100 行 shell 寫個 Docker
作者:vivo 網際網路運維團隊- Hou Dengfeng
本文主要介紹使用shell實現一個簡易的Docker。
一、目的
在初接觸Docker的時候,我們必須要了解的幾個概念就是Cgroup、Namespace、RootFs,如果本身對虛擬化的發展沒有深入的瞭解,那麼很難對這幾個概念有深入的理解,本文的目的就是通過在作業系統中以互動式的方式去理解,Cgroup/Namespace/Rootfs到底實現了什麼,能做到哪些事情,然後通過shell這種直觀的命令列方式把我們的理解組合起來,去模仿Docker實現一個縮減的版本。
二、技術拆解
2.1 Namespace
2.1.1 簡介
Linux Namespace是Linux提供的一種核心級別環境隔離的方法。學習過Linux的同學應該對chroot命令比較熟悉(通過修改根目錄把使用者限制在一個特定目錄下),chroot提供了一種簡單的隔離模式:chroot內部的檔案系統無法存取外部的內容。Linux Namespace在此基礎上,提供了對UTS、IPC、mount、PID、network、User等的隔離機制。Namespace是對全域性系統資源的一種封裝隔離,使得處於不同namespace的程序擁有獨立的全域性系統資源,改變一個namespace中的系統資源只會影響當前namespace裡的程序,對其他namespace中的程序沒有影響。
Linux Namespace有如下種類:
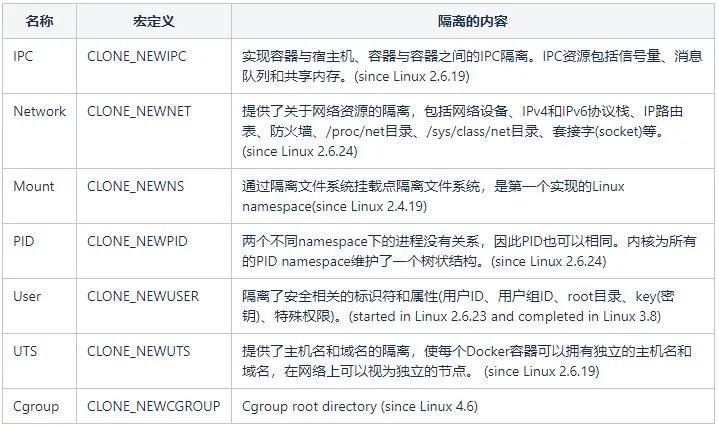
2.1.2 Namespace相關係統呼叫
amespace相關的系統呼叫有3個,分別是clone(),setns(),unshare()。
-
clone: 建立一個新的程序並把這個新程序放到新的namespace中
-
setns: 將當前程序加入到已有的namespace中
-
unshare: 使當前程序退出指定型別的namespace,並加入到新建立的namespace中
2.1.3 檢視程序所屬Namespace
上面的概念都比較抽象,我們來看看在Linux系統中怎麼樣去get namespace。
系統中的每個程序都有/proc/[pid]/ns/這樣一個目錄,裡面包含了這個程序所屬namespace的資訊,裡面每個檔案的描述符都可以用來作為setns函數(2.1.2)的fd引數。
#檢視當前bash程序關聯的Namespace
# ls -l /proc/$$/ns
total 0
lrwxrwxrwx 1 root root 0 Jan 17 21:43 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 Jan 17 21:43 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 root root 0 Jan 17 21:43 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 Jan 17 21:43 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 Jan 17 21:43 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Jan 17 21:43 uts -> uts:[4026531838]
#這些 namespace 檔案都是連結檔案。連結檔案的內容的格式為 xxx:[inode number]。
其中的 xxx 為 namespace 的型別,inode number 則用來標識一個 namespace,我們也可以把它理解為 namespace 的 ID。
如果兩個程序的某個 namespace 檔案指向同一個連結檔案,說明其相關資源在同一個 namespace 中。以ipc:[4026531839]例,
ipc是namespace的型別,4026531839是inode number,如果兩個程序的ipc namespace的inode number一樣,說明他們屬於同一個namespace。
這條規則對其他型別的namespace也同樣適用。
#從上面的輸出可以看出,對於每種型別的namespace,程序都會與一個namespace ID關聯。
#當一個namespace中的所有程序都退出時,該namespace將會被銷燬。在 /proc/[pid]/ns 裡放置這些連結檔案的作用就是,一旦這些連結檔案被開啟,
只要開啟的檔案描述符(fd)存在,那麼就算該 namespace 下的所有程序都結束了,但這個 namespace 也會一直存在,後續的程序還可以再加入進來。
2.1.4 相關命令及操作範例
本節會用UTS/IPC/NET 3個Namespace作為範例演示如何在linux系統中建立Namespace,並介紹相關命令。
2.1.4.1 IPC Namespace
IPC namespace用來隔離System V IPC objects和POSIX message queues。其中System V IPC objects包含訊息列表Message queues、號誌Semaphore sets和共用記憶體Shared memory segments。為了展現區分IPC Namespace我們這裡會使用到ipc相關命令:
# nsenter: 加入指定程序的指定型別的namespace中,然後執行引數中指定的命令。 # 命令格式:nsenter [options] [program [arguments]] # 範例:nsenter –t 27668 –u –I /bin/bash # # unshare: 離開當前指定型別的namespace,建立且加入新的namesapce,然後執行引數中執行的命令。 # 命令格式:unshare [options] program [arguments] # 範例:unshare --fork --pid --mount-proc readlink /proc/self # # ipcmk:建立shared memory segments, message queues, 和semaphore arrays # 引數-Q:建立message queues # ipcs:檢視shared memory segments, message queues, 和semaphore arrays的相關資訊 # 引數-a:顯示全部可顯示的資訊 # 引數-q:顯示活動的訊息佇列資訊
下面將以訊息佇列為例,演示一下隔離效果,為了使演示更直觀,我們在建立新的ipc namespace的時候,同時也建立新的uts namespace,然後為新的uts namespace設定新hostname,這樣就能通過shell提示符一眼看出這是屬於新的namespace的bash。範例中我們用兩個shell來展示:
shell A
#檢視當前shell的uts / ipc namespace number # readlink /proc/$$/ns/uts /proc/$$/ns/ipc uts:[4026531838] ipc:[4026531839] #檢視當前主機名 # hostname myCentos #檢視ipc message queues,預設情況下沒有message queue # ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages #建立一個message queue # ipcmk -Q Message queue id: 131072 # ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages 0x82a1d963 131072 root 644 0 0 -----> 切換至shell B執行 ------------------------------------------------------------------ #回到shell A之後我們可以看下hostname、ipc等有沒有收到影響 # hostname myCentos # ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages 0x82a1d963 131072 root 644 0 0 #接下來我們嘗試加入shell B中新的Namespace # nsenter -t 30372 -u -i /bin/bash [root@shell-B:/root] # hostname shell-B # readlink /proc/$$/ns/uts /proc/$$/ns/ipc uts:[4026532382] ipc:[4026532383] # ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages #可以看到我們已經成功的加入到了新的Namespace中
shell B
#確認當前shell和shell A屬於相同Namespace # readlink /proc/$$/ns/uts /proc/$$/ns/ipc uts:[4026531838] ipc:[4026531839] # ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages 0x82a1d963 131072 root 644 0 0 #使用unshare建立新的uts和ipc Namespace,並在新的Namespace中啟動bash # unshare -iu /bin/bash #確認新的bash uts/ipc Namespace Number # readlink /proc/$$/ns/uts /proc/$$/ns/ipc uts:[4026532382] ipc:[4026532383] #設定新的hostname與shell A做區分 # hostname shell-B # hostname shell-B #檢視之前的ipc message queue # ipcs -q ------ Message Queues -------- key msqid owner perms used-bytes messages #檢視當前bash程序的PID # echo $$ 30372 切換回shell A <-----
2.1.4.2 Net Namespace
Network namespace用來隔離網路裝置, IP地址, 埠等. 每個namespace將會有自己獨立的網路棧,路由表,防火牆規則,socket等。每個新的network namespace預設有一個本地環回介面,除了lo介面外,所有的其他網路裝置(物理/虛擬網路介面,網橋等)只能屬於一個network namespace。每個socket也只能屬於一個network namespace。當新的network namespace被建立時,lo介面預設是關閉的,需要自己手動啟動起。標記為"local devices"的裝置不能從一個namespace移動到另一個namespace,比如loopback, bridge, ppp等,我們可以通過ethtool -k命令來檢視裝置的netns-local屬性。
我們使用以下命令來建立net namespace。
相關命令:
ip netns: 管理網路namespace
用法:
ip netns list
ip netns add NAME
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]
下面使用ip netns來演示建立net Namespace。
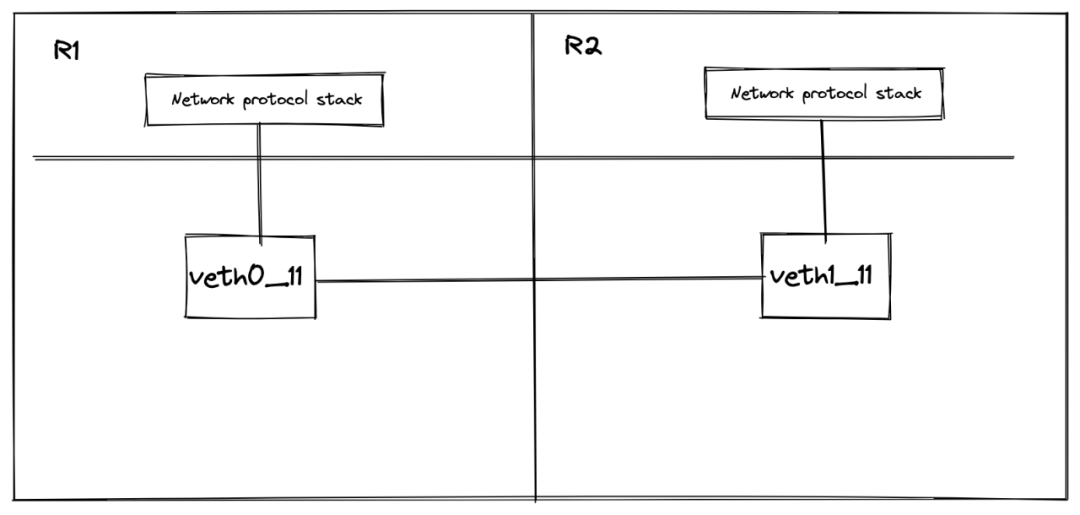
shell A
#建立一對網路卡,分別命名為veth0_11/veth1_11
# ip link add veth0_11 type veth peer name veth1_11
#檢視已經建立的網路卡
#ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 5e:75:97:0d:54:17 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.1/24 brd 192.168.1.255 scope global eth0
valid_lft forever preferred_lft forever
3: br1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/24 scope global br1
valid_lft forever preferred_lft forever
96: veth1_11@veth0_11: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 5e:75:97:0d:54:0e brd ff:ff:ff:ff:ff:ff
97: veth0_11@veth1_11: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether a6:c7:1f:79:a6:a6 brd ff:ff:ff:ff:ff:ff
#使用ip netns建立兩個net namespace
# ip netns add r1
# ip netns add r2
# ip netns list
r2
r1 (id: 0)
#將兩個網路卡分別加入到對應的netns中
# ip link set veth0_11 netns r1
# ip link set veth1_11 netns r2
#再次檢視網路卡,在bash當前的namespace中已經看不到veth0_11和veth1_11了
# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 5e:75:97:0d:54:17 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.1/24 brd 192.168.1.255 scope global eth0
valid_lft forever preferred_lft forever
3: br1: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/24 scope global br1
valid_lft forever preferred_lft forever
#接下來我們切換到對應的netns中對網路卡進行設定
#通過nsenter --net可以切換到對應的netns中,ip a展示了我們上面加入到r1中的網路卡
# nsenter --net=/var/run/netns/r1 /bin/bash
# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
97: veth0_11@if96: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether a6:c7:1f:79:a6:a6 brd ff:ff:ff:ff:ff:ff link-netnsid 1
#對網路卡設定ip並啟動
# ip addr add 172.18.0.11/24 dev veth0_11
# ip link set veth0_11 up
# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
97: veth0_11@if96: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN qlen 1000
link/ether a6:c7:1f:79:a6:a6 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 172.18.0.11/24 scope global veth0_11
valid_lft forever preferred_lft forever
-----> 切換至shell B執行
------------------------------------------------------------------
#在r1中ping veth1_11
# ping 172.18.0.12
PING 172.18.0.12 (172.18.0.12) 56(84) bytes of data.
64 bytes from 172.18.0.12: icmp_seq=1 ttl=64 time=0.033 ms
64 bytes from 172.18.0.12: icmp_seq=2 ttl=64 time=0.049 ms
...
#至此我們通過netns完成了建立net Namespace的小實驗
shell B
#在shell B中我們同樣切換到netns r2中進行設定
#通過nsenter --net可以切換到r2,ip a展示了我們上面加入到r2中的網路卡
# nsenter --net=/var/run/netns/r2 /bin/bash
# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
96: veth1_11@if97: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 5e:75:97:0d:54:0e brd ff:ff:ff:ff:ff:ff link-netnsid 0
#對網路卡設定ip並啟動
# ip addr add 172.18.0.12/24 dev veth1_11
# ip link set veth1_11 up
# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
96: veth1_11@if97: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 5e:75:97:0d:54:0e brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.12/24 scope global veth1_11
valid_lft forever preferred_lft forever
inet6 fe80::5c75:97ff:fe0d:540e/64 scope link
valid_lft forever preferred_lft forever
#嘗試ping r1中的網路卡
# ping 172.18.0.11
PING 172.18.0.11 (172.18.0.11) 56(84) bytes of data.
64 bytes from 172.18.0.11: icmp_seq=1 ttl=64 time=0.046 ms
64 bytes from 172.18.0.11: icmp_seq=2 ttl=64 time=0.040 ms
...
#可以完成通訊
切換至shell A執行 <-----
示意圖
2.2 Cgroup
2.2.1 簡介
Cgroup和namespace類似,也是將程序進行分組,但它的目的和namespace不一樣,namespace是為了隔離行程群組之間的資源,而cgroup是為了對一組程序進行統一的資源監控和限制。
Cgroup作用:
-
資源限制(Resource limiting): Cgroups可以對行程群組使用的資源總額進行限制。如對特定的程序進行記憶體使用上限限制,當超出上限時,會觸發OOM。
-
優先順序分配(Prioritization): 通過分配的CPU時間片數量及硬碟IO頻寬大小,實際上就相當於控制了程序執行的優先順序。
-
資源統計(Accounting): Cgroups可以統計系統的資源使用量,如CPU使用時長、記憶體用量等等,這個功能非常適用於計費。
-
程序控制(Control):Cgroups可以對行程群組執行掛起、恢復等操作。
Cgroups的組成:
-
task: 在Cgroups中,task就是系統的一個程序。
-
cgroup: Cgroups中的資源控制都以cgroup為單位實現的。cgroup表示按照某種資源控制標準劃分而成的任務組,包含一個或多個子系統。一個任務可以加入某個cgroup,也可以從某個cgroup遷移到另外一個cgroup。
-
subsystem: 一個subsystem就是一個核心模組,被關聯到一顆cgroup樹之後,就會在樹的每個節點(行程群組)上做具體的操作。subsystem經常被稱作"resource controller",因為它主要被用來排程或者限制每個行程群組的資源,但是這個說法不完全準確,因為有時我們將程序分組只是為了做一些監控,觀察一下他們的狀態,比如perf_event subsystem。到目前為止,Linux支援13種subsystem(Cgroup v1),比如限制CPU的使用時間,限制使用的記憶體,統計CPU的使用情況,凍結和恢復一組程序等。
-
hierarchy: 一個hierarchy可以理解為一棵cgroup樹,樹的每個節點就是一個行程群組,每棵樹都會與零到多個subsystem關聯。在一顆樹裡面,會包含Linux系統中的所有程序,但每個程序只能屬於一個節點(行程群組)。系統中可以有很多顆cgroup樹,每棵樹都和不同的subsystem關聯,一個程序可以屬於多顆樹,即一個程序可以屬於多個行程群組,只是這些行程群組和不同的subsystem關聯。如果不考慮不與任何subsystem關聯的情況(systemd就屬於這種情況),Linux裡面最多可以建13顆cgroup樹,每棵樹關聯一個subsystem,當然也可以只建一棵樹,然後讓這棵樹關聯所有的subsystem。當一顆cgroup樹不和任何subsystem關聯的時候,意味著這棵樹只是將程序進行分組,至於要在分組的基礎上做些什麼,將由應用程式自己決定,systemd就是一個這樣的例子。
2.2.2 檢視Cgroup資訊
檢視當前系統支援的subsystem
#通過/proc/cgroups檢視當前系統支援哪些subsystem
# cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 11 1 1
cpu 4 67 1
cpuacct 4 67 1
memory 5 69 1
devices 7 62 1
freezer 8 1 1
net_cls 6 1 1
blkio 9 62 1
perf_event 3 1 1
hugetlb 2 1 1
pids 10 62 1
net_prio 6 1 1
#欄位含義
#subsys_name: subsystem的名稱
#hierarchy:subsystem所關聯到的cgroup樹的ID,如果多個subsystem關聯到同一顆cgroup樹,那麼他們的這個欄位將一樣,比如這裡的cpu和cpuacct就一樣,表示他們繫結到了同一顆樹。如果出現下面的情況,這個欄位將為0:
當前subsystem沒有和任何cgroup樹繫結
當前subsystem已經和cgroup v2的樹繫結
當前subsystem沒有被核心開啟
#num_cgroups: subsystem所關聯的cgroup樹中行程群組的個數,也即樹上節點的個數
#enabled: 1表示開啟,0表示沒有被開啟(可以通過設定核心的啟動引數「cgroup_disable」來控制subsystem的開啟).
檢視程序所屬cgroup
#檢視當前shell程序所屬的cgroup # cat /proc/$$/cgroup 11:cpuset:/ 10:pids:/system.slice/sshd.service 9:blkio:/system.slice/sshd.service 8:freezer:/ 7:devices:/system.slice/sshd.service 6:net_prio,net_cls:/ 5:memory:/system.slice/sshd.service 4:cpuacct,cpu:/system.slice/sshd.service 3:perf_event:/ 2:hugetlb:/ 1:name=systemd:/system.slice/sshd.service #欄位含義(以冒號分為3列): # 1. cgroup樹ID,對應/proc/cgroups中的hierachy # 2. cgroup所繫結的subsystem,多個subsystem使用逗號分隔。name=systemd表示沒有和任何subsystem繫結,只是給他起了個名字叫systemd。 # 3. 程序在cgroup樹中的路徑,即程序所屬的cgroup,這個路徑是相對於掛載點的相對路徑。
2.2.3 相關命令
使用cgroup
cgroup相關的所有操作都是基於核心中的cgroup virtual filesystem,使用cgroup很簡單,掛載這個檔案系統就可以了。一般情況下都是掛載到/sys/fs/cgroup目錄下,當然掛載到其它任何目錄都沒關係。
檢視下當前系統cgroup掛載情況。
#過濾系統掛載可以檢視cgroup # mount |grep cgroup tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755) cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset) #如果系統中沒有掛載cgroup,可以使用mount命令建立cgroup #掛載根cgroup # mkdir /sys/fs/cgroup # mount -t tmpfs cgroup_root /sys/fs/cgroup #將cpuset subsystem關聯到/sys/fs/cgroup/cpu_memory # mkdir /sys/fs/cgroup/cpuset # sudo mount -t cgroup cpuset -o cgroup /sys/fs/cgroup/cpuset/ #將cpu和memory subsystem關聯到/sys/fs/cgroup/cpu_memory # mkdir /sys/fs/cgroup/cpu_memory # sudo mount -n -t cgroup -o cpu,memory cgroup /sys/fs/cgroup/cpu_memory
除了mount命令之外我們還可以使用以下命令對cgroup進行建立、屬性設定等操作,這也是我們後面指令碼中用於建立和管理cgroup的命令。
# Centos作業系統可以通過yum install cgroup-tools 來安裝以下命令
cgcreate: 在層級中建立新cgroup。
用法: cgcreate [-h] [-t <tuid>:<tgid>] [-a <agid>:<auid>] [-f mode] [-d mode] [-s mode]
-g <controllers>:<path> [-g ...]
範例: cgcreate -g *:student -g devices:teacher //在所有的掛載hierarchy中建立student cgroup,在devices
hierarchy掛載點建立teacher cgroup
cgset: 設定指定cgroup(s)的引數
用法: cgset [-r <name=value>] <cgroup_path> ...
範例: cgset -r cpuset.cpus=0-1 student //將student cgroup的cpuset控制器中的cpus限制為0-1
cgexec: 在指定的cgroup中執行任務
用法: cgexec [-h] [-g <controllers>:<path>] [--sticky] command [arguments]
範例: cgexec -g cpu,memory:test1 ls -l //在cpu和memory控制器下的test1 cgroup中執行ls -l命令
2.3 Rootfs
2.3.1 簡介
Rootfs 是 Docker 容器在啟動時內部程序可見的檔案系統,即 Docker容器的根目錄。rootfs 通常包含一個作業系統執行所需的檔案系統,例如可能包含典型的類 Unix 作業系統中的目錄系統,如 /dev、/proc、/bin、/etc、/lib、/usr、/tmp 及執行 Docker 容器所需的組態檔、工具等。
就像Linux啟動會先用唯讀模式掛載rootfs,執行完完整性檢查之後,再切換成讀寫模式一樣。Docker deamon為container掛載rootfs時,也會先掛載為唯讀模式,但是與Linux做法不同的是,在掛載完唯讀的rootfs之後,Docker deamon會利用聯合掛載技術(Union Mount)在已有的rootfs上再掛一個讀寫層。container在執行過程中檔案系統發生的變化只會寫到讀寫層,並通過whiteout技術隱藏唯讀層中的舊版本檔案。
Docker支援不同的儲存驅動,包括 aufs、devicemapper、overlay2、zfs 和 vfs 等,目前在 Docker 中,overlay2 取代了 aufs 成為了推薦的儲存驅動。
2.3.2 overlayfs
overlayFS是聯合掛載技術的一種實現。除了overlayFS以外還有aufs,VFS,Brtfs,device mapper等技術。雖然實現細節不同,但是他們做的事情都是相同的。Linux核心為Docker提供的overalyFS驅動有2種:overlay2和overlay,overlay2是相對於overlay的一種改進,在inode利用率方面比overlay更有效。
overlayfs通過三個目錄來實現:lower目錄、upper目錄、以及work目錄。三種目錄合併出來的目錄稱為merged目錄。
-
lower:可以是多個,是處於最底層的目錄,作為唯讀層。
-
upper:只有一個,作為讀寫層。
-
work:為工作基礎目錄,掛載後內容會被清空,且在使用過程中其內容使用者不可見。
-
merged:為最後聯合掛載完成給使用者呈現的統一檢視,也就是說merged目錄裡面本身並沒有任何實體檔案,給我們展示的只是參與聯合掛載的目錄裡面檔案而已,真正的檔案還是在lower和upper中。所以,在merged目錄下編輯檔案,或者直接編輯lower或upper目錄裡面的檔案都會影響到merged裡面的檢視展示。
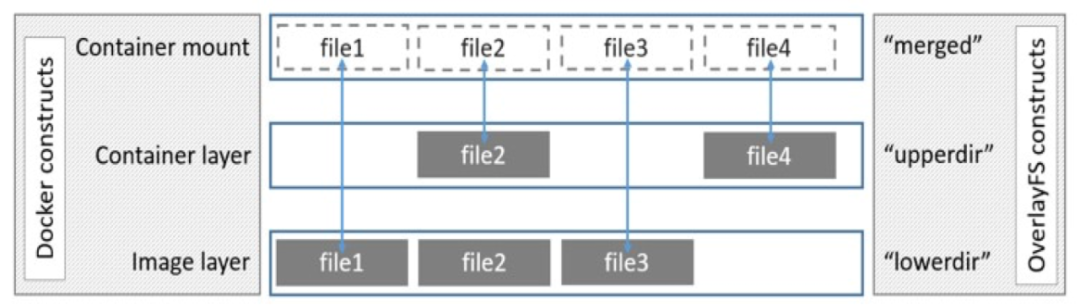
2.3.3 檔案規則
merged層目錄會顯示離它最近層的檔案。層級關係中upperdir比lowerdir更靠近merged層,而多個lowerdir的情況下,寫的越靠前的目錄離merged層目錄越近。相同檔名的檔案會依照層級規則進行「覆蓋」。
2.3.4 overlayFS如何工作
讀:
-
如果檔案在容器層(upperdir),直接讀取檔案;
-
如果檔案不在容器層(upperdir),則從映象層(lowerdir)讀取;
寫:
-
①首次寫入: 如果在upperdir中不存在,overlay執行cow操作,把檔案從lowdir拷貝到upperdir,由於overlayfs是檔案級別的(即使檔案只有很少的一點修改,也會產生的cow的行為),後續對同一檔案的在此寫入操作將對已經複製到容器的檔案的副本進行操作。值得注意的是,cow操作只發生在檔案首次寫入,以後都是隻修改副本。
-
②刪除檔案和目錄: 當檔案在容器被刪除時,在容器層(upperdir)建立whiteout檔案,映象層(lowerdir)的檔案是不會被刪除的,因為他們是唯讀的,但whiteout檔案會阻止他們顯示。
2.3.5 在系統裡建立overlayfs
shell
# 建立所需的目錄
# mkdir upper lower merged work
# echo "lower" > lower/in_lower.txt
# echo "upper" > upper/in_upper.txt
# 在lower和upper中都建立 in_both檔案
# echo "lower" > lower/in_both.txt
# echo "upper" > upper/in_both.txt
#檢視下我們當前的目錄及檔案結構
# tree .
.
|-- lower
| |-- in_both.txt
| `-- in_lower.txt
|-- merged
|-- upper
| |-- in_both.txt
| `-- in_upper.txt
`-- work
#使用mount命令將建立的目錄聯合掛載起來
# mount -t overlay overlay -o lowerdir=lower,upperdir=upper,workdir=work merged
#檢視mount結果可以看到已經成功掛載了
# mount |grep overlay
overlay on /data/overlay_demo/merged type overlay (rw,relatime,lowerdir=lower,upperdir=upper,workdir=work)
#此時再檢視檔案目錄結構
# tree .
.
|-- lower
| |-- in_both.txt
| `-- in_lower.txt
|-- merged
| |-- in_both.txt
| |-- in_lower.txt
| `-- in_upper.txt
|-- upper
| |-- in_both.txt
| `-- in_upper.txt
`-- work
`-- work
#可以看到merged中包含了lower和upper中的檔案
#然後我檢視merge中的in_both檔案,驗證了上層目錄覆蓋下層的結論
# cat merged/in_both.txt
upper
#上面我們驗證了掛載後overlayfs的讀,接下來我們去驗證下寫
#我們在merged中建立一個新檔案,並檢視
# touch merged/new_file
# tree .
.
|-- lower
| |-- in_both.txt
| `-- in_lower.txt
|-- merged
| |-- in_both.txt
| |-- in_lower.txt
| |-- in_upper.txt
| `-- new_file
|-- upper
| |-- in_both.txt
| |-- in_upper.txt
| `-- new_file
`-- work
`-- work
#可以看到新檔案實際是放在了upper目錄中
#下面我們看下如果刪除了lower和upper中都有的檔案會怎樣
# rm -f merged/in_both.txt
# tree .
.
|-- lower
| |-- in_both.txt
| `-- in_lower.txt
|-- merged
| |-- in_lower.txt
| |-- in_upper.txt
| `-- new_file
|-- upper
| |-- in_both.txt
| |-- in_upper.txt
| `-- new_file
`-- work
`-- work
#從檔案目錄上看只有merge中沒有了in_both檔案,但是upper中的檔案已經發生了變化
# ll upper/in_both.txt
c--------- 1 root root 0, 0 Jan 21 19:33 upper/in_both.txt
#upper/in_both.txt已經變成了一個空的字元檔案,且覆蓋了lower層的內容
三 、Bocker
3.1 功能演示
第二部分中我們對Namespace,cgroup,overlayfs有了一定的瞭解,接下來我們通過一個指令碼來實現個建議的Docker。指令碼源自於https://github.com/p8952/bocker,我做了image/pull/儲存驅動的部分修改,下面先看下指令碼完成後的範例:

3.2 完整指令碼
指令碼一共用130行程式碼,完成了上面的功能,也算符合我們此次的標題了。為了大家可以更深入的理解指令碼內容,這裡就不再對指令碼進行拆分講解,以下是完整指令碼。
#!/usr/bin/env bash
set -o errexit -o nounset -o pipefail; shopt -s nullglob
overlay_path='/var/lib/bocker/overlay' && container_path='/var/lib/bocker/containers' && cgroups='cpu,cpuacct,memory';
[[ $# -gt 0 ]] && while [ "${1:0:2}" == '--' ]; do OPTION=${1:2}; [[ $OPTION =~ = ]] && declare "BOCKER_${OPTION/=*/}=${OPTION/*=/}" || declare "BOCKER_${OPTION}=x"; shift; done
function bocker_check() {
case ${1:0:3} in
img) ls "$overlay_path" | grep -qw "$1" && echo 0 || echo 1;;
ps_) ls "$container_path" | grep -qw "$1" && echo 2 || echo 3;;
esac
}
function bocker_init() { #HELP Create an image from a directory:\nBOCKER init <directory>
uuid="img_$(shuf -i 42002-42254 -n 1)"
if [[ -d "$1" ]]; then
[[ "$(bocker_check "$uuid")" == 0 ]] && bocker_run "$@"
mkdir "$overlay_path/$uuid" > /dev/null
cp -rf --reflink=auto "$1"/* "$overlay_path/$uuid" > /dev/null
[[ ! -f "$overlay_path/$uuid"/img.source ]] && echo "$1" > "$overlay_path/$uuid"/img.source
[[ ! -d "$overlay_path/$uuid"/proc ]] && mkdir "$overlay_path/$uuid"/proc
echo "Created: $uuid"
else
echo "No directory named '$1' exists"
fi
}
function bocker_pull() { #HELP Pull an image from Docker Hub:\nBOCKER pull <name> <tag>
tmp_uuid="$(uuidgen)" && mkdir /tmp/"$tmp_uuid"
download-frozen-image-v2 /tmp/"$tmp_uuid" "$1:$2" > /dev/null
rm -rf /tmp/"$tmp_uuid"/repositories
for tar in $(jq '.[].Layers[]' --raw-output < /tmp/$tmp_uuid/manifest.json); do
tar xf /tmp/$tmp_uuid/$tar -C /tmp/$tmp_uuid && rm -rf /tmp/$tmp_uuid/$tar
done
for config in $(jq '.[].Config' --raw-output < /tmp/$tmp_uuid/manifest.json); do
rm -f /tmp/$tmp_uuid/$config
done
echo "$1:$2" > /tmp/$tmp_uuid/img.source
bocker_init /tmp/$tmp_uuid && rm -rf /tmp/$tmp_uuid
}
function bocker_rm() { #HELP Delete an image or container:\nBOCKER rm <image_id or container_id>
[[ "$(bocker_check "$1")" == 3 ]] && echo "No container named '$1' exists" && exit 1
[[ "$(bocker_check "$1")" == 1 ]] && echo "No image named '$1' exists" && exit 1
if [[ -d "$overlay_path/$1" ]];then
rm -rf "$overlay_path/$1" && echo "Removed: $1"
else
umount "$container_path/$1"/merged && rm -rf "$container_path/$1" && ip netns del netns_"$1" && ip link del dev veth0_"$1" && echo "Removed: $1"
cgdelete -g "$cgroups:/$1" &> /dev/null
fi
}
function bocker_images() { #HELP List images:\nBOCKER images
echo -e "IMAGE_ID\t\tSOURCE"
for img in "$overlay_path"/img_*; do
img=$(basename "$img")
echo -e "$img\t\t$(cat "$overlay_path/$img/img.source")"
done
}
function bocker_ps() { #HELP List containers:\nBOCKER ps
echo -e "CONTAINER_ID\t\tCOMMAND"
for ps in "$container_path"/ps_*; do
ps=$(basename "$ps")
echo -e "$ps\t\t$(cat "$container_path/$ps/$ps.cmd")"
done
}
function bocker_run() { #HELP Create a container:\nBOCKER run <image_id> <command>
uuid="ps_$(shuf -i 42002-42254 -n 1)"
[[ "$(bocker_check "$1")" == 1 ]] && echo "No image named '$1' exists" && exit 1
[[ "$(bocker_check "$uuid")" == 2 ]] && echo "UUID conflict, retrying..." && bocker_run "$@" && return
cmd="${@:2}" && ip="$(echo "${uuid: -3}" | sed 's/0//g')" && mac="${uuid: -3:1}:${uuid: -2}"
ip link add dev veth0_"$uuid" type veth peer name veth1_"$uuid"
ip link set dev veth0_"$uuid" up
ip link set veth0_"$uuid" master br1
ip netns add netns_"$uuid"
ip link set veth1_"$uuid" netns netns_"$uuid"
ip netns exec netns_"$uuid" ip link set dev lo up
ip netns exec netns_"$uuid" ip link set veth1_"$uuid" address 02:42:ac:11:00"$mac"
ip netns exec netns_"$uuid" ip addr add 172.18.0."$ip"/24 dev veth1_"$uuid"
ip netns exec netns_"$uuid" ip link set dev veth1_"$uuid" up
ip netns exec netns_"$uuid" ip route add default via 172.18.0.1
mkdir -p "$container_path/$uuid"/{lower,upper,work,merged} && cp -rf --reflink=auto "$overlay_path/$1"/* "$container_path/$uuid"/lower > /dev/null && \
mount -t overlay overlay \
-o lowerdir="$container_path/$uuid"/lower,upperdir="$container_path/$uuid"/upper,workdir="$container_path/$uuid"/work \
"$container_path/$uuid"/merged
echo 'nameserver 114.114.114.114' > "$container_path/$uuid"/merged/etc/resolv.conf
echo "$cmd" > "$container_path/$uuid/$uuid.cmd"
cgcreate -g "$cgroups:/$uuid"
: "${BOCKER_CPU_SHARE:=512}" && cgset -r cpu.shares="$BOCKER_CPU_SHARE" "$uuid"
: "${BOCKER_MEM_LIMIT:=512}" && cgset -r memory.limit_in_bytes="$((BOCKER_MEM_LIMIT * 1000000))" "$uuid"
cgexec -g "$cgroups:$uuid" \
ip netns exec netns_"$uuid" \
unshare -fmuip --mount-proc \
chroot "$container_path/$uuid"/merged \
/bin/sh -c "/bin/mount -t proc proc /proc && $cmd" \
2>&1 | tee "$container_path/$uuid/$uuid.log" || true
ip link del dev veth0_"$uuid"
ip netns del netns_"$uuid"
}
function bocker_exec() { #HELP Execute a command in a running container:\nBOCKER exec <container_id> <command>
[[ "$(bocker_check "$1")" == 3 ]] && echo "No container named '$1' exists" && exit 1
cid="$(ps o ppid,pid | grep "^$(ps o pid,cmd | grep -E "^\ *[0-9]+ unshare.*$1" | awk '{print $1}')" | awk '{print $2}')"
[[ ! "$cid" =~ ^\ *[0-9]+$ ]] && echo "Container '$1' exists but is not running" && exit 1
nsenter -t "$cid" -m -u -i -n -p chroot "$container_path/$1"/merged "${@:2}"
}
function bocker_logs() { #HELP View logs from a container:\nBOCKER logs <container_id>
[[ "$(bocker_check "$1")" == 3 ]] && echo "No container named '$1' exists" && exit 1
cat "$container_path/$1/$1.log"
}
function bocker_commit() { #HELP Commit a container to an image:\nBOCKER commit <container_id> <image_id>
[[ "$(bocker_check "$1")" == 3 ]] && echo "No container named '$1' exists" && exit 1
[[ "$(bocker_check "$2")" == 0 ]] && echo "Image named '$2' exists" && exit 1
mkdir "$overlay_path/$2" && cp -rf --reflink=auto "$container_path/$1"/merged/* "$overlay_path/$2" && sed -i "s/:.*$/:$(date +%Y%m%d-%H%M%S)/g" "$overlay_path/$2"/img.source
echo "Created: $2"
}
function bocker_help() { #HELP Display this message:\nBOCKER help
sed -n "s/^.*#HELP\\s//p;" < "$1" | sed "s/\\\\n/\n\t/g;s/$/\n/;s!BOCKER!${1/!/\\!}!g"
}
[[ -z "${1-}" ]] && bocker_help "$0" && exit 1
case $1 in
pull|init|rm|images|ps|run|exec|logs|commit) bocker_"$1" "${@:2}" ;;
*) bocker_help "$0" ;;
esac
README
Bocker
使用100行bash實現一個docker,本指令碼是依據bocker實現,更換了儲存驅動,完善了pull等功能。
前置條件
為了指令碼能夠正常執行,機器上需要具備以下元件:
overlayfs
iproute2
iptables
libcgroup-tools
util-linux >= 2.25.2
coreutils >= 7.5
大部分功能在centos7上都是滿足的,overlayfs可以通過modprobe overlay掛載。
另外你可能還要做以下設定:
建立bocker執行目錄 /var/lib/bocker/overlay,/var/lib/bocker/containers
建立一個IP地址為 172.18.0.1/24 的橋接網路卡 br1
確認開啟IP轉發 /proc/sys/net/ipv4/ip_forward = 1
建立iptables規則將橋接網路流量轉發至物理網路卡,範例:iptables -t nat -A POSTROUTING -s 172.18.0.0/24 -o eth0 -j MASQUERADE
實現的功能
docker build +
docker pull
docker images
docker ps
docker run
docker exec
docker logs
docker commit
docker rm / docker rmi
Networking
Quota Support / CGroups
+bocker init 提供了有限的 bocker build 能力
四、總結
到此本文要介紹的內容就結束了,正如開篇我們提到的,寫出最終的指令碼實現這樣一個小玩意並沒有什麼實用價值,真正的價值是我們通過100行左右的指令碼,以互動式的方式去理解Docker的核心技術點。在工作中與容器打交道時能有更多的思路去排查、解決問題。