(一) MdbCluster分散式記憶體資料庫——基礎架構介紹
2023-02-10 18:00:25
(一) MdbCluster分散式記憶體資料庫——基礎架構介紹
這個專案是怎麼開始的我已經有些記不清楚了,大概是原來的記憶體資料庫很不好用,一次次地讓我們踩坑,我又自以為是地覺得可以做一個更好的出來。自從擁有自己的團隊以來,我思考最多的總是如何帶著團隊做出有意義和有價值的產品,而不是將時間浪費在無謂的瑣事上面。分散式記憶體資料庫恰是這樣一個具有挑戰性,又在我們能力可控範圍內的專案。於是我和團隊的兩個小夥伴利用工作的空隙完成了這個產品。
每次當我想從頭開始做一個軟體產品的時候,都會想起《人月神話》裡面的章節。程式設計的樂趣是什麼,是什麼讓我們願意付出大量的時間和腦力去完成一個軟體產品?
「首先是一種建立事物的純粹快樂。如同小孩在玩泥巴時感到愉快一樣,成年人喜歡建立事物,特別是自己進行設計。」——每次看到自己孩子在堆沙堡的時候,我都會想起這句話,很慶幸在這個年紀還能擁有這樣的快樂。
「整個過程體現出魔術般的力量——將相互齧合的零部件組裝在一起,看到它們精妙地執行,得到預先所希望的結果。」——完成的專案越來越複雜,當每次跨過這些難度門檻的時候,也就意味著從此可以駕馭這類等級的產品了。
「程式設計師,就像詩人一樣,幾乎僅僅工作在單純的思考中。程式設計師憑空地運用自己的想象,來建造自己的城堡。」——隨著產品複雜的提升,設計在我工作中的佔比也越來越多,大腦也逐漸習慣這樣的工作方式。儘管也還偶爾做一些核心模組的編碼,沉浸其中時也能感到時間飛逝。
「資料庫」是一個龐大的產品,更何況是分散式記憶體資料庫。設計的時候是如何考慮做減法的?首先,我們用fastdb做基層記憶體資料庫,這不是我們要解決的重點。這方面業界已經很成熟了,包括timesten, altibase等等。其次,在業務層面,我們不需要實現所有資料庫的複雜操作,對於記憶體資料庫的使用,為了追求效能,一直推薦進行單表操作的,從而暫時避開了複雜的多表關聯問題。最後,我們集中力量解決的是節點分片、節點主備、節點線上擴容縮容、節點故障檢測、故障節點恢復、節點狀態管理等等分散式的問題。
一、 單體結構
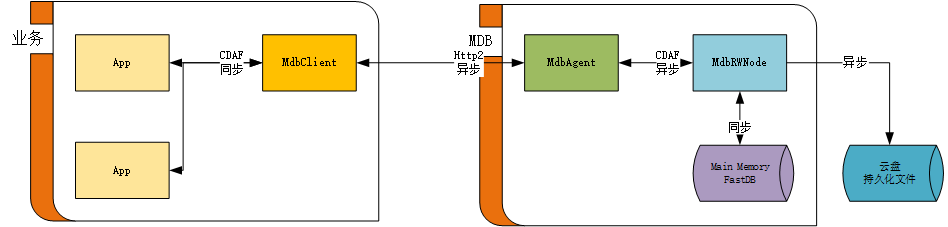
根據最初的設計方案,在實現的時候我們進一步做了減法。
MdbCluster的服務節點:
a)MdbAgent負責業務和控制訊息的接入、校驗、推播。
b) MdbRWNode負責管理本地記憶體資料庫,資料同步寫入記憶體,非同步寫入磁碟。
MdbCluster的使用者端節點:
a) MdbClient負責與在App的驅動進行同步互動,並通過http2協定與伺服器端進行通訊。
二、主備結構
在MdbCluster設計之初,打算通過二階段提交的方式來實現資料一致性。並且設計了複雜的二階段提交流程,足有三大頁的流程圖。難點不在於二階段提交本身,而在於異常發生時,系統如何保證資料不丟失,如何從故障中恢復。雖然看起來設計方案很宏偉,但一點也不優雅,實現起來一定會是個災難。看到Redis也從低版本的二階段提交改為高版本的主備模式。我們也修改了最初的設計方案。
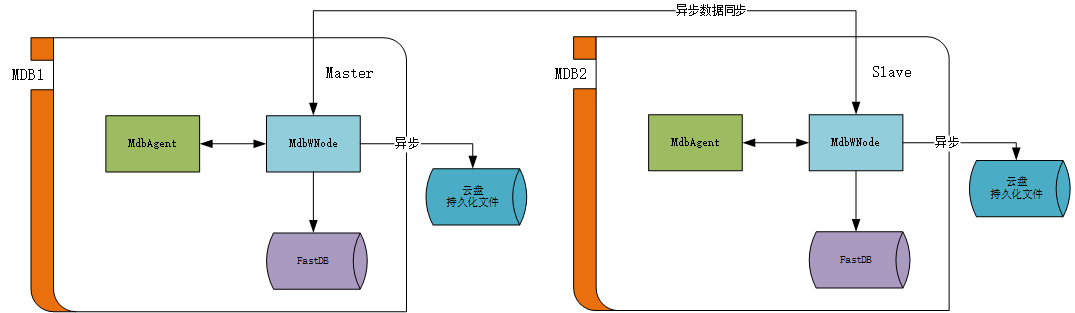
Master節點和Slave節點的MdbRWNode通過非同步的方式來同步資料。並且通過心跳的方式來檢測對端是否異常。
a) 當Slave節點異常時,資料同步中斷。在Slave節點恢復時,先從自己的資料庫檔案中恢復資料,再對接Master節點,對中斷過程中的資料進行恢復。
b) 當Master節點異常時,MDB2檢測到MDB1故障,將自己轉為Master節點,承擔業務訊息。當MDB1恢復時,先從自己的資料庫檔案中恢復資料,再對接Master節點,對中斷過程中的資料進行恢復。並做為Slave節點繼續工作。
c) 在做主備切換時,MdbAgent會對MdbClient進行廣播通知。