開源分散式支援超大規模資料分析型資料倉儲Apache Kylin實踐-下
@
使用注意
連線條件限制
Kylin只能按照構建 Model 時使用的連線條件來使用,例如在前面建立 emp_model 時,對emp表和dept表選用的是 Inner Join 也即是內連線的方式,在使用 Kylin 查詢的時候,也只能用 join 內連線,如果在使用 Kylin 查詢時使用其他連線如左連線會報錯。
select dept.dname,sum(emp.sal) from emp left join dept on emp.deptno = dept.deptno group by dept.dname;
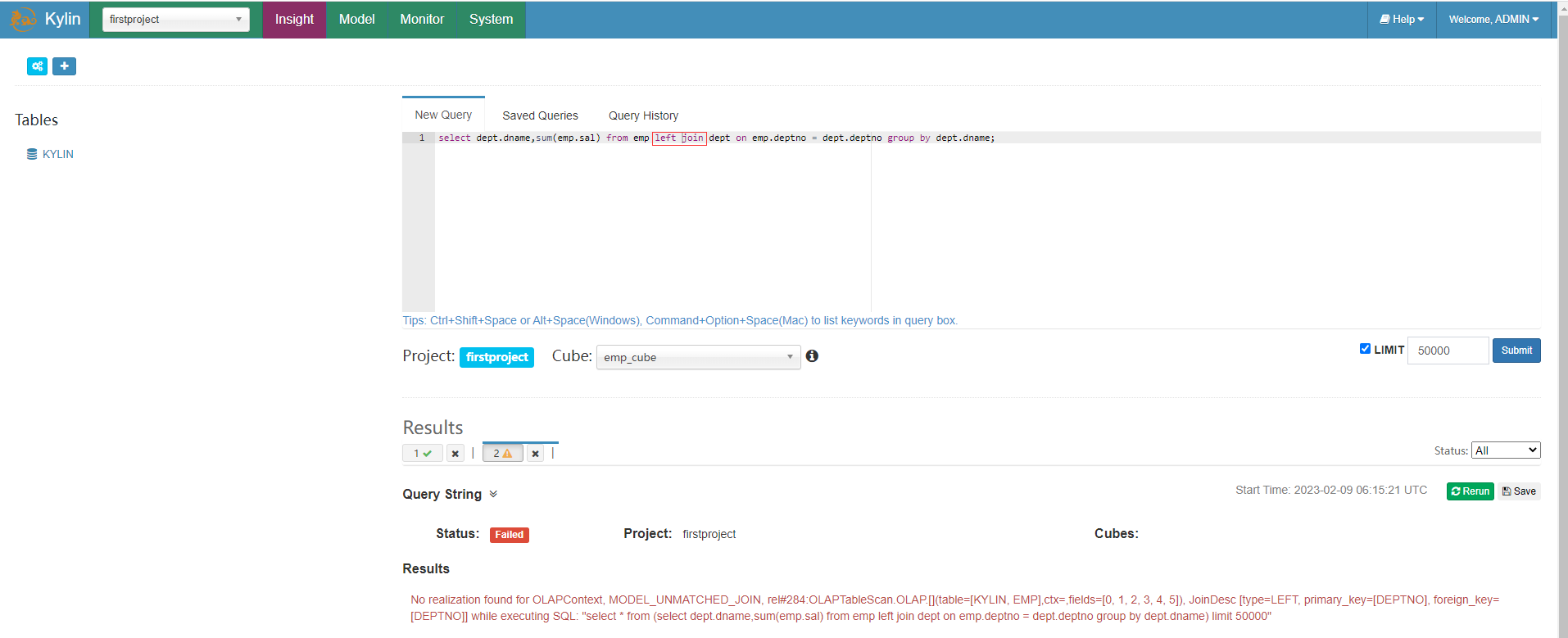
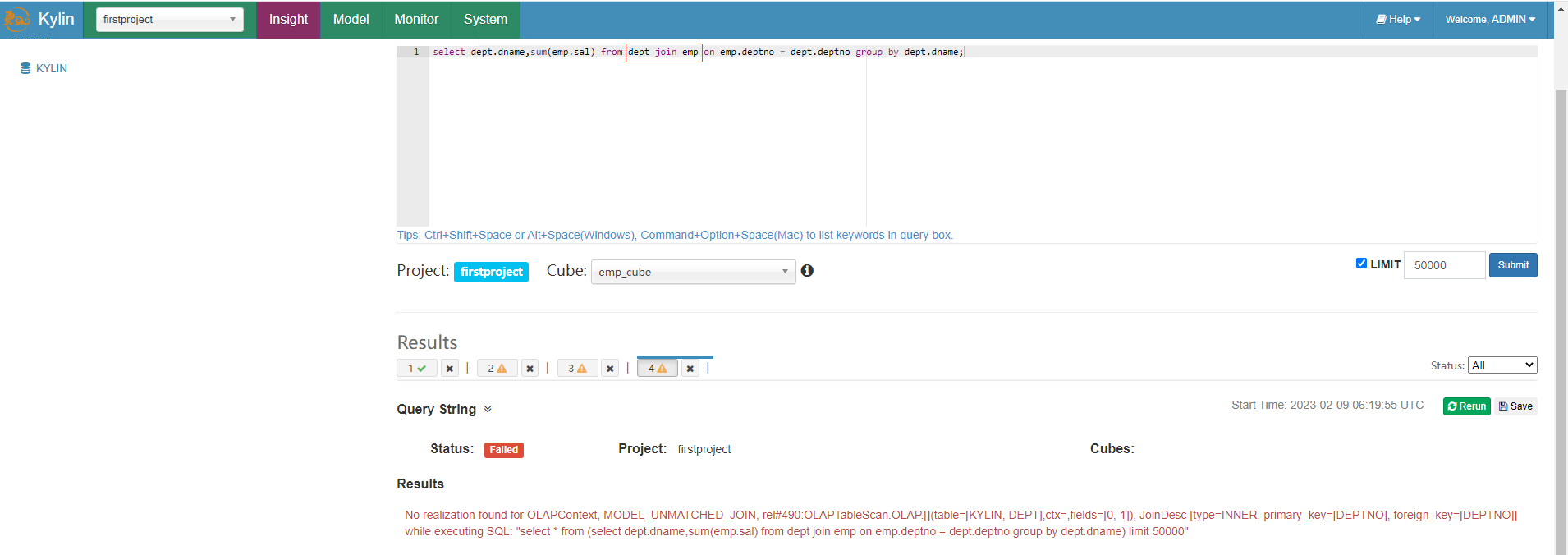
再查詢語句中還要求事實表在前,維度表在後,否則也會報錯,例如把dept部門維度表放在前面會報錯。
select dept.dname,sum(emp.sal) from dept join emp on emp.deptno = dept.deptno group by dept.dname;
維度限制
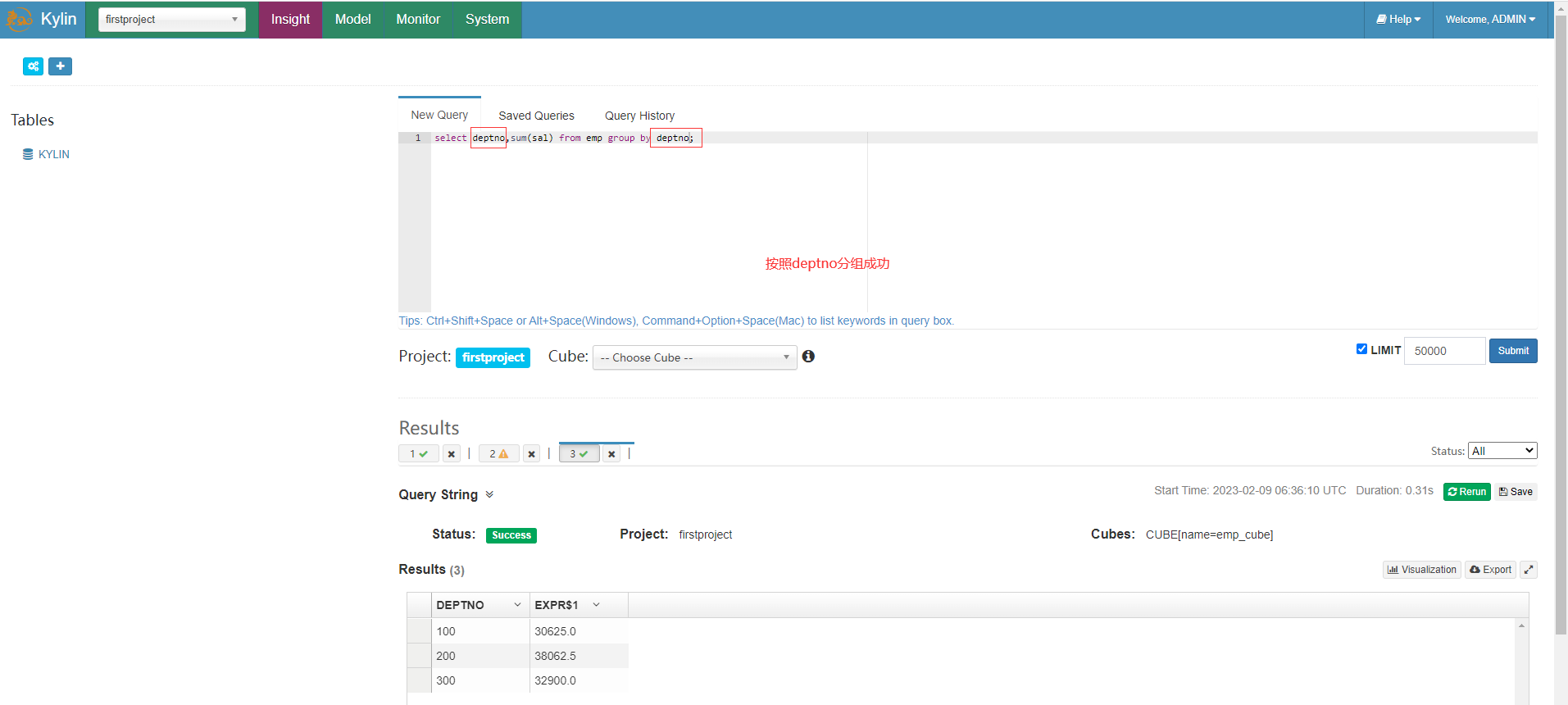
Kylin只能按照構建Cube時選擇的維度欄位分組統計,如果選擇指定維度欄位如deptno分組統計可以查詢成功
select deptno,sum(sal) from emp group by deptno;
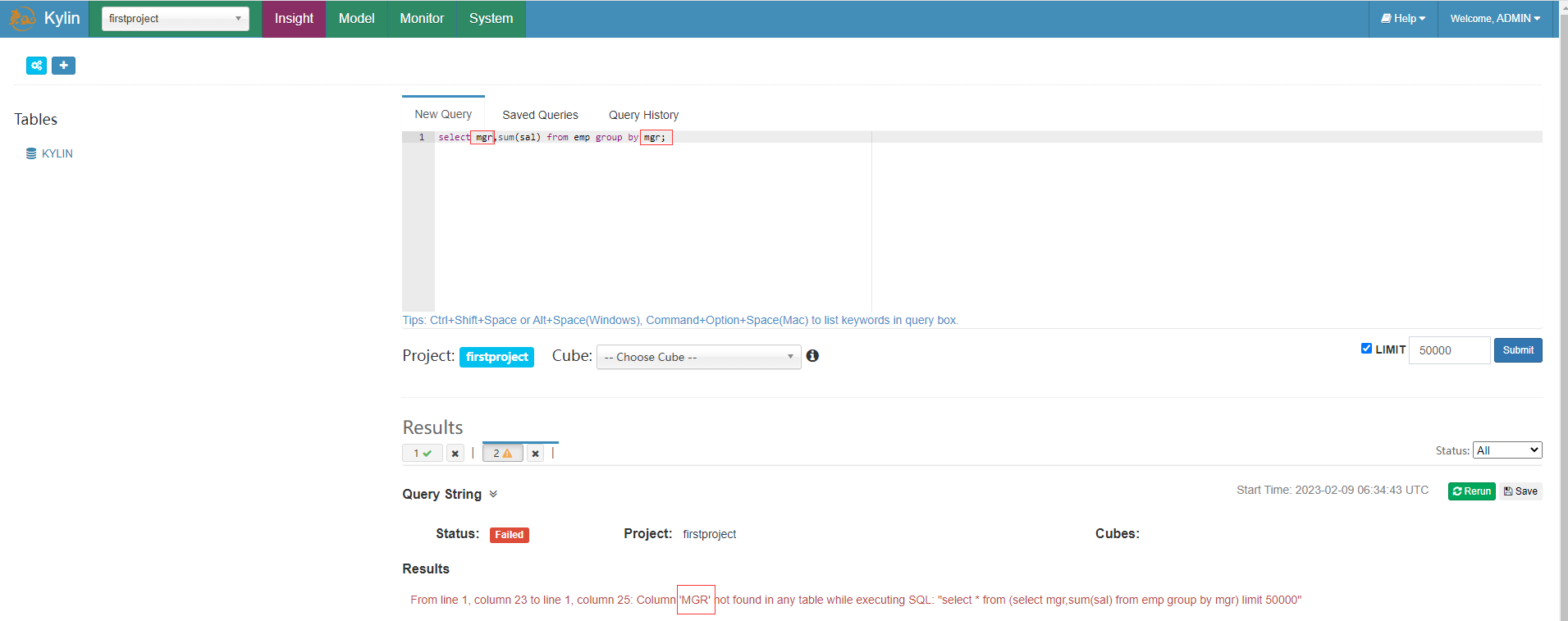
如果選擇不在前面選擇的mgr維度則查詢會報錯
select mgr,sum(sal) from emp group by mgr;
度量限制
Kylin只能統計構建 Cube 時選擇的度量值欄位,由於count在前面的度量設定裡因此可以查詢成功
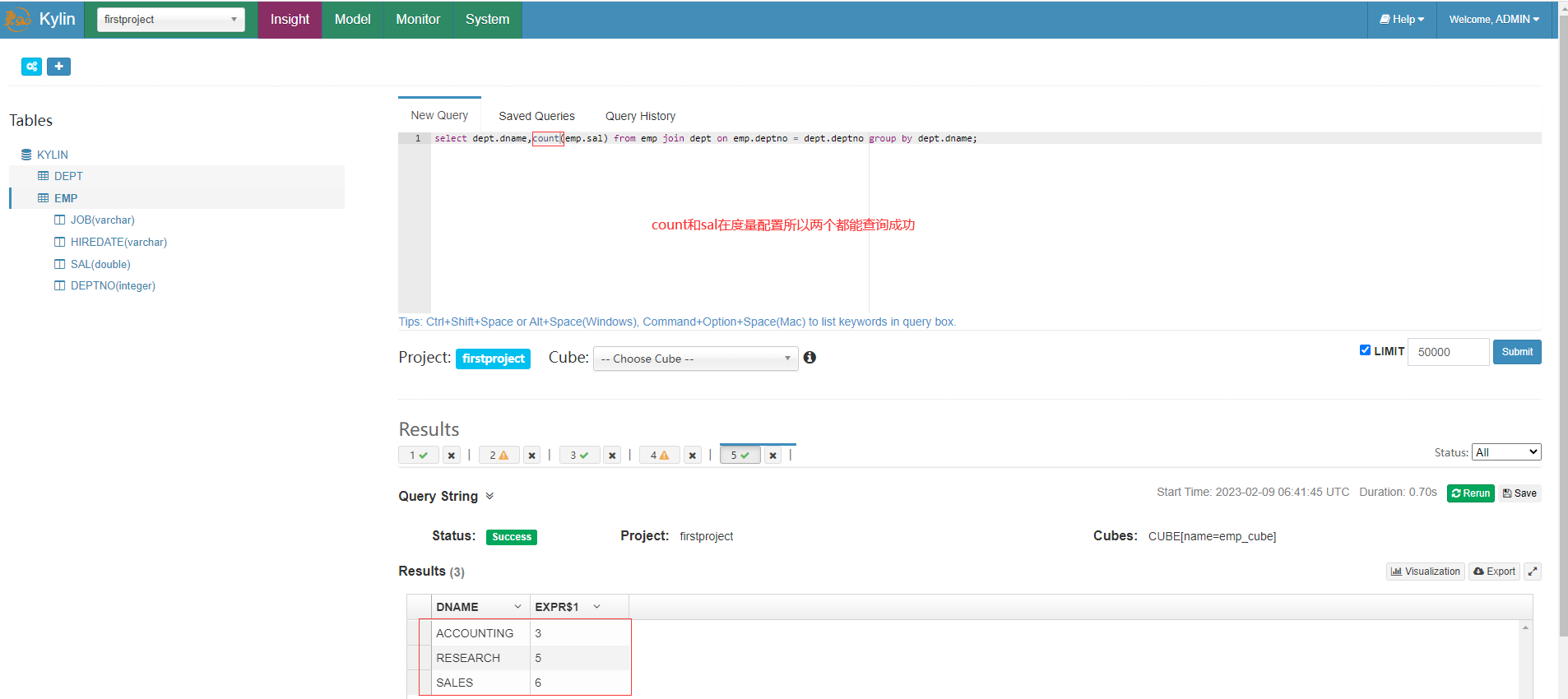
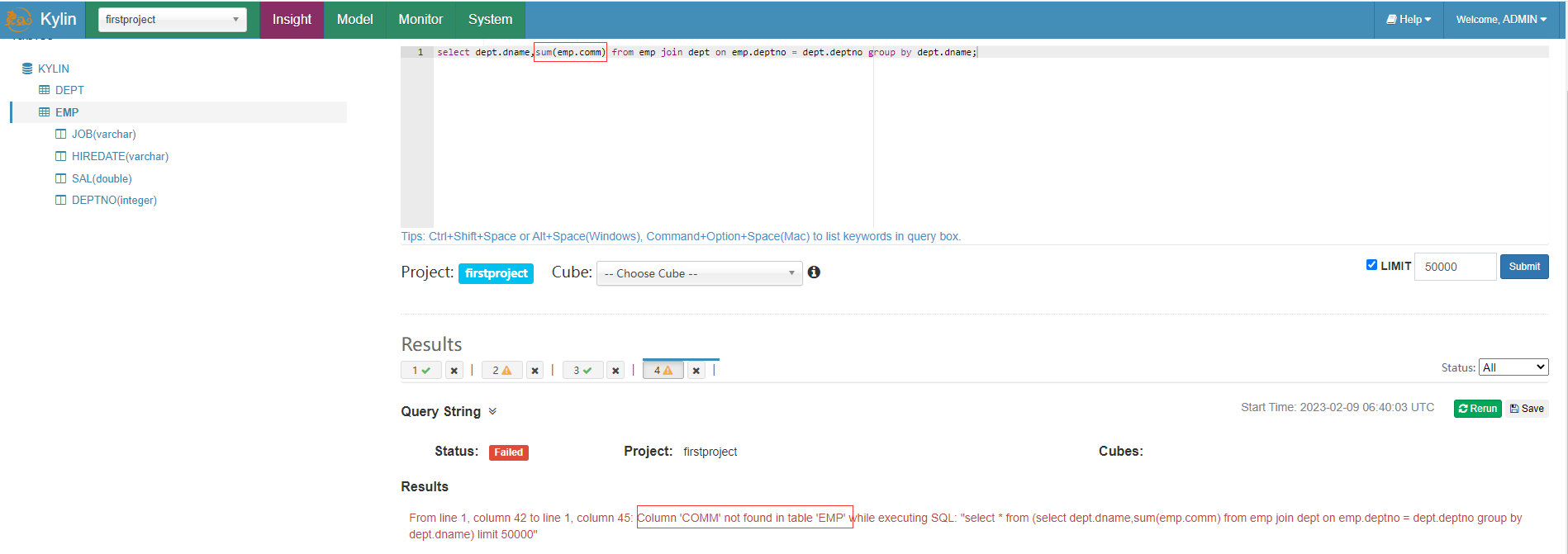
由於前面獎金comm欄位沒有放在度量裡,因此查詢報錯
select dept.dname,sum(emp.comm) from emp join dept on emp.deptno = dept.deptno group by dept.dname;
查詢引擎
Sparder
Sparder (SparderContext) 是由 Spark application 後端實現的新型分散式查詢引擎,它是作為一個 Long-running 的 Spark application 存在的。Sparder 會根據 kylin.query.spark-conf 開頭的設定項中設定的 Spark 引數來獲取 Yarn 資源,如果設定的資源引數過大,可能會影響構建任務甚至無法成功啟動 Sparder,如果 Sparder 沒有成功啟動,則所有查詢任務都會失敗,因此請在 Kylin 的 WebUI 中檢查 Sparder 狀態,不過預設情況下,用於查詢的 spark 引數會設定的比較小,在生產環境中,大家可以適當把這些引數調大一些,以提升查詢效能。
kylin.query.auto-sparder-context-enabled-enabled 引數用於控制是否在啟動 kylin 的同時啟動Sparder,預設值為 false,即預設情況下會在執行第一條 SQL 的時候才啟動 Sparder,因此 Kylin 的第一條 SQL 查詢速度一般比較慢,因為包含了 Sparder 任務的啟動時間。
檢視yarn可以看到有一個名稱為sparder_on_xxxx的yarn應用

HDFS儲存資訊
根目錄:/kylin/kylin_metadata
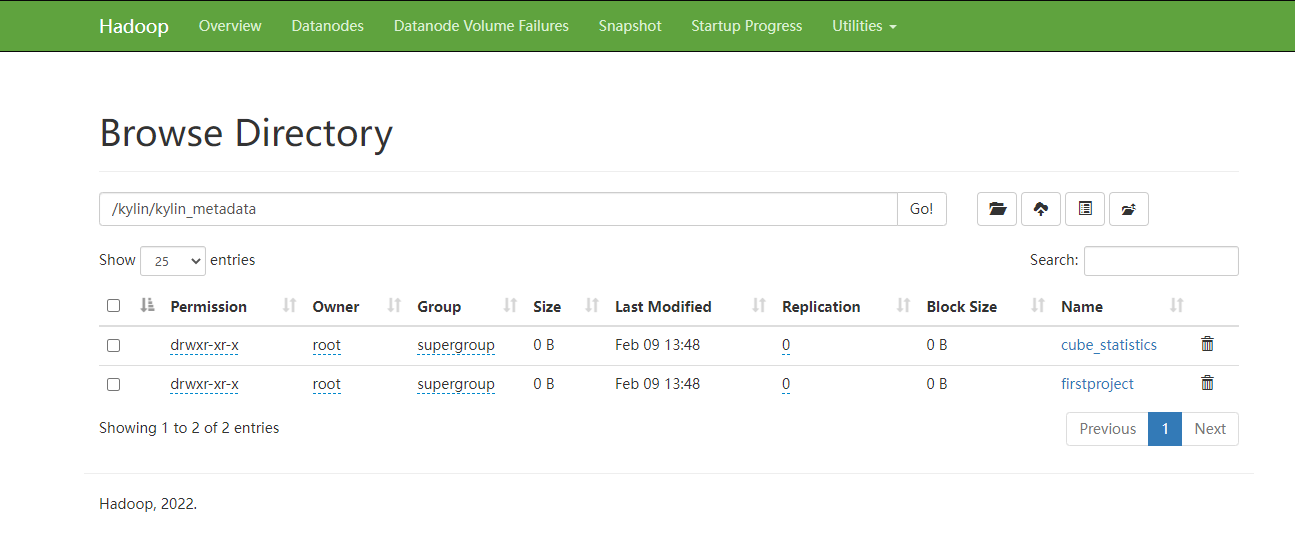
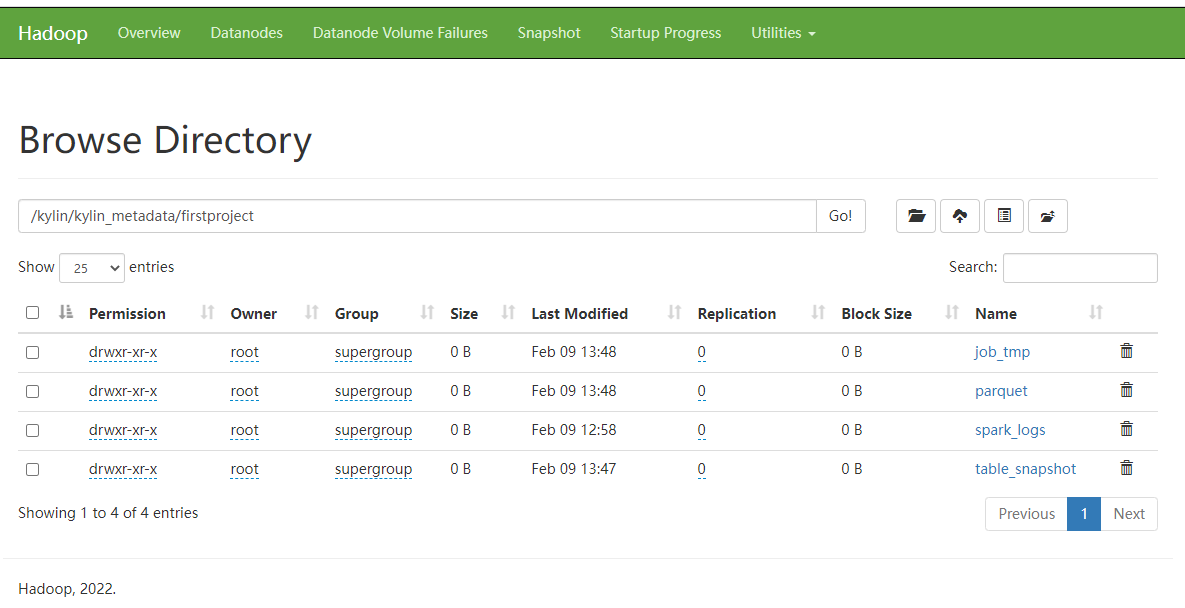
子目錄:
- 臨時檔案儲存目錄:/project_name/job_tmp
- cuboid 檔案儲存目錄: /project_name /parquet/cube_name/segment_name_XXX
- 維度錶快照儲存目錄:/project_name /table_snapshot
- Spark 執行紀錄檔目錄:/project_name/spark_logs
查詢引數
Kylin 查詢引數全部以 kylin.query.spark-conf 開頭,預設情況下,用於查詢的 spark 引數會設定的比較小,在生產環境中,大家可以適當把這些引數調大一些,以提升查詢效能。
####spark 執行模式####
#kylin.query.spark-conf.spark.master=yarn
####spark driver 核心數####
#kylin.query.spark-conf.spark.driver.cores=1
####spark driver 執行記憶體####
#kylin.query.spark-conf.spark.driver.memory=4G
####spark driver 執行堆外記憶體####
#kylin.query.spark-conf.spark.driver.memoryOverhead=1G
####spark executor 核心數####
#kylin.query.spark-conf.spark.executor.cores=1
####spark executor 個數####
#kylin.query.spark-conf.spark.executor.instances=1
####spark executor 執行記憶體####
#kylin.query.spark-conf.spark.executor.memory=4G
####spark executor 執行堆外記憶體####
#kylin.query.spark-conf.spark.executor.memoryOverhead=1G
查詢下壓設定
對於沒有cube能查到結果的,Kylin4.0版本支援這類查詢下壓到Spark SQL去查詢hive源資料
- 將conf/kylin.properties組態檔中的註釋放開
kylin.query.pushdown.runner-class-name=org.apache.kylin.query.pushdown.PushDownRunnerSparkImpl
- 頁面重新整理設定
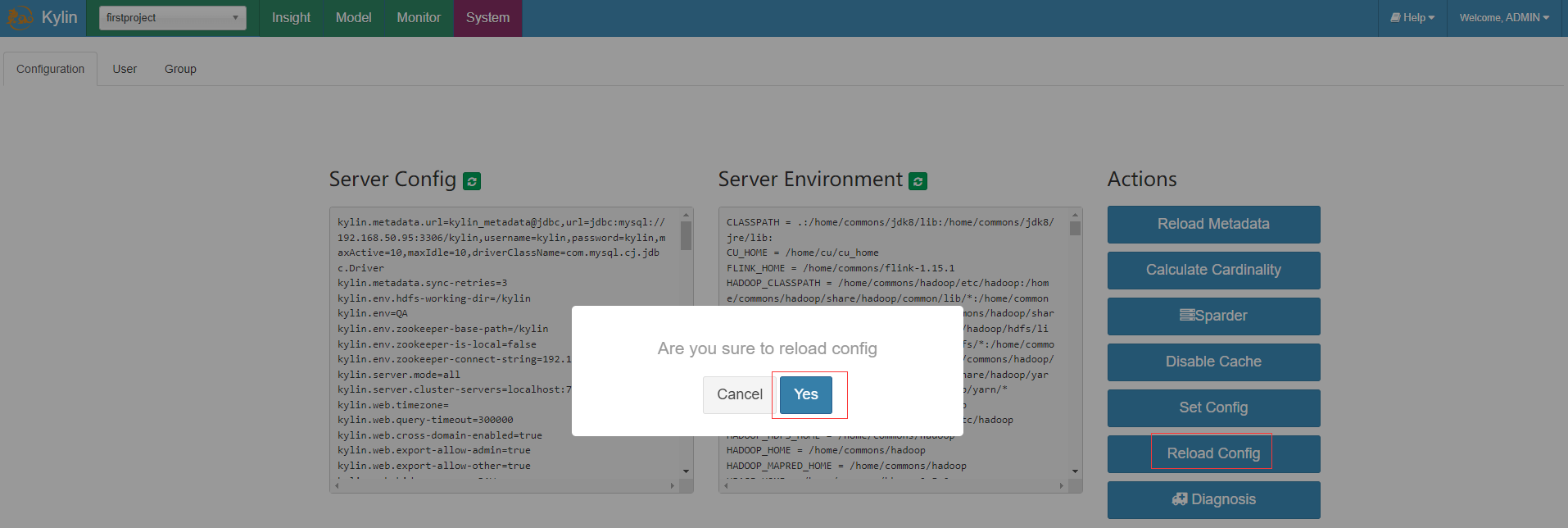
- 查詢頁面執行cube中沒有的維度而報錯的sql,可以看到這是已經將查詢下壓Spark去執行,結果也正確返回
select mgr,sum(sal) from emp group by mgr;
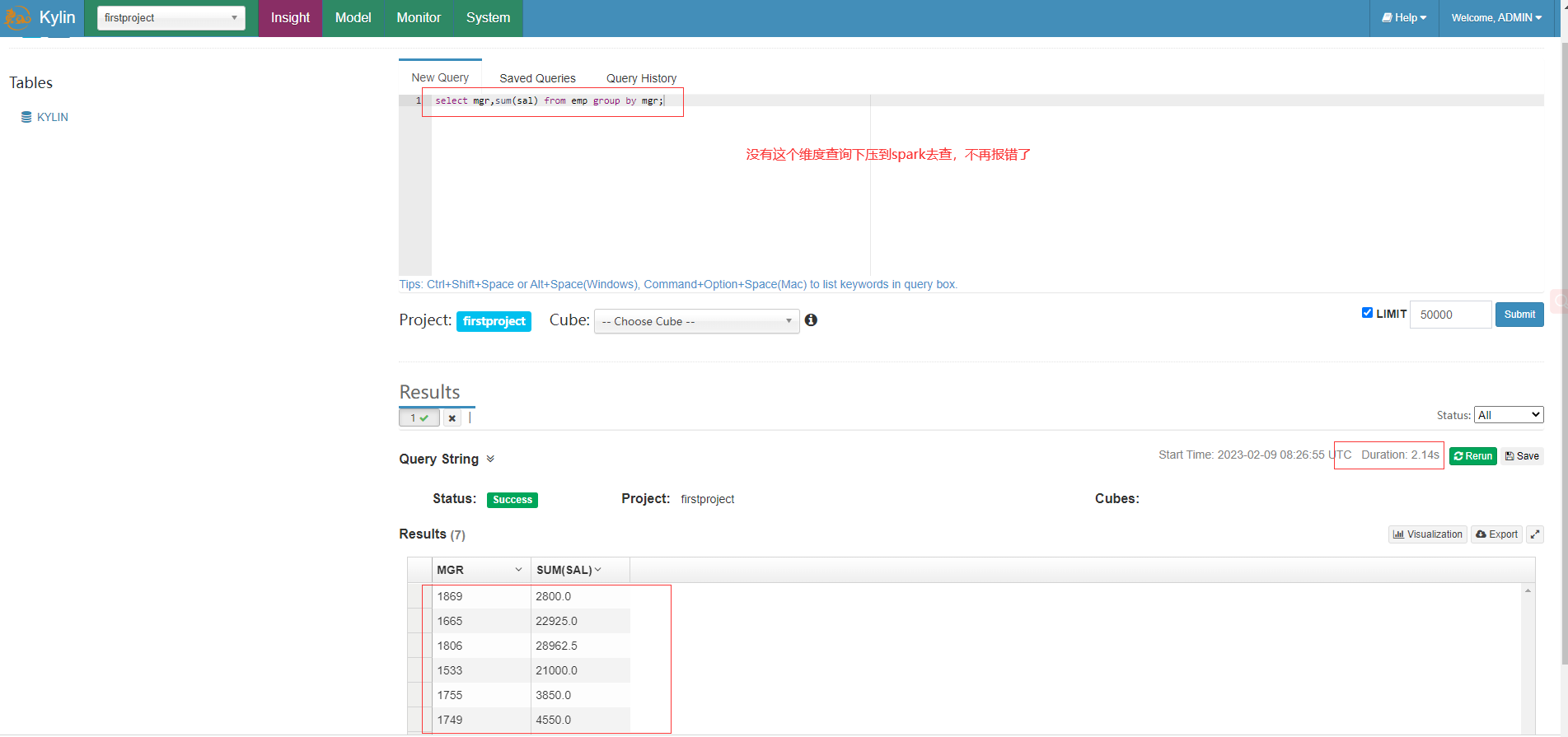
從spark WebUI也可以看到剛剛查詢下壓的Job和Stage的詳細資訊
Cube 構建優化
使用衍生維度(derived dimension)
衍生維度用於在有效維度內將維度表上的非主鍵維度排除掉,並使用維度表的主鍵(其實是事實表上相應的外來鍵)來替代它們。Kylin 會在底層記錄維度表主鍵與維度表其他維度之間的對映關係,以便在查詢時能夠動態地將維度表的主鍵「翻譯」成這些非主鍵維度,並進行實時聚合。

雖然衍生維度具有非常大的吸引力,但這也並不是說所有維度表上的維度都得變成衍生維度,如果從維度表主鍵到某個維度表維度所需要的聚合工作量非常大,則不建議使用衍生維度。
使用聚合組(Aggregation group)
聚合組(Aggregation Group)是一種強大的剪枝工具。聚合組假設一個 Cube 的所有維度均可以根據業務需求劃分成若干組(當然也可以是一個組),由於同一個組內的維度更可能同時被同一個查詢用到,因此會表現出更加緊密的內在關聯。每個分組的維度集合均是Cube 所有維度的一個子集,不同的分組各自擁有一套維度集合,它們可能與其他分組有相同的維度,也可能沒有相同的維度。每個分組各自獨立地根據自身的規則貢獻出一批需要被物化的 Cuboid,所有分組貢獻的 Cuboid 的並集就成為了當前 Cube 中所有需要物化的 Cuboid的集合。不同的分組有可能會貢獻出相同的 Cuboid,構建引擎會察覺到這點,並且保證每一 個 Cuboid 無論在多少個分組中出現,它都只會被物化一次。
對於每個分組內部的維度,使用者可以使用如下三種可選的方式定義,它們之間的關係,具體如下。
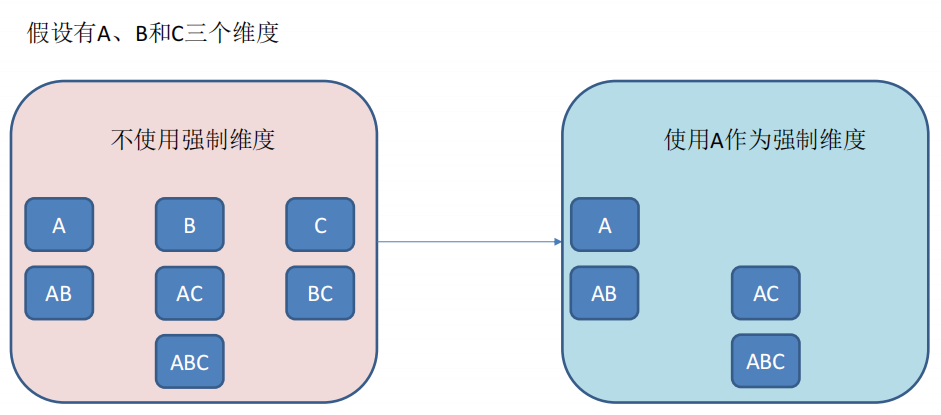
- 強制維度(Mandatory),如果一個維度被定義為強制維度,那麼這個分組產生的所有 Cuboid 中每一個 Cuboid 都會包含該維度。每個分組中都可以有 0 個、1 個或多個強制維度。如果根據這個分組的業務邏輯,則相關的查詢一定會在過濾條件或分組條件中,因此可以在該分組中把該維度設定為強制維度。(強制維度自己也不能單獨出現)
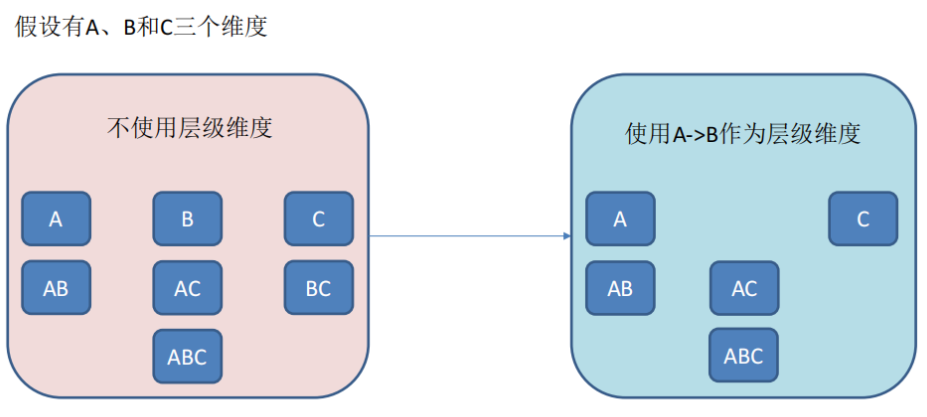
- 層級維度(Hierarchy),每個層級包含兩個或更多個維度。假設一個層級中包含 D1,D2…Dn 這 n 個維度,那麼在該分組產生的任何 Cuboid 中,這 n 個維度只會以(),(D1),(D1,D2)…(D1,D2…Dn)這 n+1 種形式中的一種出現。每個分組中可以有 0 個、1 個或多個層級,不同的層級之間不應當有共用的維度。如果根據這個分組的業務邏輯,則多個維度直接存在層級關係,因此可以在該分組中把這些維度設定為層級維度。
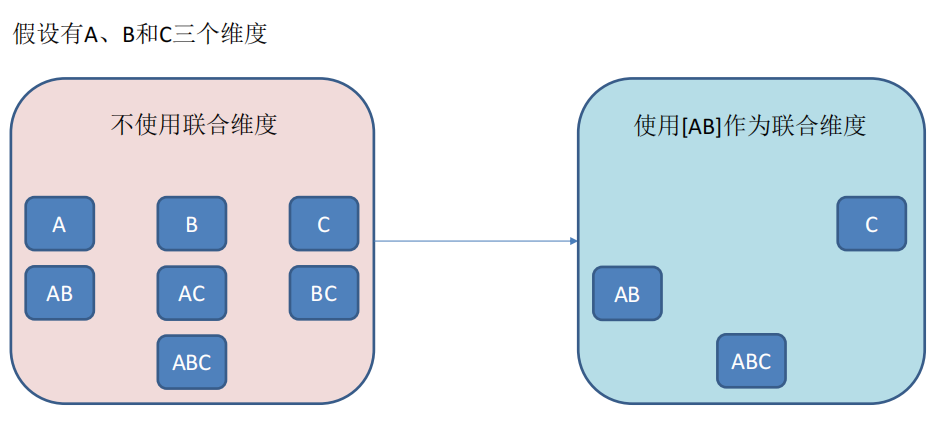
- 聯合維度(Joint),每個聯合中包含兩個或更多個維度,如果某些列形成一個聯合,那麼在該分組產生的任何 Cuboid 中,這些聯合維度要麼一起出現,要麼都不出現。每個分組中可以有 0 個或多個聯合,但是不同的聯合之間不應當有共用的維度(否則它們可以合併成一個聯合)。如果根據這個分組的業務邏輯,多個維度在查詢中總是同時出現,則可以在該分組中把這些維度設定為聯合維度。
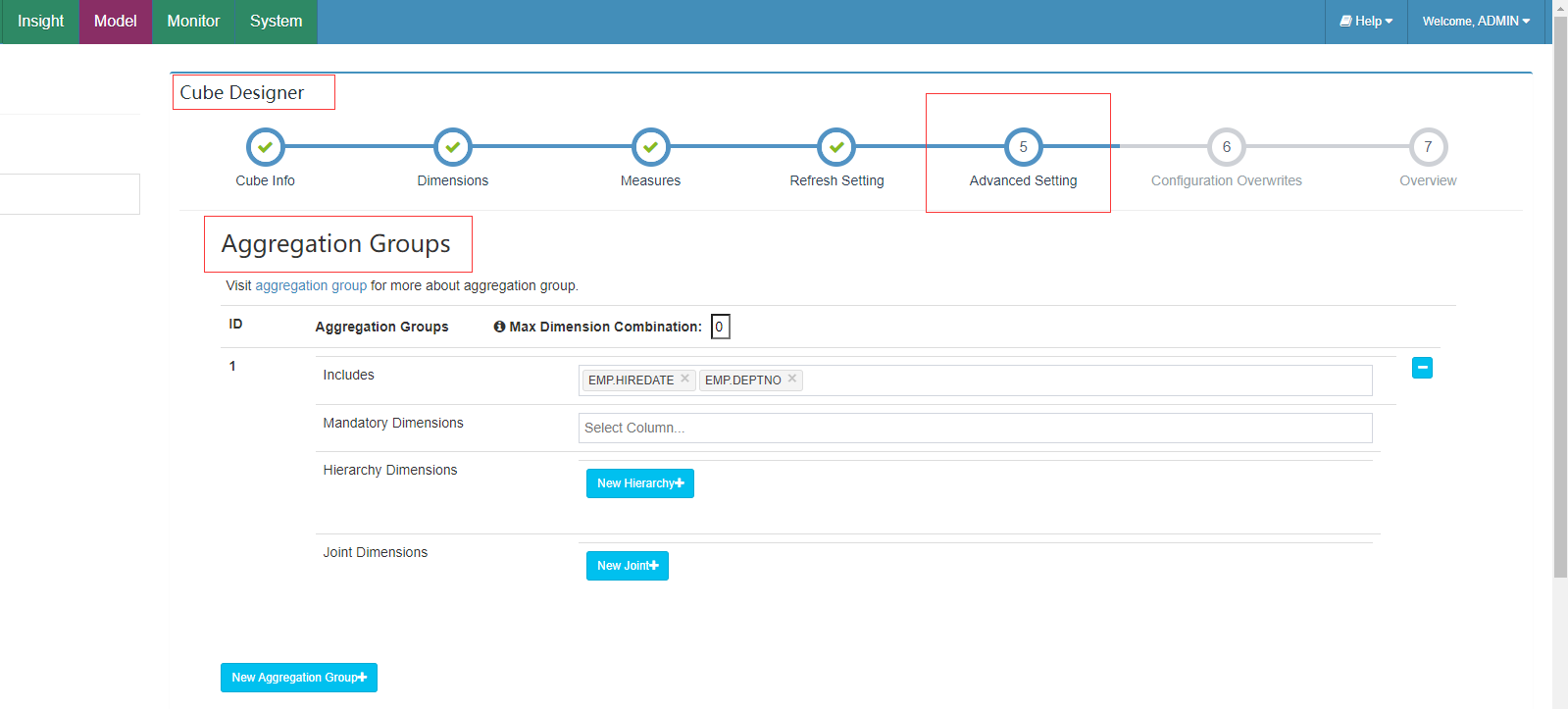
上述的聚合組可以在新建cube中Cube Designer 的 Advanced Setting 中的 Aggregation Groups 區域設定。
- 聚合組的設計非常靈活,甚至可以用來描述一些極端的設計。假設我們的業務需求非常單一,只需要某些特定的 Cuboid,那麼可以建立多個聚合組,每個聚合組代表一個 Cuboid。
- 具體的方法是在聚合組中先包含某個 Cuboid 所需的所有維度,然後把這些維度都設定為強制維度。這樣當前的聚合組就只能產生我們想要的那一個 Cuboid 了。
- 再比如,有的時候我們的 Cube 中有一些基數非常大的維度,如果不做特殊處理,它就會和其他的維度進行各種組合,從而產生一大堆包含它的 Cuboid。包含高基數維度的 Cuboid在行數和體積上往往非常龐大,這會導致整個 Cube 的膨脹率變大。如果根據業務需求知道這個高基數的維度只會與若干個維度(而不是所有維度)同時被查詢到,那麼就可以通過聚合組對這個高基數維度做一定的「隔離」。我們把這個高基數的維度放入一個單獨的聚合組,
再把所有可能會與這個高基數維度一起被查詢到的其他維度也放進來。這樣,這個高基數的維度就被「隔離」在一個聚合組中了,所有不會與它一起被查詢到的維度都沒有和它一起出現在任何一個分組中,因此也就不會有多餘的 Cuboid 產生。這點也大大減少了包含該高基數維度的 Cuboid 的數量,可以有效地控制 Cube 的膨脹率。
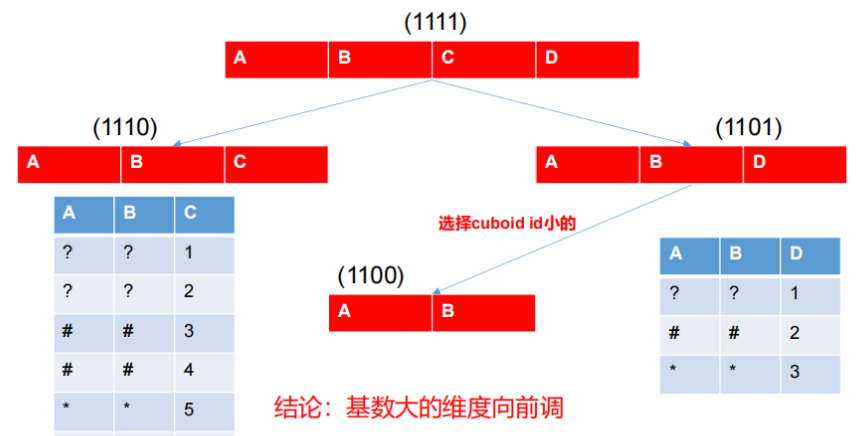
Row Key 優化
Kylin 會把所有的維度按照順序組合成一個完整的 Rowkey,並且按照這個 Rowkey 升序排列 Cuboid 中所有的行。維度的位置(Rowkey)對查詢效能有影響,可以調整順序。將過濾維放在非過濾維之前,將高基數維放在低基數維之前。
-
設計良好的 Rowkey 將更有效地完成資料的查詢過濾和定位,減少 IO 次數,提高查詢速度,維度在 rowkey 中的次序,對查詢效能有顯著的影響。
Row key 的設計原則如下:- 被用作過濾的維度放在前邊。

- 基數大的維度放在基數小的維度前邊。
RestAPI使用
身份認證
官方RestAPI使用 https://kylin.apache.org/docs/howto/howto_use_restapi.html
進入Access and Authentication API 存取和身份驗證API,標頭檔案中需要使用基本認證編碼的授權資料,例如可以使用下面的python指令碼生成
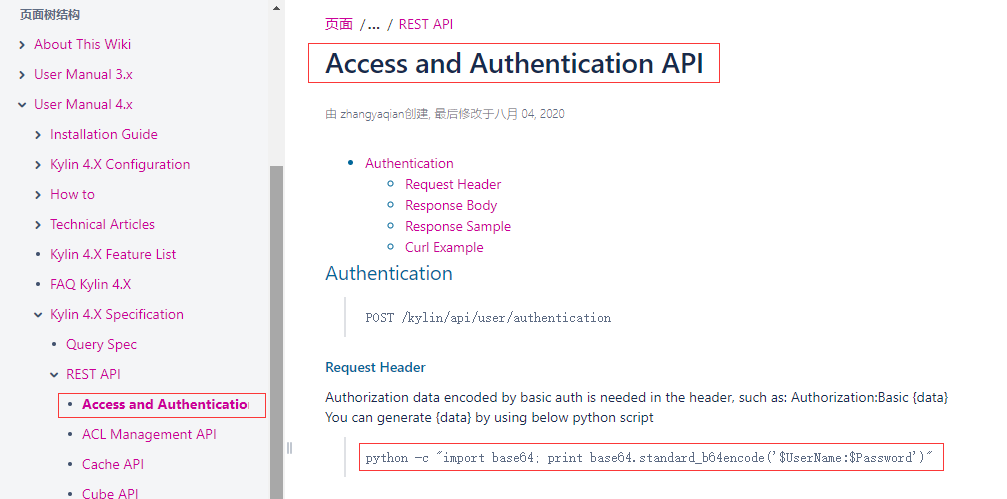
python -c "import base64; print base64.standard_b64encode('ADMIN:KYLIN')"

查詢
進入Query API後找到Curl Example的範例程式碼
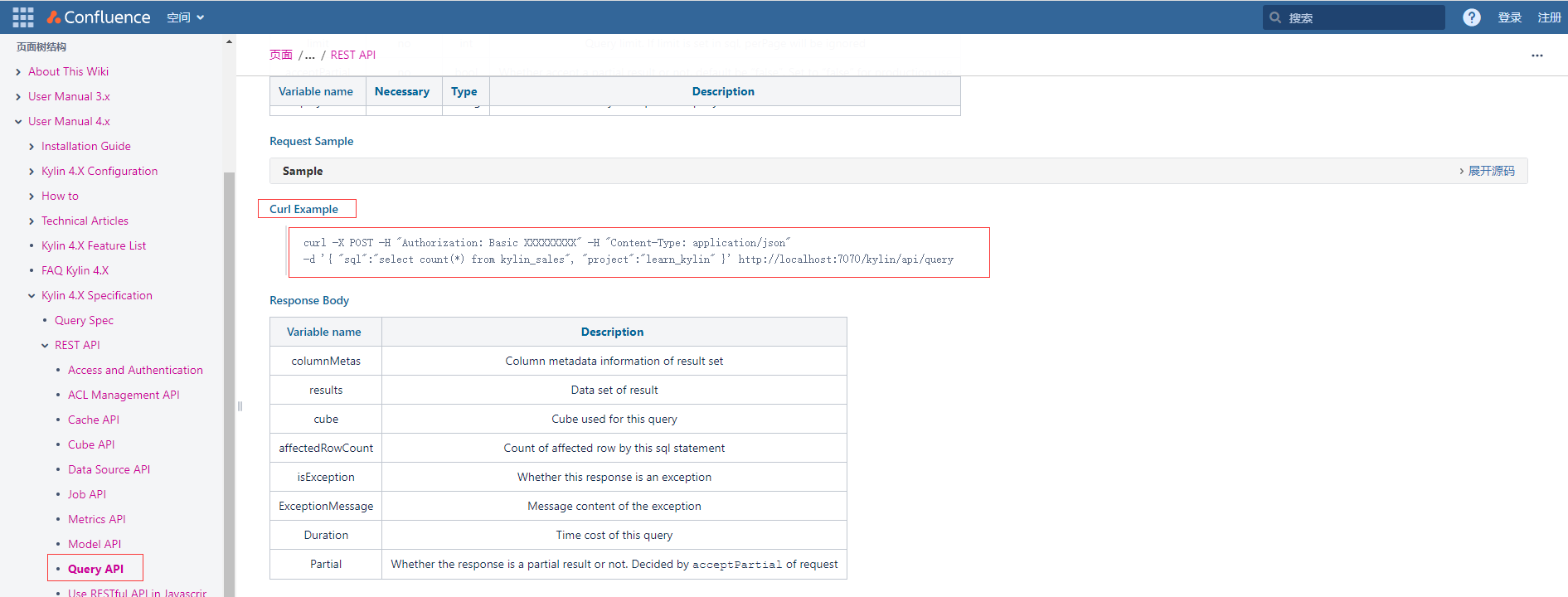
複製上面指令碼得到的授權碼並修改成如下:
curl -X POST -H "Authorization: Basic QURNSU46S1lMSU4=" -H "Content-Type: application/json" -d '{ "sql":"select dname,sum(sal) from emp e join dept d on e.deptno = d.deptno group by dname;", "project":"firstproject" }' http://hadoop1:7070/kylin/api/query
可以看到返回成功結果資料

cube定時構建
通過Cube API中找到Build Cube,檢視地址,路徑變數和請求體的引數說明
[外連圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-lukQbqYf-1676045281339)(image-20230209154440123.png)]
curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type: application/json' -d '{"startTime":'1423526400000', "endTime":'1423612800000', "buildType":"BUILD"}' http://hadoop1:7070/kylin/api/cubes/emp_cube/build
如果需要每日構建則可以通過Kylin 提供了 Restful API,將構建 cube 的命令寫到指令碼中,將指令碼交給DolphinScheduler、Azkaban之類的排程工具,以實現定時排程的功能。
整合
整合JDBC範例
新增kylin的依賴
<dependency>
<groupId>org.apache.kylin</groupId>
<artifactId>kylin-jdbc</artifactId>
<version>4.0.3</version>
</dependency>
建立KylinJdbcDemo.java測試類
import org.apache.kylin.jdbc.Driver;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Properties;
public class KylinJdbcDemo {
public static void main(String[] args) throws Exception{
Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
Properties info = new Properties();
info.put("user", "ADMIN");
info.put("password", "KYLIN");
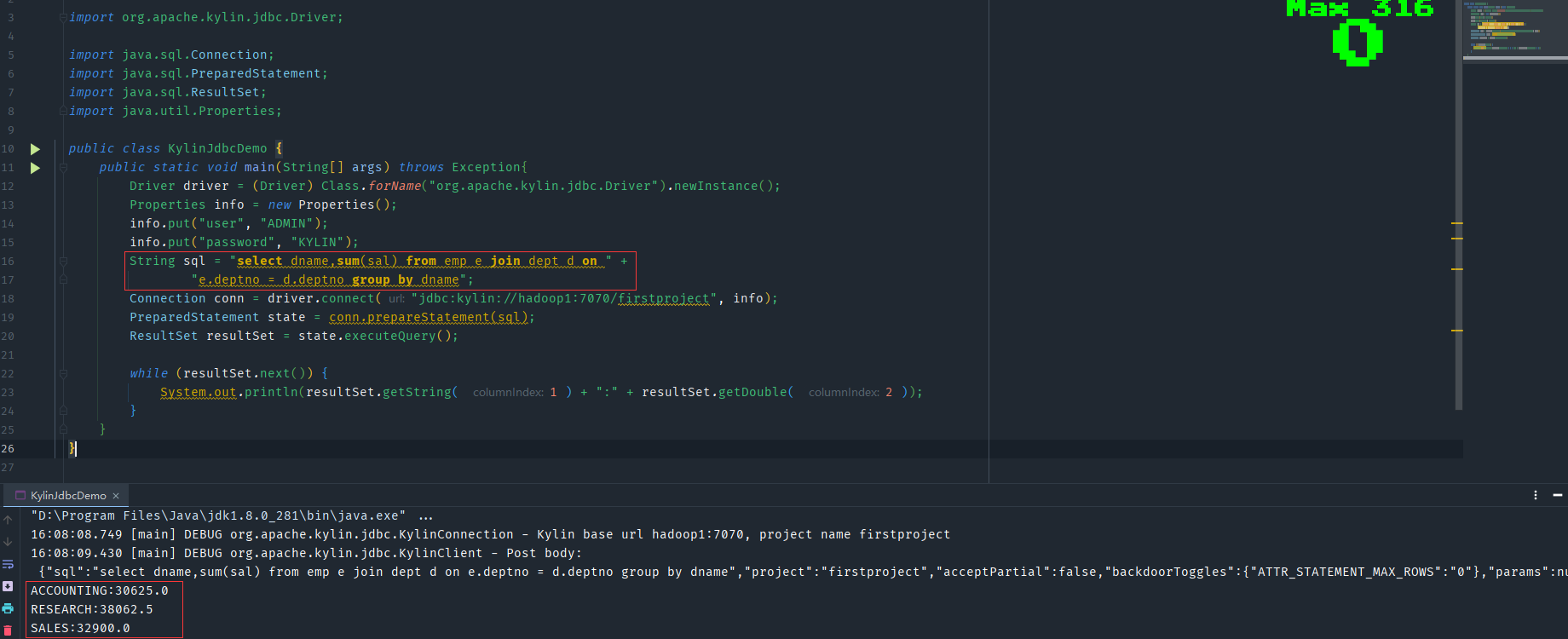
String sql = "select dname,sum(sal) from emp e join dept d on " +
"e.deptno = d.deptno group by dname";
Connection conn = driver.connect("jdbc:kylin://hadoop1:7070/firstproject", info);
PreparedStatement state = conn.prepareStatement(sql);
ResultSet resultSet = state.executeQuery();
while (resultSet.next()) {
System.out.println(resultSet.getString( 1 ) + ":" + resultSet.getDouble( 2 ));
}
}
}
執行檢視結果是正確的
- 本人部落格網站IT小神 www.itxiaoshen.com