「堆外快取」這玩意是真不錯,我要寫進簡歷了。
你好呀,我是歪歪。
之前在《3 招將吞吐量提升了 100%,現在它是我的了》這篇文章中,我在 OHC 堆外快取上插了個眼:

這次就把這個眼給回收了吧,給你盤一下 OHC。
之前的文章裡面說的是啥場景呢,我們先簡單回顧一下。
就是一個服務的各項 JVM 的設定都比較合理的情況下,它的 GC 情況還是不容樂觀。
然後 dump 了一把記憶體,一頓分析之後發現有 2 個物件特別巨大,佔了總存活堆記憶體的 76.8%。其中第 1 大物件是本地快取, GC 之後依舊存活,幹都幹不掉。
怎麼辦呢?
把快取物件移到堆外。
因為堆外記憶體並不在 GC 的工作範圍內,所以避免了快取過大對 GC 的影響。
堆外記憶體不受堆內記憶體大小的限制,只受伺服器實體記憶體的大小限制。這三者之間的關係是這樣的:實體記憶體=堆外記憶體+堆內記憶體。
對於堆外記憶體的使用,有個現成開源專案就是 OHC,開箱即用,香的一比。
當時就是這樣做了一個簡單的介紹,也沒有深入的去分析,我個人對這個 OHC 還是比較感興趣,但是有一說一,這玩意應用場景是真的不豐富,但是如果恰巧碰到了可以使用的應用場景。就可以開始你的表(裝)演(逼)了
什麼是可以使用的應用場景?
就是你的本地快取物件特別多,多到都把你「堆」裡面都快塞滿了,從而 GC 頻繁、時間長,都影響到服務的正常執行了。
這個時候一撥人說:我要求調整 JVM 引數,調大堆記憶體。
還有一撥人說:依我看,這個本地快取乾脆就別濫用了,非必要,不快取,減少記憶體佔用。
另外一撥人說:又不是不能用?
大家爭得面紅耳赤的時候,你輕飄飄的來一句:這個問題我覺得可以用堆外記憶體來解決,比如有個開源專案叫做 OHC,就比較好,可以調研一下。
事了拂衣去,深藏身與名。
所以為了以後能更好的裝這個逼,這篇文章我準備盤一盤它,但是先說好,本文不會帶你去盤原始碼,只是讓你知道有這個框架的存在,做個簡單的導讀而已。
Demo
老規矩,對於自己不瞭解的技術,都是先會簡單使用,再深入瞭解。
所以還是得搞個 Demo 才行,直接到它的 github 上找 Quickstart 就完事它的 Quickstart 就這麼一行程式碼:
https://github.com/snazy/ohc
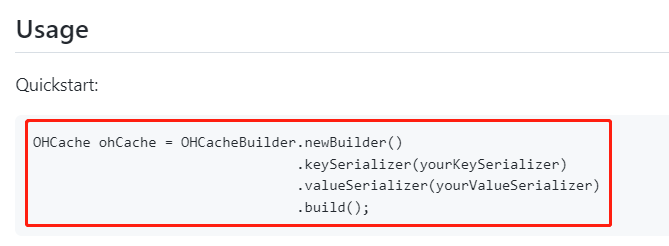
我看到的第一眼就是覺得這也太簡陋了,在我想象中,一個好的 Quickstart 是我自己貼上過來就能直接跑,很顯然,它這個不行,本資深白嫖黨表示強烈的譴責以及極度憤怒。

但是沒辦法,還是先粘過來再說。
對了,記得先匯入 maven 依賴:
<dependency>
<groupId>org.caffinitas.ohc</groupId>
<artifactId>ohc-core</artifactId>
<version>0.7.4</version>
</dependency>
貼上過來之後,我發現它這屬於一個填空題啊:
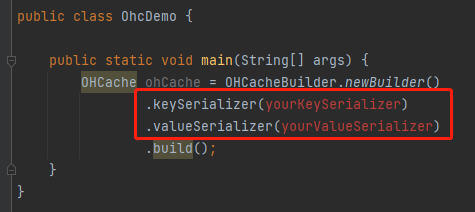
key 和 value 的序列化方式並沒有給我們提供,而是需要我們進行自定義,這一點在它的 README 中也提到了:

它說 key 和 value 的序列化需要去實現 CacheSerializer 介面,這個介面三個方法,分別是物件序列化之後的長度,序列化和反序列化方法。
需要自己去實現一個序列化方式,一瞬間我的腦海裡面蹦出了好幾個關鍵詞:Protobuf、Thrift、kryo、hessian 什麼的。
但是都太麻煩了,還得自己去編碼,我只是想搞個 Demo 嚐個味道而已,要是能從哪兒直接借鑑一個過來就好了。
所以,我把 OHC 的原始碼拉下來了,因為直覺告訴我,它的測試用例裡面肯定有現成的序列化方案。
果不其然,測試案例非常的多,而我找到了這個:
org.caffinitas.ohc.linked.TestUtils
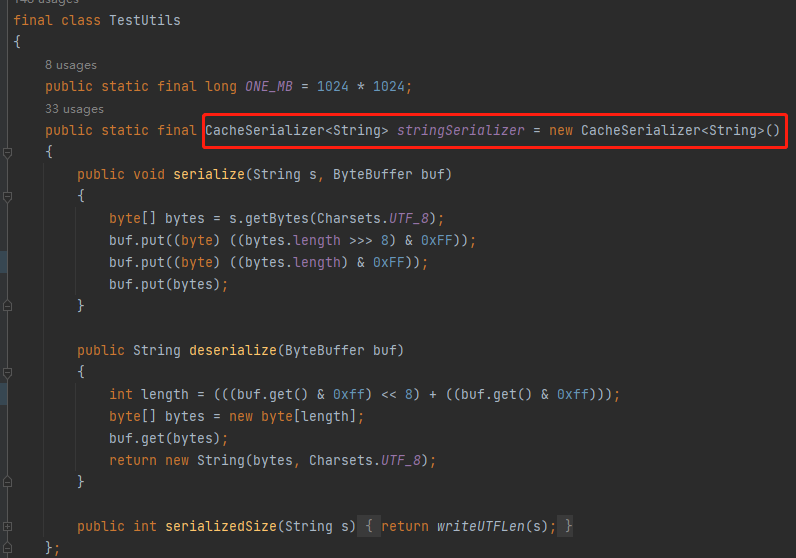
這個序列化方式就是測試用例裡面廣泛使用的方式:
現在序列化方式有了,那麼整個完整的程式碼就是這樣的,我也給你搞個舒服的 Quickstart,粘過去就能用那種:
public class OhcDemo {
public static void main(String[] args) {
OHCache ohCache = OHCacheBuilder.<String, String>newBuilder()
.keySerializer(OhcDemo.stringSerializer)
.valueSerializer(OhcDemo.stringSerializer)
.build();
ohCache.put("hello","why");
System.out.println("ohCache.get(hello) = " + ohCache.get("hello"));
}
public static final CacheSerializer<String> stringSerializer = new CacheSerializer<String>() {
public void serialize(String s, ByteBuffer buf) {
// 得到字串物件UTF-8編碼的位元組陣列
byte[] bytes = s.getBytes(Charsets.UTF_8);
// 用前16位元記錄陣列長度
buf.put((byte) ((bytes.length >>> 8) & 0xFF));
buf.put((byte) ((bytes.length) & 0xFF));
buf.put(bytes);
}
public String deserialize(ByteBuffer buf) {
// 獲取位元組陣列的長度
int length = (((buf.get() & 0xff) << 8) + ((buf.get() & 0xff)));
byte[] bytes = new byte[length];
// 讀取位元組陣列
buf.get(bytes);
// 返回字串物件
return new String(bytes, Charsets.UTF_8);
}
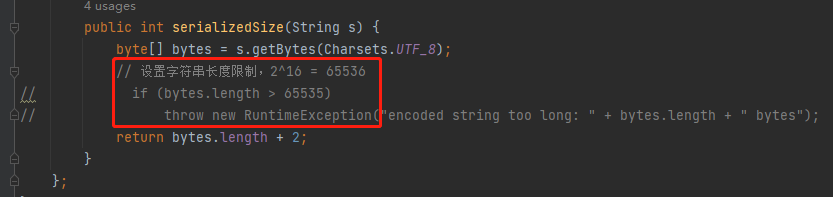
public int serializedSize(String s) {
byte[] bytes = s.getBytes(Charsets.UTF_8);
// 設定字串長度限制,2^16 = 65536
if (bytes.length > 65535)
throw new RuntimeException("encoded string too long: " + bytes.length + " bytes");
return bytes.length + 2;
}
};
}
從上面的 Demo 你也能看出來,OHCache 這個東西,和 Map 差不多,基本方法也是 put,get。
只是 put 的物件,也就是快取的物件,是由使用者自定義的序列化方法決定的。比如我上面這個只能快取字串型別,如果你想要放個自定義物件進去,就得實現一個自定義物件的系列化方法,很簡單的,網上搜一下,多的很。
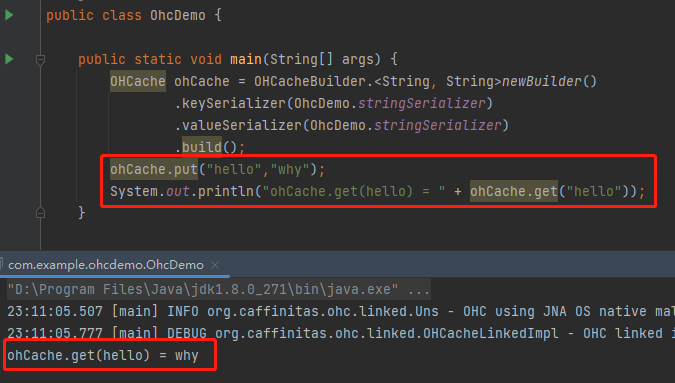
現在我們已經有一個可以執行的 Demo 了,執行之後輸出是這樣的,沒有任何毛病:
Demo 跑起來了,我們就算是找到「抓手」了,接下來就是分析它,結合自己的實際業務,沉澱出一套「可遷移、可複用」的組合拳,用來給自己「賦能」。

對比
為了讓你能更加直觀的看到堆外記憶體和堆內記憶體的區別,我給你搞兩段程式跑跑。
首先是我們堆內記憶體的代表選手,HashMap:
/**
* -Xms100m -Xmx100m
*/
public class HashMapCacheExample {
private static HashMap<String, String> HASHMAP = new HashMap<>();
public static void main(String[] args) throws InterruptedException {
hashMapOOM();
}
private static void hashMapOOM() throws InterruptedException {
//準備時間,方便觀察
TimeUnit.SECONDS.sleep(10);
int num = 0;
while (true) {
//往 map 中存放 1M 大小的字串
String big = new String(new byte[1024 * 1024]);
HASHMAP.put(num + "", big);
num++;
}
}
}
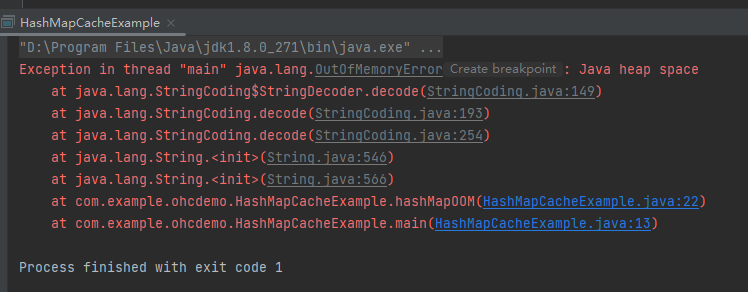
通過 JVM 引數控制堆記憶體大小為 100m,然後不斷的往 Map 中存放 1M 大小的字串,那麼這個程式很快就會出現 OOM:
其對應的在 visualvm 裡面的記憶體走勢圖是這樣的:
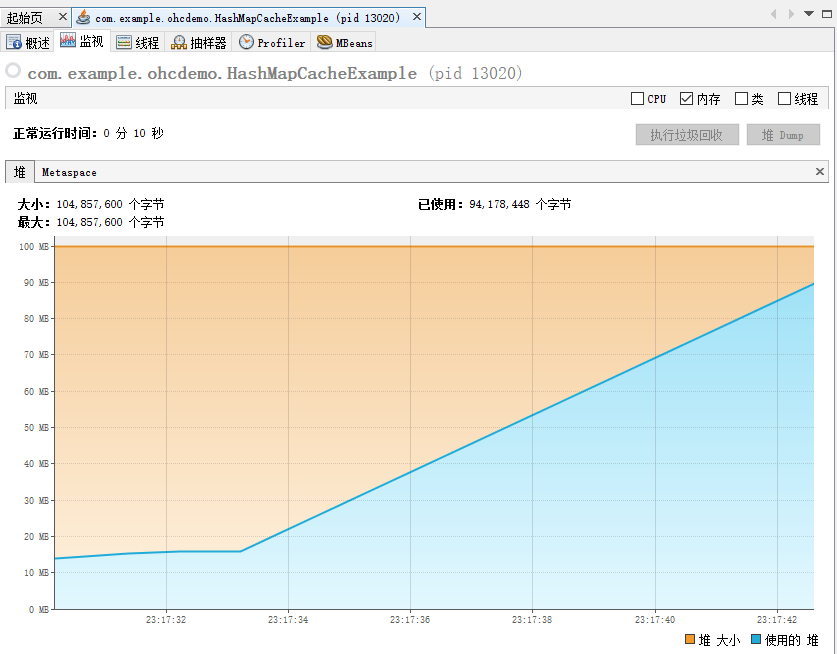
程式基本上屬於一啟動,然後記憶體就被塞滿了,接著立馬就涼了。
屬於秒了,被秒殺了。
但是,當我們同樣的邏輯,用堆外記憶體的時候,情況就不一樣了:
/**
* -Xms100m -Xmx100m
*/
public class OhcCacheDemo {
public static void main(String[] args) throws InterruptedException {
//準備時間,方便觀察
TimeUnit.SECONDS.sleep(10);
OHCache ohCache = OHCacheBuilder.<String, String>newBuilder()
.keySerializer(stringSerializer)
.valueSerializer(stringSerializer)
.build();
int num = 0;
while (true) {
String big = new String(new byte[1024 * 1024]);
ohCache.put(num + "", big);
num++;
}
}
public static final CacheSerializer<String> stringSerializer = new CacheSerializer<String>() {//前面寫過,這裡略了};
}
關於上面程式中的 stringSerializer 需要注意一點的是我做測試的時候把這個大小的限制取消掉了,目的是和 HashMap 做測試是用同樣大小為 1M 的字串:
這是程式執行了 3 分鐘之後的記憶體走勢圖:
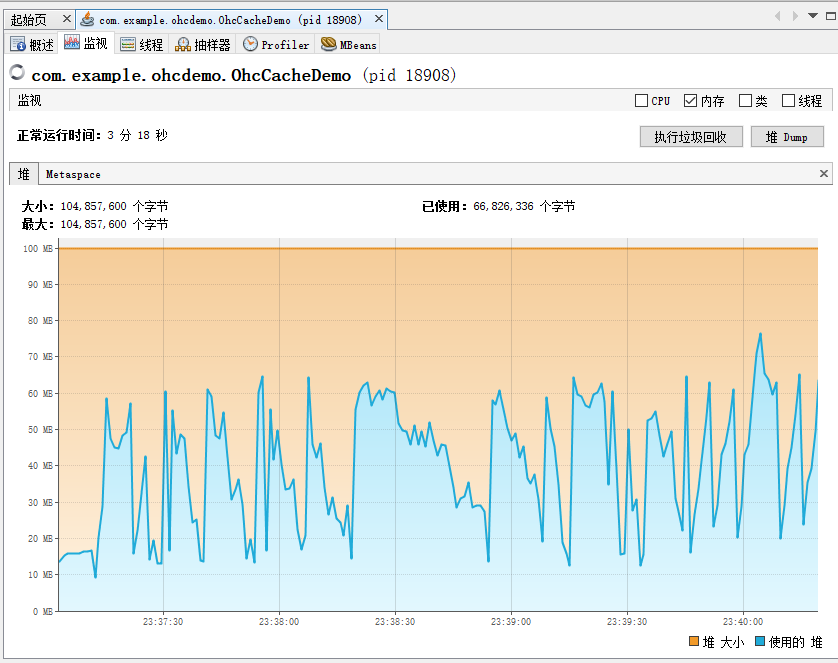
這個圖怎麼說呢?
醜是醜了點,但是咱就是說至少沒秒,程式沒崩。
當這兩個記憶體走勢圖一對比,是不是稍微就有那麼一點點感覺了。
但是另外一個問題就隨之而來了:我怎麼看 OHCache 這個玩意佔用的記憶體呢?
前面說了,它屬於堆外記憶體。JVM 的堆外,那就是我本機的記憶體了。
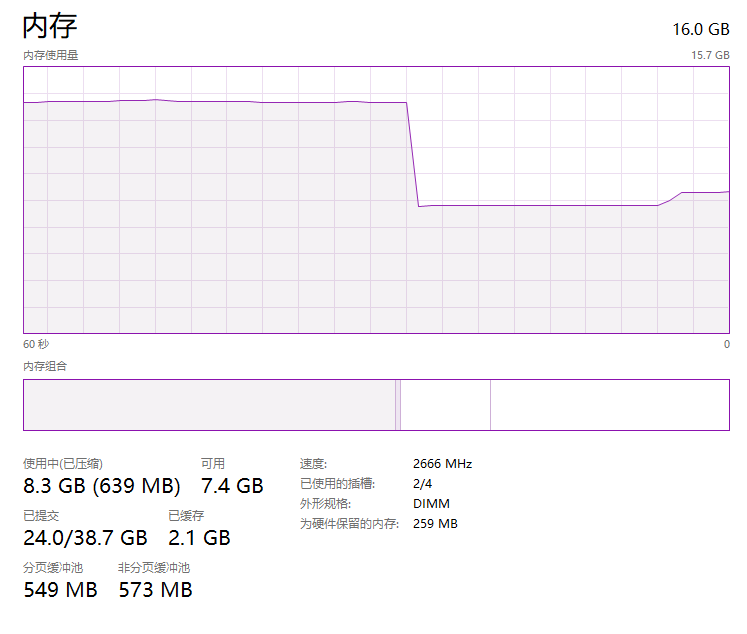
開啟工作管理員,切換到記憶體的走勢圖,正常來說走勢圖是這樣的,非常的平穩:
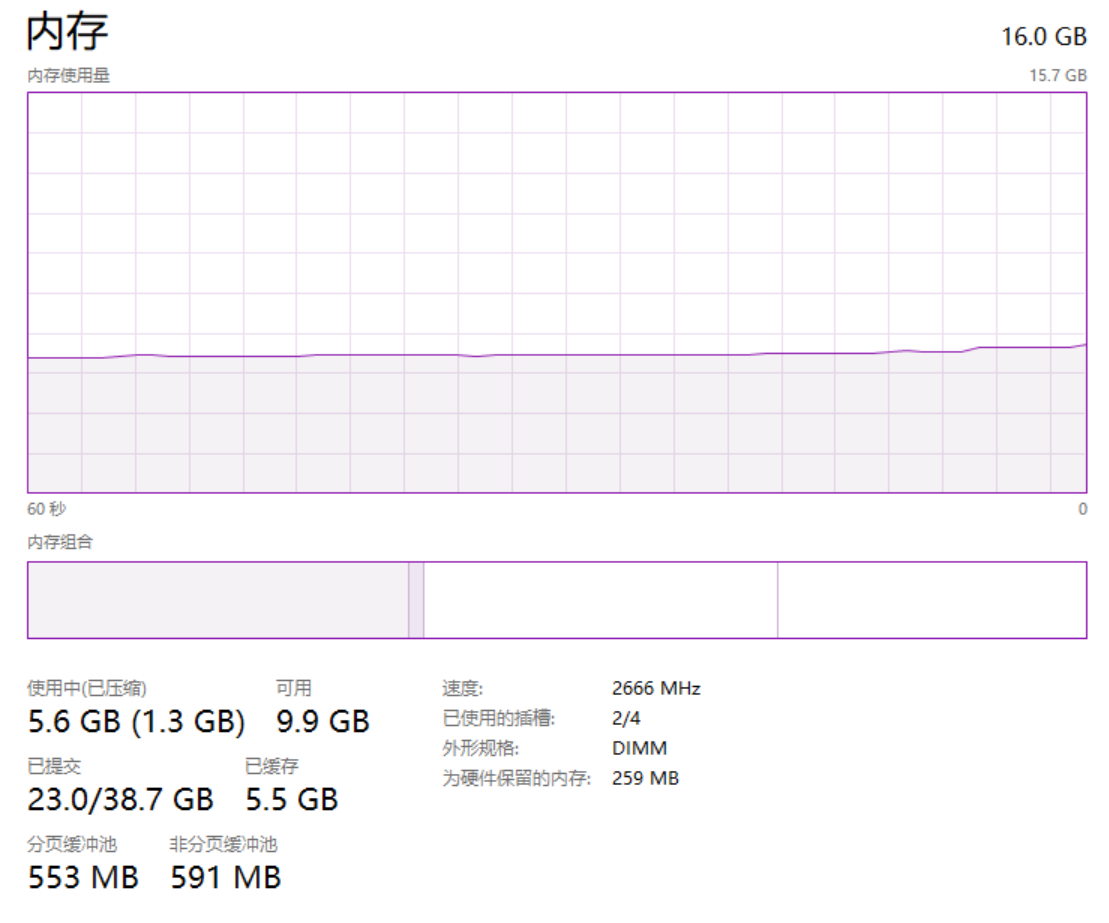
從上面截圖可以看到,我本機是 16G 的記憶體大小,目前還有 9.9G 的記憶體可以使用。
也就是說截圖的這個時刻,我能使用的堆外記憶體頂天了也就是 9.9G 這個數。
那麼我先用它個 6G,程式一啟動,走勢圖就會變成這樣:
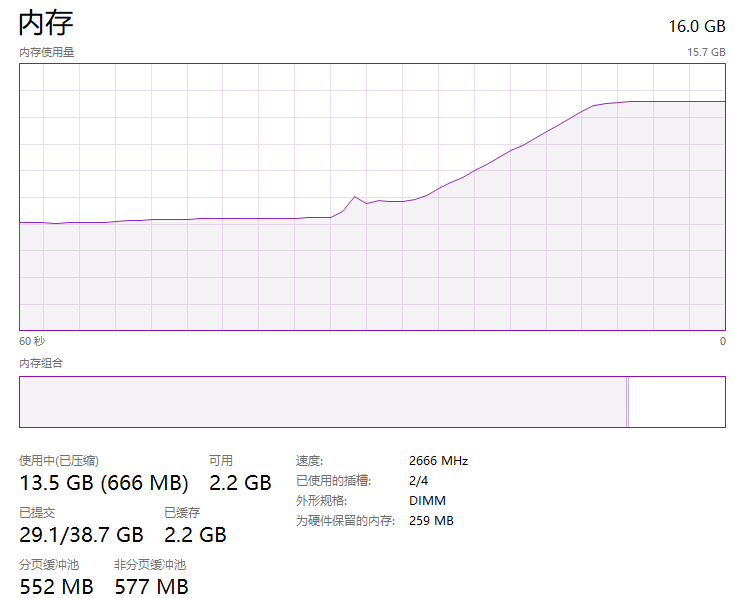
而程式一關閉,記憶體佔用立馬就釋放了:
也許你沒注意到,前面我說了一句「用它個 6G」,我怎麼控制這個 6G 的呢?
因為我在程式裡面加了這樣一行程式碼:
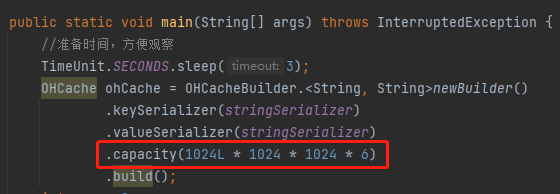
如果你不加的話,預設只會使用 64M 的堆外記憶體,看不出啥曲線。
如果你要想自己玩一玩,想親眼看看這個走勢圖,記得加上這行程式碼,具體的值按照你機器的情況給就行了,個人建議是先做好儲存工作,最好是意思意思就行了,別把值給的太大,電腦玩壞了你來找我,我不僅不賠錢,我還會笑你。

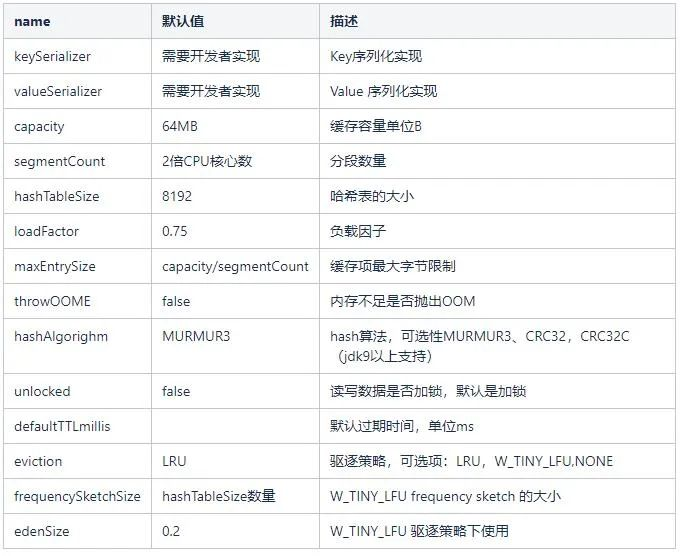
然後除了這個 「6G」 可以自定義外,還有一些很多可以自定義的引數,清單如下,可以自己研究一波:
原始碼
前面說了,本文也不會帶你去閱讀原始碼,因為這個專案的原始碼寫的已經很通俗易懂了,你自己去看,就知道主幹邏輯寫的非常的順暢,沒必要做太多的原始碼解析。
我最多在這裡指個路。
我看原始碼是從 put 方法開始看的,但是 put 方法有兩個實現類:
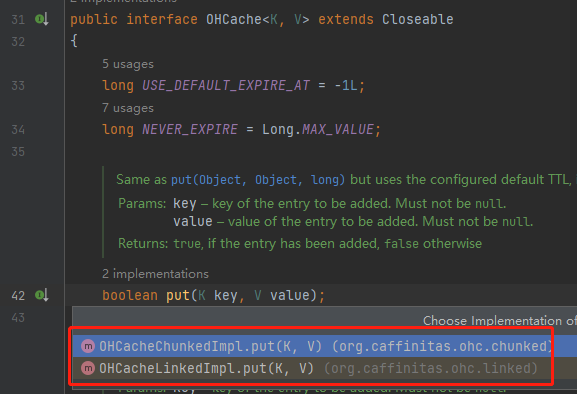
關於這兩個實現類,github 上進行了介紹:
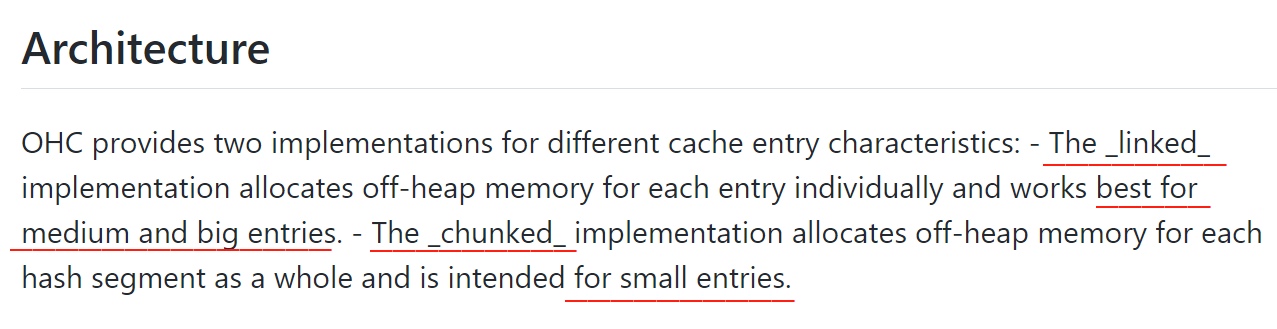
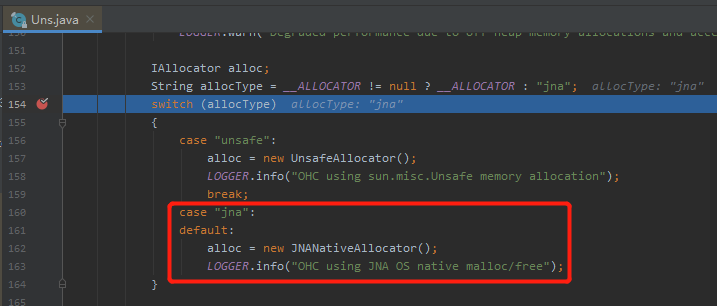
linked 實現方式:為每個需要快取的物件單獨分配堆外記憶體,對中、大條目效果最好。 chunked 實現方式:為每個雜湊段整體分配堆外記憶體,相當於有個預分配的意思,適用於小條目。
但是這裡你只需要看 linked 實現方式就行了。
為啥?
別問,問就是作者建議的,在 github 的 README 裡面有這樣一個 NOTE:
Note: the chunked implementation should still be considered experimental.
翻譯一下就是說:目前,chunked 實現方式應被當做是 experimental。
experimental,放在句末,你就知道這是一個形容詞了,什麼意思呢?
四級詞彙,如果不認識的話趕緊背一背哈,考試要考的。
作者說 chunked 實現方式還是實驗階段,肯定是有什麼「暗坑」在裡面的,不踩坑的最好方式,就是不用它。
然後,你看著看著會發現,這個資料結構,和 ConcurrentHashMap 好像啊。是的,有 Segment,有 bucket,有 entry,所以不要懷疑自己,確實很像。
接著,你看原始碼的時候,肯定是 Debug 的方式效率更高嘛。
當你 debug 的物件是 put 方法的時候,要不了幾下你就能看看這個地方:
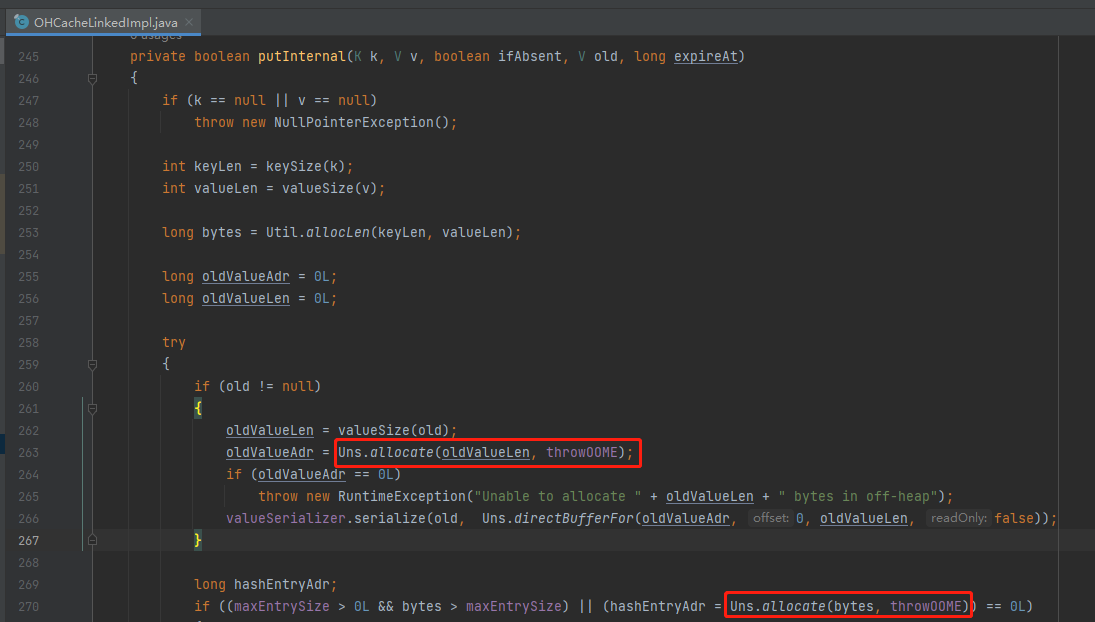
這個地方是申請堆外記憶體的操作,對應的是 IAllocator 這個介面:
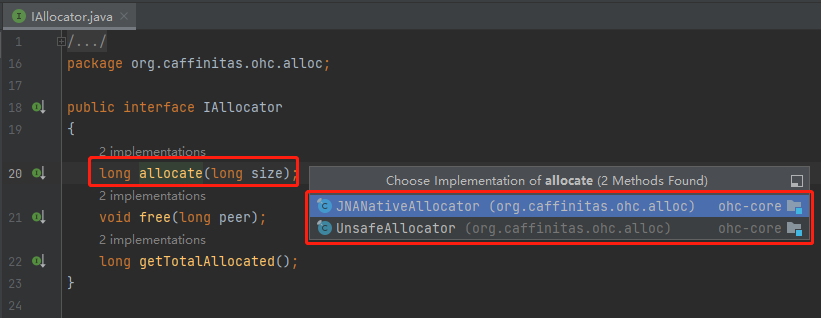
介面裡面有三個方法:
allocate:申請記憶體 free:釋放記憶體 getTotalAllocated:獲取已申請記憶體(空方法,未實現)
主要關心前兩個方法,因為我前面說了,這個是堆外記憶體,需要自己管理記憶體。管理就分為申請和釋放,對應的就是這兩個方法。
所以,這裡可以說是整個 OHC 框架的核心。
帶你盤一下這部分。

操作堆外記憶體
其實堆外記憶體這個東西,你一定是接觸過的,只不過一般是框架封裝好了,它是自己悄悄咪咪的使用,你沒注意到而已罷了。
一般我們申請堆外記憶體,就會這樣去寫:
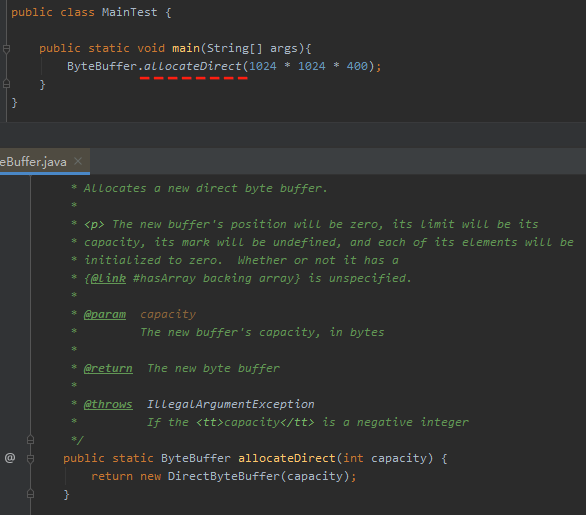
這個方法最終會呼叫 Unsafe 裡面的 allocateMemory 這個 native 方法,它相當於 C++ 的 malloc 函數:
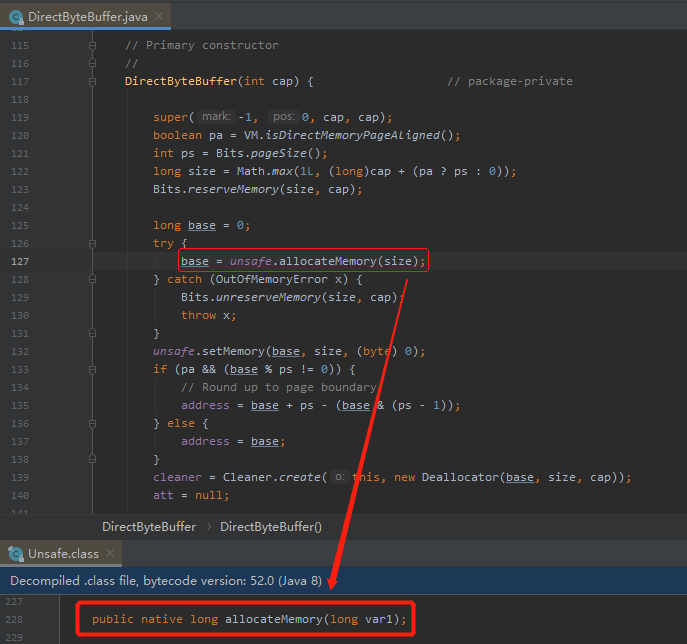
這個方法會為我們在作業系統的記憶體中去分配一個我們指定大小的記憶體供我們使用,這個記憶體就叫做堆外記憶體,不由 JVM 控制,即不在 gc 管理範圍內的。
這個方法返回值是 long 型別數值,也就是申請的記憶體對應的首地址。
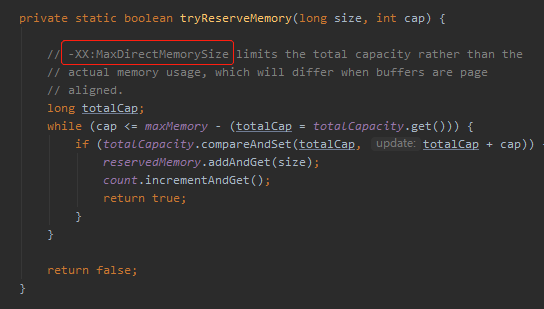
但是需要注意的是,JVM 有個叫做 -XX:MaxDirectMemorySize (最大堆外記憶體)的設定,如果使用 ByteBuffer.allocateDirect 申請堆外記憶體,大小會受到這個設定的限制,因為會呼叫這個方法:
OHC 要使用堆外記憶體,必然也是通過某個方法向作業系統申請了一部分記憶體,那麼它申請記憶體的方法,是不是也是 allocateMemory 呢?
這個問題,在 github 上作者給出了否認三連:
不僅告訴了你沒有使用,還告訴了你為什麼沒有使用:

首先,開頭的這個玩意 「TL;DR」 就直接把我幹懵逼了。然後我查了一下,原來是 「Too long; Don't read」 的縮寫,直譯過來的意思就是:太長了,讀不下去。
但是我覺得結合語境分析,作者放在的意思應該是一種類似於「長話短說」的意思。
這個短語,一般用於在文章開頭,先給出乾貨。

你看,又學一個小知識。
然後,我大概給你解釋一下這一段 English 在說個什麼意思。
作者說,繞過 ByteBuffer.allocateDirect 方法,直接分配堆外記憶體,對 GC 來說是更加平穩的,因為我們可以明確控制記憶體分配,更重要的是可以由我們自己完全控制記憶體的釋放。
如果使用 ByteBuffer.allocateDirect 方法,可能在垃圾回收期間,就釋放了堆外記憶體。
這句話對應到程式碼中就是這裡,而這樣的操作,在 OHC 裡面是不需要的。OHC 希望由框架自己來全權掌握什麼時候應該釋放:
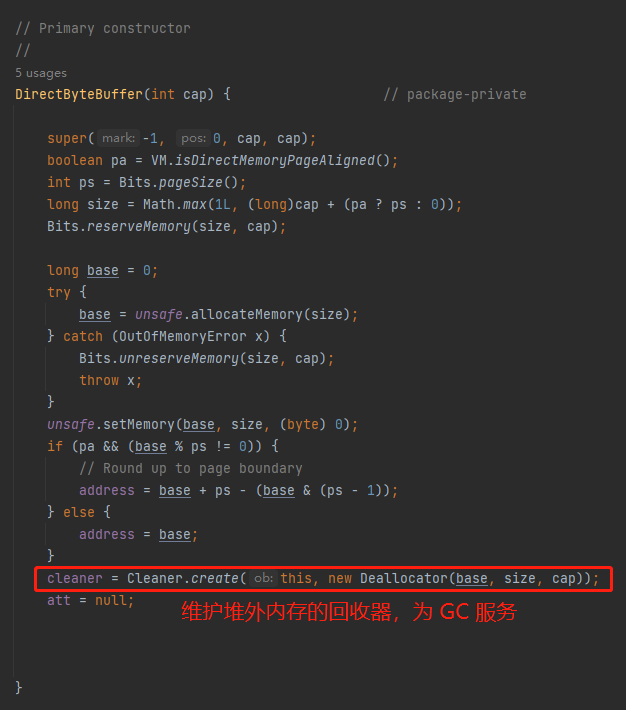
然後作者接著說:此外,如果分配記憶體的時候,沒有更多的堆外記憶體可以使用,它可能會觸發一個 Full GC,如果多個申請記憶體的執行緒同時遇到這種情況,這是有問題的,因為這意味著大量 Full GC 的連續發生。
這句話對應的程式碼是這裡:
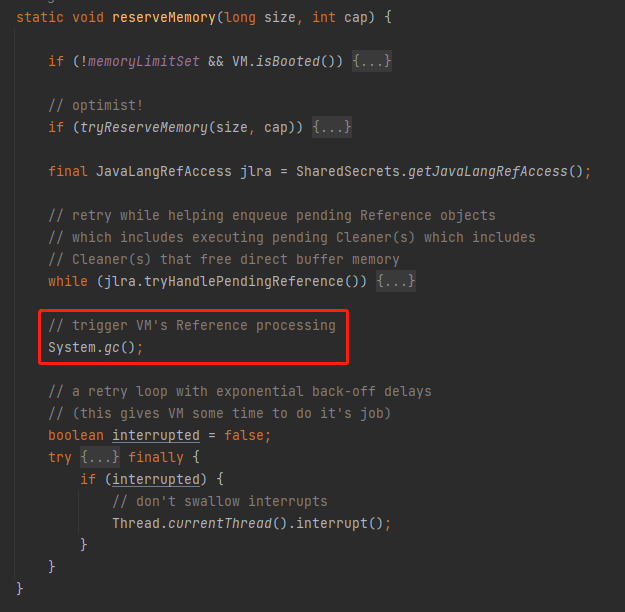
如果堆外記憶體不足的時候,會觸發一次 Full GC。可以想象,在機器記憶體吃緊的時候,程式還在不停的申請堆外記憶體,繼而導致 Full GC 的頻繁出現,是一種什麼樣的「災難性」的後果,基本上服務就處於不可用狀態了。
OHC 需要避免這種情況的發生。
除了這兩個原因之後,作者還說:
Further, the stock implementation uses a global, synchronized linked list to track off-heap memory allocations.
在 ByteBuffer.allocateDirect 方法的實現裡面,還使用了一個全域性的、同步的 linked List 這個資料結構來跟蹤堆外記憶體的分配。
這裡我不清楚它說的這個 「linked list」 對應具體是什麼東西,所以我也不亂解釋了,你要知道的話可以在評論區給我指個路,我也學習學習。
綜上,作者最後一句說:這就是為什麼 OHC 直接分配堆外記憶體的原因。
This is why OHC allocates off-heap memory directly。
然後他還提了一個建議:
and recommends to preload jemalloc on Linux systems to improve memory managment performance.
建議在 Linux 系統上預裝 jemalloc 以提高記憶體管理效能。
弦外之音就是要拿它來替換 glibc 的 malloc 嘛,jemalloc 基本上是碾壓 malloc。
關於 jemalloc 和 malloc 網上有很多相關的文章了,有興趣的也可以去找找,我這裡就不展開了。
現在我們知道 OHC 並沒有使用常規的 ByteBuffer.allocateDirect 方法來完成堆外記憶體的申請,那麼它是怎麼實現這個「騷操作」的呢?
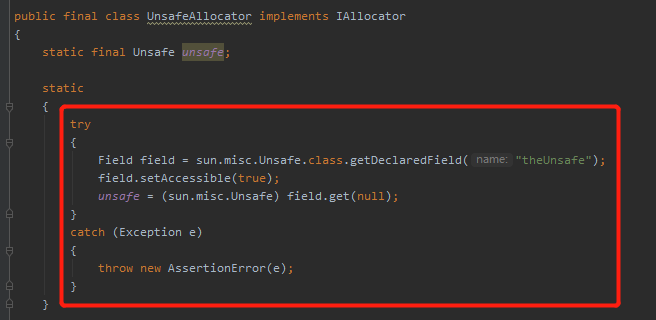
在 UnsafeAllocator 實現類裡面是這樣寫的:
org.caffinitas.ohc.alloc.UnsafeAllocator
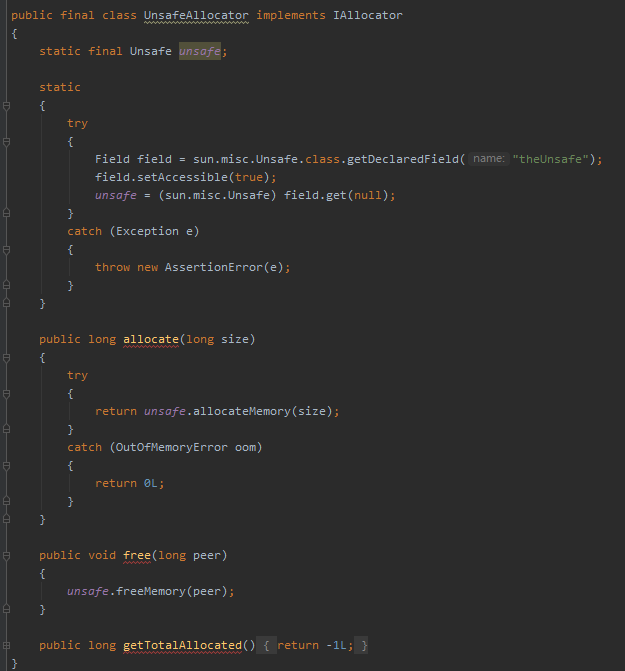
通過反射直接獲取到 Unsafe 並進行操作,沒有任何多餘的程式碼。
而在 JNANativeAllocator 實現類裡面,則採用的是 JNA 的方式操作記憶體:
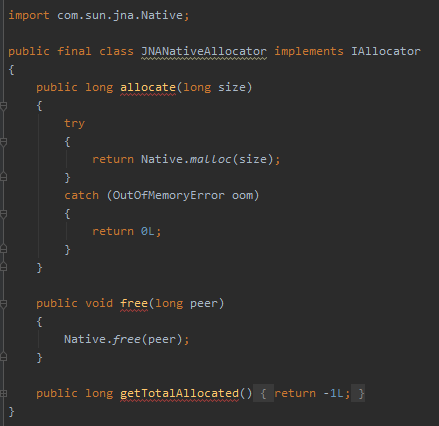
OHC 框架預設採用的是 JNA 的方式,這一點通過程式碼或者紀錄檔輸出也能進行驗證:
關於 Unsafe 和 JNA 這兩種操作堆外記憶體的方式,到底誰更好,我在網上找到了這個連結:
https://mail.openjdk.org/pipermail/hotspot-dev/2015-February/017089.html
這封郵件的是 Aleksey Shipilev 針對一個叫做 Robert 的網友提出問題進行的回覆。
問題是這樣的,Robert 他用對 Native.malloc() 和 Unsafe.allocateMemory() 進行了基準測試,發現前者的效能是後者的三倍。想知道為什麼:

然後 Aleksey Shipilev 針對這個問題進行了解析。
這哥們是誰?
他是基準測試的爸爸:
所以他的回答還是比較權威的,但是需要注意的是,他並沒有正面說明兩個方法歲更好,只是解釋了為什麼用 JMH 出現了效能差 3 倍這個現象。
另外,我必須得多說一句,通過反射拿 Unsafe 這段程式碼可是個好東西啊,建議熟讀、理解、融會貫通:
在 OHC 裡面不就是一個非常好的例子嘛,雖然有現成的方法,但是和我的場景不是非常的匹配,我並不需要一些限制性的判斷,只是想要簡簡單單的要一個堆外記憶體來用一用而已。
那我就繞過中間商,自己直接呼叫 Unsafe 裡面的方法。
怎麼拿到 Unsafe 呢?
就是前面這段程式碼,就是通過反射,你在其他的開源框架裡面可以看到非常多類似的或者一模一樣的程式碼片段。
背下來就完事。
好了,文章就到這裡了,如果對你有一絲絲的幫助,幫我點個免費的贊,不過分吧?