react無效渲染優化--工具篇

壹 ❀ 引
本文屬於我在公司的一篇技術分享文章,它在我之前 React效能優化,六個小技巧教你減少元件無效渲染一文的基礎上進行了拓展,增加了工具篇以及部分更詳細的解釋,所以內容上會存在部分重複,以下是分享的原文。
在過去一段時間,好像每次程式碼走讀大家都對於useMemo、useCallback以及memo的使用都會存在部分疑惑,比較巧的是這幾個API都與效能優化相掛鉤;可以想象效能優化這一塊一定會屬於未來前端團隊挑戰之一,所以掌握部分優化技巧是很有必要的。那麼這一次我想聚焦在react元件渲染優化上,為大家分享無效渲染常見排查手段以及避坑經驗,通過本文大家將收穫如下幾個知識點:
- 造成無效渲染的主要原因
- 五種減少無效渲染的小技巧
- 三種無效渲染排查手段
- 聊聊
useMemo、memo、useCallback,什麼時候該用什麼時候不該用? useSelector每次都會執行嗎?聊聊store更新機制- 常見快取策略以及快取利弊(快取都有代價)
- 如何在專案中發現無效渲染嚴重的元件
貳 ❀ 理解無效渲染
其實在之前我一直在強調我們需要減少的是無效渲染,而不是渲染;對於一個元件而言,狀態如果發生了改變,元件自身再次渲染這非常合理,但如何元件狀態或資料未改變,那此刻的渲染就是無效渲染。
迴歸到無效渲染,我將無效渲染的原因分為兩類:
- 元件狀態設計藕合,元件之間相互響應
- 元件
prop不穩定
關於第一點不難理解,比如現在需要開發一個相對複雜的功能,這個功能包含A B C三個子功能,正常來說我應該為三個功能定義三個元件,以及對應的三個狀態,但假設有同學就是讓這三個元件共用了一個狀態,那此刻不管你動了誰,另外兩個元件都得跟著渲染。
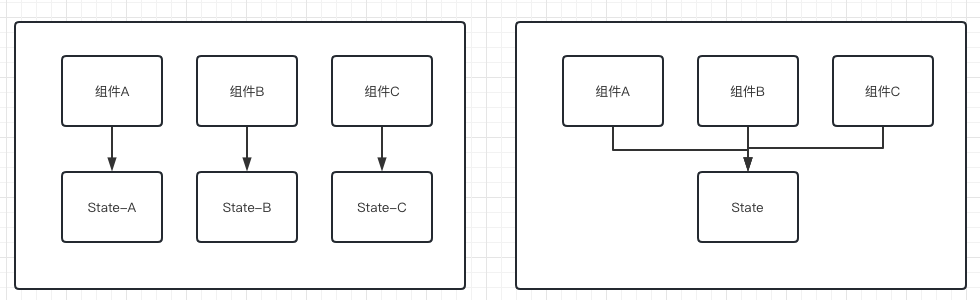
這類問題其實不僅存在state定義上,對於store的介面封裝同樣會有相同的問題,比如公司專案裡存在如下類似的程式碼:

我之前疑惑,為什麼這裡不是直接一句useSelector取出user物件,然後直接解構出五個屬性,而不是要寫五遍useSelector一個一個的取。在溝通後瞭解到,這麼做就是為了避免其它地方的元件改動了user裡的某個屬性,而這裡直接取user的話因為參照一定會變從而導致重新渲染,所以單點取的好處就是你外面改了這裡五個屬性之外的其它屬性,我這裡因為沒用到,所以就不會重新渲染。
回到user的資料設計上,如果user的資料結構包含萬物,它能被使用的元件越多,那麼它被影響的可能性自然就越大,所以儘可能保證資料設計的簡潔以及合理性很有必要。
造成無效渲染的第二大原因就是參照資料型別參照不穩定所導致,舉個最簡單的例子,元件A渲染前後都接受了一個空陣列,且兩次陣列的參照都不同,這對於元件而言因為參照不同所以是新資料自然得再次渲染,但對於研發而言,我們心裡其實是知道這是無意義的,所以如何保證其參照的穩定性就是解決無效渲染的核心了。
說到這裡有同學可能就會想,那是不是元件內只要產生新參照資料的行為就不對呢?其實並不是,當資料本身就應該更新時,它在這一刻產生一個全新的參照很合情合理,不然我們專案裡什麼filter、map之類的豈不是都用不了了。你也可以想想react自身的setState更新,我們更新state時本身也是得傳入一個全新的物件而不是直接修改,所以要更新時產生新物件非常合理。
const App = () => {
const [state, setState] = useState({ name: "聽風", age: 29 });
const handleClick = () => {
// 錯誤做法,直接修改 state, 不會更新
// state.name = '行星飛行';
// 正確做法就得重新賦予一個全新的物件,不然 state 不會更新
setState({ ...state, name: '行星飛行' });
}
return (
<div>
<div>{state.name}</div>
<div>{state.age}</div>
<button onClick={handleClick}>change name</button>
</div>
)
};
叄 ❀ 如何減少無效渲染
叄 ❀ 合理使用memo
我們知道class元件的PureComponent以及函陣列件的memo都具有淺比較的作用,所謂淺比較就是直接比較前後兩份資料是否相等,比如:
const a = [];
const b = a;
// 因為 a b 參照和值都相同,所以相等
a === b; // true
const c = [];
// 雖然 c 也是空陣列,但是參照不同所以不相等
a === c; // false
那麼加memo到底解決了什麼問題?我們假設元件前後都接收了一個空陣列,且它們參照也相同,那麼此時如果我們元件套用了memo,那麼元件就不會因為這個完全相同的資料重複渲染。這裡我寫了一個線上的memo例子方便大家理解效果,大家可以點選按鈕檢視控制檯,直接對比加與不加memo的差異。
在這個例子中,我在元件外層定義了一份參照始終相同的資料user,之後通過點選按鈕故意改變父元件P的狀態讓其渲染,以此帶動子元件C1 C2渲染,可見加了memo的C2除了初次渲染之後並不會跟隨父元件重複渲染,這就是memo的作用。
當然,假設我們的user每次都是重新建立的新物件,那我們加了memo也沒任何作用,畢竟參照不同淺比較判斷為false,還是會重複渲染。
另外,請合理使用memo,並不是所有場景都需要這麼做,這會增加記憶體開銷,假設你的元件的資料流足夠簡單甚至沒有props,你完全沒必要在元件外層套一層memo。
那麼接下來的建議,也都是基於子元件加了memo展開的,不然你即便保證父元件每一個資料參照都不變,父元件渲染時子元件還是一樣會渲染(預設行為)。
叄 ❀ 貳 不穩定的預設值
正常來說,比如子元件的userList屬性規定型別是陣列,而在父元件加工資料時提供預設值是非常好的習慣,大家可能經常看到這樣的寫法:
const App = (props) => {
// 假定userList是介面提供,介面沒回來取不到
const userList = props.userList || [];
return (
<Child userList={userList} />
)
};
那這就造成一個問題,當介面沒響應完成,只要App發生渲染,此刻userList都會不斷被重新賦值空陣列,對於Child而言,因為每次參照不同,自然Child也都要跟著渲染,所以正確的做法是將預設值提到元件外:
const emptyArr = [];
const App = (props) => {
const userList = props.userList || emptyArr;
return (
<Child userList={userList} />
)
};
叄 ❀ 叄 props直接傳遞新物件
這一種也是最直接也最容易看出來的一種不規範寫法,一般存在於對於react不太瞭解的新人或者一些老舊程式碼中,比如:
const App = () => {
return (
// 這裡每次都會傳遞一個新的空陣列過去,導致Child每次都會渲染,加了 memo 都救不了
<Child userList={[]} />
)
};
當然,它也可能不是一個空陣列,但註定每次都是一個全新參照的資料:
const App = (props) => {
return (
<Child style={{color : red}} />
)
};
再或者使用了產生新陣列的方法,比如:
const App = (props) => {
const getUserList = ()=>{
return props.userlist.map((e) => e.name)
}
return (
<Child userList={getUserList()} />
)
};
叄 ❀ 肆 合理使用useMemo與useCallback
我們知道useMemo與useCallback都能起到快取的作用,比如下面這個例子:
// 只要 App 自身重複渲染,此時 handleClick 與 user 都會重新建立,導致參照不同,所以 C 即便加了 memo 還是會重複渲染
const App = (props)=> {
const handleClick = () => {};
const fn = () => {}
const list = [];
const user = userList.filter();
return <C onClick={handleClick} list={list} user={user} />
}
只要元件App自身重複渲染,元件內的這些屬性方法本質上會被重新建立一遍,這就導致子元件C即便新增memo也無濟於事,所以對於函陣列件而言,一般要往下傳遞的資料我們可以通過useMemo與useCallback包裹,保證其參照穩定性。當然,如果一份資料只是App元件自己用,那就沒必要特意包裹了:
// 常數提到外層,保證參照唯一
const list = [];
const App = ()=> {
// 使用 useCallback 快取函數
const handleClick = useCallback(() => {});
// 只是自己使用,不作為props傳遞時,沒必要使用 useCallback 巢狀
const handleOther = () => {}
// 使用 useMemo 快取結果
const user = useMemo(()=>{
return userList.filter();
},[userList])
return <C onClick={handleClick} list={list} user={user} />
}
比如上述程式碼中的handleOther就是元件自身用,它不作為props往下層傳遞,那就根本沒必要給這個函數做快取。
另外問大家一個問題,不管是 useCallback 還是 ahooks 的 useMemoizedFn ,假設有下面這段程式碼:
const add = (a,b) => a + b;
const add_ = useMemoizedFn(add);
// 或者
// const add_ = useCallback(add, []);
add_(1,2);
add_(1,2);
請問第二次執行 add_ 時, a + b 這段邏輯會走嗎?
會,因為useCallback 快取的是函數本身,它不會幫你快取函數的結果,它的作用就是幫你保證函數參照不變,僅此而已。
總結來說,useMemo、useCallback這些與memo一定一定是配合使用的,如果下層元件加了memo,那麼你上層元件就應該儘可能保證作為props資料參照的穩定性;如果上層元件加了useCallback,那麼你的子元件就一定得配合的加memo,不然函數快取啥的其實都白加了。
叄 ❀ 伍 更穩定的useSelector
我們可以使用useSelector監聽全域性store的變化並從中取出我們想要的資料,而相同的資料獲取如果是在class元件中則應該寫在mapStateToProps中,但不管哪種寫法,當我們從state中獲取資料後就應該注意保持資料的穩定性,來看個例子:
const userList = useSelector((state) => {
const users = state.userList;
return users.filter((user) => user.age > 18);
});
在上述例子中,我們從state中獲取了userList,之後又進行了資料加工過濾出年齡大於18的使用者,這個寫法看似沒什麼問題,但事實上全域性state的狀態並沒有我們的想的那麼穩定,所以useSelector執行的次數要比你想的要多,此時只要useSelector執行一次,我們都會從state中獲取資料,並通過filter加工成一個全新的陣列。
如何改善呢?其實很簡單,將加工的行為提到外部即可,比如:
const users = useSelector((state) => {
return state.userList;
});
const userList = useMemo(() => {
return users.filter(user => user.age > 18);
}, [users])
PS:每次store變化,每一個useSelector都會執行嗎?
問大家一個問題,每次store變化時,是不是所有生命週期內元件的useSelector都會執行一遍?如果執行那像上述程式碼返回的state.userList是不是每次都是一個全新的物件?那useMemo會不會每次都執行,導致userList每次都是全新的陣列嗎?其實並不是。
我們可以將全域性store理解成一棵大樹,不同元件的資料都是這棵樹的樹枝,請求也好更新也好,一定只是更新這棵樹的不同樹枝,這棵樹從來就沒變過(store參照不變)。打個比方,假設A元件更新了樹枝a(a參照變了),B元件依賴的是樹枝b,那麼A元件的更新會導致B元件重複渲染嗎?其實不會,這個過程可以簡化為如下程式碼(如果你能不假思索的回答正確,那說明你對於store更新以及參照關係很清晰了):
// 初始化store,這是一棵大樹
const store = {
o1: {// 樹枝o1
num: 1,
},
o2: {// 樹枝o2
num: 2,
},
};
// 儲存第一份資料
const a = store.o1;
const b = store.o2;
// 假定後端返回新資料,區域性更新store中的樹枝 o1
store.o1 = {
num: 3,
};
// 再次取值
const a_ = store.o1;
const b_ = store.o2;
// 此刻這兩個相等嗎?
console.log(a === a_);
console.log(b === b_);
當B元件通過useSelector取出參照沒變化的樹枝b時,因為就沒變化,它不會無效渲染。
對於redux而言,我們可以將整個react app的store理解成一顆巨大的樹,而樹有很多分支的樹根,每一枝樹根都可以理解成某個元件所依賴的state,那麼請問假設A元件的樹根被更新了,它會對store的其它樹根的參照造成影響嗎?此時樹還是這顆樹啊,而那些沒變的樹根依舊是之前的樹根。
所以回到上文的程式碼,假設state中關於state.userList就沒有變化,那麼前後不管取多少次,因為參照相同,useMemo除了初始化會執行一次之外,之後都不會重新執行,這就能讓userList徹底穩定下來。
而假設我們因為成員介面讓state.userList進行了更新,正常來說應該在reducer中重新生成一個新陣列再賦予給store,那麼在下次useSelector執行時,我們也能拿到全新參照的users,而監聽users的useMemo就能按照正確的預期再度更新了。
肆 ❀ 聊聊什麼時候該用useMemo
好像程式碼走讀大家對於使用useMemo都存在部分爭議,其實理解這個問題很簡單,useMemo到底是用來幹嘛的?它的本意是對特別複雜的邏輯的結果進行快取,比如一段程式碼需要跑很久,有效能損耗,我們通過deps監聽變化再決定useMemo的回撥是否需要再次執行。因為快取所以值沒變,因為值不變所以參照不變,因為參照不變所以減少了無效渲染。
那麼什麼時候推薦用,什麼時候不推薦用:
- 一段程式碼的邏輯比較複雜,我不希望每次都執行,所以需要快取,這種一定要用。
- 一段程式碼可能不是很複雜,但是返回的值是參照型別,我想保證其參照不變,這種可以用。
- 一段程式碼本身簡單,返回值是基本型別,這種完全沒必要用。
deps因不可抗拒力無法穩定,此時useMemo每次都會執行,這種加了也沒太大意義。
為什麼說第三種完全沒必要用,首先基本型別不存在參照變化,值變了就是變了,那就應該渲染;值沒變元件自身也不會渲染,外加上邏輯又特別簡單,這種就完全沒快取的必要,可以說完全是負優化,比如這種:
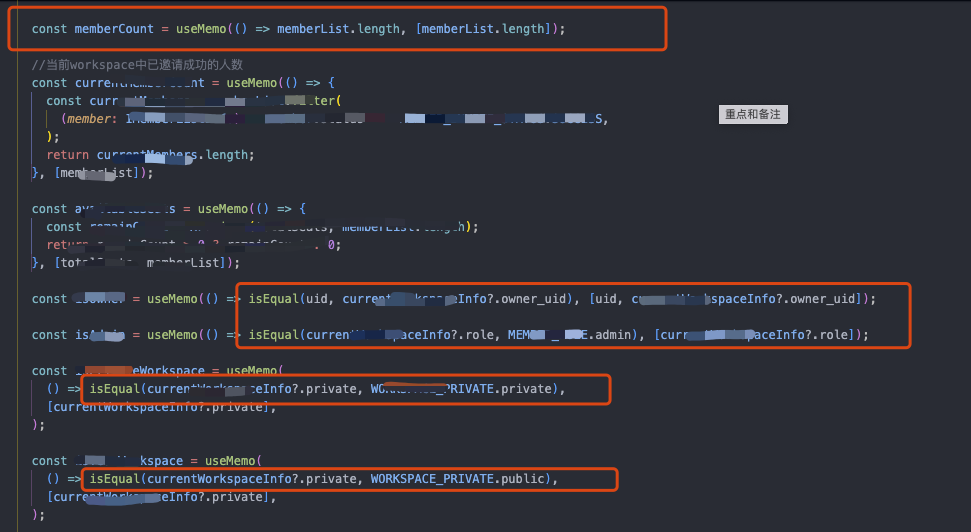
大家要注意,快取不是零代價,useMemo、useCallback與memo的執行都會做一次淺比較,也就是它會拿前後deps監聽的資料一一做===的對比,如果參照變了或者值變了它就會執行,所以對比也需要時間啊,然後你還浪費記憶體,得不償失。
關於第四點,其實我們加了useMemo是有義務在測試階段自測其穩定性的,如果你監聽的deps完全就是一個無法穩定的資料,此刻你要麼想辦法將上層資料先穩定下來,要麼就先別加useMemo,不然做的都是無效功。(確實會存在無法穩定的資料)
伍 ❀ 三種無效渲染排查手段
聊完了常見的可以避免無效渲染的寫法,有同學可能就要說了,從頭開始寫我可以注意,那假設現在要我優化一個已經寫好的無效渲染比較嚴重的元件,那我怎麼下手呢?單看程式碼我也不知道它參照是否穩定,我們來科普三種方式。
伍 ❀ 壹 why-did-you-render
why-did-you-render是一個專門用來幫你檢查無效渲染的庫,安裝和使用非常簡單,這裡簡單說下:
首先專案安裝why-did-you-render:
npm install @welldone-software/why-did-you-render --save-dev
在你的應用根目錄,比如app.tsx頂部引入設定:
import whyDidYouRender from '@welldone-software/why-did-you-render';
// 一般只在開發環境啟用
if (process.env.NODE_ENV === 'development') {
whyDidYouRender(React);
}
之後找到你想監聽的元件,比如我想監聽SidebarMenu元件,那麼在檔案底部新增如下程式碼:
SidebarMenu.whyDidYouRender = true;
之後重新整理頁面,如果該元件有無效渲染,那麼就會有對應的理由,比如:
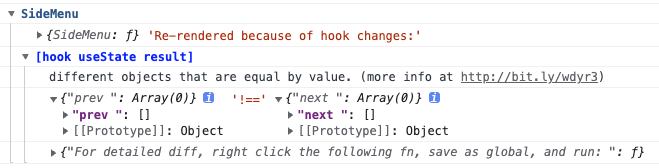
意思是說,有一個useState的結果,前後兩次都是空陣列且參照不同,所以造成了無效渲染。
注意,對於why-did-you-render而言,它一定是隻幫你找出無效渲染,且理由都是上面這種參照資料前後完全一樣,只是單純的參照不同,如何保證參照那麼又回到了上文提到的減少無效渲染的手段,如果一個元件一個無效渲染提示都沒有,那說明這個元件非常健康。
但需要注意的是,why-did-you-render的感知更多是每次重新整理頁面的初次渲染,它無法感知hover這種帶來的無效渲染,比如notta的側邊欄,可以看到hover時明明一直在渲染,但是控制檯一個提示都沒有,那怎麼辦?別急,快去西天請useWhyDidYouUpdate。
伍 ❀ 貳 useWhyDidYouUpdate
useWhyDidYouUpdate是ahooks提供的一個專門用來檢視元件update原因的hook,我們直接上官方例子,它的用法也非常簡單:
// 傳入你想在控制檯的名字,方便區分,以及你覺得可疑的資料
useWhyDidYouUpdate(componentName, props);
比如官方例子:
useWhyDidYouUpdate('useWhyDidYouUpdateComponent', { ...props, randomNum });
這裡的useWhyDidYouUpdateComponent只是你希望在控制檯輸出的名字,叫啥都行,阿貓阿狗也行,而後面的接收的是一個物件,比如你只想監聽props那就直接傳遞props即可:
const App = (props)=>{
useWhyDidYouUpdate('哈哈哈哈哈', props);
return null;
}
如果你除了props還想監聽其它的,你就可以自定義傳遞一個解構的物件,比如:
const App = (props)=>{
const userList = useSelector( state => state.userList);
const [num,setNum] = useState(1);
// 後面引數是一個物件,你要監聽多個就解構組合成一個物件就好了
useWhyDidYouUpdate('哈哈哈哈哈', {...props, num, userList});
return null;
}
需要注意的是,useWhyDidYouUpdate會告訴你你監聽資料中所有變化的資料,不管它是不是無效的更新,所以相對於why-did-you-render它更加全,缺點是需要你自己來區分識別。
伍 ❀ 叄 profiler
profiler屬於React Developer Tools的一部分,所以如果你要使用它,記得先安裝此外掛,之後開啟控制檯,你就能看到profiler的選項了,記得勾選記錄元件渲染原因的選項。
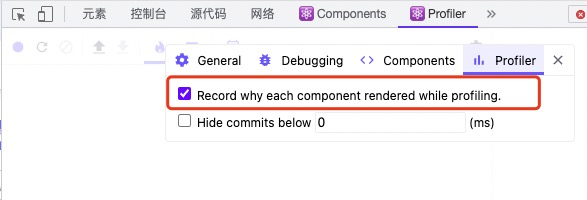
之後跟performance錄製的操作一樣,點選錄制,此時你可以盡情操作你的元件,再點選暫停,你就能看到profiler會幫你記錄剛才所有有發生渲染元件的火焰圖資料。一般情況下我們只需要關注橙色的元件,比如:
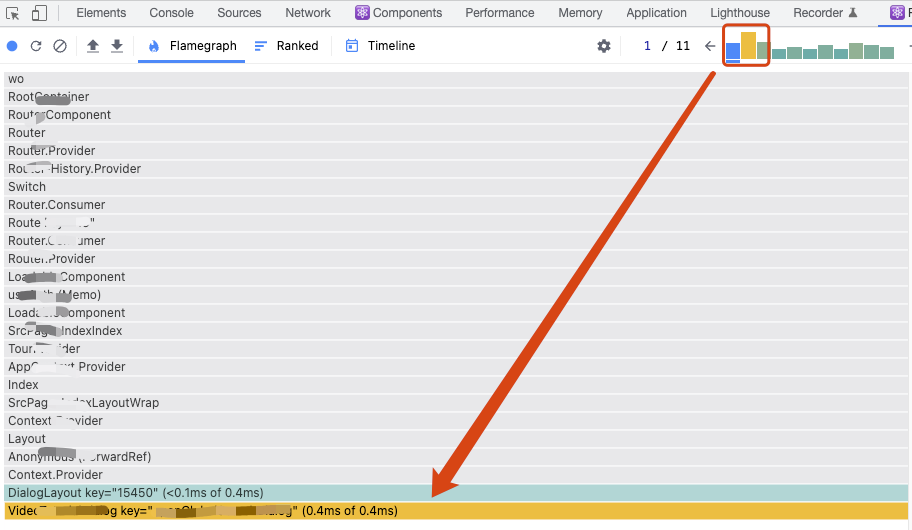

如果是state或者props變化,它會直接告訴你變數名,但如果是hooks變化,它只能告訴你這是第幾個,其實這個就很難對應,所以到頭來你還是得結合上面的兩個工具,綜合來判斷到底是哪些資料不穩定,造成的元件的多次渲染。
我們來總結下這三個工具:
- why-did-you-render:智慧幫你找出元件的無效渲染原因,一定是無效渲染才會在控制檯輸出。
- useWhyDidYouUpdate:你給什麼資料它就幫你監聽什麼,且只要是變化了它都會輸出,至於是不是無效變更需要你自行判斷。
- profiler:官方元件效能分析工具,可以直接宏觀幫你找出那些橙色的,渲染有問題的元件,然後具體原因你可以結合上述工具一起使用。
所以聊下來你會發現,這個三個工具並不是相許取代關係,而是配合使用的關係。
陸 ❀ 常見的快取策略(快取有代價)
在很多情況下,大家都會在心裡潛意識認為快取是無代價的,所以本能會想到只要是生成一個資料,我都給它加上useMemo或者其它的快取,但事實上所有的快取都是空間換時間,你想下次取快取結果,那你之前的結果就一定得儲存,要儲存就得佔用記憶體空間,這裡做個科普,介紹下市面上常見的兩種快取策略。
陸 ❀ 壹 按key快取
這種快取原理很簡單,建立一個map,然後利用你的傳參作為key,只要你下次執行時key能在map中找到值,那就預設返回結果不用重新再次執行邏輯,反之找不到,那就再次執行結果,並結合此刻的key進行新的快取,一個大致的實現就是:
const getterCache = (fn) => {
const cache = new Map();
return (...args) => {
const [uuid] = args;
// 這裡的時間複雜度是O(1)
let data = cache.get(uuid);
if (data === undefined) {
// 沒有快取
data = fn.apply(this, args); // 執行原函數獲取值
cache.set(uuid, data);
}
return data;
};
};
市面上使用這種思想的快取庫比如memoizee,但是這個庫對於快取的策略不是使用的map或者物件,而是陣列,所以當數量達到十萬級別,且你的快取函數定義的問題沒生效,這就導致每次執行都會在十萬級的陣列中查詢目標,然後沒找到再計算出一個存入陣列,導致額外的效能問題。
比如:
import memoize from 'memoizee'
const fn = function (a) {
return a * a;
};
// 使用快取
console.time('使用快取');
const memoizeFn = memoize(fn);
for (let i = 0; i < 100000; i++) {
memoizeFn(i);
}
memoizeFn(90000);
console.timeEnd('使用快取');
// 不使用快取
console.time('不使用快取');
for (let i = 0; i < 100000; i++) {
// 單純執行,啥也不快取
fn(i);
}
fn(90000);
console.timeEnd('不使用快取');

那你會說,什麼辣雞庫,用了反而更慢,其實不是庫的問題,而是使用者的問題;還記得快取函數的初衷嗎,對於執行比較耗時的邏輯進行快取以提升效能。而這個例子演示證明了一個問題,一個標準的快取庫,它內部一定也定義了快取邏輯,跑這段邏輯是需要時間的,而假設你需要快取的邏輯非常簡單,比如上述程式碼就是數位相乘,你會發現不使用快取的時間直接秒殺快取,一個函數需要執行上萬次且邏輯簡單,你快取它幹嘛??
記住,快取都是有代價的,快取程式碼執行耗時,記憶體佔用,這些都是你需要考慮的,不要為了快取而快取,這是我想表達的觀點。
陸 ❀ 貳 只記最新引數與結果
與上面的快取不同,這種快取策略的不是一個快取多次結果的物件,而是永遠是最新引數的結果,比如 memoize-one。
import memoizeOne from 'memoize-one';
function add(a, b) {
return a + b;
}
const memoizedAdd = memoizeOne(add);
// 第一次執行,結果是3
memoizedAdd(1, 2);
// 第二次執行,因為引數還是1和2,直接走換乘
memoizedAdd(1, 2);
// 第三次執行,因為引數變了,重新執行得到結果5
memoizedAdd(2, 3);
// 第四次執行,引數還是2和3,走快取
memoizedAdd(2, 3);
這裡我簡單看了下原始碼:
function memoized(
this: ThisParameterType<TFunc>,
...newArgs: Parameters<TFunc>
): ReturnType<TFunc> {
// 只有當需要快取,且this相同,且新舊入參相同時才會返回快取的結果
if (cache && cache.lastThis === this && isEqual(newArgs, cache.lastArgs)) {
return cache.lastResult;
}
// 刪除無意義的部分
}
function isEqual(first: unknown, second: unknown): boolean {
// 真正的對比其實用的是 ===
if (first === second) {
return true;
}
// 刪除部分NaN的對比
return false;
}
export default function areInputsEqual(
newInputs: readonly unknown[],
lastInputs: readonly unknown[],
): boolean {
// 先判斷入參的長度是否相同,引數長度都不同直接返回false
if (newInputs.length !== lastInputs.length) {
return false;
}
for (let i = 0; i < newInputs.length; i++) {
// 遍歷,一次拿新舊引數進行對比
if (!isEqual(newInputs[i], lastInputs[i])) {
return false;
}
}
return true;
}
其次就是每次執行看結果是不是空,以及前後引數進行淺比較看是否相等,如果都相等就直接返回cache,如果不是就重新計算更新cache。這種策略是不是讓你想到memo、useMemo了?沒錯,react的這些方法也是這個策略,這也是為什麼解決無效渲染需要保證參照資料穩定性的原因,因為淺比較就是最簡單的===。
綜合兩種策略,你會發現第一種的好處是,它會盡可能幫你把沒見過的引數以及結果都快取起來,便於下次你再執行時直接使用,但弊端就是執行次數越多,你的記憶體佔用越大。第二種策略不會有記憶體佔用的煩惱,但如果你的引數變化特別頻繁,你會發現你的快取起不到什麼作用。事實上這兩種快取使用場景不同,不具備可比性,在合適的場景使用就好了。
柒 ❀ 怎麼發現專案中存在無效渲染的元件
聊到最後,我們介紹了避免無效渲染的常規寫法,以及如何排查一個元件無效渲染的原因,有同學可能就要問了,那一個專案那麼大,我怎麼知道哪些元件需要優化呢?
兩種辦法,第一種使用profiler互動頁面,關注橙色元件即可。第二種辦法還是使用React Developer Tools,勾選如下渲染,這些重新整理頁面你就能看到每個元件的渲染情況。
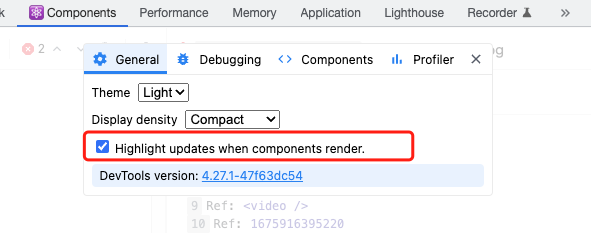
主要關注顏色深度,綠色到黃色,越偏黃色表示渲染越多,那麼接下來進入提問環節。