機器學習基礎總結
一,機器學習系統分類
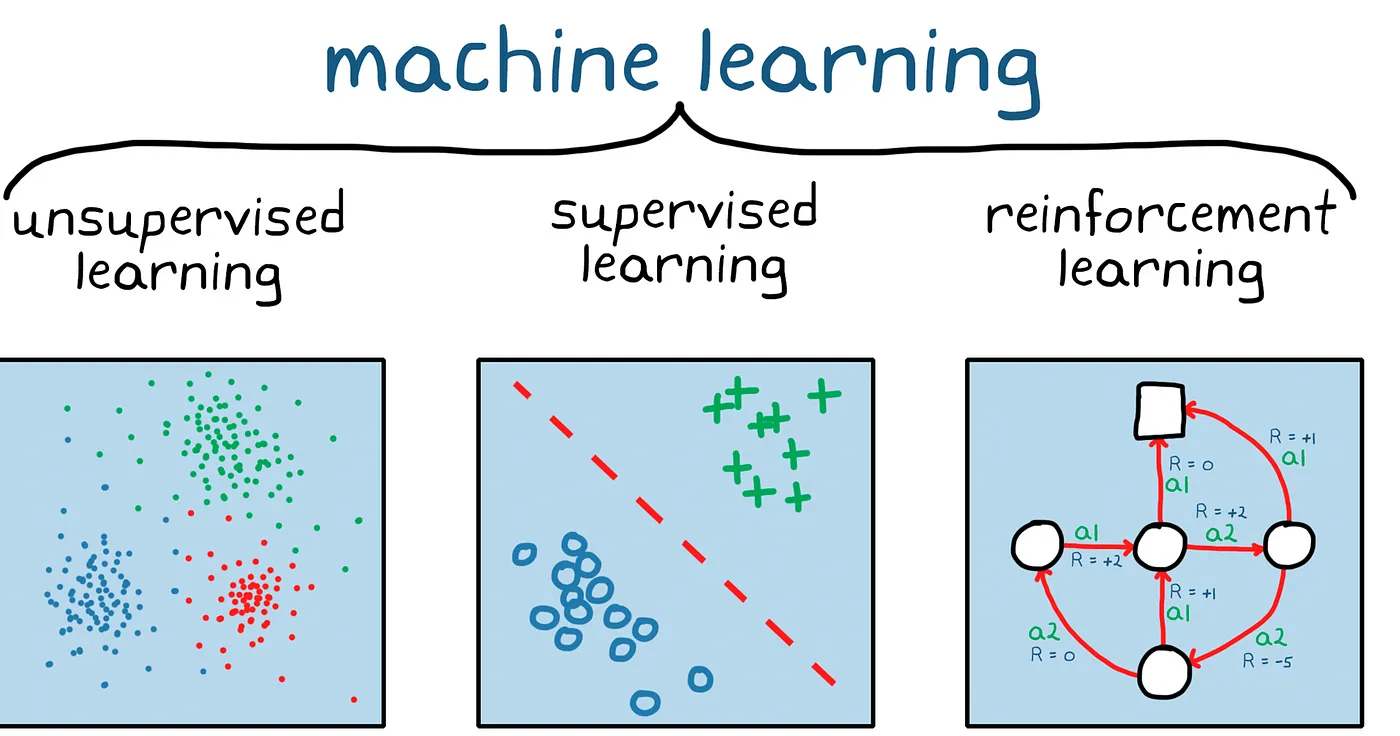
機器學習系統分為三個類別,如下圖所示:
二,如何處理資料中的缺失值
可以分為以下 2 種情況:
- 缺失值較多:直接捨棄該列特徵,否則可能會帶來較大噪聲,從而對結果造成不良影響。
- 缺失值較少:當缺失值較少(
< 10%)時,可以考慮對缺失值進行填充,有幾下幾種填充策略:- 用一個異常值填充(比如 0 ),缺失值作為一個特徵處理:
data.fillna(0) - 用均值|條件均值填充:
data.fillna(data.mean()) - 用相鄰資料填充:
data.fillna(method='pad'),data.fillna(method='bfill') - 插值:
data.interpolate() - 擬合:簡單來說,就是將缺失值也作為一個預測問題來處理:將資料分為正常資料和缺失資料,對有值的資料採用
隨機森林等方法擬合,然後對有缺失值的資料進行預測,用預測的值來填充
- 用一個異常值填充(比如 0 ),缺失值作為一個特徵處理:
三,資料淨化與特徵處理
機器學習中的資料淨化與特徵處理綜述
美團的這篇綜述文章總結得不錯,雖然缺少範例不容易直觀理解,但是初學者來說也足夠了。
3.1,清洗標註資料
清洗標註資料的方法,主要是是資料取樣和樣本過濾。
資料取樣:對於分類問題:選取正例,負例。對於迴歸問題,需要採集資料。對於取樣得到的文字,根據需要設定樣本權重,當模型不能使用全部的資料來訓練時,需要對資料進行取樣,設定一定的取樣率。取樣的方法包括隨機取樣,固定比例取樣等方法。- 樣本過濾:1.結合業務情況進行資料的過濾,例如去除crawler抓取,spam,作弊等資料。 - 2.異常點檢測,採用異常點檢測演演算法對樣本進行分析,常用的異常點檢測演演算法包括 - 偏差檢測,例如聚類,最近鄰等。
3.2,特徵分類
根據不同的分類方法,可以將特徵分為:
Low level特徵和High level特徵- 穩定特徵與動態特徵。
- 二值特徵、連續特徵、列舉特徵
Low level 特徵是較低階別的特徵,主要是原始特徵,不需要或者需要很少的人工處理和干預,例如文字中的詞向量特徵,影象特徵中的畫素點大小,使用者 id,商品 id等。High level 特徵是經過比較複雜的處理,結合部分業務邏輯或者規則、模型得到的特徵,例如人工打分,模型打分等特徵,可以用於較複雜的非線性模型。Low level 比較針對性,覆蓋面小。長尾樣本的預測值主要受 high level 特徵影響。 高頻樣本的預測值主要受 low level 特徵影響。
穩定特徵 是變化頻率較少的特徵,例如評價平均分,團購單價價格等,在較長時間段內數值都不會發生變化。動態特徵是更新變化比較頻繁的特徵,有些甚至是實時計算得到的特徵,例如距離特徵,2 小時銷量等特徵。或者叫做實時特徵和非實時特徵。針對兩類特徵的不同可以針對性地設計特徵儲存和更新方式,例如對於穩定特徵,可以建入索引,較長時間更新一次,如果做快取的話,快取的時間可以較長。對於動態特徵,需要實時計算或者準實時地更新資料,如果做快取的話,快取過期時間需要設定的較短。
二值特徵主要是 0/1 特徵,即特徵只取兩種值:0 或者 1,例如使用者 id 特徵:目前的 id 是否是某個特定的 id,詞向量特徵:某個特定的詞是否在文章中出現等等。連續值特徵是取值為有理數的特徵,特徵取值個數不定,例如距離特徵,特徵取值為是0~正無窮。列舉值特徵主要是特徵有固定個數個可能值,例如今天周幾,只有7個可能值:周1,周2,…,週日。在實際的使用中,我們可能對不同型別的特徵進行轉換,例如將列舉特徵或者連續特徵處理為二值特徵。列舉特徵處理為二值特徵技巧:將列舉特徵對映為多個特徵,每個特徵對應一個特定列舉值,例如今天周幾,可以把它轉換成7個二元特徵:今天是否是週一,今天是否是週二,…,今天是否是週日。連續值處理為二值特徵方法:先將連續值離散化(後面會介紹如何離散化),再將離散化後的特徵切分為N個二元特徵,每個特徵代表是否在這個區間內。
3.3,特徵處理與分析
對特徵進行分類後,需要對特徵進行處理,常用的特徵處理方法如下:
- 特徵歸一化,離散化,預設值處理
- 特徵降維方法
- 特徵選擇方法
特徵歸一化。在有些演演算法中,例如線性模型或者距離相關的模型(聚類模型、knn 模型等),特徵值的取值範圍會對最終的結果產生較大影響,例如輸入資料有兩種不同的特徵,其中的二元特徵取值範圍 [0, 1],而距離特徵取值可能是 [0,正無窮],兩種特徵取值範圍不一致,導致模型可能會偏向於取值範圍較大額特徵,為了平衡取值範圍不一致的特徵,需要對特徵進行歸一化處理,將特徵值取值歸一化到 [0,1] 區間,常用的歸一化方法包括:
函數歸一化,通過對映函數將特徵取值對映到[0,1]區間,例如最大最小值歸一化方法,是一種線性的對映。還有通過非線性函數的對映,例如log函數等。分維度歸一化,可以使用最大最小歸一化方法,但是最大最小值選取的是所屬類別的最大最小值,即使用的是區域性最大最小值,不是全域性的最大最小值。排序歸一化,不管原來的特徵取值是什麼樣的,將特徵按大小排序,根據特徵所對應的序給予一個新的值。
離散化。在上面介紹過連續值的取值空間可能是無窮的,為了便於表示和在模型中處理,需要對連續值特徵進行離散化處理。常用的離散化方法包括等值劃分和等量劃分。
等值劃分,是將特徵按照值域進行均分,每一段內的取值等同處理。例如某個特徵的取值範圍為 [0,10],我們可以將其劃分為10段,[0,1),[1,2),…,[9,10)。等量劃分,是根據樣本總數進行均分,每段等量個樣本劃分為 1 段。例如距離特徵,取值範圍[0,3000000],現在需要切分成 10 段,如果按照等比例劃分的話,會發現絕大部分樣本都在第 1 段中。使用等量劃分就會避免這種問題,最終可能的切分是[0,100),[100,300),[300,500),..,[10000,3000000],前面的區間劃分比較密,後面的比較稀疏。
預設值處理。有些特徵可能因為無法取樣或者沒有觀測值而缺失,例如距離特徵,使用者可能禁止獲取地理位置或者獲取地理位置失敗,此時需要對這些特徵做特殊的處理,賦予一個預設值。預設值如何賦予,也有很多種方法。例如單獨表示,眾數,平均值等。
四,交叉驗證
交叉驗證是機器學習當中的概念,一般深度學習不會使用交叉驗證方法,原因是深度學習的資料集一般都很大。但是也有例外,Kaggle 的一些醫療類比賽,訓練集一般只有幾千張,由於訓練資料很少,用來作為驗證集的資料會非常少,因此訓練的模型在驗證集上精度可能會有很大波動,這直接取決於我們所選擇的驗證集和訓練集劃分方式,也就是說,驗證集的劃分方式可能會造成驗證集精度存在較大方差,從而無法對模型進行有效評估,同時也無法進行有效的超引數調整(batch 設定多少模型最佳收斂)。
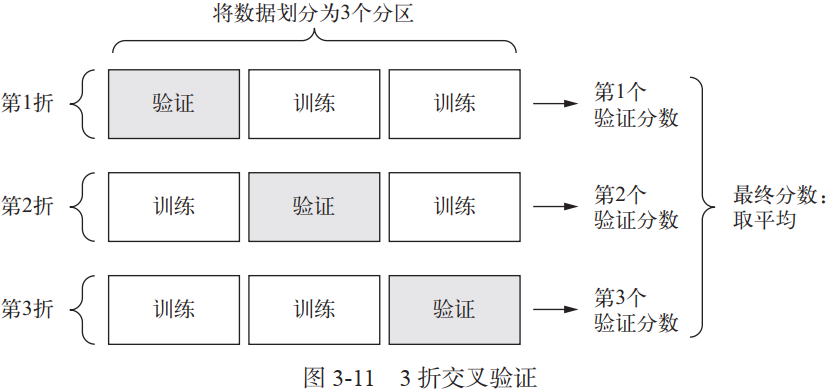
一個有效的解決辦法是,在訓練資料上面,我們可以進行交叉驗證(Cross-Validation)·。一種方法叫做 ·K-fold Cross Validation ( K 折交叉驗證), K 折交叉驗證,初始取樣分割成 K 個子樣本,一個單獨的子樣本被保留作為驗證模型的資料,其他 K-1 個樣本用來訓練。交叉驗證重複 K 次,每個子樣本驗證一次,平均 K 次模型訓練的結果,最終輸出一個單一估測。k-折交叉驗證的訓練集劃分方式如下圖所示:
- 當
K值大的時候, 我們會有更少的Bias(偏差), 更多的Variance。 - 當
K值小的時候, 我們會有更多的Bias(偏差), 更少的Variance。
k 折交叉驗證的程式碼實現可以參考《Python深度學習》第三章,在模型訓練好後,可通過計算所有 Epoch 的 K 折驗證分數的平均值,並繪製每輪的模型驗證指標變化曲線,觀察哪個 Epoch 後模型不再收斂,從而完成模型調參工作。同時,K 折交叉驗證方式訓練模型會得到 K個模型,將這個 K 個模型在測試集上的推理結果取平均值或者投票,也是一種 Ensemble 方式,可以增強模型泛化性,防止過擬合。
# 計算所有輪次中的 K 折驗證分數平均值
average_mae_history = [np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
參考資料
版權宣告 ©
本文作者:嵌入式視覺
本文連結:https://www.cnblogs.com/armcvai/p/17097079.html
版權宣告:本文為「嵌入式視覺」的原創文章,首發於 github ,遵循 CC BY-NC-ND 4.0 版權協定,著作權歸作者所有,轉載請註明出處!
鼓勵博主:如果您覺得文章對您有所幫助,可以點選文章右下角【推薦】一下。您的鼓勵就是博主最大的動力!