NodeJS 實戰系列:DevOps 尚未解決的問題
本文將通過展示 NodeJS 應用裡環境變數的提取過程,來一窺 DevOps 技術是如何應用在現在雲平臺上的運維工作中的。同時我也想讓大家在這裡看到 DevOps 的另外一面,即它並非全能,從本地開發到持續部署再到實際執行,有一些運維鴻溝依然還未被填平。「人工操作」依然是工作中的最大風險。
實戰系列來自於個人開發以及運維 site2share 網站過程中的經驗
不完美的環境變數抽取
有一件事我想我們都會同意,那就是不應該在程式碼中寫死(hard code)環境變數,比如生產環境資料庫的使用者名稱和密碼。之所以稱之為環境變數,是因為這些變數是依據你程式碼部署的環境而定的,例如生產環境和本地環境資料庫使用者名稱和密碼就多半不會相同。下面就是一段使用 sequelize 連線資料庫的程式碼的反例,其中寫死了使用者名稱和密碼:
const connectionCfg = {
username: "admin",
password: "!password",
database: "order_db",
dialect: "mysql",
}
new Sequelize(connectionCfg);
將環境變數寫死在程式碼中會產生幾個問題:
- 安全:將使用者名稱密碼暴露給所有的開發人員並不安全,刪庫跑路的風險大大增加
- 耦合:運維同學如果需要對環境進行變更(比如遷移、新增),需要聯絡「無辜的」開發同學重現編輯和部署程式碼
所有我們應該利用 process.env 或者是 dotenv 工具,來將環境變數獨立管理,讓程式碼與環境解耦。
思路我們有了,本地開發的時候如果你使用了 dotnev,它預設會讀取 .env 裡的內容作為環境變數。但是當考慮到下一步我們把應用部署到生產環節時,你要面臨的問題就是如何在你的雲服務商環境上管理你的環境變數了。
這取決於你選擇雲服務解決方案。以 site2share 為例,因為我選擇將它部署在 Azure App Service(App Service 簡單來說是一個託管性質的服務部署平臺,我可以快速部署程式碼而不用去維護背後的執行環境,並且它還提供了諸如監控、灰度部署等常用功能) 上,所以我可以直接使用 App Service 為我準備的環境變數解決方案。我只需要在我環境的 UI 介面上填寫我的環境變數即可:
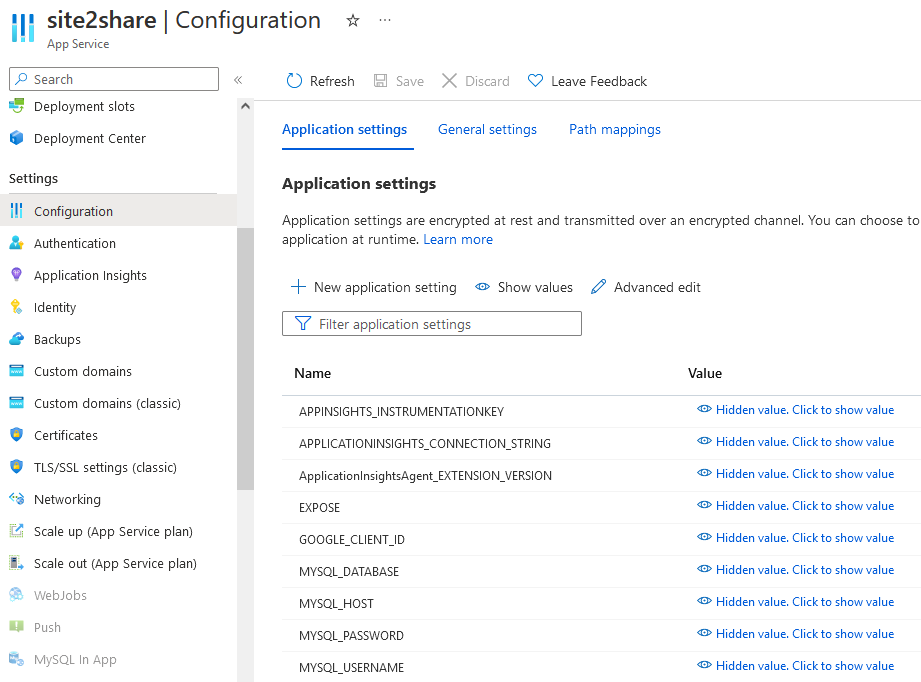
基本上目前主流雲服務廠商提供的完全託管服務(full managed service)都提供類似的機制,下面是 Digital Ocean 的 App Platform 方案提供的環境變數管理介面:

到這裡看似完美了——這樣會帶來一個風險:它並非是 IaC(Infrastructure as Code) 的。
什麼是 IaC 我在這裡舉個例子,例如每次程式碼提交之後都會觸發流水線執行測試,這裡我把「需要執行測試」這件事記錄在一個 yaml 檔案裡並且提交:
- script: |
npm run test
displayName: 'npm test'
這樣將來無論是我自己回憶,還是新同學加入,都可以通過閱讀這個檔案判斷流水線幹了什麼。如果有一天測試不小心被刪掉了,也能追溯為什麼被刪以及被誰刪掉的
非 IaC 的風險在於,如果你將來本地開發時新增了環境變數 REDIS_HOST,你需要保證雲平臺上的每個環境也需要新增 REDIS_HOST 變數(反過來說不用的環境變數也應該刪除來避免將來給維護人員帶來疑惑),然而這個步驟目前看來完全是依賴人工來完成的,因為雲平臺無法自動識別到你新增了變數
這裡我們遇到了第一道鴻溝:開發環境與雲平臺的環境變數同步問題
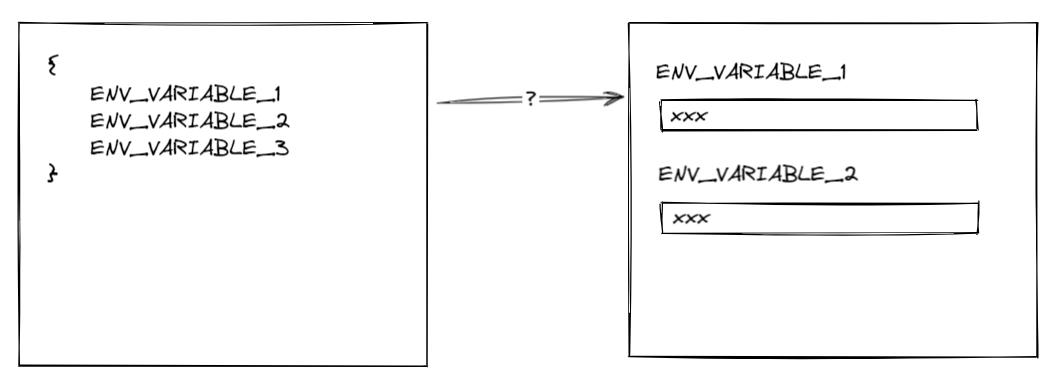
問題才剛剛開始
DevOps 沒有解決的問題
「人」 是DevOps 想要解決的問題之一,如果每次上線的成功都依賴自資深工程師的經驗,那出錯不過是早晚的事情而已。 把難的事情頻繁做就是 CI(持續整合)/CD(持續交付) 的背後思想。
例如我們常常需要對資料庫做變更,新增表或者列。把這類操作交給程式設計師手工去每個環境手工執行並非明智選擇,我們應該把它交給持續交付的流水線去完成,這樣會推動我們部署環境的標準化和自動化,減少風險。這一步驟我們將它命名為資料遷移( migration),我們看看 site2share 的資料遷移是如何做的。
因為我在程式碼中選擇了 sequelize 作為資料庫框架,所以理想情況是我只需要建立好資料遷移檔案之後執行 sequelize 提供的命令工具即可:sequelize-cli db:migrate
第一個問題是:它怎麼知道應該連線哪個資料庫以及如何連線資料庫?
sequelize 允許我們在目錄新增一個名為 .sequelizerc 的組態檔來對 sequelize 進行設定,我們可以在其中設定資料庫的連線字串和資料遷移檔案目錄,比如
const path = require('path');
const migrationDir = path.join(__dirname, "migration");
require('dotenv').config();
module.exports = {
'config': path.join(migrationDir, 'config.js'),
'migrations-path': path.join(migrationDir, 'migrations'),
'seeders-path': path.join(migrationDir, 'seeders'),
};
其中 config.js 檔案儲存的就是資料庫的連線設定,如使用者名稱和密碼:
第二個問題是:我們如何將使用者名稱和密碼等環境變數如第一小節所示抽取出來?config.js 允許我們存取 process.env.MYSQL_USERNAME,但 MYSQL_USERNAME 究竟應該如何讓流水線知道呢?
site2share 使用 Azure DevOps 作為 CI/CD 工具。很遺憾 Azure DevOps 並沒有如 App Service 那樣提供一個最優解,一種解決思路是我可以使用 Azure KeyVault 服務用作金鑰儲存,在構建的時候讀取;而我選擇的是一種更為簡單粗暴的方式:
- 將環境變數儲存到名為 .env.ci 的檔案中
- 把檔案上傳到 Azure DevOps 的 Secure Files 中,Secure Files 可以用於儲存證書型別檔案,上傳後的檔案不可以被預覽,不可以被下載
- 在 CD 過程中將 .env.ci 檔案從 secure files 裡下載到程式碼目錄裡,然後使用 dotenv 讀取載入作為環境變數
- 執行 sequelize-cli db:migrate 命令
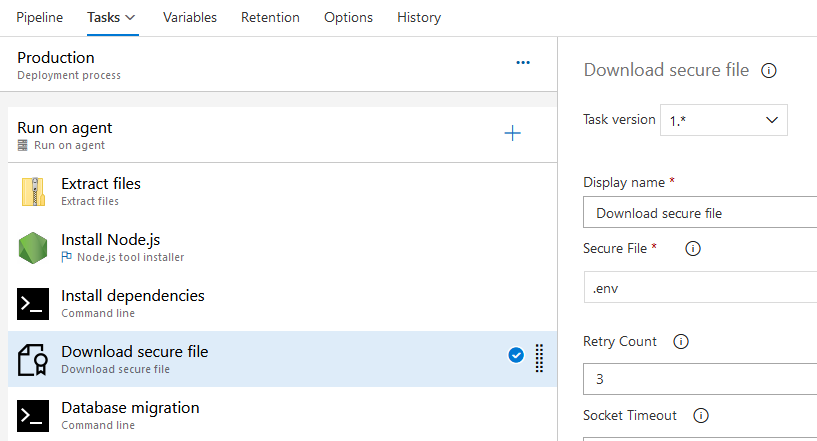
和在介面上編輯環境變數的行為類似,這種方法看上去同樣不具有可持續性的。它依賴人的手工操作
所以在這裡我們看到另一道鴻溝:環境變數從開發環境到流水線的同步問題
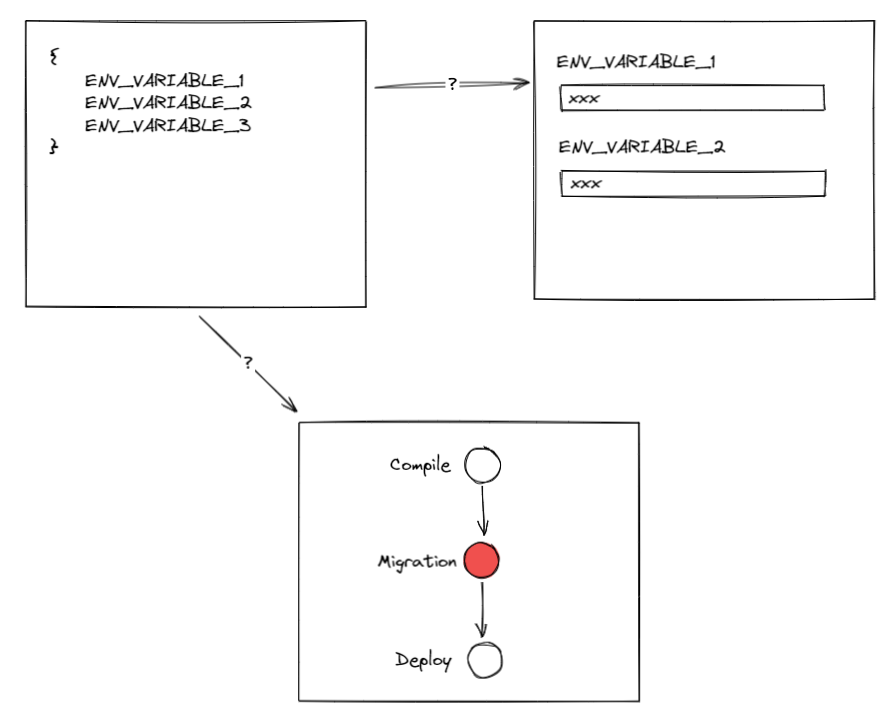
DevOps 是進步不是銀彈
DevOps 話題很大我們這裡暫且只看技術層面。我這裡不是對 DevOps 批評,更不是對 Azure 的批評。這類問題在不同的平臺都會存在,例如你如果使用阿里雲效,他們甚至不允許你以 yaml 程式碼去編輯和儲存流水線(IaC),但 IaC 也不是萬能的,當你的 yaml 檔案長達800行時基本等同於不可讀時,它起到的效果等同於不存在。雲平臺本身的 vendor-lock 的問題也是原罪
在這裡我們可以想象沒有它們運維工作會比現在難上不知道多少倍——不能因為美中不足就否認它們給我們帶來的幫助。
我們要接納這樣的一個現實:並不是所有的問題都可以用工具完美解決,「手工」暫且無法被徹底消滅。承認不完美的存在,盡所能把風險降到最小就好。
你可能也會喜歡:
- NodeJS 實戰系列:DevOps 尚未解決的問題
- NodeJS 實戰系列:如何設計 try catch
- 做一個能對標阿里雲的前端APM工具(下)
- 做一個能對標阿里雲的前端APM工具(上)
- 小心 Serverless
- SQL Server 查詢語句優化入門
- 利用Node.js+express框實現圖片上傳
- 一篇來自前端同學對後端介面的吐槽
- 關於Node.js後端架構的一點後知後覺
- 在Node.js中搭建快取管理模組'