【Rust學習】記憶體安全探祕:變數的所有權、參照與借用
作者:京東零售 周凱
一.前言
Rust 語言由 Mozilla 開發,最早釋出於 2014 年 9 月,是一種高效、可靠的通用高階語言。其高效不僅限於開發效率,它的執行效率也是令人稱讚的,是一種少有的兼顧開發效率和執行效率的語言。Rust語言具備如下特性:
•高效能 - Rust 速度驚人且記憶體利用率極高。由於沒有執行時和垃圾回收,它能夠勝任對效能要求特別高的服務,可以在嵌入式裝置上執行,還能輕鬆和其他語言整合。
•可靠性 - Rust 豐富的型別系統和所有權模型保證了記憶體安全和執行緒安全,讓您在編譯期就能夠消除各種各樣的錯誤。
•生產力 - Rust 擁有出色的檔案、友好的編譯器和清晰的錯誤提示資訊, 還整合了一流的工具 —— 包管理器和構建工具, 智慧地自動補全和型別檢驗的多編輯器支援, 以及自動格式化程式碼等等。
Rust最近幾年發展非常迅速,廣受一執行緒序員的歡迎,Rust有一個官方維護的模組庫(crates.io: Rust Package Registry),可以通過編譯器自帶的cargo管理工具方便的引入模組,目前crates.io上面的模組數量已經突破10萬個,仍在快速增長,此情此景彷彿過去10年node.js的發展情景再現。
12月11日,Linus Torvalds釋出了Linux6.1核心穩定版,並帶來一個重磅的新聞,即Linux6.1將包含對Rust語言的原生支援。儘管這一功能仍在構建中,不過這也意味著,在可見的將來,Linux的歷史將翻開嶄新的一頁——除了C之外,開發人員將第一次能夠使用另一種語言Rust進行核心開發。
在近幾年的討論中,是否在Linux核心中引入Rust多次成為議題。不過包括 Torvalds在內的一眾關鍵人物均對此表示了期待。早在2019年,Alex Gaynor和Geoffrey Thomas就曾於Linux Security Summit安全峰會上進行了演講。他們指出,在Android和Ubuntu中,約有三分之二的核心漏洞被分配到CVE中,這些漏洞都是來自於記憶體安全問題。原則上,Rust可以通過其type system和borrow checker所提供的更安全的API來完全避免這類錯誤。簡言之,Rust比C更安全。谷歌Android團隊的Wedson Almeida Filho也曾公開表示:「我們覺得Rust現在已經準備好加入C語言,作為實現核心的實用語言。它可以幫助我們減少特權程式碼中潛在錯誤和安全漏洞的數量,同時很好地與核心核心配合並保留其效能特徵。」
當前,谷歌在Android中廣泛使用Rust。在那裡,「目標不是將現有的C/C++轉換為Rust,而是隨著時間的推移,將新程式碼的開發轉移到記憶體安全語言」。這一言論也逐漸在實踐中得到論證。「隨著進入Android的新記憶體不安全程式碼的數量減少,記憶體安全漏洞的數量也在減少。從2019年到2022年,相關漏洞佔比已從Android總漏洞的76%下降到35%。2022年,在Android漏洞排行中,記憶體安全漏洞第一次不再是主因。」
本文將探尋相比於其他語言,Rust是怎樣實現記憶體安全的。Rust針對建立於記憶體堆上的複雜資料型別,設計了一套獨有的記憶體管理機制,該套機制包含變數的所有權機制、變數的作用域、變數的參照與借用,並專門針對字串、陣列、元組等複雜型別設計了slice型別,下面將具體講述這些機制與規則。
二.變數的所有權
Rust 的核心功能(之一)是 所有權(ownership)。雖然該功能很容易解釋,但它對語言的其他部分有著深刻的影響。
所有程式都必須管理其執行時使用計算機記憶體的方式。一些語言中具有垃圾回收機制,在程式執行時有規律地尋找不再使用的記憶體;在另一些語言中,程式設計師必須親自分配和釋放記憶體。Rust 則選擇了第三種方式:通過所有權系統管理記憶體,編譯器在編譯時會根據一系列的規則進行檢查。如果違反了任何這些規則,程式都不能編譯。在執行時,所有權系統的任何功能都不會減慢程式。
因為所有權對很多程式設計師來說都是一個新概念,需要一些時間來適應。好訊息是隨著你對 Rust 和所有權系統的規則越來越有經驗,你就越能自然地編寫出安全和高效的程式碼。持之以恆!
當你理解了所有權,你將有一個堅實的基礎來理解那些使 Rust 獨特的功能。在本章中,我們將通過完成一些範例來介紹所有權,這些範例基於一個常用的資料結構:字串。
棧(Stack)與堆(Heap)在很多語言中,你並不需要經常考慮到棧與堆。不過在像 Rust 這樣的系統程式語言中,值是位於棧上還是堆上在更大程度上影響了語言的行為以及為何必須做出這樣的抉擇。我們會在本文的稍後部分描述所有權與棧和堆相關的內容,所以這裡只是一個用來預熱的簡要解釋。棧和堆都是程式碼在執行時可供使用的記憶體,但是它們的結構不同。棧以放入值的順序儲存值並以相反順序取出值。這也被稱作 後進先出(last in, first out)。想象一下一疊盤子:當增加更多盤子時,把它們放在盤子堆的頂部,當需要盤子時,也從頂部拿走。不能從中間也不能從底部增加或拿走盤子!增加資料叫做 進棧(pushing onto the stack),而移出資料叫做 出棧(popping off the stack)。棧中的所有資料都必須佔用已知且固定的大小。在編譯時大小未知或大小可能變化的資料,要改為儲存在堆上。 堆是缺乏組織的:當向堆放入資料時,你要請求一定大小的空間。記憶體分配器(memory allocator)在堆的某處找到一塊足夠大的空位,把它標記為已使用,並返回一個表示該位置地址的 指標(pointer)。這個過程稱作 在堆上分配記憶體(allocating on the heap),有時簡稱為 「分配」(allocating)。(將資料推入棧中並不被認為是分配)。因為指向放入堆中資料的指標是已知的並且大小是固定的,你可以將該指標儲存在棧上,不過當需要實際資料時,必須存取指標。想象一下去餐館就座吃飯。當進入時,你說明有幾個人,餐館員工會找到一個夠大的空桌子並領你們過去。如果有人來遲了,他們也可以通過詢問來找到你們坐在哪。入棧比在堆上分配記憶體要快,因為(入棧時)分配器無需為儲存新資料去搜尋記憶體空間;其位置總是在棧頂。相比之下,在堆上分配記憶體則需要更多的工作,這是因為分配器必須首先找到一塊足夠存放資料的記憶體空間,並接著做一些記錄為下一次分配做準備。存取堆上的資料比存取棧上的資料慢,因為必須通過指標來存取。現代處理器在記憶體中跳轉越少就越快(快取)。繼續類比,假設有一個服務員在餐廳裡處理多個桌子的點菜。在一個桌子報完所有菜後再移動到下一個桌子是最有效率的。從桌子 A 聽一個菜,接著桌子 B 聽一個菜,然後再桌子 A,然後再桌子 B 這樣的流程會更加緩慢。出於同樣原因,處理器在處理的資料彼此較近的時候(比如在棧上)比較遠的時候(比如可能在堆上)能更好的工作。當你的程式碼呼叫一個函數時,傳遞給函數的值(包括可能指向堆上資料的指標)和函數的區域性變數被壓入棧中。當函數結束時,這些值被移出棧。跟蹤哪部分程式碼正在使用堆上的哪些資料,最大限度的減少堆上的重複資料的數量,以及清理堆上不再使用的資料確保不會耗盡空間,這些問題正是所有權系統要處理的。一旦理解了所有權,你就不需要經常考慮棧和堆了,不過明白了所有權的主要目的就是為了管理堆資料,能夠幫助解釋為什麼所有權要以這種方式工作。
2.1.所有權規則
首先,讓我們看一下所有權的規則。當我們通過舉例說明時,請謹記這些規則:
Rust 中的每一個值都有一個 所有者(owner)。值在任一時刻有且只有一個所有者。當所有者(變數)離開作用域,這個值將被丟棄。
2.2.變數作用域
既然我們已經掌握了基本語法,將不會在之後的例子中包含 fn main() { 程式碼,所以如果你是一路跟過來的,必須手動將之後例子的程式碼放入一個 main 函數中。這樣,例子將顯得更加簡明,使我們可以關注實際細節而不是樣板程式碼。
在所有權的第一個例子中,我們看看一些變數的 作用域(scope)。作用域是一個項(item)在程式中有效的範圍。假設有這樣一個變數:
let s = "hello";
變數 s 繫結到了一個字串字面值,這個字串值是寫死程序式程式碼中的。這個變數從宣告的點開始直到當前 作用域 結束時都是有效的。範例 1 中的註釋標明瞭變數 s 在何處是有效的。
{ // s 在這裡無效, 它尚未宣告
let s = "hello"; // 從此處起,s 是有效的
// 使用 s
} // 此作用域已結束,s 不再有效
範例 1:一個變數和其有效的作用域
換句話說,這裡有兩個重要的時間點:
•當 s 進入作用域 時,它就是有效的。
•這一直持續到它 離開作用域 為止 。
目前為止,變數是否有效與作用域的關係跟其他程式語言是類似的。現在我們在此基礎上介紹 String 型別。
2.3.String 型別
為了演示所有權的規則,我們需要一個比基本資料型別都要複雜的資料型別。前面介紹的型別都是已知大小的,可以儲存在棧中,並且當離開作用域時被移出棧,如果程式碼的另一部分需要在不同的作用域中使用相同的值,可以快速簡單地複製它們來建立一個新的獨立範例。不過我們需要尋找一個儲存在堆上的資料來探索 Rust 是如何知道該在何時清理資料的。
我們會專注於 String 與所有權相關的部分。這些方面也同樣適用於標準庫提供的或你自己建立的其他複雜資料型別。
我們已經見過字串字面值,即被寫死程序式裡的字串值。字串字面值是很方便的,不過它們並不適合使用文字的每一種場景。原因之一就是它們是不可變的。另一個原因是並非所有字串的值都能在編寫程式碼時就知道:例如,要是想獲取使用者輸入並儲存該怎麼辦呢?為此,Rust 有第二個字串型別,String。這個型別管理被分配到堆上的資料,所以能夠儲存在編譯時未知大小的文字。可以使用 from 函數基於字串字面值來建立 String,如下:
let s = String::from("hello");
這兩個冒號 :: 是運運算元,允許將特定的 from 函數置於 String 型別的名稱空間(namespace)下,而不需要使用類似 string_from 這樣的名字。
可以 修改此類字串 :
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() 在字串後追加字面值
println!("{}", s); // 將列印 `hello, world!`
那麼這裡有什麼區別呢?為什麼 String 可變而字面值卻不行呢?區別在於兩個型別對記憶體的處理上。
2.4.記憶體與分配
就字串字面值來說,我們在編譯時就知道其內容,所以文字被直接寫死進最終的可執行檔案中。這使得字串字面值快速且高效。不過這些特性都只得益於字串字面值的不可變性。不幸的是,我們不能為了每一個在編譯時大小未知的文字而將一塊記憶體放入二進位制檔案中,並且它的大小還可能隨著程式執行而改變。
對於 String 型別,為了支援一個可變,可增長的文字片段,需要在堆上分配一塊在編譯時未知大小的記憶體來存放內容。這意味著:
•必須在執行時向記憶體分配器(memory allocator)請求記憶體。
•需要一個當我們處理完 String 時將記憶體返回給分配器的方法。
第一部分由我們完成:當呼叫 String::from 時,它的實現 (implementation) 請求其所需的記憶體。這在程式語言中是非常通用的。
然而,第二部分實現起來就各有區別了。在有 垃圾回收(garbage collector,GC)的語言中, GC 記錄並清除不再使用的記憶體,而我們並不需要關心它。在大部分沒有 GC 的語言中,識別出不再使用的記憶體並呼叫程式碼顯式釋放就是我們的責任了,跟請求記憶體的時候一樣。從歷史的角度上說正確處理記憶體回收曾經是一個困難的程式設計問題。如果忘記回收了會浪費記憶體。如果過早回收了,將會出現無效變數。如果重複回收,這也是個 bug。我們需要精確的為一個 allocate 配對一個 free。
Rust 採取了一個不同的策略:記憶體在擁有它的變數離開作用域後就被自動釋放。下面是範例 1 中作用域例子的一個使用 String 而不是字串字面值的版本:
{
let s = String::from("hello"); // 從此處起,s 是有效的
// 使用 s
} // 此作用域已結束,
// s 不再有效
這是一個將 String 需要的記憶體返回給分配器的很自然的位置:當 s 離開作用域的時候。當變數離開作用域,Rust 為我們呼叫一個特殊的函數。這個函數叫做 drop,在這裡 String 的作者可以放置釋放記憶體的程式碼。Rust 在結尾的 } 處自動呼叫 drop。
注意:在 C++ 中,這種 item 在生命週期結束時釋放資源的模式有時被稱作 資源獲取即初始化(Resource Acquisition Is Initialization (RAII))。如果你使用過 RAII 模式的話應該對 Rust 的 drop 函數並不陌生。
這個模式對編寫 Rust 程式碼的方式有著深遠的影響。現在它看起來很簡單,不過在更復雜的場景下程式碼的行為可能是不可預測的,比如當有多個變數使用在堆上分配的記憶體時。現在讓我們探索一些這樣的場景。
2.4.1.變數與資料互動的方式(一):移動
在Rust 中,多個變數可以採取不同的方式與同一資料進行互動。讓我們看看範例 2 中一個使用整型的例子。
let x = 5;
let y = x;
範例 2:將變數 x 的整數值賦給 y
我們大致可以猜到這在幹什麼:「將 5 繫結到 x;接著生成一個值 x 的拷貝並繫結到 y」。現在有了兩個變數,x 和 y,都等於 5。這也正是事實上發生了的,因為整數是有已知固定大小的簡單值,所以這兩個 5 被放入了棧中。
現在看看這個 String 版本:
let s1 = String::from("hello");
let s2 = s1;
這看起來與上面的程式碼非常類似,所以我們可能會假設他們的執行方式也是類似的:也就是說,第二行可能會生成一個 s1 的拷貝並繫結到 s2 上。不過,事實上並不完全是這樣。
看看圖1 以瞭解 String 的底層會發生什麼。String 由三部分組成,如圖左側所示:一個指向存放字串內容記憶體的指標,一個長度,和一個容量。這一組資料儲存在棧上。右側則是堆上存放內容的記憶體部分。
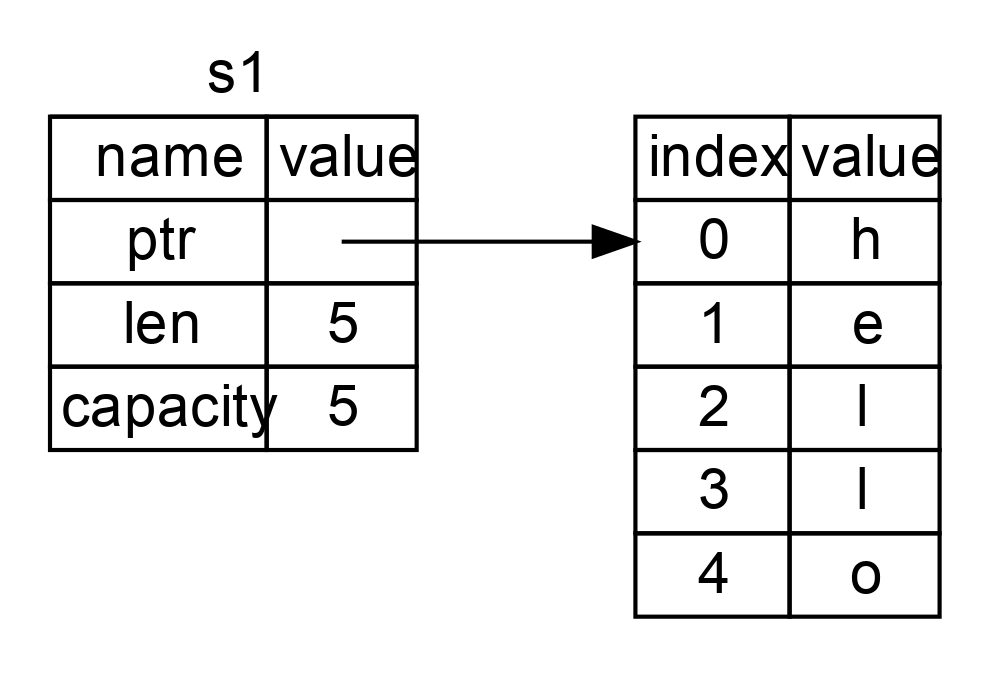
圖 1:將值 "hello" 繫結給 s1 的 String 在記憶體中的表現形式
長度表示 String 的內容當前使用了多少位元組的記憶體。容量是 String 從分配器總共獲取了多少位元組的記憶體。長度與容量的區別是很重要的,不過在當前上下文中並不重要,所以現在可以忽略容量。
當我們將 s1 賦值給 s2,String 的資料被複制了,這意味著我們從棧上拷貝了它的指標、長度和容量。我們並沒有複製指標指向的堆上資料。換句話說,記憶體中資料的表現如圖2 所示。
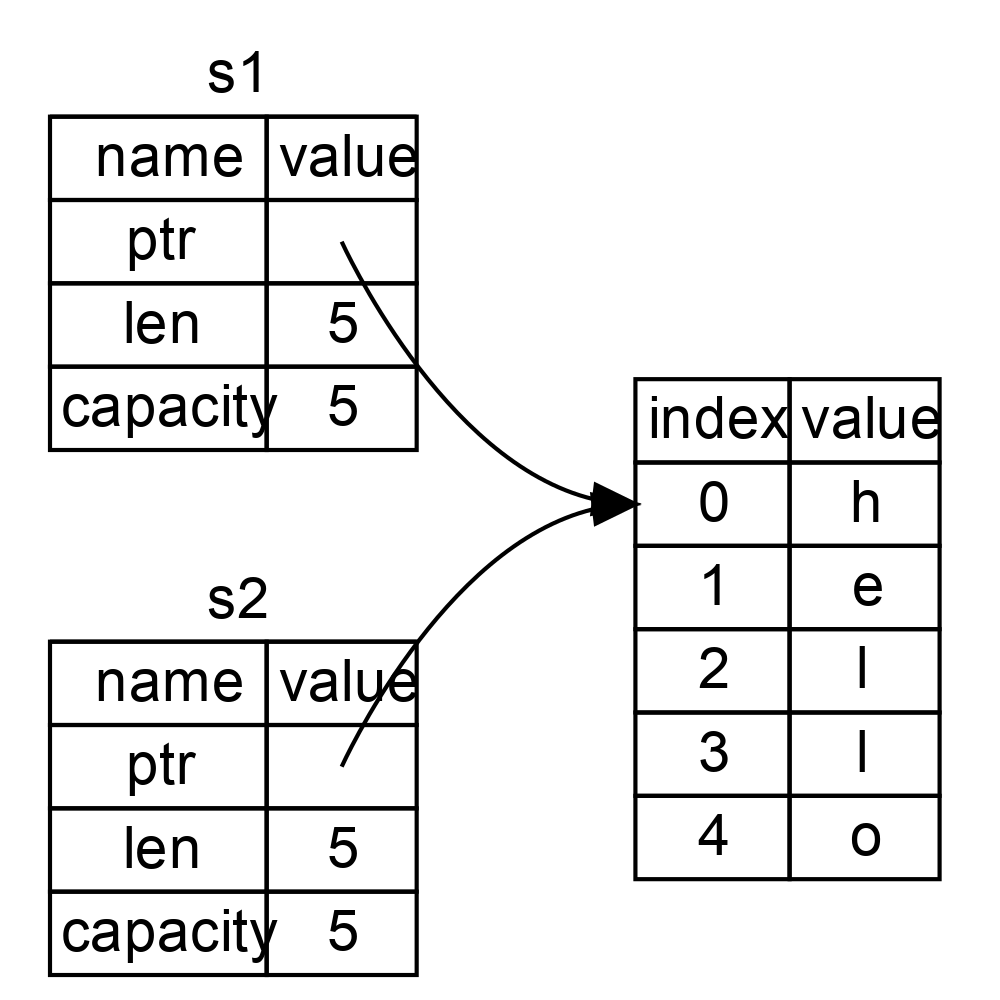
圖 2:變數 s2 的記憶體表現,它有一份 s1 指標、長度和容量的拷貝
這個表現形式看起來 並不像 圖3 中的那樣,如果 Rust 也拷貝了堆上的資料,那麼記憶體看起來就是這樣的。如果 Rust 這麼做了,那麼操作 s2 = s1 在堆上資料比較大的時候會對執行時效能造成非常大的影響。
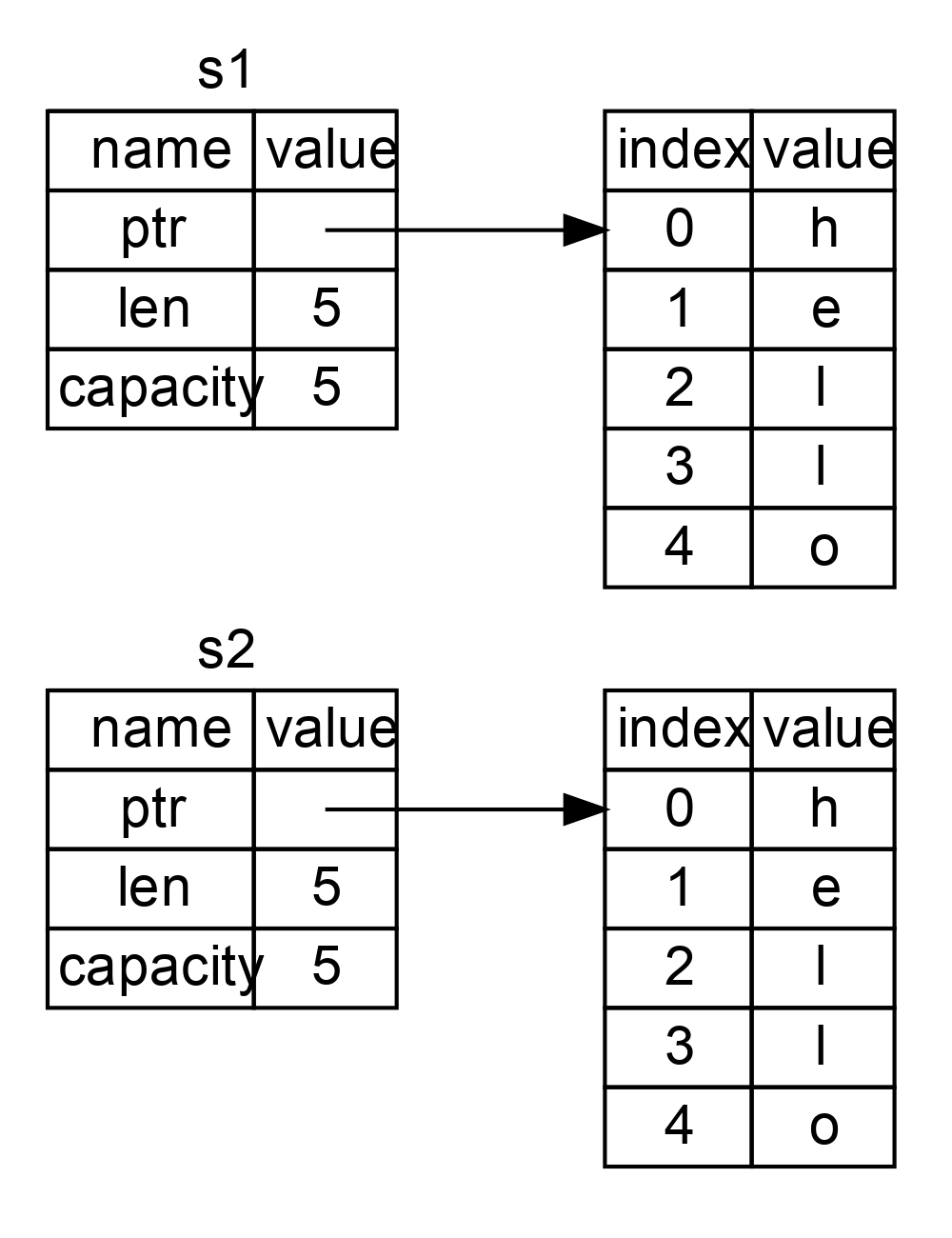
圖 3:另一個 s2 = s1 時可能的記憶體表現,如果 Rust 同時也拷貝了堆上的資料的話
之前我們提到過當變數離開作用域後,Rust 自動呼叫 drop 函數並清理變數的堆記憶體。不過圖 2 展示了兩個資料指標指向了同一位置。這就有了一個問題:當 s2 和 s1 離開作用域,他們都會嘗試釋放相同的記憶體。這是一個叫做 二次釋放(double free)的錯誤,也是之前提到過的記憶體安全性 bug 之一。兩次釋放(相同)記憶體會導致記憶體汙染,它可能會導致潛在的安全漏洞。
為了確保記憶體安全,在 let s2 = s1 之後,Rust 認為 s1 不再有效,因此 Rust 不需要在 s1 離開作用域後清理任何東西。看看在 s2 被建立之後嘗試使用 s1 會發生什麼;這段程式碼不能執行:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
你會得到一個類似如下的錯誤,因為 Rust 禁止你使用無效的參照。
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:28
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{}, world!", s1);
| ^^ value borrowed here after move
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` due to previous error
如果你在其他語言中聽說過術語 淺拷貝(shallow copy)和 深拷貝(deep copy),那麼拷貝指標、長度和容量而不拷貝資料可能聽起來像淺拷貝。不過因為 Rust 同時使第一個變數無效了,這個操作被稱為 移動(move),而不是淺拷貝。上面的例子可以解讀為 s1被 移動 到了 s2 中。那麼具體發生了什麼,如圖 4 所示。
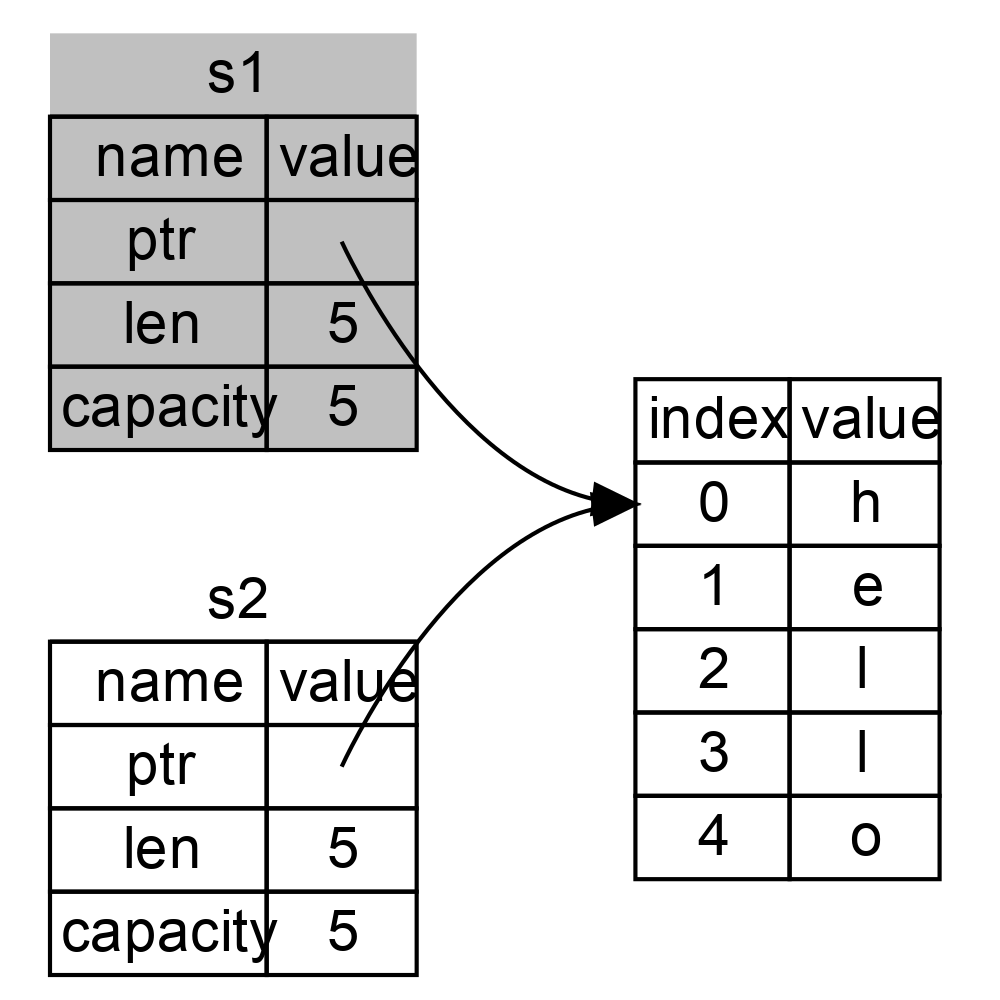
圖 4:s1 無效之後的記憶體表現
這樣就解決了我們的問題!因為只有 s2 是有效的,當其離開作用域,它就釋放自己的記憶體,完畢。
另外,這裡還隱含了一個設計選擇:Rust 永遠也不會自動建立資料的 「深拷貝」。因此,任何 自動 的複製可以被認為對執行時效能影響較小。
2.4.2.變數與資料互動的方式(二):克隆
如果我們 確實 需要深度複製 String 中堆上的資料,而不僅僅是棧上的資料,可以使用一個叫做 clone 的通用函數。第五章會討論方法語法,不過因為方法在很多語言中是一個常見功能,所以之前你可能已經見過了。
這是一個實際使用 clone 方法的例子:
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);
這段程式碼能正常執行,並且明確產生圖 3 中行為,這裡堆上的資料 確實 被複制了。
當出現 clone 呼叫時,你知道一些特定的程式碼被執行而且這些程式碼可能相當消耗資源。你很容易察覺到一些不尋常的事情正在發生。
2.4.3.只在棧上的資料:拷貝
這裡還有一個沒有提到的小竅門。這些程式碼使用了整型並且是有效的,他們是範例 2 中的一部分:
let x = 5;
let y = x;
println!("x = {}, y = {}", x, y);
但這段程式碼似乎與我們剛剛學到的內容相矛盾:沒有呼叫 clone,不過 x 依然有效且沒有被移動到 y 中。
原因是像整型這樣的在編譯時已知大小的型別被整個儲存在棧上,所以拷貝其實際的值是快速的。這意味著沒有理由在建立變數 y 後使 x 無效。換句話說,這裡沒有深淺拷貝的區別,所以這裡呼叫 clone 並不會與通常的淺拷貝有什麼不同,我們可以不用管它。
Rust 有一個叫做 Copy trait 的特殊註解,可以用在類似整型這樣的儲存在棧上的型別上。如果一個型別實現了 Copy trait,那麼一箇舊的變數在將其賦值給其他變數後仍然可用。
Rust 不允許自身或其任何部分實現了 Drop trait 的型別使用 Copy trait。如果我們對其值離開作用域時需要特殊處理的型別使用 Copy 註解,將會出現一個編譯時錯誤。
那麼哪些型別實現了 Copy trait 呢?你可以檢視給定型別的檔案來確認,不過作為一個通用的規則,任何一組簡單標量值的組合都可以實現 Copy,任何不需要分配記憶體或某種形式資源的型別都可以實現 Copy 。如下是一些 Copy 的型別:
•所有整數型別,比如 u32。
•布林型別,bool,它的值是 true 和 false。
•所有浮點數型別,比如 f64。
•字元型別,char。
•元組,當且僅當其包含的型別也都實現 Copy 的時候。比如,(i32, i32) 實現了 Copy,但 (i32, String) 就沒有。
2.5.所有權與函數
將值傳遞給函數與給變數賦值的原理相似。向函數傳遞值可能會移動或者複製,就像賦值語句一樣。範例 3 使用註釋展示變數何時進入和離開作用域:
檔名: src/main.rs
fn main() {
let s = String::from("hello"); // s 進入作用域
takes_ownership(s); // s 的值移動到函數裡 ...
// ... 所以到這裡不再有效
let x = 5; // x 進入作用域
makes_copy(x); // x 應該移動函數裡,
// 但 i32 是 Copy 的,
// 所以在後面可繼續使用 x
} // 這裡, x 先移出了作用域,然後是 s。但因為 s 的值已被移走,
// 沒有特殊之處
fn takes_ownership(some_string: String) { // some_string 進入作用域
println!("{}", some_string);
} // 這裡,some_string 移出作用域並呼叫 `drop` 方法。
// 佔用的記憶體被釋放
fn makes_copy(some_integer: i32) { // some_integer 進入作用域
println!("{}", some_integer);
} // 這裡,some_integer 移出作用域。沒有特殊之處
範例 3:帶有所有權和作用域註釋的函數
當嘗試在呼叫 takes_ownership 後使用 s 時,Rust 會丟擲一個編譯時錯誤。這些靜態檢查使我們免於犯錯。試試在 main 函數中新增使用 s 和 x 的程式碼來看看哪裡能使用他們,以及所有權規則會在哪裡阻止我們這麼做。
2.6.返回值與作用域
返回值也可以轉移所有權。範例 4 展示了一個返回了某些值的範例,與範例 3 一樣帶有類似的註釋。
檔名: src/main.rs
fn main() {
let s1 = gives_ownership(); // gives_ownership 將返回值
// 轉移給 s1
let s2 = String::from("hello"); // s2 進入作用域
let s3 = takes_and_gives_back(s2); // s2 被移動到
// takes_and_gives_back 中,
// 它也將返回值移給 s3
} // 這裡, s3 移出作用域並被丟棄。s2 也移出作用域,但已被移走,
// 所以什麼也不會發生。s1 離開作用域並被丟棄
fn gives_ownership() -> String { // gives_ownership 會將
// 返回值移動給
// 呼叫它的函數
let some_string = String::from("yours"); // some_string 進入作用域.
some_string // 返回 some_string
// 並移出給呼叫的函數
//
}
// takes_and_gives_back 將傳入字串並返回該值
fn takes_and_gives_back(a_string: String) -> String { // a_string 進入作用域
//
a_string // 返回 a_string 並移出給呼叫的函數
}
範例 4: 轉移返回值的所有權
變數的所有權總是遵循相同的模式:將值賦給另一個變數時移動它。當持有堆中資料值的變數離開作用域時,其值將通過 drop 被清理掉,除非資料被移動為另一個變數所有。
雖然這樣是可以的,但是在每一個函數中都獲取所有權並接著返回所有權有些囉嗦。如果我們想要函數使用一個值但不獲取所有權該怎麼辦呢?如果我們還要接著使用它的話,每次都傳進去再返回來就有點煩人了,除此之外,我們也可能想返回函數體中產生的一些資料。
我們可以使用元組來返回多個值,如範例 5 所示。
檔名: src/main.rs
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() 返回字串的長度
(s, length)
}
範例 5: 返回引數的所有權
但是這未免有些形式主義,而且這種場景應該很常見。幸運的是,Rust 對此提供了一個不用獲取所有權就可以使用值的功能,叫做 參照(references)。
三.參照與借用
範例 5 中的元組程式碼有這樣一個問題:我們必須將 String 返回給呼叫函數,以便在呼叫 calculate_length 後仍能使用 String,因為 String 被移動到了 calculate_length 內。相反我們可以提供一個 String 值的參照(reference)。參照(reference)像一個指標,因為它是一個地址,我們可以由此存取儲存於該地址的屬於其他變數的資料。 與指標不同,參照確保指向某個特定型別的有效值。
下面是如何定義並使用一個(新的)calculate_length 函數,它以一個物件的參照作為引數而不是獲取值的所有權:
檔名: src/main.rs
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{}' is {}.", s1, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
首先,注意變數宣告和函數返回值中的所有元組程式碼都消失了。其次,注意我們傳遞 &s1 給 calculate_length,同時在函數定義中,我們獲取 &String 而不是 String。這些 & 符號就是 參照,它們允許你使用值但不獲取其所有權。圖 5 展示了一張示意圖。
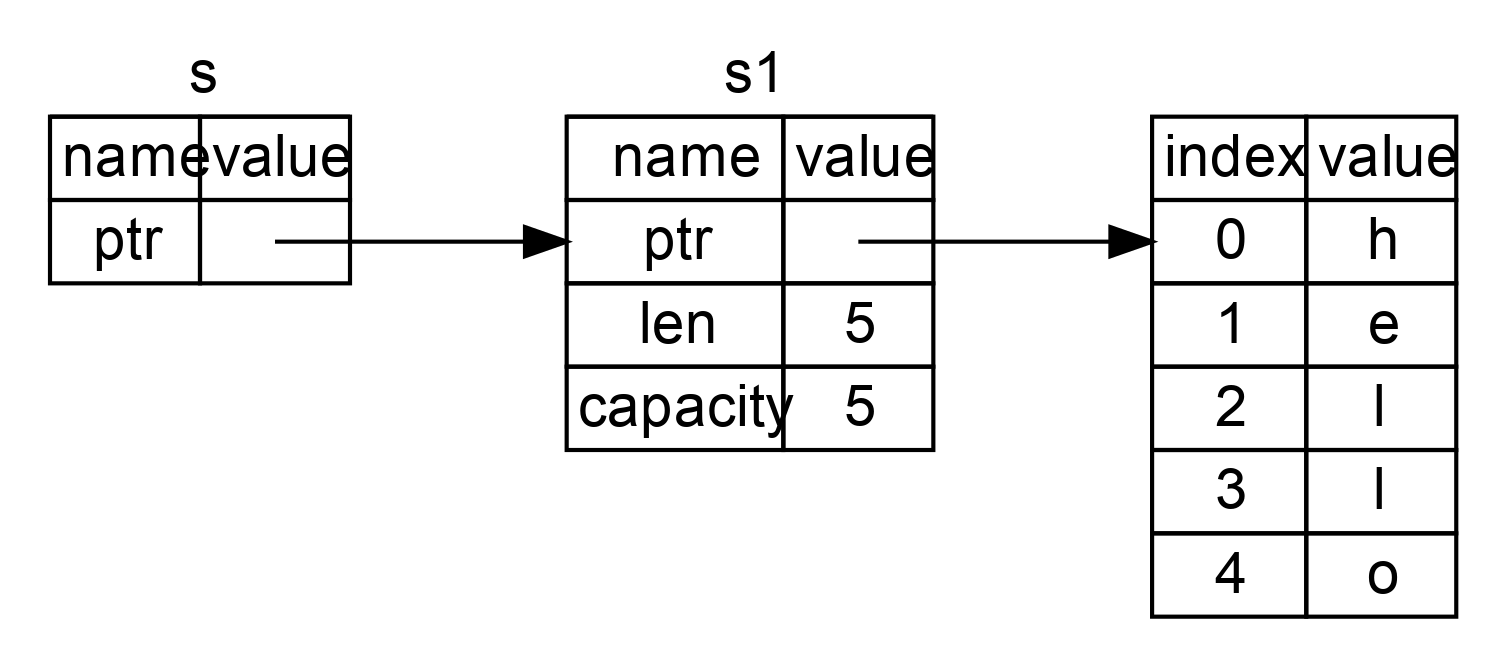
圖 5:&String s 指向 String s1 示意圖
注意:與使用 & 參照相反的操作是 解除參照(dereferencing),它使用解除參照運運算元,*。我們將會在第八章遇到一些解除參照運運算元,並在第十五章詳細討論解除參照。
仔細看看這個函數呼叫:
let s1 = String::from("hello");
let len = calculate_length(&s1);
&s1 語法讓我們建立一個 指向 值 s1 的參照,但是並不擁有它。因為並不擁有這個值,所以當參照停止使用時,它所指向的值也不會被丟棄。
同理,函數簽名使用 & 來表明引數 s 的型別是一個參照。讓我們增加一些解釋性的註釋:
fn calculate_length(s: &String) -> usize { // s是String的參照
s.len()
} // 這裡,s 離開了作用域。但因為它並不擁有參照值的所有權,
// 所以什麼也不會發生
變數 s 有效的作用域與函數引數的作用域一樣,不過當 s 停止使用時並不丟棄參照指向的資料,因為 s 並沒有所有權。當函數使用參照而不是實際值作為引數,無需返回值來交還所有權,因為就不曾擁有所有權。
我們將建立一個參照的行為稱為 借用(borrowing)。正如現實生活中,如果一個人擁有某樣東西,你可以從他那裡借來。當你使用完畢,必須還回去。我們並不擁有它。
如果我們嘗試修改借用的變數呢?嘗試範例 6 中的程式碼。劇透:這行不通!
檔名: src/main.rs
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}
範例 6:嘗試修改借用的值
這裡是錯誤:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
7 | fn change(some_string: &String) {
| ------- help: consider changing this to be a mutable reference: `&mut String`
8 | some_string.push_str(", world");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` due to previous error
正如變數預設是不可變的,參照也一樣。(預設)不允許修改參照的值。
3.1.可變參照
我們通過一個小調整就能修復範例 6 程式碼中的錯誤,允許我們修改一個借用的值,這就是 可變參照(mutable reference):
檔名: src/main.rs
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
首先,我們必須將 s 改為 mut。然後在呼叫 change 函數的地方建立一個可變參照 &mut s,並更新函數簽名以接受一個可變參照 some_string: &mut String。這就非常清楚地表明,change 函數將改變它所借用的值。
可變參照有一個很大的限制:如果你有一個對該變數的可變參照,你就不能再建立對該變數的參照。這些嘗試建立兩個 s 的可變參照的程式碼會失敗:
檔名: src/main.rs
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
錯誤如下:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` due to previous error
這個報錯說這段程式碼是無效的,因為我們不能在同一時間多次將 s 作為可變變數借用。第一個可變的借入在 r1 中,並且必須持續到在 println! 中使用它,但是在那個可變參照的建立和它的使用之間,我們又嘗試在 r2 中建立另一個可變參照,該參照借用與 r1 相同的資料。
這一限制以一種非常小心謹慎的方式允許可變性,防止同一時間對同一資料存在多個可變參照。新 Rustacean 們經常難以適應這一點,因為大部分語言中變數任何時候都是可變的。這個限制的好處是 Rust 可以在編譯時就避免資料競爭。資料競爭(data race)類似於競態條件,它可由這三個行為造成:
•兩個或更多指標同時存取同一資料。
•至少有一個指標被用來寫入資料。
•沒有同步資料存取的機制。
資料競爭會導致未定義行為,難以在執行時追蹤,並且難以診斷和修復;Rust 避免了這種情況的發生,因為它甚至不會編譯存在資料競爭的程式碼!
一如既往,可以使用大括號來建立一個新的作用域,以允許擁有多個可變參照,只是不能 同時 擁有:
let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1 在這裡離開了作用域,所以我們完全可以建立一個新的參照
let r2 = &mut s;
Rust 在同時使用可變與不可變參照時也採用的類似的規則。這些程式碼會導致一個錯誤:
let mut s = String::from("hello");
let r1 = &s; // 沒問題
let r2 = &s; // 沒問題
let r3 = &mut s; // 大問題
println!("{}, {}, and {}", r1, r2, r3);
錯誤如下:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{}, {}, and {}", r1, r2, r3);
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` due to previous error
錯誤提示我們也不能在擁有不可變參照的同時擁有可變參照。
不可變參照的使用者可不希望在他們的眼皮底下值就被意外的改變了!然而,多個不可變參照是可以的,因為沒有哪個只能讀取資料的人有能力影響其他人讀取到的資料。
注意一個參照的作用域從宣告的地方開始一直持續到最後一次使用為止。例如,因為最後一次使用不可變參照(println!),發生在宣告可變參照之前,所以如下程式碼是可以編譯的:
let mut s = String::from("hello");
let r1 = &s; // 沒問題
let r2 = &s; // 沒問題
println!("{} and {}", r1, r2);
// 此位置之後 r1 和 r2 不再使用
let r3 = &mut s; // 沒問題
println!("{}", r3);
不可變參照 r1 和 r2 的作用域在 println! 最後一次使用之後結束,這也是建立可變參照 r3 的地方。它們的作用域沒有重疊,所以程式碼是可以編譯的。編譯器在作用域結束之前判斷不再使用的參照的能力被稱為 非詞法作用域生命週期(Non-Lexical Lifetimes,簡稱 NLL)。
儘管這些錯誤有時使人沮喪,但請牢記這是 Rust 編譯器在提前指出一個潛在的 bug(在編譯時而不是在執行時)並精準顯示問題所在。這樣你就不必去跟蹤為何資料並不是你想象中的那樣。
3.2.懸垂參照(Dangling References)
在具有指標的語言中,很容易通過釋放記憶體時保留指向它的指標而錯誤地生成一個 懸垂指標(dangling pointer),所謂懸垂指標是其指向的記憶體可能已經被分配給其它持有者。相比之下,在 Rust 中編譯器確保參照永遠也不會變成懸垂狀態:當你擁有一些資料的參照,編譯器確保資料不會在其參照之前離開作用域。
讓我們嘗試建立一個懸垂參照,Rust 會通過一個編譯時錯誤來避免:
檔名: src/main.rs
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}
這裡是錯誤:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
5 | fn dangle() -> &'static String {
| ~~~~~~~~
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` due to previous error
錯誤資訊參照了一個我們還未介紹的功能:生命週期(lifetimes)。第十章會詳細介紹生命週期。不過,如果你不理會生命週期部分,錯誤資訊中確實包含了為什麼這段程式碼有問題的關鍵資訊:
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
讓我們仔細看看我們的 dangle 程式碼的每一步到底發生了什麼:
檔名: src/main.rs
fn dangle() -> &String { // dangle 返回一個字串的參照
let s = String::from("hello"); // s 是一個新字串
&s // 返回字串 s 的參照
} // 這裡 s 離開作用域並被丟棄。其記憶體被釋放。
// 危險!
因為 s 是在 dangle 函數內建立的,當 dangle 的程式碼執行完畢後,s 將被釋放。不過我們嘗試返回它的參照。這意味著這個參照會指向一個無效的 String,這可不對!Rust 不會允許我們這麼做。
這裡的解決方法是直接返回 String:
fn no_dangle() -> String {
let s = String::from("hello");
s
}
這樣就沒有任何錯誤了。所有權被移動出去,所以沒有值被釋放。
3.3.參照的規則
讓我們概括一下之前對參照的討論:
•在任意給定時間,要麼 只能有一個可變參照,要麼 只能有多個不可變參照。
•參照必須總是有效的。
接下來,我們來看看另一種不同型別的參照:slice。
四.Slice 型別
slice 允許你參照集合中一段連續的元素序列,而不用參照整個集合。slice 是一類參照,所以它沒有所有權。
這裡有一個程式設計小習題:編寫一個函數,該函數接收一個用空格分隔單詞的字串,並返回在該字串中找到的第一個單詞。如果函數在該字串中並未找到空格,則整個字串就是一個單詞,所以應該返回整個字串。
讓我們推敲下如何不用 slice 編寫這個函數的簽名,來理解 slice 能解決的問題:
fn first_word(s: &String) -> ?
first_word 函數有一個引數 &String。因為我們不需要所有權,所以這沒有問題。不過應該返回什麼呢?我們並沒有一個真正獲取 部分 字串的辦法。不過,我們可以返回單詞結尾的索引,結尾由一個空格表示。試試如範例 7 中的程式碼。
檔名: src/main.rs
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
範例 7:first_word 函數返回 String 引數的一個位元組索引值
因為需要逐個元素的檢查 String 中的值是否為空格,需要用 as_bytes 方法將 String 轉化為位元組陣列:
let bytes = s.as_bytes();
接下來,使用 iter 方法在位元組陣列上建立一個迭代器:
for (i, &item) in bytes.iter().enumerate() {
上述程式碼中, iter 方法返回集合中的每一個元素,而 enumerate 包裝了 iter 的結果,將這些元素作為元組的一部分來返回。enumerate 返回的元組中,第一個元素是索引,第二個元素是集合中元素的參照。這比我們自己計算索引要方便一些。
因為 enumerate 方法返回一個元組,我們可以使用模式來解構,我們將在第六章中進一步討論有關模式的問題。所以在 for 迴圈中,我們指定了一個模式,其中元組中的 i 是索引而元組中的 &item 是單個位元組。因為我們從 .iter().enumerate() 中獲取了集合元素的參照,所以模式中使用了 &。
在 for 迴圈中,我們通過位元組的字面值語法來尋找代表空格的位元組。如果找到了一個空格,返回它的位置。否則,使用 s.len() 返回字串的長度:
if item == b' ' {
return i;
}
}
s.len()
現在有了一個找到字串中第一個單詞結尾索引的方法,不過這有一個問題。我們返回了一個獨立的 usize,不過它只在 &String 的上下文中才是一個有意義的數位。換句話說,因為它是一個與 String 相分離的值,無法保證將來它仍然有效。考慮一下範例 8 中使用了範例 7 中 first_word 函數的程式。
檔名: src/main.rs
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s); // word 的值為 5
s.clear(); // 這清空了字串,使其等於 ""
// word 在此處的值仍然是 5,
// 但是沒有更多的字串讓我們可以有效地應用數值 5。word 的值現在完全無效!
}
範例 8:儲存 first_word 函數呼叫的返回值並接著改變 String 的內容
這個程式編譯時沒有任何錯誤,而且在呼叫 s.clear() 之後使用 word 也不會出錯。因為 word 與 s 狀態完全沒有聯絡,所以 word 仍然包含值 5。可以嘗試用值 5 來提取變數 s 的第一個單詞,不過這是有 bug 的,因為在我們將 5 儲存到 word 之後 s 的內容已經改變。
我們不得不時刻擔心 word 的索引與 s 中的資料不再同步,這很囉嗦且易出錯!如果編寫這麼一個 second_word 函數的話,管理索引這件事將更加容易出問題。它的簽名看起來像這樣:
fn second_word(s: &String) -> (usize, usize) {
現在我們要跟蹤一個開始索引 和 一個結尾索引,同時有了更多從資料的某個特定狀態計算而來的值,但都完全沒有與這個狀態相關聯。現在有三個飄忽不定的不相關變數需要保持同步。
幸運的是,Rust 為這個問題提供了一個解決方法:字串 slice。
4.1.字串 slice
字串 slice(string slice)是 String 中一部分值的參照,它看起來像這樣:
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
不同於整個 String 的參照,hello 是一個部分 String 的參照,由一個額外的 [0..5] 部分指定。可以使用一個由中括號中的 [starting_index..ending_index] 指定的 range 建立一個 slice,其中 starting_index 是 slice 的第一個位置,ending_index 則是 slice 最後一個位置的後一個值。在其內部,slice 的資料結構儲存了 slice 的開始位置和長度,長度對應於 ending_index 減去 starting_index 的值。所以對於 let world = &s[6..11]; 的情況,world 將是一個包含指向 s 索引 6 的指標和長度值 5 的 slice。
圖 6 展示了一個圖例。
圖 6:參照了部分 String 的字串 slice
對於 Rust 的 .. range 語法,如果想要從索引 0 開始,可以不寫兩個點號之前的值。換句話說,如下兩個語句是相同的:
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];
依此類推,如果 slice 包含 String 的最後一個位元組,也可以捨棄尾部的數位。這意味著如下也是相同的:
let s = String::from("hello");
let len = s.len();
let slice = &s[3..len];
let slice = &s[3..];
也可以同時捨棄這兩個值來獲取整個字串的 slice。所以如下亦是相同的:
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];
注意:字串 slice range 的索引必須位於有效的 UTF-8 字元邊界內,如果嘗試從一個多位元組字元的中間位置建立字串 slice,則程式將會因錯誤而退出。出於介紹字串 slice 的目的,本部分假設只使用 ASCII 字元集;第八章的 「使用字串儲存 UTF-8 編碼的文字」 部分會更加全面的討論 UTF-8 處理問題。
在記住所有這些知識後,讓我們重寫 first_word 來返回一個 slice。「字串 slice」 的型別宣告寫作 &str:
檔名: src/main.rs
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
我們使用跟範例 7 相同的方式獲取單詞結尾的索引,通過尋找第一個出現的空格。當找到一個空格,我們返回一個字串 slice,它使用字串的開始和空格的索引作為開始和結束的索引。
現在當呼叫 first_word 時,會返回與底層資料關聯的單個值。這個值由一個 slice 開始位置的參照和 slice 中元素的數量組成。
second_word 函數也可以改為返回一個 slice:
fn second_word(s: &String) -> &str {
現在我們有了一個不易混淆且直觀的 API 了,因為編譯器會確保指向 String 的參照持續有效。還記得範例 8 程式中,那個當我們獲取第一個單詞結尾的索引後,接著就清除了字串導致索引就無效的 bug 嗎?那些程式碼在邏輯上是不正確的,但卻沒有顯示任何直接的錯誤。問題會在之後嘗試對空字串使用第一個單詞的索引時出現。slice 就不可能出現這種 bug 並讓我們更早的知道出問題了。使用 slice 版本的 first_word 會丟擲一個編譯時錯誤:
檔名: src/main.rs
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // 錯誤!
println!("the first word is: {}", word);
}
這裡是編譯錯誤:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {}", word);
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` due to previous error
回憶一下借用規則,當擁有某值的不可變參照時,就不能再獲取一個可變參照。因為 clear 需要清空 String,它嘗試獲取一個可變參照。在呼叫 clear 之後的 println! 使用了 word 中的參照,所以這個不可變的參照在此時必須仍然有效。Rust 不允許 clear 中的可變參照和 word 中的不可變參照同時存在,因此編譯失敗。Rust 不僅使得我們的 API 簡單易用,也在編譯時就消除了一整類的錯誤!
4.1.1.字串字面值就是 slice
還記得我們講到過字串字面值被儲存在二進位制檔案中嗎?現在知道 slice 了,我們就可以正確地理解字串字面值了:
let s = "Hello, world!";
這裡 s 的型別是 &str:它是一個指向二進位制程式特定位置的 slice。這也就是為什麼字串字面值是不可變的;&str 是一個不可變參照。
4.1.2.字串 slice 作為引數
在知道了能夠獲取字面值和 String 的 slice 後,我們對 first_word 做了改進,這是它的簽名:
fn first_word(s: &String) -> &str {
而更有經驗的 Rustacean 會編寫出範例 9 中的簽名,因為它使得可以對 &String 值和 &str 值使用相同的函數:
fn first_word(s: &str) -> &str {
範例 9: 通過將 s 引數的型別改為字串 slice 來改進 first_word 函數
如果有一個字串 slice,可以直接傳遞它。如果有一個 String,則可以傳遞整個 String 的 slice 或對 String 的參照。定義一個獲取字串 slice 而不是 String 參照的函數使得我們的 API 更加通用並且不會丟失任何功能:
檔名: src/main.rs
fn main() {
let my_string = String::from("hello world");
// `first_word` 適用於 `String`(的 slice),整體或全部
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` 也適用於 `String` 的參照,
// 這等價於整個 `String` 的 slice
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` 適用於字串字面值,整體或全部
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// 因為字串字面值已經 **是** 字串 slice 了,
// 這也是適用的,無需 slice 語法!
let word = first_word(my_string_literal);
}
4.2.其他型別的 slice
字串 slice,正如你想象的那樣,是針對字串的。不過也有更通用的 slice 型別。考慮一下這個陣列:
let a = [1, 2, 3, 4, 5];
就跟我們想要獲取字串的一部分那樣,我們也會想要參照陣列的一部分。我們可以這樣做:
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
這個 slice 的型別是 &[i32]。它跟字串 slice 的工作方式一樣,通過儲存第一個集合元素的參照和一個集合總長度。你可以對其他所有集合使用這類 slice。第八章講到 vector 時會詳細討論這些集合。
五.總結
所有權、借用和 slice 這些概念讓 Rust 程式在編譯時確保記憶體安全。Rust 語言提供了跟其他系統程式語言相同的方式來控制你使用的記憶體,但擁有資料所有者在離開作用域後自動清除其資料的功能意味著你無須額外編寫和偵錯相關的控制程式碼。Rust自帶的這些機制雖然犧牲了一些靈活性,但也從根本上保證了記憶體的安全,只要遵循這些規則,就能輕鬆寫出安全的程式碼。
六.參照
[1] Rust 教學 | 菜鳥教學 (runoob.com)
[2] 除了RUST,還有國產架構:Linux6.1核心穩定版首發布!_中文科技資訊 提供快捷產業新資訊 創新驅動商業 (citnews.com.cn)
[3] crates.io: Rust Package Registry
[4] 位元組跳動在 Rust 微服務方向的探索和實踐 | QCon_程式碼_問題_時候 (sohu.com)
[5] Rust 程式設計語言 - Rust 程式設計語言 簡體中文版 (kaisery.github.io)