【論文筆記】FCN全折積網路
全折積網路(FCN)是用於圖片語意分割的一種折積神經網路(CNN),由Jonathan Long,Evan Shelhamer 和Trevor Darrell提出,由此開啟了深度學習在語意分割中的應用。語意分割是計算機視覺領域很重要的一個分支,在自動駕駛、地面檢測等方面都起到很重要作用。與簡單區分前景後景的影象分割技術不同,語意分割則不僅是區分每個畫素的前後景,更需要將其所屬類別預測出來,屬於畫素層面的分類,是密集的目標識別。傳統用於語意分割的CNN網路每個畫素點用包圍其的物件或區域類別進行標註,無論是在分割速度還是分割精度層面都很不理想。FCN參考了CNN在影象分類領域成功的經驗,是一種端到端、畫素到畫素的模型,在多個語意分割的指標中均達到了state-of-the-art。
1 傳統的CNN在做語意分割存在的問題
CNN做影象分類甚至做目標檢測的效果已經被證明並廣泛應用,影象語意分割本質上也可以認為是稠密的目標識別(需要預測每個畫素點的類別)。對於一般的分類CNN網路,如VGG和Resnet,都會在網路的最後加入一些全連線層,經過softmax後就可以獲得類別概率資訊。但是這個概率資訊是1維的,即只能標識整個圖片的類別,不能標識每個畫素點的類別,所以這種全連線方法不適用於影象分割。
傳統的基於CNN的語意分割方法是:將畫素周圍一個小區域(如25*25)作為CNN輸入,做訓練和預測。這種方法有幾個缺點:
- 儲存開銷很大。例如對每個畫素使用的影象塊的大小為25x25,然後不斷滑動視窗,每次滑動的視窗給CNN進行判別分類,因此則所需的儲存空間根據滑動視窗的次數和大小急劇上升。
- 計算效率低下。相鄰的畫素塊基本上是重複的,針對每個畫素塊逐個計算折積,這種計算也有很大程度上的重複。
- 畫素塊大小的限制了感知區域的大小。通常畫素塊的大小比整幅影象的大小小很多,只能提取一些區域性的特徵,從而導致分類的效能受到限制。
2 FCN網路
2.1 將全連線層轉化為折積層
通常的識別網路,包括LeNet,AlexNet,以及後面更加優秀的網路結構,都是輸入固定大小的影象,得到非空間結構的輸出。但是,這些網路的全連線層也可以看做是覆蓋整個影象區域的折積核。因此,可以將其轉化為全折積網路,那麼可以輸入任意大小的影象,輸出分類特徵圖,保留了空間資訊。
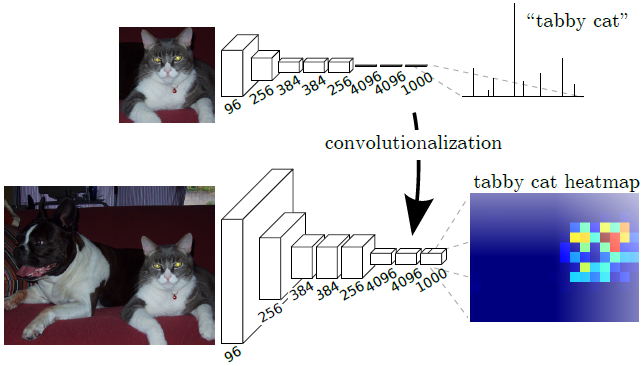
如何將全連線層轉化為折積層?
比如一個7×7×512的特徵矩陣,首先將其展平(flatten)為1×1×25088的向量,再通過全連線層得到長度為4096的向量,總引數量為25088×4096=102760448。如果使用折積(7×7,s1,4096)代替全連線層,輸出也是長度為4096的向量,總引數量為7×7×512×4096=102760448。每一個折積核有7×7×512=25088個引數,而全連線輸出向量中的每一個值都是由25088個值乘上權重得來,計算過程是一樣的,所以4096個折積核的引數可以由全連線層的4096個節點的引數reshape得到。
2.2 上取樣
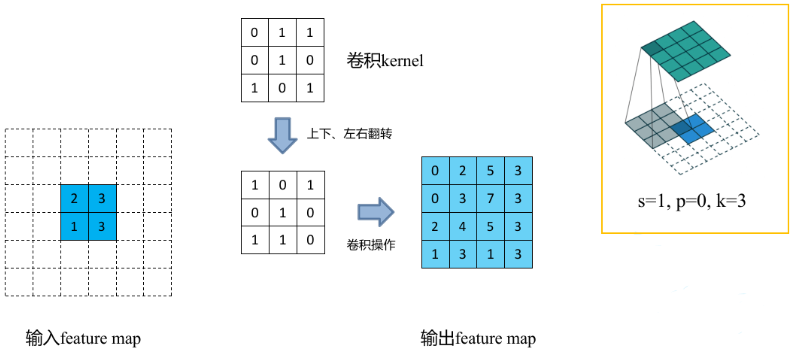
折積操作和池化操作會使得特徵圖的尺寸變小,為得到原影象大小的稠密畫素預測,需要對得到的特徵圖進行上取樣操作。可通過雙線性插值(Bilinear)實現上取樣,且雙線性插值易於通過固定折積核的轉置折積(transposed convolution)實現,轉置折積即為反折積(deconvolution)。在論文中,作者並沒有固定折積核,而是讓折積核變成可學習的引數。轉置折積操作過程如下:
- 在輸入特徵圖元素間填充s-1行、列0(其中s表示轉置折積的步距)
- 在輸入特徵圖四周填充k-p-1行、列0(其中k表示轉置折積的kernel_size大小,p為轉置折積的padding,注意這裡的padding和折積操作中有些不同)
- 將折積核引數上下、左右翻轉
- 做正常折積運算(填充0,步距1)
範例 下面假設輸入的特徵圖大小為2x2(假設輸入輸出都為單通道),通過轉置折積後得到4x4大小的特徵圖。這裡使用的轉置折積核大小為k=3,stride=1,padding=0的情況(忽略偏執bias)。
2.3 跳級結構
如果僅對最後一層的特徵圖進行上取樣得到原圖大小的分割,最終的分割效果往往並不理想。因為最後一層的特徵圖太小,這意味著過多細節的丟失。因此,通過跳級結構將低層,精細層(fine layers)與高層,粗糙層(coarse layers)結合,使得模型兼顧區域性預測以及全域性結構。下圖不顯示折積層,因此VGG中只剩下5個池化層。
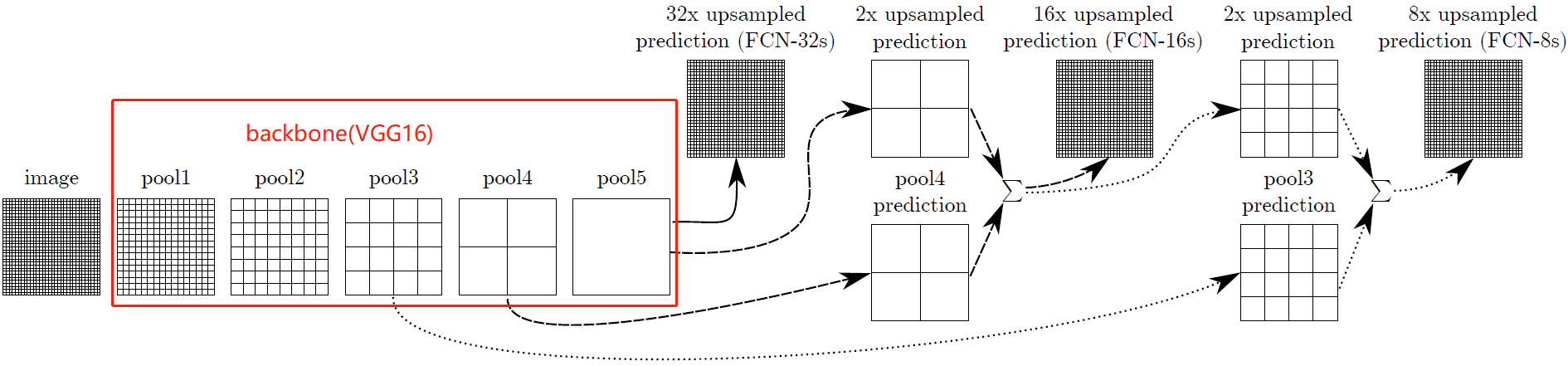
CNN的一大特點在於越深的網路感受野越大,其關於輸入圖片的全域性資訊也越多。影象語意分割要解決的兩大問題是「what」和」where」,即在判斷出影象中出現的物體類別的前提下還要定位物體的位置,深層次的CNN能很好解決「what」這個問題,但是由於網路層次的加深,也破壞了輸入圖片原始的空域資訊而淺層次的CNN網路會更好的保持原始圖片的空域資訊,所以FCN的跳躍結構就是將CNN的淺層次網路和深層次網路結合。
FCN-32s
使用VGG16作為backbone,在5次下取樣後得到7x7x512的特徵矩陣,再經過32倍上取樣恢復原圖大小。具體操作為:
- pool5後新增FC6,由Conv(7×7,s1)+ReLU+Dropout(0.5)組成,輸出特徵矩陣寬高不變,通道數變為4096
- 增加FC7,由Conv(1×1,s1)+ReLU+Dropout(0.5)組成,不改變特徵矩陣那個寬高和通道數
- 增加1x1折積(通道為num_classes)
- 增加反折積層ConvTranspose2d(64×64,s32),將coarse outputs轉化為pixel-dense outputs(長寬為原圖大小,通道數為類別數)

FCN-16s
對於FCN-16s,首先對pool5 feature進行2倍上取樣獲得2x upsampled feature,再把pool4 feature和2x upsampled feature逐點相加,然後對相加的feature進行16倍上取樣,獲得16x upsampled feature prediction。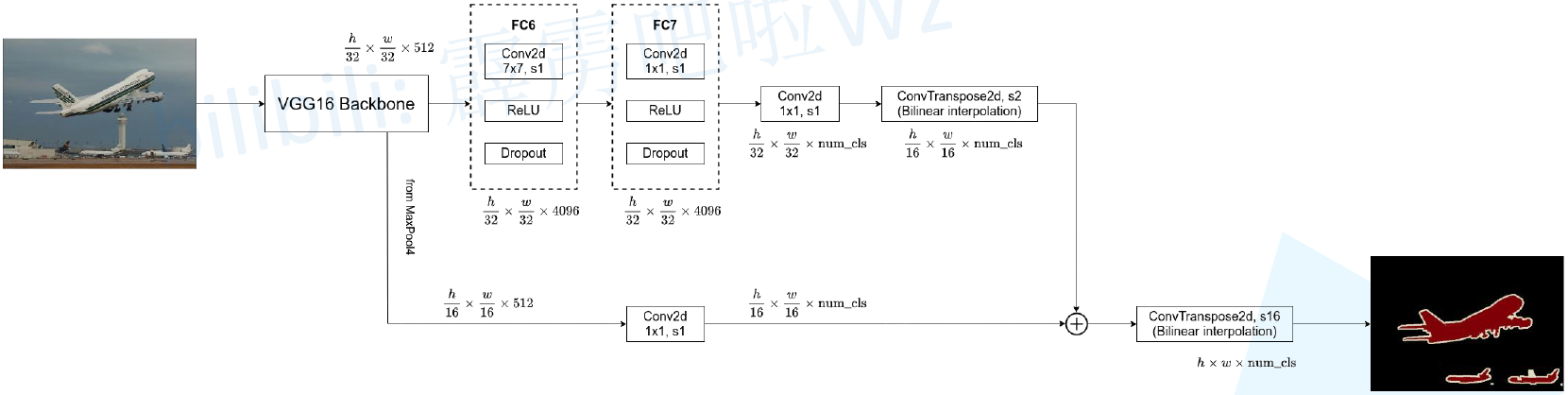
FCN-8s
對於FCN-8s,首先進行pool4+2x upsampled feature逐點相加,然後又進行pool3+2x upsampled逐點相加,即進行更多次特徵融合。得到平均IOU62.7,並且得到更好的細節(沒有提升特別大)。隨著與更低的層進行融合,但是並沒有得到較大的改善,因此沒有進行進一步的融合。
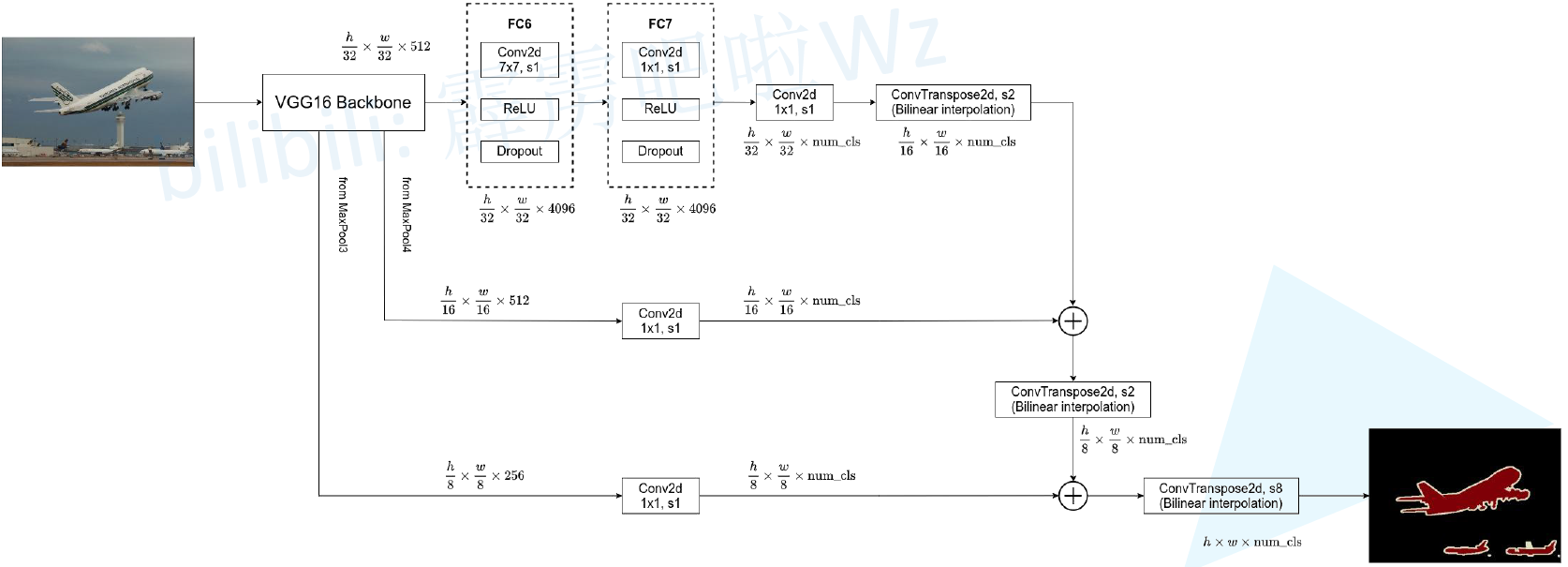
3 訓練
3.1 整體訓練流程
- VGG網路初始化:利用已經訓練好的VGG權重初始化網路,捨棄池化層和池化層後的全連線層;
- 全連線轉全折積:增加FC6,FC7,score層初始化為0,反折積層初始化為雙線性插值,最後一層反折積固定為插值不做學習;
- 訓練FCN-32s:從特徵小圖(16*16*4096)預測分割小圖(16*16*21),之後上取樣得到大圖;
- 訓練網路FCN-16s:融合了2個pooling層(pool4,pool5)的預測結果,反折積步長16;
- 訓練網路FCN-8s:融合了3個pooling層(pool3,pool4,pool5)的預測結果反折積步長8。
3.2 Patchwise Training is Loss Sampling
論文中使用21類的PASCAL VOC資料集,訓練集提供原始圖片和對應的ground truth,ground truth上每個畫素點均有用顏色表示的標籤。圖片輸入模型後得到原圖寬高的輸出,輸出與ground truth計算交叉熵損失。
通常做語意分割的方法都是使用Patchwise訓練,就是指將一張圖片中的重要部分裁剪下來進行訓練以避免整張照片直接進行訓練所產生的資訊冗餘,這種方法有助於快速收斂。FCN如何模擬這樣的隨機選一些patchs組成minibatch的過程呢?答案是先對整個影象進行逐畫素損失的計算,之後從影象上隨機採一些點組成batch,而這個batch的損失就是已經計算出的這些點的損失的平均。這個過程作者稱為「loss sampling」。因為是一次性計算出所有點的損失之後再取樣,相比取樣後再計算損失,loss sampling要更加高效。作者實驗發現,全圖訓練和取樣訓練相比最終效果差不多,但全圖訓練更快收斂,還是直接用整個影象的損失進行訓練。
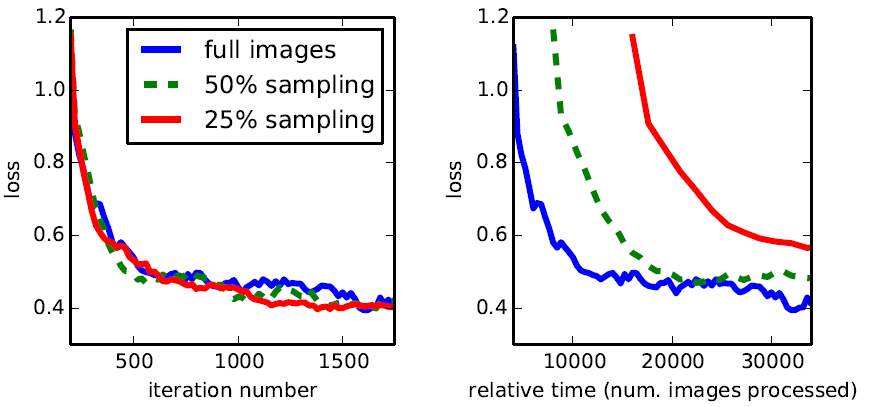
3.3 padding=100
當輸入影象長度或寬度小於192時,下取樣32倍後VGG16 backbone的輸出小於7,但後面接FC6時折積核大小為7,是沒法進行折積操作的。為了避免這個問題產生,FCN中的VGG16網路與原VGG16的一點不同是,FCN在conv1_1層中設定了padding=100來擴充影象。由於(1)語意分割輸入的影象一般不會太小(2)padding會導致計算量增大,後期還要crop裁剪,所以沒必要使用。
3.4 其他
優化器:Optimization SGD+Momentum(momentum=0.9,weight decay =5*0.0001或者2*0.0001);
批尺寸:batch size=20;
學習率:FCN-AlexNet,FCN-VGG16和FCN-GoogLeNet的學習率分別固定為0.001,0.0001,5*0.00001,或者為了偏移,學習率乘以2,訓練過程對上述引數不是很敏感,但是對學習率很敏感。分類分數折積層使用零初始化,隨機初始化並沒有改善。Dropout跟隨之前的網路使用。
Metrics:我們在語意分割和場景分割中評測了四個指標,比如畫素精度,IOU。其中nij為第i類畫素被預測為第j類畫素的數量,ncl為總類別數量。

Fine-tuning: 我們對所有層進行微調,僅僅微調分類層,能達到前者70%的效果。從頭開始訓練網路是不可行的,VGG網路訓練非常耗時(值得注意的是,VGG16是分階段訓練的,我們從完全的16層初始化開始的)。單GPU需要3天微調FCN-32s,在此基礎上,FCN-16s和FCN-8s分別需要在增加一天。
Class Balancing:全折積訓練可以進行類平衡,比如損失新增權重或者損失取樣(sampling loss)。儘管我們的資料並不是那麼平衡(3/4是背景),但是我們發現類平衡不是很必要。
Shift-and-Stitch:發現上取樣更有效,所以沒有采用Shift-and-Stitch
Augmentation 資料集增強方式:隨機映象,畫素在每一個方向上隨機偏移32畫素,但是沒有明顯的提高。
More Training Data:PASCAL VOC 2011 Table1中使用,標註了1112張圖片。Hariharan 收集8498張圖,訓練了SDS分割系統。提高了FCN-VGG16在驗證集上3.4個百分點,Mean IU達到59.4.
參考:
1. 轉置折積(Transposed Convolution)
3. 深度學習論文翻譯--Fully Convolutional Networks for Semantic Segmentation
4. 【影象分割 之 開山之作】 2015-FCN CVPR
5. FCN網路解析
7. FCN論文筆記