課程回顧|以智慧之力,加速媒體生產全自動程序
本文內容整理自「智慧媒體生產」系列課程第二講:視訊AI與智慧生產製作,由阿里雲智慧視訊雲高階技術專家分享視訊AI原理,AI輔助媒體生產,音視訊智慧化能力和底層原理,以及如何利用阿里雲現有資源使用音視訊AI能力。課程回放見文末。
01 演演算法演進:視訊AI原理
在媒體生產的全生命週期中,AI演演算法輔助提升內容生產製作效率,為創作保駕護航。
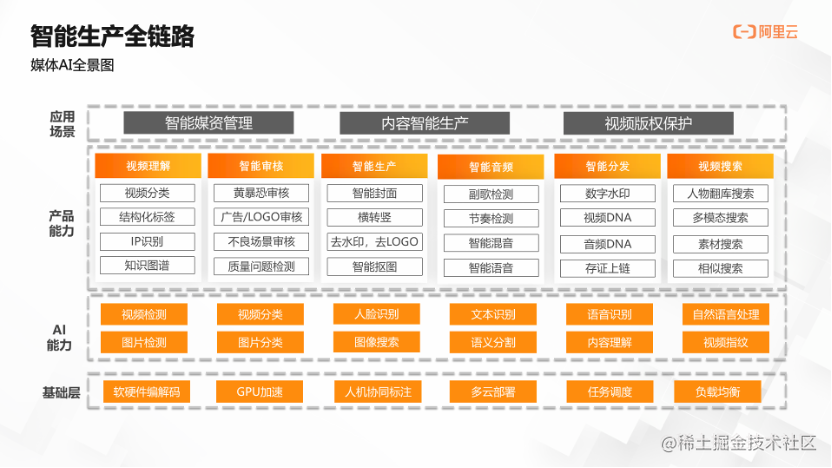
智慧生產全鏈路
智慧生產全鏈路可分為五大部分。傳統的媒體生產包含採集、編輯、儲存、管理和分發五個流程,隨著人工智慧技術的興起,五大流程涉及到越來越多的機器參與,其中最主要的便是AI技術的應用。以下舉例說明:
l 採集
在攝像機拍攝時同步進行綠幕摳圖,這在演播室或者影視製作場景中是比較常見的。
l 編輯
編輯過程運用到很多技術,比如橫轉豎、提取封面、疊加字幕等,同時這些字幕還可以通過語音識別的方式提取出來再疊加在畫面上。
l 儲存
視訊在採集和編輯之後,需要儲存下來進行結構化分析,像智慧標籤就是運用在儲存場景,從視訊中提取出相應的標籤,進行結構化的儲存,並把視訊庫中的視訊進行結構化關聯。
l 管理
儲存下來的視訊如何管理?如何通過關鍵詞檢索到對應的視訊?在管理環節,AI可以幫助進行多模態的檢索,比如人物搜尋等。
l 分發
在儲存和管理之後,視訊分發也運用到AI技術,比如音視訊DNA、溯源水印等版權保護應用。如果通過直播流的方式對廣大使用者進行直播,那麼分發環節還會涉及到直播稽核,以免出現直播故障。

基於智慧生產全鏈路,媒體AI全景圖應運而生,共分為四個層次:
最上面的層次表達媒體生產的應用場景,包含智慧媒資管理、內容智慧生產以及視訊版權保護。
往下是產品能力,即AI組合達成的能力,比如視訊分類、智慧封面、智慧摳圖等。
再往下是AI原子能力,比如語音識別、自然語言處理這些底層的AI能力。
最下是支撐AI能力的基礎底座,如編解碼和GPU加速等。以上組合起來,生成一張AI運用在智慧生產中的全景圖。
視訊AI原理
視訊AI的底層原理究竟是什麼?
人工智慧發源於機器學習,而機器學習最早只是一種統計手段,像決策樹、支援向量機、隨機森林等各種數學方法。
隨著時代發展,科學家提出一種人工神經網路的計算方法,或者說演演算法,後來發現人工神經網路可以變得更大、層次變得更深,經過進一步探索發展,在二十多年前提出了深度學習的觀點和概念。
所謂深度學習,就是在原先的人工神經網路上,把中間的層次(我們稱之為隱含層)擴充套件成兩個層次、三個層次,甚至發展到現在的幾十個層次,即可得到更多的輸入層和輸出層節點。
當神經網路變得更大、更深的時候,機器學習就演化成深度學習,也就是我們現在俗稱的AI。
隨之而來產生一個問題:如何將AI運用到視訊和影象中?
假如有一個1080P的視訊,視訊大小為1920✖1080,此時一張影象上就存在百萬個畫素。如果把百萬個畫素點都放入神經網路中,會產生巨大的計算量,遠遠超出常規計算機所能達到的上限。
因此,在把影象放入神經網路前需要進行處理,研究人員提出了折積神經網路,而這也是現在所有影象和視訊AI的基礎。
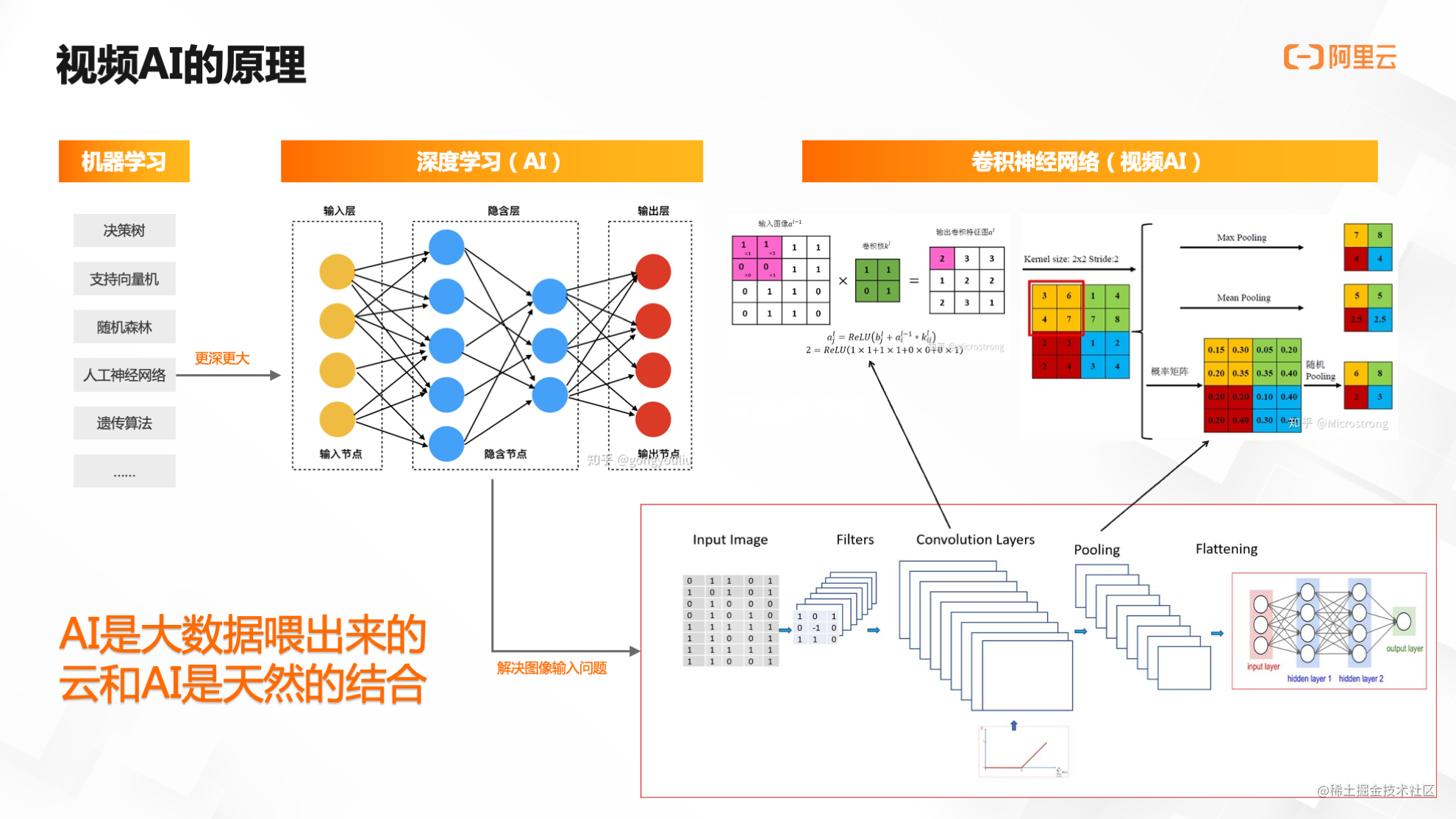
在折積神經網路的標準模型中,影象進入神經網路之前需要進行兩步操作:
第一步是折積層。所謂折積就是拿一個折積核(可以簡單理解為一個矩陣)和原始影象的每一個折積核大小的矩陣進行矩陣層的操作,最後得到一個特徵影象。由於有多個折積核,所以一張圖片可以提取出多個特徵影象。
特徵影象直接放入神經網路還是太大,因此,需要進行第二步池化層操作,池化層的作用就是下取樣,可採取多種方式,比如把方格中的最大值、平均值或者加權平均值作為最終輸出值,形成下取樣資料。
在上述例子中,一張影象的大小降低為原先的四分之一,輸入到神經網路之後,極大降低了原始資料量,即可進行影象神經網路處理。由此可見,用通俗的話來講,視訊或影象的AI模型必須是由巨量資料喂出來的。
巨量資料天然地長在雲上,雲和AI天然的結合,可以使AI在雲上得到較好的發展與運用。
瞭解視訊AI原理之後,如何反過來評價AI的效果?
以典型的分類問題舉例,假如有100個視訊,需要找出其中出現過人的視訊,那麼有兩個指標可以評價AI模型的好壞:一個是精度,另一個是召回率。
所謂的精度是指,假設AI演演算法最終找出50個視訊,但是檢查之後發現,其中只有40個是真正有人的,那麼精度計算為40➗50=0.8。
召回率是指,假設這100個視訊中真正有人的一共有80個,而AI找出了其中40個,那麼召回率計算為0.5。
可以發現,精度和召回率是一對矛盾。假如想提高精度,只要找出來的視訊少一點,就可以保證每個找出來的視訊都是對的,即精度上升,但此時召回率一定會下降。
現階段的AI並不完美,也就是說,目前AI還只能輔助視訊生產,生產視訊的主體還是人。
AI輔助生產
AI輔助生產可以由以下兩個範例進行說明。
範例一:通過圖片搜尋相關圖片或視訊。Demo顯示,輸入一張周星馳的圖片後,機器雖然不認識這是誰,但是能夠從圖片中提取此人的外貌特徵,然後在視訊庫裡做相應搜尋,找出一堆包含周星馳的視訊。

範例二:智慧橫轉豎。傳統電影和電視劇均為橫屏播放,隨著行動網際網路興起,這些電影和電視劇需要在手機端進行投放,由此誕生了智慧橫轉豎這樣的AI演演算法,將大量的橫屏視訊轉換成豎屏視訊,幫助橫屏視訊在手機端分發。
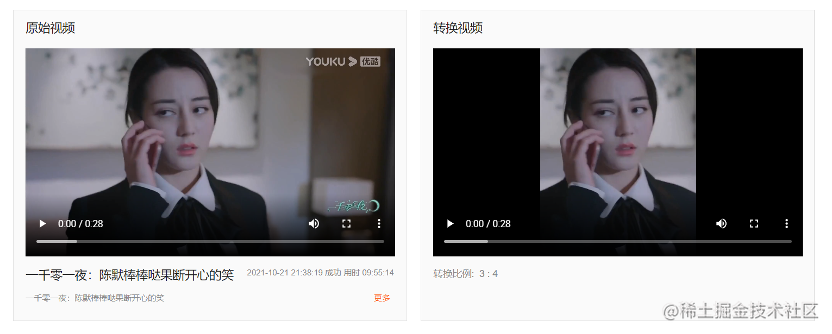
電視劇橫轉豎效果
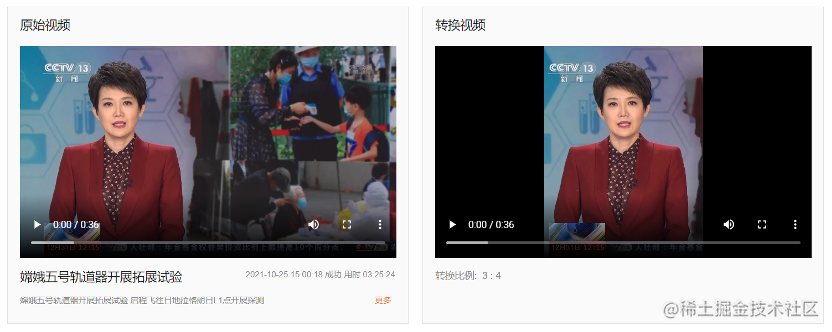
新聞橫轉豎效果
02 智慧進階:視訊內容理解
智慧標籤
智慧標籤基於AI對於視訊內容的理解,自動提取視訊中的標籤、關鍵詞等資訊,分析詳情會展示為四部分:
第一部分是視訊標籤,獲取視訊的類目,視訊出現過哪些人物,人物出現的時間點以及在視訊中的位置,人物的相似度等。
第二部分是文字標籤,會提煉出一些關鍵詞,包括視訊文字中出現過的組織機構,比如央視等。
後面兩部分為文字識別和語音識別,分別通過圖片OCR技術和語音雲識別技術實現。
具體範例可在AI體驗館中進行體驗,同時,也提供API接入檔案進行參考。
體驗中心:https://retina.aliyun.com/
API接入檔案:https://help.aliyun.com/document_detail/163485.html
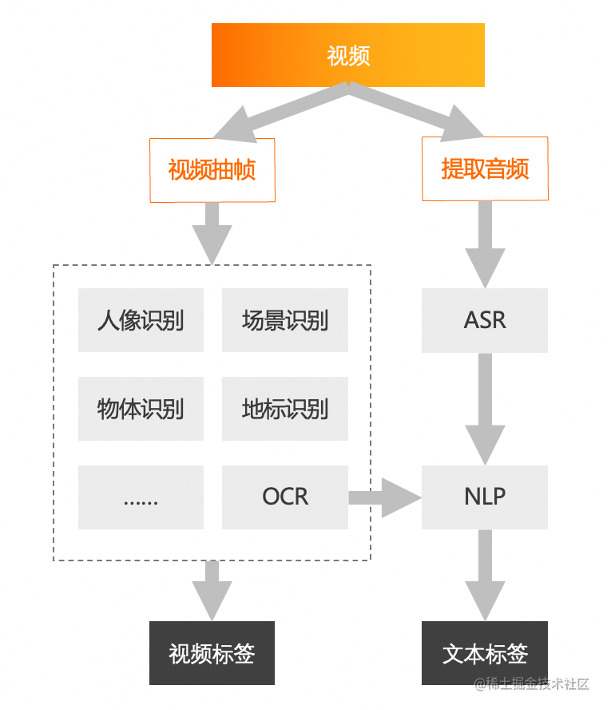
AI是如何從視訊中提取出資訊的呢?從視訊標籤的流程圖中可以看到,輸入一個視訊,分別進行兩部分操作:
一部分是對視訊做抽幀處理,抽幀得到的影象通過人像識別、場景識別、物體識別、地標識別、OCR等影象AI識別模型,提煉出視訊標籤。
另一部分是把視訊中的音訊提取出來,然後通過ASR得到文字結果,最後再經過NLP(自然語言處理),提取出文字標籤。
智慧稽核
視訊稽核的技術原理與視訊標籤相同,唯一不同的是,視訊標籤可以理解為一個正向的視訊內容理解,而視訊稽核是負向的,稽核需要識別出一些不合規的、有問題的內容,比如鑑黃、暴恐涉政、違規、二維條碼、不良場景等資訊。

視訊檢索
視訊檢索的核心技術點是利用標籤結果進行視訊的分析和查詢。
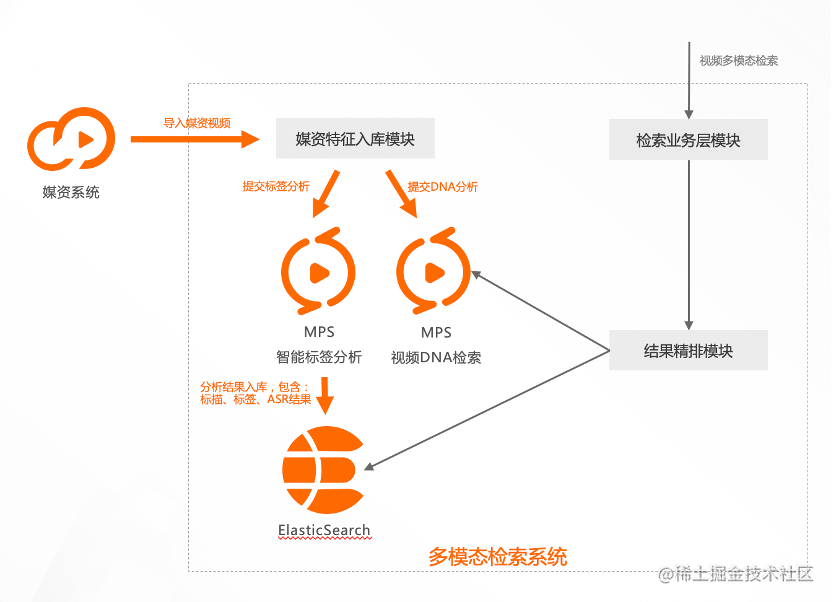
視訊檢索架構圖顯示,媒資系統中的視訊通過媒資特徵入庫模組,匯入到智慧標籤分析中,並得到一系列的標籤,包括視訊標籤、文字標籤,原始的ASR、OCR結果等,將這些結果連同視訊的後設資料資訊比如標題、描述等,利用ElasticSearch開源服務進行文字資訊的倒排索引和查詢。
視訊檢索過程中會涉及到精排模組,這需要由業務層來實現。如果只是從ES中把符合檢索條件的結果提取出來,不一定能滿足業務層需求,比方說業務層面對政治新聞場景時,會要求把某些人物的搜尋結果更靠前排序,而這就是精排模組所需要做的工作。
檢索系統一般都會根據業務層排序,接入業務介面模組,由此一個基本的檢索系統搭建完成。但是,現在的檢索系統只能按照文字檢索視訊。如何通過一張圖片,檢索到相似的圖片或視訊呢?
這涉及到視訊DNA檢索技術。所謂的視訊DNA,就是把視訊裡面的關鍵幀或者某一鏡頭提煉出關鍵資訊,我們把它稱之為DNA,並把這些資訊放入向量資料庫中進行檢索,更多內容可通過體驗中心和接入檔案進行拓展瞭解。
體驗中心:https://retina.aliyun.com/
API接入檔案:https://help.aliyun.com/document_detail/93553.html
03 能力升級:音視訊智慧處理
基於視訊內容理解,如何對視訊進行智慧處理?
綠幕摳圖
綠幕摳圖是在視訊拍攝或者採集時,把背景替換成電腦製作的畫面。在演播室場景中,實際拍攝時根據需求,在主持人的背後放置綠幕背景或者藍幕背景。
影視製作場景同樣運用到綠幕摳圖,比如科幻片中無法實景拍攝的部分,會在後期進行背景疊加或其他處理工作,通過在人物背後放置綠幕的方式,把人物主體提取出來。
綠幕摳圖要求輸入的是藍幕或者綠幕視訊,解析度不超過4K,同時輸入一張背景圖片,即可輸出替換背景後的視訊。以下為範例說明:一個人從綠幕前走過,替換背景後,變成此人在背景前走路,整體效果非常自然。

視訊連結:https://v.youku.com/v_show/id_XNTk0MDc4Mjc3Mg==.html

視訊連結: https://v.youku.com/v_show/id_XNTk0MDc4Mjc5Ng==.html
如何評價綠幕摳圖的質量?首先要處理好邊緣溢色,比如在頭髮邊緣,由於原始的影象背景是綠幕,頭髮縫邊緣必然會染上一些綠色,技術上需要把這些邊緣溢色擦除掉。
此外,如何真實地呈現透明度,併疊加背後的內容,還有運動模糊,地面陰影等,均是綠幕摳圖質量好壞的評價點。
橫轉豎
橫轉豎是在行動網際網路上分發視訊的必備處理手段。
傳統人工製作橫轉豎視訊的難點在於:一,需要專業的剪輯軟體和製作人員,成本高,速度慢;二,在目標移動比較快的場景中,需要逐幀剪裁,工作量巨大;三,剪裁目標區域後,前後幀難以對齊。因此,橫轉豎視訊更適合由機器製作實現。
智慧橫轉豎的演演算法流程是:首先對視訊進行鏡頭分割,所謂的鏡頭分割就是在視訊製作中,按照不同拍攝機位的轉變,識別鏡頭的切換,並把不同鏡頭分割開來。

視訊連結:https://v.youku.com/v_show/id_XNTk0MDg4MjA0NA==.html
其次是主體選擇,在主體選擇時,一般選擇畫面中最醒目的人作為目標,在上述舞蹈場景中,主體就是這個正在跳舞的人。
然後是鏡頭追蹤,每幀影象做好初期選擇之後,下一幀都要跟隨目標,即框定的影象跟隨這個人進行移動。
最後是路徑平滑,鏡頭追蹤完成之後,最終生成的豎屏視訊必須是平滑的,不能出現翹邊等不良效果。更多內容可參見官網:
體驗中心:https://retina.aliyun.com/
API接入檔案:https://help.aliyun.com/document_detail/169896.html
其他視訊智慧處理能力
目前,阿里雲視訊雲提供的視訊智慧處理能力,可分為以下四類:
-
ROI提取,即感興趣區域提取,包括綠幕摳圖和橫轉豎;
-
智慧擦除,比如去圖示、去字幕;
-
關鍵資訊提煉,比如智慧封面,即從視訊中提取出最能表現視訊的一張圖片;視訊摘要,提取出視訊中最能表現視訊的簡短視訊;
-
結構化分析,比如字幕提取,把嵌入在影象中的字幕自動提取出來;PPT拆條,可以將一個課程視訊自動拆成段落。

講完視訊智慧處理能力,接下來介紹兩項音訊智慧處理能力:副歌識別和節奏檢測。
副歌識別
副歌是指歌曲中的高潮片段。副歌識別有何應用場景?比如,很多音樂APP的試聽功能,會直接播放歌曲中的高潮片段,人為進行提取相當麻煩,而副歌識別就能很好地完成任務。
副歌識別的演演算法流程為:輸入歌曲之後,首先進行音樂段落檢測,然後提取副歌段落,並進行精調使之更貼合,最後再生成副歌片段。

副歌識別的範例顯示,通過呼叫之後,演演算法會返回兩個結果值,即副歌的開始時間點和結束時間點。

大家可以對返回的結果和音訊進行對照,從72秒副歌開始,到102秒副歌結束,副歌識別結果還是非常準確的。
節奏檢測
節奏檢測即識別音樂中的節奏點,其主要應用場景為視訊製作和音樂推薦,比如,通過識別出音樂節奏點,進行鬼畜視訊的製作;通過識別音樂的節拍型別,是四三拍還是四四拍,幫助進行音樂分類等。
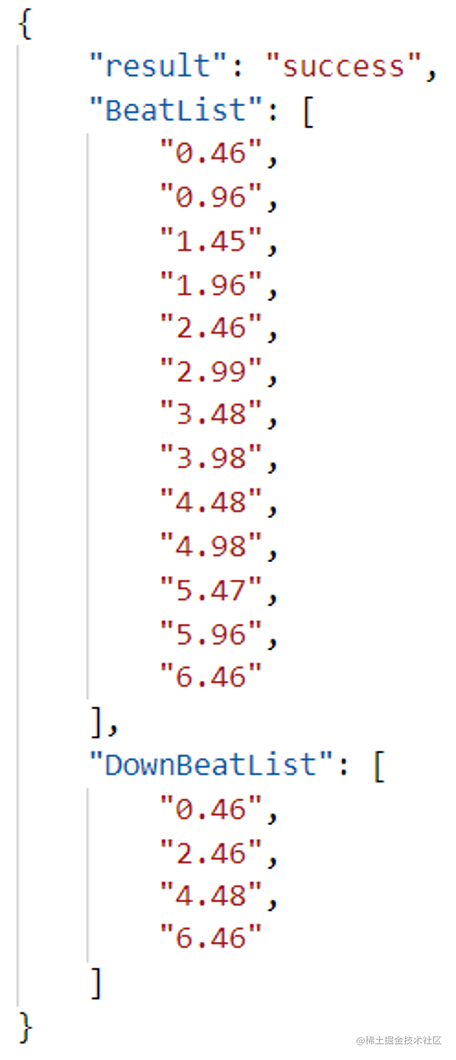
繼續以上述音訊範例,節奏檢測演演算法輸出兩個結果:第一個是節拍時間點,如0.46秒、0.96秒均為節拍時間點;第二個是downbeat時間點,在樂理中解釋為重拍,其中0.46秒為第一拍,2.46秒為第五拍,也就是說每四拍為一個小節,每小節的第一拍為重拍,由此檢測出該音樂的節奏。
其他音訊智慧處理能力
此外,視訊雲還提供其他音訊智慧處理能力,包括混音,ASR語音識別和TTS語音合成。混音即把兩個音樂片段進行疊加,其中涉及到音量增益和自動控制演演算法。
這些能力進行組合,還可以實現更多玩法,比如歌曲串燒,首先通過副歌識別,把幾首歌曲的副歌部分提取出來,然後進行節奏檢測,把合適的節拍點合在一起,最終組合成一首完整的歌曲串燒。
04 開箱即用:阿里雲媒資服務
基於視訊AI原理以及效果,阿里雲利用現有資源,提供更方便、更高效的音視訊AI使用能力。
MPS服務
MPS是媒體處理的英文簡稱。阿里雲提供針對多媒體的資料處理服務,將媒體處理過程抽象成兩種模式:一種是輸入音視訊等多媒體檔案,經過智慧化媒體處理,生成一個新的媒體檔案,比如之前提到的智慧橫轉豎。
另一種模式是輸入一個媒體檔案,輸出經過媒體處理分析後的一系列結構化資料,比如智慧標籤或智慧稽核。
MPS支援多項音視訊智慧處理能力,此外,MPS的媒體檔案型別,既可以輸入OSS檔案,也支援輸入網路URL地址。

MPS介面呼叫的流程為:
第一步,開通MPS產品,在開通的過程中,控制檯會引導進行增加許可權等相關操作。
開通MPS產品:https://www.aliyun.com/product/mts
第二步,呼叫MPS的Open API介面,獲得Access Key,包括AK的ID和金鑰。所有阿里雲的Open API都要通過AK和SK存取。
使用RAM服務獲取AccessKey:https://ram.console.aliyun.com/manage/ak
第三步,認真閱讀MPS提供的API檔案:https://help.aliyun.com/document_detail/29210.html
第四步,針對開發需要,選用不同程式語言,並安裝依賴模組:https://help.aliyun.com/document_detail/188024.html
第五步,編寫程式碼。
阿里雲MPS服務提供的智慧化能力可以分為四個維度:
一是視訊內容理解,包含智慧標籤,智慧稽核,媒體DNA,媒體DNA是視訊檢索中的重要組成部分,還有智慧封面、視訊摘要等。
二是視訊智慧處理,像橫轉豎、去圖示、去字幕、字幕提取等,從電視劇或電影中抽取出字幕,並輸出TXT或者SRT格式,此外,也包括綠幕摳圖和PPT拆條等。
三是音訊智慧處理,包含副歌檢測、混音處理、節奏檢測和音質檢測等。
四是圖片智慧處理,包含橫轉豎、去圖示和人像風格化。人像風格化可以把一張人像圖片風格化成不同的形式,比如把人像進行卡通化,或者進行3D處理。

IMS服務
IMS服務是阿里雲近年來新上的服務,全稱是智慧媒體服務,和MPS服務的區別在於:
IMS服務圍繞直播和點播場景,是針對媒體處理的全流程服務,可認為是MPS服務的重大產品迭代和升級。
第一,IMS不僅針對於單個媒體處理過程,而是對於媒體服務全流程、全生產週期的管理和製作;
第二,IMS的整合度更高,不光可以進行單個原子能力的音視訊處理,還可以進行媒資管理、工作流觸發等,讓開發者更方便地使用音視訊智慧化能力;
第三,IMS更智慧,後續所有智慧化能力升級後都會集中體現在IMS服務中。

IMS控制檯融合了媒資管理,媒資庫中的音訊視訊檔,包括圖片、輔助的媒資,都可以通過IMS服務進行展示和管理。
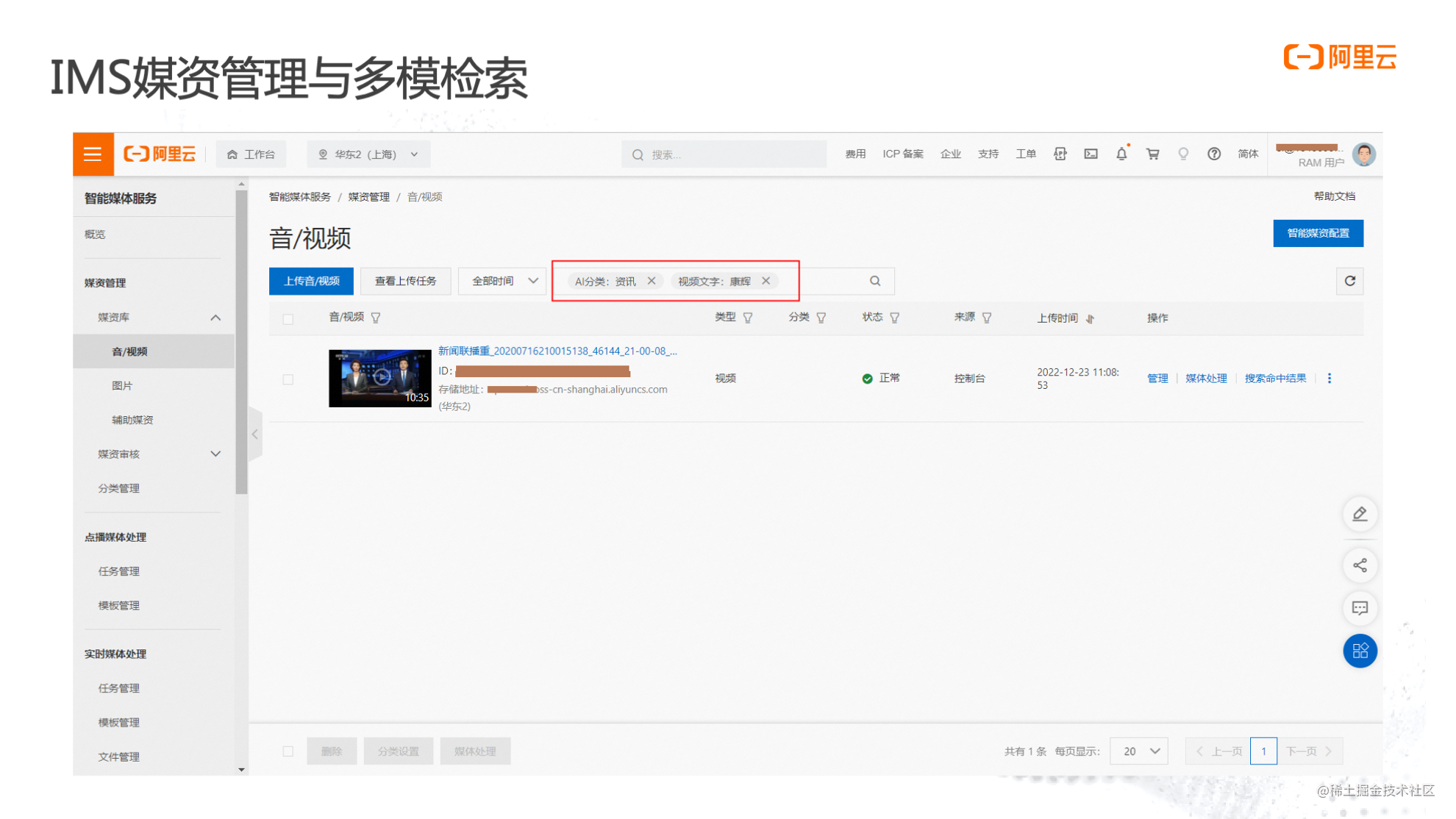
利用多模檢索的智慧化能力,IMS可以實現多媒體檔案的智慧化檢索。傳統的音視訊檔檢索,只能針對標題或者簡介進行,而IMS支援對上傳的音視訊檔做AI自動分類,並根據分類結果進行搜尋,同時,也支援對視訊中的文字進行自動識別檢索。
比如,新聞聯播的畫面中出現了「康輝」兩個字樣,雖然視訊檔的標題和簡介裡都沒有出現過「康輝」,但在搜尋「康輝」時,AI還是可以搜尋識別出此視訊檔,這就是多模檢索的能力。
Retina多媒體AI體驗中心
上述MPS和IMS服務的智慧化能力,都需要通過Open API呼叫或者控制檯開通使用,而Retina體驗中心可以讓大家更方便快捷地進行體驗,只需上傳視訊或圖片,就可以直觀地得到經過智慧化處理後的結果。
例如,在Retina平臺,你可以體驗人像卡通化的效果,只需上傳一張人像圖片,經過自動處理,就能獲得童話風格的卡通人像圖片,更多體驗就在:http://retina.aliyun.com/

隨著視訊與AI技術的發展和演進,AI在媒體生產領域中發揮著越來越重要的作用,以更快的速度、更高的效率完成之前難以實現的事情。
未來,AI將從輔助媒體生產,逐漸轉變為直接生產有意義、有價值、有情感的視訊,進一步加速媒體生產製作全自動處理程序。
更多完整內容詳見課程回放 ⬇️

視訊連結:https://v.youku.com/v_show/id_XNTk0MjQ4Mjk5Mg==.html