VSCode一鍵接入Notebook體驗演演算法套件快速完成水錶讀數
摘要:本範例圍繞真實AI需求場景,介紹VSCode一鍵接入Notebook體驗演演算法套件快速完成水錶讀數的使用流程。
本文分享自華為雲社群《VSCode一鍵接入Notebook體驗演演算法套件快速完成水錶讀數》,作者:HWCloudAI。
本範例圍繞真實AI需求場景,介紹VSCode一鍵接入Notebook體驗演演算法套件快速完成水錶讀數的使用流程。
演演算法開發套件中目前提供自研(ivg系列)和開源(mm系列)共兩套演演算法資產,可應用於分類、檢測、分割和OCR等任務中。本範例中將組合使用自研分割演演算法(ivgSegmentation)和開源OCR演演算法(mmOCR)完成水錶讀數識別專案,並使用演演算法開發套件將其部署為華為雲線上服務。
說明:
本案例教學僅適用於「華北-北京四」區域,新版Notebook。
準備資料
- 登入OBS控制檯,建立OBS物件桶,區域選擇「華北-北京四」。
- 登入ModelArts控制檯,選擇控制檯區域為「華北-北京四」。
- 在「全域性設定」頁面檢視是否已經設定授權,允許ModelArts存取OBS。如果沒有設定授權,請參考設定存取授權(全域性設定)新增授權。
- 分別下載本案例的資料集,水錶錶盤分割資料集和水錶錶盤讀數OCR識別資料集到OBS桶中,OBS路徑範例如下
obs://{OBS桶名稱}/water_meter_segmentation 水錶錶盤分割資料集
obs://{OBS桶名稱}/water_meter_crop 水錶錶盤讀數OCR識別資料集
說明:
從AIGallery下載資料集免費,但是資料集儲存在OBS桶中會收取少量費用,具體計費請參見OBS價格詳情頁,案例使用完成後請及時清除資源和資料。
準備開發環境
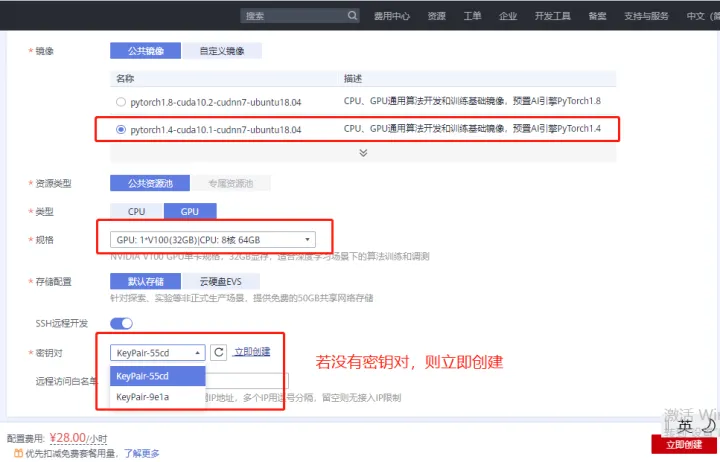
在「ModelArts控制檯 > 開發環境 > Notebook(New)」頁面中,建立基於pytorch1.4-cuda10.1-cudnn7-ubuntu18.04映象,型別為GPU的Notebook,具體操作請參見建立Notebook範例章節。
本案例需要使用VS Code 遠端連線Notebook,需要開啟SSH遠端開發。
圖1 建立Notebook範例
1.範例的金鑰檔案需要下載至原生的如下目錄或其子目錄中:
Windows:C:\Users{{user}}
Mac/Linux: Users/{{user}}
2.在ModelArts控制檯->開發環境 Notebook,單擊「操作」列的「更多 > VS Code接入」。

如果本地已安裝VS Code,請單擊「開啟」,進入「Visual Studio Code」頁面。
如果本地未安裝VS Code,請根據實際選擇「win」或「其他」下載並安裝VS Code。VS Code安裝請參考安裝VS Code軟體。
如果使用者之前未安裝過ModelArts VS Code外掛,此時會彈出安裝提示,請單擊「Install and Open」進行安裝;如果之前已經安裝過外掛,則不會有該提示,請跳過此步驟,直接執行後面步驟
安裝過程預計1~2分鐘,安裝完成後右下角會彈出對話方塊,請單擊「Reload Window and Open」。
在彈出的提示中,勾選「Don’t ask again for this extension」,然後單擊"Open"。
3.遠端連線Notebook範例。
- 遠端連線執行前,會自動在(Windows:C:\Users{{user}}.ssh或者downloads,Mac/Linux: Users/{{user}}/.ssh或者downloads)目錄下根據金鑰名稱查詢金鑰檔案,如果找到則直接使用該金鑰開啟新視窗並嘗試連線遠端範例,此時無需選擇金鑰。
- 如果未找到會彈出選擇框,請根據提示選擇正確的金鑰。
- 如果金鑰選擇錯誤,則彈出提示資訊,請根據提示資訊選擇正確金鑰。
- 當彈出提醒範例連線失敗,請關閉彈窗,並檢視OUTPUT視窗的輸出紀錄檔,請檢視FAQ並排查失敗原因。
使用演演算法套件進行開發
Step1 建立演演算法工程
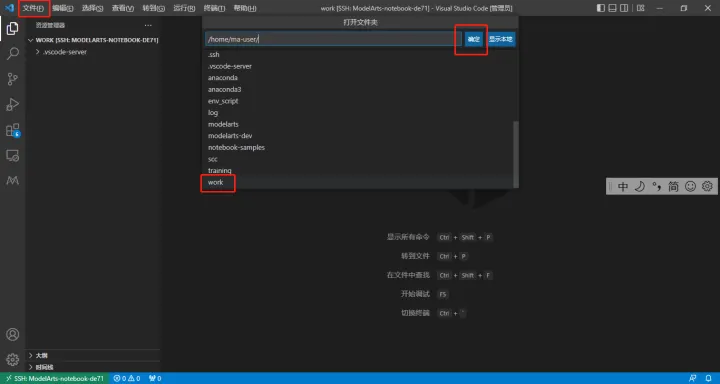
1.成功接入之後,在VS Code頁面點選檔案->開啟資料夾,選擇如下資料夾開啟
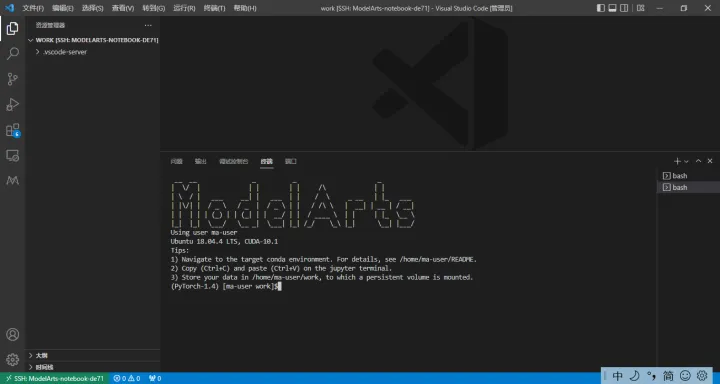
2.新建終端
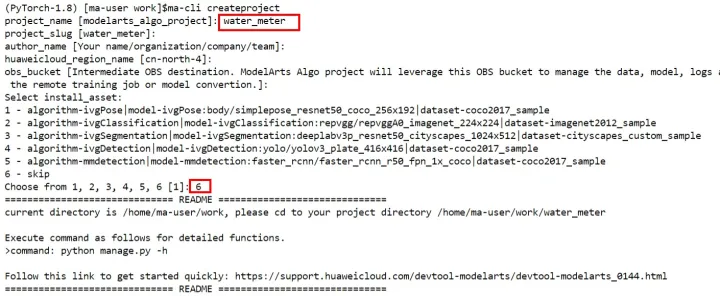
3.在work目錄下執行
ma-cli createproject
命令建立工程,根據提示輸入工程名稱,例如:water_meter。然後直接回車選擇預設引數,並選擇跳過資產安裝步驟(選擇6)。
4.執行以下命令進入工程目錄。
cd water_meter
5.執行以下命令拷貝專案資料到Notebook中。
python manage.py copy --source {obs_dataset_path} --dest ./data/raw/water_meter_crop
python manage.py copy --source {obs_dataset_path} --dest ./data/raw/water_meter_segmentation
說明:
{obs_dataset_path}路徑為Step1 準備資料中下載到OBS中的資料集,比如「obs://{OBS桶名稱}/water_meter_segmentation」和「obs://{OBS桶名稱}/water_meter_crop」
Step2 使用deeplabv3完成水錶區域分割任務
1.首先安裝ivgSegmentation套件。
python manage.py install algorithm ivgSegmentation==1.0.2
如果提示ivgSegmentation版本不正確,可以通過命令python manage.py list algorithm查詢版本。
2.安裝ivgSegmentation套件後,在介面左側的工程目錄中進入「./algorithms/ivgSegmentation/config/sample」資料夾中檢視目前支援的分割模型,以sample為例(sample預設的演演算法就是deeplabv3),資料夾中包括config.py(演演算法外殼設定)和deeplabv3_resnet50_standard-sample_512x1024.py(模型結構)。
3.錶盤分割只需要區分背景和讀數區域,因此屬於二分類,需要根據專案所需資料集對組態檔進行修改,如下所示:
修改./algorithms/ivgSegmentation/config/sample/config.py檔案。
# config.py alg_cfg = dict( ... data_root='data/raw/water_meter_segmentation', # 修改為真實路徑本地分割資料集路徑 ... )

修改完後按Ctrl+S儲存。
4.修改./algorithms/ivgSegmentation/config/sample/deeplabv3_resnet50_standard-sample_512x1024.py檔案。
# deeplabv3_resnet50_standard-sample_512x1024.py gpus=[0] ... data_cfg = dict( ... num_classes=2, # 修改為2類 ... ... train_scale=(512, 512), # (h, w)#size全部修改為(512, 512) ... train_crop_size=(512, 512), # (h, w) ... test_scale=(512, 512), # (h, w) ... infer_scale=(512, 512), # (h, w) )
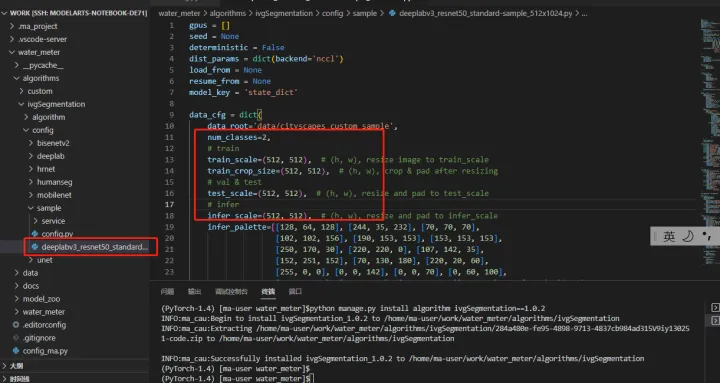
5.修改完按Ctrl+S儲存。
6.在water_meter工程目錄下,安裝deeplabv3預訓練模型。
python manage.py install model ivgSegmentation:deeplab/deeplabv3_resnet50_cityscapes_512x1024
7.訓練分割模型。(推薦使用GPU進行訓練)
# shell python manage.py run --cfg algorithms/ivgSegmentation/config/sample/config.py --gpus 0
訓練好的模型會儲存在指定位置中,預設為output/deeplabv3_resnet50_standard-sample_512x1024/checkpoints/中。
8.驗證模型效果。
模型訓練完成後,可以在驗證集上計算模型的指標,首先修改組態檔的模型位置。
修改./algorithms/ivgSegmentation/config/sample/config.py。
# config.py alg_cfg = dict( ... load_from='./output/deeplabv3_resnet50_standard-sample_512x1024/checkpoints/checkpoint_best.pth.tar', # 修改訓練模型的路徑 ... ) # shell python manage.py run --cfg algorithms/ivgSegmentation/config/sample/config.py --pipeline evaluate
9.模型推理。
模型推理能夠指定某一張圖片,並且推理出圖片的分割區域,並進行視覺化,首先需要指定需要推理的圖片路徑。
修改./algorithms/ivgSegmentation/config/sample/config.py
alg_cfg = dict( ... img_file = './data/raw/water_meter_segmentation/image/train_10.jpg' # 指定需要推理的圖片路徑 ... )
執行如下命令推理模型效果。
# shell
python manage.py run --cfg algorithms/ivgSegmentation/config/sample/config.py --pipeline infer
推理輸出的圖片路徑在./output/deeplabv3_resnet50_standard-sample_512x1024下。
10.匯出SDK。
演演算法開發套件支援將模型匯出成一個模型SDK,方便進行模型部署等下游任務。
# shell
python manage.py export --cfg algorithms/ivgSegmentation/config/sample/config.py --is_deploy
Step3 水錶讀數識別
1.首先安裝mmocr套件。
python manage.py install algorithm mmocr
2.安裝mmocr套件後,./algorithms/mmocr/config/textrecog資料夾中包括config.py(演演算法外殼設定),需要根據所需演演算法和資料集路徑修改組態檔。以下以robust_scanner演演算法為例。
修改./algorithms/mmocr/algorithm/configs/textrecog/robustscanner_r31_academic.py,
# robustscanner_r31_academic.py ... train_prefix = 'data/raw/water_meter_crop/' # 修改資料集路徑改為水錶ocr識別資料集路徑 train_img_prefix1 = train_prefix + 'train' train_ann_file1 = train_prefix + 'train.txt' test_prefix = 'data/raw/water_meter_crop/' test_img_prefix1 = test_prefix + ‘val’ test_ann_file1 = test_prefix + ‘val.txt’
3.安裝robust_scanner預訓練模型。
python manage.py install model mmocr:textrecog/robust_scanner/robustscanner_r31_academic
4.訓練OCR模型。
初次使用mmcv時需要編譯mmcv-full,該過程較慢,可以直接使用官方預編譯的依賴包。
預編譯包URL: https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html
pip install https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/mmcv_full-1.3.8-cp37-cp37m-manylinux1_x86_64.whl
將./algorithms/mmocr/config/textrecog/config.py中的epoch(迭代數量)改為2,如下圖所示:
python manage.py run --cfg algorithms/mmocr/config/textrecog/config.py
訓練好的模型會儲存在指定位置中,預設為output/${algorithm}中。
5.驗證模型效果。
模型訓練完成後,可以在驗證集上計算模型的指標,首先修改組態檔的模型位置。
修改./algorithms/mmocr/config/textrecog/config.py
# config.py ... model_path = './output/robustscanner_r31_academic/latest.pth' ... # shell python manage.py run --cfg algorithms/mmocr/config/textrecog/config.py --pipeline evaluate
6.模型推理。
模型推理能夠指定某一張圖片,並且推理出圖片的分割區域,並進行視覺化。首先需要指定待推理的圖片路徑,修改algorithms/mmocr/config/textrecog/config.py檔案,具體如下。
修改./algorithms/mmocr/algorithm/configs/textrecog/robust_scanner/config.py
... infer_img_file='./data/raw/water_meter_crop/val/train_10.jpg' # 指定需要推理的圖片路徑 ... # shell python manage.py run --cfg algorithms/mmocr/config/textrecog/config.py --pipeline infer
推理輸出的圖片路徑在output/robustscanner_r31_academic/vis下
7.匯出SDK。
# shell
python manage.py export --cfg algorithms/mmocr/config/textrecog/config.py
Step4 部署為線上服務
本次展示僅部署OCR服務, 包括本地部署和線上部署, 部署上線後呼叫部署服務進行本地圖片的推理,獲取水錶的預測讀數。部署線上服務,需要指定OBS桶以便儲存部署所需要的檔案。
1.在algorithms/mmocr/config/textrecog/config.py檔案中設定OBS桶,即obs_bucket=<please input your own bucket here>。
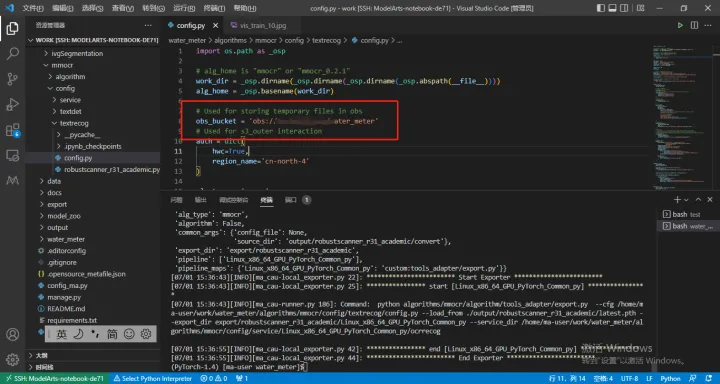
2.執行下述命令:
python manage.py export --cfg algorithms/mmocr/config/textrecog/config.py --is_deploy # 匯出部署模型 python manage.py deploy --cfg algorithms/mmocr/config/textrecog/config.py # 本地部署 python manage.py deploy --cfg algorithms/mmocr/config/textrecog/config.py --launch_remote#線上部署,會耗時一會兒,請耐心等待
點選此處,檢視部署成功的線上服務
Step5 清除資源和資料
通過此範例學習完成建立演演算法套件流程後,如果不再使用,建議您清除相關資源,避免造成資源浪費和不必要的費用。
- 停止Notebook:在「Notebook」頁面,單擊對應範例操作列的「停止」。
- 刪除資料:點選此處,前往OBS控制檯,刪除上傳的資料,然後刪除資料夾及OBS桶。