真正「搞」懂HTTP協定13之HTTP2
在前面的章節,我們把HTTP/1.1的大部分核心內容都過了一遍,並且給出了基於Node環境的一部分範例程式碼,想必大家對HTTP/1.1已經不再陌生,那麼HTTP/1.1的學習基本上就結束了。這兩篇文章,我會和大家一起,學習一下HTTP/2和HTTP/3。
還記得我們在之前的時間回溯那篇文章裡,簡單的聊過HTTP/2和HTTP/3,是為了提升HTTP/1.1所存在的效能問題的,這篇文章我們先來看看HTTP/2帶來了哪些效能上的改進和提升。下一篇我們再來學習HTTP/3的效能優化。
不知道大家在第一次接觸HTTP/2、HTTP/3這樣的名字的時候會不會有些詫異?怎麼不是HTTP/2.0、HTTP/3.0呢?針對這個問題,HTTP/2的工作組給出了官方的回答。他們認為以前的「1.0」「1.1」造成了很多的混亂和誤解,讓人在實際的使用中難以區分差異,所以就決定 HTTP 協定不再使用小版本號(minor version),只使用大版本號(major version),從今往後 HTTP 協定不會出現 HTTP/2.0、2.1,只會有「HTTP/2」「HTTP/3」……這樣就可以明確無誤地辨別出協定版本的「躍程序度」,讓協定在一段較長的時期內保持穩定,每當釋出新版本的 HTTP 協定都會有本質的不同,絕不會有「零敲碎打」的小改良。
一、相容HTTP/1
當我們在實際工作中想要開發基於之前版本的新版本程式碼時,第一個想到的問題就是相容,我要如何相容以前的程式碼,使得使用舊版本的使用者也可以儘可能無感的切換到新版本,享受新版本帶來的絲滑感受。HTTP/2也是如此,它在揹負眾多期待的同時,也揹負了HTTP/1龐大的歷史包袱,所以協定的修改就必須要考慮如何相容HTTP/1,否則就會破壞網際網路上無數現有的資產,這肯定不是大家想要看到的。那HTTP/2是怎麼做的呢?
HTTP/2把HTTP分解成了「語法」和「語意」兩部分,語法層面不做改動,與HTTP/1也就是RFC7231完全一致。比如請求方法、URI、狀態碼、頭欄位等都保持不變,這樣就消除了再學習的成本,基於HTTP的上層不需要任何的改動,可以無縫轉換到HTTP/2。
特別要說的是,HTTP/2沒有再URI裡引入新的協定名,仍然用「http」表示明文協定,用「https」表示加密協定。這是一個非常了不起的決定,可以讓瀏覽器或者伺服器去自動升級或降級協定,免去了選擇的麻煩,讓使用者在上網的時候都意識不到協定的切換,實現平滑過渡。
在「語意」保持穩定之後,HTTP/2 在「語法」層做了「天翻地覆」的改造,完全變更了 HTTP 報文的傳輸格式。
二、頭部壓縮
首先,為啥要對頭部進行壓縮呢?假設這樣一種場景,一個GET請求,返回的body十分簡單啊,可能就是個簡單的文字,幾十個位元組。但是頭欄位卻又幾百個,限制的十分嚴謹細膩,而這樣的請求在整個系統專案中又應用的十分頻繁,成了不折不扣的「大頭兒子」。更要命的是,這些報文的傳輸中,大部分的頭欄位都是一樣的。再者,HTTP針對body有很多優化的手段,卻對Header一點優化都沒有。
基於以上的這些原因,為了優化「長尾效應」導致大量的頻寬消耗在這了這些冗餘度極高的資料上的情況,HTTP/2就把頭部壓縮作為效能改進的一個重點,優化的方式,就是壓縮。但是HTTP/2的頭部壓縮並不是想body那樣的壓縮手段,而是專門開發了「HPACK」演演算法,在使用者端和伺服器端建立「字典」,用索引號表示重複的字串,還釆用哈夫曼編碼來壓縮整數和字串,可以達到 50%~90% 的高壓縮率。
客製化的HPACK
由於HTTP/2在語意上與HTTP/1相容,所以報文還是Header+Body的形式,但是在請求傳送前,必須要用「HPACK」演演算法來壓縮頭部資料。
「HPACK」演演算法是專門為壓縮HTTP頭部客製化的演演算法,與gzip、zlib等壓縮演演算法不同,它是一個「有狀態」的演演算法,需要使用者端和伺服器都維護一份「索引表」,也可以說是字典,壓縮和解壓縮就是查表和更新表的操作。
為了方便管理和壓縮,HTTP/2廢除了原有的起始行的概念,把起始行裡面的請求方法、URI、狀態碼等統一轉換成了頭欄位的形式,並且給這些「不是頭欄位的頭欄位」起了個特別的名字——「偽頭欄位」。而起始行裡面的版本號和錯誤短語因為沒啥大用,就給廢棄了。
為了與「真頭欄位」區分開,這些偽頭欄位會在名字前面加上一個「:」,比如「:authority」、「:method」、「:status」,分別表示的是域名、請求方法和狀態碼。現在 HTTP 報文頭就簡單了,全都是「Key-Value」形式的欄位,於是 HTTP/2 就為一些最常用的頭欄位定義了一個唯讀的「靜態表」(Static Table)。
下面的這個表格列出了「靜態表」的一部分,這樣只要查表就可以知道欄位名和對應的值,比如數位「2」代表「GET」,數位「8」代表狀態碼 200。
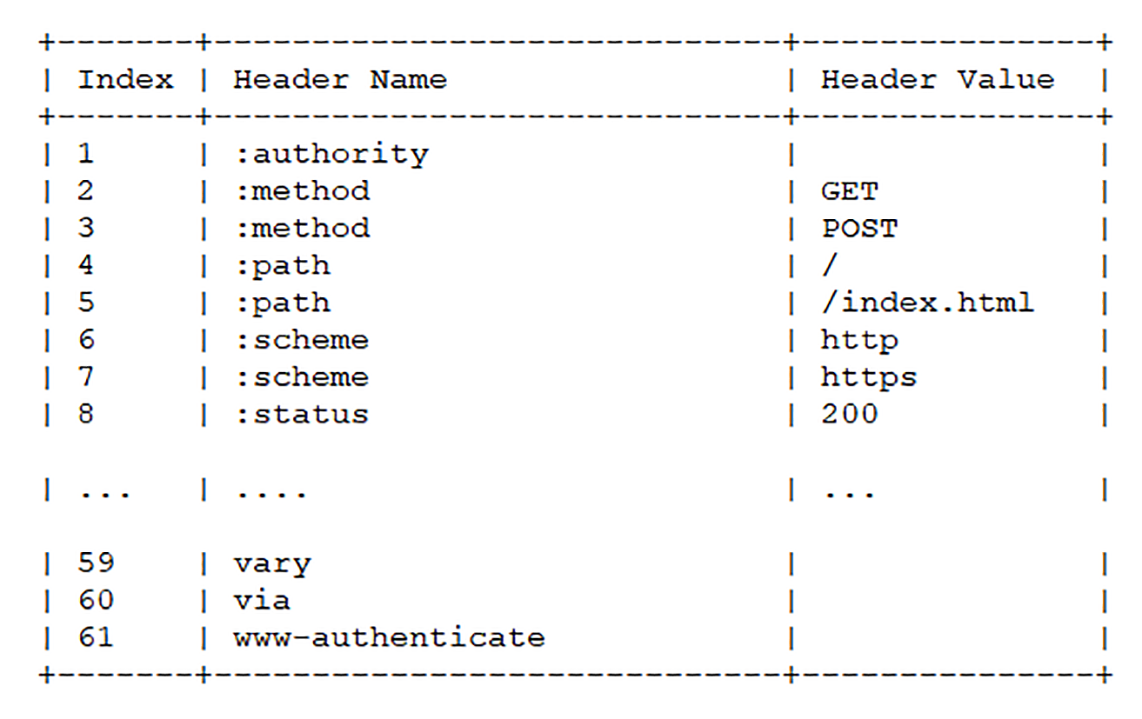
但如果表裡只有 Key 沒有 Value,或者是自定義欄位根本找不到該怎麼辦呢?這就要用到「動態表」(Dynamic Table),它新增在靜態表後面,結構相同,但會在編碼解碼的時候隨時更新。
比如說,第一次傳送請求時的「user-agent」欄位長是一百多個位元組,用哈夫曼壓縮編碼傳送之後,使用者端和伺服器都更新自己的動態表,新增一個新的索引號「65」。那麼下一次傳送的時候就不用再重複發那麼多位元組了,只要用一個位元組傳送編號就好。
你可以想象得出來,隨著在 HTTP/2 連線上傳送的報文越來越多,兩邊的「字典」也會越來越豐富,最終每次的頭部欄位都會變成一兩個位元組的程式碼,原來上千位元組的頭用幾十個位元組就可以表示了,壓縮效果比 gzip 要好得多。
三、二進位制幀
大家知道HTTP/1是純文字形式的報文,它的優點就是對人友好,一目瞭然,用最簡單的工具,甚至不用工具就可以開發偵錯,非常方便。
但是HTTP/2改變了延續十多年的現狀,不再使用肉眼可見的ASCII碼,而是向下層的TCP/IP協定「靠攏」,全面採用二進位制格式。這樣雖然對人不友好,但卻大大方便了計算機的解析。原來使用純文字的時候容易出現多義性,比如大小寫、空白字元、回車換行、多字少字等等,程式在使用時必須用複雜的狀態機,效率低,還很麻煩。
二進位制裡只有0和1,可以嚴格規定欄位大小、順序、標誌位等格式,對錯分明,解析起來沒有歧義,實現簡單,而且體積小、速度快,做到「內部提效」。
基於二進位制的基礎,HTTP/2進行了大刀闊斧的改革。
它把TCP協定的部分特性挪到了應用層,把原來「Header+Body」的訊息「打散」為數個小片的二進位制「幀」(Frame),用"HEADERS"幀存放頭資料,「DATA」幀存放實體資料。
這種做法有點像是「Chunked」分塊編碼的方式(參見第 16 講),也是「化整為零」的思路,但 HTTP/2 資料分幀後「Header+Body」的報文結構就完全消失了,協定看到的只是一個個的「碎片」。
二進位制幀的結構
我們先來看張圖吧:

我們看圖說話。幀開頭就是三個位元組的長度,預設上限是2^14到2^24,也就是說HTTP/2的幀的大小通常不超過16K,最大是16M。當然,這個長度不包括幀頭(Frame Header)的9個位元組。
長度後面的一個位元組是幀型別,大致可以分為資料框和控制幀兩類,HEADERS幀和DATA幀屬於資料框,存放的是HTTP報文,而SETTINGS、PING、PRIORITY等則是用來管理流的控制幀。
HTTP/2總共定義了10種型別的幀,但一個位元組最多可以標識256種,所以也允許在標準之外定義其他型別實現功能擴充套件。
第五個位元組是非常重要的幀標誌資訊,可以儲存8個標誌位,攜帶簡單的控制資訊。常用的標誌位有 END_HEADERS 表示頭資料結束,相當於 HTTP/1 裡頭後的空行(「\r\n」),END_STREAM 表示單方向資料傳送結束(即 EOS,End of Stream),相當於 HTTP/1 裡 Chunked 分塊結束標誌(「0\r\n\r\n」)。
報文頭裡最後4個位元組流識別符號,也就是幀所屬的「流」,接收方使用它就可以從亂序的幀裡識別出具有相同流 ID 的幀序列,按順序組裝起來就實現了虛擬的「流」。
四、流與多路複用
有了二進位制格式的資料後,就可以把一整塊的資料打散,然後傳送出去。那碎片到了目的地後要怎麼組裝起來呢?
HTTP/2為此定義了一個流(Stream)的概念,它是二進位制幀的雙向傳輸序列,同一個訊息往返的幀會分配一個唯一的流ID。你可以把它想象成是一個虛擬的「資料流」,在裡面流動的是一串有先後順序的資料框,這些資料框按照次序組裝起來就是HTTP/1裡的請求報文和響應報文。
因為「流」是虛擬的,實際上並不存在,所以 HTTP/2 就可以在一個 TCP 連線上用「流」同時傳送多個「碎片化」的訊息,這就是常說的「多路複用」( Multiplexing)——多個往返通訊都複用一個連線來處理。
在「流」的層面上看,訊息是一些有序的「幀」序列,而在「連線」的層面上看,訊息卻是亂序收發的「幀」。多個請求 / 響應之間沒有了順序關係,不需要排隊等待,也就不會再出現「隊頭阻塞」問題,降低了延遲,大幅度提高了連線的利用率。
為了更好地利用連線,加大吞吐量,HTTP/2 還新增了一些控制幀來管理虛擬的「流」,實現了優先順序和流量控制,這些特性也和 TCP 協定非常相似。
HTTP/2 還在一定程度上改變了傳統的「請求 - 應答」工作模式,伺服器不再是完全被動地響應請求,也可以新建「流」主動向使用者端傳送訊息。比如,在瀏覽器剛請求 HTML 的時候就提前把可能會用到的 JS、CSS 檔案發給使用者端,減少等待的延遲,這被稱為「伺服器推播」(Server Push,也叫 Cache Push)。
這麼說還是有點僵硬,不那麼好理解,我們來看張圖,再深入的理解下什麼是虛擬的流和多路複用。
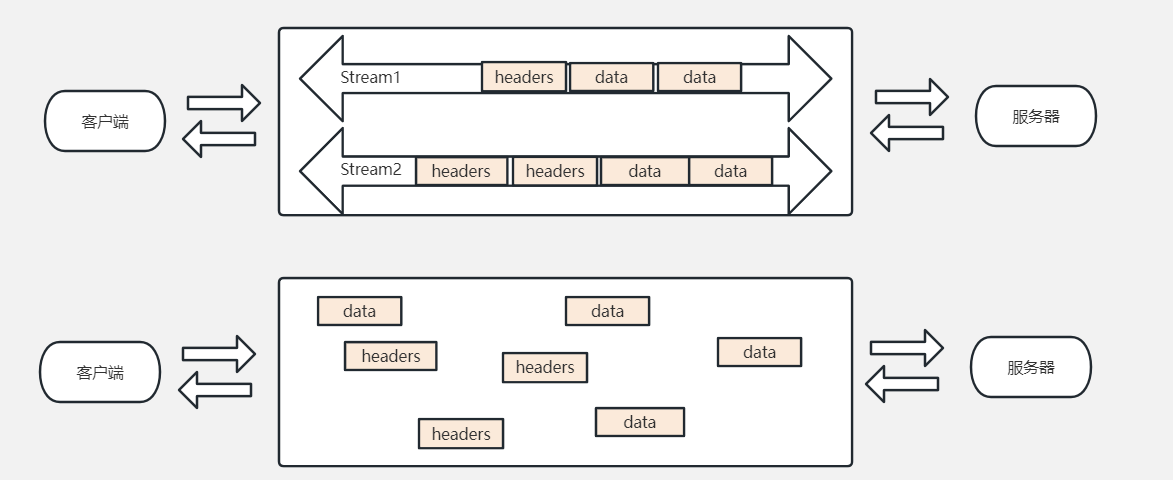
我們先來看第一部分,有Stream1、Stream2標識的就代表著虛擬流,其實在實際的傳輸種並不存在,只是一種往返的標識,表示我是屬於這一次通訊的,所以才說流是虛擬的。
然後是下面的這一部分,就是打散的在TCP通道種傳輸的一個又一個二進位制幀資料,每個幀資料種會有流ID,到達終點後會根據流ID來拼接成一個完整的資料。這樣是不是就更好理解了什麼是虛擬流。
在 HTTP/2 連線上,雖然幀是亂序收發的,但只要它們都擁有相同的流 ID,就都屬於一個流,而且在這個流裡幀不是無序的,而是有著嚴格的先後順序。
其實上面的圖稍微缺失了一點東西,我們把它加上:
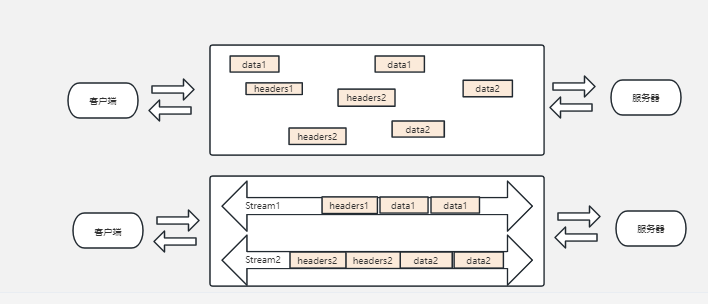
我們看上圖,其實在傳輸的時候是亂序的,每個幀都有其獨立的流ID,然後就像是虛擬了流的傳輸。
HTTP/2流的特點
我們學了不少關於HTTP/2流的內容,那麼我們繼續看看HTTP/2的流有哪些特點吧。
流是可並行的,一個 HTTP/2 連線上可以同時發出多個流傳輸資料,也就是並行多請求,實現「多路複用」;
使用者端和伺服器都可以建立流,雙方互不干擾;
流是雙向的,一個流裡面使用者端和伺服器都可以傳送或接收資料框,也就是一個「請求 - 應答」來回;
流之間沒有固定關係,彼此獨立,但流內部的幀是有嚴格順序的;
流可以設定優先順序,讓伺服器優先處理,比如先傳 HTML/CSS,後傳圖片,優化使用者體驗;
流 ID 不能重用,只能順序遞增,使用者端發起的 ID 是奇數,伺服器端發起的 ID 是偶數;
在流上傳送「RST_STREAM」幀可以隨時終止流,取消接收或傳送;
第 0 號流比較特殊,不能關閉,也不能傳送資料框,只能傳送控制幀,用於流量控制。
基於這些內容,我們還可以推斷出一些更深層次的東西。比如說,HTTP/2 在一個連線上使用多個流收發資料,那麼它本身預設就會是長連線,所以永遠不需要「Connection」頭欄位(keepalive 或 close)。
又比如,下載大檔案的時候想取消接收,在 HTTP/1 裡只能斷開 TCP 連線重新「三次握手」,成本很高,而在 HTTP/2 裡就可以簡單地傳送一個「RST_STREAM」中斷流,而長連線會繼續保持。
再比如,因為使用者端和伺服器兩端都可以建立流,而流 ID 有奇數偶數和上限的區分,所以大多數的流 ID 都會是奇數,而且使用者端在一個連線裡最多隻能發出 2^30,也就是 10 億個請求。所以就要問了:ID 用完了該怎麼辦呢?這個時候可以再發一個控制幀「GOAWAY」,真正關閉 TCP 連線。
流狀態轉換
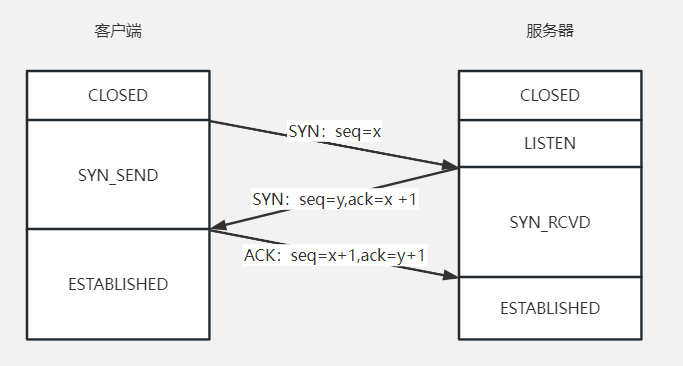
大家記不記得TCP的三次握手,其實本質上是封包的交換和雙方狀態的轉換,最開始的時候,使用者端和伺服器都處於CLOSED狀態,當用戶端發起一個SYN的時候,伺服器會進入LISTEN狀態。然後往復的封包會使使用者端和伺服器切換狀態,我們貼一下之前貼過的圖:
那麼,HTTP/2的流其實也有一個狀態轉換的過程。我們先來看下流狀態轉換的圖:
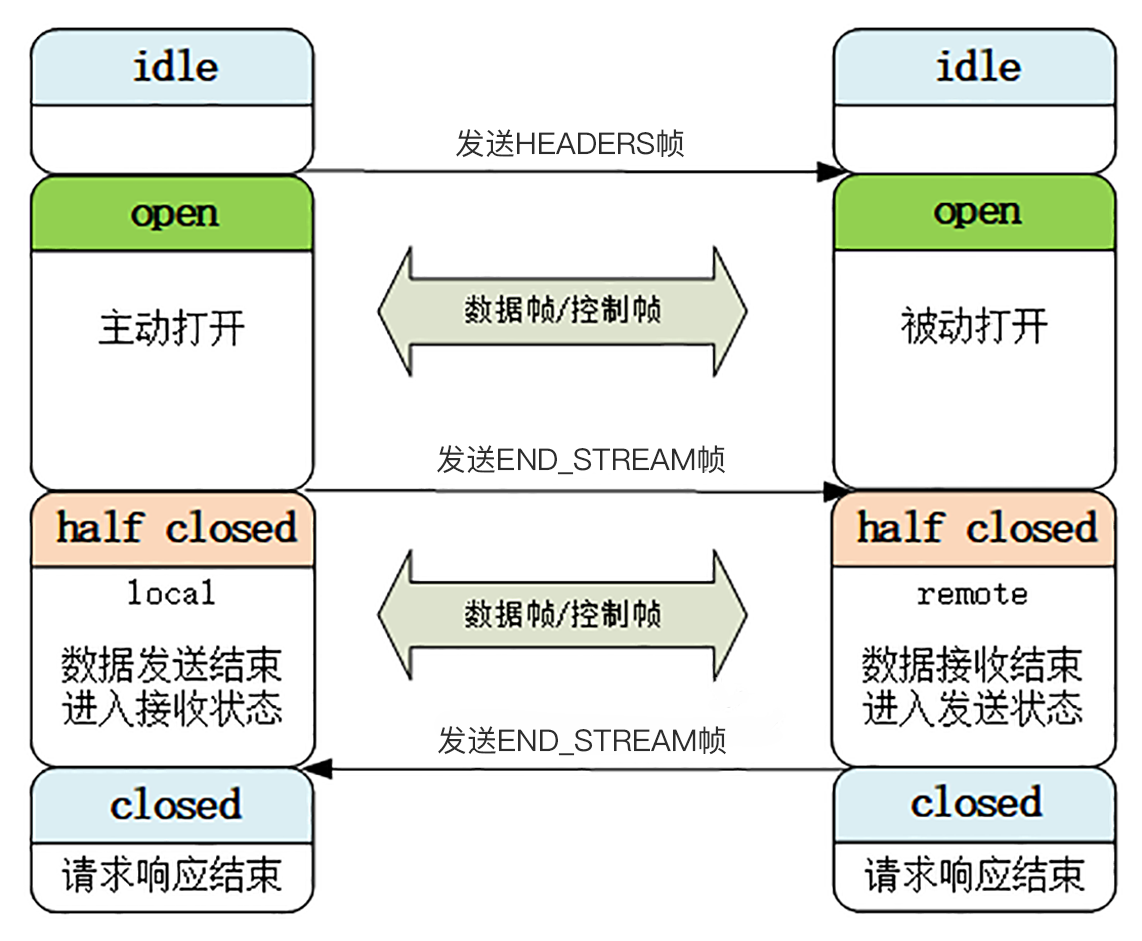
最開始的時候,流都是空閒(idle)狀態,也就是」不存在「,可以理解成是待分配的」號段資源「。
當用戶端傳送HEADERS幀後,有了流ID,流就進入了」開啟「狀態,兩端都可以收發資料,然後使用者端傳送一個帶「END_STREAM」標誌位的幀,流就進入了「半關閉」狀態。
這個「半關閉」狀態很重要,意味著使用者端的請求資料已經傳送完了,需要接受響應資料,而伺服器端也知道請求資料接收完畢,之後就要內部處理,再傳送響應資料。
響應資料發完了之後,也要帶上「END_STREAM」標誌位,表示資料傳送完畢,這樣流兩端就都進入了「關閉」狀態,流就結束了。
剛才也說過,流 ID 不能重用,所以流的生命週期就是 HTTP/1 裡的一次完整的「請求 - 應答」,流關閉就是一次通訊結束。
下一次再發請求就要開一個新流(而不是新連線),流 ID 不斷增加,直到到達上限,傳送「GOAWAY」幀開一個新的 TCP 連線,流 ID 就又可以重頭計數。
我們再看看這張圖,是不是和 HTTP/1 裡的標準「請求 - 應答」過程很像,只不過這是發生在虛擬的「流」上,而不是實際的 TCP 連線,又因為流可以並行,所以 HTTP/2 就可以實現無阻塞的多路複用。
五、小結
本來我是想寫個HTTP/2的例子的,但是程式碼其實Node官網有,我寫也是照抄,另外,還需要本地安裝openssl的證書(因為雖然協定不強制加密,但是現在的瀏覽器不加密就不能用HTTP/2),我嫌麻煩,就不寫了~
我們目前學完了HTTP/2的大部分核心特性,這些內容肯定不是HTTP/2的全部,但是卻是最重要的一部分。
另外,HTTP/2為了相容HTTP/1的明文特點,可以像以前一樣使用明文傳輸資料,不強制使用加密通訊,不過格式還是二進位制,只是不需要解密。但是由於HTTPS是大勢所趨,基本上網際網路上的HTTP/2都是加密的。但是為了區分加密和明文這兩個不同版本,HTTP/2定義了h2和h2c兩個字串來區分。
相比於HTTPS,HTTP/2的下層實際上是HPACK和STREAM,加密則是TLS1.2+,這個大家瞭解下就可以了。
最後,還有一個核心的概念叫做」連線前言「,我剛剛也說了,HTTP/2事實上是基於TLS的,所以在正式傳送資料前就會有TCP握手和TLS握手,當TLS握手成功後,使用者端必須傳送一個」連線前言「,用來確認建立HTTP/2連線。
這個「連線前言」是標準的 HTTP/1 請求報文,使用純文字的 ASCII 碼格式,請求方法是特別註冊的一個關鍵字「PRI」,全文只有 24 個位元組:
PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n
那為啥要這樣做呢?沒有為啥,就是王八的屁股~規定。
還有,HTTP/2固然有很多優點,不然還搞它幹啥,但是HTTP/2也有不少的問題。最嚴重的問題就是丟包和TCP的重新連線。丟包問題是在TCP級別的,HTTP/2解決不了TCP級別的隊頭阻塞,所以當包丟失後,就要等待後續的包再重新傳一遍,當達到一定的丟包率,甚至效能表現還不如HTTP/1。而重新連線,則發生在IP地址切換的時候,TCP就要再次握手,經歷慢啟動,而且之前連線裡積累的HPACK字典也都沒了,必須重新計算,導致頻寬的浪費和延遲。
好啦,HTTP/2的內容很多,僅僅是這一篇文章肯定不夠,但是大家學會了虛擬流、理解了多路複用、頭部壓縮的HPACK,其實也就瞭解了HTTP/2的核心,其它的細節,大家可以去規範中自行查閱學習。
本文來自部落格園,作者:Zaking,轉載請註明原文連結:https://www.cnblogs.com/zaking/p/17106495.html