多變數兩兩相互關係聯合分佈圖的Python繪製
本文介紹基於Python中seaborn模組,實現聯合分佈圖繪製的方法。
聯合分佈(Joint Distribution)圖是一種檢視兩個或兩個以上變數之間兩兩相互關係的視覺化圖,在資料分析操作中經常需要用到。一幅好看的聯合分佈圖可以使得我們的資料分析更加具有可視性,讓大家眼前一亮。
那麼,本文就將用seaborn來實現聯合分佈圖的繪製。seaborn是一個基於matplotlib的Python資料視覺化模組,藉助於其,我們可以通過較為簡單的操作,繪製出各類動人的圖片。
首先,引入需要的模組。
import pandas as pd
import seaborn as sns
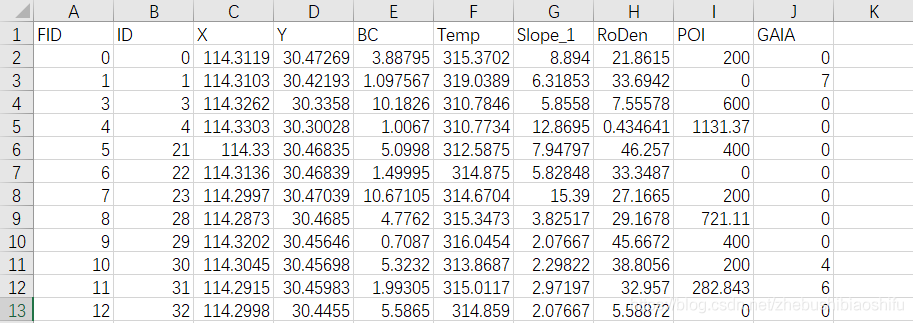
接下來,將儲存有我們需要繪製聯合分佈圖資料的檔案匯入。因為我是將資料儲存於.csv檔案,所以我這裡用pd.read_csv來實現資料的匯入。我的資料在.csv檔案中長如下圖的樣子,其中共有107行,包括106行樣本加1行列標題;以及10列。我們就看前幾行即可:
匯入資料的程式碼如下:
data_path="G:/black_carbon_paper/97_BC20201230/00_Original/AllData5Factor.csv"
column_names=['FID','ID','X','Y','BC','Temp','Slope','RoDen','POI','GAIA']
my_data=pd.read_csv(data_path,names=column_names,header=0)
其中,data_path是.csv檔案儲存位置與檔名,column_names是匯入的資料在Python中我希望其顯示的名字(為什麼原始資料本來就有列標題但還要再設定這個column_names,本文下方有介紹);header=0表示.csv檔案中的0行(也就是我們一般而言的第一行)是列標題;如果大家的初始資料沒有列標題,即其中的第一行就是資料自身,那麼就需要設定header=None。
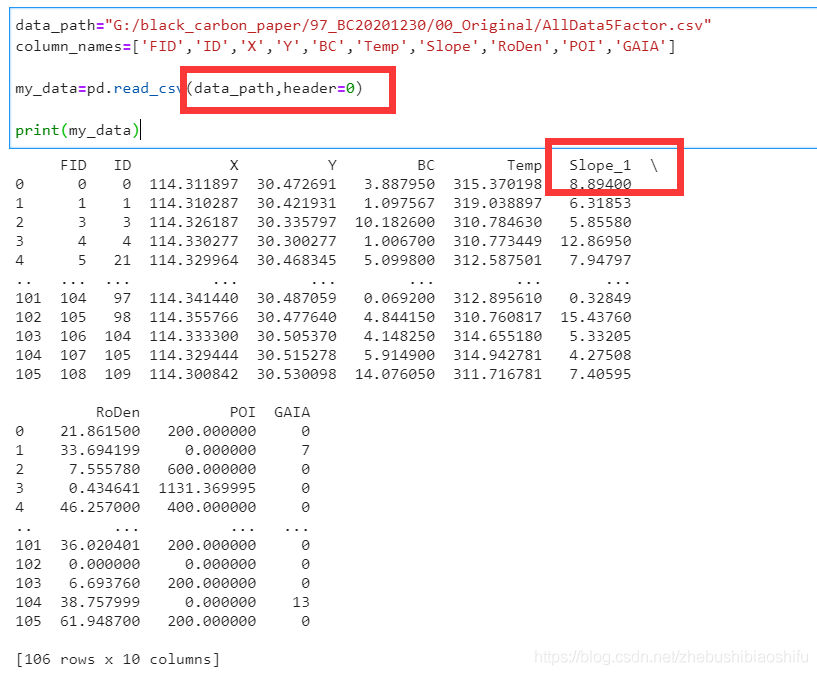
執行上述程式碼,我們將匯入的資料列印,看看在Python中其長什麼樣子。
print(my_data)
![]()
可以看到,匯入Python後資料的第7列,原本叫做Slope_1,但是設定我們自己命名的column_names後,其就將原本資料的列標題改為我們自己設定的標題Slope了。如果我們不設定column_names,匯入的資料就是這個樣子:
可以看到,我們不用column_names的話,資料匯入Python後列名就是原始的Slope_1。
我們繼續。其實用seaborn繪製聯合分佈圖非常簡單(這就是seaborn對matplotlib改進,讓我們繪製複雜的圖時候不需要太麻煩),僅僅只有一下兩句程式碼:
joint_columns=['BC','Temp','Slope','RoDen','POI','GAIA']
sns.pairplot(my_data[joint_columns],kind='reg',diag_kind='kde')
其中,第一句是定義我們想要參與繪製聯合分佈圖的列,將需要繪圖的列標題放入joint_column。可以看到,因為我的資料中,具有ID這種編號列,而肯定編號是不需要參與繪圖的,那麼我們就不將其放入joint_column即可。
第二句就是繪圖。kind表示聯合分佈圖中非對角線圖的型別,可選'reg'與'scatter'、'kde'、'hist','reg'代表在圖片中加入一條擬合直線,'scatter'就是不加入這條直線,'kde'是等高線的形式,'hist'就是類似於柵格地圖的形式;diag_kind表示聯合分佈圖中對角線圖的型別,可選'hist'與'kde','hist'代表直方圖,'kde'代表直方圖曲線化。
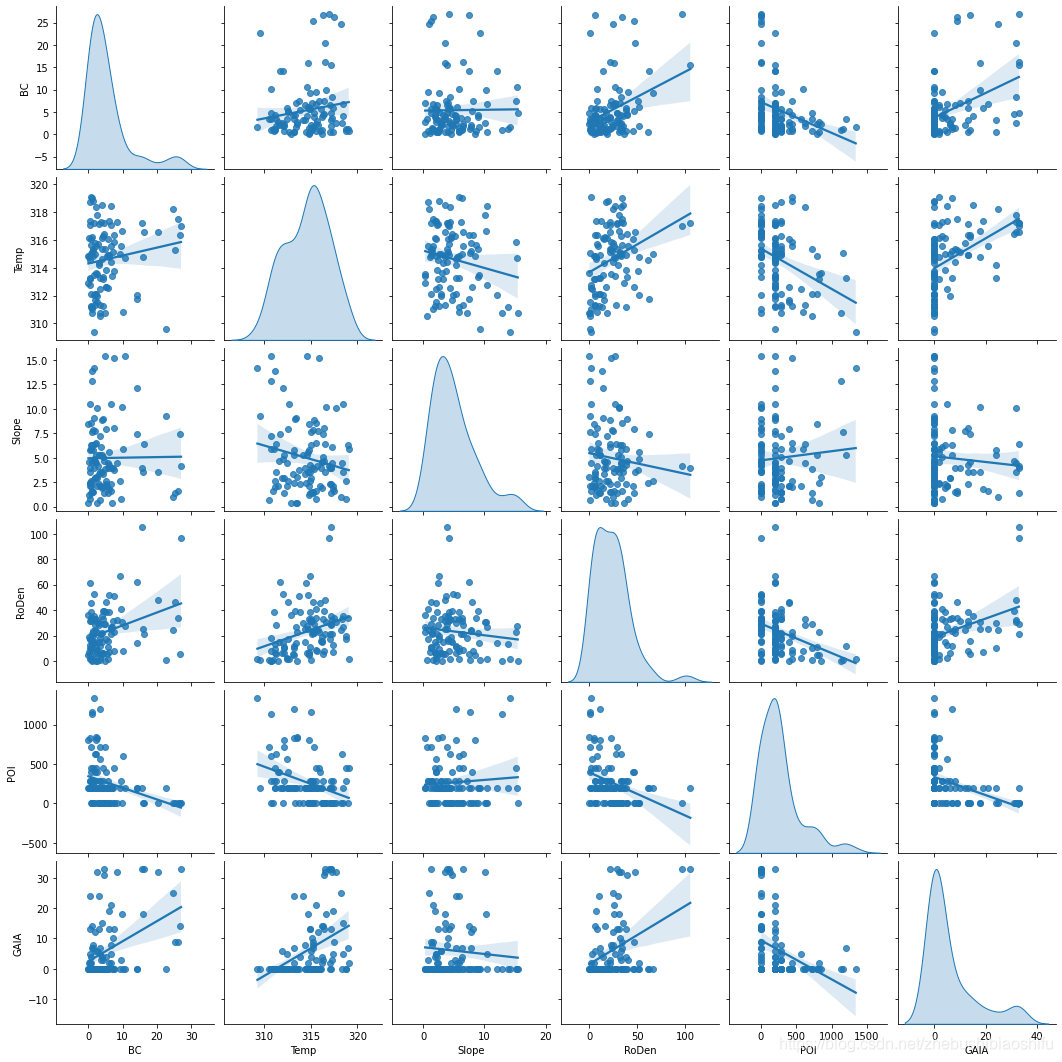
以kind和diag_kind分別選擇'reg'和'kde'為例,繪圖結果如下:
以kind和diag_kind分別選擇'scatter'和'hist'為例,繪圖結果如下:
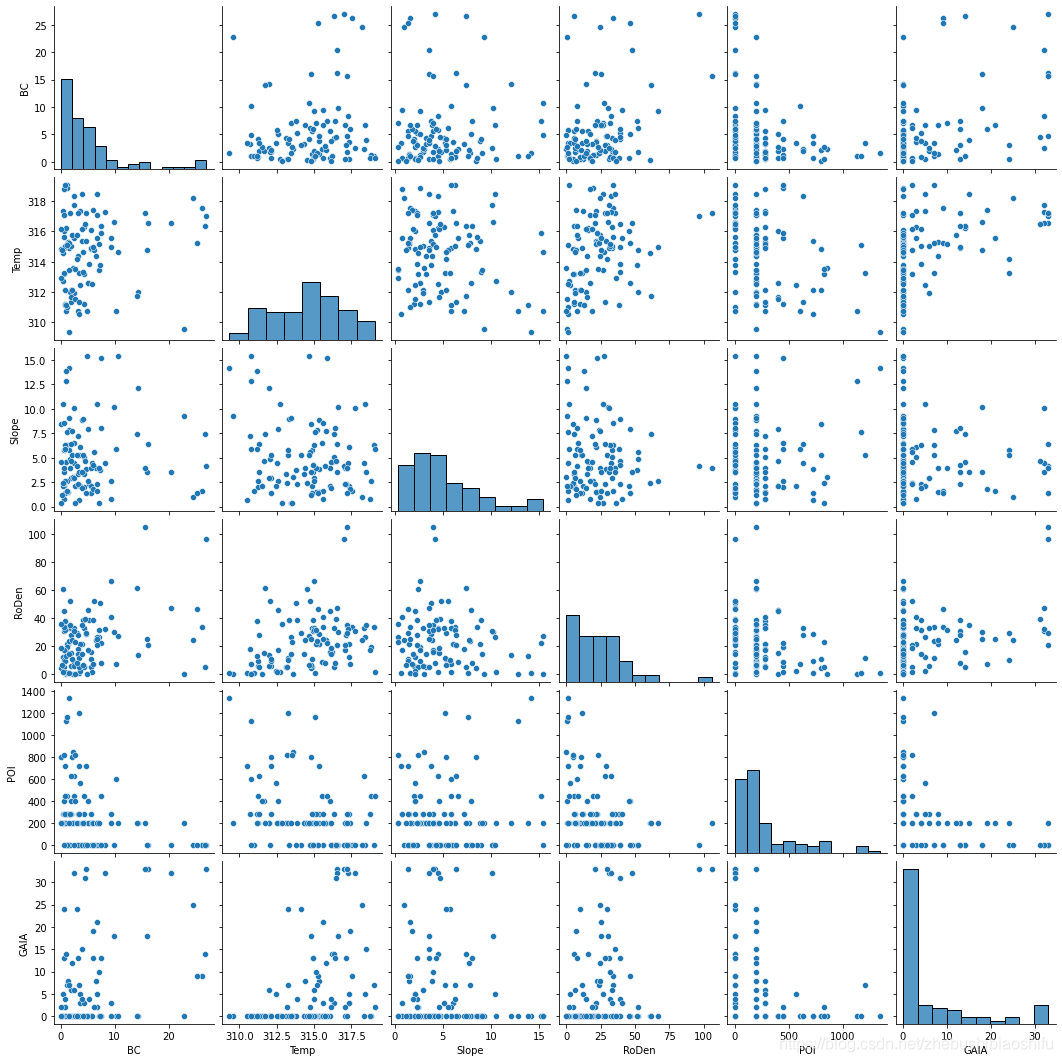
個人感覺第一幅圖好看些~
不過,由於參與繪圖的變數個數比較多,因此使得圖中的字型有點看不清。可以加上一句程式碼在sns.pairplot這句程式碼的上面:
sns.set(font_scale=1.2)
其中,font_scale就是字型的大小,後面的數位越大,字型就越大。以font_scale=1.2為例,讓我們看看效果:
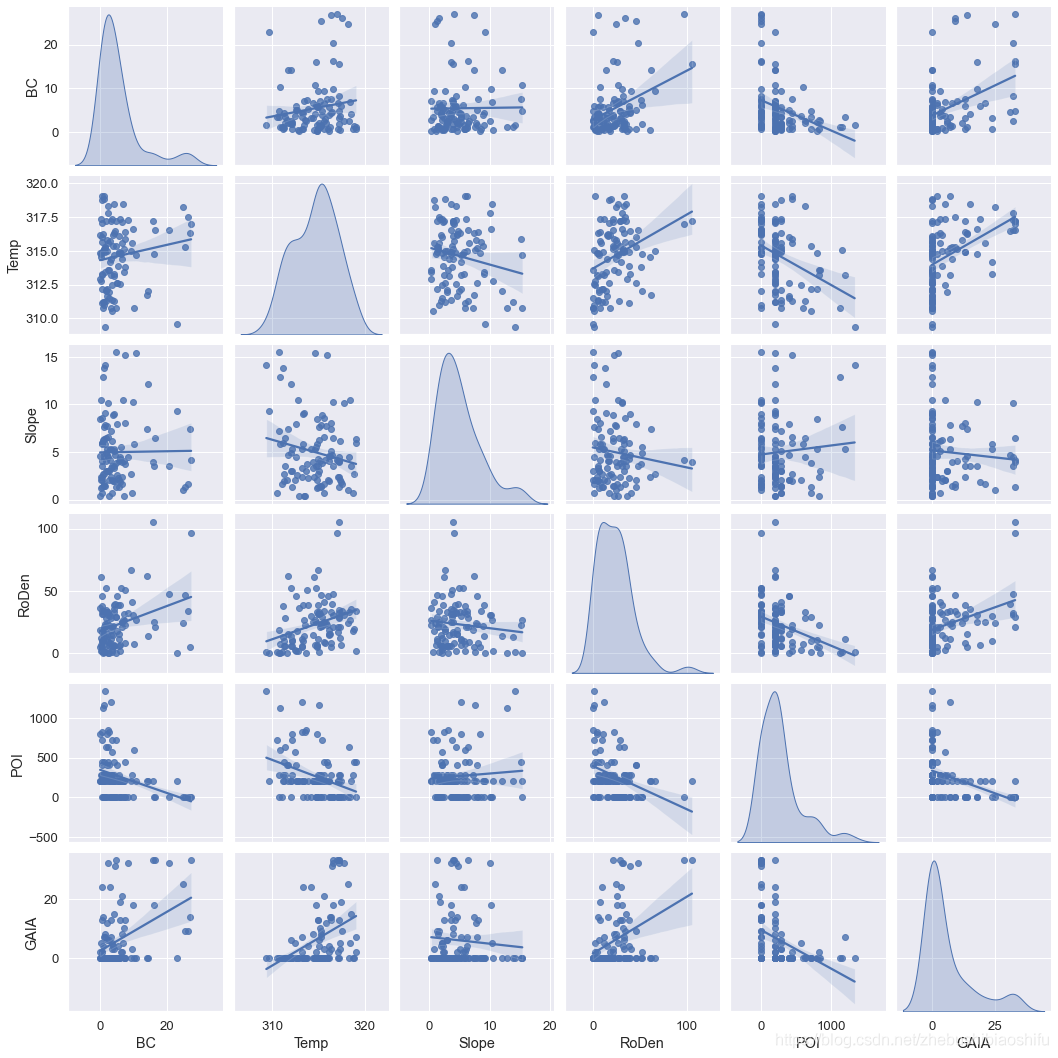
這樣子字型就大了~