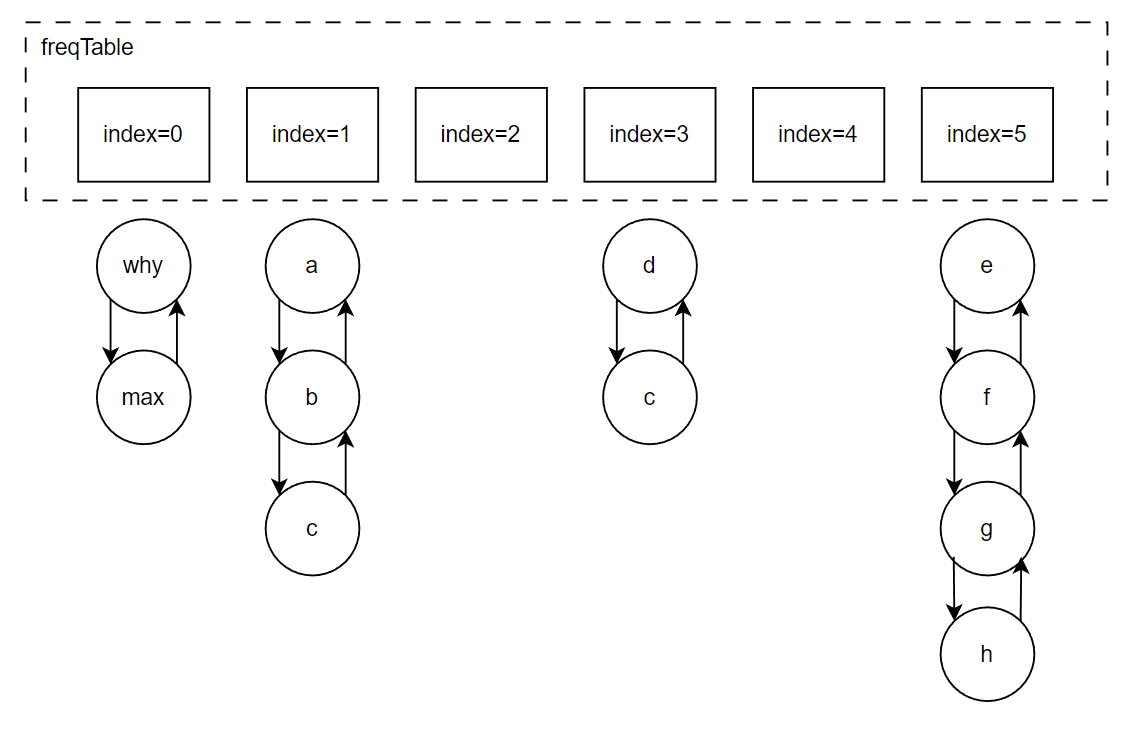
比如 index=3 位置放的 d 和 c,含義就是 d 和 c 在快取裡面被存取的頻次是 4 次。
但是,d 和 c 誰待的時間更長呢?
我也不知道,所以得看看原始碼裡面刪除元素的時候,是移走 last 還是 first,移走誰,誰就在這個頻率下待的時間最長。
答案就藏在它的驅逐方法裡面:
org.apache.dubbo.common.utils.LFUCache#proceedEviction
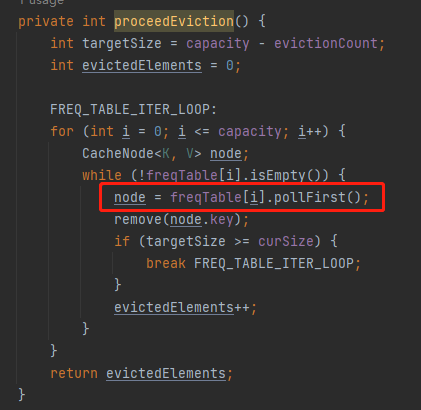
從陣列的第一個坑位開始遍歷陣列,如果這個坑位下掛的有連結串列,然後開始不斷的移除頭結點,直到驅逐指定個數的元素。
移除頭結點,所以,d 是在這個頻次中待的時間最長的。
基於這個圖片,假設現在佇列滿了,那麼接下來,肯定是要把 why 這個節點給「優化」了:
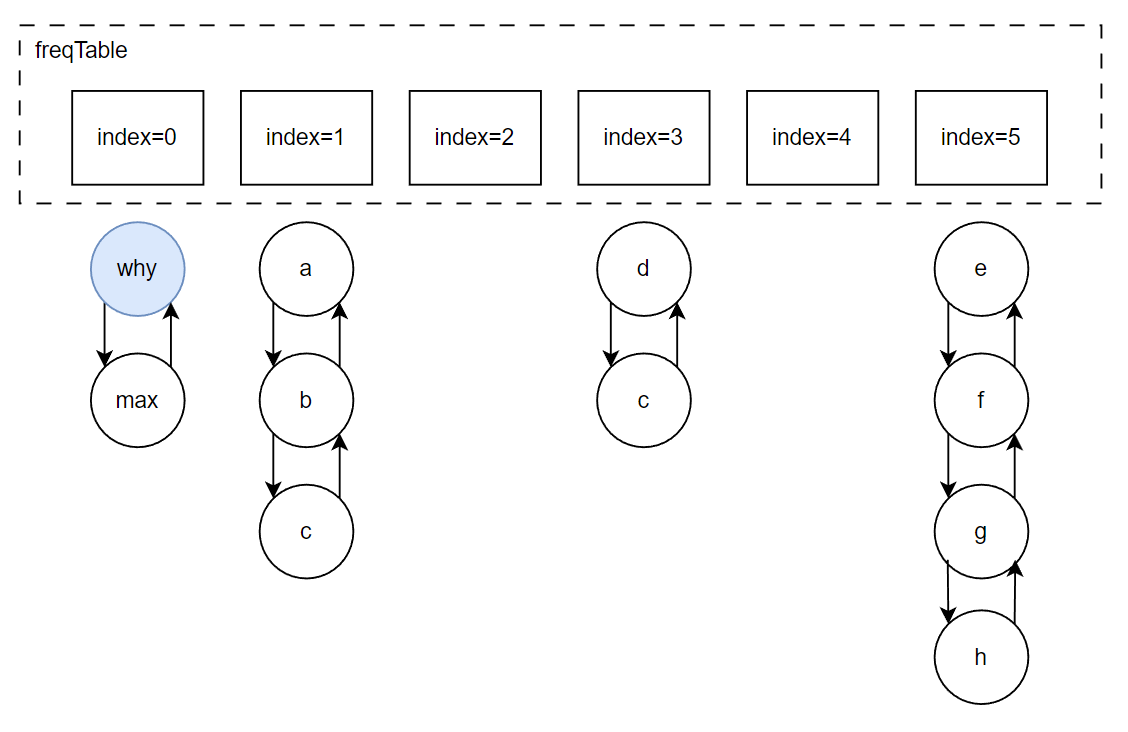
這就是 Dubbo 裡面 LFU 實現的最核心的思想,很巧妙啊,基於陣列的順序,來表示元素被存取的頻次。

但是,細細的嗦一下味道之後,你有沒有想過這樣一個問題,當我存取快取中的元素的次數大於 freqTable 陣列的長度的時候,會出現什麼神奇的現象?
我還是給你用程式碼示意:
雖然 mx 元素的存取次數比 why 元素的次數多得多,但是這兩個元素最後都落在了 freqTable 陣列的最後一個坑位中。
也就是會出現這樣的場景:
好,我問你一個問題:假設,在這樣的情況下,要淘汰元素了,誰會被淘汰?
肯定是按照頭結點的順序開始淘汰,也就是 why 這個節點。
接下來注意了,我再問一個問題:假設此時 why 有幸再次被存取了一下,然後才來一個新的元素,觸發了淘汰策略,誰會被淘汰?
why 會變成這個坑位下的連結串列中的 last 節點,從而躲避過下一次淘汰。mx 元素被淘汰了。
這玩意突然就從 LFU,變成了一個 LRU。在同一個實現裡面,既有 LFU 又有 LRU,這玩意,知識都學雜了啊。
我就問你 6 不 6?

所以,這就是 Dubbo 的 LFU 演演算法實現的一個弊端,這個弊端是由於它的設計理念和資料結構決定的,如果想要避免這個問題,我覺得有點麻煩,得推翻從來。
所以我這裡也只是給你描述一下有這個問題的存在。
然後,關於 Dubbo 的 LFU 的實現,還有另外一個神奇的東西,我覺得這純純的就是 BUG 了。
我還是給你搞一個測試用例:
@Test
void testPutAndGet() {
LFUCache<String, Integer> cache = new LFUCache<>(5, 0.2f);
for (int i = 0; i < 5; i++) {
cache.put(i + "", i);
cache.get(i + "");
}
cache.put("why", 18);
Integer why = cache.get("why");
System.out.println("why = " + why);
}
一個容量為 5 的 LFUCache,我先放五個元素進去,每個元素 put 之後再 get 一下,所以每個元素的頻率變成了 2。
然後,此時我放了一個 why 進去,然後在取出來的時候, why 沒了。

你這啥快取啊,我剛剛放進去的東西,等著馬上就要用呢,結果獲取的時候沒了,這不是 BUG 是啥?
問題就出在它的 put 方法中:
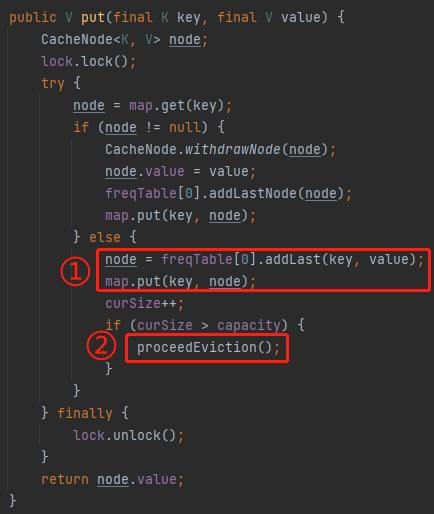
標號為 ① 的地方往快取裡面放,放置完畢之後,判斷是否會觸發淘汰機制,然後在標號 ② 的地方刪除元素。
前面說了,淘汰策略,proceedEviction 方法,是從 freqTable 陣列的第一個坑位開始遍歷陣列,如果這個坑位下掛的有連結串列,然後開始不斷的移除頭結點,直到驅逐指定個數的元素。
所以,在剛剛我的範例程式碼中,why 元素剛剛放進去,它的頻率是 1,放在了 freqTable 陣列的第 0 個位置。
放完之後,一看,觸發淘汰機制了,讓 proceedEviction 方法看看是誰應該被淘汰了。
你說,這不是趕巧了嘛,直接又把 why 給淘汰了,因為它的存取頻率最低。
所以,立馬去獲取 「why」 的時候,獲取不到。
這個地方的邏輯就是有問題的。
不應該採取「先放新元素,再判斷容量,如果滿了,觸發淘汰機制」的實現方案。
而應該採取「先判斷容量,如果滿了,再觸發淘汰機制,最後再放新元素的」方案。
也就是我需要把這兩行程式碼換個位置:
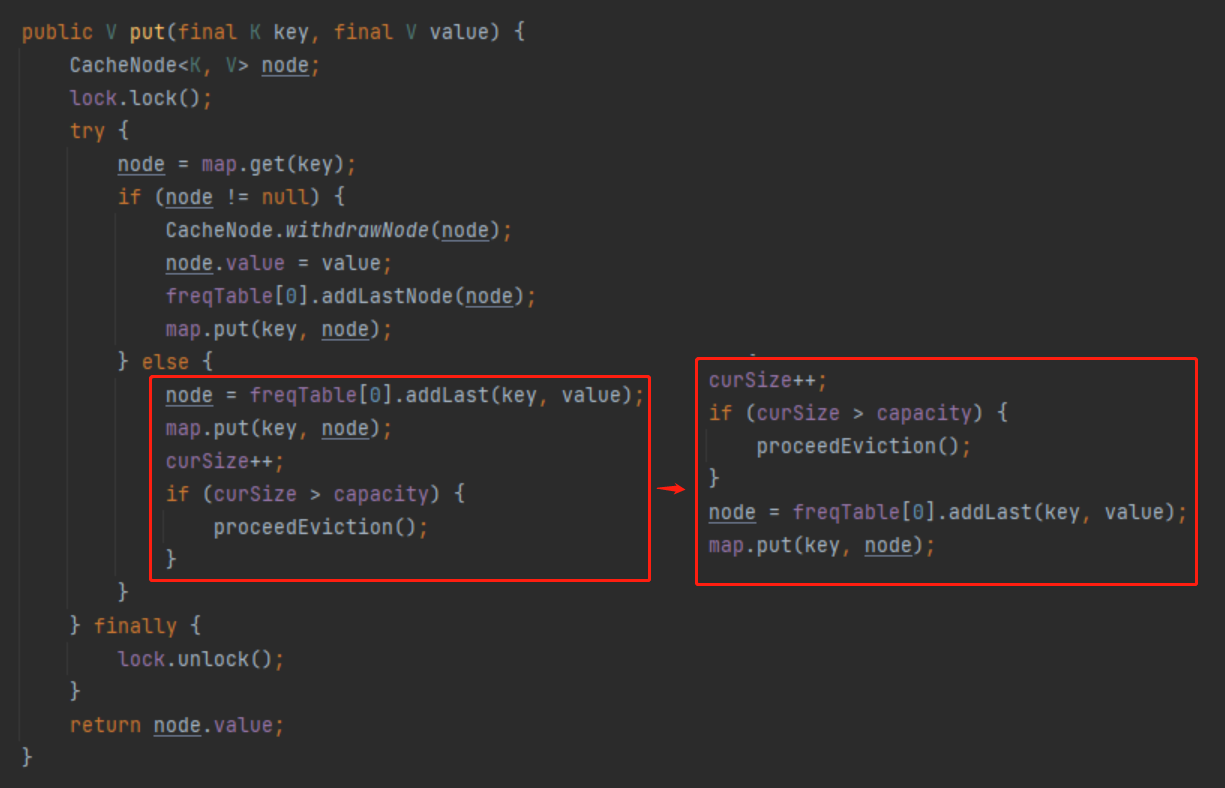
再次執行測試案例,就沒有問題了:
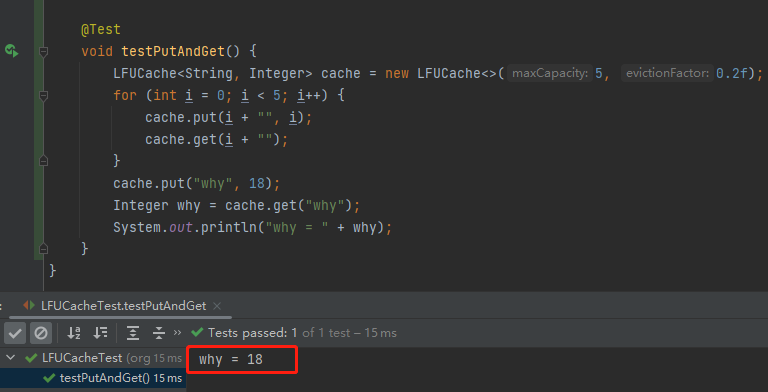
誒,你說這是什麼?
這不就是為開源專案貢獻原始碼的好機會嗎?
於是...
https://github.com/apache/dubbo/pull/11538
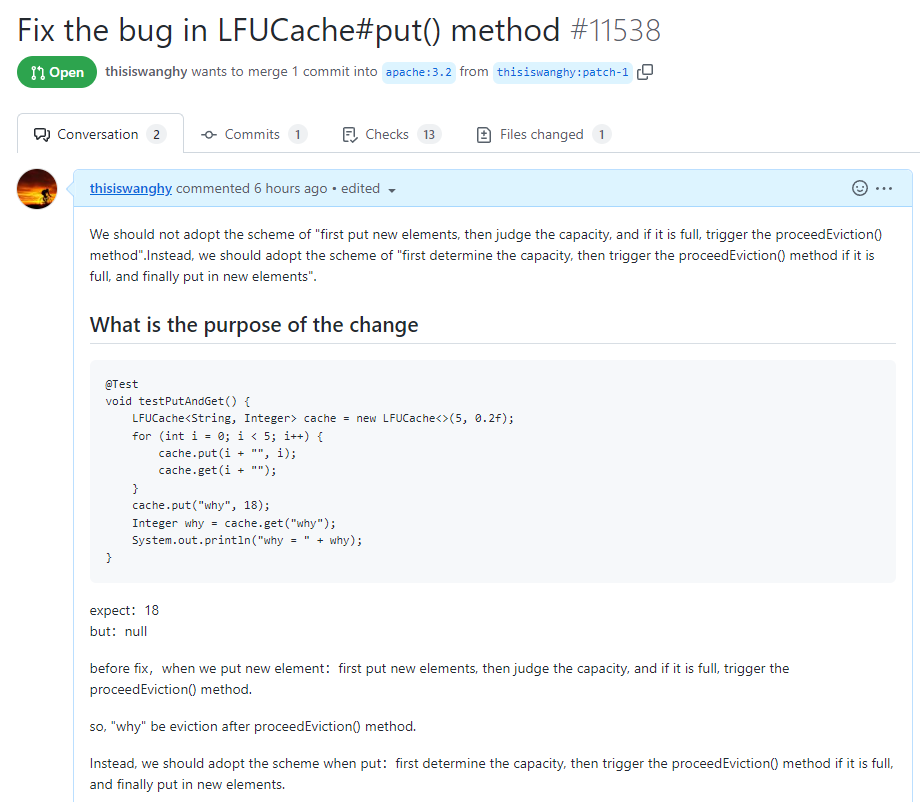
關於提 pr,有一個小細節,我悄悄的告訴你:合不合並什麼的不重要,重要的是全英文提問,哪怕是中文一鍵翻譯過來的,也要貼上去,逼格要拉滿,檔次要上去...
至於最後,如果沒合併,說明我考慮不周,又是新的素材。
如果合併了,簡歷上又可以寫:熟練使用 Dubbo,併為其貢獻過原始碼。
到時候,我臉皮再厚一點,還可以寫成:閱讀過 Apache 頂級開源專案原始碼,多次為其貢獻過核心原始碼,並寫過系列博文,加深學習印象...
不能再說了,剩下的就靠自己悟了!

最後,文章就到這裡了,如果對你有一絲絲的幫助,幫我點個免費的贊,不過分吧?