Sentinel入門到實操 (限流熔斷降級)
微服務保護——Sentinel
介紹Sentinel
1.背景
Sentinel是阿里巴巴開源的一款微服務流量控制元件。官網地址:https://sentinelguard.io/zh-cn/index.html
Sentinel 具有以下特徵:
•豐富的應用場景:Sentinel 承接了阿里巴巴近 10 年的雙十一大促流量的核心場景,例如秒殺(即突發流量控制在系統容量可以承受的範圍)、訊息削峰填谷、叢集流量控制、實時熔斷下游不可用應用等。
•完備的實時監控:Sentinel 同時提供實時的監控功能。您可以在控制檯中看到接入應用的單臺機器秒級資料,甚至 500 臺以下規模的叢集的彙總執行情況。
•廣泛的開源生態:Sentinel 提供開箱即用的與其它開源框架/庫的整合模組,例如與 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相應的依賴並進行簡單的設定即可快速地接入 Sentinel。
•完善的 SPI 擴充套件點:Sentinel 提供簡單易用、完善的 SPI 擴充套件介面。您可以通過實現擴充套件介面來快速地客製化邏輯。例如客製化規則管理、適配動態資料來源等。
2. 服務保護技術對比
在SpringCloud當中支援多種服務保護技術:
早期比較流行的是Hystrix框架,但目前國內實用最廣泛的還是阿里巴巴的Sentinel框架,這裡我們做下對比:
| Sentinel | Hystrix | |
|---|---|---|
| 隔離策略 | 號誌隔離 | 執行緒池隔離/號誌隔離 |
| 熔斷降級策略 | 基於慢呼叫比例或異常比例 | 基於失敗比率 |
| 實時指標實現 | 滑動視窗 | 滑動視窗(基於 RxJava) |
| 規則設定 | 支援多種資料來源 | 支援多種資料來源 |
| 擴充套件性 | 多個擴充套件點 | 外掛的形式 |
| 基於註解的支援 | 支援 | 支援 |
| 限流 | 基於 QPS,支援基於呼叫關係的限流 | 有限的支援 |
| 流量整形 | 支援慢啟動、勻速排隊模式 | 不支援 |
| 系統自適應保護 | 支援 | 不支援 |
| 控制檯 | 開箱即用,可設定規則、檢視秒級監控、機器發現等 | 不完善 |
| 常見框架的適配 | Servlet、Spring Cloud、Dubbo、gRPC 等 | Servlet、Spring Cloud Netflix |
3.安裝Sentinel
1)下載
sentinel官方提供了UI控制檯,方便我們對系統做限流設定。大家可以在GitHub下載。
課前資料也提供了下載好的jar包:

2)執行
將jar包放到任意非中文目錄,執行命令:
java -jar sentinel-dashboard-1.8.1.jar
如果要修改Sentinel的預設埠、賬戶、密碼,可以通過下列設定:
| 設定項 | 預設值 | 說明 |
|---|---|---|
| server.port | 8080 | 伺服器埠 |
| sentinel.dashboard.auth.username | sentinel | 預設使用者名稱 |
| sentinel.dashboard.auth.password | sentinel | 預設密碼 |
例如,修改埠:
java -Dserver.port=8090 -jar sentinel-dashboard-1.8.1.jar
3)存取
存取http://localhost:8080頁面,就可以看到sentinel的控制檯了:需要輸入賬號和密碼,預設都是:sentinel

登入後,發現一片空白,什麼都沒有:這是因為我們還沒有與微服務整合。
微服務整合Sentinel
四步驟:
0. 啟動Nacos
進入到nacos的bin資料夾中cmd:startup.cmd -m standalone
1. 依賴
在指定微服務中匯入該依賴
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
2. yaml組態檔
修改application.yaml檔案,新增下面內容:
server:
port: 8088 #微服務地址
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8080 #sentinel控制檯存取地址
3. 存取任意介面
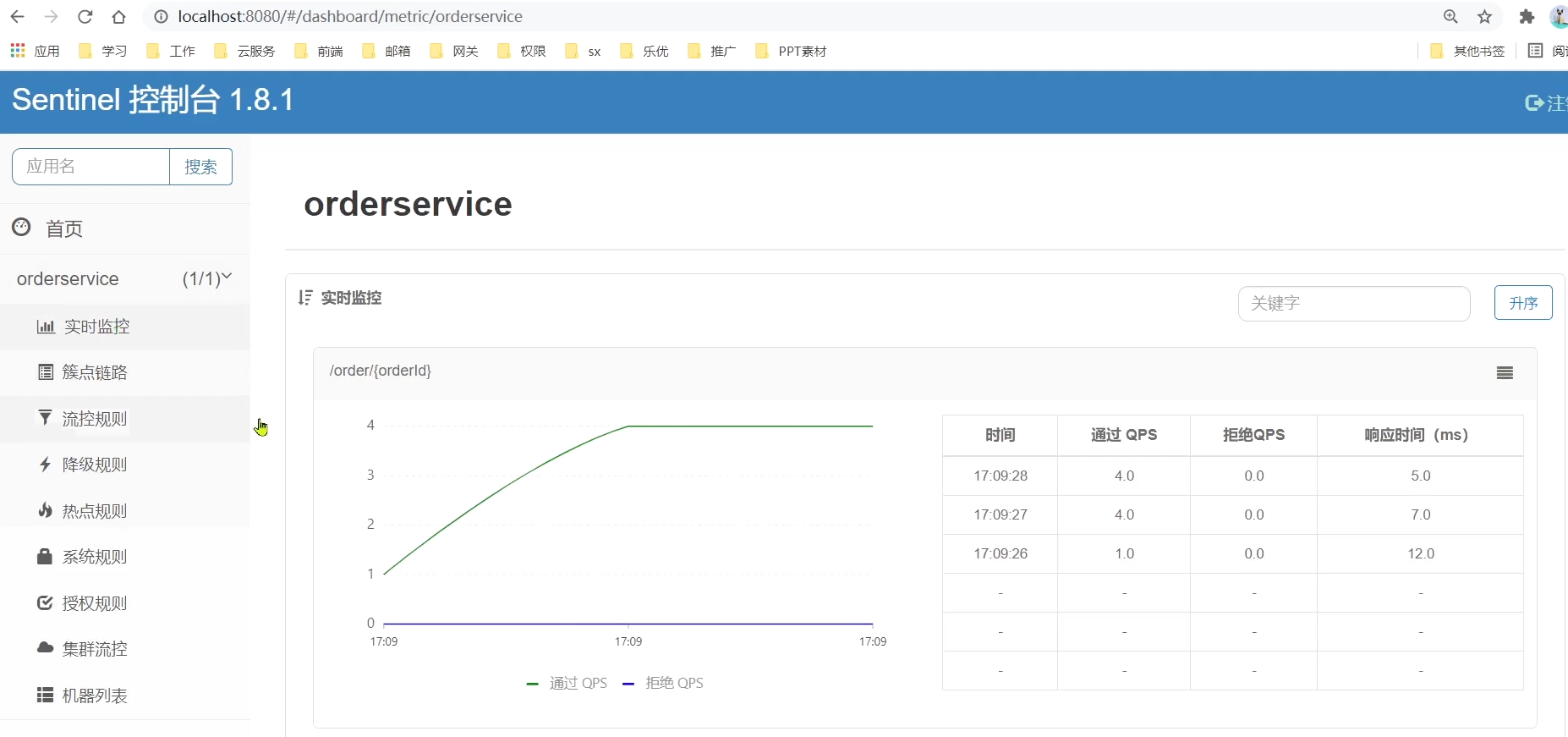
開啟瀏覽器,存取任意介面 如:http://localhost:8088/order/101,這樣才能觸發sentinel的監控。
然後再存取sentinel的控制檯,檢視效果:
FeignClient整合Sentinel
整合後編寫失敗降級邏輯:就是請求失敗後不是直接返回一個異常而是返回一個空物件(保證使用者體驗)
SpringCloud中,微服務呼叫都是通過Feign來實現的,因此做使用者端保護必須整合Feign和Sentinel。
1. 修改組態檔
保證已經有了Feign和sentinel依賴
修改OrderService的application.yml檔案,開啟Feign的Sentinel功能:
feign:
sentinel:
enabled: true # 開啟feign對sentinel的支援
2. 編寫請求失敗降級邏輯
業務失敗後,不能直接報錯,而應該返回使用者一個友好提示或者預設結果,這個就是失敗降級邏輯。
給FeignClient編寫請求失敗後的降級邏輯
①方式一:FallbackClass,無法對遠端呼叫的異常做處理【不推薦】
②方式二:FallbackFactory,可以對遠端呼叫的異常做處理【推薦】
這裡我們演示方式二的請求失敗降級處理。
步驟一:在feing-api專案中定義類,實現FallbackFactory:
程式碼:
package cn.itcast.feign.clients.fallback;
import cn.itcast.feign.clients.UserClient;
import cn.itcast.feign.pojo.User;
import feign.hystrix.FallbackFactory;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class UserClientFallbackFactory implements FallbackFactory<UserClient> {
@Override
public UserClient create(Throwable throwable) {
return new UserClient() { //前提是必須有UserClient類和findById方法
@Override
public User findById(Long id) {
log.error("查詢使用者異常", throwable);
return new User();
}
};
}
}
步驟二:在feing-api專案中的DefaultFeignConfiguration類中將UserClientFallbackFactory註冊為一個Bean:
記得設定類需要@Component
@Bean
public UserClientFallbackFactory userClientFallbackFactory(){
return new UserClientFallbackFactory();
}
步驟三:在feing-api專案中的UserClient介面中使用UserClientFallbackFactory:
import cn.itcast.feign.clients.fallback.UserClientFallbackFactory;
import cn.itcast.feign.pojo.User;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
@FeignClient(value = "userservice", fallbackFactory = UserClientFallbackFactory.class)
public interface UserClient {
@GetMapping("/user/{id}")
User findById(@PathVariable("id") Long id);
}
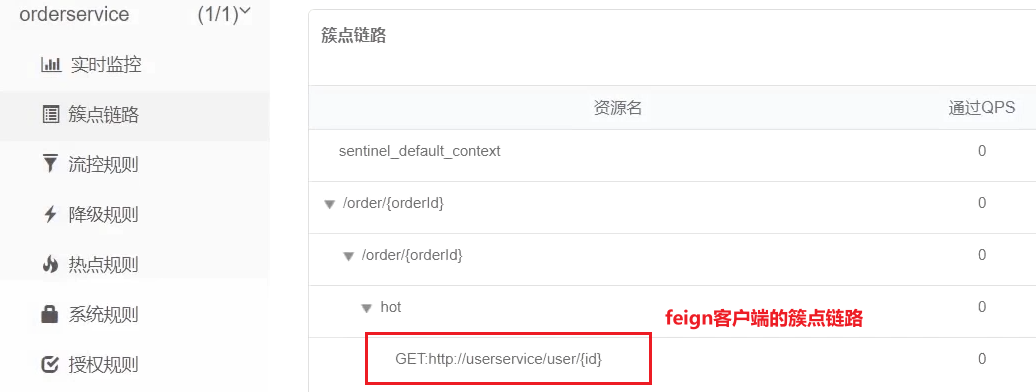
重啟後,存取一次訂單查詢業務,然後檢視sentinel控制檯,可以看到新的簇點鏈路:
雪崩問題
白話:雪崩問題是微服務之間相互呼叫,因為呼叫鏈中的一個服務故障,引起整個鏈路都無法存取的情況。
服務A和其他服務需要服務D響應,但此時服務D故障了,服務A無法接收到結果。由於伺服器支援的執行緒和並行數有限,請求一致阻塞會導致伺服器資源耗盡,從而導致依賴於當前服務的其它服務隨著時間的推移,最終也都會變的不可用,形成級聯失敗,雪崩就發生了
與服務D執行緒有關的服務雪崩:
服務D故障——> 服務A等有關服務阻塞
與服務D執行緒無關服務雪崩:
服務D故障——> 大量請求阻塞 ——> 伺服器資源耗盡 ——>其他服務變得不可用 ——> 級聯失敗(雪崩)
如果服務提供者I發生了故障,當前的應用的部分業務因為依賴於服務I,因此也會被阻塞。此時,其它不依賴於服務I的業務似乎不受影響。但是,依賴服務I的業務請求被阻塞,使用者不會得到響應,則tomcat的這個執行緒不會釋放,於是越來越多的使用者請求到來,越來越多的執行緒會阻塞。伺服器支援的執行緒和並行數有限,請求一直阻塞,會導致伺服器資源耗盡,從而導致所有其它服務都不可用,那麼當前服務也就不可用了。那麼,依賴於當前服務的其它服務隨著時間的推移,最終也都會變的不可用,形成級聯失敗,雪崩就發生了

解決方案
限流是對服務的保護,避免因瞬間高並行流量而導致服務故障,進而避免雪崩。是一種預防措施。
超時處理、執行緒隔離、降級熔斷是在部分服務故障時,將故障控制在一定範圍,避免雪崩。是一種補救措施。
1. 預防措施
1.1 限流
流量控制:限制業務存取的QPS,避免服務因流量的突增而故障。

2. 補救措施
2.1 超時處理
超時處理:設定超時時間,請求超過一定時間沒有響應就返回錯誤資訊,不會無休止等待
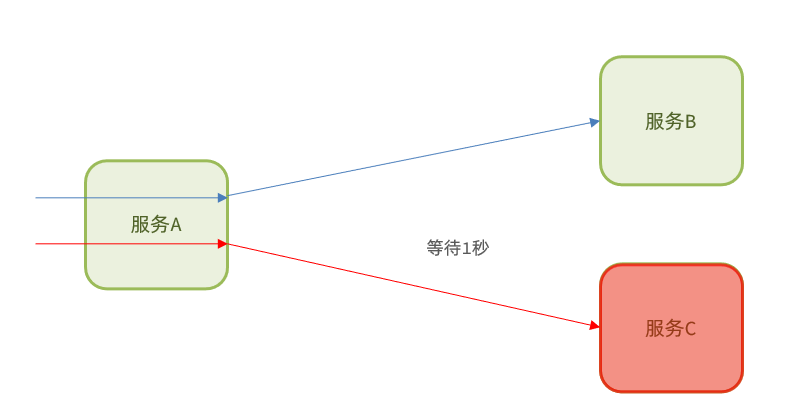
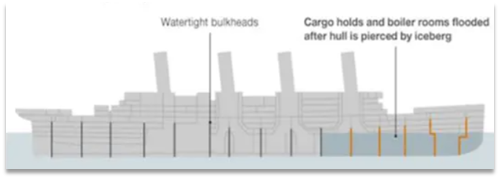
2.2 艙壁模式
艙壁模式來源於船艙的設計:船艙都會被隔板分離為多個獨立空間,當船體破損時,只會導致部分空間進入,將故障控制在一定範圍內,避免整個船體都被淹沒。
我們可以限定每個業務能使用的執行緒數,避免耗盡整個tomcat的資源,因此也叫執行緒隔離。

2.3 斷路器
斷路器模式:由斷路器統計業務執行的異常比例,如果超出閾值則會熔斷該業務,攔截存取該業務的一切請求。
斷路器會統計存取某個服務的請求數量,異常比例:
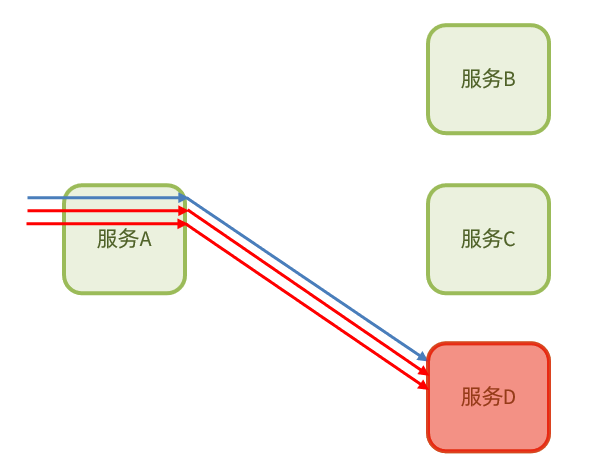
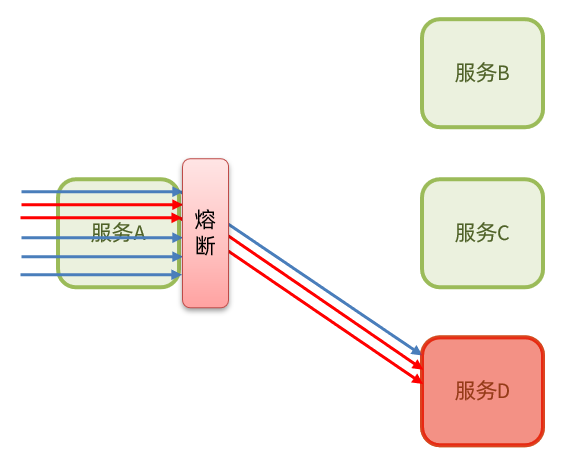
當發現存取服務D的請求異常比例過高時,認為服務D有導致雪崩的風險,會攔截存取服務D的一切請求,形成熔斷:
限流:流量控制
1. 簇點鏈路
當請求進入微服務時,首先會存取DispatcherServlet,然後進入Controller、Service、Mapper,這樣的一個呼叫鏈就叫做簇點鏈路。簇點鏈路中被監控的每一個介面就是一個資源。
預設情況下sentinel會監控SpringMVC的每一個端點(Endpoint,也就是controller中的方法),因此SpringMVC的每一個端點(Endpoint)就是呼叫鏈路中的一個資源。
例如,我們剛才存取的order-service中的OrderController中的端點:/order/

流控、熔斷等都是針對簇點鏈路中的資源來設定的,因此我們可以點選對應資源後面的按鈕來設定規則:
- 流控:流量控制
- 降級:降級熔斷
- 熱點:熱點引數限流,是限流的一種
- 授權:請求的許可權控制
2. 流控模式
QPS是每秒請求數
流控模式有哪些?
•直接:對當前資源限流
•關聯:高優先順序資源觸發閾值,對低優先順序資源限流。
•鏈路:閾值統計時,只統計從指定資源進入當前資源的請求,是對請求來源的限流
2.1 直接模式
直接模式:請求存取介面在每秒內只能通過n個請求(n是單機閾值),其他請求會報錯429:被限流
設定規則:

2.2 關聯模式
需要對哪個介面限流就對哪個介面(端點)設定流控
使用場景:比如使用者支付時需要修改訂單狀態,同時使用者要查詢訂單。查詢和修改操作會爭搶資料庫鎖,產生競爭。業務需求是優先支付和更新訂單的業務,因此當修改訂單業務觸發閾值時,需要對查詢訂單業務限流。
滿足以下條件可以使用關聯模式:
- 兩個有競爭關係的資源
- 一個優先順序較高,一個優先順序較低
關聯模式:統計與當前資源相關的另一個資源(相不相關人為說了算),觸發閾值時,對當前資源限流
設定規則:
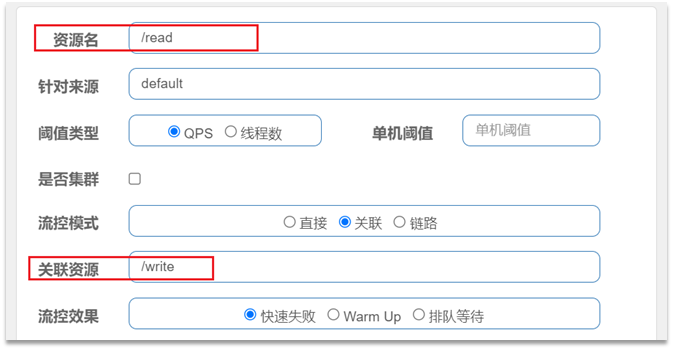
語法說明:當/write資源存取量觸發閾值n時,就會對/read資源限流,避免影響/write資源。
舉例:
需求說明:
-
在OrderController新建兩個端點:/order/query和/order/update,無需實現業務
-
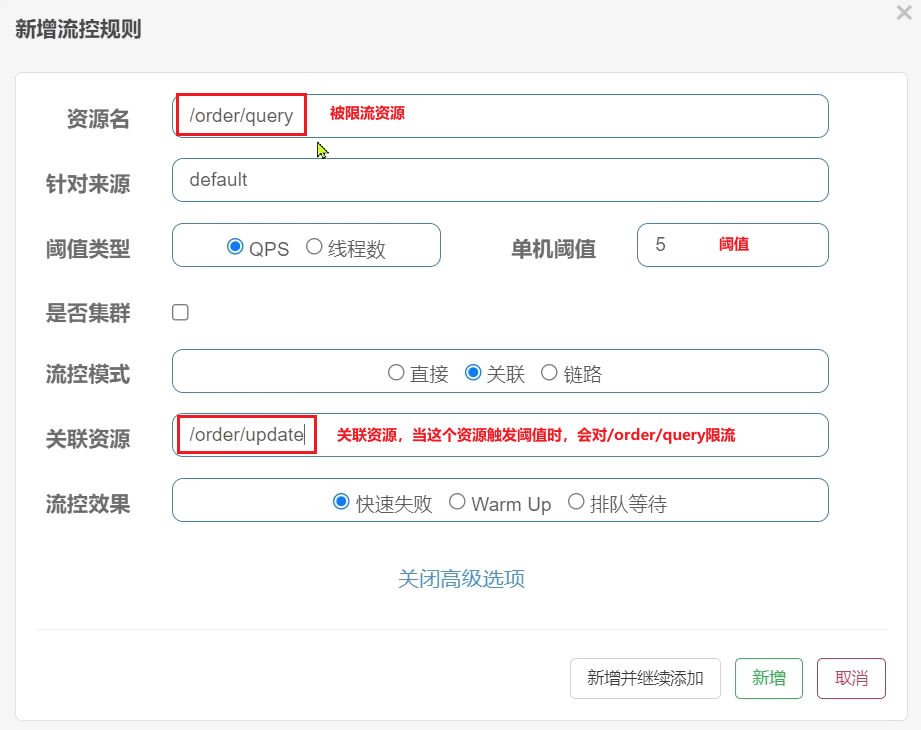
設定流控規則,當/order/ update資源被存取的QPS超過5時,對/order/query請求限流
1)定義/order/query端點,模擬訂單查詢
@GetMapping("/query")
public String queryOrder() {
return "查詢訂單成功";
}
2)定義/order/update端點,模擬訂單更新
@GetMapping("/update")
public String updateOrder() {
return "更新訂單成功";
}
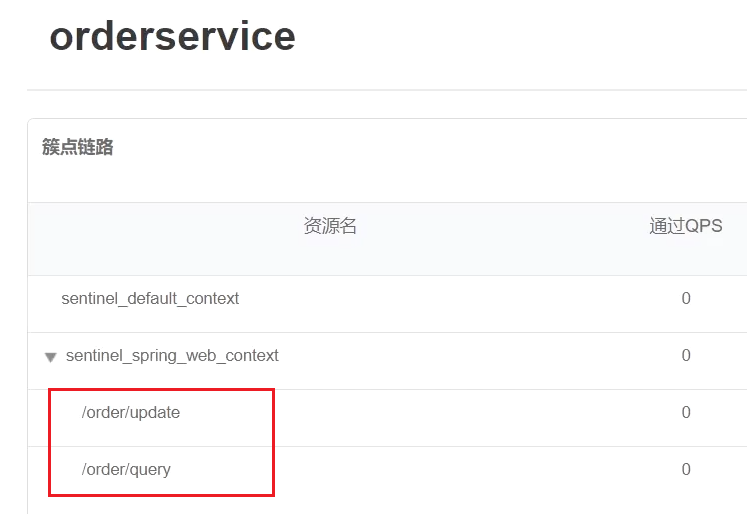
重啟微服務並存取介面,檢視sentinel控制檯的簇點鏈路:
3)設定流控規則
對哪個端點限流,就點選哪個端點後面的按鈕。我們是對訂單查詢/order/query限流,因此點選它後面的按鈕:

在表單中填寫流控規則:
4)在Jmeter測試
選擇《流控模式-關聯》:
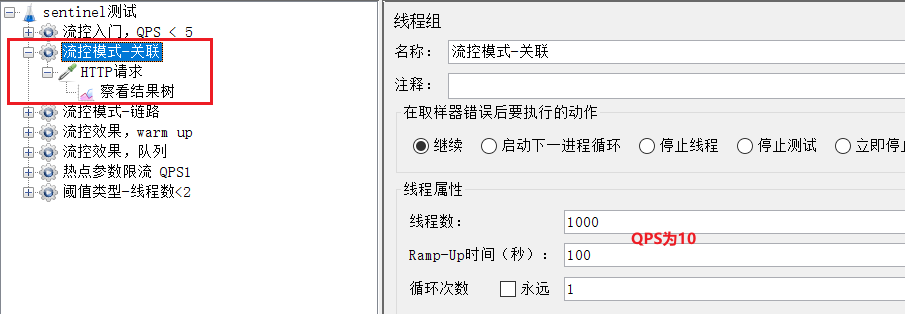
可以看到1000個使用者,100秒,因此QPS為10,超過了我們設定的閾值:5
檢視http請求:
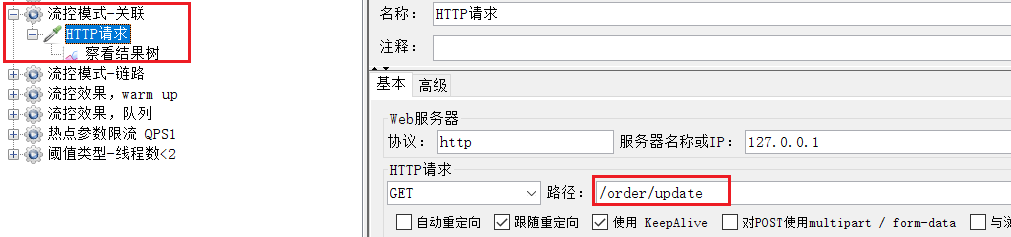
請求的目標是/order/update,這樣這個斷點就會觸發閾值。
但限流的目標是/order/query,我們在瀏覽器存取,可以發現:確實被限流了。

2.3鏈路模式
鏈路模式:只針對從指定鏈路存取到本資源的請求做統計,判斷是否超過閾值。
設定範例:
例如有兩條請求鏈路:
- /test1 --> /common
- /test2 --> /common
test1和test2是介面,common一般是方法。判斷從這個介面存取這個方法的單機閾值是否到達QPS,超過則限制
如果只希望統計從/test2進入到/common的請求,則可以這樣設定:
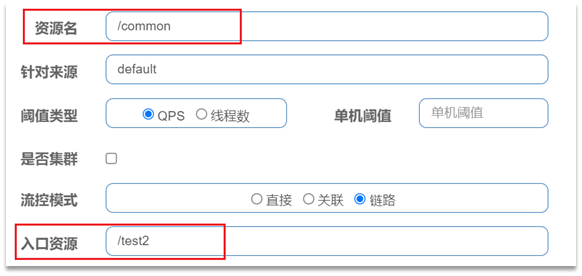
舉例:
需求:有查詢訂單和建立訂單業務,兩者都需要查詢商品。針對從查詢訂單進入到查詢商品的請求統計,並設定限流。
步驟:
-
在OrderService中新增一個queryGoods方法,不用實現業務
-
在OrderController中,改造/order/query端點,呼叫OrderService中的queryGoods方法
-
在OrderController中新增一個/order/save的端點,呼叫OrderService的queryGoods方法
-
給queryGoods設定限流規則,從/order/query進入queryGoods的方法限制QPS必須小於2
實現:
1)新增查詢商品方法
在order-service服務中,給OrderService類新增一個queryGoods方法:
public void queryGoods(){
System.err.println("查詢商品");
}
2)查詢訂單時,查詢商品
在order-service的OrderController中,修改/order/query端點的業務邏輯:
@GetMapping("/query")
public String queryOrder() {
// 查詢商品
orderService.queryGoods();
// 查詢訂單
System.out.println("查詢訂單");
return "查詢訂單成功";
}
3)新增訂單,查詢商品
在order-service的OrderController中,修改/order/save端點,模擬新增訂單:
@GetMapping("/save")
public String saveOrder() {
// 查詢商品
orderService.queryGoods();
// 查詢訂單
System.err.println("新增訂單");
return "新增訂單成功";
}
4)給查詢商品新增資源標記
預設情況下,OrderService中的方法是不被Sentinel監控的,需要我們自己通過註解來標記要監控的方法。
給OrderService的queryGoods方法新增@SentinelResource註解:
@SentinelResource("goods")
public void queryGoods(){
System.err.println("查詢商品");
}
鏈路模式中,是對不同來源的兩個鏈路做監控。但是sentinel預設會給進入SpringMVC的所有請求設定同一個root資源,會導致鏈路模式失效。
我們需要關閉這種對SpringMVC的資源聚合,修改order-service服務的application.yml檔案:
spring:
cloud:
sentinel:
web-context-unify: false # 關閉context整合
重啟服務,存取/order/query和/order/save,可以檢視到sentinel的簇點鏈路規則中,出現了新的資源:
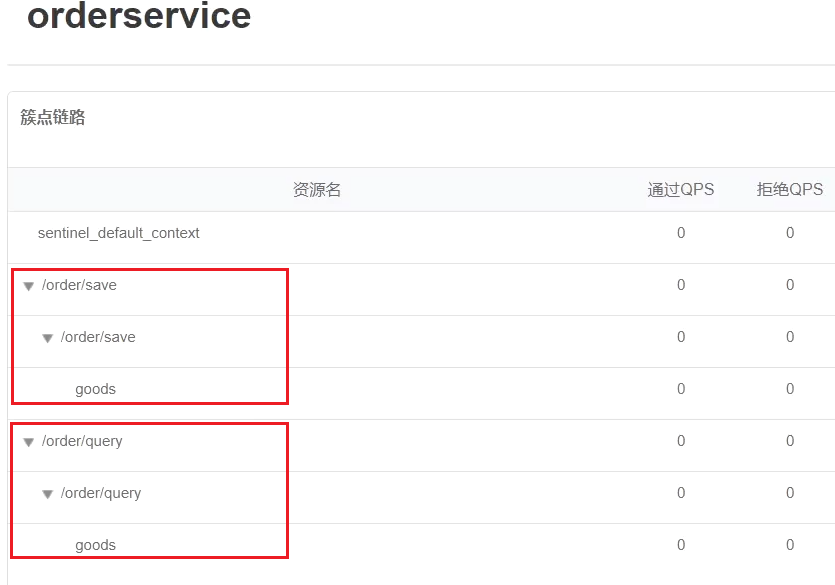
5)新增流控規則
點選goods資源後面的流控按鈕,在彈出的表單中填寫下面資訊:只統計從/order/query進入/goods的資源,QPS閾值為2,超出則被限流。

6)Jmeter測試
選擇《流控模式-鏈路》:
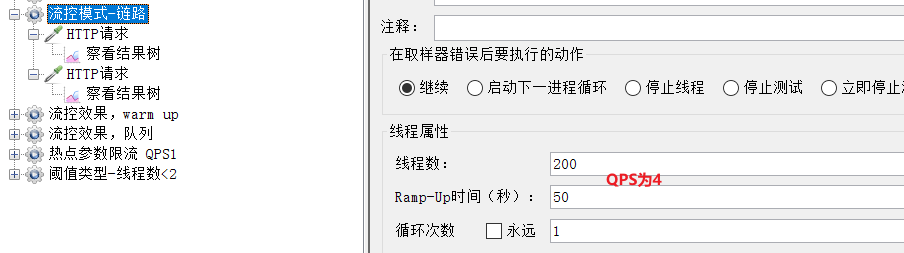
可以看到這裡200個使用者,50秒內發完,QPS為4,超過了我們設定的閾值2
一個http請求是存取/order/save:
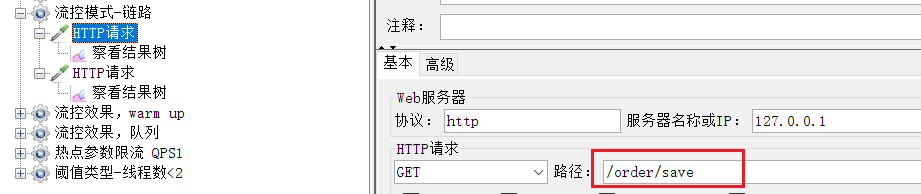
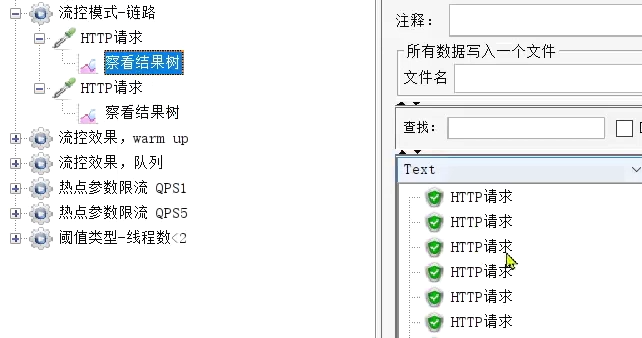
執行的結果:完全不受影響。
另一個是存取/order/query:
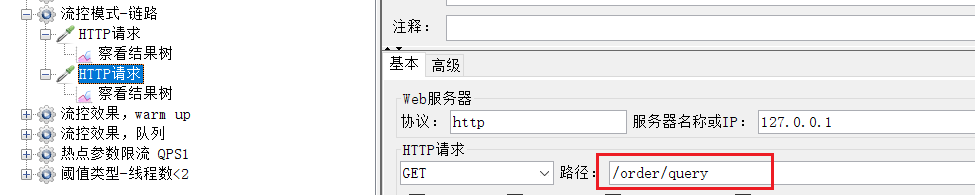
執行結果:每次只有2個通過。
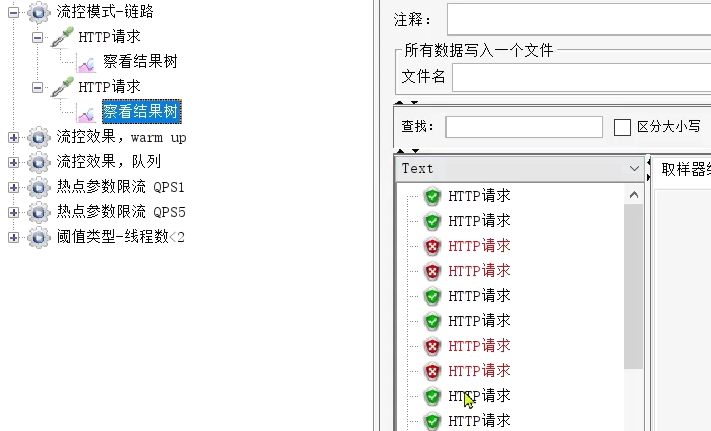
3. 流控效果
快速失敗:QPS超過閾值時,拒絕新的請求
warm up: QPS超過閾值時,拒絕新的請求;QPS閾值是逐漸提升的,可以避免冷啟動時高並行導致服務宕機。
排隊等待:請求會進入佇列,按照閾值允許的時間間隔依次執行請求;如果請求預期等待時長大於超時時間,直接拒絕
在流控的高階選項中,還有一個流控效果選項:
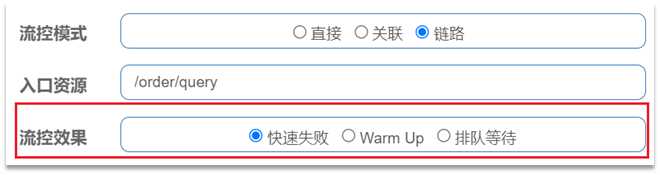
流控效果是指請求達到流控閾值時應該採取的措施,包括三種:
-
快速失敗:達到閾值後,新的請求會被立即拒絕並丟擲FlowException異常。是預設的處理方式。
-
warm up:預熱模式,對超出閾值的請求同樣是拒絕並丟擲異常。但這種模式閾值會動態變化,從一個較小值逐漸增加到最大閾值。
-
排隊等待(勻速器):讓所有的請求按照先後次序排隊執行,兩個請求的間隔不能小於指定時長
【勻速排隊,讓請求以勻速的速度通過,閾值型別必須設定為QPS,否則無效】
3.1 快速失敗
達到閾值後,新的請求會被立即拒絕並丟擲FlowException異常。是預設的處理方式。
3.2 warm up
閾值一般是一個微服務能承擔的最大QPS,但是一個服務剛剛啟動時,一切資源尚未初始化(冷啟動),如果直接將QPS跑到最大值,可能導致服務瞬間宕機。
warm up也叫預熱模式,是應對服務冷啟動的一種方案。請求閾值初始值是 maxThreshold / coldFactor,持續指定時長後,逐漸提高到maxThreshold值。而coldFactor的預設值是3
例如,我設定QPS的maxThreshold為10,預熱時間為5秒,那麼初始閾值就是 10 / 3 ,也就是3,然後在5秒後逐漸增長到10.
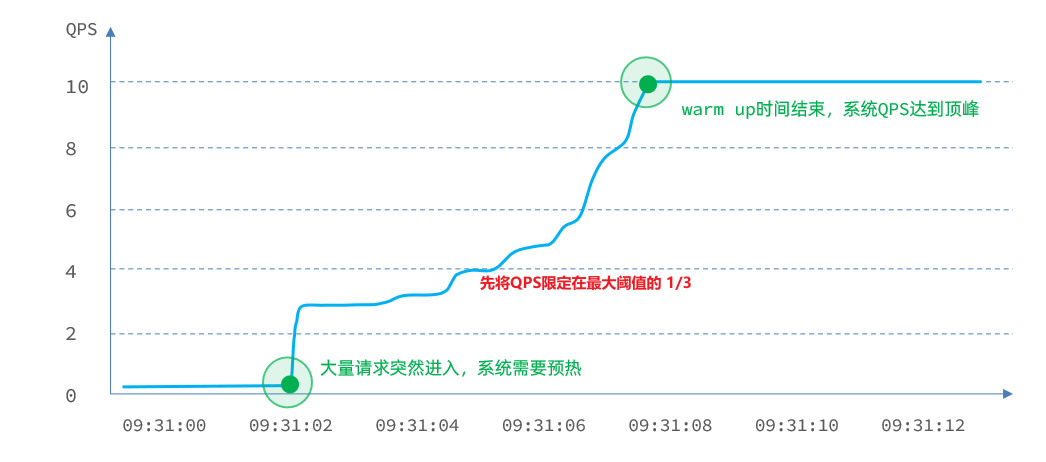
舉例:
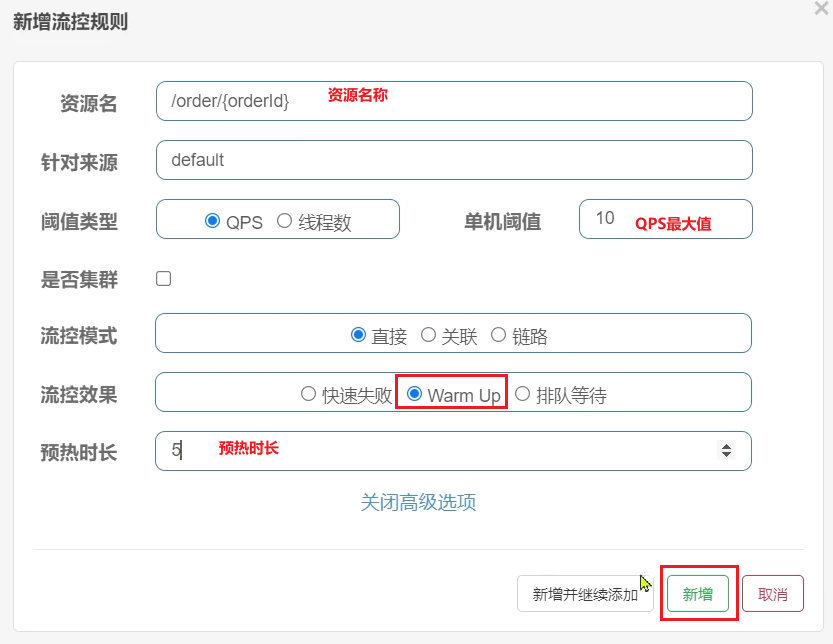
需求:給/order/{orderId}這個資源設定限流,最大QPS為10,利用warm up效果,預熱時長為5秒
1)設定流控規則:
2)Jmeter測試
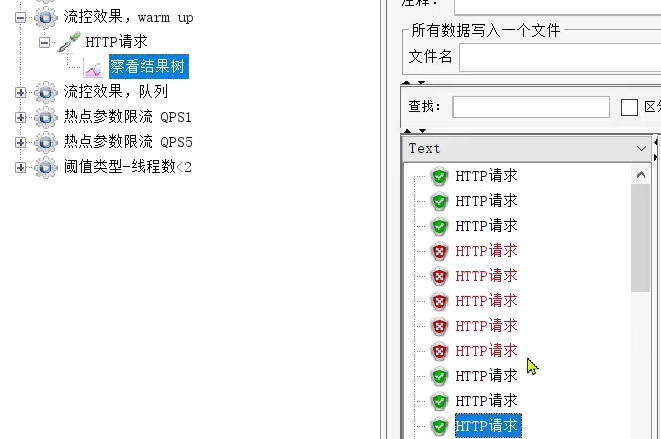
選擇《流控效果,warm up》:
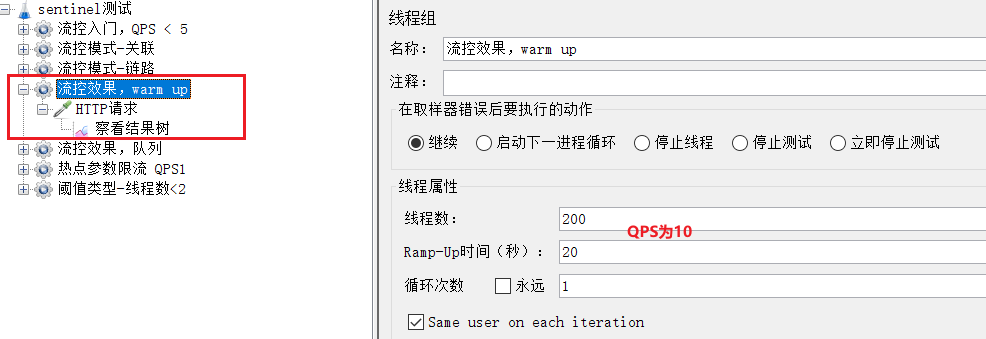
QPS為10.
剛剛啟動時,大部分請求失敗,成功的只有3個,說明QPS被限定在3:
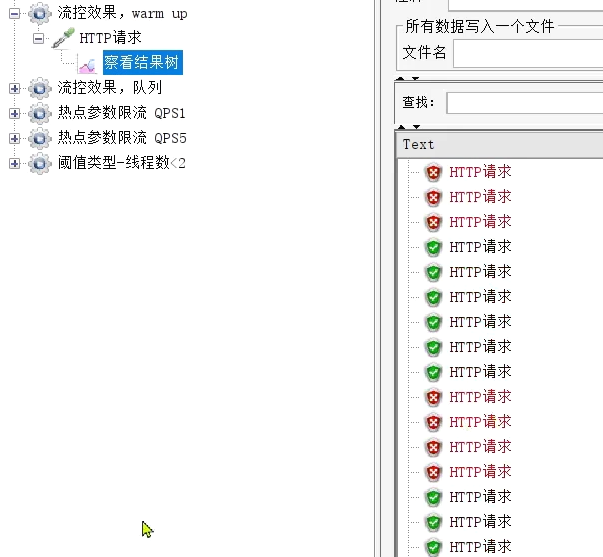
隨著時間推移,成功比例越來越高:
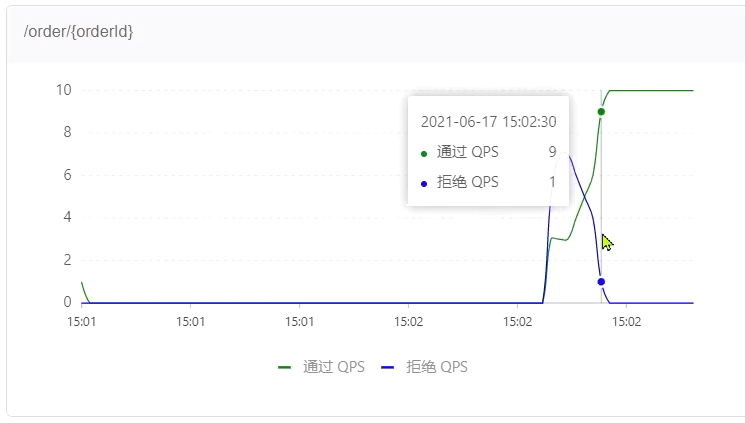
到Sentinel控制檯檢視實時監控:

一段時間後:
3.3 排隊等待
當請求超過QPS閾值時,快速失敗和warm up 會拒絕新的請求並丟擲異常。
而排隊等待則是讓所有請求進入一個佇列中,然後按照閾值允許的時間間隔依次執行。後來的請求必須等待前面執行完成,如果請求預期的等待時間超出最大時長,則會被拒絕。
工作原理
例如:QPS = 5,意味著每200ms處理一個佇列中的請求;timeout = 2000,意味著預期等待時長超過2000ms的請求會被拒絕並丟擲異常。
那什麼叫做預期等待時長呢?
比如現在一下子同時來了12 個請求,因為每200ms執行一個請求,那麼:
- 第6個請求的預期等待時長 = 200 * (6 - 1) = 1000ms
- 第12個請求的預期等待時長 = 200 * (12-1) = 2200ms
現在,第1秒同時接收到10個請求,但第2秒只有1個請求,此時QPS的曲線這樣的:
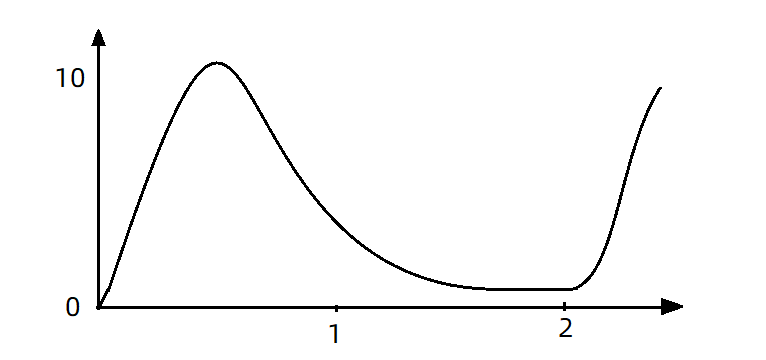
如果使用佇列模式做流控,所有進入的請求都要排隊,以固定的200ms的間隔執行,QPS會變的很平滑:
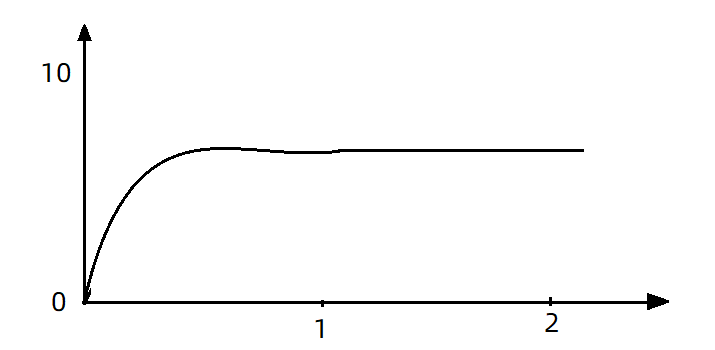
平滑的QPS曲線,對於伺服器來說是更友好的。
舉例:
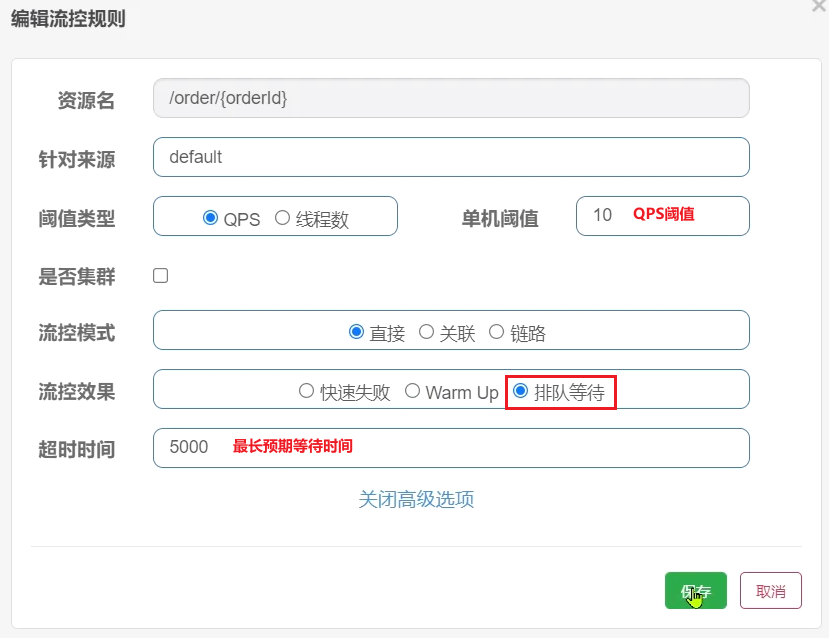
需求:給/order/{orderId}這個資源設定限流,最大QPS為10,利用排隊的流控效果,超時時長設定為5s
1)新增流控規則
2)Jmeter測試
選擇《流控效果,佇列》:
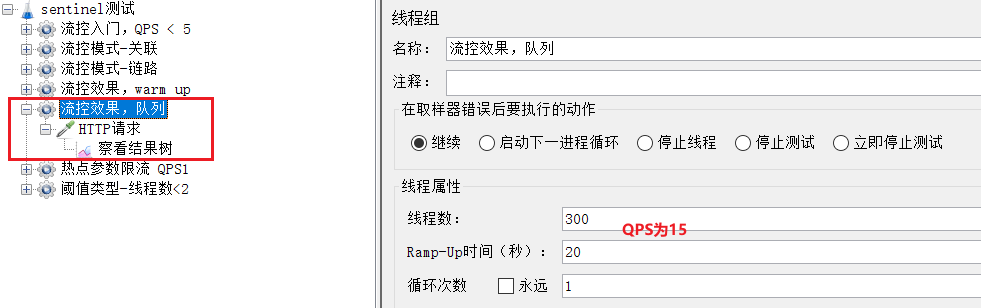
QPS為15,已經超過了我們設定的10。
如果是之前的 快速失敗、warmup模式,超出的請求應該會直接報錯。
但是我們看看佇列模式的執行結果:
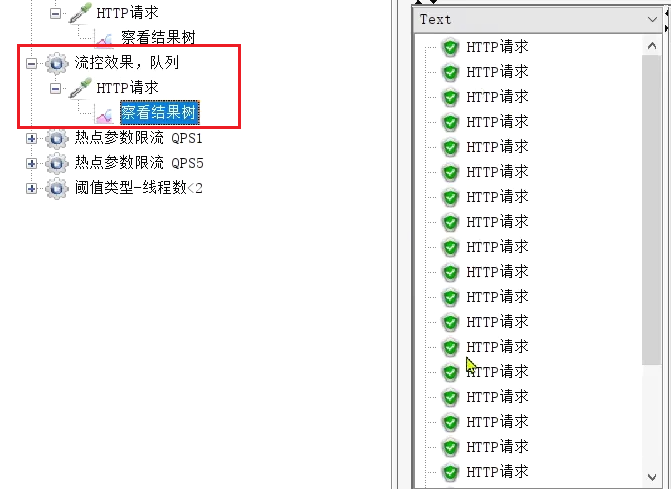
全部都通過了。
再去sentinel檢視實時監控的QPS曲線:
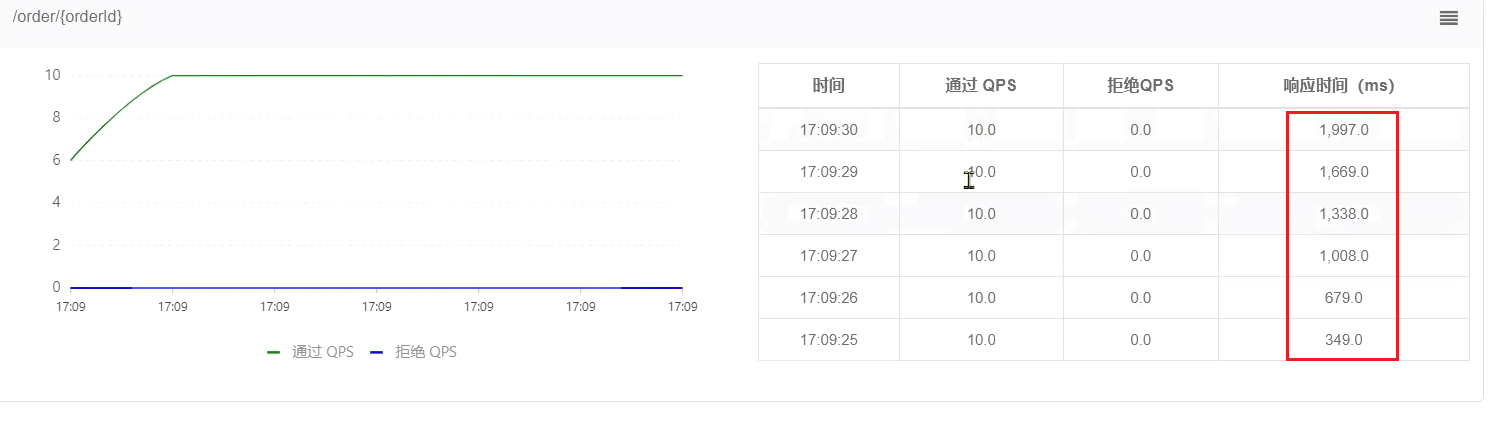
QPS非常平滑,一致保持在10,但是超出的請求沒有被拒絕,而是放入佇列。因此響應時間(等待時間)會越來越長。
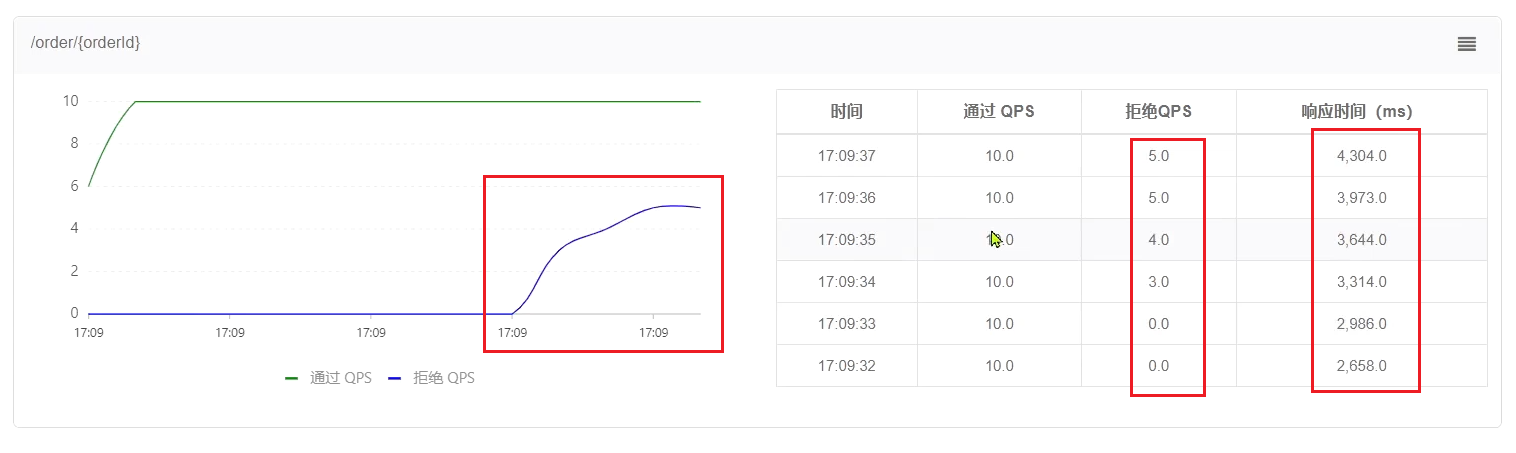
當佇列滿了以後,才會有部分請求失敗:
限流 :熱點引數限流
之前的限流是統計存取某個資源的所有請求,判斷是否超過QPS閾值。而熱點引數限流是分別統計引數值相同的請求,判斷是否超過QPS閾值。
1. 全域性引數限流
例如,一個根據id查詢商品的介面:

存取/goods/{id}的請求中,id引數值會有變化,熱點引數限流會根據引數值分別統計QPS,統計結果:

當id=1的請求觸發閾值被限流時,id值不為1的請求不受影響。
設定範例:

解釋:對hot這個資源的0號引數(第一個引數)做統計,每1秒相同引數值的請求數不能超過5
2. 熱點引數限流
剛才的設定中,對查詢商品這個介面的所有商品一視同仁,QPS都限定為5.
而在實際開發中,可能部分商品是熱點商品,例如秒殺商品,我們希望這部分商品的QPS限制與其它商品不一樣,高一些。那就需要設定熱點引數限流的高階選項了:
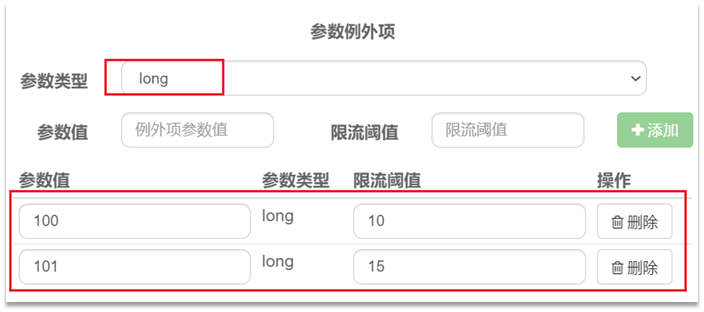
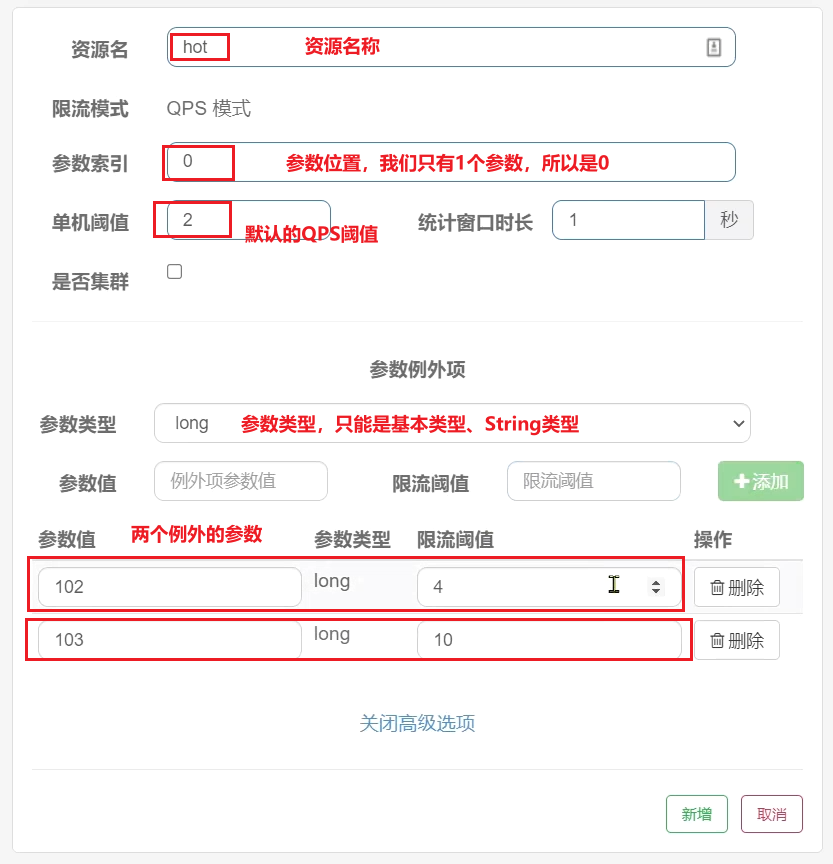
結合上一個設定,這裡的含義是對0號的long型別引數限流,每1秒相同引數的QPS不能超過5,有兩個例外:
•如果引數值是100,則每1秒允許的QPS為10
•如果引數值是101,則每1秒允許的QPS為15
案例
案例需求:給/order/{orderId}這個資源新增熱點引數限流,規則如下:
•預設的熱點引數規則是每1秒請求量不超過2
•給102這個引數設定例外:每1秒請求量不超過4
•給103這個引數設定例外:每1秒請求量不超過10
注意事項:熱點引數限流對預設的SpringMVC資源無效,需要利用@SentinelResource註解標記資源
1)標記資源
給order-service中的OrderController中的/order/{orderId}資源新增註解:

2)熱點引數限流規則
存取該介面,可以看到我們標記的hot資源出現了:
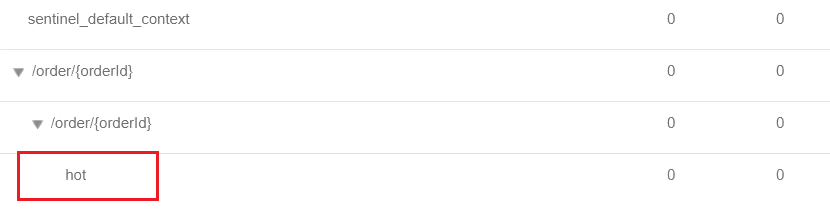
這裡不要點選hot後面的按鈕,頁面有BUG
點選左側選單中熱點規則選單:
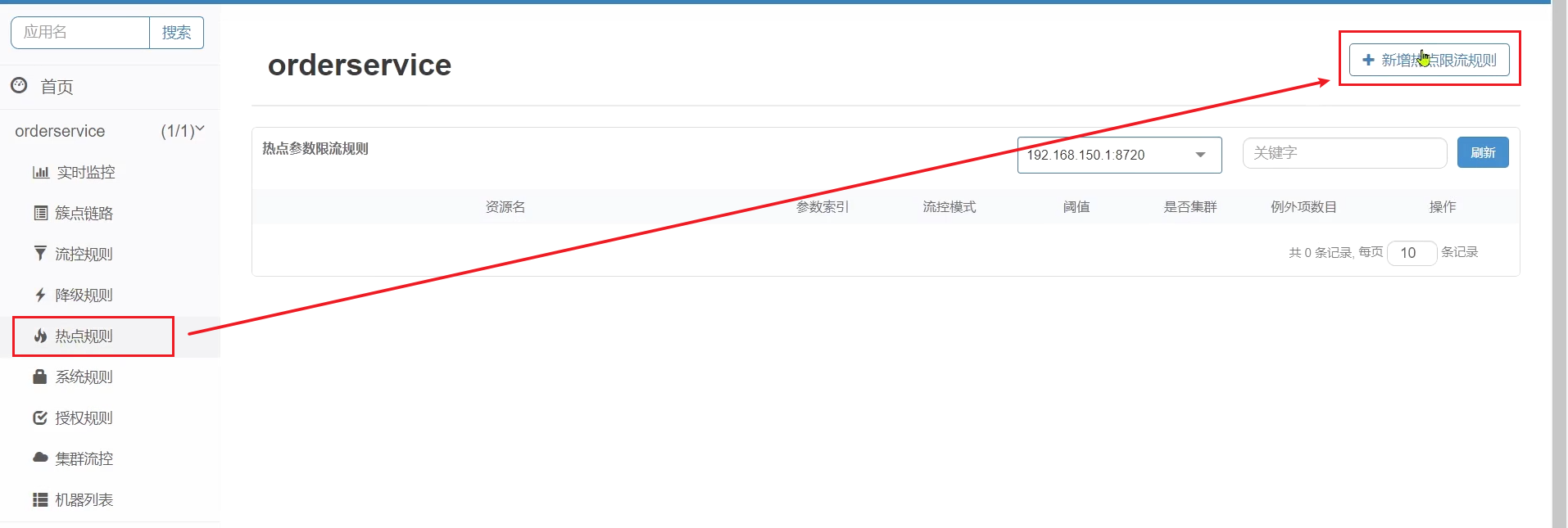
點選新增,填寫表單:
3)Jmeter測試
選擇《熱點引數限流 QPS1》:

這裡發起請求的QPS為5.
包含3個http請求:
普通引數,QPS閾值為2

執行結果:

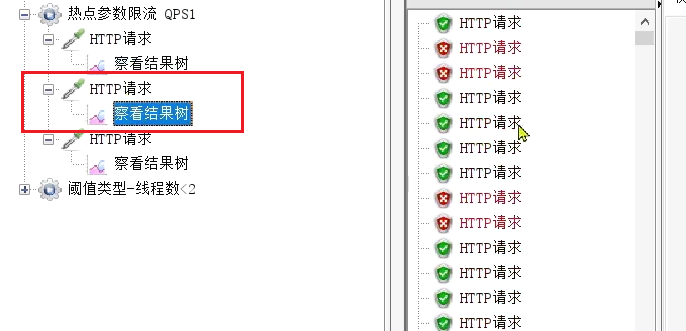
例外項,QPS閾值為4

執行結果:
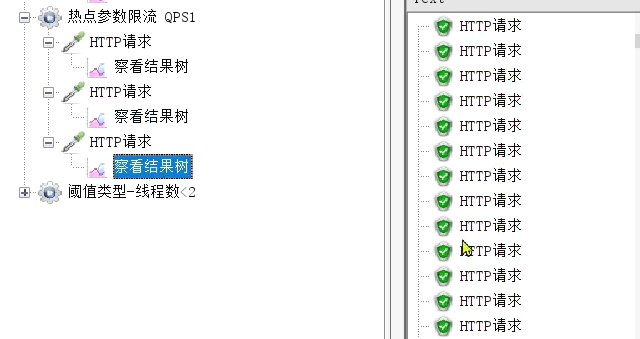
例外項,QPS閾值為10

執行結果:
艙壁模式:執行緒隔離
執行緒隔離建議設定監控介面裡的遠端呼叫,因為一旦發生熔斷和隔離是不允許外界存取該介面。監控遠端呼叫是因為遠端呼叫使用的feign-api模組對遠端呼叫介面方法寫了發生熔斷和隔離時返回空物件。如果監控外部介面,一旦發生隔離則直接報錯,阻止使用者存取介面並不會返回空物件(因為該介面方法沒寫發生熔斷和隔離時返回空物件)。
1. 執行緒隔離的兩種方式
執行緒隔離有兩種方式實現:
區別:
號誌——高扇出(高並行) 執行緒池——底扇出(請求量小)
特點:
號誌隔離——基於計數器模式,簡單,開銷小
執行緒池隔離是——基於執行緒池模式,有額外開銷,但隔離控制更強
-
執行緒池隔離
-
號誌隔離(Sentinel預設採用,選擇QPS)
如圖:
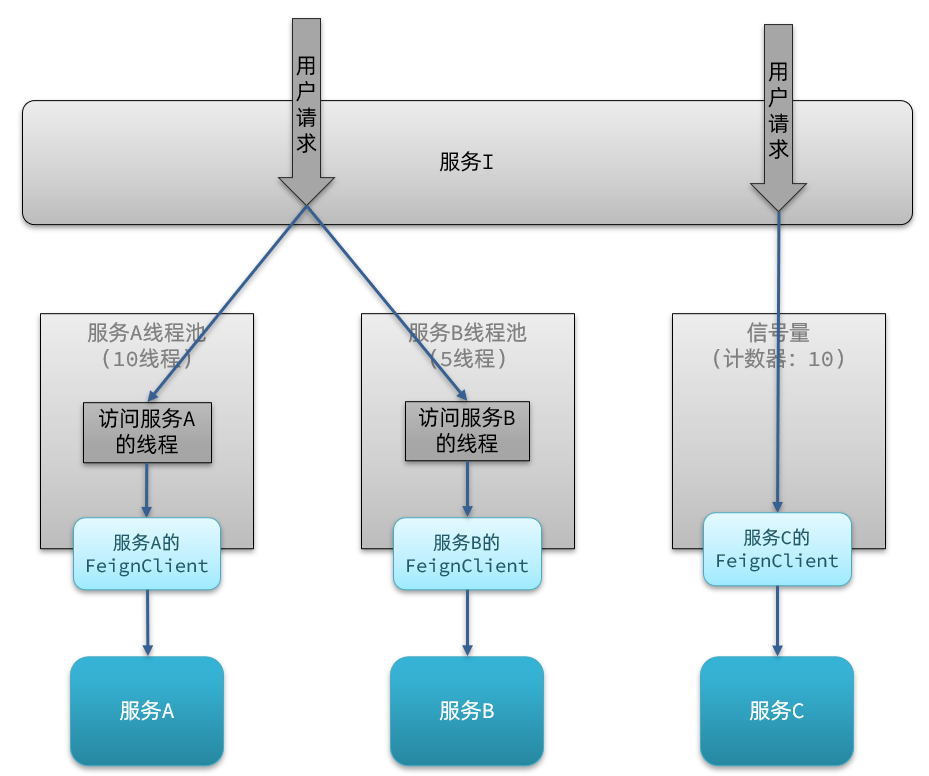
執行緒池隔離:給每個服務呼叫業務分配一個執行緒池,利用執行緒池本身實現隔離效果
號誌隔離:不建立執行緒池,而是計數器模式,記錄業務使用的執行緒數量,達到號誌上限時,禁止新的請求。
兩者的優缺點:

2. sentinel的執行緒隔離
用法說明:
在新增限流規則時,可以選擇兩種閾值型別:
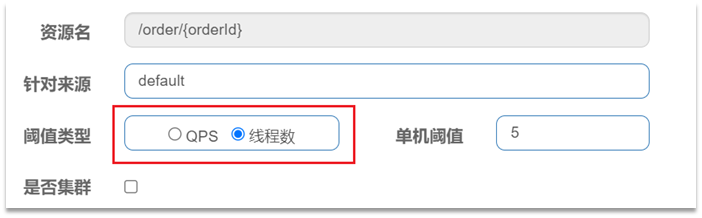
-
QPS:就是每秒的請求數,在快速入門中已經演示過
-
執行緒數:是該資源能使用用的tomcat執行緒數的最大值。也就是通過限制執行緒數量,實現執行緒隔離(艙壁模式)。
案例:
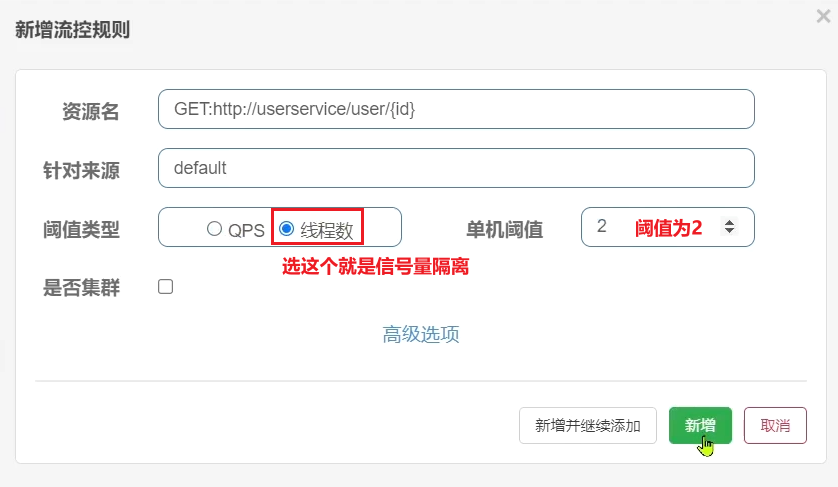
案例需求:給 order-service服務中的UserClient的查詢使用者介面設定流控規則,執行緒數不能超過 2。然後利用jemeter測試。
1)設定隔離規則
選擇feign介面後面的流控按鈕:

填寫表單:
2)Jmeter測試
選擇《閾值型別-執行緒數<2》:
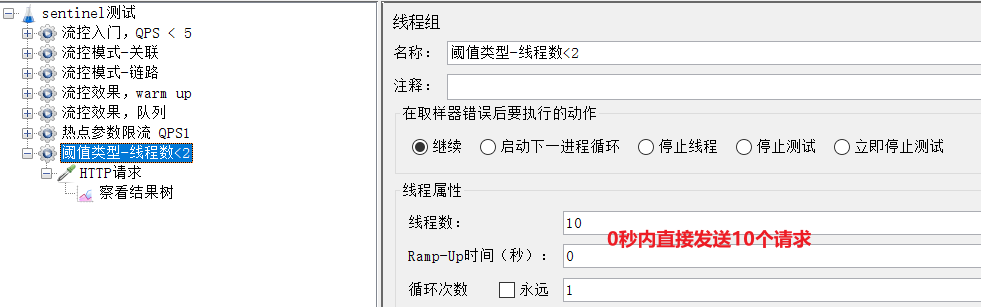
一次發生10個請求,有較大概率並行執行緒數超過2,而超出的請求會走之前定義的失敗降級邏輯。
檢視執行結果:
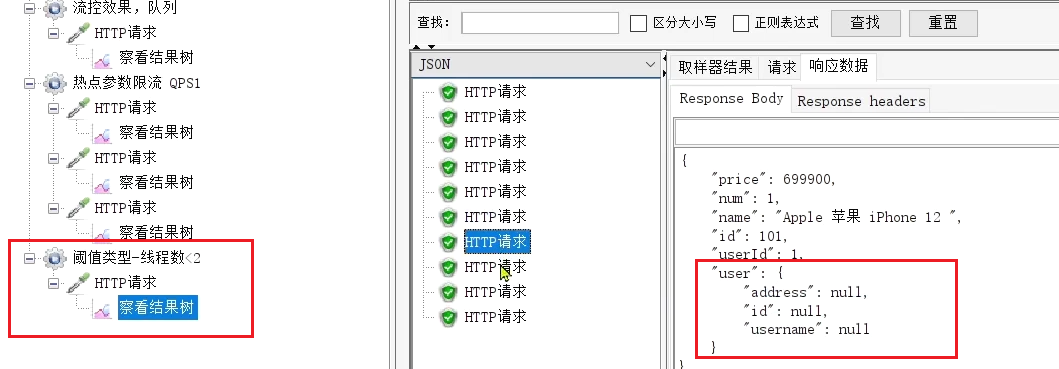
發現雖然結果都是通過了,不過部分請求得到的響應是降級返回的null資訊。
路斷器:熔斷降級
熔斷建議設定監控介面裡的遠端呼叫,因為一旦發生熔斷和隔離是不允許外界存取該介面。監控遠端呼叫是因為遠端呼叫使用的feign-api模組對遠端呼叫介面方法寫了發生熔斷和隔離時返回空物件。如果監控外部介面,一旦發生熔斷則直接報錯,阻止使用者存取介面並不會返回空物件(因為該介面方法沒寫發生熔斷和隔離時返回空物件)。
熔斷降級是解決雪崩問題的重要手段。其思路是由斷路器統計服務呼叫的異常比例、慢請求比例,如果超出閾值則會熔斷該服務。即攔截存取該服務的一切請求;而當服務恢復時,斷路器會放行存取該服務的請求。
斷路器控制熔斷和放行是通過狀態機來完成的:

狀態機包括三個狀態:
- closed:關閉狀態,斷路器放行所有請求,並開始統計異常比例、慢請求比例。超過閾值則切換到open狀態
- open:開啟狀態,服務呼叫被熔斷,存取被熔斷服務的請求會被拒絕,快速失敗,直接走降級邏輯。Open狀態5秒後會進入half-open狀態
- half-open:半開狀態,放行一次請求,根據執行結果來判斷接下來的操作。
- 請求成功:則切換到closed狀態
- 請求失敗:則切換到open狀態
斷路器熔斷策略有三種:慢呼叫、異常比例、異常數
1. 熔斷策略一:慢呼叫
慢呼叫:業務的響應時長(RT)大於指定時長的請求認定為慢呼叫請求。在指定時間內,如果請求數量超過設定的最小數量,慢呼叫比例大於設定的閾值,則觸發熔斷。
例如:

解讀:RT超過500ms的呼叫是慢呼叫,統計最近10000ms內的請求,如果請求量超過10次,並且慢呼叫比例不低於0.5,則觸發熔斷,熔斷時長為5秒。然後進入half-open狀態,放行一次請求做測試。
案例:
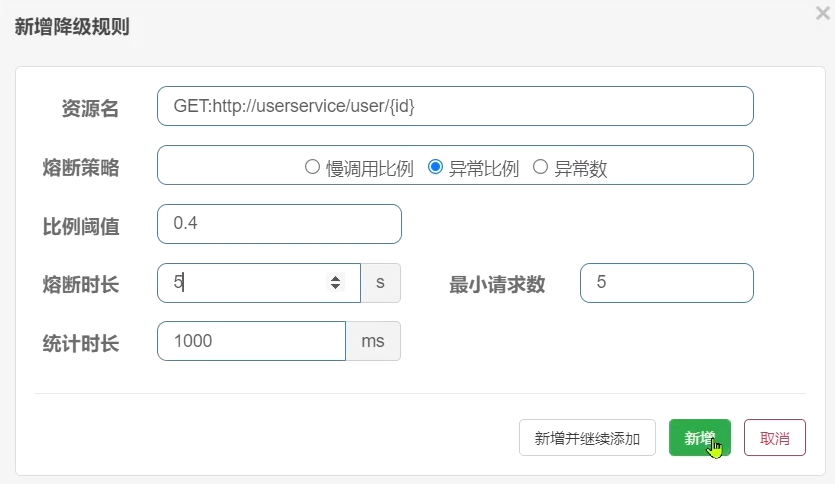
需求:給 UserClient的查詢使用者介面設定降級規則,慢呼叫的RT閾值為50ms,統計時間為1秒,最小請求數量為5,失敗閾值比例為0.4,熔斷時長為5
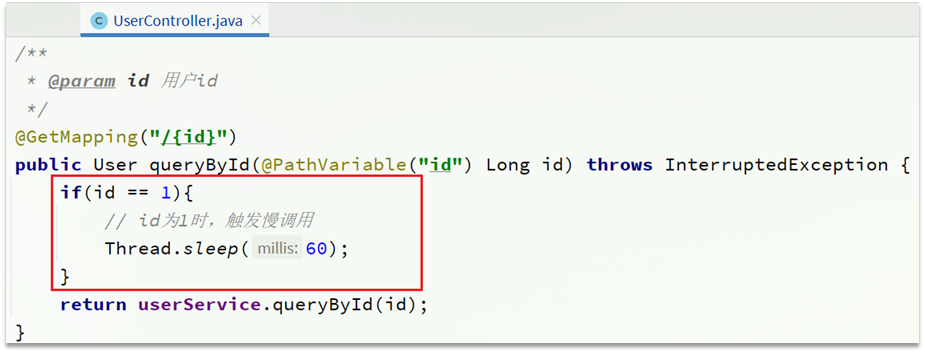
1)設定慢呼叫
修改user-service中的/user/{id}這個介面的業務。通過休眠模擬一個延遲時間:
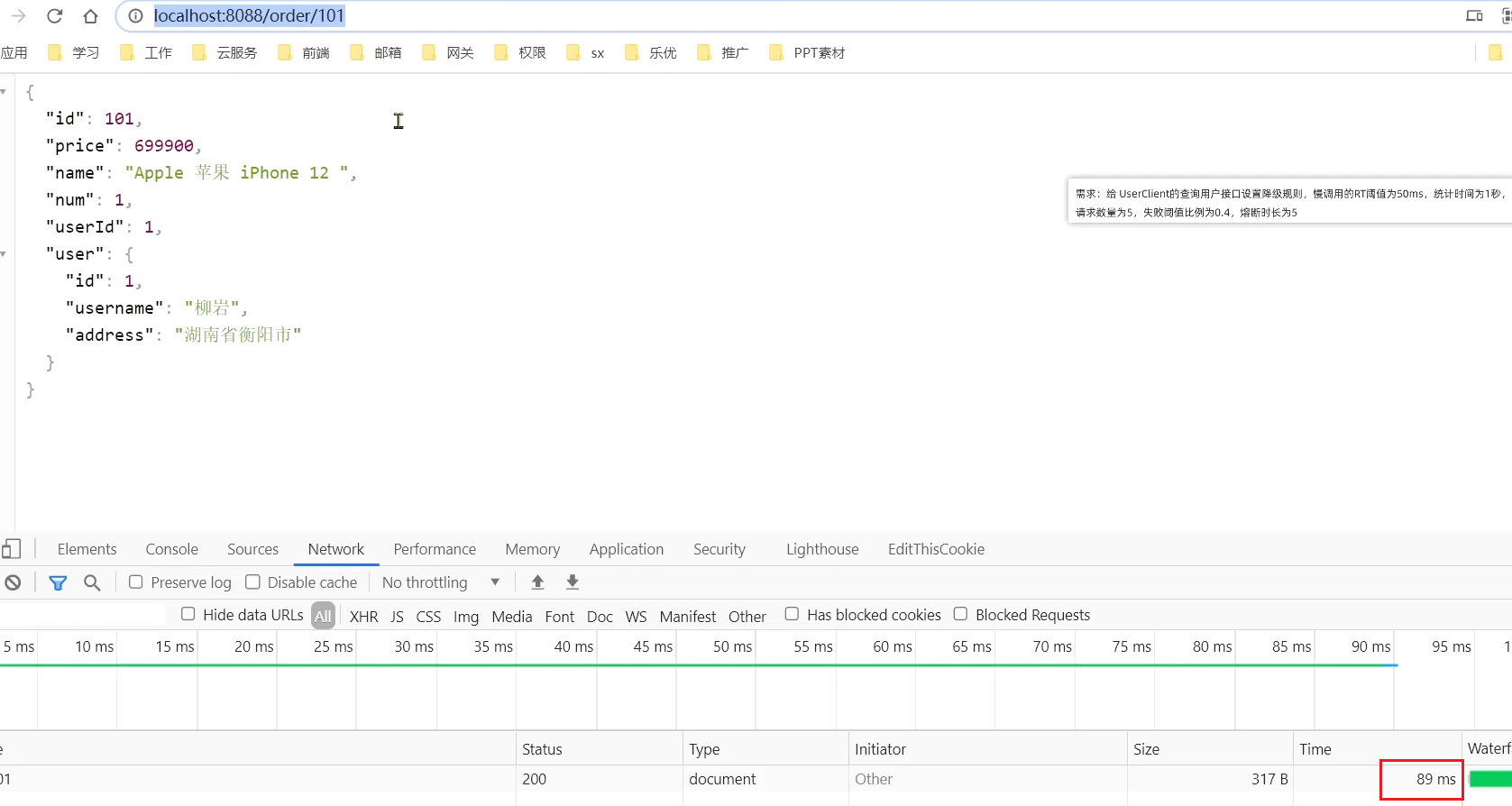
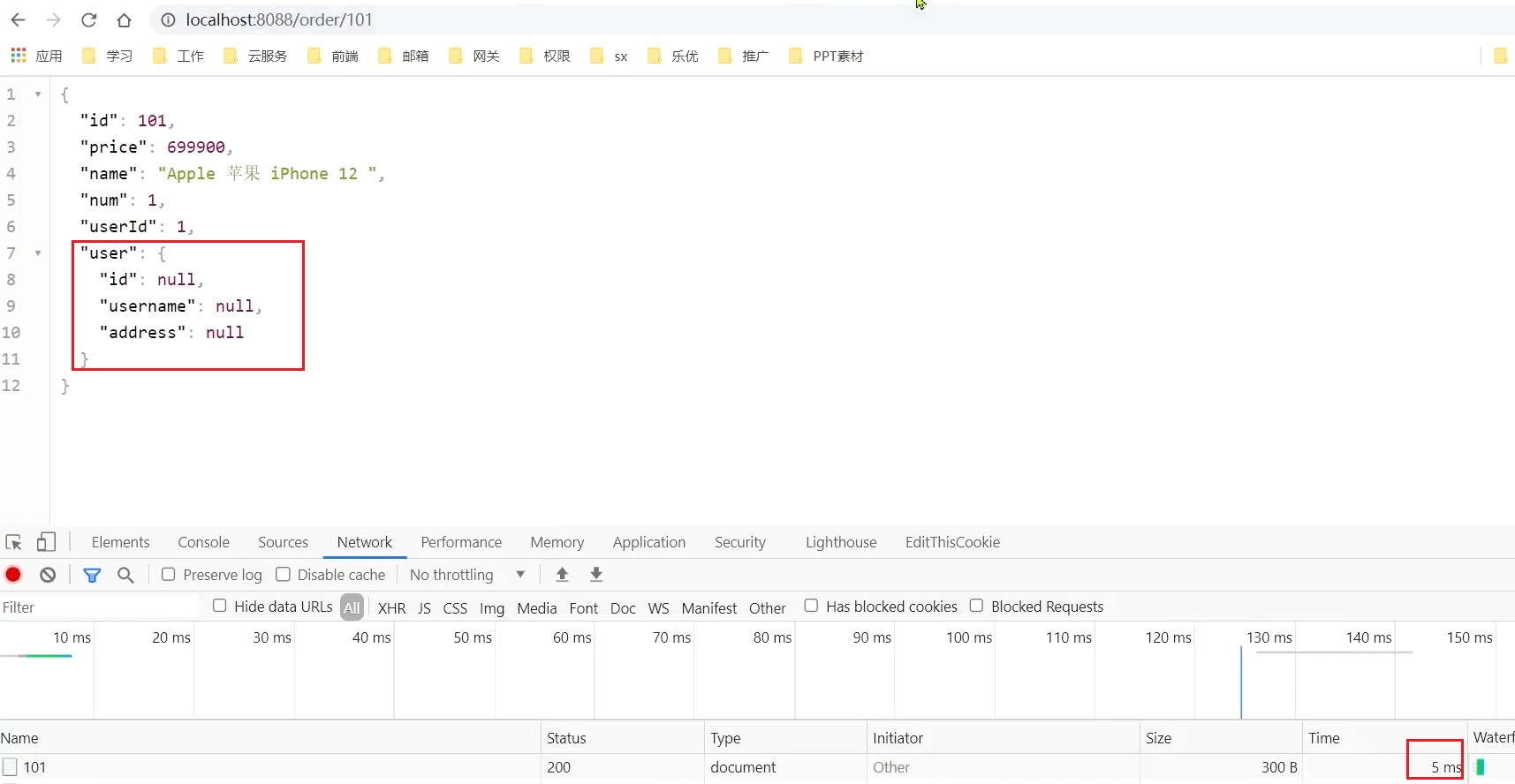
此時,orderId=101的訂單,關聯的是id為1的使用者,呼叫時長為60ms:
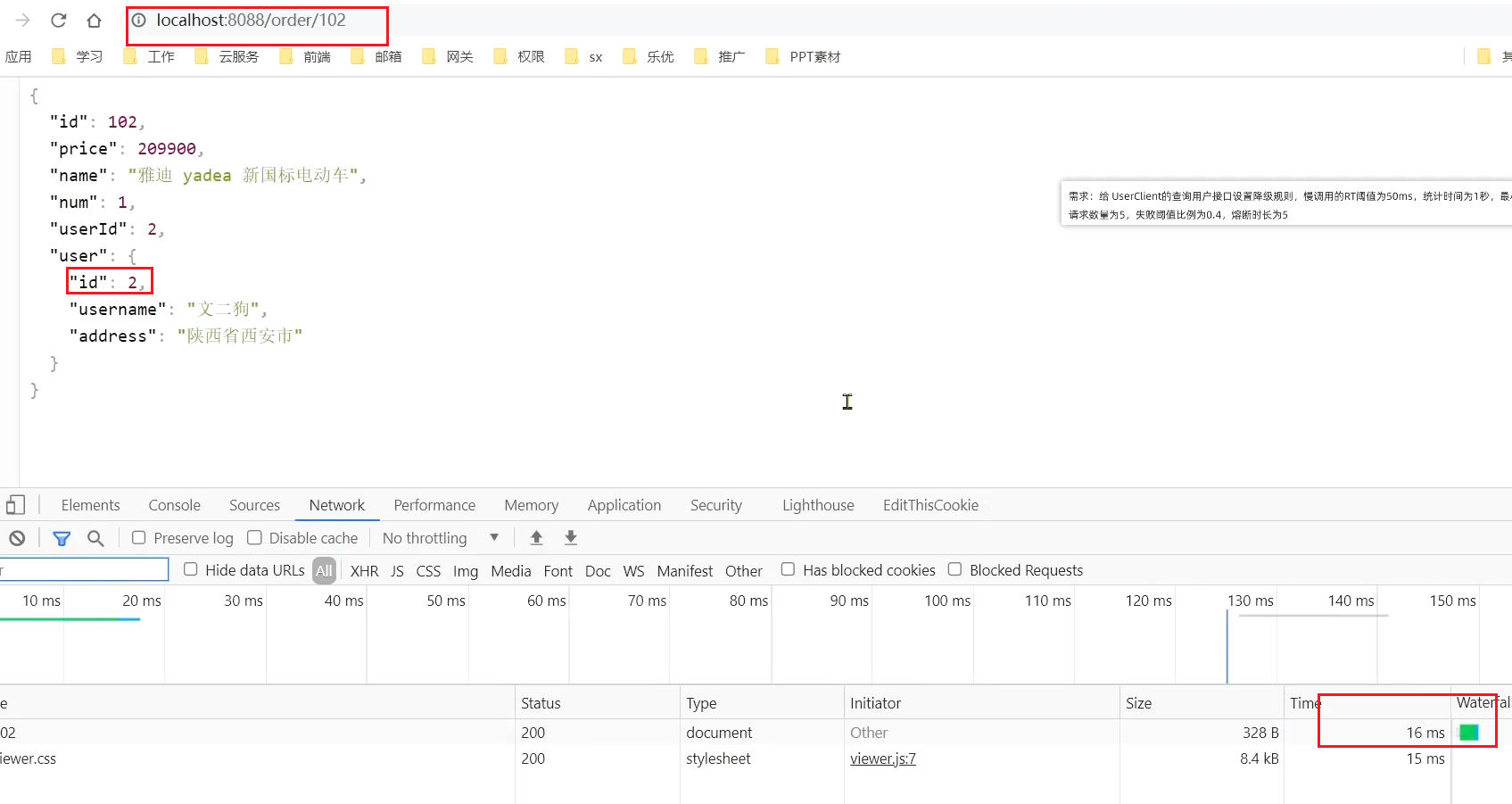
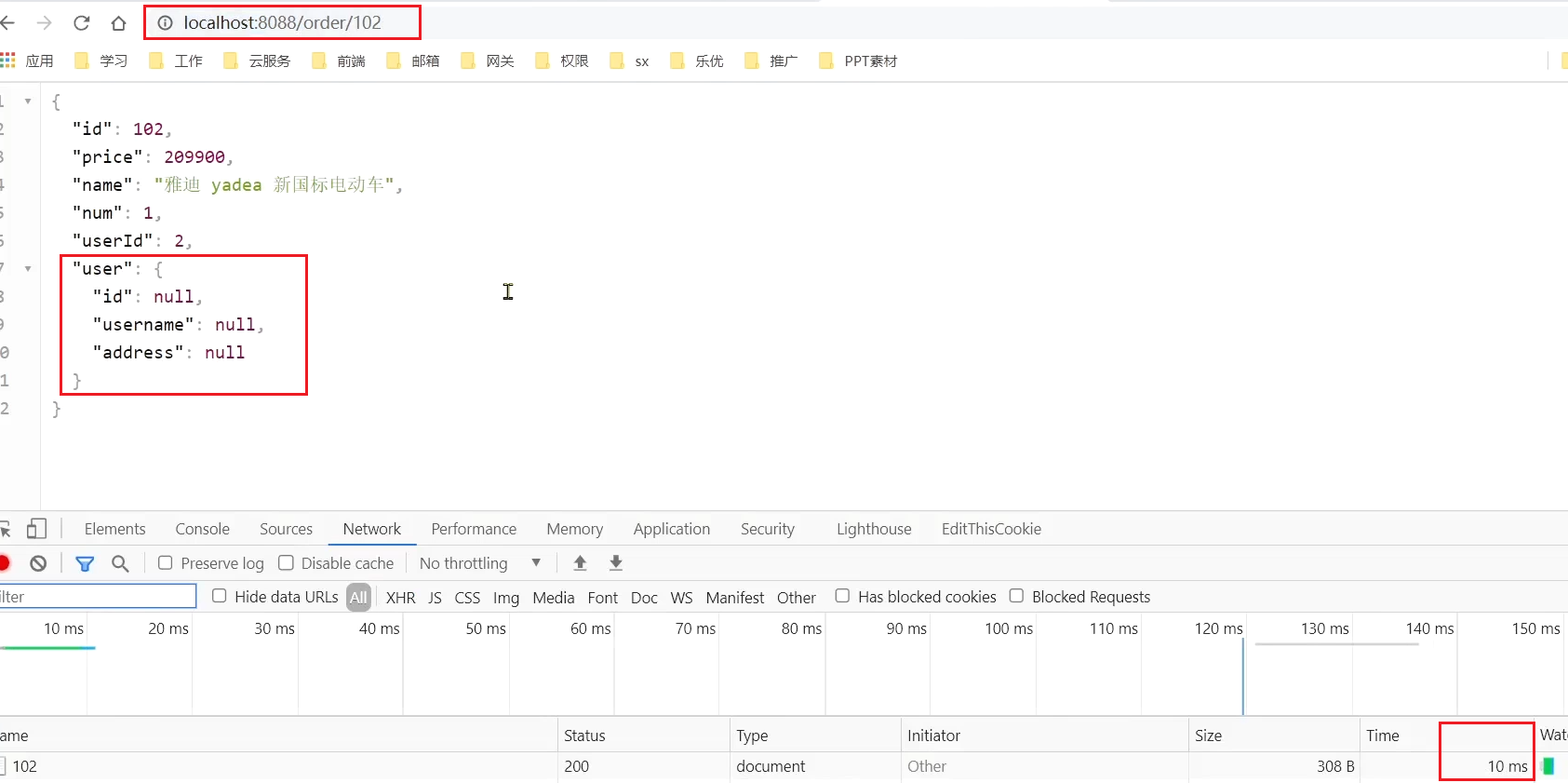
orderId=102的訂單,關聯的是id為2的使用者,呼叫時長為非常短;
2)設定熔斷規則
下面,給feign介面設定降級規則:

規則:
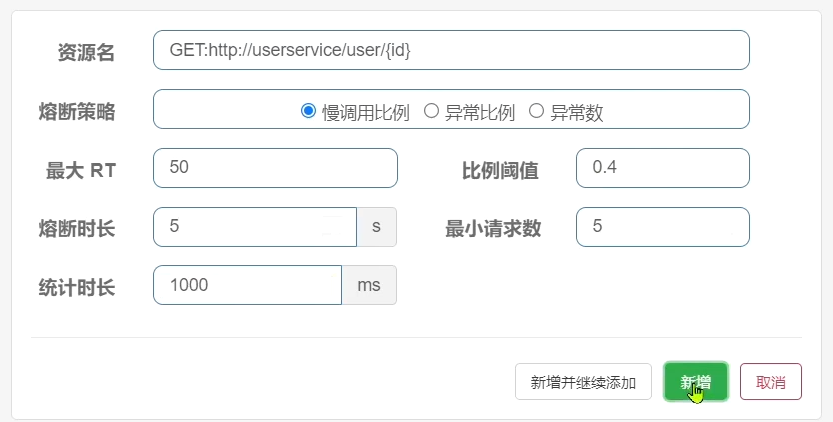
超過50ms的請求都會被認為是慢請求
3)測試
在瀏覽器存取:http://localhost:8088/order/101,快速重新整理5次後,可以發現:觸發了熔斷,請求時長縮短至5ms,快速失敗了,並且走降級邏輯,返回的null
這裡呼叫order/101是因為,這個介面裡面會呼叫user/101。所以還是會觸發前面設定的熔斷規則
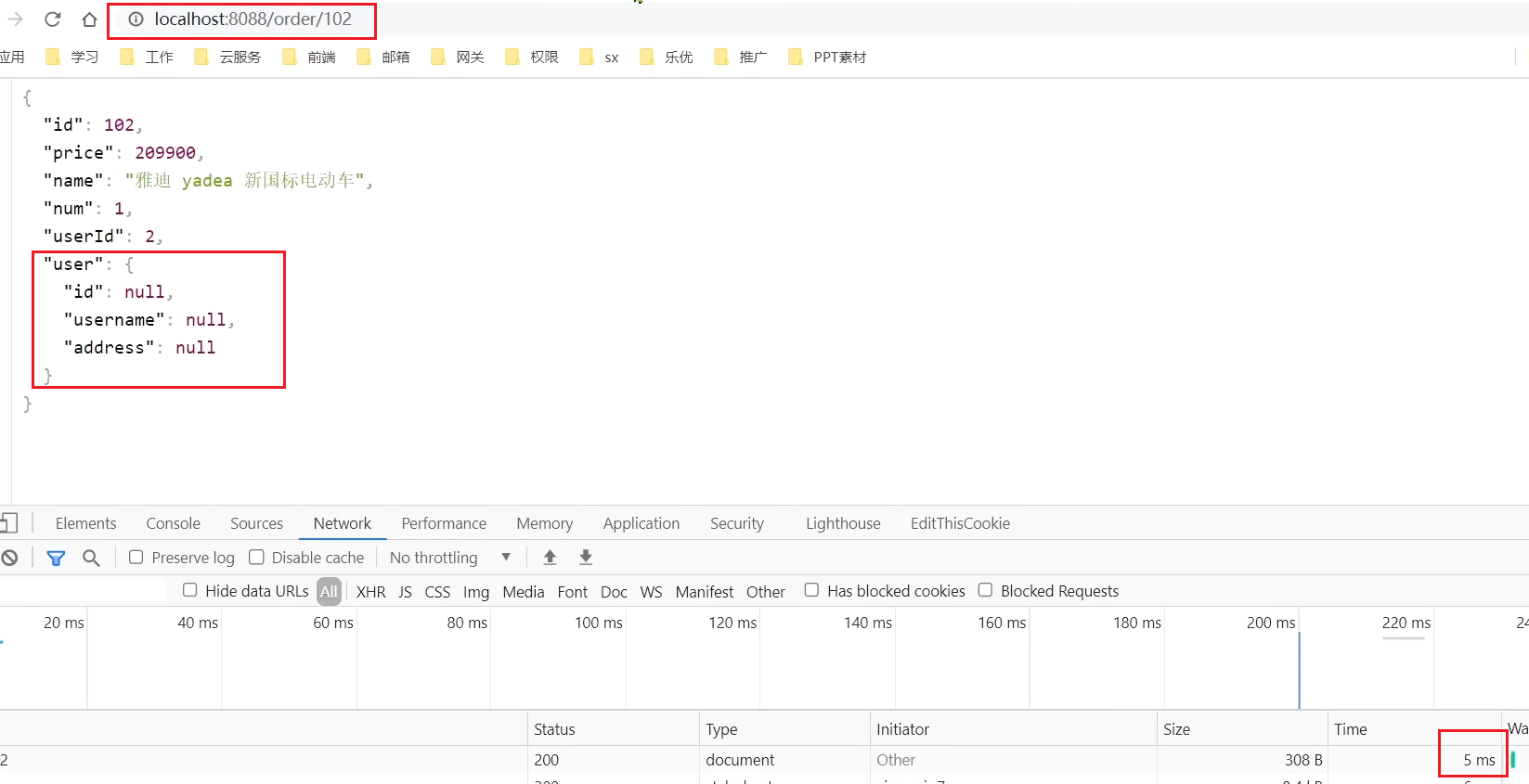
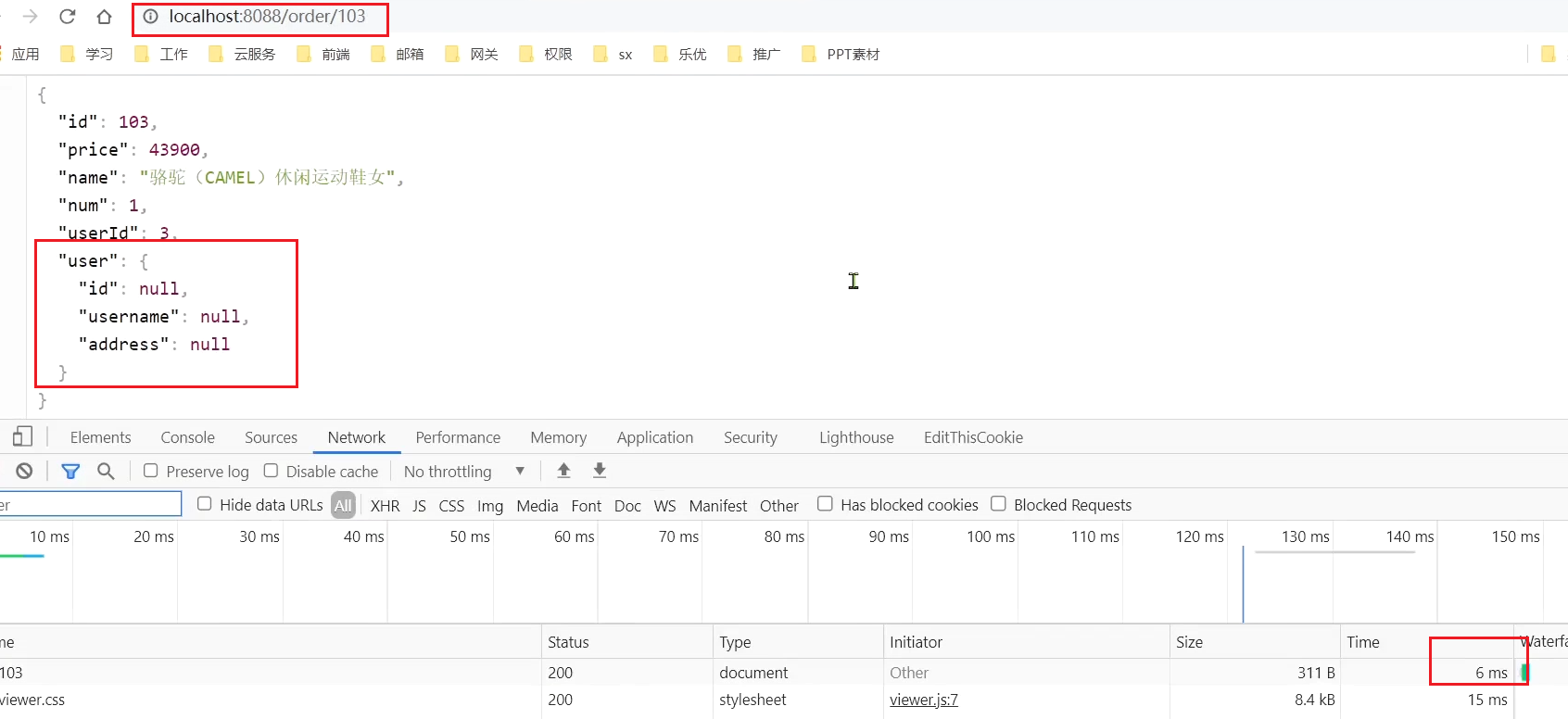
在瀏覽器存取:http://localhost:8088/order/102,竟然也被熔斷了:
2. 熔斷策略二和三:異常比例、異常數
異常比例或異常數:統計指定時間內的呼叫,如果呼叫次數超過指定請求數,並且出現異常的比例達到設定的比例閾值(或超過指定異常數),則觸發熔斷。
例如,一個異常比例設定:
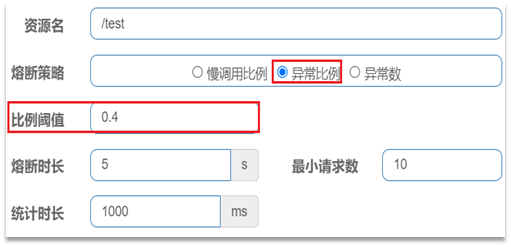
解讀:統計最近1000ms內的請求,如果請求量超過10次,並且異常比例不低於0.4,則觸發熔斷。
一個異常數設定:

解讀:統計最近1000ms內的請求,如果請求量超過10次,並且異常比例不低於2次,則觸發熔斷。
案例
需求:給 UserClient的查詢使用者介面設定降級規則,統計時間為1秒,最小請求數量為5,失敗閾值比例為0.4,熔斷時長為5s
1)設定異常請求
首先,修改user-service中的/user/{id}這個介面的業務。手動丟擲異常,以觸發異常比例的熔斷:也就是說,id 為 2時,就會觸發異常

2)設定熔斷規則
下面,給feign介面設定降級規則:

規則:在5次請求中,只要異常比例超過0.4,也就是有2次以上的異常,就會觸發熔斷。
3)測試
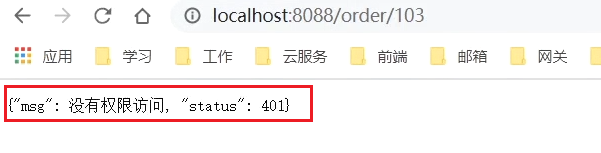
在瀏覽器快速存取:http://localhost:8088/order/102,快速重新整理5次,觸發熔斷:
此時,我們去存取本來應該正常的103:
授權
授權規則可以對請求方來源做判斷和控制。(通過判斷請求方的請求頭是否攜帶指定的引數來判斷)
1. sentinel授權介紹
授權規則可以對呼叫方的來源做控制,有白名單和黑名單兩種方式。
-
白名單:來源(origin)在白名單內的呼叫者允許存取
-
黑名單:來源(origin)在黑名單內的呼叫者不允許存取
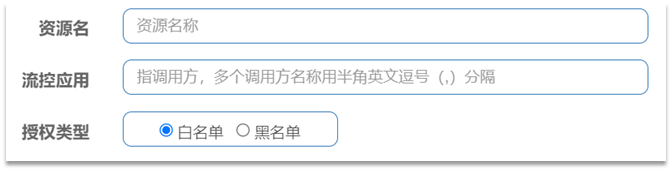
點選左側選單的授權,可以看到授權規則:
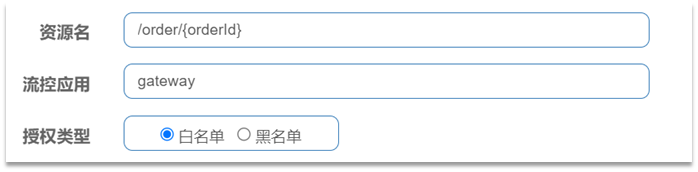
-
資源名:就是受保護的資源,例如/order/
-
流控應用:是來源者的名單,
- 如果是勾選白名單,則名單中的來源被許可存取。
- 如果是勾選黑名單,則名單中的來源被禁止存取。
比如:
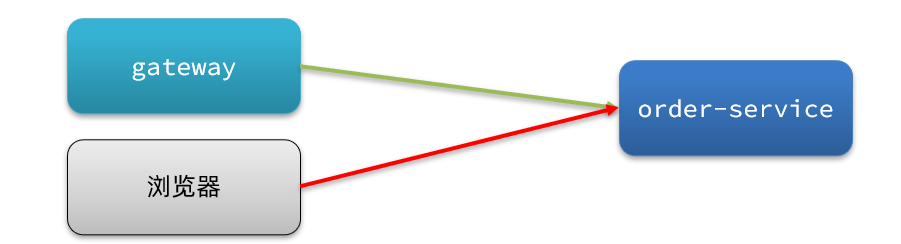
我們允許請求從gateway到order-service,不允許瀏覽器存取order-service,那麼白名單中就要填寫閘道器的來源名稱(origin)。
如何得到origin呢?
Sentinel是通過RequestOriginParser這個介面的parseOrigin來獲取請求的來源的。
public interface RequestOriginParser {
/**
* 從請求request物件中獲取origin,獲取方式自定義
*/
String parseOrigin(HttpServletRequest request);
}
這個方法的作用就是從request物件中,獲取請求者的origin值並返回。
預設情況下,sentinel不管請求者從哪裡來,返回值永遠是default,也就是說一切請求的來源都被認為是一樣的值default。
因此,我們需要自定義這個介面的實現,讓不同的請求,返回不同的origin。
2. sentinel設定授權
2.1 給閘道器新增請求頭
既然獲取請求origin的方式是從reques-header中獲取origin值,我們必須讓所有從gateway路由到微服務的請求都帶上origin頭。
這個需要利用之前學習的一個GatewayFilter來實現,AddRequestHeaderGatewayFilter。
修改gateway服務中的application.yml,新增一個defaultFilter:
spring:
cloud:
gateway:
default-filters:
- AddRequestHeader=origin,gateway #逗號前是key,後面是value
routes:
# ...略
這樣,從gateway路由的所有請求都會帶上origin頭,值為gateway。而從其它地方到達微服務的請求則沒有這個頭。
2.2 獲取請求的origin
例如order-service服務中,我們定義一個RequestOriginParser的實現類:我們會嘗試從request-header中獲取origin值。
package cn.itcast.order.sentinel;
import com.alibaba.csp.sentinel.adapter.spring.webmvc.callback.RequestOriginParser;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import javax.servlet.http.HttpServletRequest;
@Component
public class HeaderOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest request) {
// 1.獲取請求頭
String origin = request.getHeader("origin");
// 2.非空判斷
if (StringUtils.isEmpty(origin)) {
origin = "blank";
}
return origin;
}
}
2.3 sentinel操作
我們新增一個授權規則,放行origin值為gateway的請求。

設定如下:
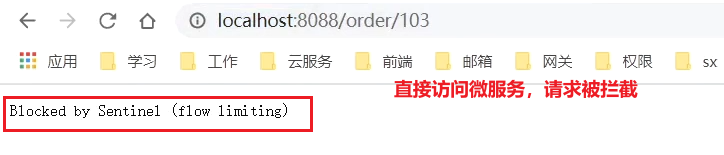
現在,我們直接跳過閘道器,存取order-service服務:
通過閘道器存取:

自定義異常結果
預設情況下,發生限流、降級、授權攔截時,都會丟擲異常到呼叫方。異常結果都是flow limmiting(限流)。這樣不夠友好,無法得知是限流還是降級還是授權攔截。
1.異常型別
而如果要自定義異常時的返回結果,需要實現BlockExceptionHandler介面:
public interface BlockExceptionHandler {
/**
* 處理請求被限流、降級、授權攔截時丟擲的異常:BlockException
*/
void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception;
}
這個方法有三個引數:
- HttpServletRequest request:request物件
- HttpServletResponse response:response物件
- BlockException e:被sentinel攔截時丟擲的異常
這裡的BlockException包含多個不同的子類:
| 異常 | 說明 |
|---|---|
| FlowException | 限流異常 |
| ParamFlowException | 熱點引數限流的異常 |
| DegradeException | 降級異常 |
| AuthorityException | 授權規則異常 |
| SystemBlockException | 系統規則異常 |
2.自定義例外處理
下面,我們就在order-service定義一個自定義例外處理類:
package cn.itcast.order.sentinel;
import com.alibaba.csp.sentinel.adapter.spring.webmvc.callback.BlockExceptionHandler;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.alibaba.csp.sentinel.slots.block.authority.AuthorityException;
import com.alibaba.csp.sentinel.slots.block.degrade.DegradeException;
import com.alibaba.csp.sentinel.slots.block.flow.FlowException;
import com.alibaba.csp.sentinel.slots.block.flow.param.ParamFlowException;
import org.springframework.stereotype.Component;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
@Component
public class SentinelExceptionHandler implements BlockExceptionHandler {
@Override
public void handle(HttpServletRequest request, HttpServletResponse response, BlockException e) throws Exception {
String msg = "未知異常";
int status = 429;
if (e instanceof FlowException) {
msg = "請求被限流了";
} else if (e instanceof ParamFlowException) {
msg = "請求被熱點引數限流";
} else if (e instanceof DegradeException) {
msg = "請求被降級了";
} else if (e instanceof AuthorityException) {
msg = "沒有許可權存取";
status = 401;
}
response.setContentType("application/json;charset=utf-8");
response.setStatus(status);
response.getWriter().println("{\"msg\": " + msg + ", \"status\": " + status + "}");
}
}
重啟測試,在不同場景下,會返回不同的異常訊息.
限流:
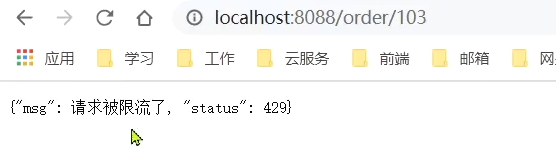
授權攔截時:
sentinel規則持久化
sentinel的所有規則都是記憶體儲存,重啟後所有規則都會丟失。在生產環境下,我們必須確保這些規則的持久化,避免丟失。
1.規則管理模式
規則是否能持久化,取決於規則管理模式,sentinel支援三種規則管理模式:
- 原始模式:Sentinel的預設模式,將規則儲存在記憶體,重啟服務會丟失。
- pull模式(儲存各伺服器本地,一定時間內會輪詢檢查規則並更新)
- push模式(儲存在nacos註冊中心)【推薦】
2. pull模式
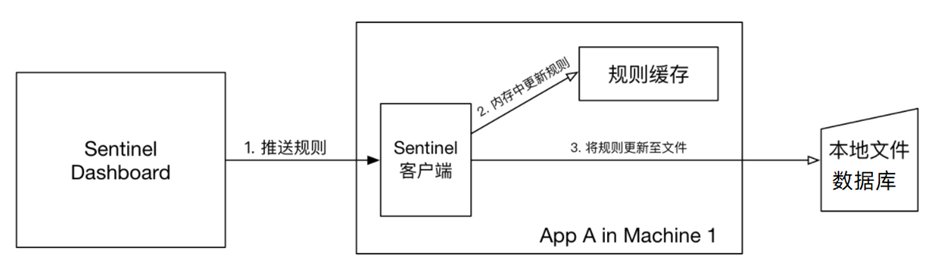
pull模式:控制檯將設定的規則推播到Sentinel使用者端,而使用者端會將設定規則儲存在本地檔案或資料庫中。以後會定時去本地檔案或資料庫中查詢,更新本地規則。
3. push模式
push模式:控制檯將設定規則推播到遠端設定中心,例如Nacos。Sentinel使用者端監聽Nacos,獲取設定變更的推播訊息,完成本地設定更新。

4. 實現push模式
4.1 引入依賴
在order-service中引入sentinel監聽nacos的依賴:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
4.2 設定nacos地址
在order-service中的application.yml檔案設定nacos地址及監聽的設定資訊:
spring:
cloud:
sentinel:
datasource:
flow:
nacos:
server-addr: localhost:8848 # nacos地址
dataId: orderservice-flow-rules #該組態檔的名稱
groupId: SENTINEL_GROUP #該組態檔所在組的名稱
rule-type: flow # 還可以是:degrade、authority、param-flow
flow:
nacos:
server-addr: localhost:8848 # nacos地址
dataId: orderservice-degrade-rules #該組態檔的名稱
groupId: SENTINEL_GROUP #該組態檔所在組的名稱
rule-type: degrade # 還可以是:degrade、authority、param-flow
#... 可以多個flow根據需求設定
4.3 修改sentinel原始碼
一般不這樣修改太麻煩了,直接去網上找別人改好的
SentinelDashboard預設不支援nacos的持久化,需要修改原始碼。
4.3.1 解壓
解壓課前資料中的sentinel原始碼包:

然後並用IDEA開啟這個專案,結構如下:

4.3.2 修改nacos依賴
在sentinel-dashboard原始碼的pom檔案中,nacos的依賴預設的scope是test,只能在測試時使用,這裡要去除:

將sentinel-datasource-nacos依賴的scope去掉:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
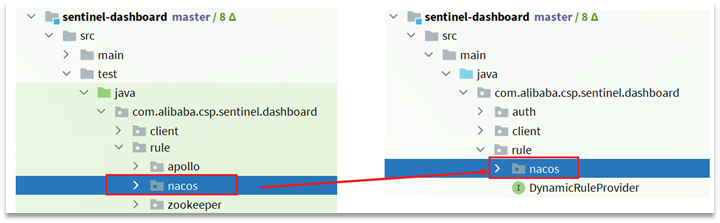
4.3.3 新增nacos支援
在sentinel-dashboard的test包下,已經編寫了對nacos的支援,我們需要將其拷貝到main下。
4.3.4 修改nacos地址
然後,還需要修改測試程式碼中的NacosConfig類:

修改其中的nacos地址,讓其讀取application.properties中的設定:
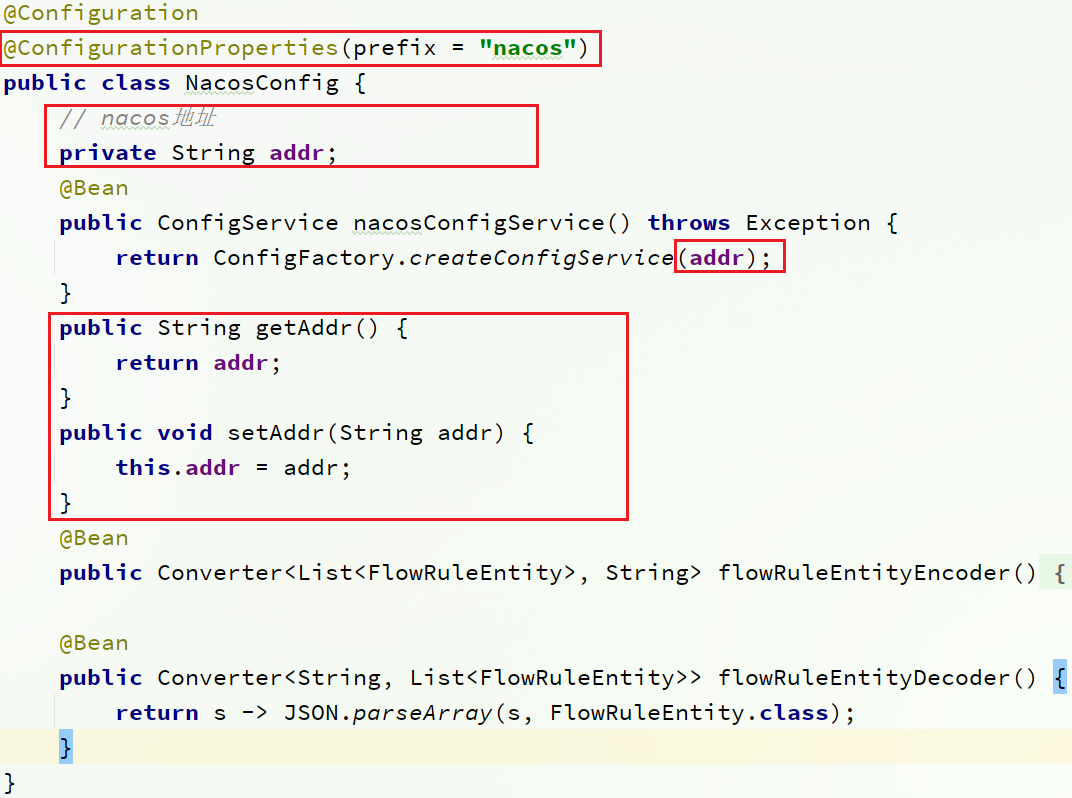
在sentinel-dashboard的application.properties中新增nacos地址設定:
nacos.addr=localhost:8848
4.3.5 設定nacos資料來源
另外,還需要修改com.alibaba.csp.sentinel.dashboard.controller.v2包下的FlowControllerV2類:

讓我們新增的Nacos資料來源生效:

4.3.6 修改前端頁面
接下來,還要修改前端頁面,新增一個支援nacos的選單。
修改src/main/webapp/resources/app/scripts/directives/sidebar/目錄下的sidebar.html檔案:
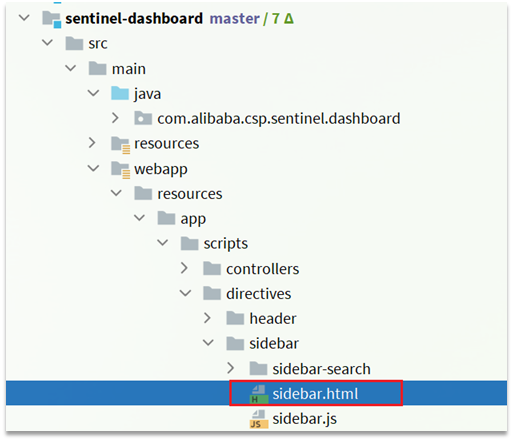
將其中的這部分註釋開啟:

修改其中的文字:

4.3.7 重新編譯、打包專案
執行IDEA中的maven外掛,編譯和打包修改好的Sentinel-Dashboard:
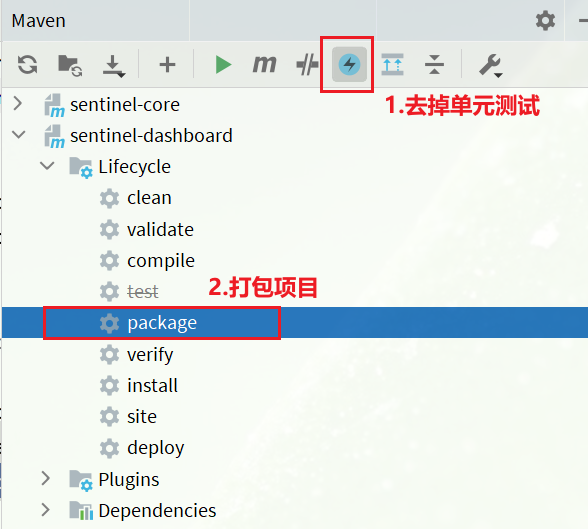
4.3.8 啟動
啟動方式跟官方一樣:
java -jar sentinel-dashboard.jar
如果要修改nacos地址,需要新增引數:
java -jar -Dnacos.addr=localhost:8848 sentinel-dashboard.jar
本文來自部落格園,作者:不吃紫菜,遵循CC 4.0 BY-SA版權協定,轉載請附上原文出處連結:https://www.cnblogs.com/buchizicai/p/17093746.html及本宣告。
本文版權歸作者所有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。