基於Apache Hudi 構建Serverless實時分析平臺
NerdWallet 的使命是為生活中的所有財務決策提供清晰的資訊。 這涵蓋了一系列不同的主題:從選擇合適的信用卡到管理您的支出,到找到最好的個人貸款,再到為您的抵押貸款再融資。 因此,NerdWallet 提供了跨越眾多領域的強大功能,例如信用監控和警報、用於跟蹤淨值和現金流的儀表板、機器學習 (ML) 驅動的建議,以及為數百萬使用者提供的更多功能。
為了為我們的使用者構建一個一體化和高效能的體驗,我們需要能夠使用來自多個獨立團隊的大量不同的使用者資料。 這需要強大的資料文化以及一套資料基礎設施和自助服務工具,以實現創造力和共同作業。
這篇文章中我們闡述了一個用例,該用例說明 NerdWallet 如何通過構建支援來自整個公司的流資料的無伺服器 Serverless 管道來擴充套件其資料生態系統。 我們迭代了兩種不同的架構,並且說明在初始設計中遇到的挑戰,以及我們在第二個架構中使用 Apache Hudi 和其他 AWS 服務所獲得的收益。
問題定義
NerdWallet 收集了大量的支出資料。 此資料用於為使用者構建有用的儀表板和見解。資料儲存在 Amazon Aurora 叢集中。 儘管 Aurora 叢集作為聯機事務處理 (OLTP) 引擎執行良好,但它不適合大型、複雜的聯機分析處理 (OLAP) 查詢,因此我們無法向分析師和資料工程師公開直接的資料庫存取許可權。資料所有者必須使用唯讀副本上的資料來解決此類請求。 隨著資料量以及資料消費者和請求的多樣性的增長,這個過程變得更加難以維護。 此外資料科學家大多需要從 Amazon Simple Storage Service (Amazon S3) 等物件儲存存取資料檔案。
我們決定探索所有消費者都可以使用開放標準工具和協定安全且可延伸地獨立完成他們自己的資料請求的替代方案。 從資料網格範例中汲取靈感,我們設計了一個基於 Amazon S3 的資料湖,將資料生產者與消費者分離,同時提供自助服務、安全合規且可延伸的易於設定的工具集。
初始架構
下圖是初始設計的架構

該設計包括以下關鍵元件:
- 使用 AWS Data Migration Service (AWS DMS),因為它是一種託管服務,可促進資料從各種資料儲存(例如關聯式資料庫和 NoSQL 資料庫)移動到 Amazon S3。 AWS DMS 允許使用變更資料捕獲 (CDC) 進行一次性遷移和持續複製,以保持源資料儲存和目標資料儲存同步。
- 使用 Amazon S3 作為我們資料湖的基礎,因為它具有可延伸性、永續性和靈活性。 您可以將儲存從 GB 級無縫增加到 PB 級,只需為您使用的部分付費,它提供 11 個 9 的可用性,支援結構化、半結構化和非結構化資料,並與廣泛的 AWS 服務組合進行原生整合。
- AWS Glue 是一種完全託管的資料整合服務。 AWS Glue 可以更輕鬆地在不同資料儲存之間分類、清理、轉換和可靠地傳輸資料。
- Amazon Athena 是一種無伺服器互動式查詢引擎,可讓您使用標準 SQL 直接在 Amazon S3 中輕鬆分析資料。 Athena 自動擴充套件——並行執行查詢——因此結果很快,即使是大型資料集、高並行和複雜的查詢。
該架構適用於小型測試資料集,然而團隊很快就遇到了大規模生產資料集的問題。
挑戰
團隊遇到了以下挑戰
- 長批次處理時間和複雜的轉換邏輯——Spark 批次處理作業的單次執行需要 2-3 小時才能完成,並且在針對數十億條記錄進行測試時,我們最終支付了相當大的 AWS 賬單。 核心問題是我們必須重建最新狀態併為每個作業執行重寫每個分割區的整個記錄集,即使增量更改是分割區的單個記錄也是如此。
- 大量使用者端增加了複雜性——此工作負載包含數百萬個使用者端,一種常見的查詢模式是按單個使用者端 ID 進行過濾。 我們被迫進行了許多優化,例如謂詞下推、調整 Parquet 檔案大小、使用分桶分割區方案等。 隨著越來越多的資料所有者採用這種架構,我們將不得不針對他們的資料模型和消費者查詢模式客製化每一個優化。
- 實時用例的有限可延伸性——這種批次提取、轉換和載入 (ETL) 架構無法擴充套件以處理每秒數千條記錄更新插入的每小時更新。 此外資料平臺團隊要跟上多樣化的實時分析需求將是一項挑戰。 增量查詢、時間旅行查詢、改進延遲等都需要在很長一段時間內進行大量投入。改進這個問題將開啟近實時 ML 推理和基於事件的警報等。
由於初始架構設計的所有這些限制,我們決定重新設計一個真正的增量處理架構
解決方案
下圖展示了我們重新設計的架構。為了支援實時用例,我們在架構中新增了 Amazon Kinesis Data Streams、AWS Lambda、Amazon Kinesis Data Firehose 和 Amazon Simple Notification Service (Amazon SNS)。
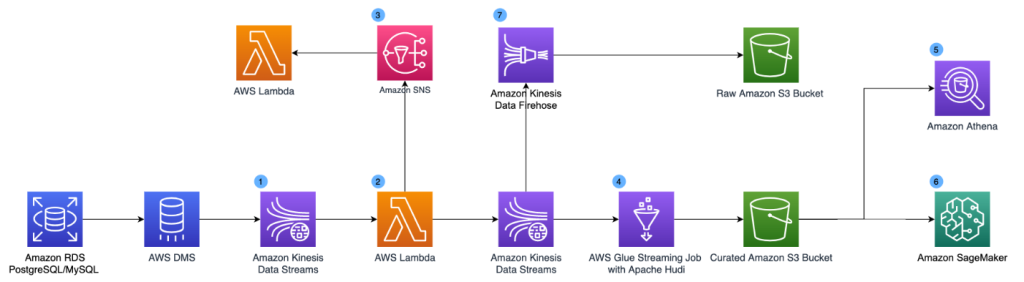
新引入的元件如下:
- Amazon Kinesis Data Streams 是一種無伺服器流資料服務,可以輕鬆捕獲、處理和儲存資料流。 我們將 Kinesis 資料流設定為 AWS DMS 的目標,資料流收集 CDC 紀錄檔。
- 我們使用 Lambda 函數來轉換 CDC 記錄。 我們在 Lambda 函數的記錄級別應用架構驗證和資料擴充,轉換後的結果釋出到第二個 Kinesis 資料流以供資料湖使用和 Amazon SNS 主題,以便可以將更改分散到各種下游系統。
- 下游系統可以訂閱 Amazon SNS 主題並根據 CDC 紀錄檔採取實時操作(在幾秒鐘內)。 這可以支援異常檢測和基於事件的警報等用例。
- 為了解決批次處理時間長的問題,我們使用 Apache Hudi 格式儲存資料,並使用 AWS Glue 流作業執行流式 ETL。 Apache Hudi 是一個開源的事務性資料湖框架,極大地簡化了增量資料處理和資料管道開發。 Hudi 允許使用增量資料管道構建流式資料湖,支援事務、記錄級更新和刪除儲存在資料湖中的資料。 Hudi 與各種 AWS 分析服務(如 AWS Glue、Amazon EMR 和 Athena)很好地整合,這使其成為我們之前架構的直接擴充套件。 Apache Hudi 解決了記錄級更新和刪除挑戰,而 AWS Glue 流作業將長時間執行的批次處理轉換轉換為低延遲的微批次處理轉換。 我們使用 Apache Hudi 的 AWS Glue 聯結器在 AWS Glue 流式處理作業中匯入 Apache Hudi 依賴項,並將轉換後的資料連續寫入 Amazon S3。 Hudi 完成了記錄級更新插入的所有繁重工作,而我們只需設定編寫器並將資料轉換為 Hudi Copy-on-Write 表型別。 藉助 Hudi on AWS Glue 流式作業,我們將核心資料集的資料新鮮度延遲從數小時減少到 15 分鐘以下。
- 為了解決高基數 UUID 的分割區挑戰,我們使用分桶技術。 Bucketing 將基於特定列的資料分組到一個分割區中。 這些列稱為儲存桶鍵。 將相關資料分組到一個儲存桶(分割區中的一個檔案)時可以顯著減少 Athena 掃描的資料量,從而提高查詢效能並降低成本。 我們現有的查詢已經根據使用者 ID 進行了過濾,因此我們可以顯著提高 Athena 使用的效能,而無需通過使用分桶使用者 ID 作為分割區方案來重寫查詢。 例如,以下程式碼顯示每個使用者在特定類別中的總支出:
SELECT ID, SUM(AMOUNT) SPENDING
FROM "{{DATABASE}}"."{{TABLE}}"
WHERE CATEGORY IN (
'ENTERTAINMENT',
'SOME_OTHER_CATEGORY')
AND ID_BUCKET ='{{ID_BUCKET}}'
GROUP BY ID;
- 我們的資料科學家團隊可以使用 Amazon SageMaker 存取資料集並執行 ML 模型訓練。
- 我們通過 Amazon Kinesis Data Firehose 在 Amazon S3 中維護原始 CDC 紀錄檔的副本。
結論
採用一種無伺服器流處理架構,該架構可以在我們資料湖的新鮮度幾分鐘內擴充套件到每秒數千次寫入。在目前的規模下,Hudi 作業每秒處理每個 AWS Glue Worker 大約 1.75 MiB,它可以自動向上和向下擴充套件(得益於 AWS Glue 自動擴充套件)。 由於 Hudi 的增量更新與我們的第一次架構相比,在不到 5 分鐘的時間內端到端新鮮度有了顯著改善。
藉助 Amazon S3 上的 Hudi,我們已經建立了一個高槓杆基礎來個性化我們的使用者體驗。 擁有資料的團隊現在可以通過千篇一律的解決方案中內建的可靠性和效能特徵在整個組織內共用他們的資料。 這使我們的資料消費者能夠構建更復雜的訊號,為生活中的所有財務決策提供清晰度。
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

