深度覆盤-重啟 etcd 引發的異常
作者資訊:
唐聰、王超凡,騰訊雲原生產品中心技術專家,負責騰訊雲大規模 TKE 叢集和 etcd 控制面穩定性、效能和成本優化工作。
王子勇,騰訊雲專家級工程師, 騰訊雲端計算產品技術服務專家團隊負責人。
概況
作為當前中國廣泛使用的雲視訊會議產品,騰訊會議已服務超過 3 億使用者,能高並行支撐千萬級使用者同時開會。騰訊會議數百萬核心服務都部署在騰訊雲 TKE 上,通過全球多地域多叢集部署實現高可用容災。在去年使用者使用最高峰期間,為了支撐更大規模的並行線上會議的人數,騰訊會議與 TKE 等各團隊進行了一輪新的擴容。
然而,在這過程中,一個簡單的 etcd 程序重啟操作卻觸發了一個的詭異的 K8s 故障(不影響使用者開會,影響新一輪後臺擴容效率),本文介紹了我們是如何從問題現象、到問題分析、大膽猜測排除、再次復現、嚴謹驗證、根治隱患的,從 Kubernetes 到 etcd 底層原理,從 TCP RFC 草案再到核心 TCP/IP 協定棧實現,一步步定位並解決問題的詳細流程(最終定位到是特殊場景觸發了核心 Bug)。
希望通過本文,讓大家對 etcd、Kubernetes 和核心的複雜問題定位有一個較為深入的瞭解,掌握相關方法論,同時也能讓大家更好的瞭解和使用好 TKE,通過分享我們的故障處理過程,提升我們的透明度。
背景知識
首先給大家簡要介紹下騰訊會議的簡要架構圖和其使用的核心產品 TKE Serverless 架構圖。
騰訊會議極簡架構圖如下:
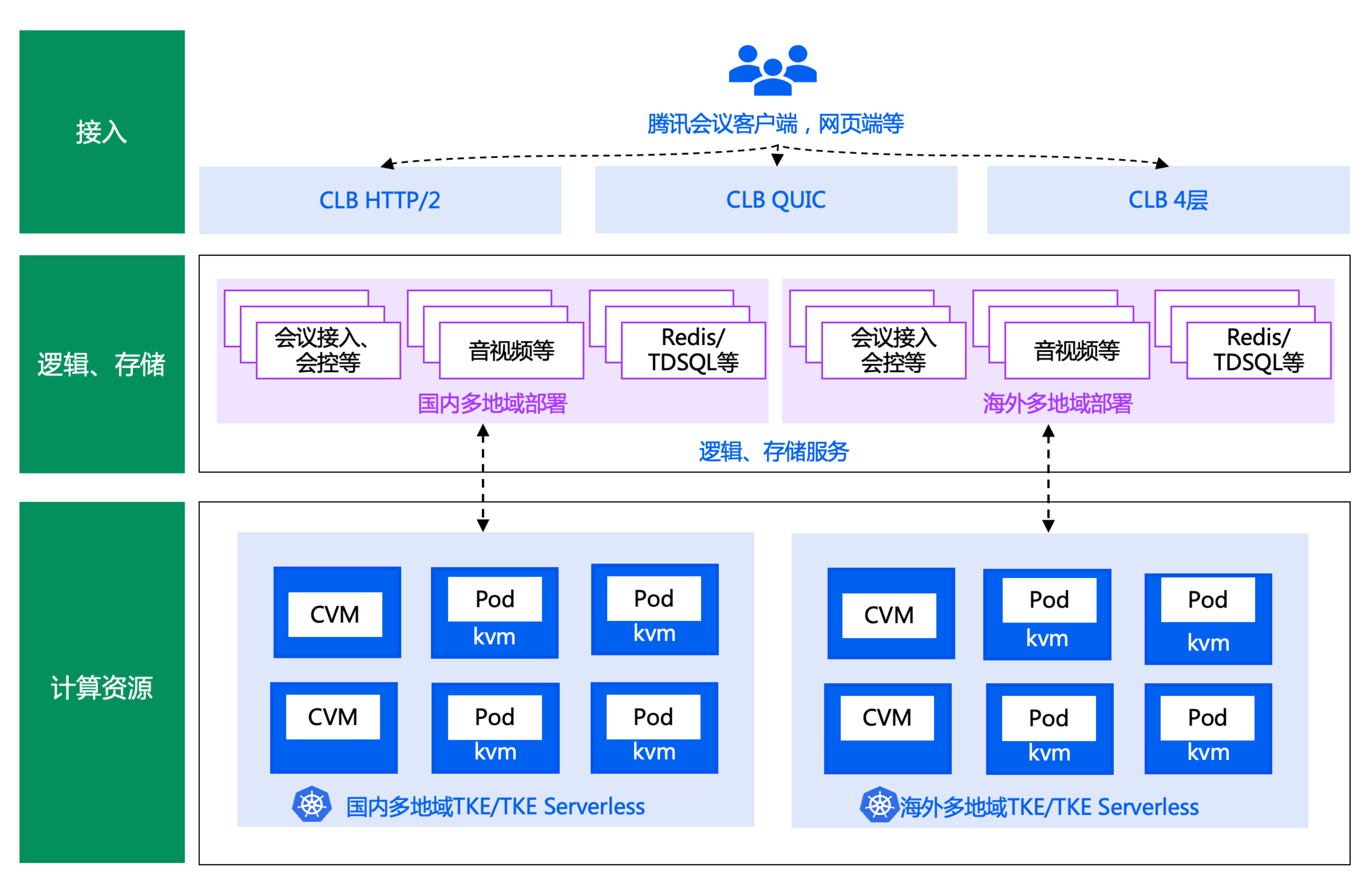
騰訊會議重度使用的 TKE Serverless 架構如下:
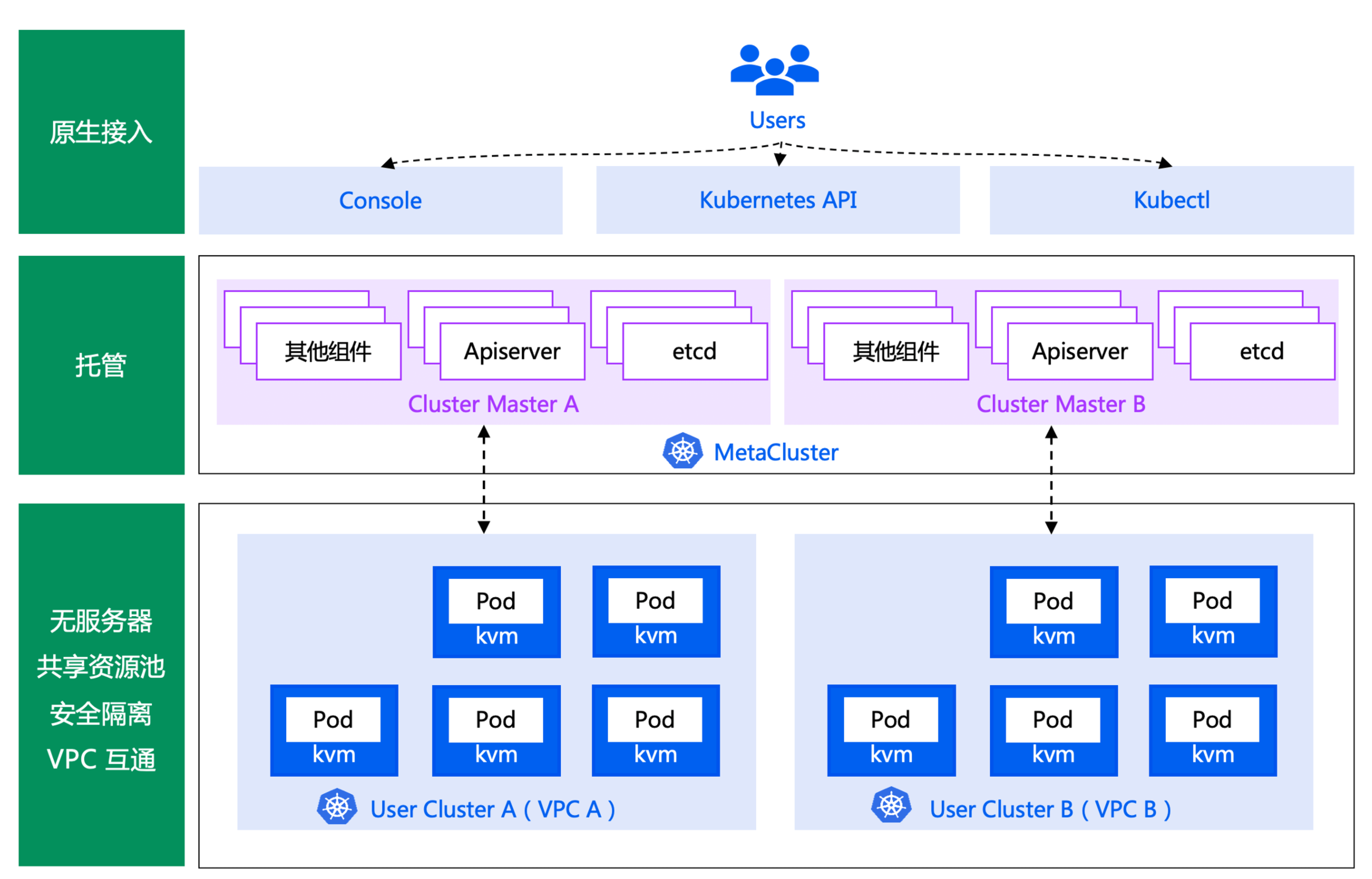
騰訊會議幾乎全部業務都跑在 TKE Serverless 產品上,Master 元件部署在我們metacluster 中(K8s in K8s),超大叢集可能有10多個 APIServer,etcd 由服務化的 etcd 平臺提供,APIServer 存取 etcd 鏈路為 svc -> cluster-ip -> etcd endpoint。業務各個 Pod 獨佔一個輕量級的虛擬機器器,安全性、隔離性高,業務無需關心任何 Kubernetes Master、Node 問題,只需要專注業務領域的開發即可。
問題現象
在一次資源擴容的過程中,騰訊會議的研發同學晚上突然在群裡反饋他們上海一個最大叢集出現了業務擴容失敗,收到反饋後研發同學,第一時間檢視後,還看到了如下異常:
● 部分 Pod 無法建立、銷燬
● 某類資源 Get、list 都是超時
● 個別元件出現了 Leader Election 錯誤
● 大部分元件正常,少部分控制器元件有如下 list pvc 資源超時紀錄檔
k8s.io/client-go/informers/factory.go:134: Failed to watch
*v1.PersistentVolumeClaim: failed to list
*v1.PersistentVolumeClaim: the server was unable to return a
response in the time allotted, but may still be processing the
request (get persistentvolumeclaims)
然而 APIServer 負載並不高,當時一線研發同學快速給出了一個控制面出現未知異常的結論。隨後 TKE 團隊快速進入攻艱模式,開始深入分析故障原因。
問題分析
研發團隊首先檢視了此叢集相關變更記錄,發現此叢集在幾個小時之前,進行了重啟 etcd 操作。變更原因是此叢集規模很大,在之前的多次擴容後,db size 使用率已經接近 80%,為了避免 etcd db 在業務新一輪擴容過程中被寫滿,因此係統進行了一個經過審批流程後的,一個常規的調大 etcd db quota 操作,並且變更後系統自檢 etcd 核心指標正常。
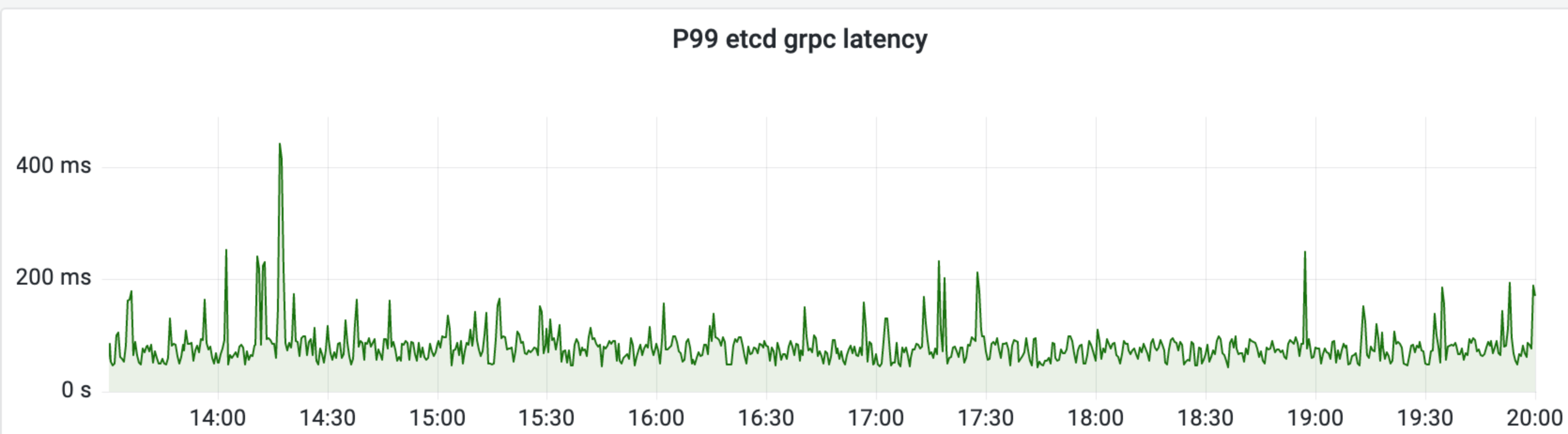
我們首先分析了 etcd 的介面延時、頻寬、watch 監控等指標,如下圖所示,
etcd P99 延時毛刺也就 500ms,節點頻寬最大的是平均 100MB/s 左右,初步看並未發現任何異常。
隨後又回到 APIServer,一個在請求在 APIServer 內部經歷的各個核心階段(如下圖所示):
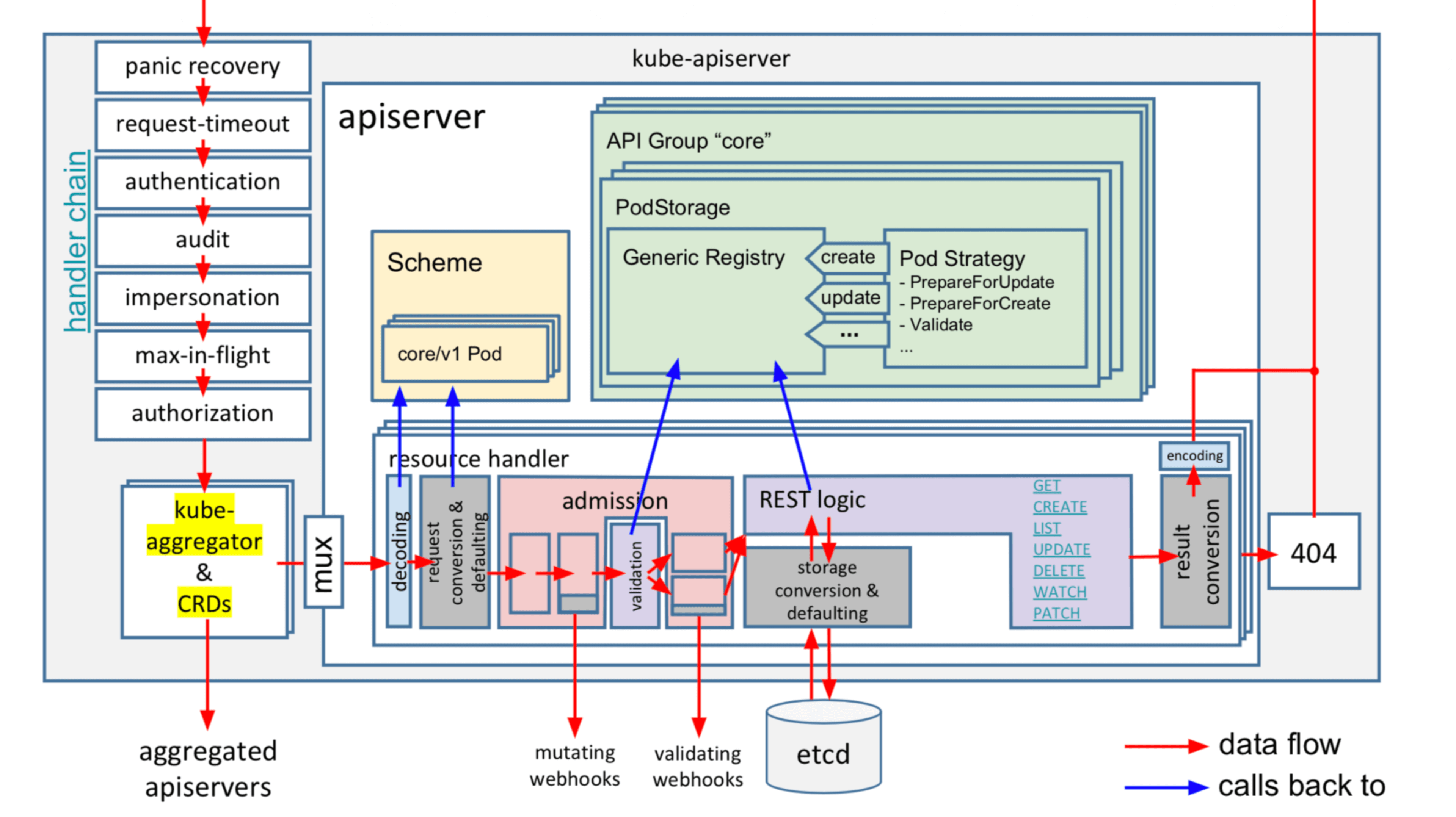
● 鑑權 (校驗使用者 token、證書是否正確)
● 審計
● 授權 (檢查是否使用者是否有許可權存取對應資源)
● 限速模組 (1.20 後是優先順序及公平管理)
● mutating webhook
● validating webhook
● storage/cache
● storage/etcd
請求在發往 APIServer 前,client 可能導致請求慢的原因:
● client-go 限速,client-go 預設 qps 5, 如果觸發限速,則紀錄檔級別 4 以上(高版本 client-go 紀錄檔級別 3 以上)可以看到使用者端紀錄檔中有列印 Throttling request took 相關紀錄檔
那到底是哪個階段出現了問題,導致 list pvc 介面超時呢?
● 根據 client QPS 很高、並且通過 kubectl 連線異常範例也能復現,排除了 client-go 限速和 client 到 apiserver 網路連線問題
● 通過審計紀錄檔搜尋到不少 PVC 資源的 Get 和 list 5XX 錯誤,聚集在其中一個範例
● 通過 APIServer Metrics 檢視和 trace 紀錄檔排除 webhook 導致的超時等
● 基於 APIServer 存取 etcd 的 Metrics、Trace 紀錄檔確定了是 storage/etcd 模組耗時很長,但是隻有一個 APIServer 範例、某類資源有問題
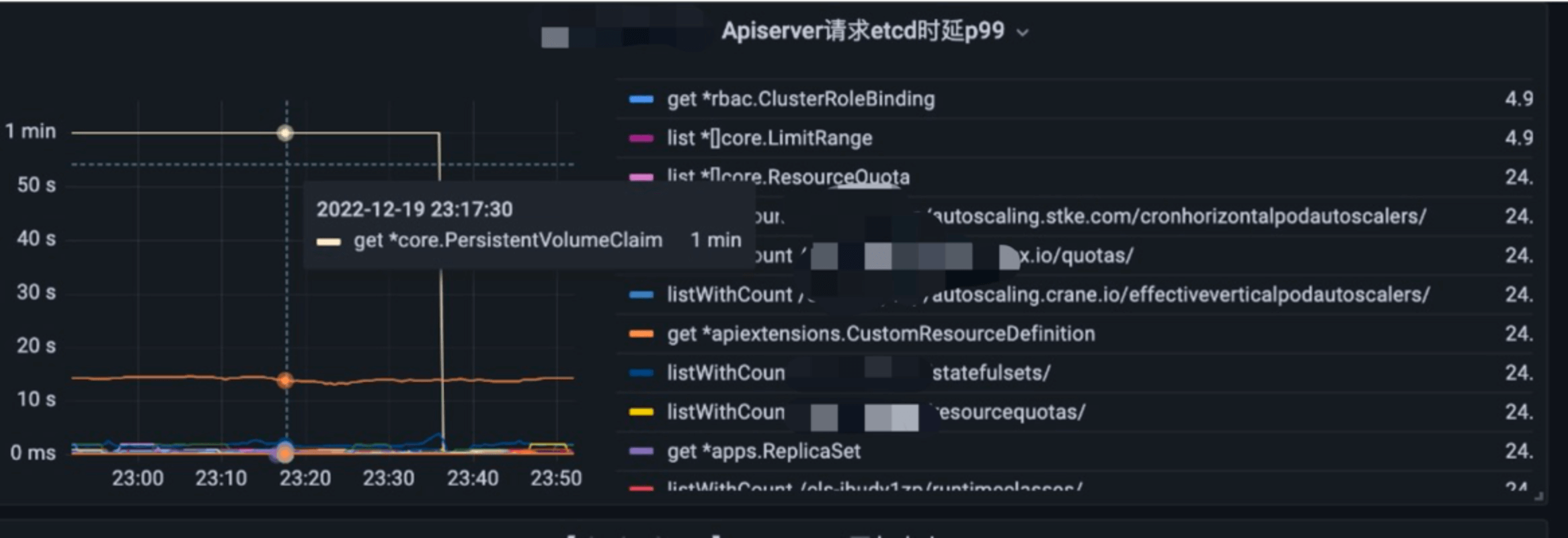
那為什麼 etcd 側看到的監控延時很低,而 APIServer 存取 etcd 延時很高,而且只是某類資源出現問題,不是所有資源呢?
首先,我們檢視下 APIServer 的 etcd 延時統計上報程式碼 (以 Get 介面為例):

它統計的是整個 Get 請求(實際呼叫的是 etcd Range 介面)從 client 發出到收到結果的耗時,包括了整個網路鏈路和 etcd RPC 邏輯處理耗時。
而 etcd 的 P99 Range 延時是基於 gRPC 攔截器機制實現的,etcd 在啟動 gRPC Server 的時候,會註冊一個一元攔截器實現延時統計,在 RPC 請求入口和執行 RPC 邏輯完成時上報延時,也就是它並不包括 RPC 請求在資料接收和傳送過程中的耗時,相關邏輯封裝在 monitor 函數中,簡要邏輯如下所示:
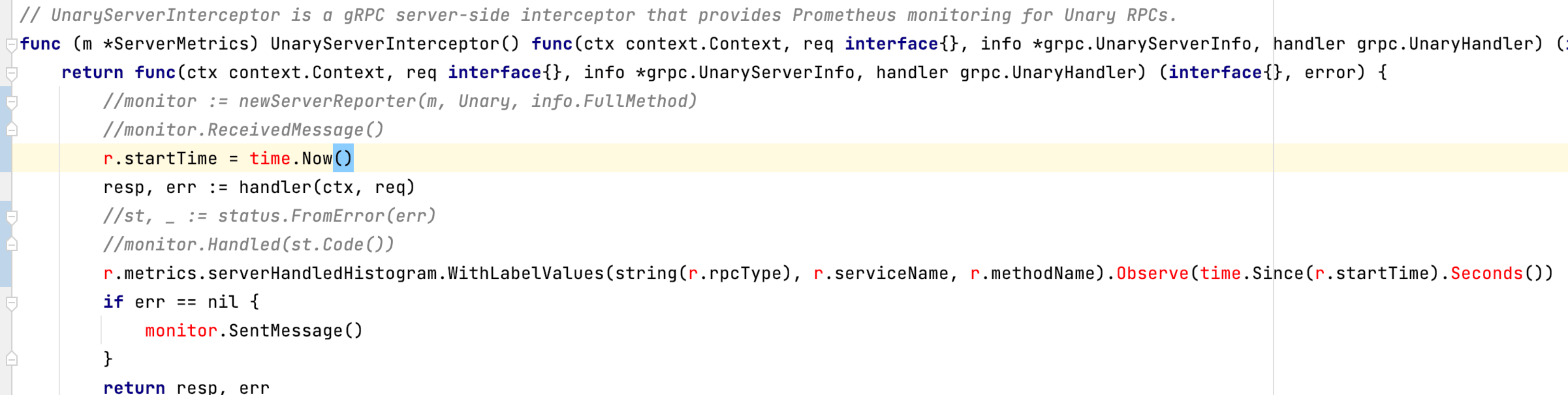
最後一個疑問為什麼是某類資源出現問題?
APIServer 在啟動的時候,會根據 Kubernetes 中的每個資源和版本建立一個獨立etcd client,並根據設定決定是否開啟 watch cache,每個 client 一般 1 個 TCP 連線,一個 APIServer 範例會高達上百個 etcd 連線。etcd client 與 etcd server 通訊使用的是 gRPC 協定,而 gRPC 協定又是基於 HTTP/2 協定的。
PVC 資源超時,Pod、Node 等資源沒超時,這說明是 PVC 資源對應的底層 TCP 連線/應用層 HTTP/2 連線出了問題。
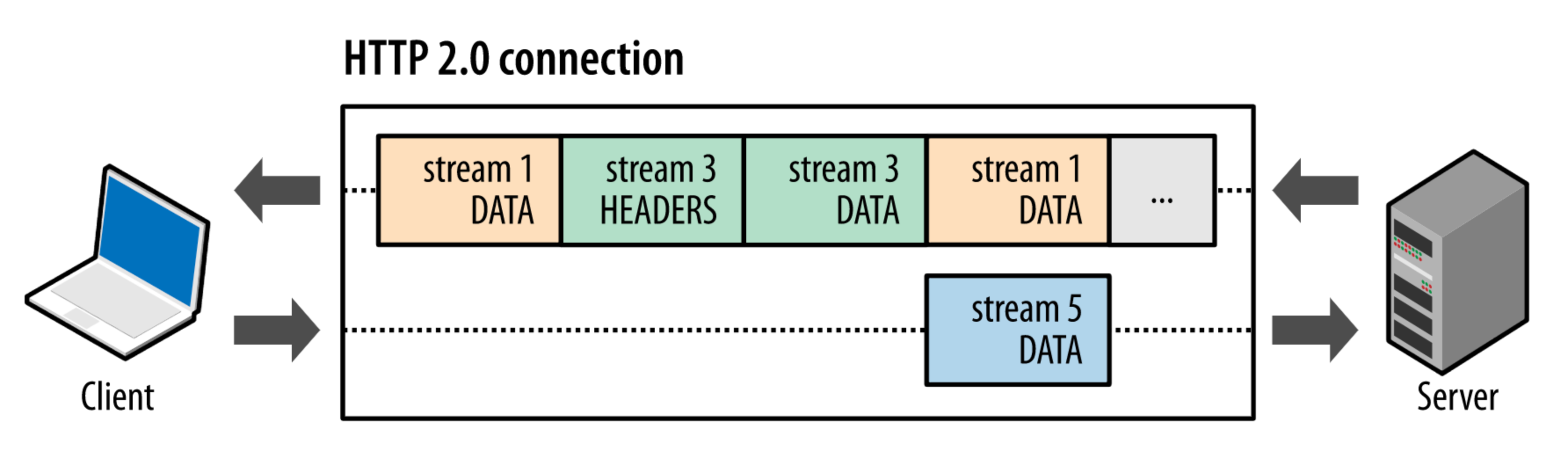
在 HTTP/2 協定中,訊息被分解獨立的幀(Frame),交錯傳送,幀是最小的資料單位。每個幀會標識屬於哪個流(Stream),流由多個資料框組成,每個流擁有一個唯一的 ID,一個資料流對應一個請求或響應包。如上圖所示,client 正在向 server 傳送資料流 5 的幀,同時 server 也正在向 client 傳送資料流 1 和資料流 3 的一系列幀。一個連線上有並行的三個資料流,HTTP/2 可基於幀的流 ID 將並行、交錯傳送的幀重新組裝成完整的訊息。
也就是,通過 HTTP/2 的多路複用機制,一個 etcd HTTP/2 連線,可以滿足高並行情況下各種 client 對 PVC 資源的查詢、建立、刪除、更新、Watch 請求。
那到底是這個連線出了什麼問題呢?
明確是 APIServer 和 etcd 的網路鏈路出現了異常之後,我們又有了如下猜測:
● 異常範例 APIServer 所在節點出現異常
● etcd 叢集 3 個節點底層網路異常
● etcd HTTP/2 連線最大並行流限制 (單 HTTP/2 連線最大同時開啟的並行流是有限制的)
● TCP 連線觸發了核心未知 bug,連線疑似 hang 住一樣
● .....
然而我們對 APIServer 和 etcd 節點進行了詳細的系統診斷、網路診斷,除了發現 etcd 節點出現了少量毛刺丟包,並未發現其他明顯問題,當前 etcd 節點也僅使用了 1/3 的節點頻寬,但是請求依然巨慢,因此基本可以排除頻寬超限導致的請求超時。
etcd HTTP/2 連線最大並行流限制的特點是此類資源含有較大的並行請求數、同時應有部分成功率,不應全部超時。然而通過我們一番深入排查,通過審計紀錄檔、Metrics 監控發現 PVC 資源的請求絕大部分都是 5XX 超時錯誤,幾乎沒有成功的,同時我們發現了一個 CR 資源也出現了連線異常,但是它的並行請求數很少。基於以上分析,etcd HTTP/2 連線最大並行流限制猜測也被排除。
問題再次陷入未知,此刻,就要寄出終極殺器——抓包大法,來分析到底整個 TCP 連線鏈路發生了什麼。
要通過抓包來分析具體請求,首先我們就要面臨一個問題,當前單個 APIServer 到 etcd 同時存在上百個連線,我們該如何縮小範圍,定位到具體異常的 TCP 連線呢?要定位到具體的異常連線,主要會面臨以下幾個問題:
- 資料量大:APIServer 大部分連線都會不停的向 etcd 請求資料,而且部分請求的資料量比較大,如果抓全量的包分析起來會比較困難。
- 新建連線無法復現:該問題隻影響個別的資源請求,也就是隻影響存量的幾個長連結,增量連線無法復現。
- APIServer 和 etcd 之間使用 https 通訊,解密困難,無法有效分析包的內容:由於長連結已經建立,已經過了 tls 握手階段,同時節點安全管控限制,短時間不允許使用 ebpf 等 hook 機制,因此無法拿到解密後的內容。
為了定位到具體的異常連線,我們做了以下幾個嘗試:
- 首先針對響應慢的資源,不經過 Loadbalancer,直接請求 APIServer 對應的 RS,將範圍縮小到具體某一個 APIServer 副本上
- 針對異常的 APIServer 副本,先將它從 Loadbalancer 的後端摘掉,一方面可以儘快恢復業務,另一方面也可以避免有新的流量進來,可以降低抓包資料量(PS:摘掉 RS 的同時,Loadbalancer 支援發雙向 RST,可以將使用者端和 APIServer 之間的長連結也斷掉)。
- 對異常的 APIServer 副本進行抓包,抓取 APIServer 請求 etcd 的流量,同時通過指令碼對該異常的 APIServer 發起並行查詢,只查詢響應慢的資源,然後對抓包資料進行分析,同一時間點 APIServer 對 etcd 有大量並行請求的長連線即為異常連線。
定位到異常連線後,接下來就是分析該連線具體為什麼異常,通過分析我們發現 etcd 回給 APIServer 的包都很小,每個 TCP 包都是 100 位元組以下:
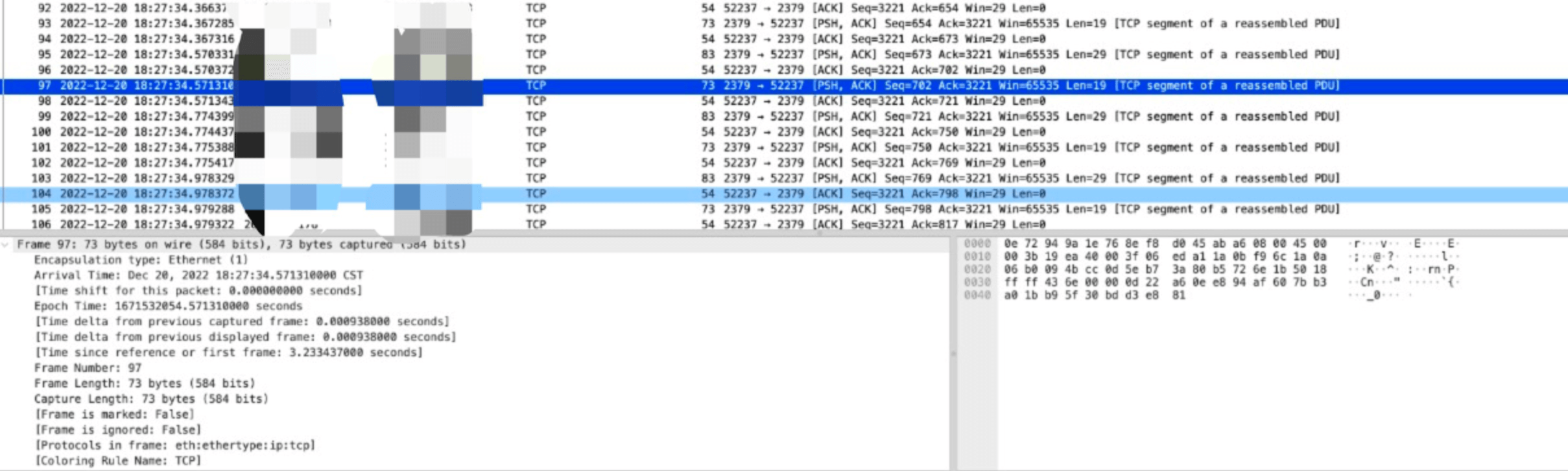
通過 ss 命令檢視連線的 TCP 引數,發現 MSS 居然只有 48 個位元組:
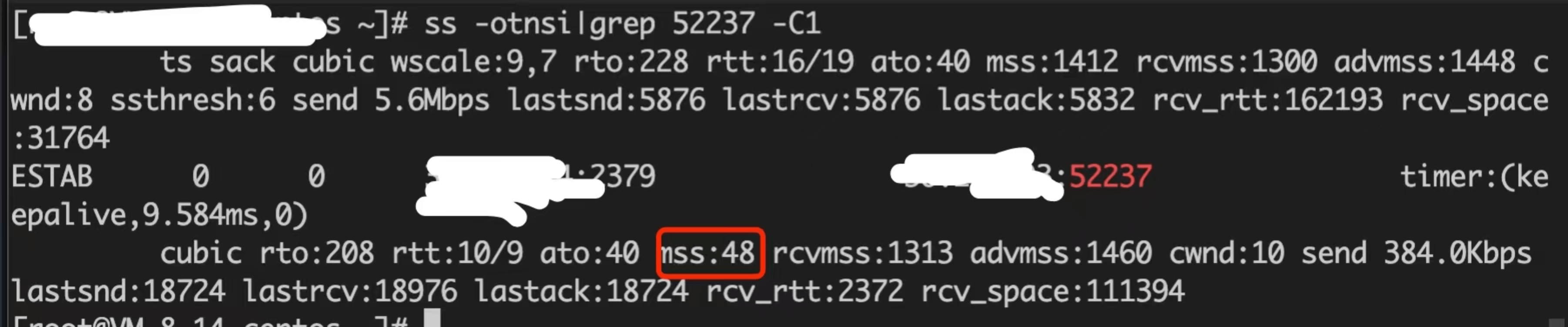
這裡簡單介紹下 TCP MSS(maximum segment size)引數, 中文名最大分段大小,單位是位元組,它限制每次網路傳輸的封包的大小,一個請求由多個封包組成,MSS 不包括 TCP 和 IP 協定包頭部分。TCP 中還有一個跟包大小的引數是 MTU(maximum transmission unit),中文名是最大傳輸單位,它是網際網路裝置(路由器等)可以接收的最巨量資料包的值,它包括 TCP 和 IP 包頭,以及 MSS。
受限於 MTU 值大小(最大1500),MTU 減去 TCP 和 IP 包頭,雲底層網路轉發所使用的協定包頭,MSS 一般在1400左右。然而在我們這裡,如下圖所示,對 ss 統計分析可以看到,有 10 幾個連線 MSS 只有 48 和 58。任意一個請求尤其是查詢類的,都會導致請求被拆分成大量小包傳送,應用層必定會出現各類超時錯誤,client 進而又會觸發各種重試,最終整個連線出現完全不可用。
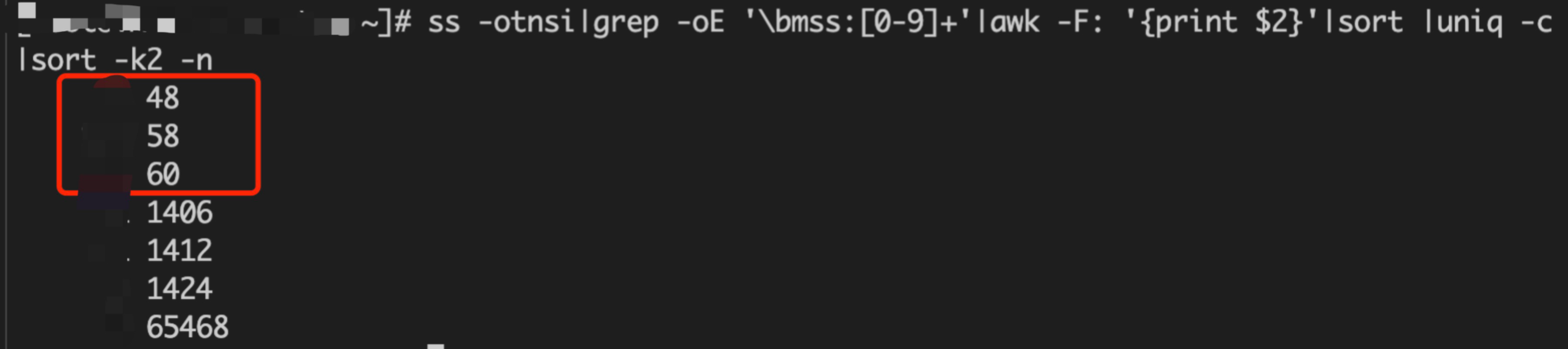
在確定是 MSS 值過小導致上層各種詭異超時現象之後,我們進一步思考,是什麼地方改掉了 MSS。然而 MSS 協商是在三次握手中建立的,存量的異常連線比較難找到相關資訊。
核心分析過程
抓包分析
為了進一步搞清楚問題發生的根本原因,我們在風險可控的情況下,在業務低峰期,凌晨1點,主動又做了一次相似的變更,來嘗試復現問題。從抓到的包看 TCP 的選項,發現 MSS 協商的都是比較大,沒有特別小的情況:

僅 SYN, SYN+ack 包帶有 MSS 選項,並且值都大於 1000, 排除底層網路裝置篡改了 MSS 造成的問題。
核心分析
那核心當中,什麼地方會修改 MSS 的值?
假設一開始不瞭解核心程式碼,但是我們能知道這個 MSS 欄位是通過 ss 命令輸出的,那麼可以從 ss 命令程式碼入手。該命令來自於 iproute2 這個包,搜尋下 MSS 關鍵詞, 可知在 ss 程式中,通過核心提供的 sock_diag netlink 介面, 查詢到的資訊。在tcp_show_info函數中做解析展示:
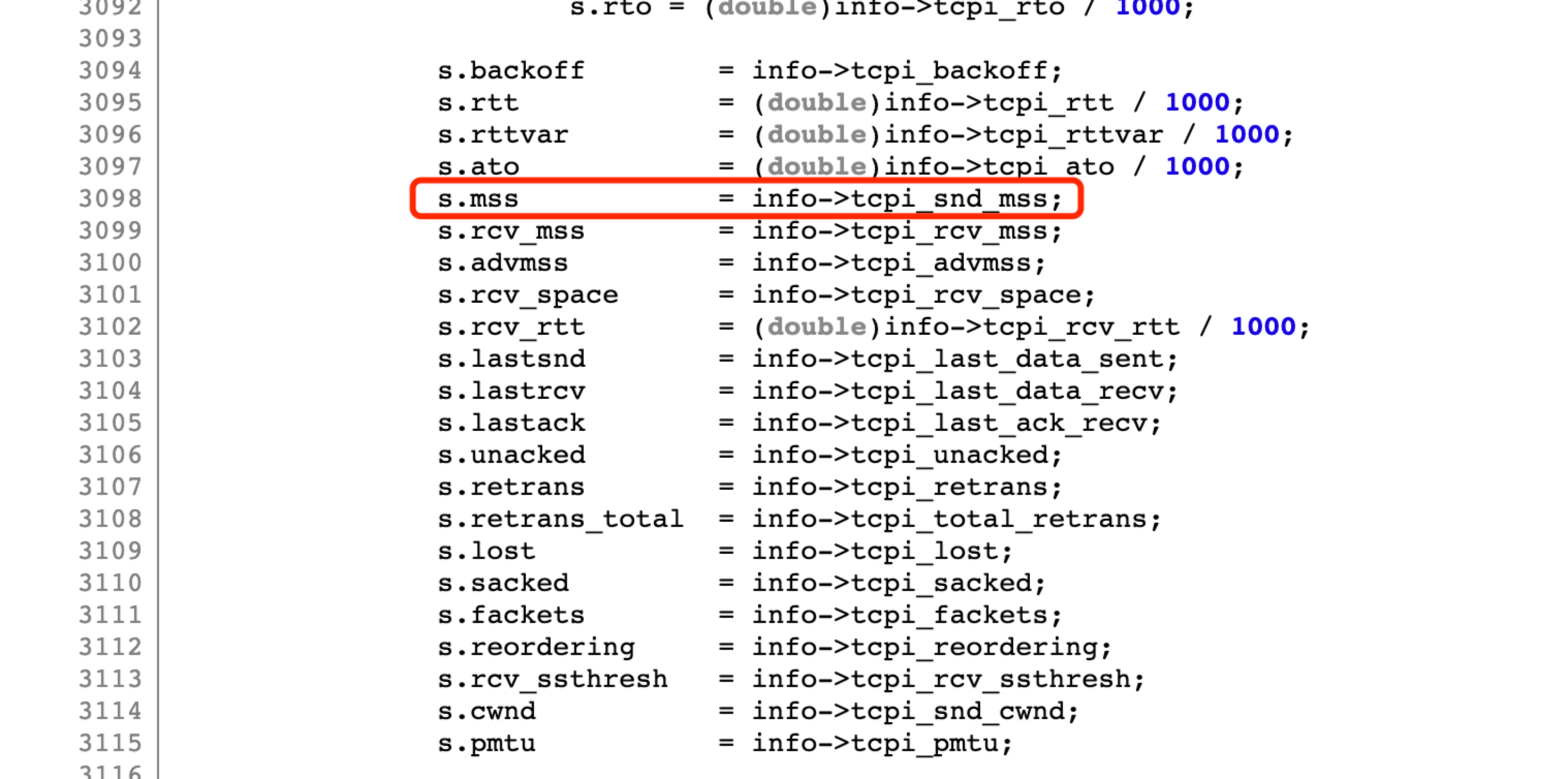
可知 MSS 欄位來自核心的 tcpi_snd_mss。
之後,從核心裡面查詢該值賦值的地方:
2 2749 net/ipv4/tcp.c <<tcp_get_info>>
info->tcpi_snd_mss = tp->mss_cache;
繼續找mss_cache的賦值位置:
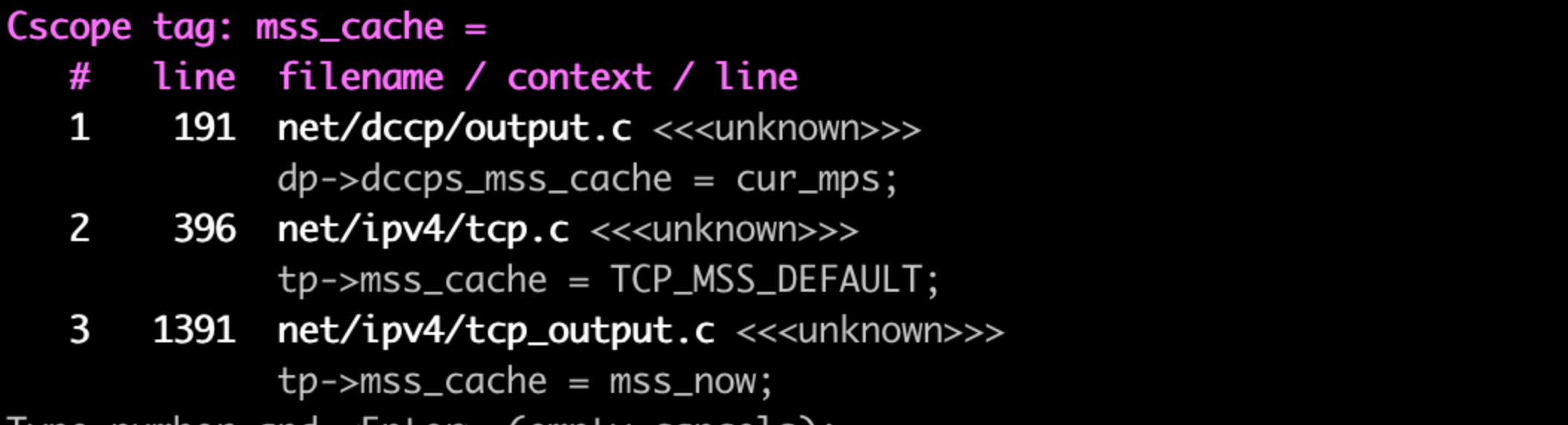
只有2處,第一處是tcp_init_sock中呼叫,當中的賦值是初始值tcp_mss_DEFAULT 536U, 與抓到的現場不匹配,直接可忽略。
第二處:
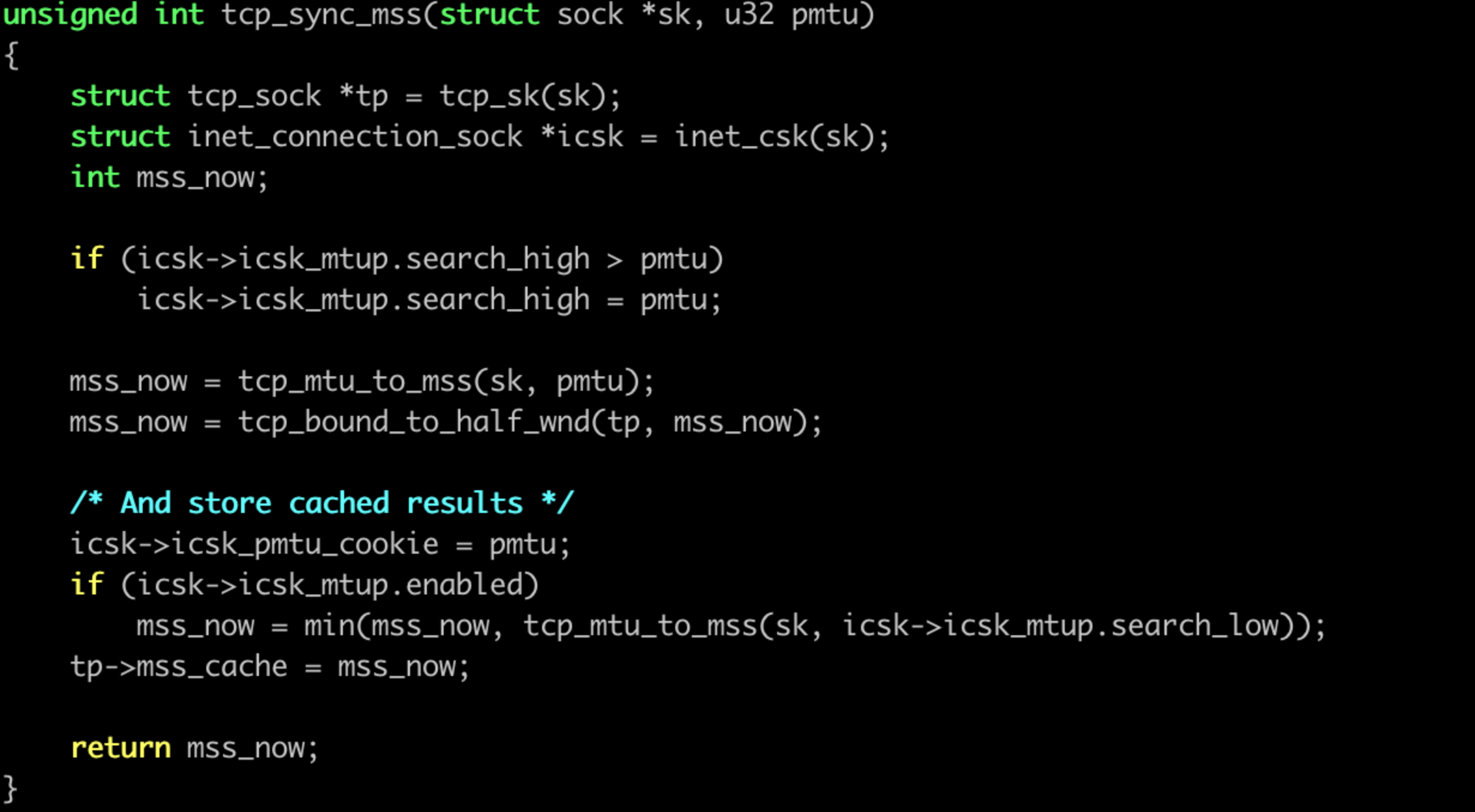
這裡面可能 2 個地方會影響,一個是pmtu, 另外一個是 tcp_bound_to_half_wnd.
抓包裡面沒明顯看到 MTU 異常造成的流異常反饋資訊。聚焦在視窗部分:
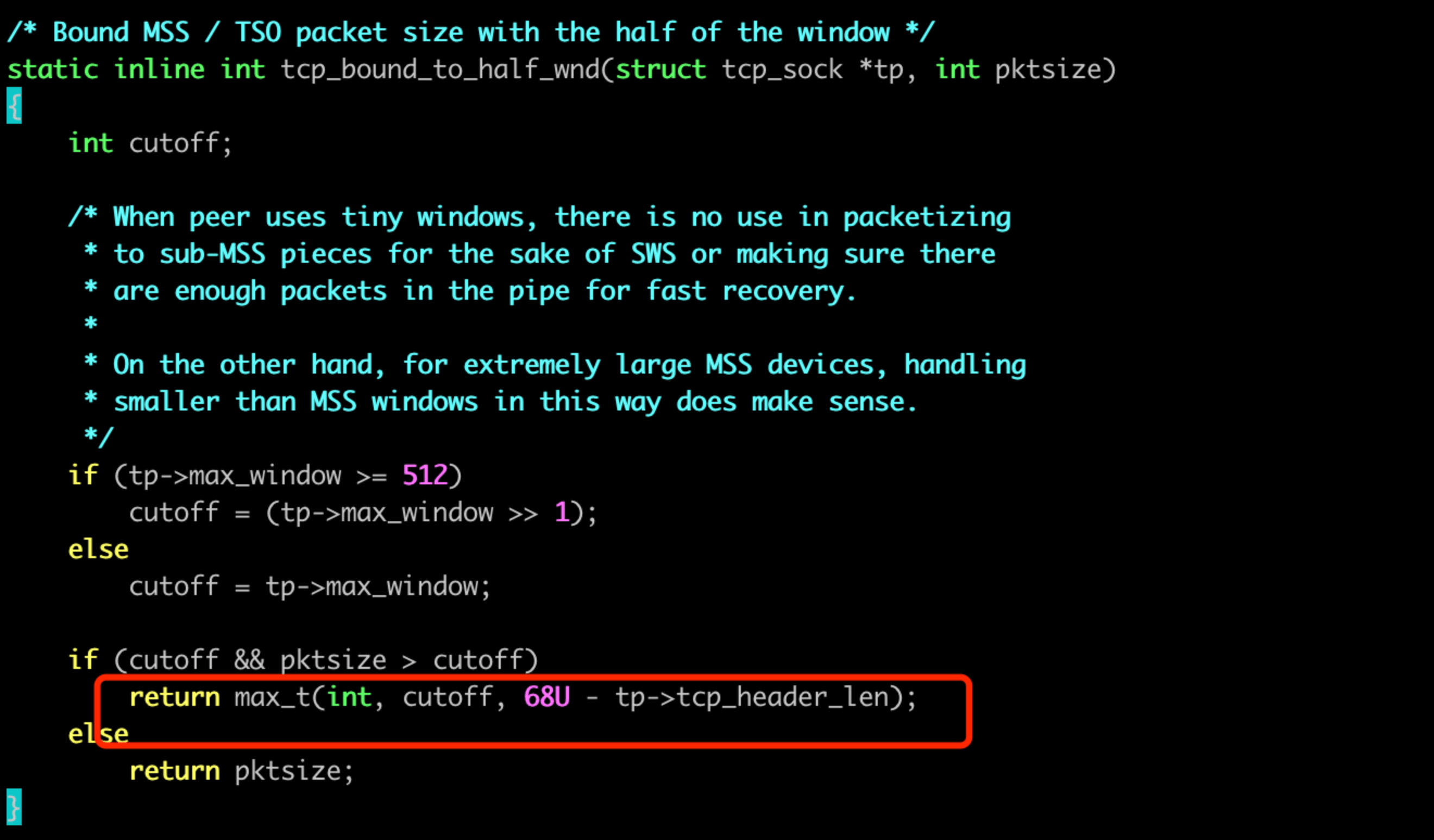
這裡有個很可疑的地方。若是視窗很小,那麼最後會取視窗與68位元組 -tcp_header_len 的最大值,tcp_header_len 預設 20 位元組的話,剛好是 48 位元組。和咱們抓包看到的最小的 MSS 為 48 一致, 嫌疑很大。
那什麼地方會修改最大視窗大小?
TCP 修改的地方並不多,tcp_rcv_synsent_state_process中收到 SYN 包修改(狀態不符合我們當前的 case),另外主要的是在tcp_ack_update_window函數中,收 ack 之後去更新:
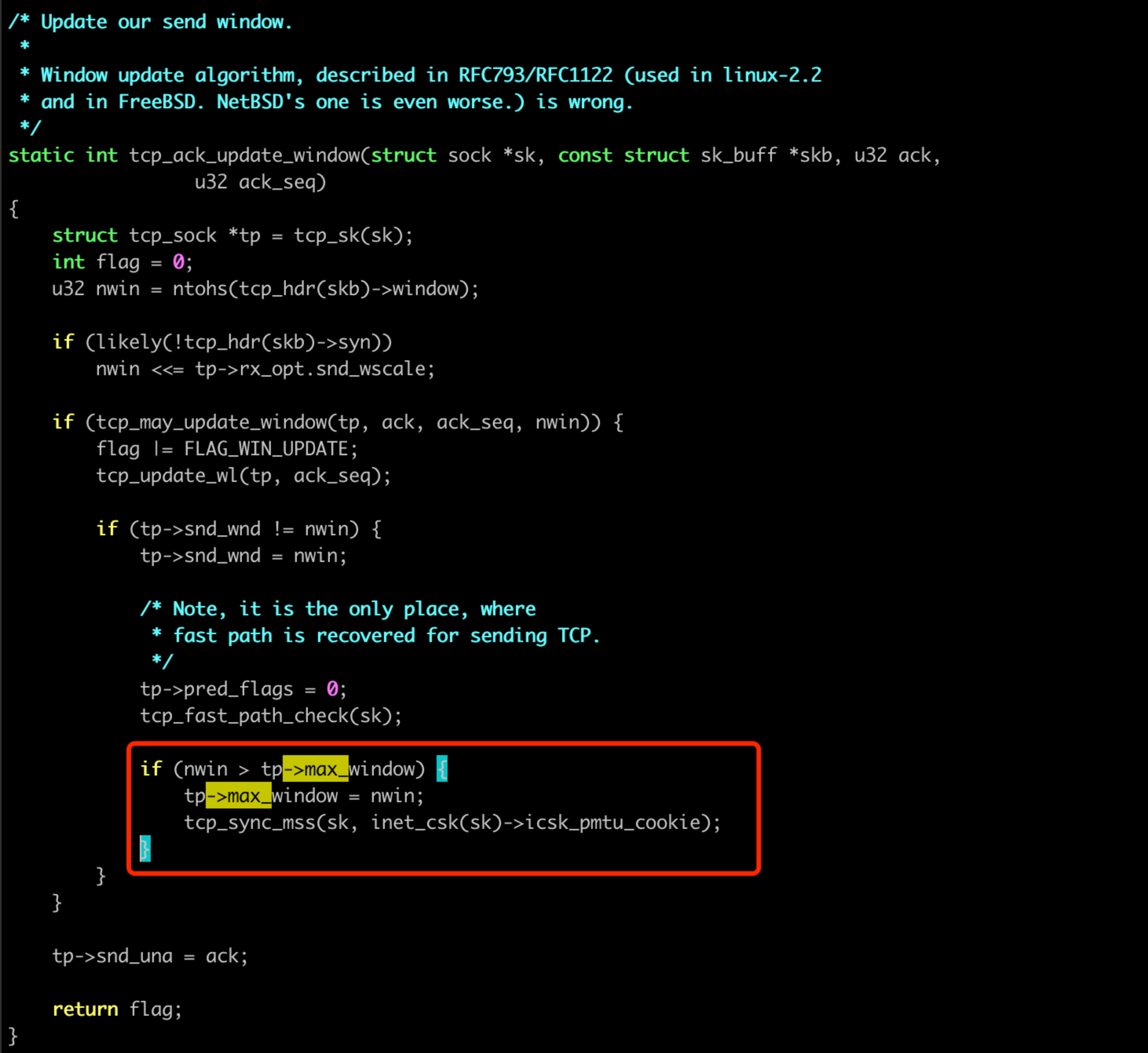
分析收到的 ack 包,我們能發現對方通告的視窗, 除了 SYN 之外,都是29位元組:
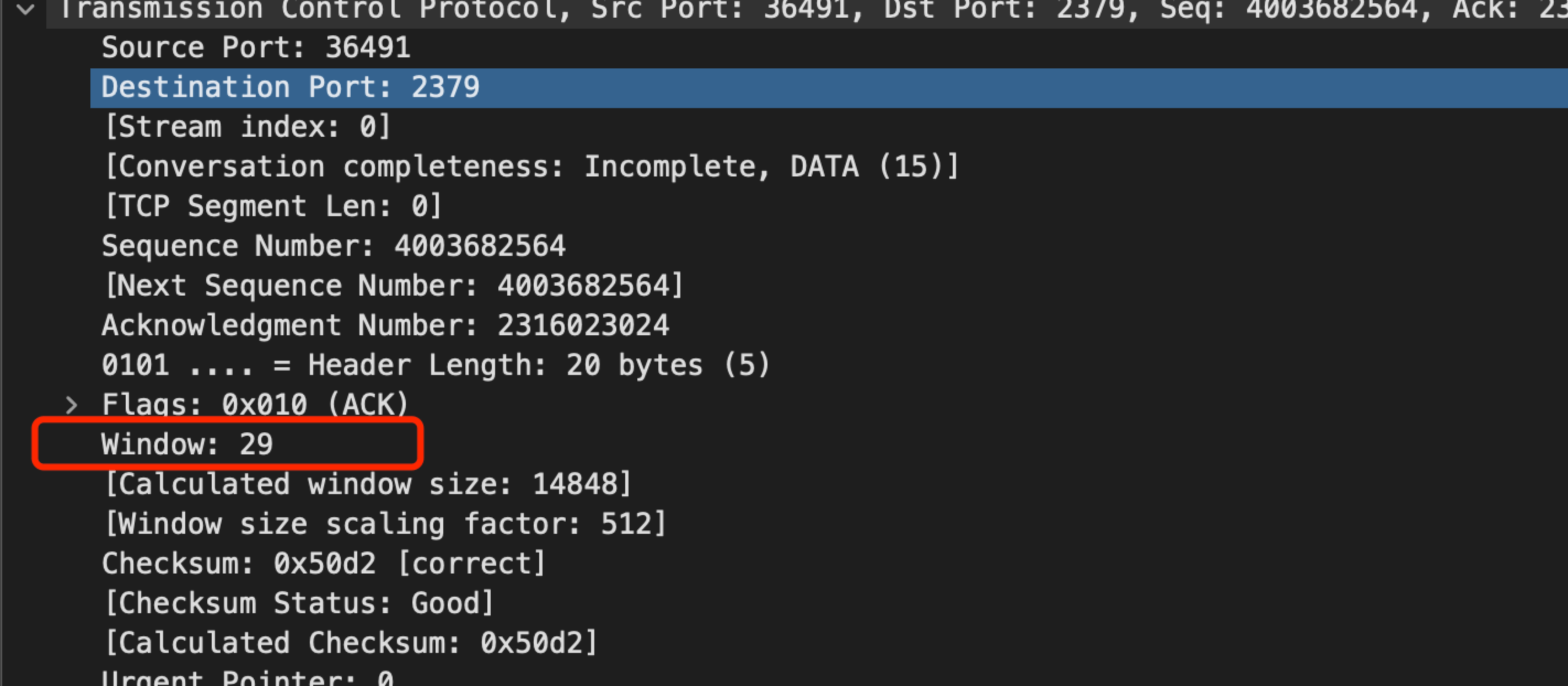
SYN 包裡面能看到放大因子是:
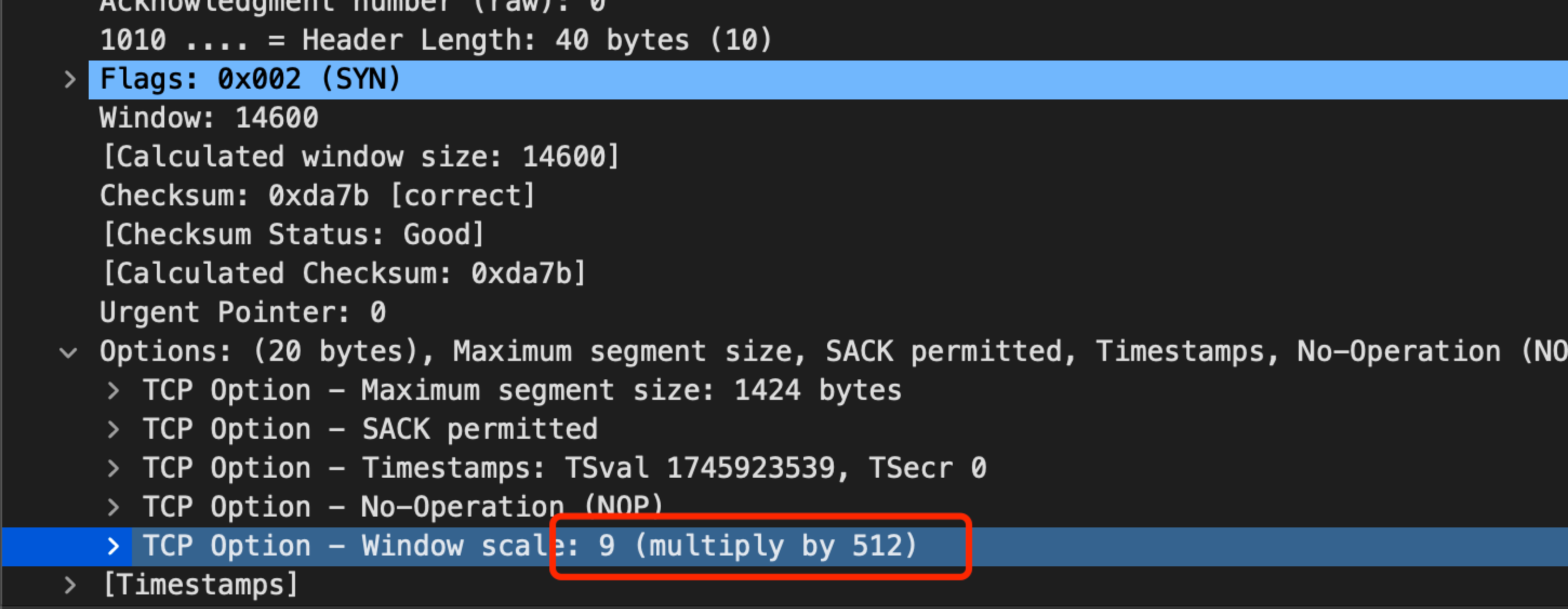
按理說,計算出來的視窗按照
if (likely(!tcp_hdr(skb)->syn))
nwin <<= tp->rx_opt.snd_wscale;
計算,應該是14848位元組,但是從 MSS 的體現看,似乎這個 scale 丟失了。實際上,對比正常和異常的連線,發現確實 TCP 的 scale 選項在核心裡面,真的丟了:

從 ss 裡面對比正常和異常的連線看,不僅僅是 window scale 沒了,連 timestamp, sack 選項也同時消失了!很神奇!
我們來看看 ss 裡面獲取的這些欄位對應到核心的什麼值:
ss 程式碼:

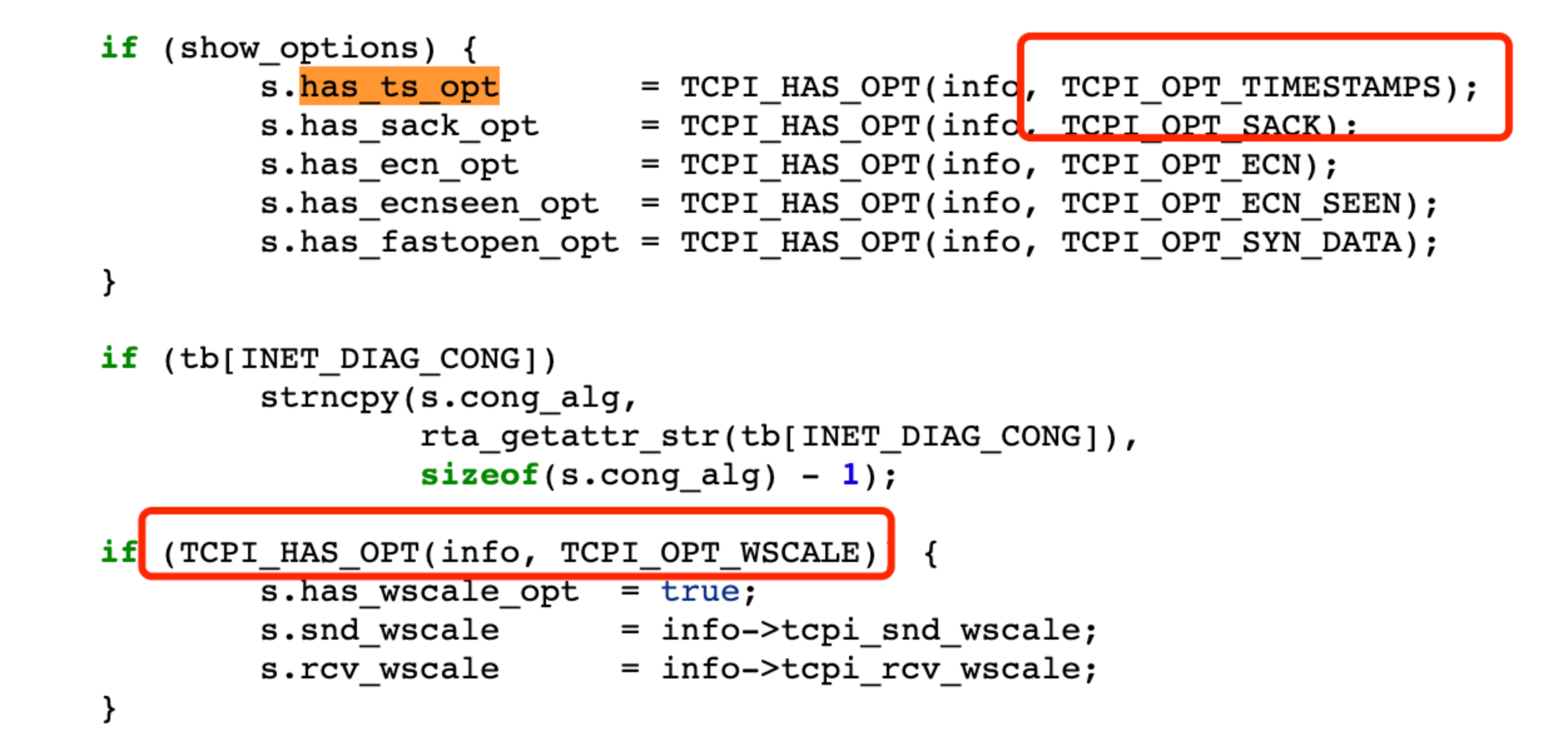
對應到核心 tcp_get_info 函數的資訊:
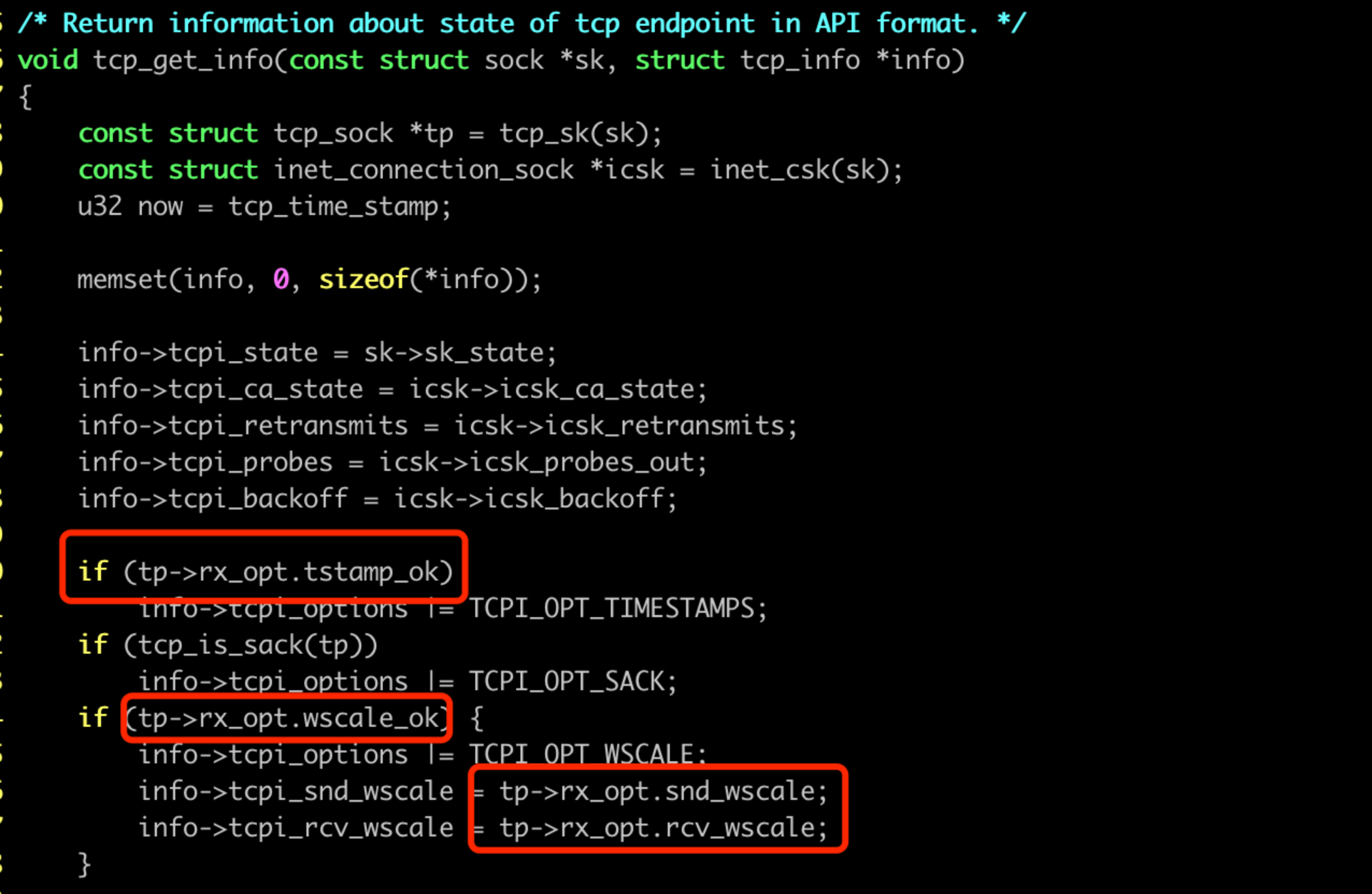
那核心什麼地方會清空 window scale 選項?
搜尋把 wscale_ok 改為 0 的地方,實際上並不多,我們可以比較輕易確定是 tcp_clear_options 函數乾的:
static inline void tcp_clear_options(struct tcp_options_received *rx_opt)
{
rx_opt->tstamp_ok = rx_opt->sack_ok = 0;
rx_opt->wscale_ok = rx_opt->snd_wscale = 0;
}
他同時會清空 ts, sack, scale 選項, 和我們的場景再匹配不過。
搜尋 tcp_clear_options 的呼叫方,主要在tcp_v4_conn_request和cookie_check_timestamp 兩個地方,具體呼叫位置的邏輯都和 SYN cookie 特性有較強關聯性。
if (want_cookie && !tmp_opt.saw_tstamp)
tcp_clear_options(&tmp_opt);
bool cookie_check_timestamp(struct tcp_options_received *tcp_opt,
struct net *net, bool *ecn_ok)
{
/* echoed timestamp, lowest bits contain options */
u32 options = tcp_opt->rcv_tsecr & TSMASK;
if (!tcp_opt->saw_tstamp) {
tcp_clear_options(tcp_opt);
return true;
}
兩個條件都比較一致,看起來是 SYN cookie 生效的情況下,對方沒有傳遞 timestamp 選項過來(實際上,按照 SYN cookie 的原理,傳送給對端的回包中,會儲存有編碼進 tsval 欄位低 6 位的選項資訊),就會呼叫 tcp_clear_options, 清空視窗放大因子等選項。
從系統紀錄檔裡面,我們也能觀察到確實觸發了 SYN cookie 邏輯:

所以,根因終於開始明確,etcd 重啟,觸發了大量 APIServer 瞬間到 etcd 的新建連線,短時間的大量新建連線觸發了 SYN cookie 保護檢查邏輯。但是因為使用者端沒有在後續包中將 timestamp 選項傳過來,造成了視窗放大因子丟失,影響傳輸效能
使用者端為什麼不在每一個包都傳送 timestamp,而是隻在第一個 SYN 包傳送?
首先,我們來看看 RFC 規範,協商了 TCP timestamp 選項後,是應該選擇性的發?還是每一個都發?

答案是,後續每一個包 TCP 包都需要帶上時間戳選項。
那麼,我們的核心中為什麼 SYN 包帶了 TCP timestamp 選項,但是後續的包沒有了呢?
搜尋 tsval 關鍵詞:

可以看到 tcp_syn_options 函數中,主動建連時候,會根據 sysctl_tcp_timestmps 設定選項決定是否開啟時間戳選項。
檢視使用者端系統,該選項確實是開啟的,符合預期:
net.ipv4.tcp_timestamps = 1
那為什麼別的包都不帶了呢?使用者端角度,發了 SYN,帶上時間戳選項,收到伺服器端 SYN+ack 以及時間戳,走到 tcp_rcv_synsent_state_process 函數中,呼叫 tcp_parse_options 解析 TCP 選項:
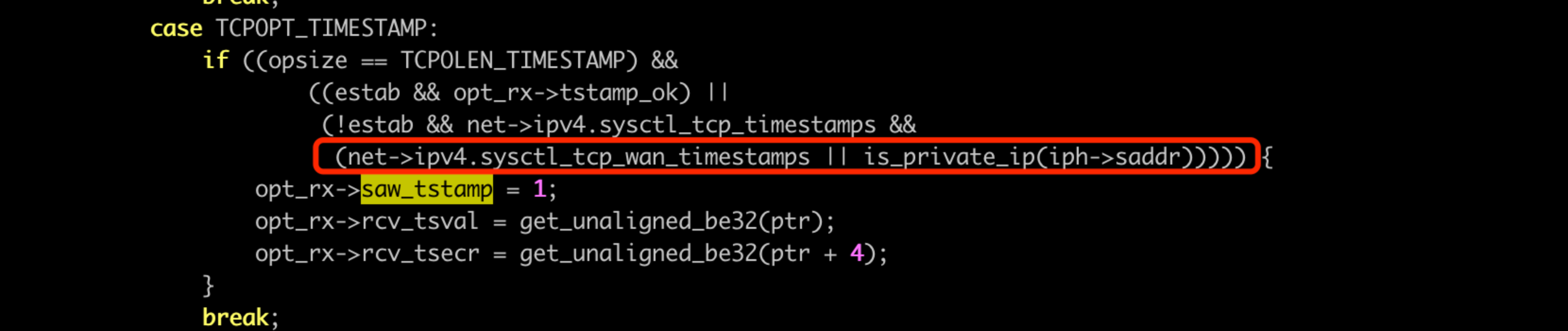
這裡,就算伺服器端回包帶了 TCP 時間戳選項,本機也要看兩個 sysctl:
● sysctl_tcp_timestamps 這個比較好理解。核心標準的。
● sysctl_tcp_wan_timestamps 這個看起來是針對外網開啟時間戳的選項?很詭異。
此處就會有坑了,如果 wan_timestamps 選項沒開啟,saw_tstamp 不會設定為1, 後續也就不會再傳送 TCP 時間戳選項。
檢視 wan_timestamps 設定,確實預設是關閉的:
net.ipv4.tcp_wan_timestamps = 0
所以這裡真相也就明確了:因為 tcp_timestamps 選項開啟,所以核心建連是會傳送時間戳選項協商,同時因為 tcp_wan_timestamps 關閉,在使用非私有網段的情況下,會造成後續的包不帶時間戳(雲環境容器管控特殊網段的原因)。
和 SYN cookie 的場景組合在一起,最終造成了 MSS 很小,效能較差的問題。
tcp_wan_timestamps 是內部的特性,是為了解決外網時間戳不正確而加的特性,TKE 團隊發現該問題後已反饋給相關團隊優化,當前已經優化完成。
總結
本文問題表象,APIServer 資源請求慢,看似比較簡單,實則在通過 APIServer Metrics 指標、etcd Metrics 指標、APIServer 和 etcd Trace 紀錄檔、審計紀錄檔、APIServer 和 etcd 原始碼深入分析後,排除了各種可疑原因,最後發現是一個非常底層的網路問題。
面對底層網路問題,在找到穩定復現的方法後,我們通過抓包神器 tcpdump,豐富強大的網路工具 iproute2 包(iproute2 包中的 ss 命令,能夠獲取 TCP 的很多底層資訊,比如 rtt,視窗因子,重傳次數等,對診斷問題很有幫助),再結合TCP RFC、linux 原始碼(程式碼面前無祕密,不管是使用者態工具還是核心態),多團隊的共同作業,成功破案。
通過此案例,更讓我們深刻體會到,永遠要對現網生產環境保持敬畏之心,任何操作都可能會引發不可預知的風險,監控系統不僅要檢測變更服務核心指標,更要對主調方的核心指標進行深入檢測。
參與本文問題定位的還有騰訊雲網路專家趙奇園、核心專家楊玉璽。
【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多幹貨!!
