論文翻譯:2022_Phase-Aware Deep Speech Enhancement: It’s All About The Frame Length
摘要
雖然相位感知語音處理近年來受到越來越多的關注,但大多數幀長約為32 ms的窄頻STFT方法顯示出相位對整體效能的影響相當有限。與此同時,現代基於深度神經網路(DNN)的方法,如Conv-TasNet,隱式修改幅度和相位,在非常短的幀(2 ms)上產生了出色的效能。
在這一觀察的啟發下,本文系統地研究了相位和幅度在不同幀長的DNN語音增強中的作用。結果表明,基於相位感知的神經網路可以充分利用之前關於純淨語音重建的研究表明:當使用短幀時,相位譜變得更加重要,而幅度譜的重要性降低。實驗表明,當同時估計幅度和相位時,較短的幀可以顯著提高具有顯式相位估計的DNN的效能。相反,如果只處理幅值不估計相位,32 ms幀可以獲得最佳效能。基於DNN的相位估計得益於使用較短的幀,並建議基於神經網路的相位感知語音增強方法推薦用約4 ms的幀長。
索引術語:語音增強,神經網路,幀長,相位感知
1 引言
單通道語音增強通常在時頻域進行,為了獲得時頻表示,可以應用諸如短時傅立葉變換(STFT)等具有多個自由引數的變換。這些引數(即幀長、幀移和窗函數,參見第2節)必須適當地選擇。然而,不僅要考慮訊號本身,還要考慮應用於時頻表示的演演算法;STFT引數的選擇應該產生對當前演演算法最有用的表示[1]。
本文重點關注基於深度神經網路(DNNs)的語音增強演演算法幀長的選擇,特別是針對相位感知方法。STFT表示是複數的,通常分為幅度譜和相位譜。相位譜與語音增強任務的相關性一直是一個爭論的話題。傳統上,由於經驗研究[2]和理論結果[3],它被認為是不重要的。然而,最近的研究表明,相位確實攜帶語音相關資訊[4]、[5]。受這些研究結果的推動,相位感知語音處理得到了一定程度的復興,並提出了多種相位感知語音處理方法,如[6]-[10]。
近年來,深度神經網路已迅速成為許多領域的首選工具,包括音訊和語音處理。因此,最近的許多相位感知的語音增強和聲源分離方法使用深度神經網路直接估計相位譜[11]-[13],或估計相位導數並從中重建相位[14],[15]。其他基於DNN的方法包括直接對複數譜進行操作,而不將[16]-[18]分為幅度和相位,或者僅考慮相位以改進幅度估計[19]。
一些作者採取了不同的方法,完全用學習到的編碼器-解碼器機制取代了基於STFT的表示,這通常會產生實數表示[20]-[22]。這些編碼器-解碼器方法一個有趣方面是,當使用大約2ms的非常短的幀時,它們表現出非常好的效能,甚至短至0.125毫秒[21]。這與基於STFT的方法形成了鮮明的對比,後者通常使用大約20 ms到60 ms的幀長。注意,雖然學習的編碼器-解碼器方法最初是為了源分離而提出的,但它們在語音增強任務[23],[24]上也表現出良好的效能。
隨著開創性的學習編碼器-解碼器Conv-TasNet模型[20]的釋出,一些作者提出了擴充套件和分析。在其他結果中,已經表明,ConvTasNet效能的主要影響因素是使用短幀和時域損失函數,而不是學習的編碼器-解碼器[25],[26]。研究還表明,當用STFT替換學習到的編碼器時,最佳輸入特徵集取決於所選擇的幀長[26],[27];對於較長的幀(25 ms到64 ms),幅度譜工作得很好,而較短的幀(2 ms到4 ms)只有將完整的複數譜作為輸入(以實部和虛部連線的形式)時才表現出更好的效能。這個觀察是特別重要的,因為它意味著相位感知語音處理(無論是隱式還是顯式相位估計)應該可能採用與僅幅值處理不同的幀長。
論文[24]雖然已經研究了相位感知語音增強DNNs中損失函數的選擇對於感知測量的影響,但我們還不知道關於幀長選擇的這種分析。先前與DNN無關的研究表明,相位對語音相關任務的重要性隨著STFT引數的選擇而變化。特別是,在不使用典型幀長(對應於大約20 ms到40 ms),使用更短幀[28],[29]或使用有效縮短幀[4],可以僅從相位譜中獲得非常好的訊號重建。對於較長的典型幀[28]、[30],也觀察到了類似的結果。然而,由於長幀會產生演演算法延遲,這對於許多實時語音處理裝置來說可能是禁止的,因此出於實際原因,我們選擇關注短幀。從[28]複製的圖1顯示了相位和幅度對重建純淨語音可懂度的貢獻如何隨著幀長的變化而變化。人們觀察到,隨著幀變短,相位變得更重要,而幅度逐漸失去相關性。然而,請注意,這些發現是基於oracle資料上的一些人工訊號重構實驗——它們是否也適用於實際的語音增強、源分離等尚不清楚。
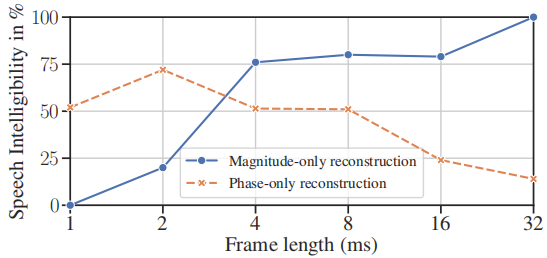
圖1:從[28]複製的結果摘錄,這裡顯示為說明目的。
從幅度譜或相位譜重構語音(用噪聲代替其他分量)時,得到的語音訊號的可懂度很大程度上取決於幀長的選擇。完整圖及詳細資訊見[28,圖2]。
語音處理中典型的幀長(約32 ms)可以被認為是準平穩的,但又足夠長,可以覆蓋多個濁音的基本週期(基本週期在2 ms到12.5 ms之間)[31]。這些考慮適用於幅度譜,但不一定適用於相位譜。事實上,似乎相位譜的不相關性部分是由於實驗中幀長的選擇。
基於之前的結果和觀察,本文試圖回答的問題是:哪種幀長對基於STFT的相位感知語音增強DNN最有利?以具有顯式相位估計的深度神經網路為例,分析和比較了不同幀長下的效能。為了獲得進一步的見解,本文還試圖描述每個幀長上的幅度和相位譜的相對貢獻,並表明上述關於短幀中相位重要性的觀察在語音增強的背景下也是相關和有用的。
2 預備知識
3 神經網路框架
本文提出的DNN架構是[12]中提出的用於視聽語音分離和增強的模型的改編,由鬆耦合的幅值和相位子網路組成。雖然我們在這裡不考慮音視訊輸入,但該模型相對簡單,可以對幅度和相位進行顯式估計,這對我們的實驗至關重要。與視訊流相關的部分被忽略,模型進行了相應的調整。結果網路如圖2所示,如下所述
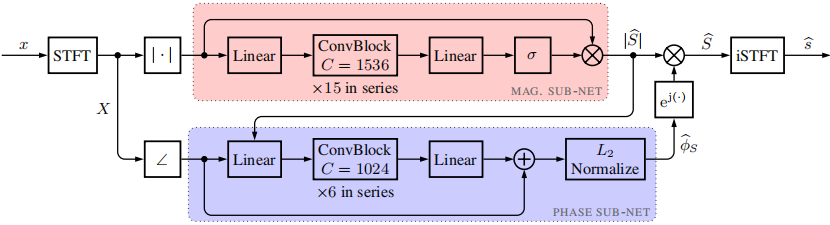
圖2:所提出的網路架構概述,基於[12]的視聽模型,儘管僅使用帶噪語音訊號作為輸入
基本折積塊如圖3所示。請注意,相位子網路的輸入由估計幅度以及噪聲相位的餘弦和正弦組成,為了簡單起見,這裡顯示為單個輸入
這兩個子網路都使用沿時間軸的一維深度可分離折積層[32]實現折積神經網路(在這種設定中,輸入端的不同頻點被視為通道)。兩個網路都由多個相同的殘差塊組成;基本構建塊由預啟用(ReLU)、批次歸一化層和折積層組成,折積層的輸出被新增到塊的輸入中(見圖3)。
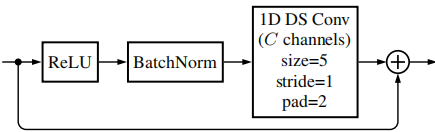
圖3 基本殘差折積塊,由ReLU預啟用、批次歸一化層和一維深度可分離折積層組成
3.1 幅度子網路
幅度子網路採用帶噪幅度譜$|X|$輸出一個實數掩模,該掩模應用於帶噪STFT幅度譜以產生幅度估計(注意,來自[12]的原始網路使用梅爾尺度的頻譜以及視訊特徵作為輸入)。噪聲幅度譜通過15個折積塊的鏈進行,每個折積塊有1536個輸入/輸出通道。輸入和輸出的線性層有助於對頻率間關係建模,並將資料投影到正確的維度。將sigmoid啟用函數應用於輸出,得到一個值在[0,1]內的實數掩碼。實數的掩模與輸入相乘,得到一個幅度估計$|\hat{S}|$。
3.2 相位子網路
相位子網路的輸入是沿頻率軸的$|\hat{S}|$, $cos(\phi X)$和$sin(\phi X)$的級聯。它被輸入到一個線性輸入層,隨後通過6個具有1024個通道的折積塊和一個線性輸出層。線性層的輸出被視為相位殘差的餘弦和正弦的級聯,它們被新增到各自的輸入。對得到的估計進行$L_2$歸一化,以確保餘弦和正弦輸出彼此一致(即它們表示複平面上的一個單位向量)。
3.3 訓練過程
與[12]中提出的多階段學習方法相比,我們只是在由不同訊雜比(SNR)的帶噪和純淨語音樣本對組成的整個訓練集上訓練網路(更多細節請參見第4.1節)。本文采用了一種時域損失函數,即負尺度不變訊號失真比(negative scale invariant signal to distortion ratio, SI-SDR)[33],而不是[12]中提出的頻域損失函數。當幅度譜和相位譜都被估計時,SISDR損失已經被證明可以產生優越的結果[26]。
4 實驗
我們進行的主要實驗是比較該模型在不同STFT幀長$M$的效能,在感知和客觀測量方面。由於我們考慮的模型包括相位和幅度的顯式估計,我們還能夠分析和量化幅度和相位估計的相對貢獻,再次作為幀長的函數。這種分析的方式與[4]、[28]、[29]中的感知實驗類似,儘管這裡我們使用純淨幅度和相位的估計,而不是純淨或噪聲訊號。對於每個幀長,我們產生三個純淨語音訊號的估計:網路的實際輸出以及兩個由估計幅度和噪聲相位組成的合成訊號,反之亦然:
$$公式4:\hat{s} =iSTFT\{|\widehat{S}| \mathrm{e}^{\mathrm{j} \widehat{\phi}_S}\}$$
$$公式5:\widehat{s}_{\mathrm{mag}} =iSTFT\{|\widehat{S}| \mathrm{e}^{\mathrm{j} \phi_X}\}$$
$$公式6:\widehat{s}_{\mathrm{ph}} =iSTFT\{|X| \mathrm{e}^{\mathrm{j} \widehat{\phi}_S}\}$$
為了進行公平的比較,我們必須保持DNN引數的數量恆定。在我們考慮的網路架構的情況下,引數的數量取決於頻點數量$K$。因此,我們在應用DFT之前對幀進行零補全,使得K = 257,這對應於$f_s$ = 16kHz時我們考慮的最長幀($M_t$ = 32 ms)。在所有實驗中,我們使用平方根Hann窗,重疊比R = 50%。同樣的視窗用於正向和逆STFT。
4.1 資料及訓練明細
在訓練中,我們使用2020年深度噪聲抑制(DNS)資料集[34]的純淨語音和噪聲,SNR$\in ${- 5,0,…, 10} dB。每個語音長度為2 s,資料集總共包含100 h的語音,其中80%用於訓練,剩餘20%用於驗證。使用Adam優化器訓練所有模型,batch size大小為32,學習率為$10^{-4}$。如果10個迭代週期內驗證損失沒有減少,則停止訓練。
在兩個測試集上進行評估:DNS合成無混響測試集,包含150個節選語音,每個語音10 s,訊雜比$\in ${0,1,…, 20}dB,另一個自定義測試集,由來自WSJ語料庫[35]的純淨語音和來自CHiME3資料集[36]的噪聲組成,混合訊雜比$\in ${−10,−5,…, 20} dB。該測試集共包含672個摘要。所有訓練和評估資料都以$f_s$ = 16kHz取樣。
5 結果和討論
表1:DNS測試集上的評估結果
對於每個重構訊號(如公式(4)到(6)展示了各種幀長下POLQA和ESTOI的改進(對帶噪輸入訊號的w.r.t.)
每列中最好的結果和接近的秒數以粗體顯示
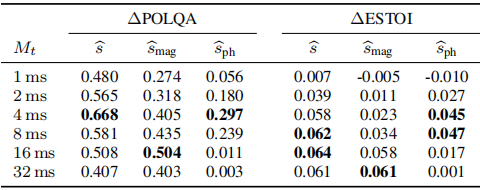
在DNS測試集上的評估結果如表1所示。雖然可理解性(在ESTOI方面)受幀長選擇的影響不大,但我們看到了對語音質量(POLQA)的顯著影響,它受益於減少幀長,直到在$M_t$ = 4 ms達到最大值,之後開始下降,但對於1 ms到2 ms的非常短的幀仍然達到相對較高的值。對於POLQA和ESTOI,基於幅度和基於相位的估計(分別為$\hat{s}_{mag}$和$\hat{s}_{ph}$)顯示了一幅有趣的影象:在$M_t$ = 32 ms時,$\hat{s}_{mag}$達到了與$\hat{s}$相似的值,而基於相位的估計$\hat{s}_{ph}$與噪聲輸入相比幾乎沒有改善。隨著幀長的減少,這種情況逐漸發生變化:基於幅度的估計失去了質量和可理解性,而基於相位的估計則相反。
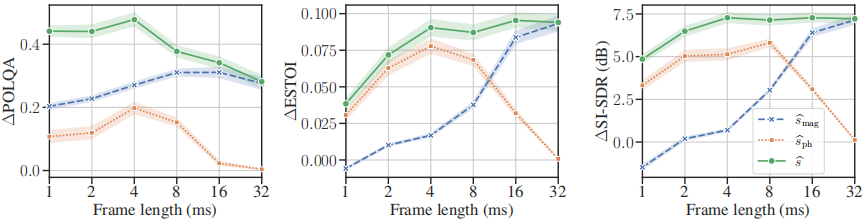
圖4:WSJ/CHiME測試集的評估結果(見章節4.1)。
圖中顯示了POLQA, ESTOI和SI-SDR在所有訊雜比下的平均改進隨幀長的變化。
誤差帶表示95%的置信區間。短幀有利於POLQA測量的語音估計質量。
此外,基於相位和基於幅度的重建的不同度量顯示出一種互補的行為,這讓人想起在之前的oracle實驗中觀察到的行為(參見圖1)。
如圖4所示,對更大的WSJ/CHiME資料集的評估在POLQA、ESTOI和SI-SDR方面顯示出類似的趨勢。雖然ESTOI和SI-SDR在幀長上幾乎保持不變,但POLQA顯然從較短的幀中受益。同樣,可以看到基於幅度和基於相位的估計的互補行為。這種行為非常類似於早期基於oracle的研究[28],[29]。實際上,∆ESTOI結果與圖1之間有驚人的相似之處,儘管基於相位的估計變得更好的點略有偏移。
POLQA的改進在Mt = 4 ms時達到最大,其中基於相位的估計也達到最大。當幀數更短時,所有三個指標的效能都會下降。總的來說,ESTOI和SI-SDR的改進似乎並不強烈依賴於幀長,儘管上述互補行為也可以清楚地觀察到。然而,在這種相位感知設定中,隨著幀變短,語音質量(POLQA)確實呈現上升趨勢。我們將這種依賴性歸因於相位和幅度譜的相對貢獻以及它們之間的相互作用。雖然基於幅值的估計顯示短幀的質量下降,但相位譜的貢獻提高了整體效能,導致了優越的結果。
由於圖4中的結果是在所有訊雜比下的平均結果,我們在圖5中通過顯示兩個選定幀長(4 ms, 16 ms)在不同訊雜比下的POLQA改進來提供進一步的瞭解。除了較短幀的整體效能較好和較長幀的相位估計不重要之外(cf. Fig. 4),基於幅度和相位估計的質量對訊雜比的依賴性更強。特別是,在低訊雜比(≤0 dB)下,基於相位的估計實際上超過了基於幅度的估計,這表明相位估計在困難的噪聲條件下尤其有益,根據先前的感知研究[37]。這也轉化為聯合估計的情況(即$\hat{s}$),其中幀長之的∆POLQA差異在低訊雜比下更明顯。
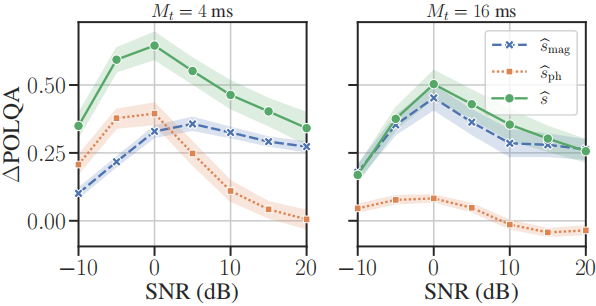
圖5:M_t$\in ${4,16}ms WSJ/CHiME測試集上的平均POLQA改進,顯示為輸入訊雜比的函數
6 結論
在這項工作中,我們提出了一項關於幀長對基於DNNs的STFT相位感知語音增強的影響的研究。結果表明,通過使用相對較短的幀(4 ms),與通常在基於STFT的處理中使用的較長幀相比,效能有了顯著提高。此外,通過顯式估計相位和幅度,我們能夠表明這種效能提升與幅度和相位估計的單獨貢獻有關,這高度依賴於幀長。這反映了以前在oracle資料上的實驗得出的見解,同時首次表明,可以利用這一現象來改善語音增強結果。
7 貢獻
這項工作得到了德意志Forschungsgemeinschaft (DFG,德國研究基金會)的資助-專案編號247465126。我們要感謝J. Berger和Rohde&Schwarz swiss squal AG對POLQA的支援。
8 參考文獻
[1] T. Virtanen, E. Vincent, and S. Gannot, 「Time-Frequency Processing: Spectral Properties,」 in Audio Source Separation and Speech Enhancement, John Wiley & Sons, Ltd, 2018, pp. 15–29.
[2] D. Wang and J. Lim, 「The unimportance of phase in speech enhancement,」 IEEE Trans. on Acoustics, Speech, and Signal Processing, vol. 30, no. 4, pp. 679–681, Aug. 1982. ∆POLQA ∆ESTOI ∆SI-SDR (dB) ∆POLQA
[3] Y. Ephraim and D. Malah, 「Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator,」 IEEE Trans. on Acoustics, Speech, and Signal Processing, vol. 32, no. 6, pp. 1109–1121, Dec. 1984.
[4] K. Paliwal, K. W´ojcicki, and B. Shannon, 「The importance of phase in speech enhancement,」 Speech Communication, vol. 53, no. 4, pp. 465–494, Apr. 2011.
[5] T. Gerkmann, M. Krawczyk-Becker, and J. Le Roux, 「Phase Processing for Single-Channel Speech Enhancement: History and recent advances,」 IEEE Signal Processing Magazine, vol. 32, no. 2, pp. 55–66, Mar. 2015.
[6] J. Le Roux and E. Vincent, 「Consistent Wiener Filtering for Audio Source Separation,」 IEEE Signal Processing Letters, vol. 20, no. 3, pp. 217–220, Mar. 2013.
[7] T. Gerkmann, 「MMSE-optimal enhancement of complex speech coefficients with uncertain prior knowledge of the clean speech phase,」 in 2014 IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), May 2014.
[8] ——, 「Bayesian Estimation of Clean Speech Spectral Coeffi- cients Given a Priori Knowledge of the Phase,」 IEEE Trans. Signal Process., vol. 62, no. 16, pp. 4199–4208, Aug. 2014.
[9] M. Krawczyk and T. Gerkmann, 「STFT Phase Reconstruction in Voiced Speech for an Improved Single-Channel Speech Enhancement,」 IEEE/ACM Trans. Audio Speech Lang. Process., vol. 22, no. 12, pp. 1931–1940, Dec. 2014.
[10] P. Mowlaee and J. Kulmer, 「Harmonic Phase Estimation in Single-Channel Speech Enhancement Using Phase Decomposition and SNR Information,」 IEEE/ACM Trans. on Audio, Speech, and Language Processing, vol. 23, no. 9, pp. 1521–1532, Sep. 2015.
[11] N. Takahashi, P. Agrawal, N. Goswami, and Y. Mitsufuji, 「PhaseNet: Discretized Phase Modeling with Deep Neural Networks for Audio Source Separation,」 in Interspeech 2018, Sep. 2, 2018.
[12] T. Afouras, J. S. Chung, and A. Zisserman, 「The Conversation: Deep Audio-Visual Speech Enhancement,」 in Interspeech 2018, Sep. 2, 2018.
[13] J. Le Roux, G. Wichern, S. Watanabe, A. Sarroff, and J. R. Hershey, 「Phasebook and Friends: Leveraging Discrete Representations for Source Separation,」 IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 2, pp. 370–382, May 2019.
[14] N. Zheng and X.-L. Zhang, 「Phase-Aware Speech Enhancement Based on Deep Neural Networks,」 IEEE/ACM Trans. on Audio, Speech, and Language Processing, vol. 27, no. 1, pp. 63–76, Jan. 2019.
[15] Y. Masuyama, K. Yatabe, Y. Koizumi, Y. Oikawa, and N. Harada, 「Phase Reconstruction Based On Recurrent Phase Unwrapping With Deep Neural Networks,」 in 2020 IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), May 2020.
[16] D. S. Williamson, Y. Wang, and D. Wang, 「Complex ratio masking for joint enhancement of magnitude and phase,」 in 2016 IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), Mar. 2016.
[17] K. Tan and D. Wang, 「Learning Complex Spectral Mapping With Gated Convolutional Recurrent Networks for Monaural Speech Enhancement,」 IEEE/ACM Trans. on Audio, Speech, and Language Processing, vol. 28, pp. 380–390, 2020.
[18] Y. Hu, Y. Liu, S. Lv, M. Xing, S. Zhang, Y. Fu, J. Wu, B. Zhang, and L. Xie, 「DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement,」 in Interspeech 2020, Oct. 25, 2020.
[19] H. Erdogan, J. R. Hershey, S. Watanabe, and J. Le Roux, 「Phasesensitive and recognition-boosted speech separation using deep recurrent neural networks,」 in 2015 IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), Apr. 2015.
[20] Y. Luo and N. Mesgarani, 「Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation,」 IEEE/ACM Trans. on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1256–1266, Aug. 2019.
[21] Y. Luo, Z. Chen, and T. Yoshioka, 「Dual-Path Rnn: Efficient Long Sequence Modeling for Time-Domain Single-Channel Speech Separation,」 in 2020 IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), May 2020.
[22] C. Subakan, M. Ravanelli, S. Cornell, M. Bronzi, and J. Zhong, 「Attention Is All You Need In Speech Separation,」 in 2021 IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), Jun. 2021.
[23] Y. Koyama, T. Vuong, S. Uhlich, and B. Raj, 「Exploring the Best Loss Function for DNN-Based Low-latency Speech Enhancement with Temporal Convolutional Networks,」 Aug. 20, 2020. arXiv: 2005.11611 [cs, eess].
[24] Z.-Q. Wang, G. Wichern, and J. Le Roux, 「On the Compensation Between Magnitude and Phase in Speech Separation,」 IEEE Signal Processing Letters, vol. 28, pp. 2018–2022, 2021.
[25] D. Ditter and T. Gerkmann, 「A Multi-Phase Gammatone Filterbank for Speech Separation Via Tasnet,」 in 2020 IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), May 2020.
[26] J. Heitkaemper, D. Jakobeit, C. Boeddeker, L. Drude, and R. Haeb-Umbach, 「Demystifying TasNet: A Dissecting Approach,」 in 2020 IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), May 2020.
[27] M. Pariente, S. Cornell, A. Deleforge, and E. Vincent, 「Filterbank Design for End-to-end Speech Separation,」 in 2020 IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), May 2020.
[28] M. Kazama, S. Gotoh, M. Tohyama, and T. Houtgast, 「On the significance of phase in the short term Fourier spectrum for speech intelligibility,」 The Journal of the Acoustical Society of America, vol. 127, no. 3, pp. 1432–1439, 2010.
[29] T. Peer and T. Gerkmann, 「Intelligibility Prediction of Speech Reconstructed From Its Magnitude or Phase,」 in Speech Communication; 14th ITG Conference, Kiel (online), Sep. 2021.
[30] L. Alsteris and K. Paliwal, 「Importance of window shape for phase-only reconstruction of speech,」 in 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, vol. 1, May 2004.
[31] K. K. Paliwal, J. G. Lyons, and K. K. W´ojcicki, 「Preference for 20-40 ms window duration in speech analysis,」 in 2010 4th International Conference on Signal Processing and Communication Systems, 2010.
[32] F. Chollet, 「Xception: Deep Learning with Depthwise Separable Convolutions,」 in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, Jul. 2017.
[33] J. Le Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, 「SDR – Half-baked or Well Done?」 In 2019 IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), May 2019.
[34] C. K. Reddy, V. Gopal, R. Cutler, E. Beyrami, R. Cheng, H. Dubey, S. Matusevych, R. Aichner, A. Aazami, S. Braun, P. Rana, S. Srinivasan, and J. Gehrke, 「The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results,」 in Interspeech 2020, Oct. 25, 2020.
[35] D. B. Paul and J. M. Baker, 「The design for the wall street journal-based CSR corpus,」 in Proceedings of the Workshop on Speech and Natural Language - HLT ’91, Harriman, New York, 1992.
[36] J. Barker, R. Marxer, E. Vincent, and S. Watanabe, 「The third ‘CHiME’ speech separation and recognition challenge: Dataset, task and baselines,」 in 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), 2015.
[37] M. Krawczyk-Becker and T. Gerkmann, 「An evaluation of the perceptual quality of phase-aware single-channel speech enhancement,」 The Journal of the Acoustical Society of America, vol. 140, no. 4, EL364–EL369, Oct. 2016.