我製作了一個部落格園文章資訊統計的小工具
2023-02-14 15:03:27
前言
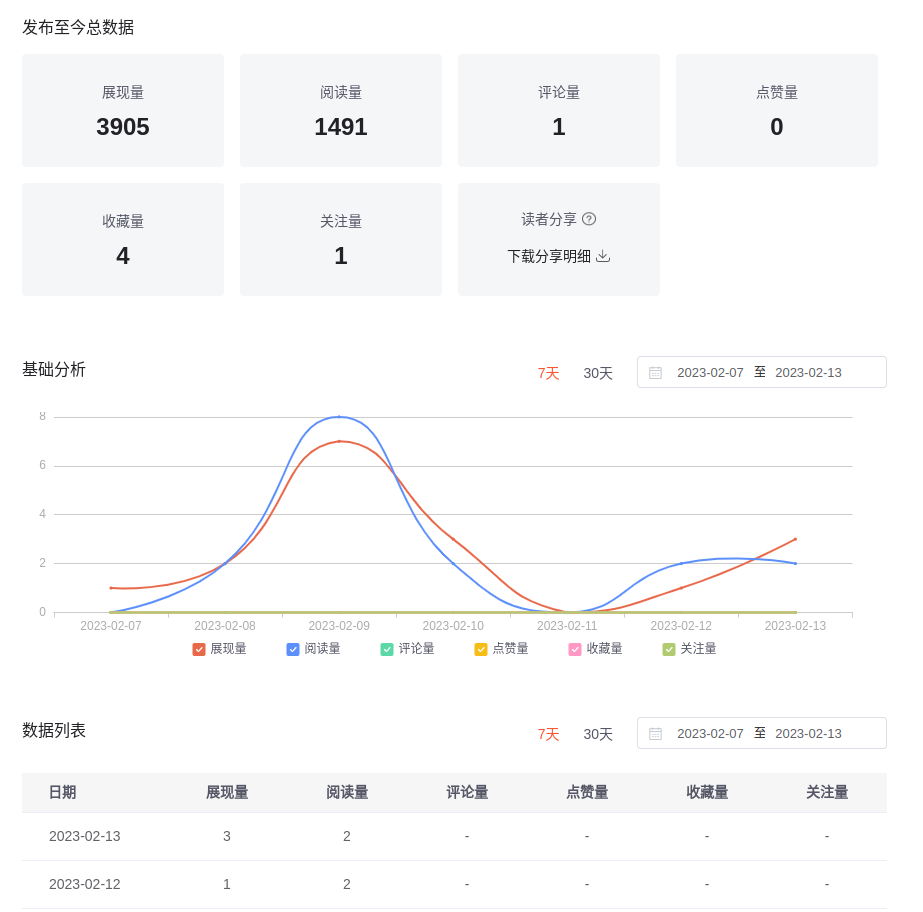
部落格園在個人首頁有一個簡單的部落格資料統計,以部落格園官方的首頁為例:

但是這些資料不足以分析更為細節的東西
起初我是想把部落格園作為個人學習的雲筆記,但在一點點的記錄中,我逐漸把部落格園視為知識創作和知識分享的平臺
所以從年後開始,就想著做一個類似 CSDN 裡統計文章資料的工具
這樣的統計功能可以更好的去分析讀者對於內容的需求,瞭解文章內容的價值,以及從側面認識自己在知識創作方面的能力
程式
這個程式是我昨天晚上一時興起,看到了一位博主的文章 Python爬蟲實戰-統計部落格園閱讀量問題 ,正好檢驗自己對python的掌握,於是補充和修改了他的程式碼。因為想著要更為直觀的展示文章資料,所以分了幾個模組去寫,以方便後續增加和修改功能
程式目前只有三個 .py 檔案,爬取資料後解析並寫入到 txt 中(後續會使用更規範的方法做持久化處理)
主程式 main.py
from spider import spider
from store import write_data
# 設定部落格名,例如我的部落格地址為:https://www.cnblogs.com/KoiC,此處則填入KoiC
blog_name = 'KoiC'
if __name__ == '__main__':
post_info = spider(blog_name)
# print(post_info)
write_data(post_info, blog_name)
print('執行完畢!')
爬蟲模組 spider.py
import time
import requests
import re
from lxml import etree
def spider(blog_name):
"""
爬取相關資料
"""
# 設定UA和目標部落格url
headers = {
"User-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.41"
}
url = "https://www.cnblogs.com/" + blog_name + "/default.html?page=%d"
# 測試存取
req = requests.get(url, headers)
print('測試存取狀態:%d'%req.status_code)
print('開始爬取資料...')
post_info = [] # 全部博文資訊
#分頁爬取資料
for page_num in range(1, 999):
# 指向目標url
new_url = format(url%page_num)
# 獲取頁面
req = requests.get(url=new_url, headers=headers)
# print(req.status_code)
tree = etree.HTML(req.text)
# 獲取目標資料(各博文名稱和閱讀量)
count_list = tree.xpath('//div[@class="forFlow"]/div/div[@class="postDesc"]/span[1]/text()')
title_list = tree.xpath('//div[@class="postTitle"]/a/span/text()')
# 獲取該頁博文數量
post_count = len(count_list)
# 如果該頁沒有博文,跳出迴圈
if post_count == 0:
break
# 解析目標資料
for i in range(post_count):
# 對資料進行處理
post_title = title_list[i].strip() # 處理前後多餘的空格、換行等
post_view_count = re.findall('\d+', count_list[i]) # 正規表示式獲取閱讀量資料
single_post_info = [post_title, post_view_count[0]] # 單篇博文資料
post_info.append(single_post_info)
time.sleep(0.8)
return post_info
持久化模組 store.py
import os
import time
def write_data(post_info, blog_name):
"""
對資料進行持久化
"""
print('開始寫入資料...')
# 獲取時間
now_time = time.localtime(time.time())
select_date = time.strftime('%Y-%m-%d', now_time)
select_time = time.strftime('%Y-%m-%d %H:%M:%S ', now_time)
# 按日期建立檔案路徑
file_path = './{:s}/{:s}'.format(str(now_time.tm_year), str(now_time.tm_mon))
try:
os.makedirs(file_path) # 該方法建立路徑時,若路徑存在會報異常,使用 try catch 跳過異常
except OSError:
pass
# 寫入資料
try:
fp = open('{:s}/{:s}.txt'.format(file_path, select_date), 'a+', encoding = 'utf-8')
fp.write('閱讀量\t\t 博文題目\n')
view_count = 0 # 總閱讀量
for single_post_info in post_info:
view_count += int(single_post_info[1])
fp.write('{:<12s}{:s}\n'.format(single_post_info[1], single_post_info[0]))
fp.write('------部落格名:{:s} 博文數量:{:d} 總閱讀量:{:d} 統計時間:{:s}\n\n'.format(blog_name, len(post_info), view_count, select_time))
# 關閉資源
fp.close()
except FileNotFoundError:
print('無法開啟指定的檔案')
except LookupError:
print('指定編碼錯誤')
except UnicodeDecodeError:
print('讀取檔案時解碼錯誤')
執行結果
程式會在目錄下按日期建立資料夾
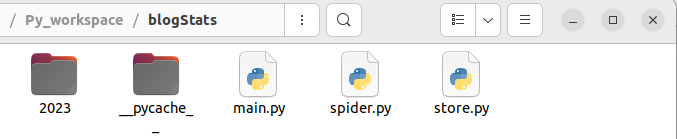
進入後可找到以日期命名的 txt 檔案,以我自己的部落格為例,得到以下統計資訊:
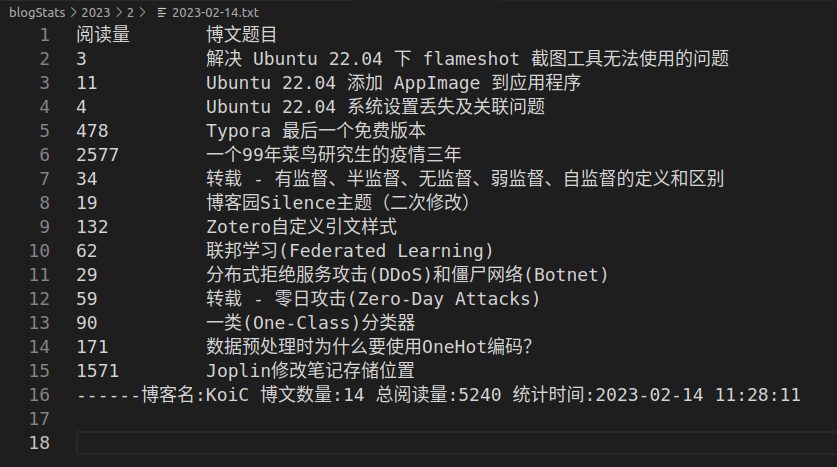
可以將程式掛在伺服器上,定時統計資料,觀察閱讀量的漲幅。
後續我會逐漸完善功能,形成一個自動化的小工具,感興趣的可以點個關注,謝謝閱讀!